Paper Reading: Gradient Boosted Neural Decision Forest
Posted 乌漆 WhiteMoon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paper Reading: Gradient Boosted Neural Decision Forest相关的知识,希望对你有一定的参考价值。
Paper Reading 是从个人角度进行的一些总结分享,受到个人关注点的侧重和实力所限,可能有理解不到位的地方。具体的细节还需要以原文的内容为准,博客中的图表若未另外说明则均来自原文。
| 论文概况 | 详细 |
|---|---|
| 标题 | 《Gradient Boosted Neural Decision Forest》 |
| 作者 | Manqing Dong, Lina Yao, Xianzhi Wang, Boualem Benatallah, Shuai Zhang, Quan Z. Sheng |
| 发表期刊 | IEEE Transactions on Services Computing |
| 发表年份 | 2021 |
| 期刊等级 | 中科院 SCI 期刊分区(2022年12月最新升级版)2 区 |
| 论文代码 | 未公开 |
作者单位:

研究动机
随机森林和梯度提升决策树是树的模型的两个代表性模型,但神经网络通常具有更多的参数,在捕获复杂信息方面具有优势。尽管这两类模型各有优势,但它们也有各自的局限性。虽然神经网络在处理大规模数据方面表现出优势,但它在较小的数据集上存在过拟合的风险,同时缺乏对其结果的可解释性。基于树的模型高度依赖于特征的质量,在特征较少的小型数据集上表现出良好和快速的预测,但在处理图像、语音和文本等更复杂的特征时能力不足。为了应对上述问题,最近的一些研究将两种模型的优势结合起来,一个方向是将随机森林与神经网络相结合,另一个方向是将提升的思想整合到神经网络中。
文章贡献
