可视化探索开源项目的 contributor 关系
Posted NebulaGraph
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可视化探索开源项目的 contributor 关系相关的知识,希望对你有一定的参考价值。

引语:作为国内外最大的代码托管平台,根据最新的 GitHub 数据,它拥有超 372,000,000 个仓库,其中有 28,000,000 是公开仓。分布式图数据库 NebulaGraph 便是其中之一,同其他开源项目一样,NebulaGrpah 也有自己的 contributor 们,他们是何时,通过哪个 pr 与 NebulaGraph 产生联系的呢?本文尝试用可视化方式,来探索这些 contributor 的痕迹。
世界上有两种需求,一种是能做的,另外一种是不能做的;当然按照合理不合理角度,大多数的需求都是合理但能做的,就像本文的需求一样——用可视化的方式,来“窥探” nebula 开源社区中 contributor 同项目的关系,及他们留下的 pr 痕迹。
故事从两个月前讲起,有一天我司研发 liuyu 同学装了一款名叫 ClickHouse 的数据库,他发现 CK 有一个感人的 contributor 系统表,这不得让我们的运营来“借鉴”下么?
现在,我们来看看感动我司研发的 ClickHouse 是怎么样的存在。
让人感动的 ClickHouse Contributor 系统表
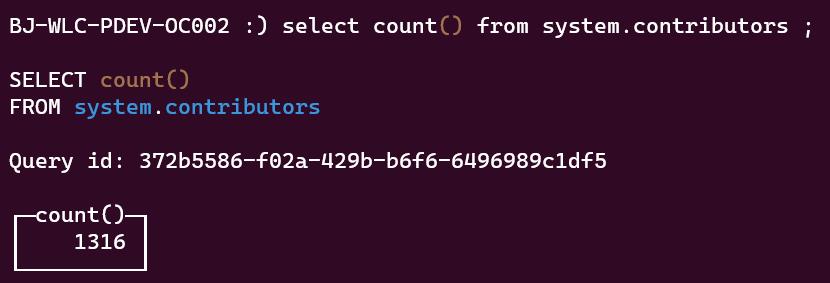
简单来说,只要你装了 CK 数据库,不需要连接任何数据库,系统自带一个数据表,你可以执行以下 SQL
select count() from system.contributors
就能得到一个现有的 CK contributor 总量(下面数据存在一定滞后性):
也可以按照下列方式随机获得 20 位 contributor 名单:
select * from system.contributors limit 20;
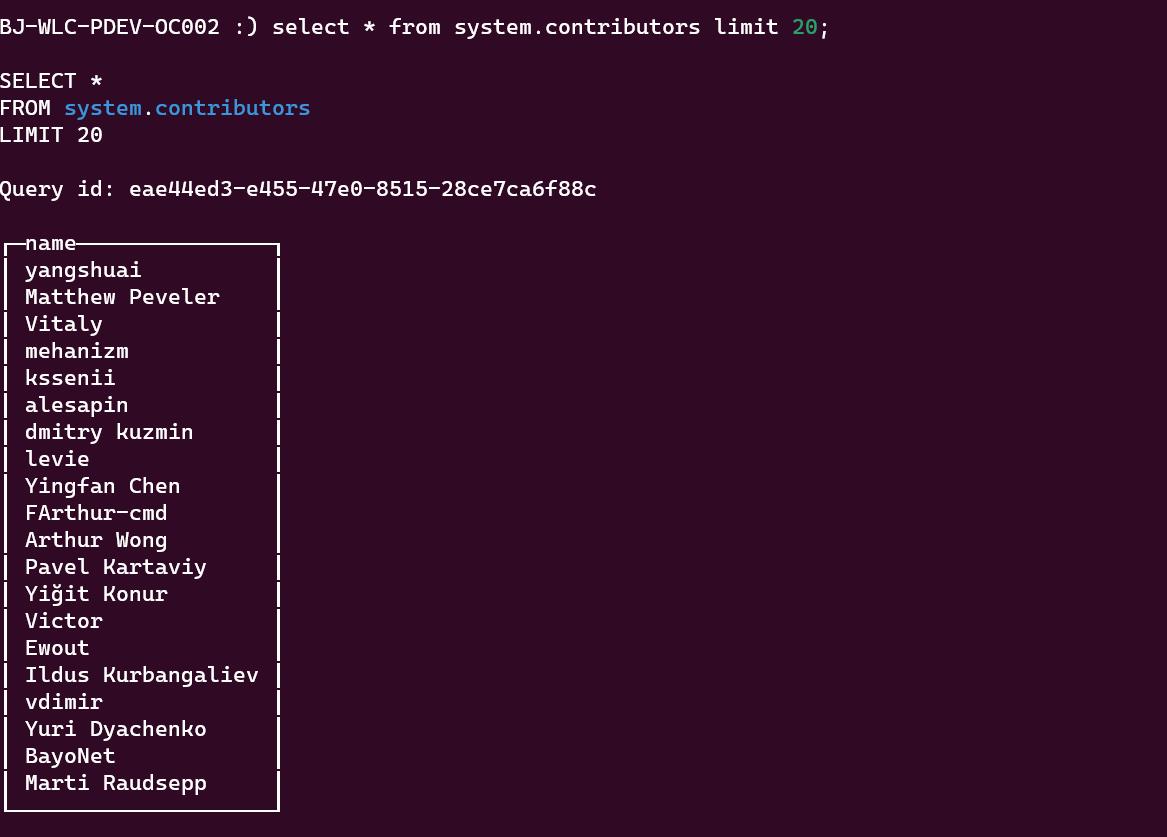
这种用 SQL 方式查看 contributor 的方式还挺 cool 的,毕竟 contributor 是一群通过提交 pr 来完善、迭代产品的人,其中很大一部分的 contributor 是工程师,SQL 更是信手拈来。
现在问题来了,作为一个不会写 SQL 的运营,如何满足我司研发提出的让他感动一下的 contributor 系统表?冷静下,ClickHouse 的这个 SQL 看 contributor 的方式固然很酷,但是终归到底是要查看贡献者同开源项目的关系。说到“搞关系”,还不得是我们的图数据库。巧的是,NebulaGraph 就是一款图数据库,虽然在本文的数据集过于简单用,也不是什么大规模数据,用图数据库有点“杀鸡用牛刀”,但不妨一试。看看,不会写 SQL 的运营怎么用可视化的方式来查看 contributor 和项目关系。
看得见的 contributor 和 pr 关系
效果先行,在这个章节,我们来看下 NebulaGraph 开源社区的 contributor 和 pr 情况,而这些数据是如何生成、展示的实操部分在后面。
开源社区全览
这里收录了所有 NebulaGraph 相关的公开仓的贡献情况,大概是这样的:
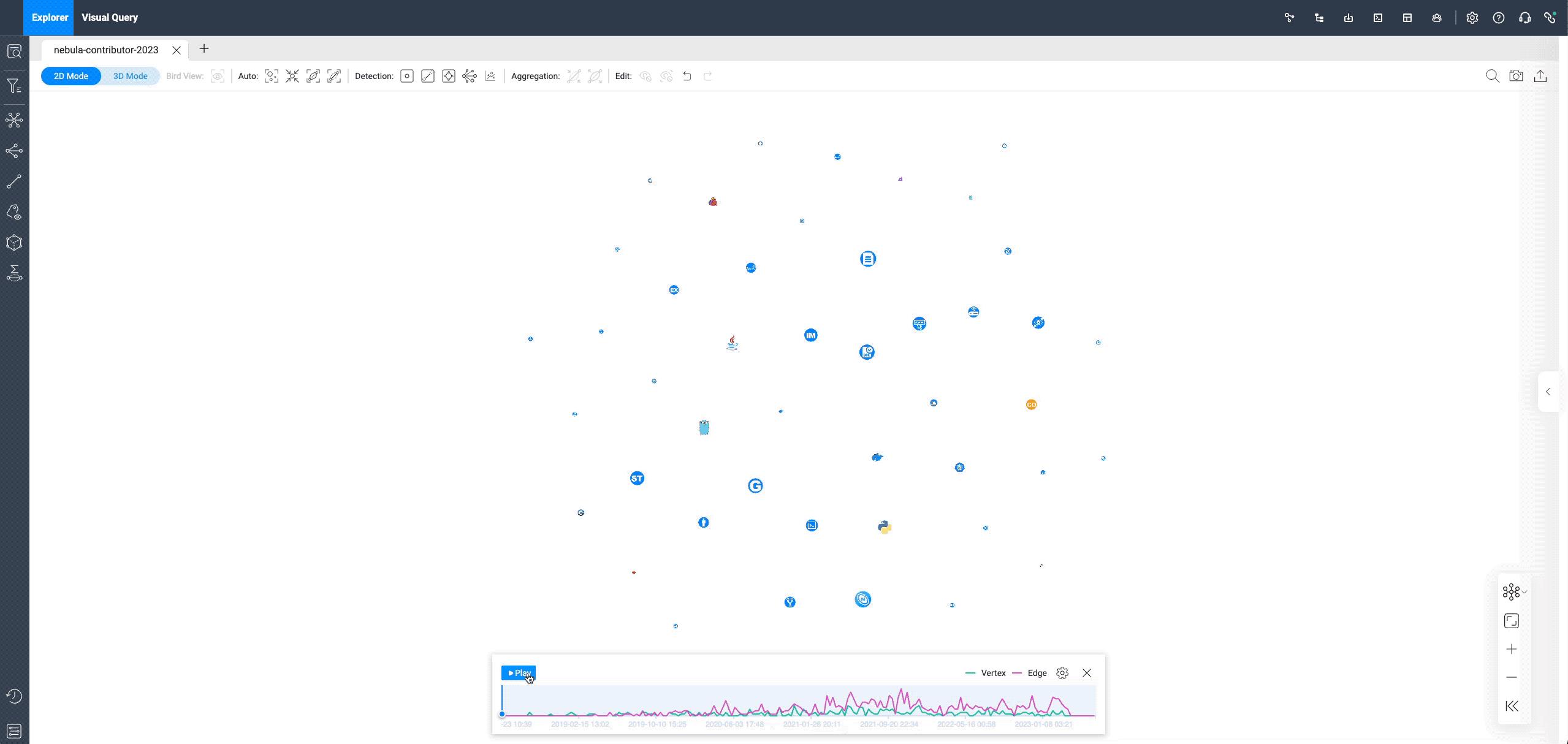
加上时序之后,能看到一个个 contributor(方形图)出现在画布上,同各个 repo(圆形图)连接在一起。这里仅仅展示了所有 contributor 第一次提交 pr,更多的查询在后面的「可视化图探索」部分。
下面的章节为实操内容,一起看看如何生成可视化的 contributor 和开源项目的关系图吧。
手把手带你可视化探索数据
