python全栈开发第10天-正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python全栈开发第10天-正则表达式相关的知识,希望对你有一定的参考价值。
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
1.grep : 最早的文本匹配程序,使用POSIX定义的基本正则表达式(BRE)来匹配文本。
2.egrep : 扩展式grep,其使用扩展式正规表达式(ERE)来匹配文本。(一般这个是我们最常用的,此命令和grep -E 是一样的)
3.fgrep : 快速grep,这个版本匹配固定字符串而非正则表达式。并且是唯一可以并行匹配多个字符串的版本。
如下简单的介绍grep命令:
语法格式:
grep [options ...] pattern-spec [files ...]
用途:
匹配一个或多个模式的文本行。
我们以文件a.txt中的以下内容来进行举例示意grep命令各个参数的功能:
root
root123
123root
2222222222222222222
rrrrrroot
rOot
rOOT
rooooooooooot
rooooottttttttttt
kkkkkkk
参数(options):
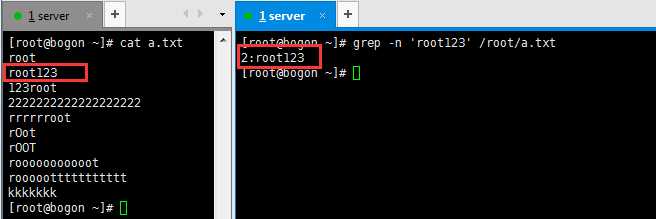
-n :显示行号,举例如图:
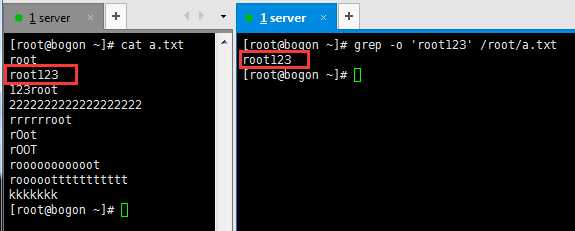
-o :只显示匹配的内容
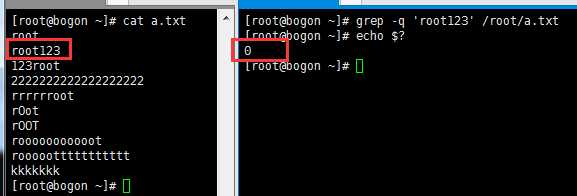
-q :静默模式,没有任何输出,得用$?来判断执行成功没有,即有没有过滤到想要的内容
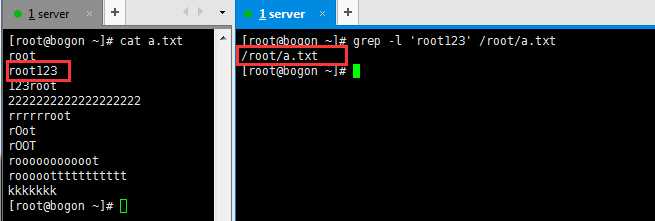
-l :如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl一起用,grep -rl ‘root‘ /etc
-A :如果匹配成功,则将匹配行及其后n行一起打印出来
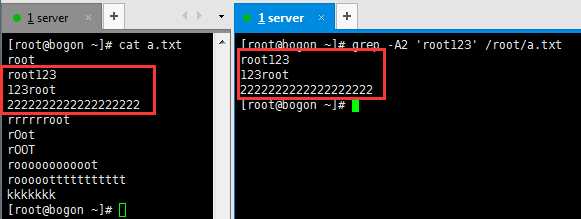
-B :如果匹配成功,则将匹配行及其前n行一起打印出来
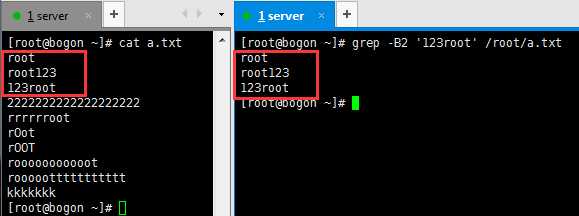