本文通过整合基于树的方法和神经网络,提出了一个梯度增强神经决策森林(GrNDF)模型。GrNDF 具有较高的高灵活性和可解释性,灵活性体现在通过将输入映射到嵌入层来灵活地处理不同类型或大小的特征。可解释性体现在可以通过神经决策树传递输入来解释,其中分裂节点显示输入数据到叶节点的概率,叶节点显示预测结果的不同概率分布。并通过概率神经决策树提供输入来解释,其中分裂节点显示传输到叶节点的输入的概率,而叶节点显示用于预测的不同概率分布。GrNDF 进行了调参实验和消融实验,并评估了模型在几个不同特点的数据集上的性能。与一系列 baseline 和现有的研究相比,本文模型具有较好的预测性能。
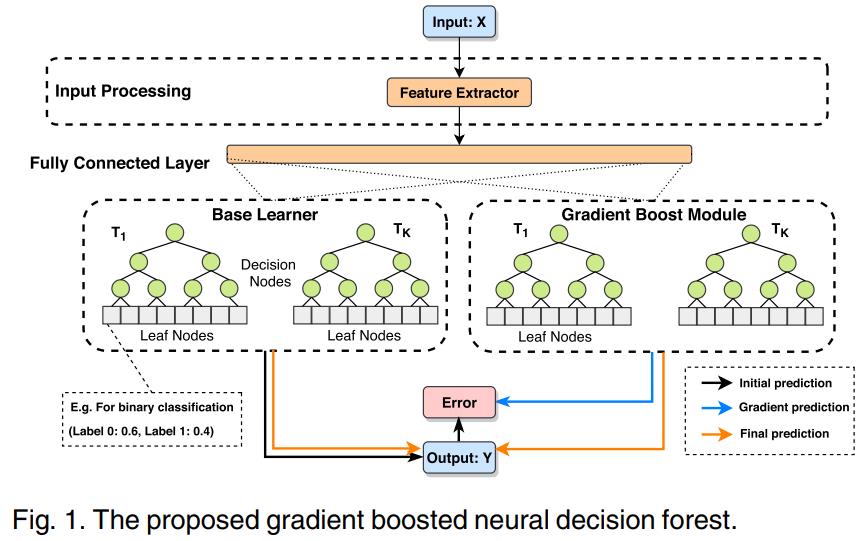
本文方法
输入处理层
本文使用卷积自编码器(CAE)作为输入层,CAE 可以处理一维和二维输入。自编码器(AE)是一种无监督组件,由一个编码器和一个解码器组成,能对输入生成稠密特征表示。编码器将输入将通过几个层次,获得潜在表示 H,如下公式所示。其中 fE(*) 为非线性函数,例如可以选用 sigmoid 函数,WE 和 bE分别为对应的权重和偏置。
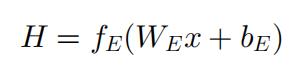
编码器通过几个层次对输入数据进行重表示,输入 x 可以表示为 xc,如下公式所示:
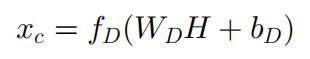
可以选用多种不同的结构来构建编码器和解码器层,本文在编码器和解码器层中使用卷积层。

在优化方面,本文在考虑重建误差和任务预测误差的情况下更新了 CA 的参数,以此提高潜在表示 H 的鲁棒性和预测性能。然后使用潜在表示 H 的变换作为神经决策森林的输入,H 将经过几个全连接层转化为 xFC,即 xFC = ffc(WFC·XH + bFC)。
神经决策森林
在森林中有 K 棵树,每棵树都是一个结构化的分类器,由决策节点 D 和预测节点 L 组成。每个决策节点 D 表示为下面公式:
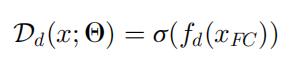
其中各个符号的含义如下:
| 符号 | 含义 |
|---|---|
| σ(x) | sigmoid 函数 |
