Python-selenium-元素识别和定位
Posted 灬阿东丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-selenium-元素识别和定位相关的知识,希望对你有一定的参考价值。
一、 浏览器基本操作
浏览器中加载url get() --首先要启动浏览器

浏览器最大化 maxsize_window()

刷新 refresh()

返回上一页 back()

向前进一页 forward

截图 get_screenshot_as_file(“文件路径”)

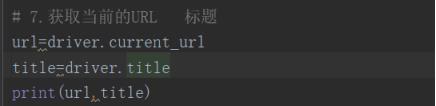
获取当前页的URL current_url
关闭当前tab页面 close()
退出当前driver quit()

二、 7大识别方法
识别原则:元素要唯一
通过id定位元素

通过name定位元素

通过class_name定位元素

通过tag_name定位元素 不靠谱
通过link定位元素

通过css定位元素
通过xpath定位元素
三、 xpath识别方法
作用:通过路径识别
注意事项:分隔符为/,索引下标是从1开始
通过绝对路径做定位


通过相对路径做定位
如果开头是两个斜线(//),表示文件中所有符合模式的元素都会被选出来,即使处于树中不同的层级也会被选出来

通过元素索引做定位,索引的初始位置为1

通过xpath属性做定位 [@属性=’值’]

通过部分属性值匹配

通过任意属性值匹配元素

使用xpath的text函数

以上是关于Python-selenium-元素识别和定位的主要内容,如果未能解决你的问题,请参考以下文章