-C :如果匹配成功,则将匹配行及其前后n行一起打印出来
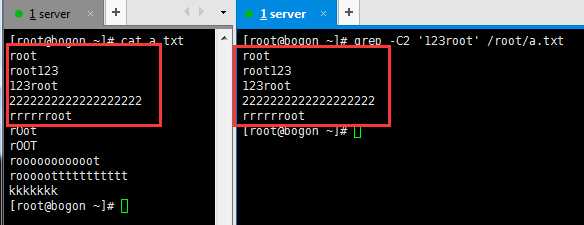
--color 是着重显示要匹配的内容
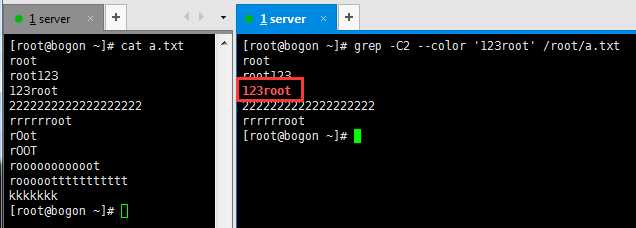
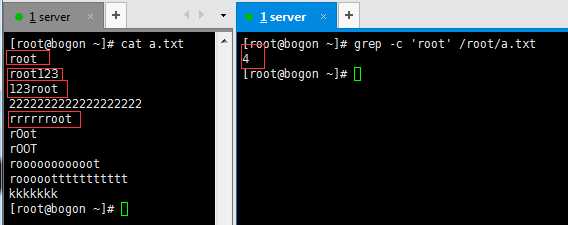
-c :如果匹配成功,则将匹配到的行数打印出来
-E :等于egrep,扩展
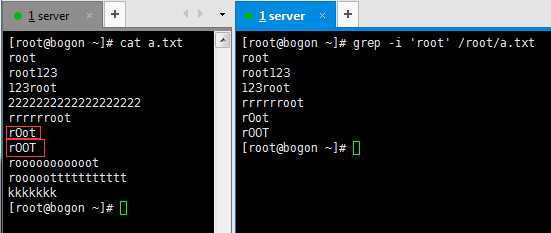
-i :忽略大小写
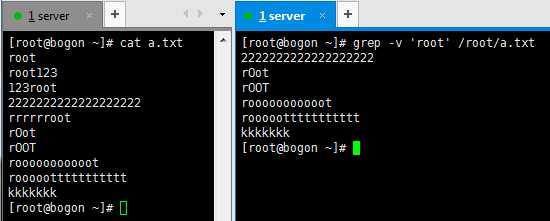
-v :取反,不匹配
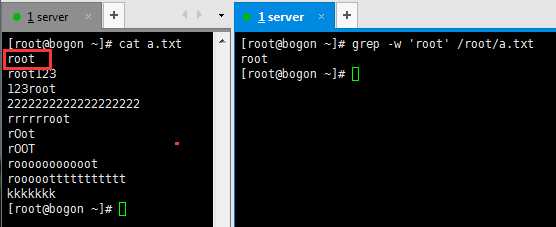
-w:匹配单词
二、正则介绍
^ 行首
$ 行尾
. 除了换行符以外的任意单个字符
* 前导字符的零个或多个
.* 所有字符
[] 字符组内的任一字符
[^] 对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^] 非字符组内的字符开头的行
[a-z] 小写字母
[A-Z] 大写字母
[a-Z] 小写和大写字母
[0-9] 数字
\\< 单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\\> 单词尾
扩展正则 sed 加 -r 参数 或转义
grep 加 -E 或 egrep 或转义
AWK 直接支持 但不包含{n,m}
可以使用--posix支持
[[email protected] ~]# awk ‘/ro{1,3}/{print}‘ /etc/passwd
[[email protected] ~]# awk --posix ‘/ro{1,3}/{print}‘ /etc/passwd
sed -n ‘/roo\\?/p‘ /etc/passwd
sed -rn ‘/roo?/p‘ /etc/passwd
? 前导字符零个或一个
+ 前导字符一个或多个
abc|def abc或def
a(bc|de)f abcf 或 adef
x\\{m\\} x出现m次
x\\{m,\\} x出现m次至多次(至少m次)
x\\{m,n\\} x出现m次至n次
posix定义的字符分类
[:alnum:] Alphanumeric characters.
