基于python的Splash基本使用和负载均衡配置
Posted wangxuanyou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python的Splash基本使用和负载均衡配置相关的知识,希望对你有一定的参考价值。
1. 工具
语言:python3.7,Lua
编译器:pycharm
包管理工具:pip
工具:Scrapy-Splash
应用容器引擎:docker
2. 功能介绍
利用Splash,我们可以实现如下功能:
异步方式处理多个网页渲染过程;
获取渲染后的页面的源代码或截图;
通过关闭图片渲染或者使用Adblock规则来加快页面渲染速度;
可执行特定的JavaScript脚本;
可通过Lua脚本来控制页面渲染过程;
获取渲染的详细过程并通过HAR(HTTP Archive)格式呈现。
3. 项目实战
首先,在本机端口运行Splash服务,打开http://localhost:8050/
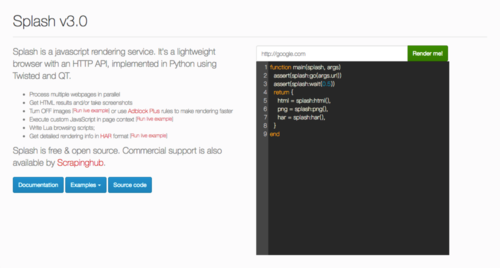
在输入框内输入https://www.shou.edu.cn/,然后点击Render me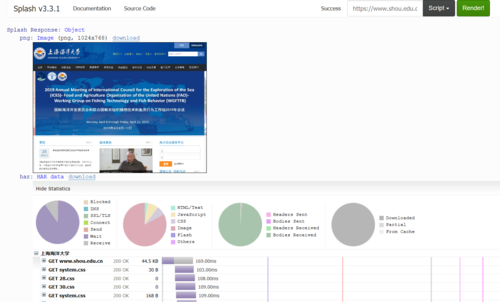
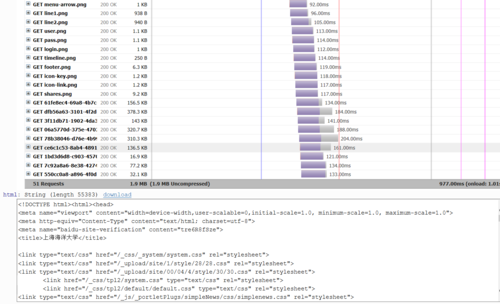
可以看到,网页的返回结果呈现了渲染截图、HAR加载统计数据、网页的源代码。
通过HAR的结果可以看到,Splash执行了整个网页的渲染过程,包括CSS、JavaScript的加载等过程,呈现的页面和我们在浏览器中得到的结果完全一致。
4. Splash Lua脚本
Splash是通过Lua脚本来控制了页面的加载过程的,然后执行一系列渲染操作。
入口及返回值
function main(splash, args)
splash:go("https://www.shou.edu.cn/")
splash:wait(1) local title = splash:evaljs("document.title") return {title=title}end
本代码通过evaljs()方法传入JavaScript脚本,而document.title的执行结果就是返回网页标题,执行完毕后将其赋值给一个title变量,随后将其返回。
异步处理
function main(splash, args) local example_urls = {"https://www.shou.edu.cn/", "http://www.gdou.edu.cn/", "http://www.ouc.edu.cn/"} local urls = args.urls or example_urls local results = {} for index, url in ipairs(urls) do
local ok, reason = splash:go("http://" .. url) if ok then
splash:wait(2)
results[url] = splash:png() end
end
return resultsend
在脚本内调用的wait()方法类似于Python中的sleep(),其参数为等待的秒数。当Splash执行到此方法时,它会转而去处理其他任务,然后在指定的时间过后再回来继续处理。
更多Lua脚本的语法详见http://www.runoob.com/lua/lua-basic-syntax.html
5. Splash对象属性
args
该属性可以获取加载时配置的参数,比如URL,如果为GET请求,它还可以获取GET请求参数;如果为POST请求,它可以获取表单提交的数据。
function main(splash, args) local url = args.urlend
第二个参数args就相当于splash.args属性
js_enabled
这个属性是Splash的JavaScript执行开关,可以将其配置为true或false来控制是否执行JavaScript代码,默认为true。
function main(splash, args)
splash:go("https://www.shou.edu.cn/")
splash.js_enabled = false
local title = splash:evaljs("document.title") return {title=title}end
更多对象如resource_timeout、images_enabled、plugins_enabled、scroll_position详见https://blog.csdn.net/weixin_38239050/article/details/82584613
6. Splash对象的方法
详见https://splash.readthedocs.io/en/stable/scripting-ref.html
7. Splash API调用
详见https://splash.readthedocs.io/en/stable/scripting-element-object.html
8. 配置Splash服务
要搭建Splash负载均衡,首先要有多个Splash服务。假如多台远程主机的都开启了Splash服务,它这几个服务必须完全一致,都是通过Docker的Splash镜像开启的。访问其中任何一个服务时,都可以使用Splash服务。
9. 配置负载均衡
选用任意一台带有公网IP的主机来配置负载均衡。首先,在这台主机上装好Nginx,然后修改Nginx的配置文件nginx.conf,添加各台主机的ip。
10. 配置认证
现在Splash是可以公开访问的,如果不想让其公开访问,还可以配置认证,这仍然借助于Nginx。可以在server的location字段中添加auth_basic和auth_basic_user_file字段。
http {
upstream splash {
least_conn;
server xxx;
server xxx;
……
}
server {
listen 8050;
location / {
proxy_pass http://splash;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}
11. 测试
import requestsfrom urllib.parse import quoteimport re
lua = ‘‘‘function main(splash, args)
local treat = require("treat")
local response = splash:http_get("https://www.shou.edu.cn/")
return treat.as_string(response.body)
end‘‘‘
url = ‘http://splash:8050/execute?lua_source=‘ + quote(lua)
response = requests.get(url, auth=(‘admin‘, ‘admin‘))
ip = re.search(‘(d+.d+.d+.d+)‘, response.text).group(1)print(ip)
这里URL中的splash字符串请自行替换成自己的Nginx服务器IP。这里我修改了Hosts,设置了splash为Nginx服务器IP。
以上是关于基于python的Splash基本使用和负载均衡配置的主要内容,如果未能解决你的问题,请参考以下文章