lightdb增量检查点特性及稳定性测试
Posted LightDB分布式数据库非官方技术站点
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lightdb增量检查点特性及稳定性测试相关的知识,希望对你有一定的参考价值。
checkpoint是一个数据库事件,它将已修改的数据从高速缓存刷新到磁盘,并更新控制文件和数据文件,此时会有大量的I/O写操作。
在PostgreSQL中,检查点(后台)进程执行检查点;当发生下列情况之一时,其进程将启动:
- 检查点间隔时间由checkpoint_timeout设置(默认间隔为300秒(5分钟))
- 在9.5版或更高版本中,pg_xlog中WAL段文件的总大小(在10版或更高版本中为pg_WAL)已超过参数max_WAL_size的值(默认值为1GB(64个16MB文件))。
- PostgreSQL服务器在smart或fast模式下关闭。
- 手动checkpoint。
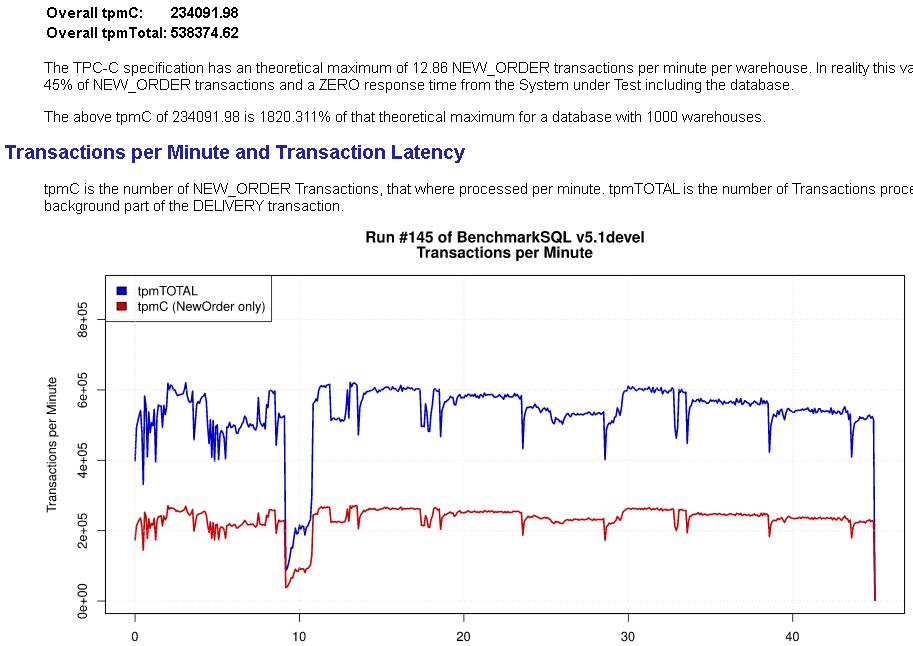
从lightdb 23.2开始,正式支持增量检查点机制。启用增量检查点后,运行曲线如下:
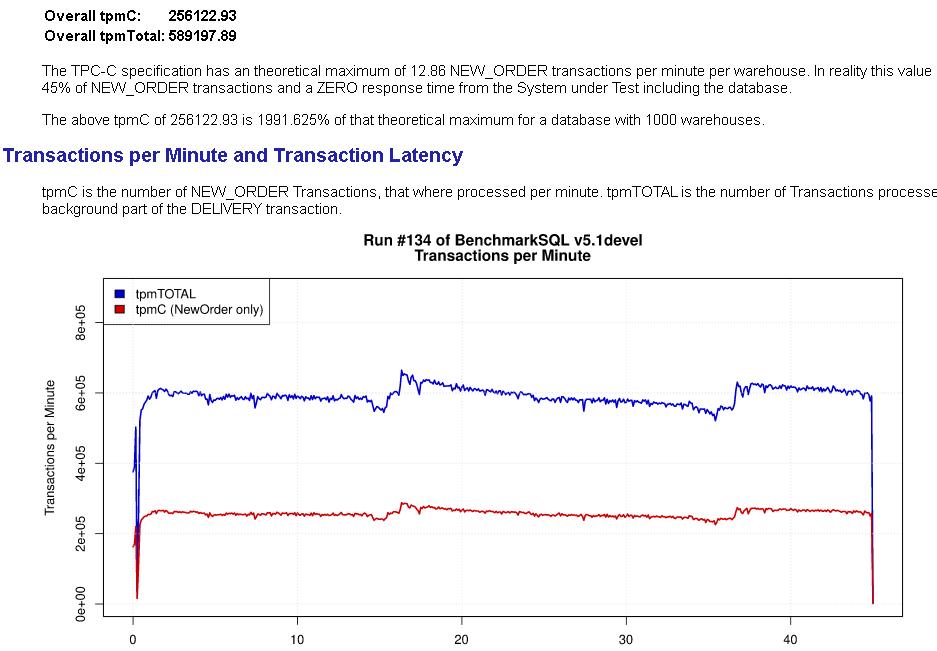
虽然通过优化相关参数,也能达到比较接近的效果,但是完全依赖于DBA和精细调优的结果。而采用增量检查点,该过程完全自动化了,大大提升了数据库的自治性。
其由下列参数控制:
enable_incremental_checkpoint,是否启用增量检查点,默认:off
incre_checkpoint_timeout:增量检查点模式下检查点的触发间隔
log_pagewriter:是否在PageWriter内打印日志
enable_candidate_buf_usage_count:是否在管理页面空闲队列时考虑页面的usage count
enable_double_write=off ,是否启用双写,默认:off。如果未启用增量检查点,该参数无效。
dw_file_num:双写文件的数量
dw_file_size: 每个双写文件的大小
max_io_capacity:用户预估的磁盘I/O带宽
pagewriter_thread_num:PageWriter子进程的数量
pagewriter_sleep:PageWriter刷页的间隔
lightdb22.1新特性-新增多种优化器提示
LightDB 22.1 新特性-新增优化器提示
LightDB 22.1 在原先基础上新增了多种优化器提示,包括use_hash_aggregation,semijoin/antijoin,swap_join_inputs。
use_hash_aggregation/no_use_hash_aggregation
使用此优化器提示可以控制group by的算法,目前group by有两种算法,一种为排序,另一种为哈希, 通过使用use_hash_aggregation可以控制group by使用hash算法,使用no_use_hash_aggregation控制group by不使用hash算法,也即使用排序算法。示例如下:
lightdb@postgres=# create table test1 (key1 int primary key, key2 int);
CREATE TABLE
lightdb@postgres=# EXPLAIN (COSTS false) select max(id) from t1 where id>1 group by id order by id;
QUERY PLAN
-------------------------------------------
GroupAggregate
Group Key: id
-> Index Only Scan using t1_pkey on t1
Index Cond: (id > 1)
(4 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select/*+ use_hash_aggregation*/ max(id) from t1 where id>1 group by id order by id;
QUERY PLAN
------------------------------------
Sort
Sort Key: id
-> HashAggregate
Group Key: id
-> Seq Scan on t1 @"lt#0"
Filter: (id > 1)
(6 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select max(id) from t1 where id>1 group by id;
QUERY PLAN
--------------------------
HashAggregate
Group Key: id
-> Seq Scan on t1
Filter: (id > 1)