匹配范围为 [a-zA-Z0-9]
[:alpha:] Alphabetic characters.
匹配范围为 [a-zA-Z]
[:blank:] Space or tab characters.
匹配范围为 空格和TAB键
[:cntrl:] Control characters.
匹配控制键 例如 ^M 要按 ctrl+v 再按回车 才能输出
[:digit:] Numeric characters.
匹配所有数字 [0-9]
[:graph:] Characters that are both printable and visible. (A space is print-
able, but not visible, while an a is both.)
匹配所有可见字符 但不包含空格和TAB 就是你在文本文档中按键盘上能用眼睛观察到的所有符号
[:lower:] Lower-case alphabetic characters.
小写 [a-z]
[:print:] Printable characters (characters that are not control characters.)
匹配所有可见字符 包括空格和TAB
能打印到纸上的所有符号
[:punct:] Punctuation characters (characters that are not letter, digits, con-
trol characters, or space characters).
特殊输入符号 +-=)(*&^%$#@!~`|\\"‘{}[]:;?/>.<,
注意它不包含空格和TAB
这个集合不等于^[a-zA-Z0-9]
[:space:] Space characters (such as space, tab, and formfeed, to name a few).
[:upper:] Upper-case alphabetic characters.
大写 [A-Z]
[:xdigit:] Characters that are hexadecimal digits.
16进制数 [0-f]
使用方法:
[[email protected] ~]# grep --color ‘[[:alnum:]]‘ /etc/passwd
三、sed命令:
sed命令行格式为:
sed [-nefri] ‘command’ 输入文本/文件
常用选项:
-n∶取消默认的输出,使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来
-e∶进行多项编辑,即对输入行应用多条sed命令时使用. 直接在指令列模式上进行 sed 的动作编辑
-f∶指定sed脚本的文件名. 直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作
-r∶sed 的动作支援的是延伸型正则表达式的语法。(预设是基础正则表达式语法)
-i∶直接修改读取的文件内容,而不是由屏幕输出
常用命令:
a ∶ 新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c ∶ 取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
d ∶ 删除,因为是删除,所以 d 后面通常不接任何内容
i ∶ 插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行)
p∶ 列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起用
s∶ 取代,可以直接进行替换的工作。通常这个 s 的动作可以搭配正则表达式。例如 1,20s/old/new/g
定址
|
|
只显示指定行范围的文件内容,例如:
sed -n ‘100,200p‘ mysql_slow_query.log
地址是逗号分隔的,那么需要处理的地址是这两行之间的范围(包括这两行在内)。范围可以用数字、正则表达式、或二者的组合表示。例如:
|
|
举例:(假设我们有一文件名为ab)
删除某行
[[email protected] ruby] # sed ‘1d‘ ab #删除第一行
[[email protected] ruby] # sed ‘$d‘ ab #删除最后一行
[[email protected] ruby] # sed ‘1,2d‘ ab #删除第一行到第二行
[[email protected] ruby] # sed ‘2,$d‘ ab #删除第二行到最后一行
显示某行
. [[email protected] ruby] # sed -n ‘1p‘ ab #显示第一行
[[email protected] ruby] # sed -n ‘$p‘ ab #显示最后一行
[[email protected] ruby] # sed -n ‘1,2p‘ ab #显示第一行到第二行
[[email protected] ruby] # sed -n ‘2,$p‘ ab #显示第二行到最后一行
使用模式进行查询
[[email protected] ruby] # sed -n ‘/ruby/p‘ ab #查询包括关键字ruby所在所有行
[[email protected] ruby] # sed -n ‘/\\$/p‘ ab #查询包括关键字$所在所有行,使用反斜线\\屏蔽特殊含义
增加一行或多行字符串
[[email protected] ruby]# cat ab
Hello!
ruby is me,welcome to my blog.