| fd(xFC) | fd(xFC) = WT·xFC,是对于 xFC 的转换函数 |
| Θ | 自编码器和全连接层使用的参数集合 |
如果树的深度被定义为 n_depth,则树中 2^n_depth 决策节点和 2^n_depth+1 叶节点。样本到达树 Tk 并到达树叶 l 的概率为:
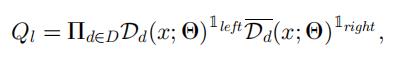
一个样本被预测为 y 类的概率为,Ply 表示根据前面定义的概率分布 Pl(Y/x) ,Θ 和 Λ 分别是输入处理层和神经决策林的参数。
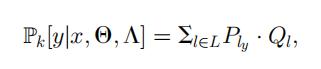
神经决策树森林是决策树 F 的集合 T1, …, TK,通过平均每棵树的输出来提供对样本 x 的预测。
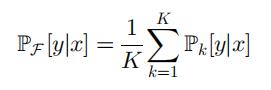
对标签的预测为:
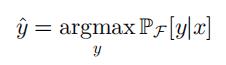
梯度提升模块
梯度提升模块与神经决策森林具有相同的结构。
传统的梯度提升
提升的原理是在函数空间中进行优化,通常给定问题的估计函数 f^(x) 是加性的,公式如下:
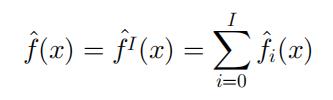
其中各个符号的含义如下:
| 符号 | 含义 |
|---|---|
| f^0 | 基学习器的初始预测 |
| f^iI i=1 | 函数增量 |
| I | 梯度提升模块的数量 |
| f^i | 迭代 i 中的集成预测 |
弱学习器者 h(x, θ) 在增量函数中以贪婪的方式确定的。模型将 f^0 与 h(x, θ0) 集成在一起,并选择一个新的函数 h(x, θi) 与沿预测数据方向的负梯度 gi(x) 最平行。如下公式所示,其中 L 为 loss 函数。
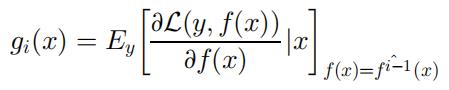
将每个步长设置为 ρ,选择与 -g(x) 最相关的新函数增量。有 N 个样本时,可以用最小二乘最小化来表示优化:
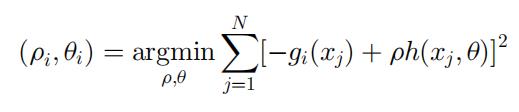
