(Java)记一次通过API递归分页“爬取”网页数据的开发经历
Posted Apluemxa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(Java)记一次通过API递归分页“爬取”网页数据的开发经历相关的知识,希望对你有一定的参考价值。
前言
在最近的互联网项目开发中,需要获取用户的访问ip信息进行统计的需求,用户的访问方式可能会从微信内置浏览器、Windows浏览器等方式对产品进行访问。
当然,获取这些关于ip的信息是合法的。但是,这些ip信息我们采用了其它第三方的服务来记录,并不在我们的数据库中。
这些ip信息是分组存放的,且每个分组都都是分页(1页10条)存放的,如果一次性访问大量的数据,API很有可能会报错。
怎样通过HTTP的方式去获取到信息,并且模拟浏览器每页每页获取10条的信息,且持久到数据库中,就成了当下亟需解决的问题。
通过以上的分析,可以有大致以下思路:
1、拿到该网页http请求的url地址,同时获取到调用该网页信息的参数(如:header、param等);
2、针对分页参数进行设计,由于需要不断地访问同一个接口,所以可以用循环+递归的方式来调用;
3、将http接口的信息进行解析,同时保证一定的访问频率(大部分外部http请求都会有访问频率限制)让返回的数据准确;
4、整理和转化数据,按照一定的条件,批量持久化到数据库中。
一、模拟http请求
我们除了在项目自己写API接口提供服务访问外,很多时候也会使用到外部服务的API接口,通过调用这些API来返回我们需要的数据。
如:
钉钉开放平台https://open.dingtalk.com/document/orgapp/user-information-creation、
微信开放平台https://open.weixin.qq.com/cgi-bin/index?t=home/index&lang=zh_CN等等进行开发。
这里分享一下从普通网页获取http接口url的方式,从而达到模拟http请求的效果:
以谷歌chrome浏览器为例,打开调式模式,根据下图步骤:
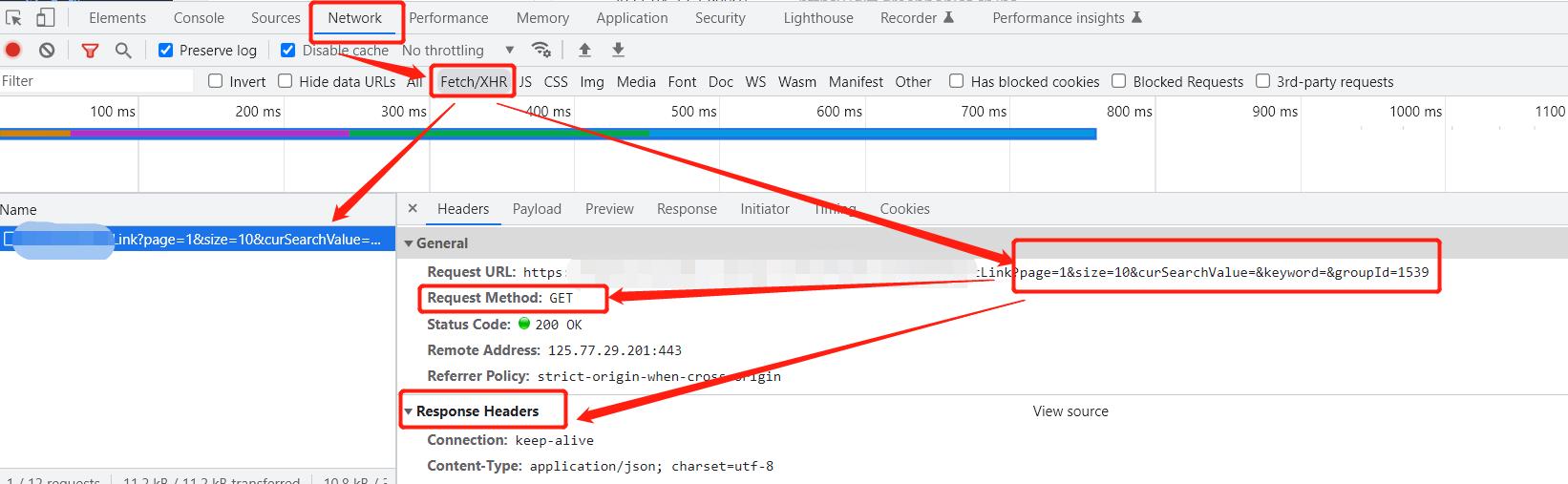
尤其注意使用Fetch/XHR,右键该url—>copy—>copy as cURL(bash):
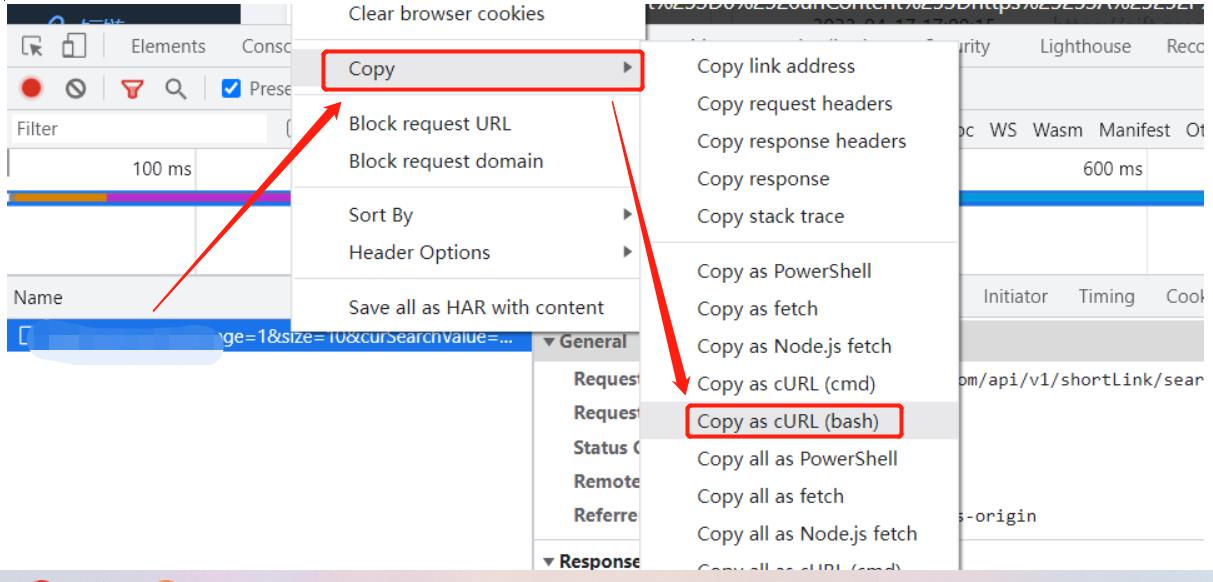
随后粘贴到Postman中,模拟http请求:
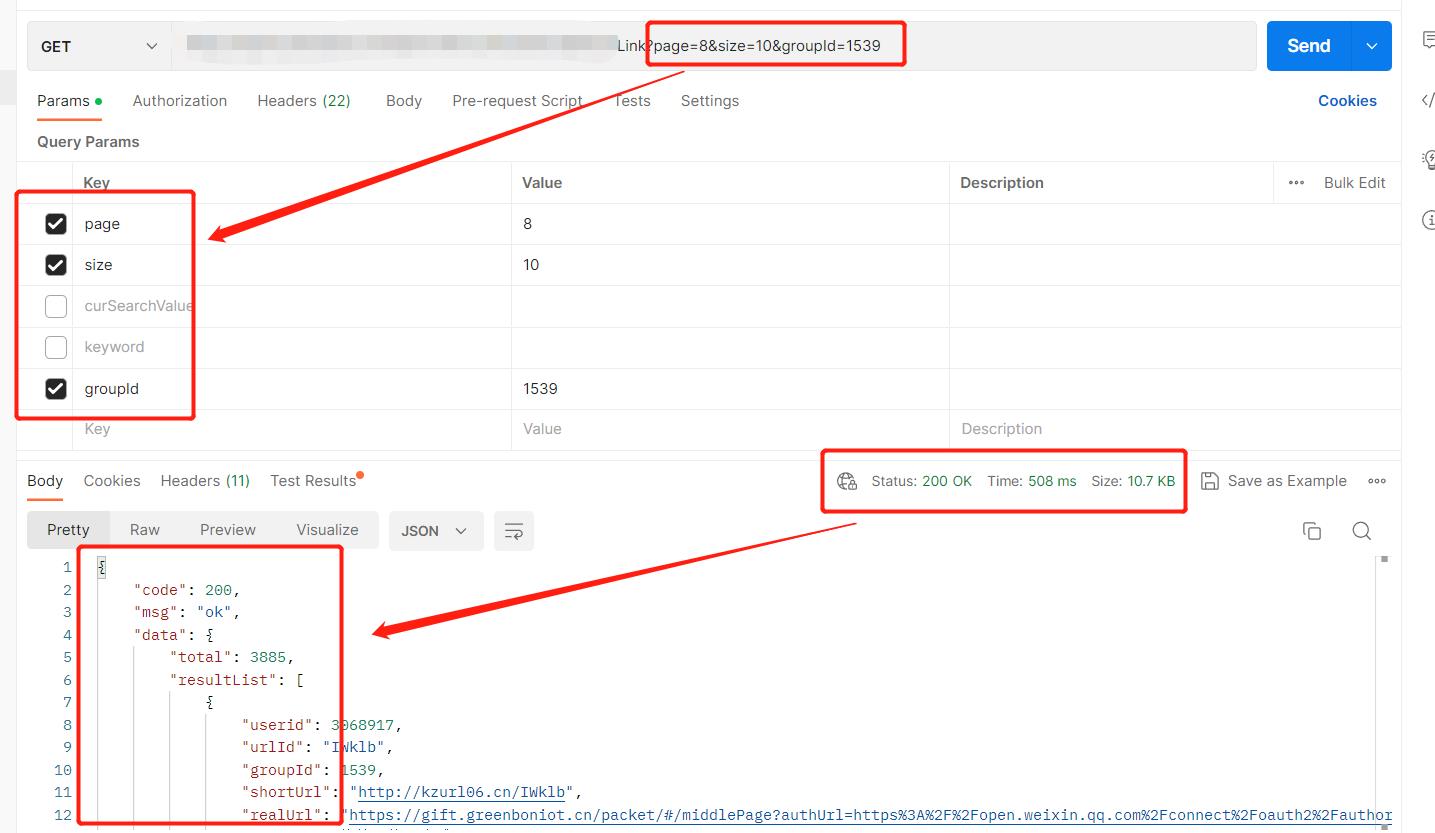
粘贴的同时,还会自动带上header参数(以下这4个参数比较重要,尤其是cookie):
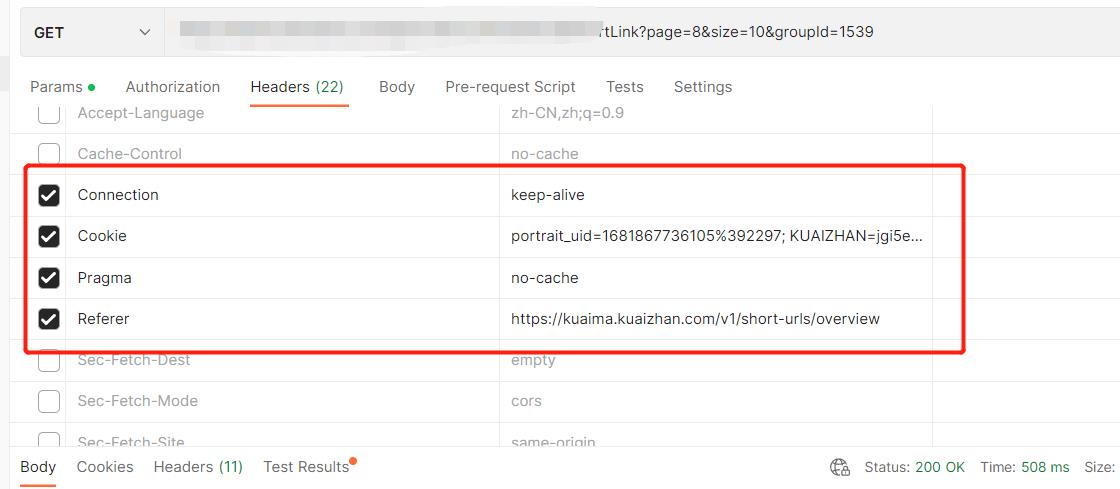
这样,就可以访问到所需的数据了,并且数据是json格式化的,这便于我们下一步的数据解析。
二、递归+循环设计
有几个要点需要注意:
1、分内外两层,内外都需要获取数据,即外层获取的数据是内层所需要的;
2、每页按照10条数据来返回,直到该请求没有数据,则访问下一个请求;
3、递归获取当前请求的数据,注意页数的增加和递归终止条件。
废话不多说,直接上代码:
点击查看代码
public boolean getIpPoolOriginLinksInfo(HashMap<String, Object> commonPageMap, HashMap<String, String> headersMap,String charset)
