python爬虫之解析库正则表达式
Posted hxms
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之解析库正则表达式相关的知识,希望对你有一定的参考价值。
上次说到了requests库的获取,然而这只是开始,你获取了网页的源代码,但是这并不是我们的目的,我们的目的是解析链接里面的信息,比如各种属性 @href @class span 抑或是p节点里面的文本内容,但是我们需要一种工具来帮我们寻找出这些节点,总不能让我们自己一个一个复制粘贴来完成吧,那样的话,还要程序员干嘛>>计算机是为了方便人们才被发明出来的.
这次我们使用一个非常好用的工具>>正则表达式,可能有的大佬已经听说过了,哦,就是那么一个东西,并说,不是用css选择器或者xpath,beautifulsoup来解析不是更好吗?当然,我开始的时候也是听大佬们这么说的,但是再一些简单的提取信息里,正则表达式的速度确实是最快的,而且有相同的结构的话,构造的表达式更快,关于正则表达式详解大家可以去百度一下>>正则表达式详解<<那里有更多的使用方法,我只是总结利用了一些我个人认为比较好用的正则表达式用法.
例如我们获取了以下的一个网页源代码:
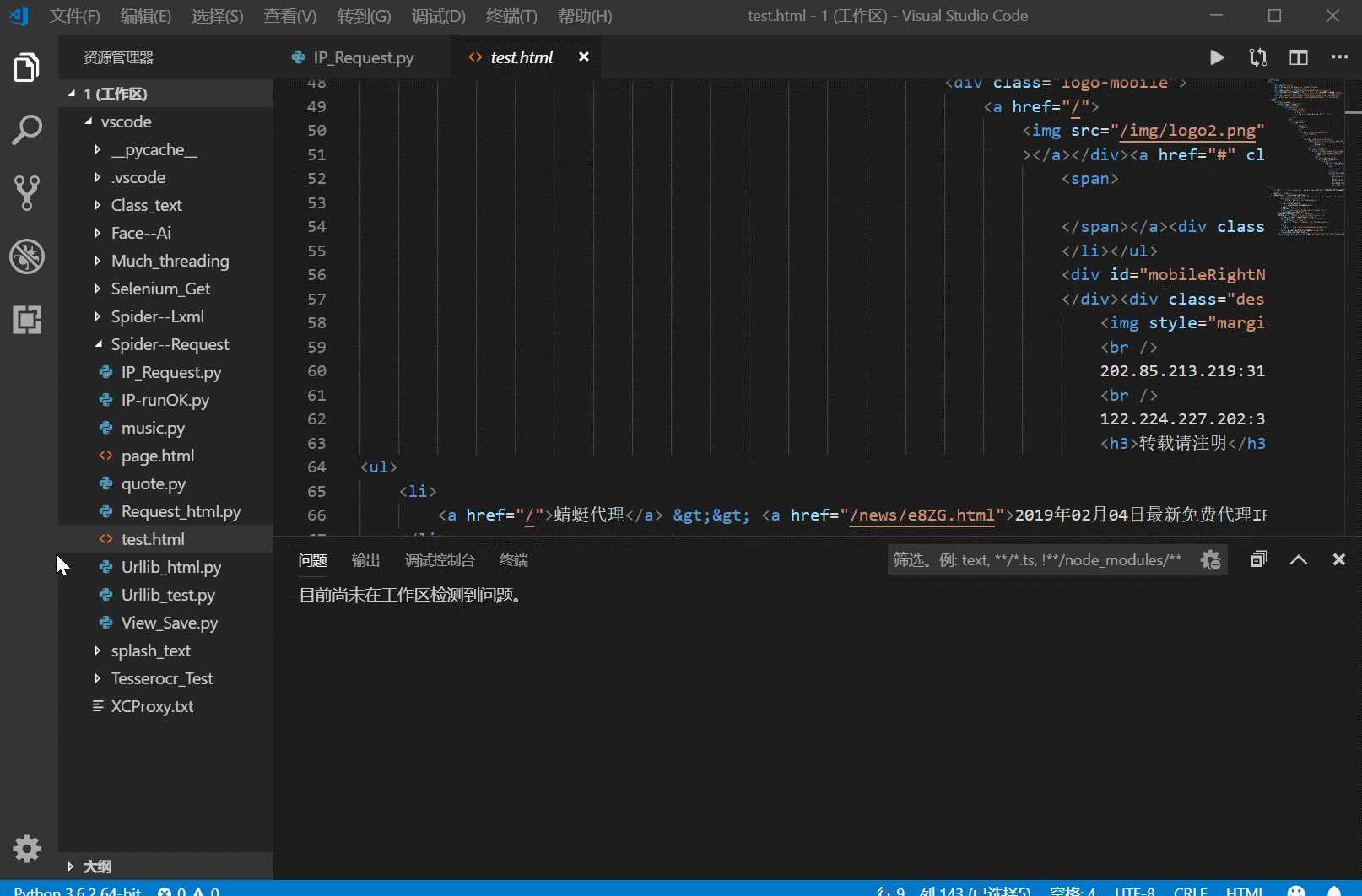
我们想要获取br节点里面的IP地址,怎么办呢/我们可以构造表达式 首先我们得了解一下元字符:
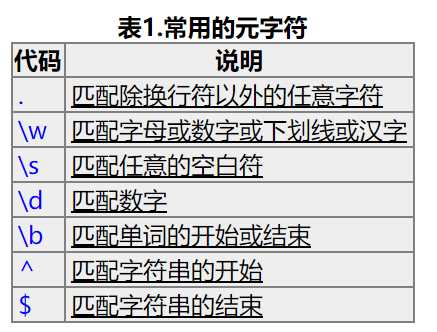
这里说明了匹配得用法,w就是匹配除了非字符的,例如空格 , $%^[email protected]#这些全部别省略而过,因为不符合匹配规则,想要匹配空格,就要换成s 这里我们再了解一下限定符的概念:
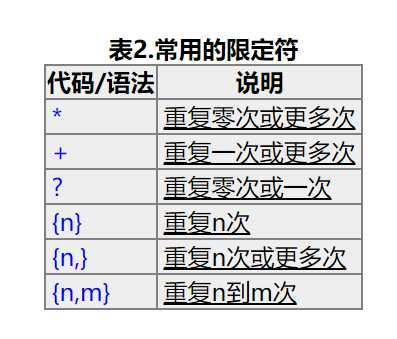