本文的梯度提升模块
本文中的弱学习器 h(x, θ) 是神经决策森林,每个梯度提升步骤将构建新的神经决策森林,弱学习器之间共享输入处理层。构建初始模型 f0=h(x, θ0) 后可得到预测 f0=y。假设有 N 个样本,M 个类,loss 函数可定义为:
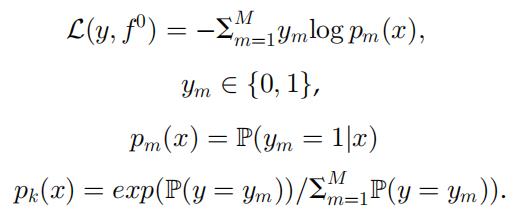
第一个梯度提升模块的预测目标如下:
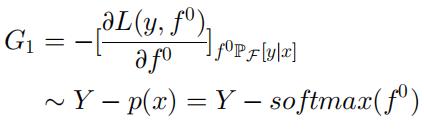
具体而言,假设有 I 个模块,第 I 个模块的预测目标是 Error(I),每个梯度提升模块有以下几个步骤。其中 Error(I) 是梯度提升模块的预测与标签之间的距离,通过将该距离与步长超参数 ρ 添加到预测 fI-1 的先前的猜测中来更新预测 fI,并将 fI-1 中每个概率节点的和缩放为 1。经过 I 步梯度增强,可以得到最终的预测 y^。
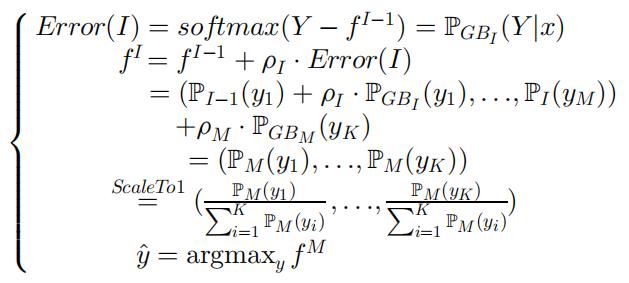
训练过程
GrNDF 的预测使用交叉熵作为分类任务的损失函数,其中 Θ 为输入处理层的参数,Λ 为神经决策森林中的参数。
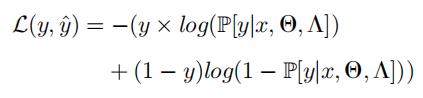
输入处理层为卷积自编码器,自编码器的重构 loss 如下:
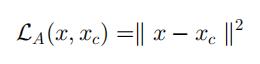
模型的总 loss 为:
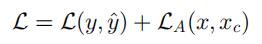
模型的训练过程相当于求解最优参数 Θ 和 Λ:
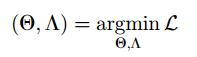
卷积自编码器的中间层的输出将作为几个全连接层的输入,作为每个神经决策林的输入,自编码器和神经决策林的参数同时用 RMSProp 优化方法更新。首先参数将被随机初始化,然后得到初始预测 f^0 和相应的损失 L。更新参数时先保持 Λ 不变,按照如下步骤反向传播更新 Θ。
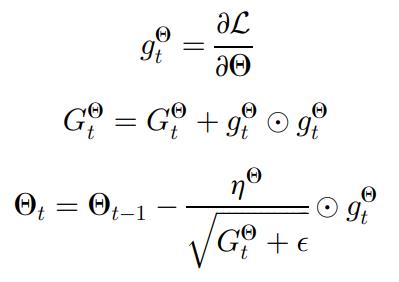