(4 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select/*+ no_use_hash_aggregation*/ max(id) from t1 where id>1 group by id;
QUERY PLAN
---------------------------------------------------
GroupAggregate
Group Key: id
-> Index Only Scan using t1_pkey on t1 @"lt#0"
Index Cond: (id > 1)
(4 rows)
lightdb@postgres=#
semijoin/antijoin
semijoin/hash_sj/nl_sj/merge_sj/no_semijoin
此优化器提示用来控制exists/in子链接join时使用或不使用semijoin,并可以控制seimjoin的算法,是走nestloop、hash还是merge join。示例如下:
lightdb@postgres=# create table test1 (key1 int primary key, key2 int);
CREATE TABLE
lightdb@postgres=# create table test2 (key1 int primary key, key2 int);
CREATE TABLE
lightdb@postgres=#
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where exists (select * from test2 where test1.key1=test2.key1);
QUERY PLAN
----------------------------------------
Hash Join
Hash Cond: (test1.key1 = test2.key1)
-> Seq Scan on test1
-> Hash
-> Seq Scan on test2
(5 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where exists (select /*+semijoin*/* from test2 where test1.key1=test2.key1);
QUERY PLAN
---------------------------------------------------------
Merge Semi Join
Merge Cond: (test1.key1 = test2.key1)
-> Index Scan using test1_pkey on test1 @"lt#1"
-> Index Only Scan using test2_pkey on test2 @"lt#0"
(4 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where exists (select /*+hash_sj*/* from test2 where test1.key1=test2.key1);
QUERY PLAN
----------------------------------------
Hash Semi Join
Hash Cond: (test1.key1 = test2.key1)
-> Seq Scan on test1 @"lt#1"
-> Hash
-> Seq Scan on test2 @"lt#0"
(5 rows)
lightdb@postgres=#
lightdb@postgres=# create table tt1 (id int, t int, name varchar(255));
CREATE TABLE
lightdb@postgres=# create table tt2 (id int , salary int);
CREATE TABLE
lightdb@postgres=# create index idx_t1_id on tt1(id);
CREATE INDEX
lightdb@postgres=# create index idx_t2_id on tt2(id);
CREATE INDEX
lightdb@postgres=#
lightdb@postgres=# EXPLAIN (COSTS false) select * from tt1 where exists (select * from tt2 where tt1.id=tt2.id);
QUERY PLAN
----------------------------------------------
Nested Loop Semi Join
-> Seq Scan on tt1
-> Index Only Scan using idx_t2_id on tt2