end
[[email protected] ruby] # sed ‘1a drink tea‘ ab #第一行后增加字符串"drink tea"
Hello!
drink tea
ruby is me,welcome to my blog.
end
[[email protected] ruby] # sed ‘1,3a drink tea‘ ab #第一行到第三行后增加字符串"drink tea"
Hello!
drink tea
ruby is me,welcome to my blog.
drink tea
end
drink tea
[[email protected] ruby] # sed ‘1a drink tea\\nor coffee‘ ab #第一行后增加多行,使用换行符\\n
Hello!
drink tea
or coffee
ruby is me,welcome to my blog.
end
代替一行或多行
[[email protected] ruby] # sed ‘1c Hi‘ ab #第一行代替为Hi
Hi
ruby is me,welcome to my blog.
end
[[email protected] ruby] # sed ‘1,2c Hi‘ ab #第一行到第二行代替为Hi
Hi
end
替换一行中的某部分
格式:sed ‘s/要替换的字符串/新的字符串/g‘ (要替换的字符串可以用正则表达式)
[[email protected] ruby] # sed -n ‘/ruby/p‘ ab | sed ‘s/ruby/bird/g‘ #替换ruby为bird
[[email protected] ruby] # sed -n ‘/ruby/p‘ ab | sed ‘s/ruby//g‘ #删除ruby
插入
[[email protected] ruby] # sed -i ‘$a bye‘ ab #在文件ab中最后一行直接输入"bye"
[[email protected] ruby]# cat ab
Hello!
ruby is me,welcome to my blog.
end
bye
替换:
-e是编辑命令,用于sed执行多个编辑任务的情况下。在下一行开始编辑前,所有的编辑动作将应用到模式缓冲区中的行上。
sed -e ‘1,10d‘ -e ‘s/My/Your/g‘ datafile
#选项-e用于进行多重编辑。第一重编辑删除第1-3行。第二重编辑将出现的所有My替换为Your。因为是逐行进行这两项编辑(即这两个命令都在模式空间的当前行上执行),所以编辑命令的顺序会影响结果。
# 替换两个或多个空格为一个空格
sed ‘s/[ ][ ]*/ /g‘ file_name
# 替换两个或多个空格为分隔符:
sed ‘s/[ ][ ]*/:/g‘ file_name
# 如果空格与tab共存时用下面的命令进行替换
# 替换成空格
sed ‘s/[[:space:]][[:space:]]*/ /g‘ filename
# 替换成分隔符:
sed ‘s/[[:space:]][[:space:]]*/:/g‘ filename
==============
sed命令的调用:
在命令行键入命令;将sed命令插入脚本文件,然后调用sed;将sed命令插入脚本文件,并使sed脚本可执行
sed [option] sed命令 输入文件 在命令行使用sed命令,实际命令要加单引号
sed [option] -f sed脚本文件 输入文件 使用sed脚本文件
sed脚本文件 [option] 输入文件 第一行具有sed命令解释器的sed脚本文件
option如下:
n 不打印; sed不写编辑行到标准输出,缺省为打印所有行(编辑和未编辑),p命令可以用来打印编辑行
c 下一命令是编辑命令,使用多项编辑时加入此选项
f 如果正在调用sed脚本文件,使用此选项,此选项通知sed一个脚本文件支持所用的sed命令,如
sed -f myscript.sed input_file 这里myscript.sed即为支持sed命令的文件
使用重定向文件即可保存sed的输出
使用sed在文本中定位文本的方式:
x x为一行号,比如1
x,y 表示行号范围从x到y,如2,5表示从第2行到第5行
/pattern/ 查询包含模式的行,如/disk/或/[a-z]/