然后采用类似的更新策略来更新神经决策林中的参数,对于梯度提升模块用更新基学习器 f^0 类似的方式更新每个梯度提升模块的参数。具有多个梯度提升模块的模型的训练过程如下图所示,其中黑线表示数据,红线表示反向传播过程。
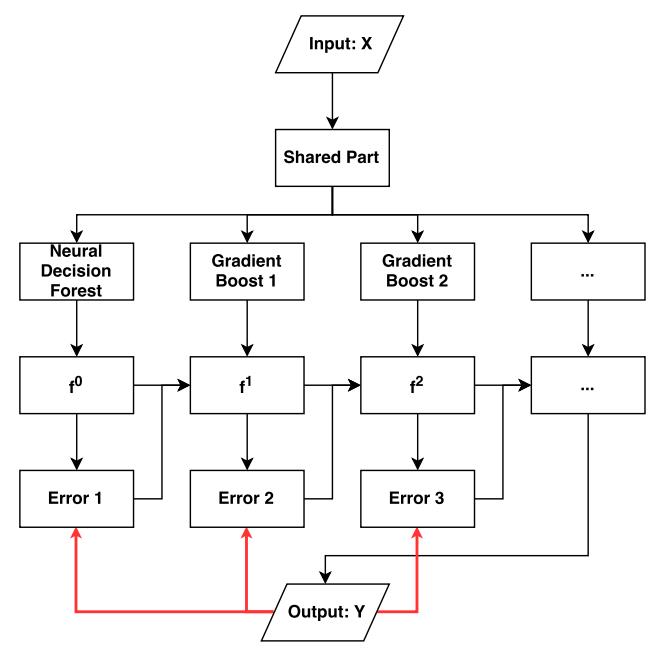
总体而言,本文算法的训练、测试的流程如下伪代码所示。原文中还有对算法时空复杂度的分析,详情可参照原文。

实验结果
数据集和实验设置
本文在 4 个不同特点的数据集进行实验,数据集的详细信息如下。Epileptic Seizure Recognition 数据集随机分为 8000 个训练样本和 3500 个测试样本。MHEALTH 和 Amazon Review 数据集,随机分为 80% 的训练数据和 20% 的测试数据。Fashion MNIST 数据集将每个图像平铺成 784 个维度的向量。
对于输入处理层,在自动编码器中使用两个卷积层,后面接一个全连接层。对于神经决策森林,将树的深度设置为 3,并在基学习器上添加一个梯度提升模块。批量大小约为整个数据集的 10%,层中神经元的数量根据特征向量的维度而变化。
对比算法方面选择三种 baseline 方法和四种更新的研究来评估本文算法的效率,三种相关的 baseline 方法为 GBDT、Random Forest 和 CNN,其他 4 种方案为 neural decision forest、gradient boost convolutional neural networks、autoencoder 和一种同时使用卷积神经网络和卷积自动编码器的模型。实验时为所有模型提供相同的输入,评价指标为 accuracy、precision、recall、F1。
试验评估
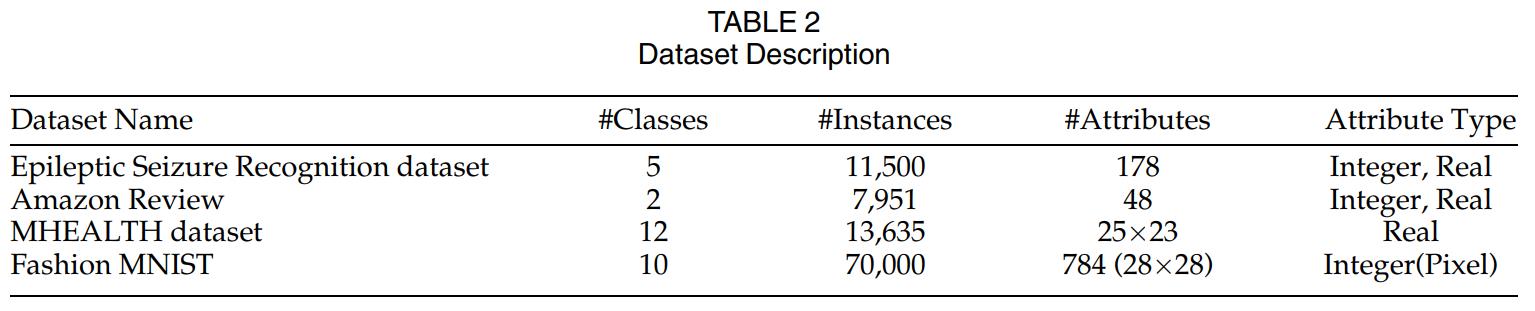
实验结果如下表所示,基于神经网络的方法通常优于决策树的 boosting 或 bagging,可能是因为神经网络具备更强的捕捉特征的复杂非线性组合的能力。本文的 GrNDF 相比 NDF 模型添加梯度增强模块,从实验结果可见确实提高了基础学习器的准确性。本文的模型将神经决策森林与梯度增强思想相结合,比大多数比较方法表现得更好。