Index Cond: (id = tt1.id)
(4 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select * from tt1 where exists (select /*+no_semijoin*/* from tt2 where tt1.id=tt2.id);
QUERY PLAN
-------------------------------------------
Hash Join
Hash Cond: (tt1.id = tt2.id)
-> Seq Scan on tt1 @"lt#1"
-> Hash
-> HashAggregate
Group Key: tt2.id
-> Seq Scan on tt2 @"lt#0"
(7 rows)
lightdb@postgres=#
hash_aj/nl_aj/merge_aj
此优化器提示用来控制not exists/not in子链接使用antijoin时的算法,是走nestloop、hash还是merge join。示例如下:
lightdb@postgres=# create table tt1 (id int, t int, name varchar(255));
CREATE TABLE
lightdb@postgres=# create table tt2 (id int , salary int);
CREATE TABLE
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where not exists (select 1 from test2 where test1.key1=test2.key1);
QUERY PLAN
----------------------------------------
Hash Anti Join
Hash Cond: (test1.key1 = test2.key1)
-> Seq Scan on test1
-> Hash
-> Seq Scan on test2
(5 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where not exists (select/*+hash_aj*/ 1 from test2 where test1.key1=test2.key1);
QUERY PLAN
----------------------------------------
Hash Anti Join
Hash Cond: (test1.key1 = test2.key1)
-> Seq Scan on test1 @"lt#1"
-> Hash
-> Seq Scan on test2 @"lt#0"
(5 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where not exists (select/*+nl_aj*/ 1 from test2 where test1.key1=test2.key1);
QUERY PLAN
---------------------------------------------------------
Nested Loop Anti Join
-> Seq Scan on test1 @"lt#1"
-> Index Only Scan using test2_pkey on test2 @"lt#0"
Index Cond: (key1 = test1.key1)
(4 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1 where not exists (select/*+merge_aj*/ 1 from test2 where test1.key1=test2.key1);
QUERY PLAN
---------------------------------------------------------
Merge Anti Join
Merge Cond: (test1.key1 = test2.key1)
-> Index Scan using test1_pkey on test1 @"lt#1"
-> Index Only Scan using test2_pkey on test2 @"lt#0"
(4 rows)
lightdb@postgres=#
swap_join_inputs
此优化器提示用来指定hash join的外表(驱动表)。示例如下:
lightdb@postgres=# create table test1 (key1 int primary key, key2 int);
CREATE TABLE
lightdb@postgres=# create table test2 (key1 int primary key, key2 int);
CREATE TABLE