/pattern/pattern/ 查询包含两个模式的行,如/disk/disks/
/pattern/,x 在给定行号上查询包含模式的行,如/disk/,3
x,/pattern/ 通过行号和模式查询匹配行,如 3,/disk/
x,y! 查询不包含指定行号x和y的行
基本sed编辑命令:
p 打印匹配行 c/ 用新文本替换定位文本
= 显示文件行号 s 使用替换模式替换相应模式
a/ 在定位行号后附加新文本信息 r 从另一个文本中读文本
i/ 在定位行号后插入新文本信息 w 写文本到一个文件
d 删除定位行 q 第一个模式匹配完成后退出或立即退出
l 显示与八进制ASCII代码等价的控制字符 y 传送字符
n 从另一个文本中读文本下一行,并附加在下一行 {} 在定位行执行的命令组
g 将模式2粘贴到/pattern n/
基本sed编程举例:
使用p(rint)显示行: sed -n ‘2p‘ temp.txt 只显示第2行,使用选项n
打印范围: sed -n ‘1,3p‘ temp.txt 打印第1行到第3行
打印模式: sed -n ‘/movie/‘p temp.txt 打印含movie的行
使用模式和行号查询: sed -n ‘3,/movie/‘p temp.txt 只在第3行查找movie并打印
显示整个文件: sed -n ‘1,$‘p temp.txt $为最后一行
任意字符: sed -n ‘/.*ing/‘p temp.txt 注意是.*ing,而不是*ing
打印行号: sed -e ‘/music/=‘ temp.txt
附加文本:(创建sed脚本文件)chmod u+x script.sed,运行时./script.sed temp.txt
#!/bin/sed -f
/name1/ a/ #a/表示此处换行添加文本
HERE ADD NEW LINE. #添加的文本内容
插入文本: /name1/ a/ 改成 4 i/ 4表示行号,i插入
修改文本: /name1/ a/ 改成 /name1/ c/ 将修改整行,c修改
删除文本: sed ‘1d‘ temp.txt 或者 sed ‘1,4d‘ temp.txt
替换文本: sed ‘s/source/OKSTR/‘ temp.txt 将source替换成OKSTR
sed ‘s//$//g‘ temp.txt 将文本中所有的$符号全部删除
sed ‘s/source/OKSTR/w temp2.txt‘ temp.txt 将替换后的记录写入文件temp2.txt
替换修改字符串: sed ‘s/source/"ADD BEFORE" &/p‘ temp.txt
结果将在source字符串前面加上"ADD BEFORE",这里的&表示找到的source字符并保存
sed结果写入到文件: sed ‘1,2 w temp2.txt‘ temp.txt
sed ‘/name/ w temp2.txt‘ temp.txt
从文件中读文本: sed ‘/name/r temp2.txt‘ temp.txt
在每列最后加文本: sed ‘s/[0-9]*/& Pass/g‘ temp.txt
从shell向sed传值: echo $NAME | sed "s/go/$REP/g" 注意需要使用双引号
快速一行命令:
‘s//.$//g‘ 删除以句点结尾行
‘-e /abcd/d‘ 删除包含abcd的行
‘s/[][][]*/[]/g‘ 删除一个以上空格,用一个空格代替
‘s/^[][]*//g‘ 删除行首空格
‘s//.[][]*/[]/g‘ 删除句号后跟两个或更多的空格,用一个空格代替
‘/^$/d‘ 删除空行
‘s/^.//g‘ 删除第一个字符,区别 ‘s//.//g‘删除所有的句点
‘s/COL/(.../)//g‘ 删除紧跟COL的后三个字母
‘s/^////g‘ 删除路径中第一个/
///////////////////////////////////////////////////////////////////////
、使用句点匹配单字符 句点“.”可以匹配任意单字符。“.”可以匹配字符串头,也可以是中间任意字符。假定正在过滤一个文本文件,对于一个有1 0个字符的脚本集,要求前4个字符之后为X C,匹配操作如下:. . . .X C. . . .
