Python 3 Anaconda 下爬虫学习与爬虫实践
Posted wangziyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 3 Anaconda 下爬虫学习与爬虫实践 相关的知识,希望对你有一定的参考价值。
下面研究如何让<html>内容更加“友好”的显示
之前略微接触的prettify能为显示增加换行符,提高可阅读性,用法如下:
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.prettify())
同样,它也可以为其中的个别标签做专门的处理,比如对a标签进行处理
代码如下:
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.a.prettify())
其输出结果如下:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">
新闻
</a>
可以发现a标签被清晰的打印了出来
关于bs4库的总结

下面进行信息标记的学习
信息标记的三种形式:
XML,YAML,JSON(JavaScript Object Notation)
XML是使用尖括号(最早通用标记语言,较为繁琐)
JSON(常用于接口处理,但其无法注释)
是有类型的键值对 key:value
比如 "name":"北京邮电大学"
"name"是键(key) “北京邮电大学”是值(value)
当值有多个的时候使用[,]组织,例如
"name":["北京邮电大学","清华大学"]
键值对之间可以嵌套使用,比如:
"name" : {
"newName":"北京理工大学",
"oldName":"延安自然科学院"
}
YAML(用于各类系统的配置文件,有注释易读)
无类型键值对(用缩进表达所属关系)
下面学习信息提取的一般方法
实例:
提取HTML中所有URL链接
思路:
1.搜索到所有<a>标签
2.解析<a>标签格式,提取href后的链接内容
下面是代码部分:
from bs4 import BeautifulSoup
import requests
r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for link in soup.find_all(\'a\'):
print(link.get(\'href\'))
效果为:
http://news.baidu.com
https://www.hao123.com
http://map.baidu.com
http://v.baidu.com
http://tieba.baidu.com
等等
成功爬取到所有链接。
这其中非常重要的查找函数为:
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串
attrs:对标签属性值的检索字符串,可标注属性检索
recursice:是否对子孙全部检索,默认True。
string: <>...</>中字符串区域的检索字符串
比如
print(soup.find_all(string=re.compile(\'Li\')))
这里如果是soup.find_all(\'a\')就可以找到所有a标签
soup.find_all([\'a\',\'b\'])就可以找到所有的a标签和b标签
下面想找到b开头的所有式子,这时需要使用正则表达式,也就是re库,后面会详细学习,先用一下,代码如下:
from bs4 import BeautifulSoup
import requests
import re
r=requests.get("https://www.baidu.com/")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for tag in soup.find_all(re.compile(\'b\')):
print(tag.name)
下面是查找
soup.find_all(\'p\',\'course\')查找p标签下类名为course的
suop.find_all(id=\'link1\')查找id为link1的
由于find_all非常常见,所以
<tag>(...)等价于<tag>.find_all(...)
soup(...)等价于soup.find_all(...)
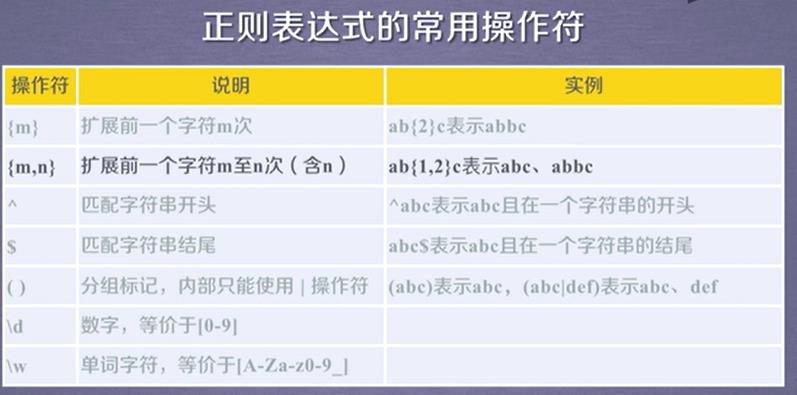
正则表达式:
regular expression RE
比如 \'PY\'开头,后续存在不多于10个字符,后续字符不能是\'P\'或者\'Y\'
正则表达式:PY[^PY]{0,10}
. 表示单个字符
[] 字符集,[abc]表示a,b,c


以上是关于Python 3 Anaconda 下爬虫学习与爬虫实践 的主要内容,如果未能解决你的问题,请参考以下文章