限定符的意思根据我的理解是匹配该符合匹配规则的次数,如果没有要求,它可能匹配出全部给你,也可能只匹配第一个结果给你,限定符就起到了匹配次数的效果,让你做到想使用匹配规则多少次就多少次.下面是一些常用的正则表达式:

可能大家看的有些疑惑,那是因为你之前没有接触过表达式,但是你参照一下上面的规则,再参悟一下,多尝试匹配,看看错在哪里,大概坚持一两天,你就会有一种豁然开朗的感觉,哦,原来是这么一回事啊,我理解一下一个规则用法,比如用户名的匹配规则:<< /^是匹配的开始 然后到[a-z0-9 是说匹配从a到z和0到9的所有字符,然后是_-,,它说明在里面可以匹配下划线_和字符- ,{3,16}是匹配从3次到16次,意思是说该用户可能限制在3到16字节,超过就没有意义了,多了就会导致提取信息的不纯洁性了>> 当然有时候我们想偷懒怎么办,这些规则有太复杂了,光是构造就得花费很多时间了,这时候,我最喜欢得懒惰限定符出现了,先看规则:
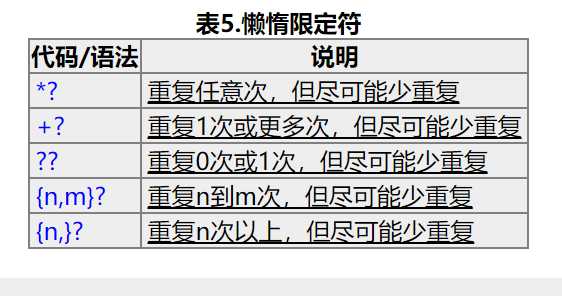
这里可以这样理解 (.*)是匹配尽可能多的字符串,(.*?)是匹配尽可能匹配少的字符 在python中()表示返回匹配得内容,内容为()里面得字符,如果你想获取@href的属性,直接构造为(‘.*?href="(.*?)" ,h.*?‘)就可以获取href的属性了,不过要记住,它返回的是一个列表的形式,所以你想要实现分行显示,还要对列表进行遍历,输入到文本中,继而实现简单的爬取信息.演示如下:
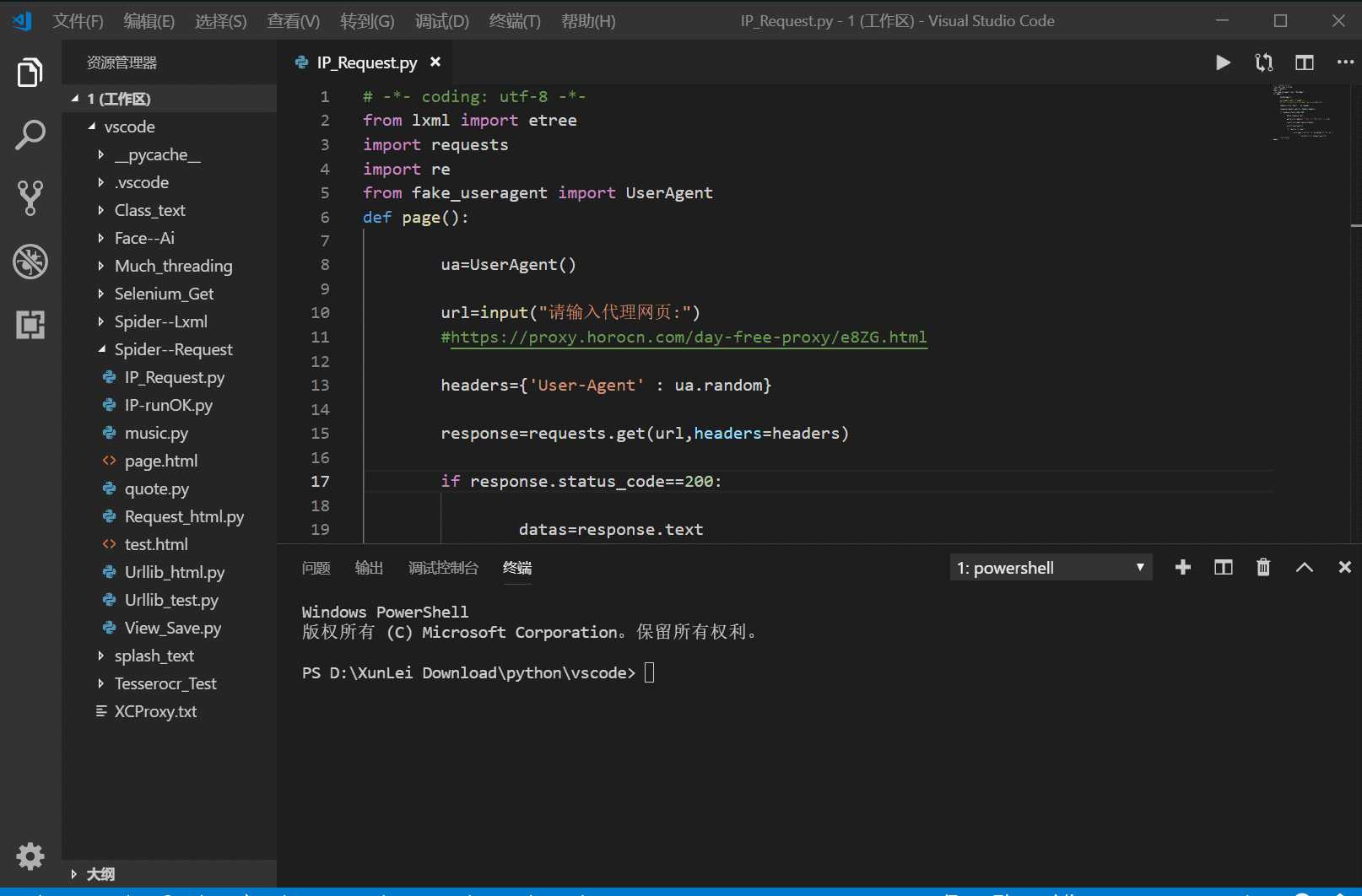
我把我自己写的源代码贴出来,可能不是很完善,只是一个很简单的函数,哪里有缺陷大佬们指出一下
# -*- coding: utf-8 -*- # author :HXM from lxml import etree import requests import re from fake_useragent import UserAgent def