下面着重介绍下本文的可视化工具——NebulaGraph Explorer,具体介绍看文档:https://docs.nebula-graph.com.cn/3.4.1/nebula-explorer/about-explorer/ex-ug-what-is-explorer/。对我而言,Explorer 有两大特点:易上手、所见即所得。我可以白嫖我司线上 Explorer 环境,不用搭建自己的数据库就能直接用,当然你如果想和我一样有个免费的线上环境,估计得用 NebulaGraph Cloud,它配有可视化图探索工具 NebulaGrpah Explorer。
用来进行数据探索的工具有了,现在就是数据哪里来的问题了。
简单建模
在采集数据之前,我们需要简单建模(我从未见过如此简单的图模型)了解需要采集的数据。下图为图模型:
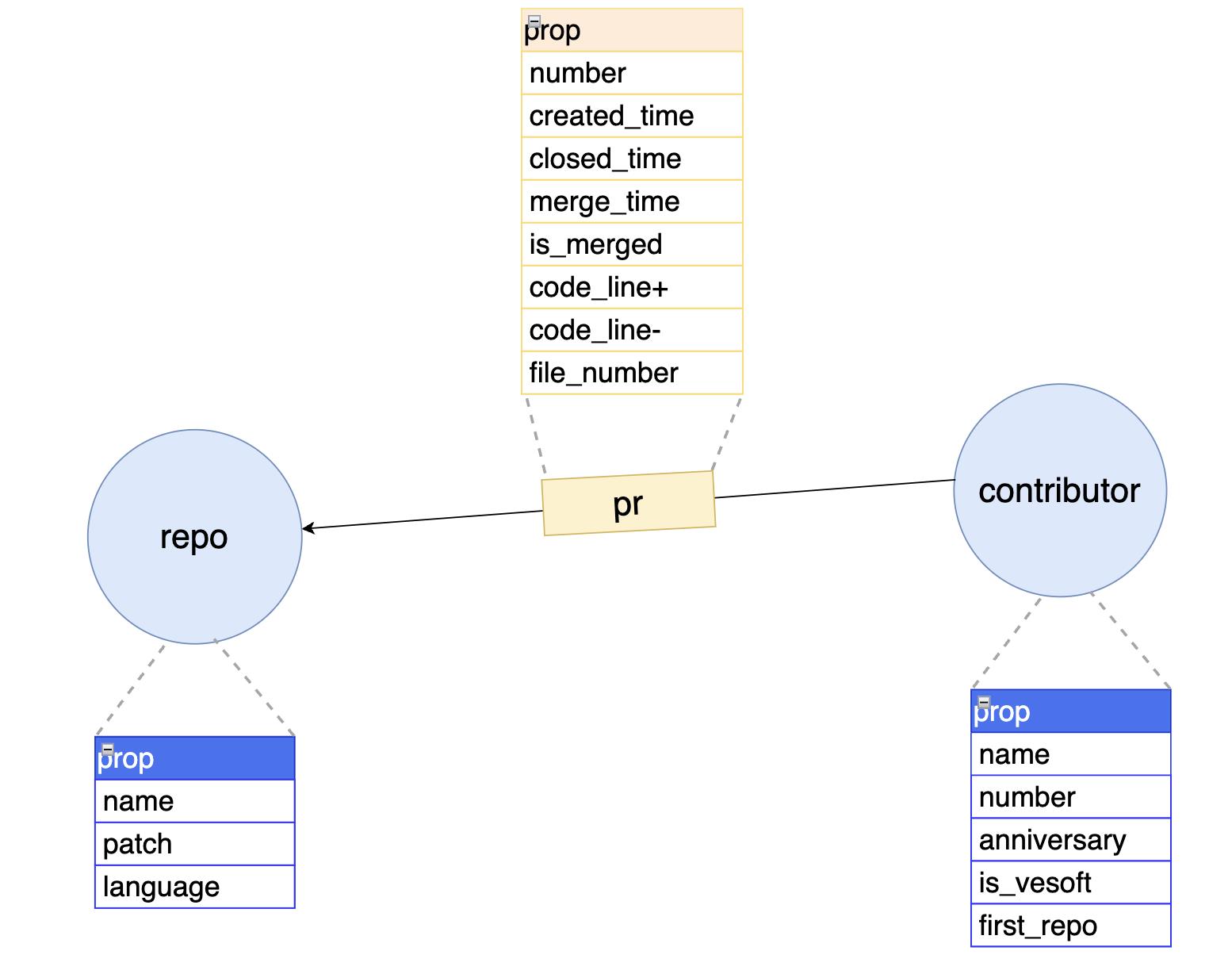
这个图模型中有两种点类型:repo 和 contributor,它们之间由 pr 这个边联系在一起构成了最基础的点边图模型。在分布式图数据库 NebulaGraph 中点的类型用 tag 来表示,边类型有 edgetype,一个点可以有若干种 tag,点的 ID 为 vid,像是你的身份证一样为唯一标识。
- tag
- repo,拥有仓库名
name,主要编程语言language以及仓库路径path等三种属性; - contributor,拥有贡献者名
name,贡献者编号number,诞生日anniversary,是否为 NebulaGraph 开发商雇员is_vesoft,第一个被合并 pr 所属仓first_repo。加入了判断“是否为 NebulaGraph 开发商雇员”的属性是为了避免超大节点,因为一个企业雇员的 pr 产量不同于其他的非雇员贡献者。(这点会在后面的可视化展示中体现)
- repo,拥有仓库名
- edgetype
- pr,拥有 pr 编号
number,提交时间created_time,关闭时间closed_time,合并时间merged_time,是否被合并is_merged,变更情况:ins_code_line、des_code_line、file_number。上面的时间字段可以用来筛选出某个时间区间里的 pr 边;
- pr,拥有 pr 编号
contributor 数据采集
下面这段代码是拜托我司优秀的 IT 工程师乔治编写的,那些需要配置、填上你自己信息的地方,我用注释进行了标注:
# Copyright @Shinji-IkariG
from github import Github
from datetime import datetime
import sh
from sh import curl
import csv
import requests
import time
def main():
# 你的 GitHub ID
GH_USER = \'xxx\'
# 你的个人 token,可以前往 GitHub 设置中的 Developer settings 生成自己的 token
GH_PAT = \'xxx\'
github = Github(GH_PAT)
# 你需要爬取的开源组织的组织名
org = github.get_organization(\'vesoft-inc\')
repos = org.get_repos(type=\'all\', sort=\'full_name\', direction=\'asc\')
# 命名存放爬下来的 pr 数据的文件
with open(\'all-prs.csv\', \'w\', newline=\'\') as csvfile:
# 爬取哪些数据
fieldnames = [\'pr num\',\'repo\',\'author\', \'create date\',\'close date\',\'merged date\',\'version\',\'labels1\',\'state\',\'branch\',\'assignee\',\'reviewed(commented)\',\'reviewd(approved)\',\'request reviewer\',\'code line(+)\',\'code line(-)\',\'files number\']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for repo in repos:
print(repo)
Apulls = repo.get_pulls(state=\'all\', sort=\'created\')
prs = []
for a in Apulls:
prs.append(a)
for i in prs:
github = Github(GH_PAT)
print(\'rate_limite\' , github.rate_limiting[0])
if github.rate_limiting[0] < 500:
if github.rate_limiting_resettime - time.time() > 0:
time.sleep(github.rate_limiting_resettime - time.time()+900)
else:time.sleep(3700)
else:
print(i.number)
prUrl = \'https://api.github.com/repos/\'+ str(repo.full_name) + \'/pulls/\' + str(i.number)
pr = requests.get(prUrl, auth=(GH_USER, GH_PAT))
assigneesList = []
if pr.json().get(\'assignees\'):
for assignee in pr.json().get(\'assignees\'):
assigneesList.append(assignee.get(\'login\'))
else: ""
reviewerCList = []
reviewerAList = []
reviewers = requests.get(prUrl + \'/reviews\', auth=(GH_USER, GH_PAT))
if reviewers.json():
for reviewer in reviewers.json():
if reviewer.get(\'state\') == \'COMMENTED\':
if reviewer.get(\'user\'):
reviewerCList.append(reviewer.get(\'user\').get(\'login\'))
else: reviewerCList.append(\'GHOST USER\')
elif reviewer.get(\'state\') == \'APPROVED\':
if reviewer.get(\'user\'):
reviewerAList.append(reviewer.get(\'user\').get(\'login\'))
else: reviewerAList.append(\'GHOST USER\')
else : print(reviewer.get(\'state\'), \'TYPE REVIEWS\')
else: ""
reqReviewersList = []
reqReviewers = requests.get(prUrl + \'/requested_reviewers\', auth=(GH_USER, GH_PAT))
if reqReviewers.json().get(\'users\'):
for reqReviewer in reqReviewers.json().get(\'users\'):
reqReviewersList.append(reqReviewer.get(\'login\'))
print(reqReviewersList)
else: ""
labelList = []
if pr.json().get(\'labels\'):
for label in pr.json().get(\'labels\'):
