mysql执行优化器
Posted 意犹未尽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql执行优化器相关的知识,希望对你有一定的参考价值。
sql
这个ql看着给人感觉t表是驱动表,其实优化器优化后trc才是驱动表,因为t的查询条件筛选出来有50多万,二trc筛选只有几千条
explain select distinct t.`id` as "id", t.deleted as "deleted", t.no as "no", ru.name as "requester_name", tm.solve_minutes as "ticketMetric_solve_minutes" , t.subject as "subject", create_user.name as "user_name", t.priority as "priority", eu.name as "engineer_user_name", t.created_at as "created_at" , type.name as "ticketType_name", tm.solved_at as "ticketMetric_solved_at", tm.last_comment_at as "ticketMetric_last_comment_at", review_user.name as "reviewUser_name", ug.name as "requester_userGroup_name" , catalog.id as "serviceCatalog_id", tm.plan_solved_at as "ticketMetric_plan_solved_at", t.status as "status", t.updated_at as "updated_at", t.engineer_id as "engineer_id" , eu.id as "engineer_user_id", t.requester_id as "requester_id", ug.id as "requester_userGroup_id", t.ticket_type_id as "ticketType_id", t.ticket_metric_id as "ticketMetric_id" , t.user_id as "user_id", t.review_user_id as "reviewUser_id" from ticket t left join engineer eg on t.engineer_id = eg.id left join `user` eu on eg.user_id = eu.id inner join `user` ru on t.requester_id = ru.id left join user_group ug on ru.user_group_id = ug.id left join ticket_type type on t.ticket_type_id = type.id left join ticket_metric tm on t.ticket_metric_id = tm.id