//接口调用频率限制
check(commonAPICheckData);
String linkUrl = "https://xxx.xxx.com/api/v1/xxx/xxx";
HashMap<String, Object> linkParamsMap = new HashMap<>();
linkParamsMap.put("page",commonPageMap.get("page"));
linkParamsMap.put("size",commonPageMap.get("size"));
String httpLinkResponse = null;
//封装好的工具类,可以直接用apache的原生httpClient,也可以用Hutool的工具包
httpLinkResponse = IpPoolHttpUtils.doGet(linkUrl,linkParamsMap,headersMap,charset);
JSONObject linkJson = null;
JSONArray linkArray = null;
linkJson = JSON.parseObject(httpLinkResponse).getJSONObject("data");
linkArray = linkJson.getJSONArray("resultList");
if (linkArray != null)
//递归计数
if (!commonPageMap.get("page").toString().equals("1"))
commonPageMap.put("page","1");
// 每10条urlId,逐一遍历
for (Object linkObj : linkJson.getJSONArray("resultList"))
JSONObject info = JSON.parseObject(linkObj.toString());
String urlId = info.getString("urlId");
// 获取到的每个urlId,根据urlId去获取ip信息(即内层的业务逻辑,我这里忽略,本质就是拿这里的参数传到内层的方法中去)
boolean flag = getIpPoolOriginRecords(urlId, commonPageMap, headersMap, charset);
if (!flag)
break;
Integer page = Integer.parseInt(linkParamsMap.get("page").toString());
if (page <= Math.ceil(Integer.parseInt(linkJson.getString("total"))/10))
Integer newPage = Integer.parseInt(linkParamsMap.get("page").toString()) + 1;
linkParamsMap.put("page", Integer.toString(newPage));
// 递归分页拉取
getIpPoolOriginLinksInfo(linkParamsMap,headersMap,charset);
else
return true;
return true;
三、解析数据(调用频率限制)