labelList.append(label.get(\'name\'))
else: ""
milestone = pr.json().get(\'milestone\').get(\'title\') if pr.json().get(\'milestone\') else ""
writer.writerow(\'pr num\': i.number,\'repo\': repo.full_name,\'author\': pr.json().get(\'user\').get(\'login\'), \'create date\': pr.json().get(\'created_at\'),\'close date\': pr.json().get(\'closed_at\'),\'merged date\': pr.json().get(\'merged_at\'),\'version\': milestone,\'labels1\': ",".join(labelList),\'state\': pr.json().get(\'state\'),\'branch\': pr.json().get(\'base\').get(\'ref\'),\'assignee\': ",".join(assigneesList),\'reviewed(commented)\': ",".join(reviewerCList),\'reviewd(approved)\': ",".join(reviewerAList),\'request reviewer\': ",".join(reqReviewersList),\'code line(+)\': pr.json().get(\'additions\'),\'code line(-)\': pr.json().get(\'deletions\'),\'files number\': pr.json().get(\'changed_files\'))
if __name__ == "__main__":
main()
#pip3 install sh pygithub
等你运行完上面代码,便能得到一个名叫 “all-prs.csv”。脚本爬取的是 vesoft-inc(NebulaGraph 开发商)组织下的所有仓,这里并没有区分仓库状态,这就意味着它也会将私有仓的数据爬取下来。因此,我们要对数据进行二次处理。这里略过我简单处理数据的过程,处理完的 pr 数据中可以抽取相关的 contributor 数据。
上面提到过每个点都有 vid,因此将 contributor 的 vid 设定为他/她的 GitHub ID,repo 的 vid 则采用缩写,而边的数据中起点和终点就为上面的 contributor vid 和 repo vid。
现在我们有了,contributor.csv,pr.csv,repo.csv 三个文件,格式类似:
# contributor.csv
wenhaocs,haowen,148,2021-09-24 16:53:33,1,nebula
lopn,lopn,149,2021-09-26 06:02:11,0,nebula-docs-cn
liwenhui-soul,liwenhui-soul,150,2021-09-26 13:38:20,1,nebula
Reid00,Reid00,151,2021-10-08 06:20:24,0,nebula-http-gateway
...
# pr.csv
nevermore3,nebula,4095,2022-03-29 11:23:15,2022-04-13 03:29:44,2022-04-13 03:29:44,1,2310,3979,31
cooper-lzy,docs_cn,1614,2022-03-30 03:21:35,2022-04-07 07:28:31,2022-04-07 07:28:31,1,107,2,4
wuxiaobai24,nebula,4098,2022-03-30 05:51:14,2022-04-11 10:54:04,2022-04-11 10:54:03,1,53,0,3