left join user create_user on t.user_id = create_user.id left join user review_user on t.review_user_id = review_user.id left join service_catalog catalog on t.service_catalog_id = catalog.id where t.provider_id = 20813 and (t.status is null or t.status not in (\'deleted\', \'suspended\')) and (t.deleted = false or t.deleted is null) and tm.solved_at >= \'2023-04-01 00:00:00\' and tm.solved_at <= \'2023-04-30 23:59:59\' and t.id in ( select trc.ticket_id from ticket_r_cc trc where trc.service_desk_id in (29504) )
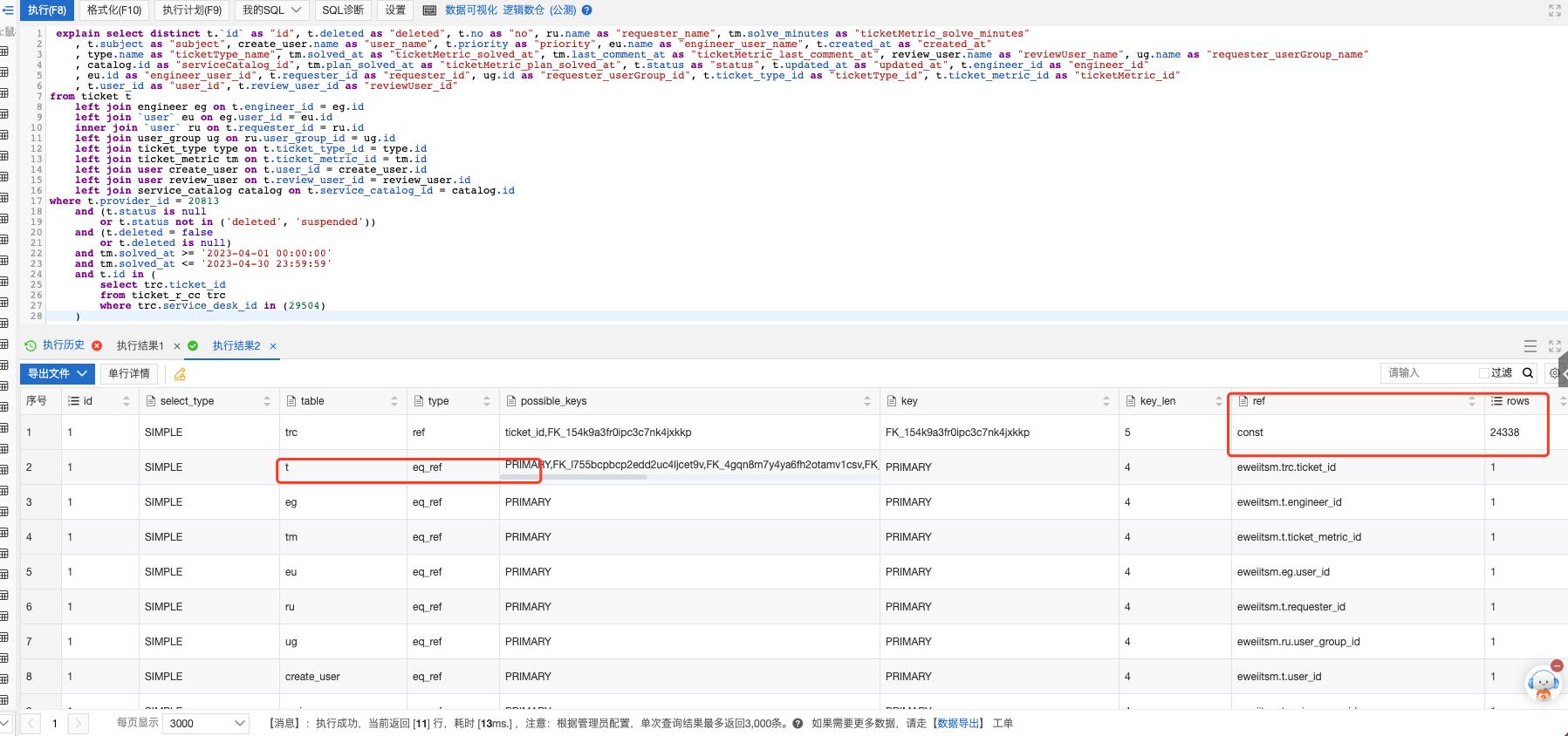
mysql查询优化器为什么可能会选择错误的执行计划
可能导致mysql优化器选择错误的执行计划的原因如下:
A:统计信息不准确,mysql依赖存储引擎提供的统计信息来评估成本,但有的存储引擎提供的信息是准确的,有的引擎提供的可能就偏差很大,如:innodb因为其MVCC的架构,并不能维护一个数据表的行数的精确统计。
B:执行计划中的成本估算不等同于实际执行的成本,所以即使统计信息精准,优化器给出的执行计划也可能不是最优的,如:有时候某个执行计划虽然需要读取更多的页,但它的实际执行成本却更小,因为如果这些页面都是顺序或者这些页面都在内存中,那么它的访问成本将小很
多。mysql层面并不知道哪些页面在内存中,哪些在磁盘上,所以查询实际执行过程中到底需要多少次物理IO是无法预估的。
C:mysql的最优可能和你觉得最优的不一样,你可能希望执行时间尽可能地短,但是mysql只是基于成本模型选择最优执行计划,而有些时候这并不是最快的执行计划(因为mysql的成本估算主要基于扫描行数,而如果这些行是顺序的或者是在内存中,那么扫描速度就会很快,相反,如果这些行是在磁盘上且是无序的,就会产生随机读取,那么就算扫描更少的行,可能执行时间更长,而优化器在评估成本的时候并不考虑任何层面的缓存,它假设读取任何数据都需要一次磁盘IO)。
D:mysql从不考虑其他并发执行的查询,这可能影响到当前查询的速度
E:mysql也并不是任何时候都是基于成本优化,有时候也会基于一些固定的规则,如:如果存在全文搜索的match()子句,则在存在全文索引的时候就使用全文索引,即使有时候使用别的索引和where条件可以远比这种方式快,mysql也仍然使用对应的全文索引。
F:mysql不会考虑不受控制的操作成本,如:执行存储过程或者用户自定义函数的成本
G:优化器有时候无法去估算所有可能的执行计划,所以它可能错过实际上最优的执行计划。
以上是关于mysql执行优化器的主要内容,如果未能解决你的问题,请参考以下文章