page(): ua=UserAgent() url=input("请输入代理网页:") #https://proxy.horocn.com/day-free-proxy/e8ZG.html headers={‘User-Agent‘ : ua.random} response=requests.get(url,headers=headers) if response.status_code==200: datas=response.text pattern=re.compile(‘.*?<br />(.*?)#.*?<br />‘,re.S)#re.S表示换行匹配,不受行数限制,python常用pattern来封装表达式规则,极大方便了调用 result=re.findall(pattern,datas) print(type(result)) for results in result: with open ("ip.txt","a",encoding="utf-8") as f: f.write("{} ".format(results)) return None page()
这里还要说一个重要的匹配方式,是python中独有的
import re #表示导入正则表达式
re.match表示是从第一字符开始匹配,如果规则没有从第一个字符开始表示,尽管你想要的信息就在HTML里面,你也匹配不出来
re.search表示只匹配符合规则的第一字符并返回结果,对匹配限定符规则是无效的,即不遵守限定匹配次数
re.findall表示匹配所有符合规则的字符,遵守限定次数规则,最常用的匹配re库函数
好了,正则表达式就介绍到这里,不过这只是皮毛而已,不过对我们目前应该是够用的,后面还有零断宽言等,大家有兴趣可以了解一下>
以上是关于python爬虫之解析库正则表达式的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫之Beautiful Soup库,基本使用以及提取页面信息