2、在行首以^匹配字符串或字符序列 ^只允许在一行的开始匹配字符或单词。在行首第4个字符为1,匹配操作表示为:^ . . . 1
3、在行尾以$匹配字符串或字符 可以说$与^正相反,它在行尾匹配字符串或字符, $符号放在匹配单词后。如果在行尾匹配单词j e t 0 1,操作如下:j e t 0 1 $ 如果只返回包含一个字符的行,操作如下:^ . $
4、使用*匹配字符串中的单字符或其重复序列 使用此特殊字符匹配任意字符或字符串的重复多次表达式。
5、使用/屏蔽一个特殊字符的含义 有时需要查找一些字符或字符串,而它们包含了系统指定为特殊字符的一个字符。如果要在正则表达式中匹配以* . p a s结尾的所有文件,可做如下操作:/ * / . p a s
6、使用[]匹配一个范围或集合 使用[ ]匹配特定字符串或字符串集,可以用逗号将括弧内要匹配的不同字符串分开,但并不强制要求这样做(一些系统提倡在复杂的表达式中使用逗号),这样做可以增 加模式的可读性。使用“ -”表示一个字符串范围,表明字符串范围从“ -”左边字符开始,到“ -”右边字符结束。假定要匹配任意一个数字,可以使用:[ 0 1 2 3 4 5 6 7 8 9 ] 要匹配任意字母,则使用:[ A - Z a - z ]表明从A - Z、a - z的字母范围。
7、使用/{/}匹配模式结果出现的次数 使用*可匹配所有匹配结果任意次,但如果只要指定次数,就应使用/ { / },此模式有三种形式,即:
pattern/{n/} 匹配模式出现n次。
pattern/{n,/} 匹配模式出现最少n次。
pattern/{n,m} 匹配模式出现n到m次之间,n , m为0 - 2 5 5中任意整数。
匹配字母A出现两次,并以B结尾,操作如下:A / { 2 / } B匹配值为A A B 匹配A至少4次,使用:A / { 4 , / } B
===============
替换单引号为空:
可以这样写:
sed ‘s/‘"‘"‘//g‘
sed ‘s/‘\\‘‘//g‘
sed s/\\‘//g
==============
在文件的第一行前面插入一行abc
sed -i ‘1i\\abc‘ urfile
sed功能部分引用:
http://www.cnblogs.com/emanlee/archive/2013/09/07/3307642.html
作业:grep作业(正则表达式及字符处理)
目标文件/etc/passwd,使用grep命令或egrep
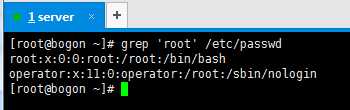