lightdb@postgres=# EXPLAIN (COSTS false) select * from test1, test2 where test1.key1 = test2.key1;
QUERY PLAN
----------------------------------------
Hash Join
Hash Cond: (test1.key1 = test2.key1)
-> Seq Scan on test1
-> Hash
-> Seq Scan on test2
(5 rows)
lightdb@postgres=# EXPLAIN (COSTS false) select /*+swap_join_inputs(test2)*/* from test1, test2 where test1.key1 = test2.key1;
LOG: pg_hint_plan:
used hint:
swap_join_inputs(test2@lt#0)
not used hint:
duplication hint:
error hint:
QUERY PLAN
----------------------------------------
Hash Join
Hash Cond: (test2.key1 = test1.key1)
-> Seq Scan on test2 @"lt#0"
-> Hash
-> Seq Scan on test1 @"lt#0"
(5 rows)
lightdb@postgres=#
需要注意的是,如果SQL原先不为hashjoin, 使用了此hint后会变为hashjoin。示例如下:
lightdb@postgres=# create table t_1(key1 int not null);
CREATE TABLE
lightdb@postgres=# create table t_2(key1 int not null);
CREATE TABLE
lightdb@postgres=# explain select /*swap_join_inputs(t_2)*/* from t_1,t_2 where t_1.key1=t_2.key1;
QUERY PLAN
-------------------------------------------------------------------
Merge Join (cost=359.57..860.00 rows=32512 width=8)
Merge Cond: (t_1.key1 = t_2.key1)
-> Sort (cost=179.78..186.16 rows=2550 width=4)
Sort Key: t_1.key1
-> Seq Scan on t_1 (cost=0.00..35.50 rows=2550 width=4)
-> Sort (cost=179.78..186.16 rows=2550 width=4)
Sort Key: t_2.key1
-> Seq Scan on t_2 (cost=0.00..35.50 rows=2550 width=4)
(8 rows)
lightdb@postgres=# explain select /*+swap_join_inputs(t_2)*/* from t_1,t_2 where t_1.key1=t_2.key1;
LOG: pg_hint_plan:
used hint:
swap_join_inputs(t_2@lt#0)
not used hint:
duplication hint:
error hint:
QUERY PLAN
---------------------------------------------------------------------------
Hash Join (cost=67.38..1247.18 rows=32512 width=8)
Hash Cond: (t_2.key1 = t_1.key1)
-> Seq Scan on t_2 @"lt#0" (cost=0.00..35.50 rows=2550 width=4)
-> Hash (cost=35.50..35.50 rows=2550 width=4)
-> Seq Scan on t_1 @"lt#0" (cost=0.00..35.50 rows=2550 width=4)
(5 rows)
lightdb@postgres=#
ey1)
-> Seq Scan on t_2 @“lt#0” (cost=0.00…35.50 rows=2550 width=4)
-> Hash (cost=35.50…35.50 rows=2550 width=4)
-> Seq Scan on t_1 @“lt#0” (cost=0.00…35.50 rows=2550 width=4)
(5 rows)
lightdb@postgres=#
以上是关于lightdb增量检查点特性及稳定性测试的主要内容,如果未能解决你的问题,请参考以下文章