一般来说,调用外部API接口会有调用频率的限制,即一段时间内不允许频繁请求接口,否则会返回报错,或者禁止调用。基于这样的限制,我们可以简单设计一个接口校验频率的方法,防止请求的频率太快。
废话不多说,代码如下:
点击查看代码
/**
* 调用频率校验,按照分钟为单位校验
* @param commonAPICheckData
*/
private void check(CommonAPICheckData commonAPICheckData)
int minuteCount = commonAPICheckData.getMinuteCount();
try
if (minuteCount < 2)
//接近频率限制时,休眠2秒
Thread.sleep(2000);
else
commonAPICheckData.setMinuteCount(minuteCount-1);
catch (InterruptedException e)
throw new RuntimeException("-------外部API调用频率错误!--------");
点击查看代码
@Data
public class CommonAPICheckData
/**
* 每秒调用次数计数器,限制频率:每秒钟2次
*/
private int secondCount = 3;
/**
* 每分钟调用次数计数器,频率限制:每分钟100次
*/
private int minuteCount = 100;
四、数据持久化
爬出来的数据我这里是按照一条一条入库的,当然也可以按照批次进行batch的方式入库:
点击查看代码
/**
* 数据持久化
* @param commonIpPool
*/
private boolean getIpPoolDetails(CommonIpPool commonIpPool)
try
//list元素去重,ip字段唯一索引
commonIpPoolService.insert(commonIpPool);
catch (Exception e)
if (e instanceof DuplicateKeyException)
return true;
throw new RuntimeException(e.getMessage());
return true;
五、小结
其实,爬取数据的时候我们会遇到各种各样的场景,这次分享的主要是分页递归的相关思路。
有的时候,如果网页做了防爬的功能,比如在header上加签、访问前进行滑动图片校验、在cookie上做加密等等,之后有时间还会接着分享。
代码比较粗糙,如果大家有其它建议,欢迎讨论。
如有错误,还望大家指正。
JAVA爬取天天基金网数据
天天基金网网址:http://quote.eastmoney.com/center/gridlist.html#fund_lof
爬取基金历史记录代码:
1。首先要自己定义几个参数:基金编码,页数,每页显示条数 开始时间结束时间等
(我这直接写的静态方法使用的 大家可以改成Test方法自行进行测试)
/** * httClient 请求 GET * 获取基金网数据1 */ public static JSONArray testDepartmentList1(String code){ Integer pageIndex = 1; Integer pageSize=20; String startTime="2018-1-1"; String endTime = "2020-4-15"; String referer = "http://fundf10.eastmoney.com/f10/jjjz_" + code + ".html"; long time = System.currentTimeMillis(); String url = "http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18306596328894644803_1571038362181&" + "fundCode=%s&pageIndex=%s&pageSize=%s&startDate=%s&endDate=%s&_=%s"; url = String.format(url,code,pageIndex,pageSize,startTime,endTime,time); System.out.println("url= " + url); System.out.println(url); HttpRequest request = HttpUtil.createGet(url); request.header("Referer", referer); String str = request.execute().body(); //获取str的长度 System.out.println("str=" + str); int length = str.length(); System.out.println("length=" + length); //indexOf返回某个指定的字符串值在字符串中首次出现的位置 int indexStart = str.indexOf("("); System.out.println(indexStart); //截取字符串 str = str.substring(indexStart + 9, length - 90); System.out.println(str); //转换为Obj类型 JSONObject jsonObject = JSON.parseObject(str); System.out.println(jsonObject); //获取数组 JSONArray jsonArray = jsonObject.getJSONArray("LSJZList"); //计算数组的长度 int size = jsonArray.size(); System.out.println(size); return jsonArray; }
通过基金编码查询基金名称
(由于查询的基金历史日期url里面的信息只有基金编号跟涨跌幅日期等 没有基金名称 我们通过基金网的查询功能自行填充基金编码进行查询)
/** * httClient 请求 GET * 获取基金网数据2 */ @Test public static String testDepartmentList2(String code) { //数据链接 String referer = "http://so.eastmoney.com/web/s?keyword="+code+""; long time = System.currentTimeMillis(); String url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&fltt" + "=2&fields=f59,f169,f170,f161,f163,f171,f126,f168,f164,f78,f162,f43,f46,f44,f45,f60,f47," + "f48,f49,f84,f116,f55,f92,f71,f50,f167,f117,f85,f84,f58,f57,f86,f172,f108,f118,f107,f164," + "f177&invt=2&secid=0."