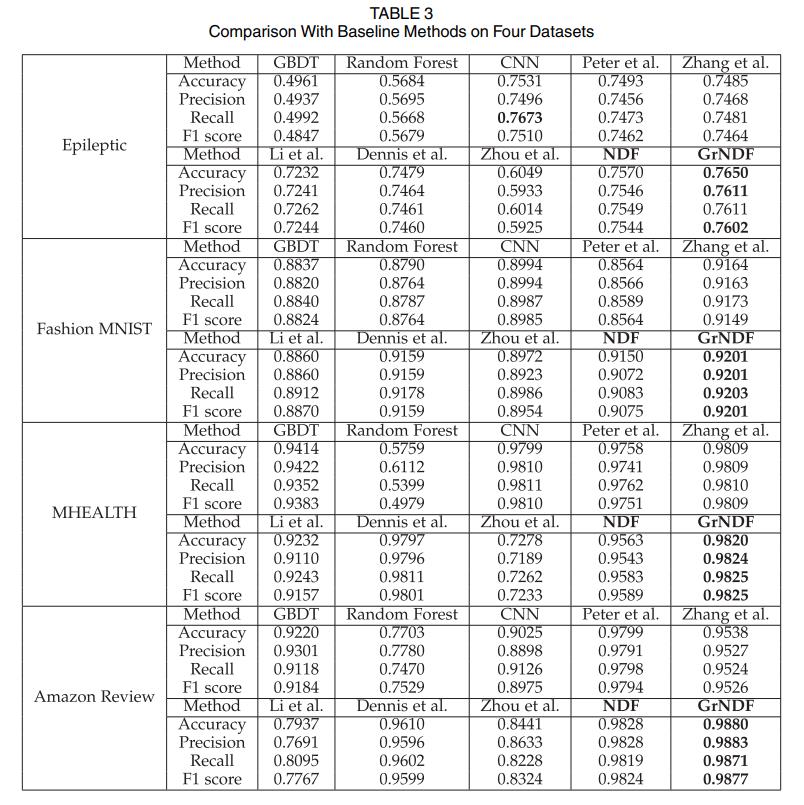
下图为四个数据集的混淆矩阵。
调参实验
本文在输入处理层、神经决策森林和梯度增强模块中设置参数,下表总结了在实验中使用的设置。以 Fashion-MNIST 数据集为例,默认设置中输入处理层包括两个卷积层和一个全连接层,神经决策森林有 20 棵树、深度为 3、梯度升压模块个数为 1,每个神经层的神经元数量控制在一定范围内。
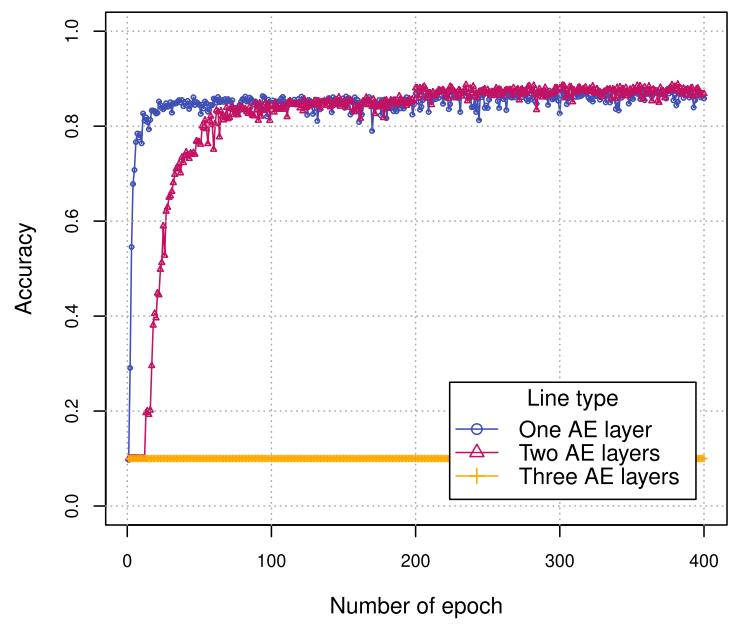
下展示了对自编码器中卷积层数的选择,两个卷积层的模型比只有一个卷积层的模型性能更好,单层模型的计算开销较小且性能可以接受,三层模型很难从输入中学习。
下图对全连接层的数量进行选择,没有完全连接层的模型可以快速收敛,随着层数的增加模型需要更多的 epoch 才能收敛。
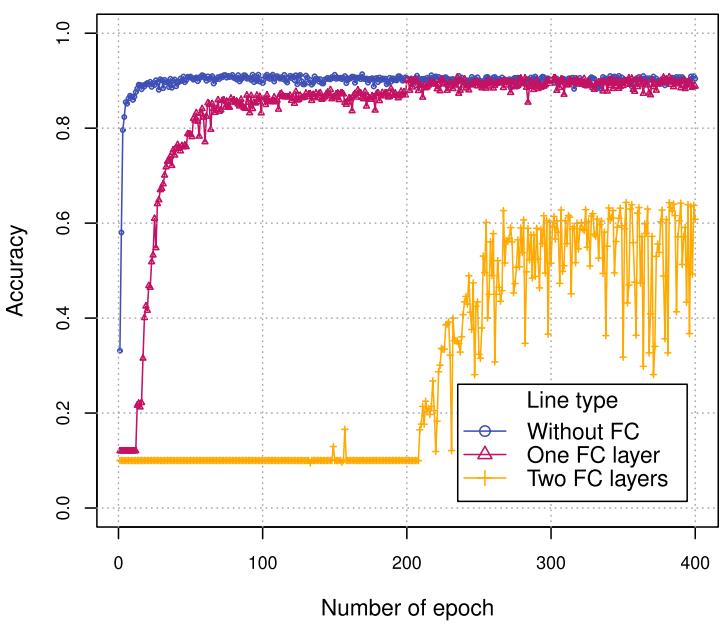
对于神经决策树的设置,下图展示了较深的树比较浅的树更快获得良好的性能。
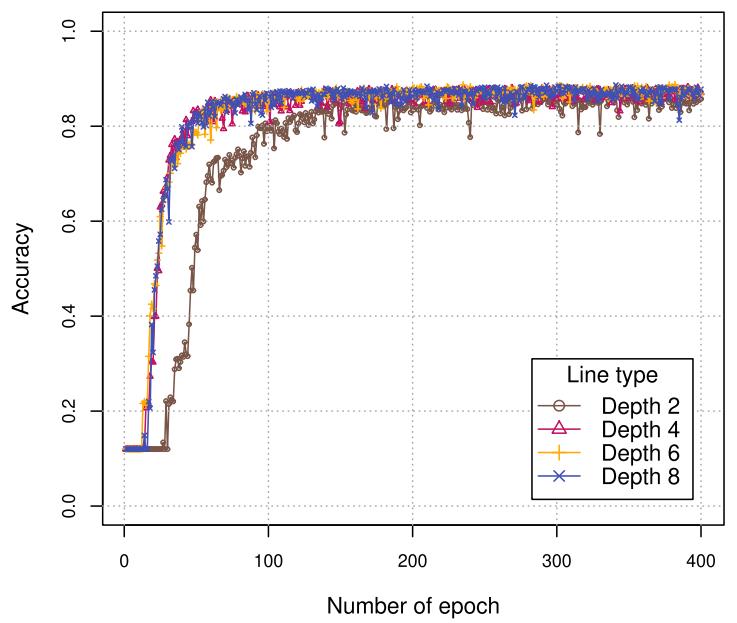
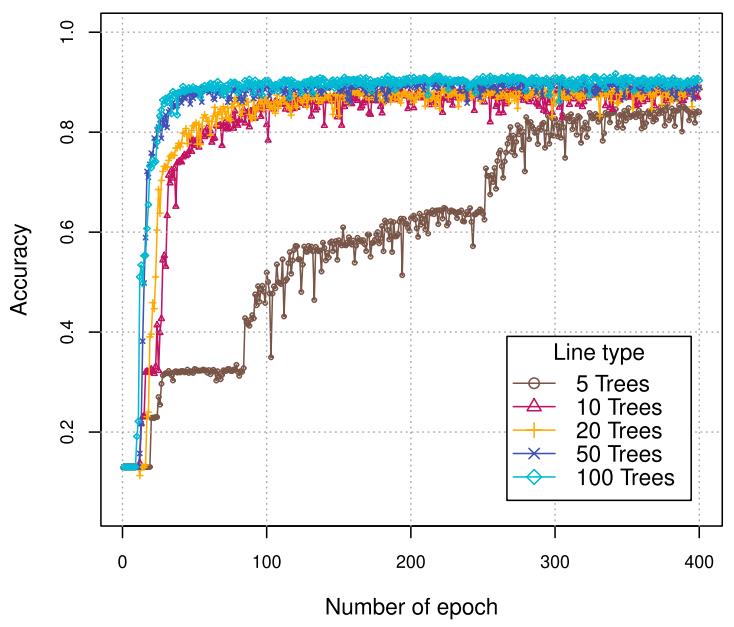
对于树的数量,下图展示了大森林的学习速度快于小森林。
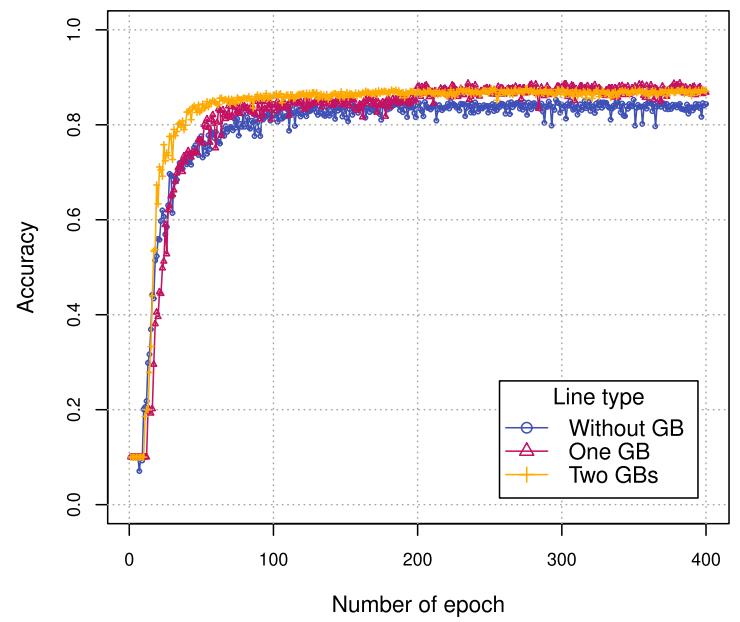
对于梯度提升模块的设置,下图展示了添加梯度提升模块提高了模型的性能。有两个梯度提升模块的模型性能更好,且在训练过程中性能更加稳定。
对于激活函数的设置,下图显示了不同的选项对最终结果的影响有限,其中使用 ReLU 和 LeakyReLU 函数时,模型的性能在训练过程中会出现波动。
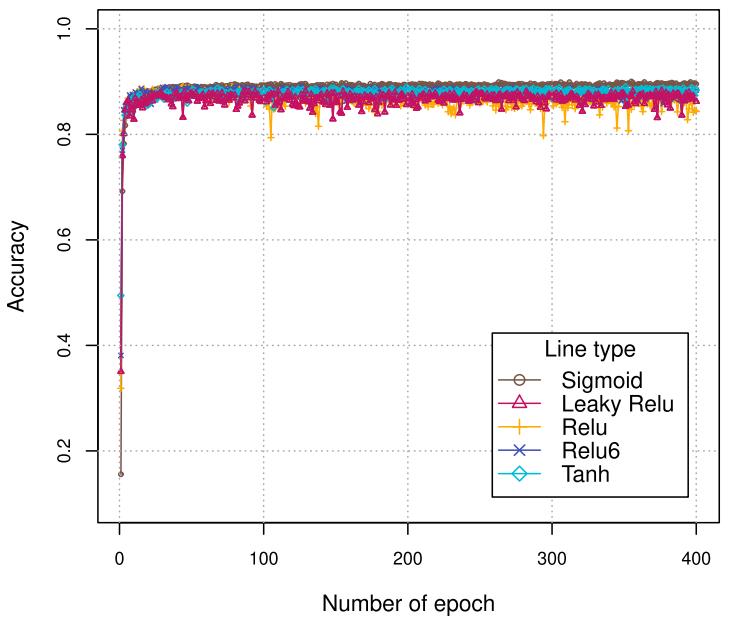
调参实验的结果表明在基础模型中加入梯度提升模块的重要性。
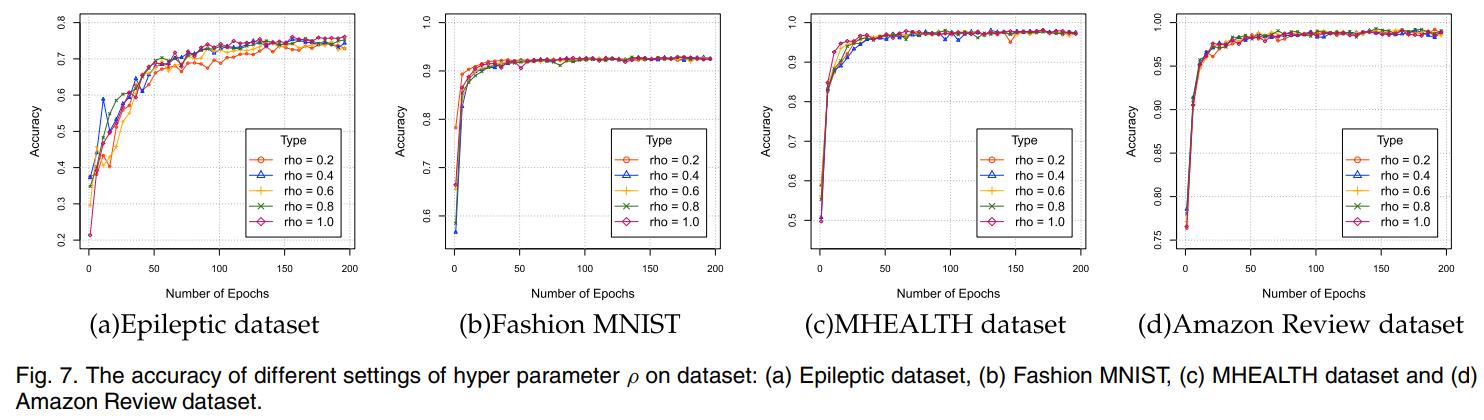