1.显示出所有含有root的行:
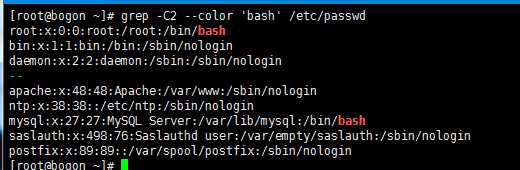
2.输出任何包含bash的所有行,还要输出紧接着这行的上下各两行的内容:
3. 显示出有多少行含有nologin。

4.显示出那些行含有root,并将行号一块输出。

5.显示出文件

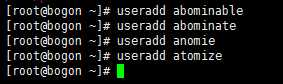
6.新建用户
abominable
abominate
anomie
atomize
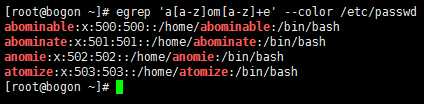
编写正则表达式,将他们匹配出来
7.建四个用户
Alex213sb
Wpq2222b
yH438PIG
egon666
egon
过滤出用户名组成是字母+数字+字母的行

8.显示出/etc目录下所有包含root的文件名
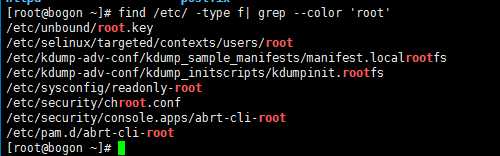
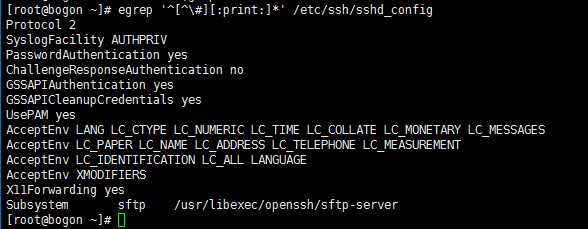
9. 过滤掉/etc/ssh/sshd_config内所有注释和所有空行
[[email protected] ~]# egrep ‘^[^\\#][:print:]*‘ /etc/ssh/sshd_config
作业三:Sed作业:以/etc/passwd文件为模板
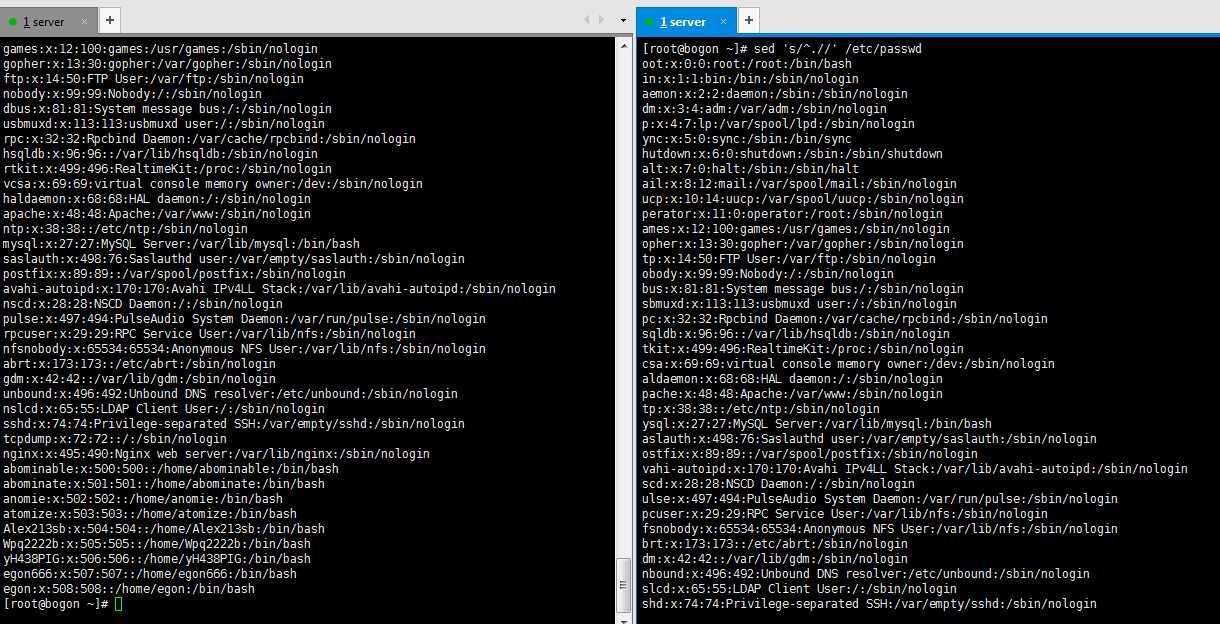
1,删除文件每行的第一个字符。
[[email protected] ~]# sed ‘s/^.//‘ /etc/passwd
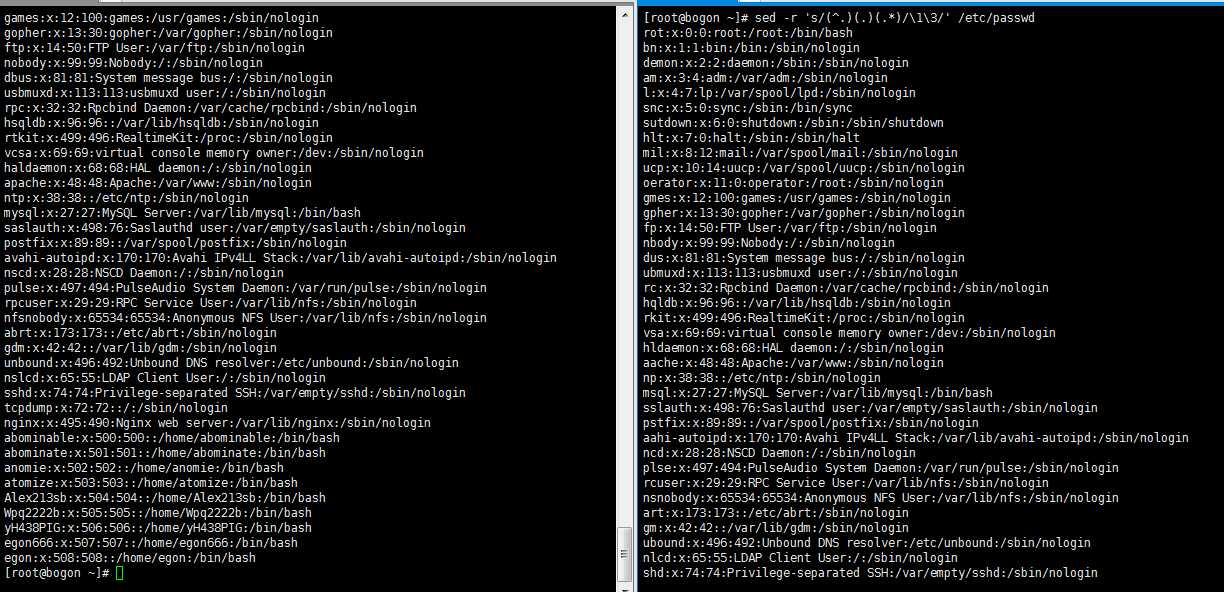
2,删除文件每行的第二个字符。
[[email protected] ~]# sed -r ‘s/(^.)(.)(.*)/\\1\\3/‘ /etc/passwd
3,删除文件每行的最后一个字符。
sed -r ‘s/(.)$//‘ /etc/passwd
4,删除文件每行的倒数第二个字符。
sed -r ‘s/(.*)(.)(.)$/\\1\\3/‘ /etc/passwd
5,删除文件每行的第二个单词。
sed -r ‘s/^([a-Z0-9]+)([^a-Z]+)([a-Z]+)([^a-Z]+)/\\1\\2\\4/‘ /etc/passwd
6,删除文件每行的倒数第二个单词。