NicolaCage,website,876,2022-03-30 06:08:02,2022-03-30 06:09:21,2022-03-30 06:09:21,1,4,2,1
...
#repo.csv
clients,nebula-clients,vesoft-inc/nebula-clients,Java
common,nebula-common,vesoft-inc/nebula-common,C++
community,nebula-community,vesoft-inc/nebula-community,Markdown
console,nebula-console,vesoft-inc/nebula-console,Go
...
数据导入
数据导入之前需要创建相关的 Schema 进行数据映射。
创建 Schema
现在我们需要把图结构模型变成 NebulaGraph 能识别的 Schema,有两种方式来创建 Schema:一是用查询语言 nGQL 来编写 Schama,另外一种则是用可视化图探索工具 NebulaGraph Explorer 提供的可视化界面填写信息完成。和我一样对查询语言不熟悉的小伙伴,建议首选后者。
登陆到 NebulaGraph Explorer 之后,先创建一个图空间(类似 MySQL 中的 Table):
效果同下面的 nGQL 语言:
# nebula-contributor-2023 是这个图空间名字,其他默认;
CREATE SPACE \'nebula-contributor-2023\'(partition_num = 10, vid_type = FIXED_STRING(32))
创建完图空间之后,再创建两个点类型和一个边类型,二者创建方式类似。
下面,以创建相对复杂的 contributor 点类型为例:
同效于这条 nGQL 语句:
CREATE tag contributor (name string NULL, number int16 NULL, anniversary datetime NULL, is_vesoft bool NULL, first_merged string NULL) COMMENT = "贡献者"
同样的 repo 和 pr 边可以用下面的 nGQL 或同上图一样用 Explorer。
# 创建 repo tag
CREATE tag repo (repo_name string NULL, language string NULL, path string NULL) COMMENT = "仓库"
# 创建 pr edge
CREATE edge pr (number int NULL, created_time datetime NULL, closed_time datetime NULL DEFAULT NULL, merged_time datetime NULL DEFAULT NULL, is_merged bool NULL, ins_code_line int NULL, des_code_line int NULL, file_changed_num int NULL)
导入数据
因为用了可视化工具 Explorer,所以上传数据也可以用“看得见的方法”。在创建完 Schema 之后,点击这个右上角的菜单栏“Import”,开始数据导入。
数据源选择本地,找到上面准备的 3 个 csv 文件所在路径,把文件上传之后。开始【导入】过程,在这个步骤主要是完成本地数据文件同 Schema 的关联。类似下图:
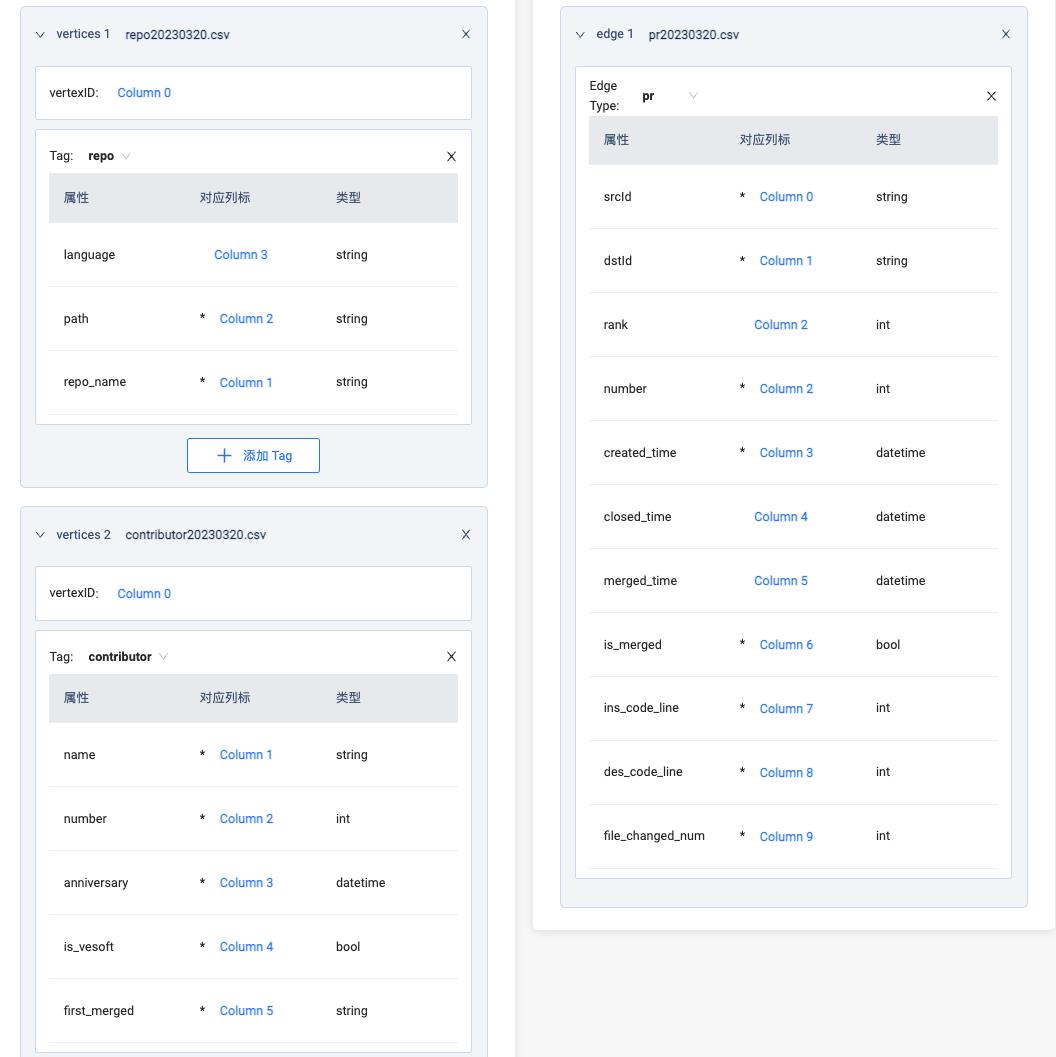
在整个数据集中,我们有两种点:vertices 1 关联 repo 的 csv 数据,vertices 2 关联 contributor 数据,指定各自的 VID 和相关属性的所在列之后,就可以导入数据了。在边数据关联这块,因为我们之前已经在 csv 中加入了 repo 和 contributor 的各自 VID,所以这里同点的关联一样,简单勾选哪列是起点(Column 0)、哪列是终点(对应上图的 Column 1)。