在设置不同的超参数 ρ 时,下图中展示了 ρ 对不同数据集的影响略有差异。通常较大的 ρ 可提供更好的性能,但需要更多的迭代才能收敛。
消融实验
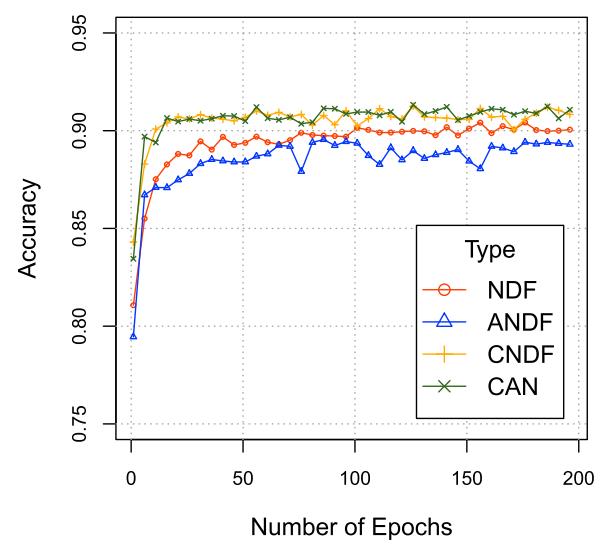
消融实验研究了输入处理层的选择、梯度提升模块的有效性、模型的可解释性。
输入处理层方面考虑了四个模块:全连接层、自编码器、卷积层和卷积自编码器,所有方法的神经层的维度以及基学习器和梯度增强模块的设置都是相同的。结果如下图所示,在 Fashion MNIST 数据集上可见处理输入的方式会影响预测结果。基于 CNN 的方法性能更好,添加自编码器可以略微提高模型的性能。因此对于不同的任务,可以选择不同的输入处理层,本文的模型具有一定的灵活性。
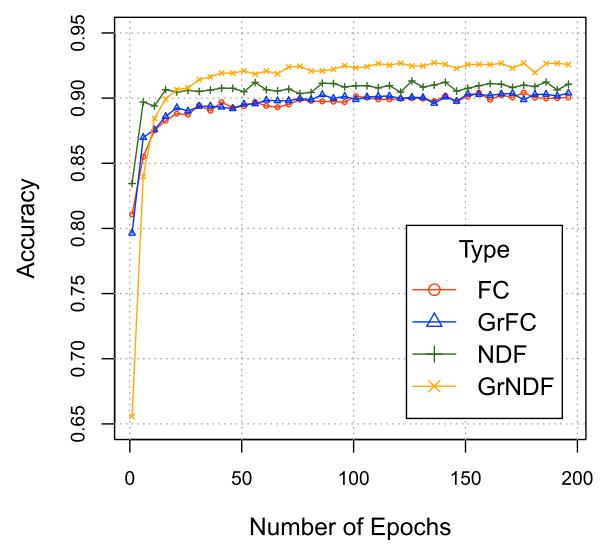
梯度提升模块方面,此处使用不同的基学习器来测试梯度增强是否也适用于其他基学习器。使用全连接层(FC)和神经决策森林(NDF)、GrFC 和 GrNDF。下图的结果表明,加入梯度增强模块可以提高不同基学习器下的模型的性能。
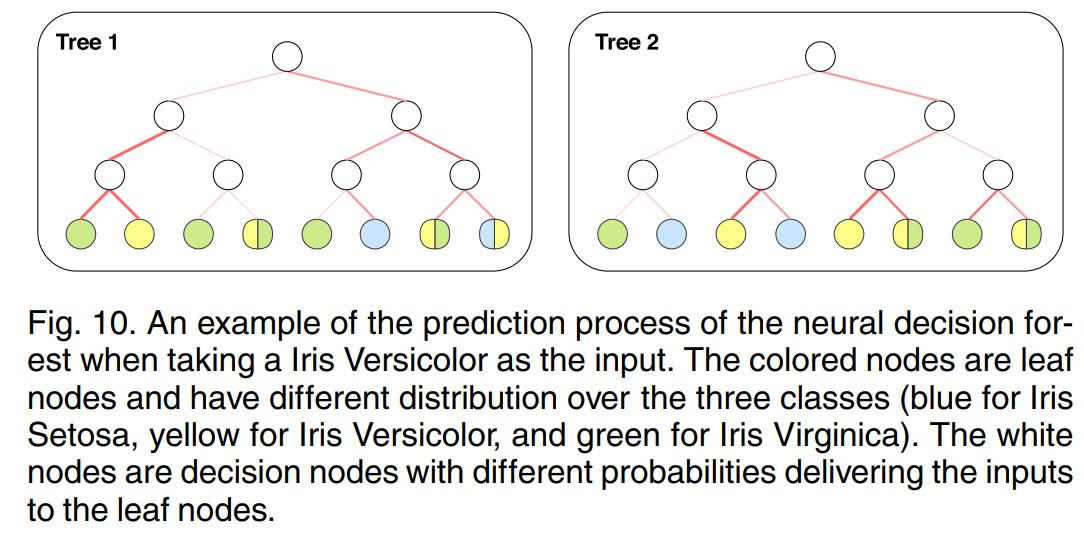
可解释性方面,下图显示了以鸢尾花作为输入的神经决策森林的预测过程,可见神经决策森林使预测过程具有可解释性和灵活性。
优点和创新点
个人认为,本文有如下一些优点和创新点可供参考学习:
- 本文将神经决策森林和提升方法整合在一起设计了一个模型,使模型能够结合神经网络和树模型的优点;
- 在输入方面,本文使用了自编码器为不同特点的输入数据生成一个嵌入,对原始的特征进行了构造;
- 参数实验和消融实验部分,本文尝试了多种可用的设置,证明本文的方法具有一定的灵活性。
CVPR 2016 paper reading
1. Neuroaesthetics in fashion: modeling the perception of fashionability, Edgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel Urtasun, in CVPR 2015.