sed -r ‘s/([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)$/\\1\\3\\4/‘ /etc/passwd
7,删除文件每行的最后一个单词。
sed -r ‘s/([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)$/\\1\\2\\3/‘ /etc/passwd
8,交换每行的第一个字符和第二个字符。
sed -r ‘s/^(.)(.*)(.)$/\\3\\2\\1/‘ /etc/passwd
9,交换每行的第一个字符和第二个单词。
sed -r ‘s/^(.)([a-Z0-9]*)([^a-Z0-9]+)([a-Z0-9]+)([^a-Z0-9]+)/\\4\\2\\3\\1\\5/‘ /etc/passwd
10,交换每行的第一个单词和最后一个单词。
sed -r ‘s/^([a-Z]+)([^a-Z]+)(.*)([^a-Z]+)([a-Z]+)$/\\5\\2\\3\\4\\1/‘ /etc/passwd
11,删除一个文件中所有的数字。
sed -r ‘s/[0-9]//g‘ /etc/passwd
12,删除每行开头的所有空格。
sed -r ‘s/^ *//g‘ /etc/passwd
13,用制表符替换文件中出现的所有空格。
sed -r ‘s/ /\\t/g‘ /etc/passwd
14,把所有大写字母用括号()括起来。
sed -r ‘s/[A-Z]/(&)/g‘ /etc/passwd
15,打印每行3次。
sed ‘p;p‘ /etc/passwd
16,只显示每行的第一个单词。
sed -r ‘s/^([a-Z]+)([^a-Z]+)(.*)/\\1/‘ /etc/passwd
17,打印每行的第一个单词和第三个单词。
sed -r ‘s/^([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]+)/\\5\\2\\3\\4\\1\\6/‘ /etc/passwd
18,用命令获取格式为 mm/yy/dd 的日期格式,结合管道,将其换成 mm;yy;dd格式
[[email protected] ~]# date +%m/%Y/%d |sed -r ‘s/\\//;/g‘

以上是关于python全栈开发第10天-正则表达式的主要内容,如果未能解决你的问题,请参考以下文章
python全栈开发第九篇Python常用模块一(主要是re正则和collections)