需要进行特殊说明的是,因为一个 contributor 和一个 repo 会存在多次提交 pr 记录,即:多条同 pr 边类型的边。而对同一类型边的处理问题,图数据库 NebulaGraph 引入了 rank 字段来表示两个点之间多条同一类型,但边属性不同的边。如果你不设定 rank,插入多条同一类型边,则会进行数据覆盖操作,以最后成功插入的边数据为准。
为了偷懒,这里 rank 我直接用了 pr 编号 number 列,仔细看,上面的 rank 和 number 都是读取的同一列 Column 2 数据。
可视化图探索
现在我们有数据了,可以进入到可视化图探索模式了。
在“Visual Query”菜单下,拖拽两个 tag:contributor 和 repos,选择 pr 边,【运行】,就能看到所有 contributor 提交的 pr 数据。它的效果等同于下面这句 nGQL 查询语言:
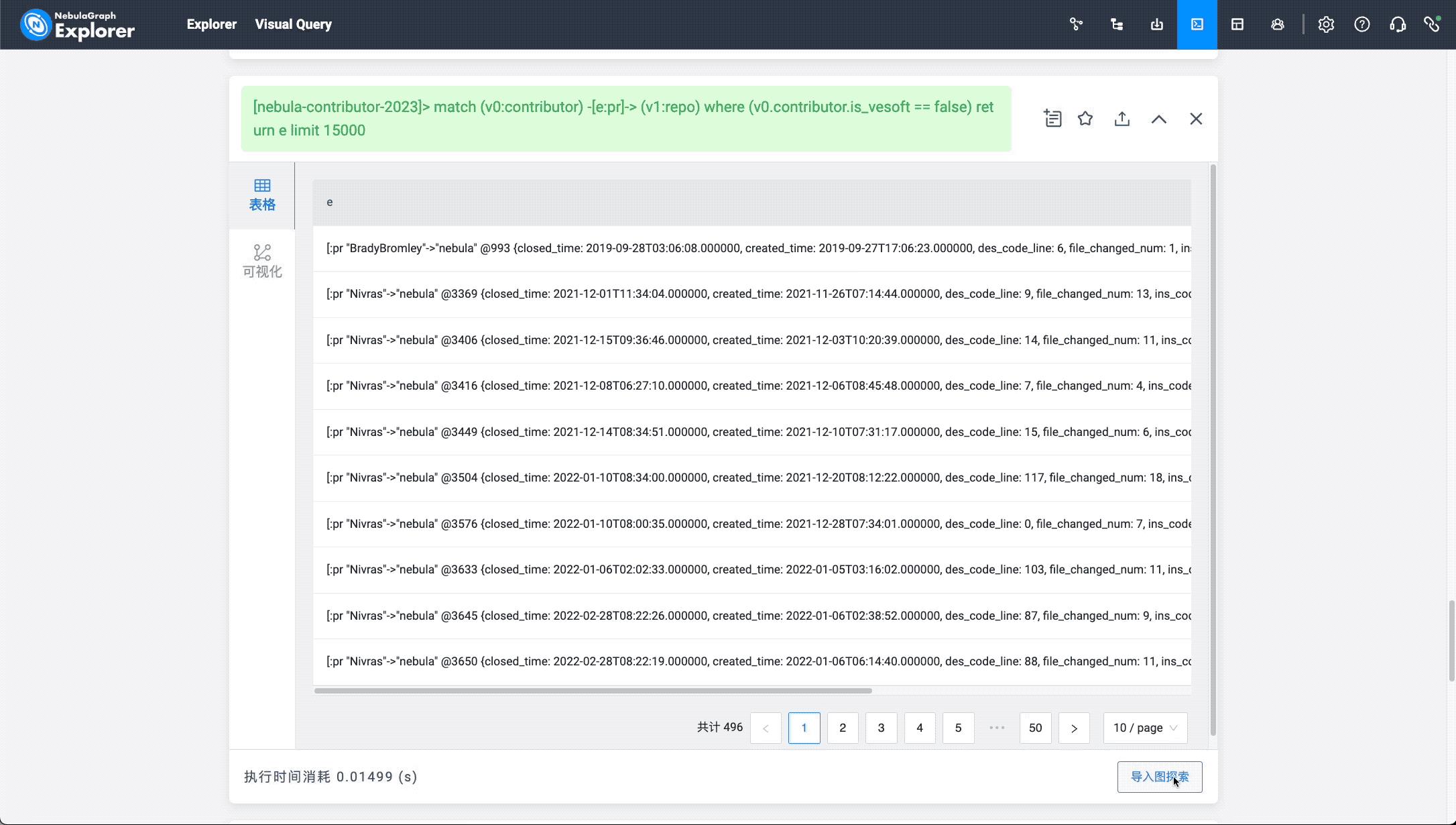
match (v0:contributor) -[e:pr]-> (v1:repo) return e limit 15000
我们随意加入一点像是下面这种小细节:
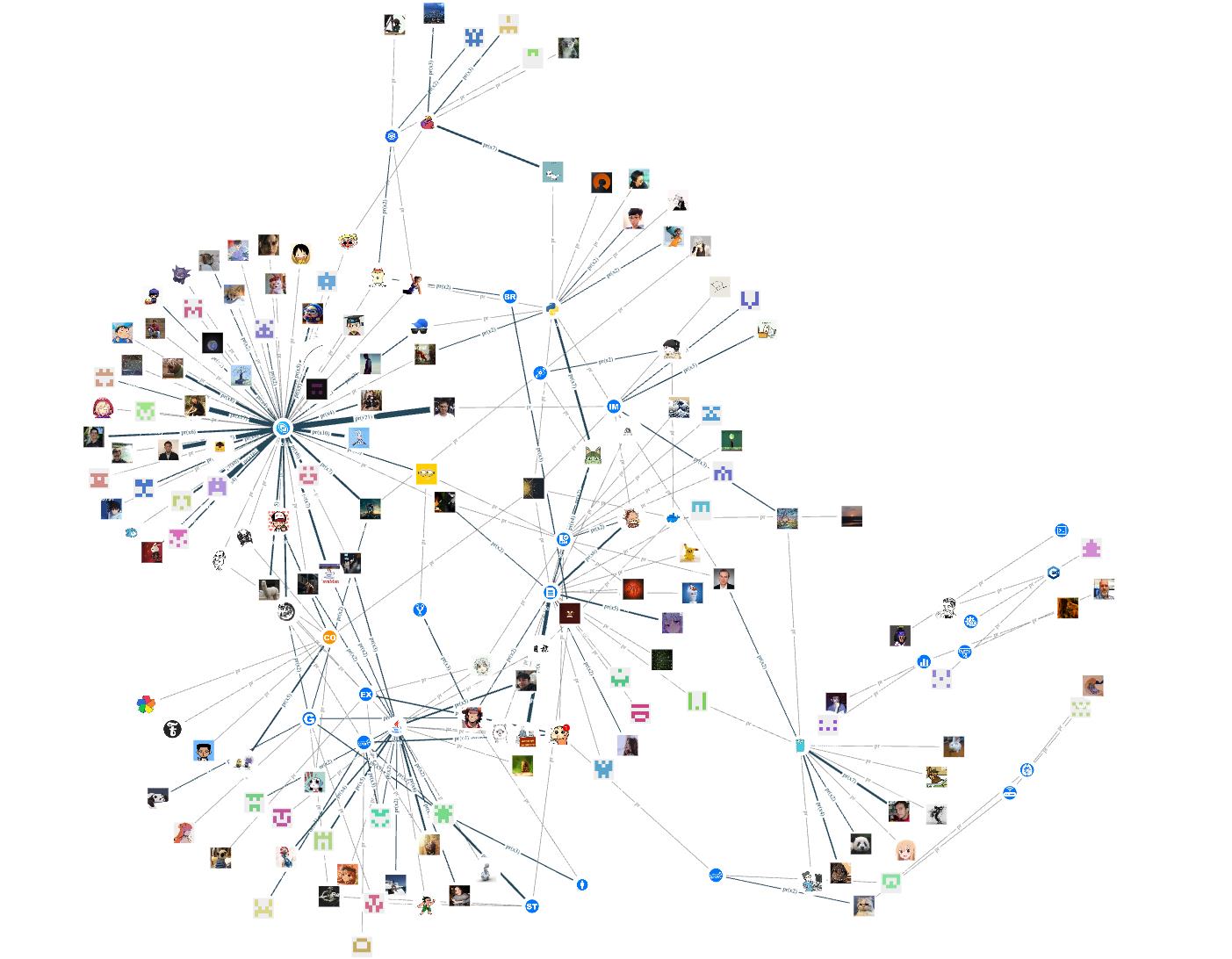
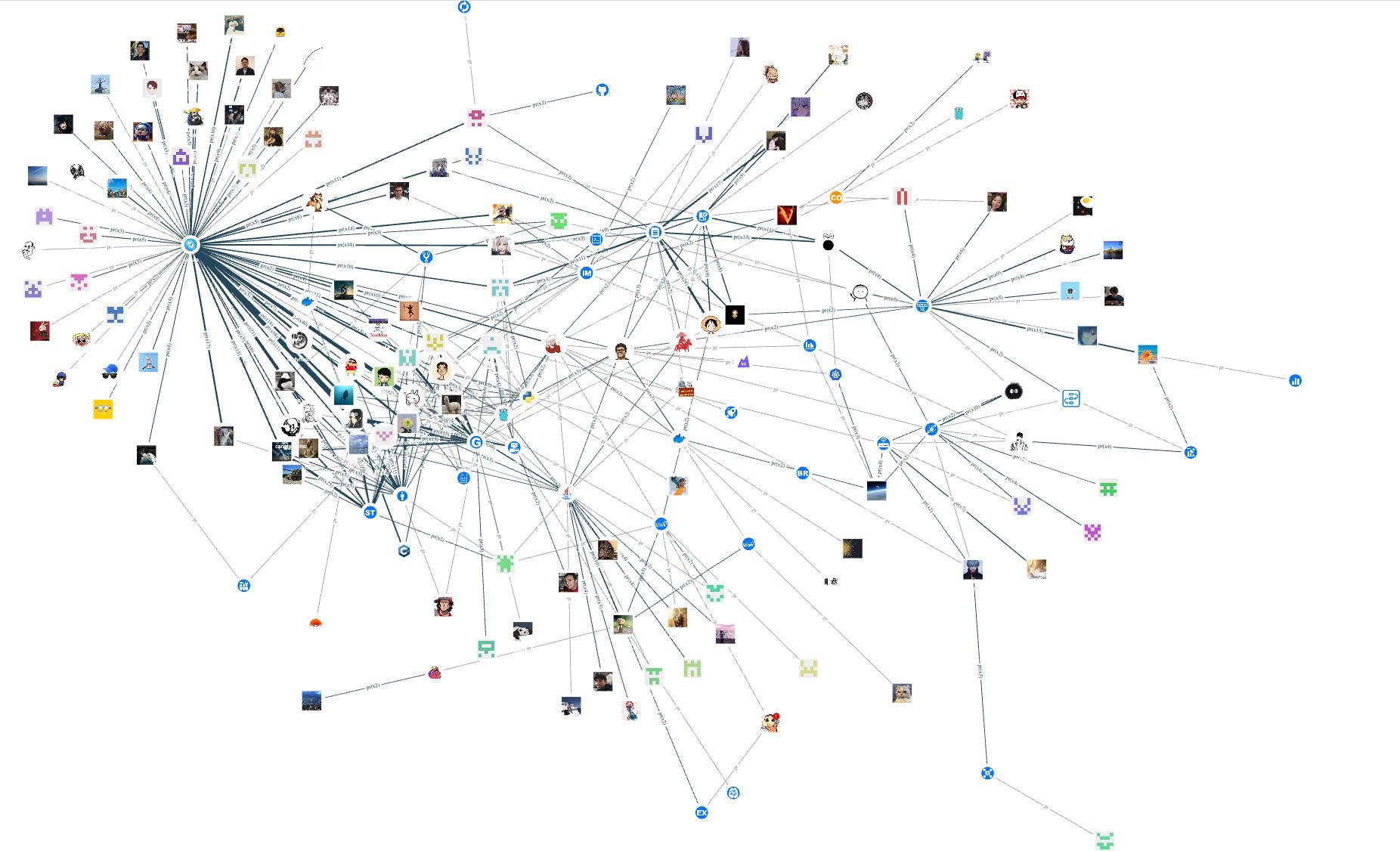
我们把点的头像全部换下,这里为了节省时间找研发小哥龙仔开了个绿色通道批量上传了 contributor 和 repo 点的头像。现在,整图的效果展示是这样的:

因为 nebula 最大的贡献来源于其雇员(员工),所以这里我们除去雇员,查看下非雇员的贡献情况,效果同查询语言:
match (v0:contributor) -[e:pr]-> (v1:repo) where (v0.contributor.is_vesoft == false) return e limit 15000
上图是将 nGQL 查询结果导入到画布,对应的 NebulaGraph Explorer 操作为点击【导入图探索】,再进行同类型边合并,放大 contributor 点的大小,选择辐射模式,就呈现了最终效果:
看看仓库编程语言为 C++、Python、Go、Java 各自的贡献者情况:
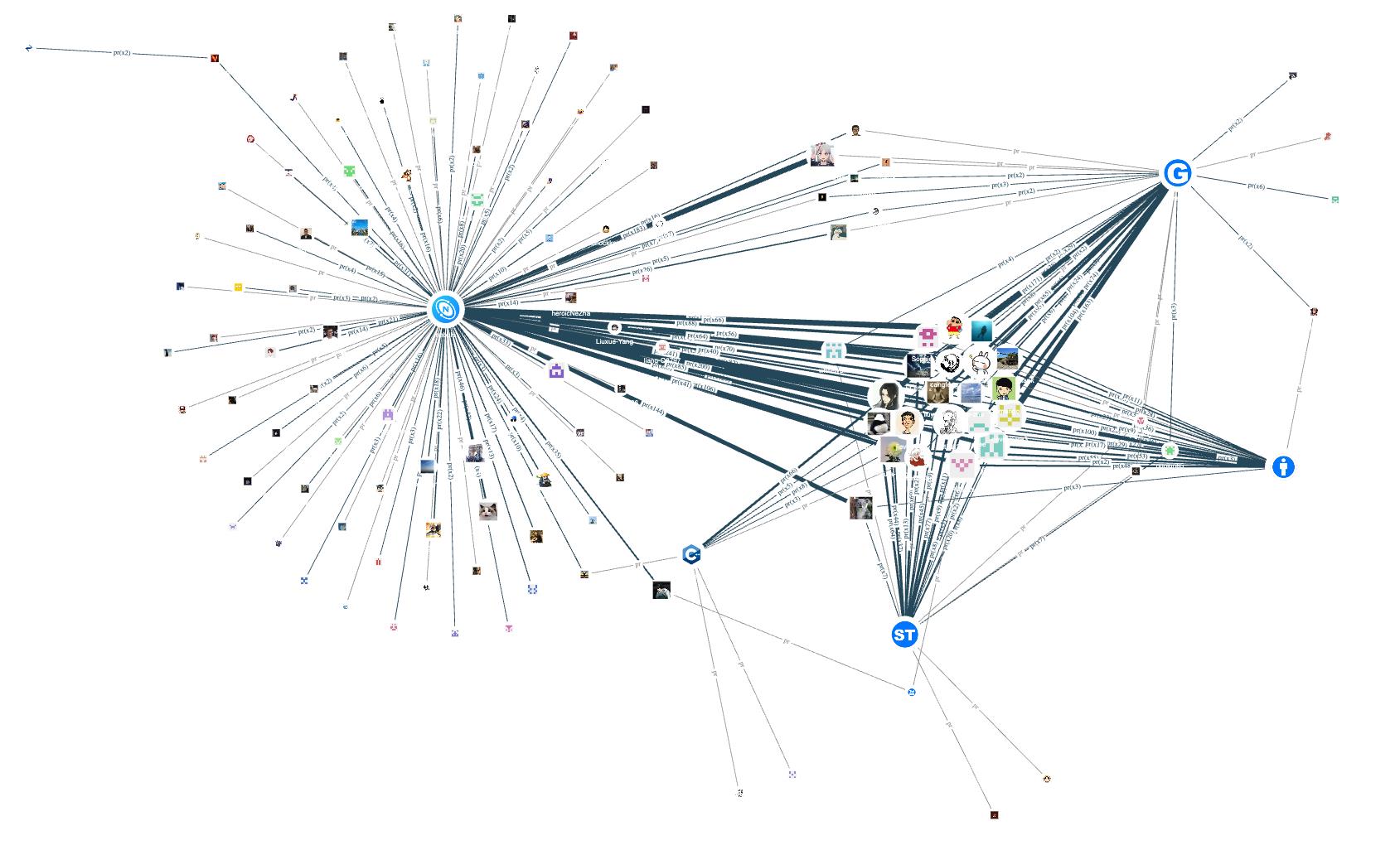

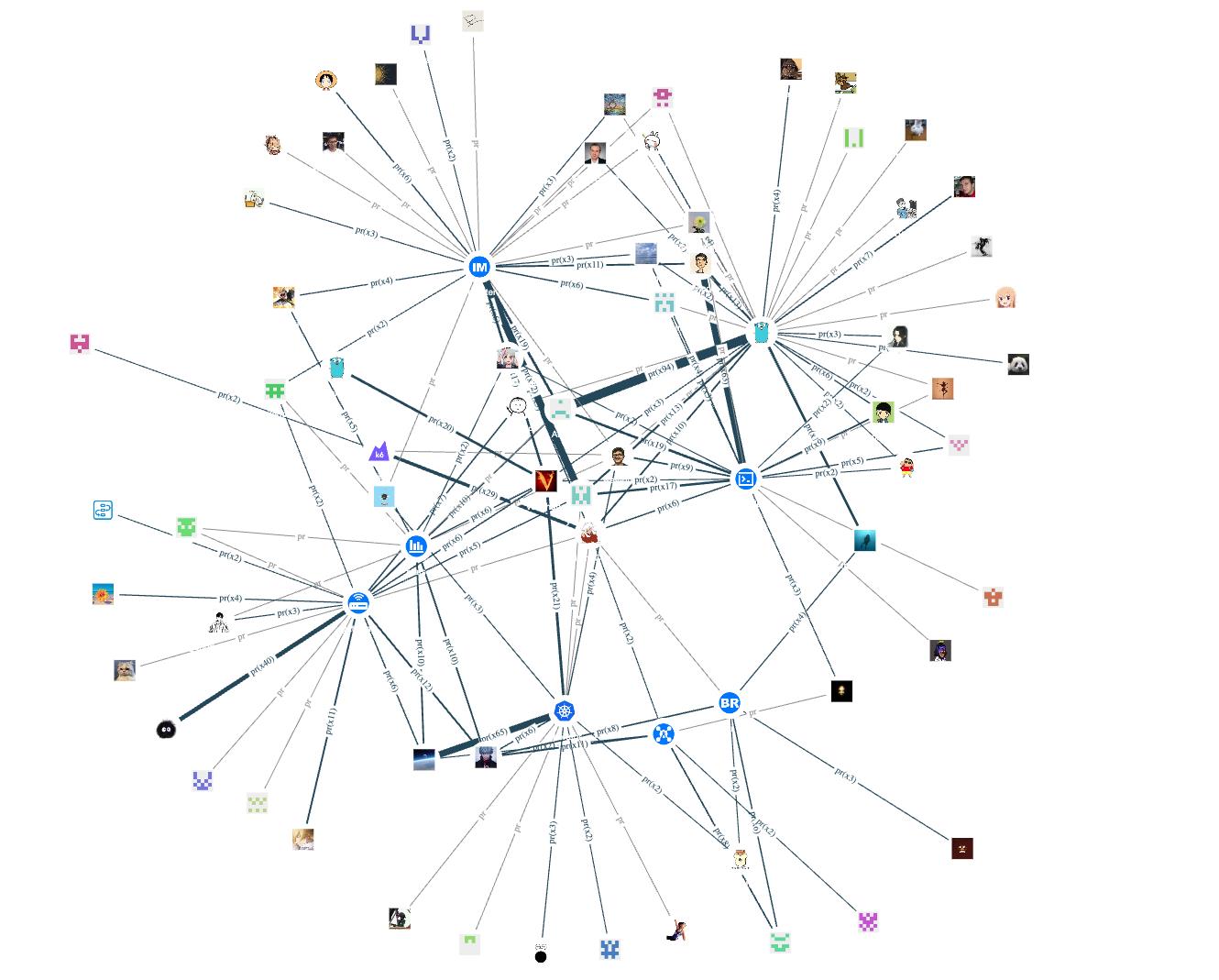
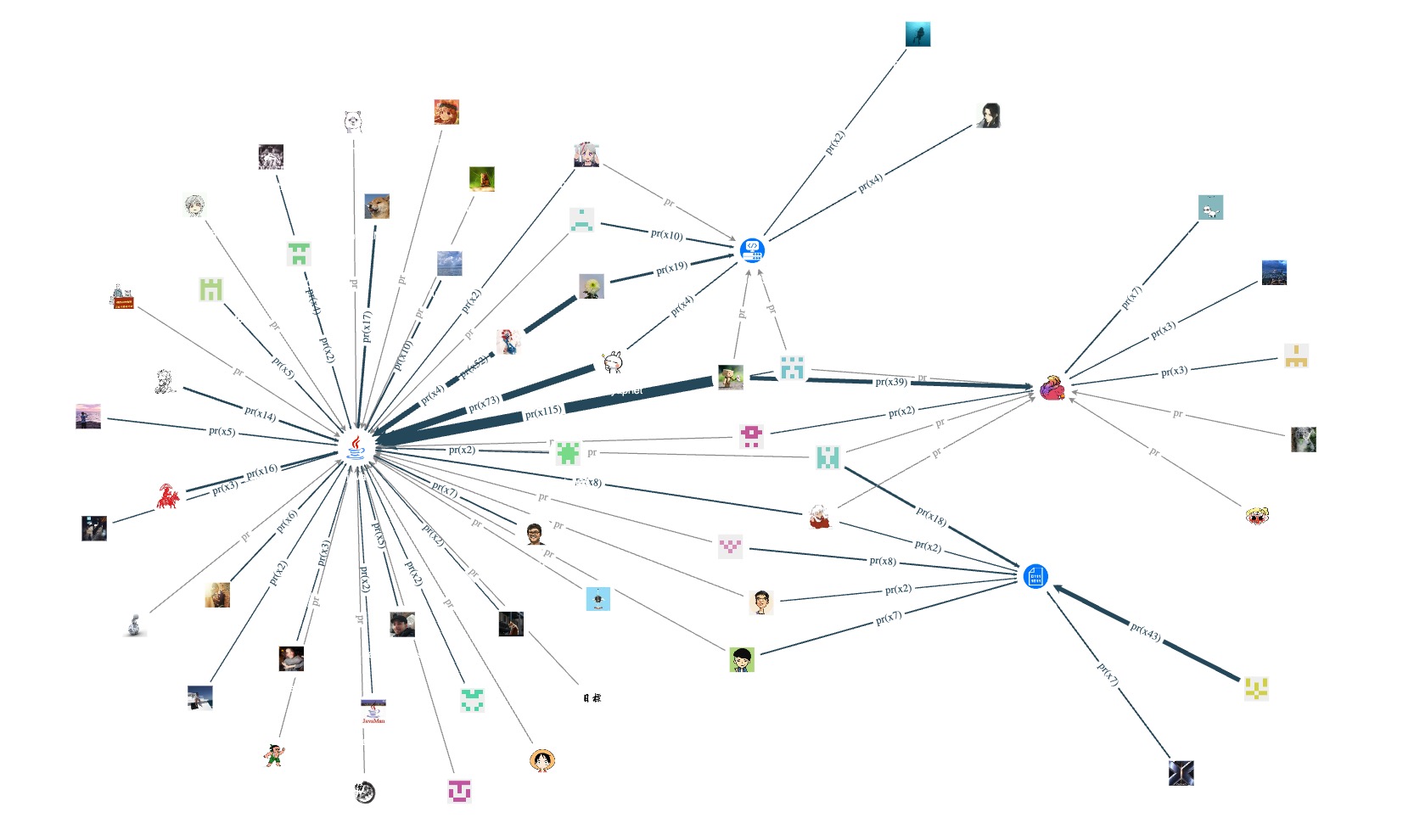
可以看到,内核仓 nebula 采用了 C++,不少相关的周边工具也用了 C++。因此,整个开源项目中 C++ 的贡献者(点)还是比较多的。反之,目前只有 Python 客户端 nebula-python、同步工具 auto_sync 和安装工具 nebula-ansible 使用 Python 语言开发,因此相较于其他编程语言,contributor 数量并不多。
说到内核仓,我们来看看内核仓 nebula 的非雇员贡献者情况:
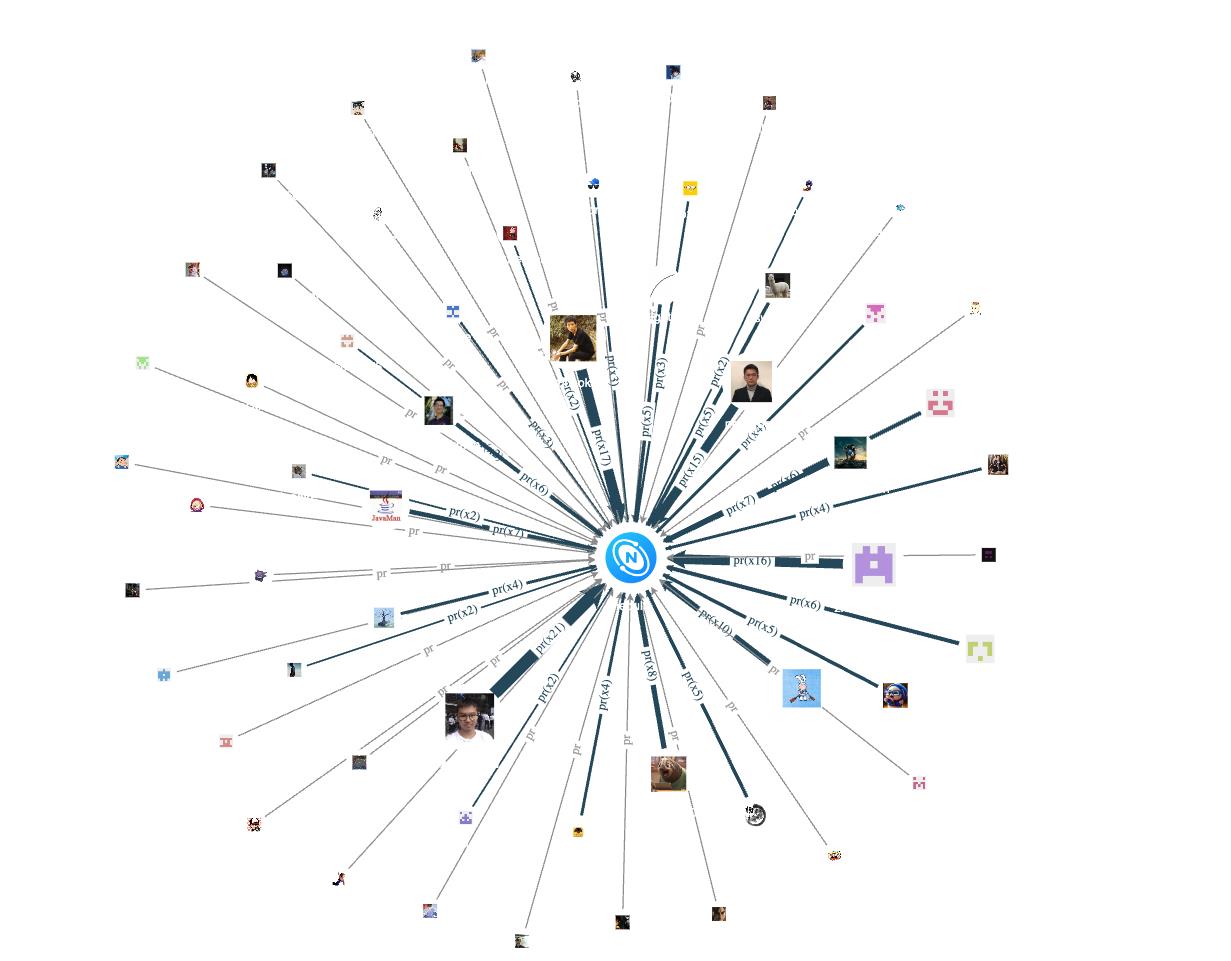
通过合并同类型 pr 边,根据边的粗细我们可以看到核心仓的活跃贡献者。留意上面那个 Java logo 的图像,并非是 nebula 同 Java 联谊了,而是 2020 年的 Committer ChenXU 用了 Java 的 logo 作为头像(狗头)。
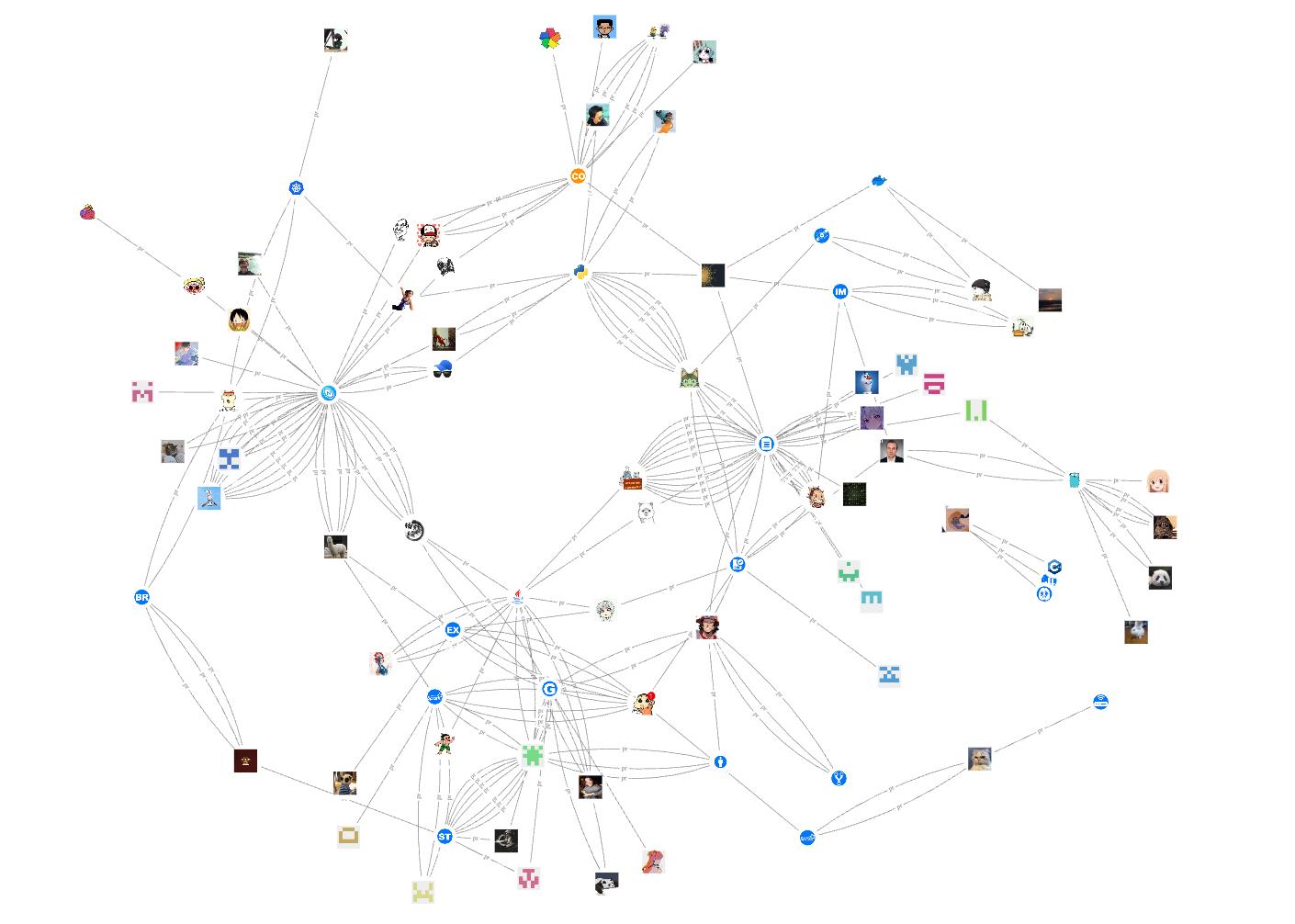
再来看看 2021 年诞生的非雇员 contributor 他们的贡献情况:
最后,来看看有哪些 pr 还没被 merge,这里需要用到 pr 边的 is_merged 属性(记得创建个索引哦~):
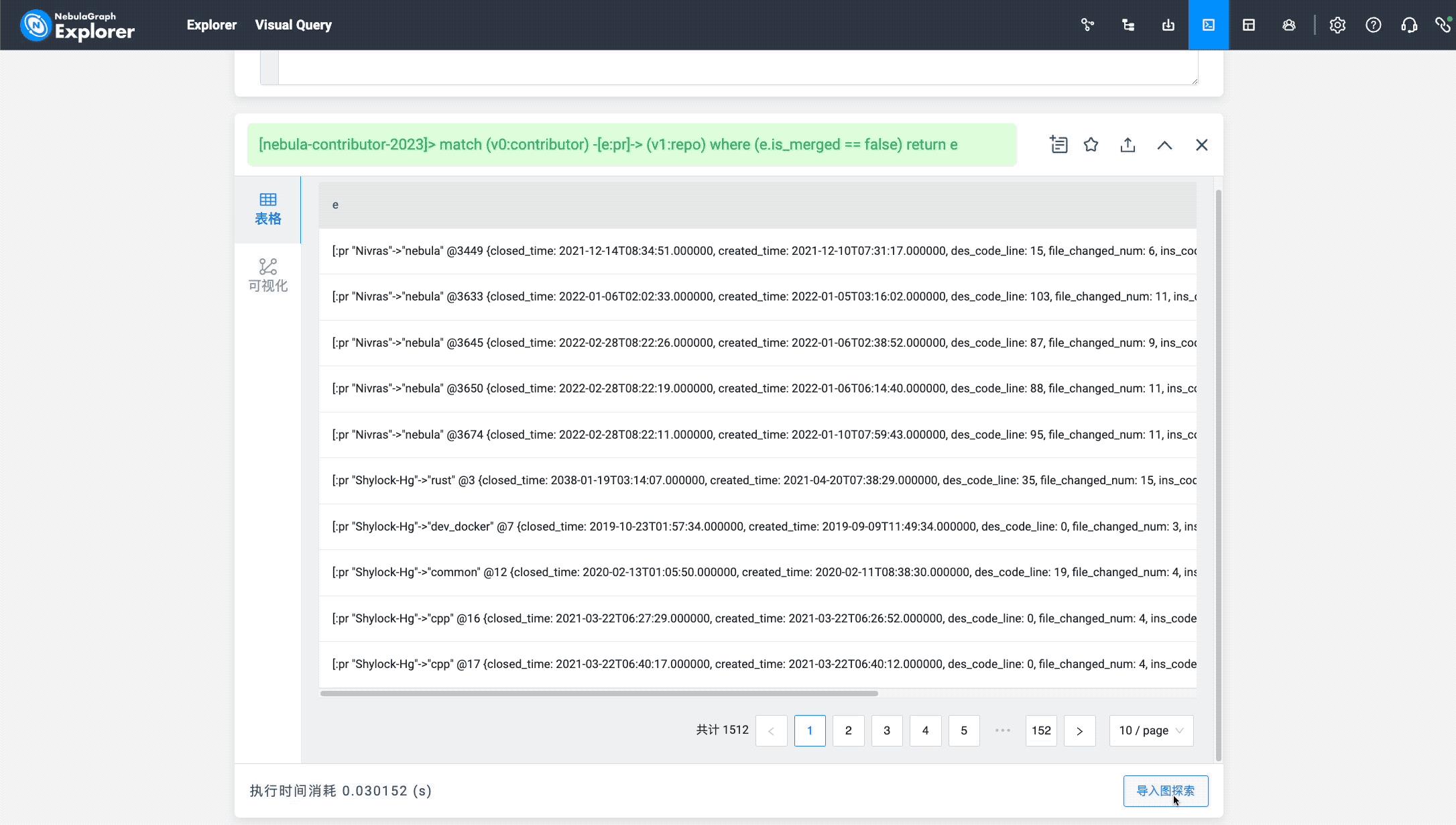