Goal: learn and predict how fashionable a person looks on a photograph, and suggest subtle improvements that user could make to improve her/his appeal.
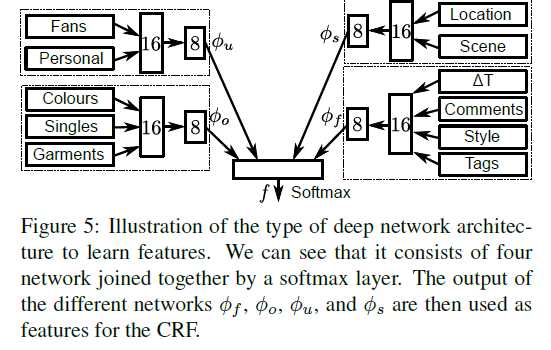
This paper proposes a Conditional Random Field model that jointly reasons about several fashionability factors such as the type of outfit (全套装备) and garments (衣服) the user is wearing, the type of the user, the photograph‘s setting (e.g., the scenery behind the user), and the fashionability score.
Importantly, the proposed model is able to give rich feed back to the user, conveying which garments or even scenery she/he should change in order to improve fashionability.

This paper collects a novel dataset that consists of 144,169 user posts from a clothing-oriented social website chictopia.com. In a post, a user publishes one to six photographs of her/himself wearing a new outfit. Generally each photograph shows a different angle of the user or zoons in on different garments. User sometimes also add a description of the outfit, and/or tags of the types and colors of the garments they are wearing.

Discovering fashion from weak data:
The energy of the CRF as a sum of energies encoding unaries for each variable as well as non-parametric pairwise pothentials which reflect the correlations between the different random variables:
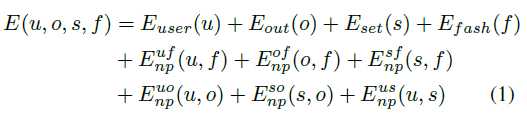
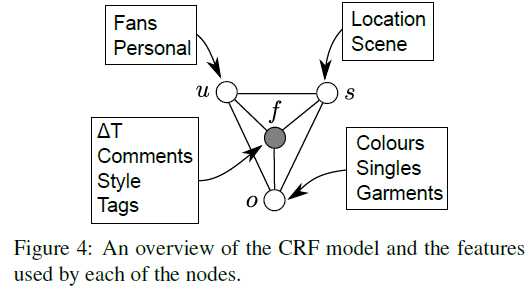
User specific features:
- the logarithm of the number of fans
- use rekognition to compute attributes of all the images of each post, keep the features for the image with the highest score.
Then compute the unary potentials as the output of a small neural network, produce an 8-D feature map.
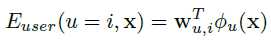
Outfit features:
bag-of-words approach on the "garments" and "colours" meta-data
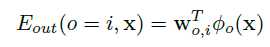
Setting features:
- the output of a pre-trained scene classifier (multi-layer perceptron, whose input is CNN feature)
- user-provided location: look up the latitude and longitude of the user-provided location, project all the values on the unit sphere, and add some small Guassian noise. Then perform unsupervised clustering using the geodesic distances, and use the geodesic distance from each cluster center as a feature.
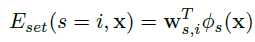
Fashion:
- delta time: the time between the creation of the post and when the post was crawled as a feature
- bag-of-words on the "tag"
- comments: parse the comments with the sentiment-analysis model, which can predict how positive a review is on a 1- 5 scale, sum the scores for each post.
- style: style classifier pretrained on Flickr80K.
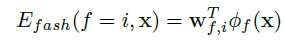
Correlations:
use a non-parametric function for each pairwise and let the CRF learn the correlations:
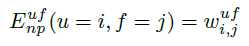
Similarly for the other pairwise potentials.
Learn and Inference:
First jointly train the deep networks that are used for feature extraction to predict fashionablity, and estimate the initial latent states using clustering.
Then learn the CRF model using the primal-dual method.
以上是关于Paper Reading: Gradient Boosted Neural Decision Forest的主要内容,如果未能解决你的问题,请参考以下文章