祝上面所有未被 merged 的 pr 都能被合并(虽然这是不可能的)。
nGQL 合集
这里是上面所有查询结果的对应 nGQL 查询语句:
# 查看各个查询语言的开源仓库贡献情况
match (v0:contributor) -[e:pr]-> (v1:repo) where (v1.repo.language == "C++") return e
match (v0:contributor) -[e:pr]-> (v1:repo) where (v1.repo.language == "Python") return e
match (v0:contributor) -[e:pr]-> (v1:repo) where (v1.repo.language == "Go") return e
match (v0:contributor) -[e:pr]-> (v1:repo) where (v1.repo.language == "Java") return e
# 内核仓 nebula 的非雇员贡献者
match (v0:contributor) -[e:pr]-> (v1:repo) where (v1.repo.repo_name == "nebula" and v0.contributor.is_vesoft == false) return e
# 2021 年诞生的非雇员 contributor
match (v0:contributor) -[e:pr]-> (v1:repo) where (v0.contributor.anniversary >= datetime("2021-01-01T00:00:00") and v0.contributor.anniversary < datetime("2022-01-01T00:00:00") ) and v0.contributor.is_vesoft ==false return e
# 目前未被合并的 pr
match (v0:contributor) -[e:pr]-> (v1:repo) where (e.is_merged == false) return e
数据集
本数据集为 NebulaGraph 公开仓数据,统计截止时间为 2023.03.20。因为部分 datetime 属性不能为空,为空字段人为填充了为 2038-01-19 03:14:07(timestamp 类型上限)。如果你要使用该数据集,记得留意 datetime 属性值的处理。
数据集下载地址:nebula-contributor-dataset
最后,以此文感谢所有 nebula 社区的 contributor 们 lol
谢谢你读完本文 (///▽///)
让我们一起走进大数据开源项目--第2节
看了上一节,这节我们来讲解一下:
数据可视化
在大数据的海洋中,如何更直观对数据进行探索和可视化也是目前最值得关注的方向,这类开源项目包括D3,Chart.js, Arbor, DC.js, Sigma.js, Zeppelin等,熟悉前端技术的攻城师可以分分钟利用这些优秀的library将大数据直接以图表形式展示给人们。
================================================================================================
以下为个人评价:
1、当前的数据仓库产品,又发生了较大变化,kylin和durid的成熟,为OLAP提供了更好的解决方案,另外在数据分析中spark也愈发成熟
2、MADlib已经成为apache的顶级项目,另外HAWQ也发布到了2.2.0.0,相信很快会成为顶级项目
3、GemFire是个不错的东东,抽空研究下,其版权属于Pivotal(EMC与VMware/GE合资公司),Redis的创始人Salvatore Sanfilippo 现在也供职于Pivotal。当前主要应用银行、社保、12306等交易系统。
大数据开源框架
- ElasticSearch
1.1 ElasticSearch的优点:
高并发。实测es单机分配10g内存单实例,写入能力1200qps,60g内存、12核CPU起3个实例预计可达到6000qps。
同机房单条数据写入平均3ms(比mysql慢,mg不清楚)
容错能力比mg强。比如1主多从,主片挂了从片会自动顶上
满足大数据下实时读写需求,无需分库(不存在库的概念)。
易扩展。实例间做下配置即可扩展并发性和容积,自动分配的写入机制,无需操心传统db中多主同步的诟病
支持较复杂的条件查询,group by、排序都不是问题
具有一定的关系性,但不用担心大字段的问题
1.2 ElasticSearch的缺点:
不支持事务;
读写有一定延时;
无权限管理.
-
Lucene
Lucene 是一个 JAVA 搜索类库,它本身并不是一个完整的解决方案,需要额外的开发工作。
2.1 Lucene的优点
成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索。2.2 Lucene的缺点
需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善。- Redis
3.1 Redis的优点
读写性能优异
支持数据持久化,支持AOF和RDB两种持久化方式
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
数据结构丰富:除了支持string类型的value外还支持string、hash、set、sortedset、list等数据结构。
3.2 Redis的缺点
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis的主从复制采用全量复制,复制过程中主机会fork出一个子进程对内存做一份快照,并将子进程的内存快照保存为文件发送给从机,这一过程需要确保主机有足够多的空余内存。若快照文件较大,对集群的服务能力会产生较大的影响,而且复制过程是在从机新加入集群或者从机和主机网络断开重连时都会进行,也就是网络波动都会造成主机和从机间的一次全量的数据复制,这对实际的系统运营造成了不小的麻烦。
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
- HBase
4.1 HBase的优点
列的可以动态增加,并且列为空就不存储数据,节省存储空间.
Hbase自动切分数据,使得数据存储自动具有水平scalability.
Hbase可以提供高并发读写操作的支持
4.2 HBase的缺点
不能支持条件查询,只支持按照Row key来查询。
暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉。
- Hadoop
5.1 Hadoop的优点
Hadoop集群的扩展性是其一大特点,Hadoop可以扩展至数千个节点,对数据持续增长,数据量特别巨大的需求很合适。
Hadoop的成本是其另一大优势,由于Hadoop是开源项目,而且不仅从软件上节约成本,硬件上的要求也不高。目前去IOE潮流风行,低成本的Hadoop也是一大推手。
Hadoop生态群活跃,其周边开源项目丰富,HBase, Hive,Impala等等基础开源项目众多。
6.5.2 Hadoop的缺点
全量场景,任务内串行
重吞吐量,响应时间完全没有保证
中间结果不可见,不可分享
单输入单输出,链式浪费严重
链式MR不能并行
粗粒度容错,可能会造成陷阱
图计算不友好
迭代计算不友好
不能支持秒级计算,只适合做离线数据分析任务
这些只是本人的一些见解,如果有什么不对的随时可以指出。
以后会更新一些其他的关于大数据的文章。
很多人都知道我有大数据培训资料,都天真的以为我有全套的大数据开发、hadoop、spark等视
频学习资料。我想说你们是对的,我的确有大数据开发、hadoop、spark的全套视频资料。
如果你对大数据开发感兴趣可以加口群领取免费学习资料: 763835121
以上是关于可视化探索开源项目的 contributor 关系的主要内容,如果未能解决你的问题,请参考以下文章