+code+"&cb=jQuery1124006112441213993569_1587006450385&_=1587006450403"; url = String.format(url,code); System.out.println("请求url:" + url); //http请求 HttpRequest request = HttpUtil.createGet(url); request.header("Referer", referer); String str = request.execute().body(); //获取str的长度 System.out.println("str=" + str); int length = str.length(); System.out.println("length=" + length); //indexOf返回某个指定的字符串值在字符串中首次出现的位置 int i = str.indexOf("("); System.out.println(i); //截取字符串 str = str.substring(i + 55, length - 3); System.out.println(str); //转换为Obj类型 JSONObject jsonObject = JSON.parseObject(str); System.out.println(jsonObject); String fundName = jsonObject.getString("f58"); return fundName; }
业务层实现:(主要功能:用户输入基金编号查询某个基金时如果数据库没有,自动从天天基金网爬取数据存储到数据库并显示到页面上)
显示的数据分别有:基金编号 基金日期 基金名称 实际价格 每日涨跌幅
@Override public List<FundHistory> query(String fundCode) { List<FundHistory> query = fundHistoryDao.query(fundCode); if (query.size()==0) { JSONArray jsonArray = testDepartmentList1(fundCode); System.out.println(jsonArray); //计算数组的长度 int size = jsonArray.size(); System.out.println(size); //for循环遍历 for (int j = 0; j < size; j++) { JSONObject jsonObject1 = jsonArray.getJSONObject(j); //获取净值日期 String date = jsonObject1.getString("FSRQ"); //获取单位净值 Double unit = jsonObject1.getDouble("DWJZ"); //获取累积净值 Double Accumulates = jsonObject1.getDouble("LJJZ"); //获取日增长率 String growthRate = jsonObject1.getString("JZZZL"); //创建时间 DateTime dateTime = new DateTime(); //获取创建时间 String datetime = String.valueOf(dateTime); FundHistory fundHistory = new FundHistory(); fundHistory.setFundCode(fundCode); fundHistory.setDate(date); fundHistory.setUnit(unit); fundHistory.setAccumulates(Accumulates); fundHistory.setGrowthRate(growthRate); fundHistory.setCreateTime(datetime); fundHistoryDao.saveFundHistory(fundHistory); } FundHistory fundHistory = new FundHistory(); fundHistory.setFundCode(fundCode); //获取基金名称 String fundName = testDepartmentList2(fundCode); fundHistory.setFundName(fundName); fundHistoryDao.updateFundHistory(fundHistory); List<FundHistory> query2 = fundHistoryDao.query(fundCode); FundHistory fundHistory1 = query2.get(0); fundDao.saveFund2(fundHistory1); return query2; } return query; }
controller层
/** * 基金页面数据交互 * @param * @return */ @RequestMapping("/enquiryfund") @ResponseBody public Result enquiryfund(String fundCode,String fundName){ Result result = new Result<>(); if (fundCode!=""){ List<FundHistory> query = fundHistoryService.query(fundCode); if (query==null){ List<FundHistory> query2 = fundHistoryService.query(fundCode); result.setData(query2); return result; } result.setData(query); return result; }else if (fundName!=""){ List<FundHistory> fundHistories = fundHistoryService.query2(fundName); result.setData(fundHistories); return result; } return result; }
运行效果如图:
(根据基金编号进行查询基金 如果数据库没有则自动从天天基金网拉取数据并显示到页面上 共拉取20条历史数据)
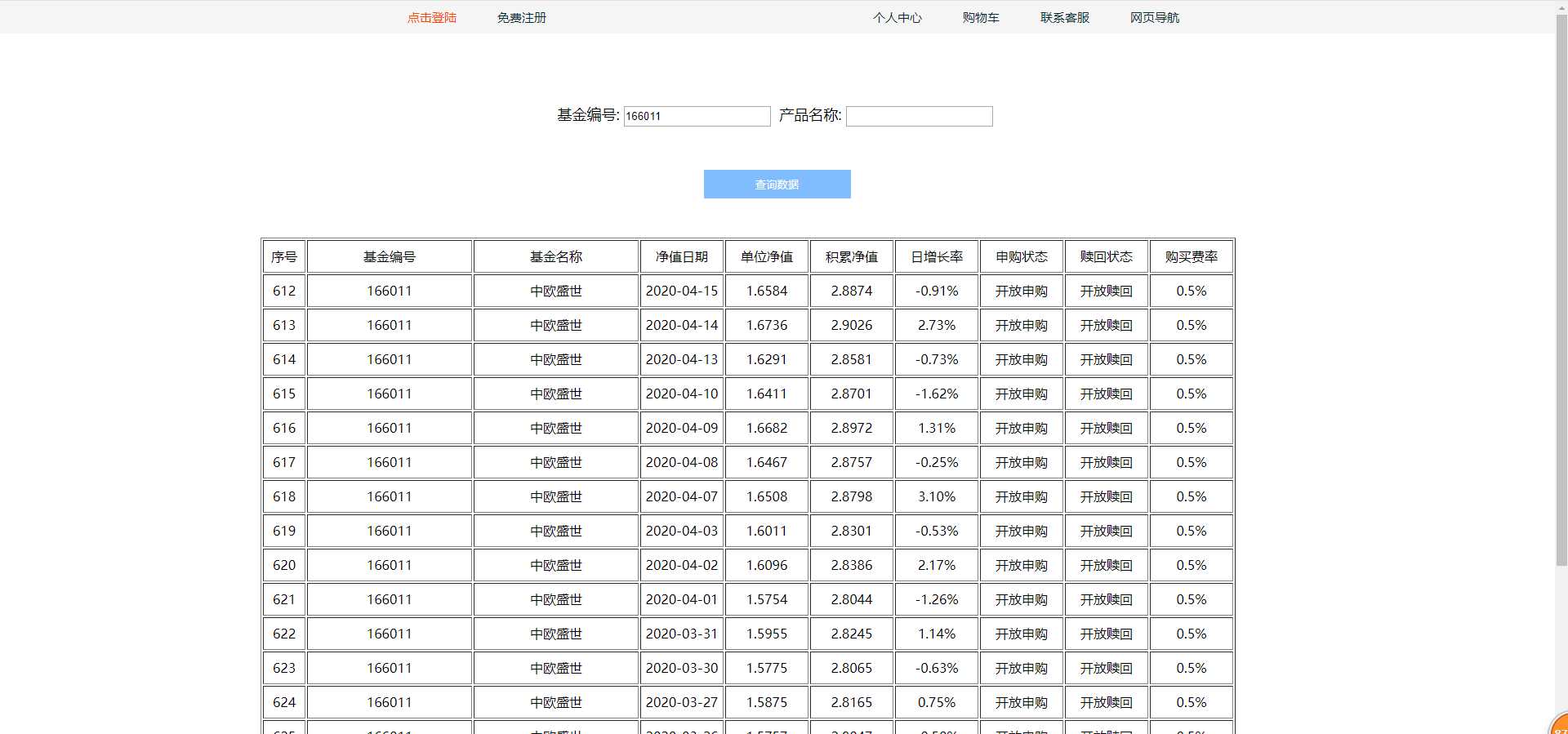
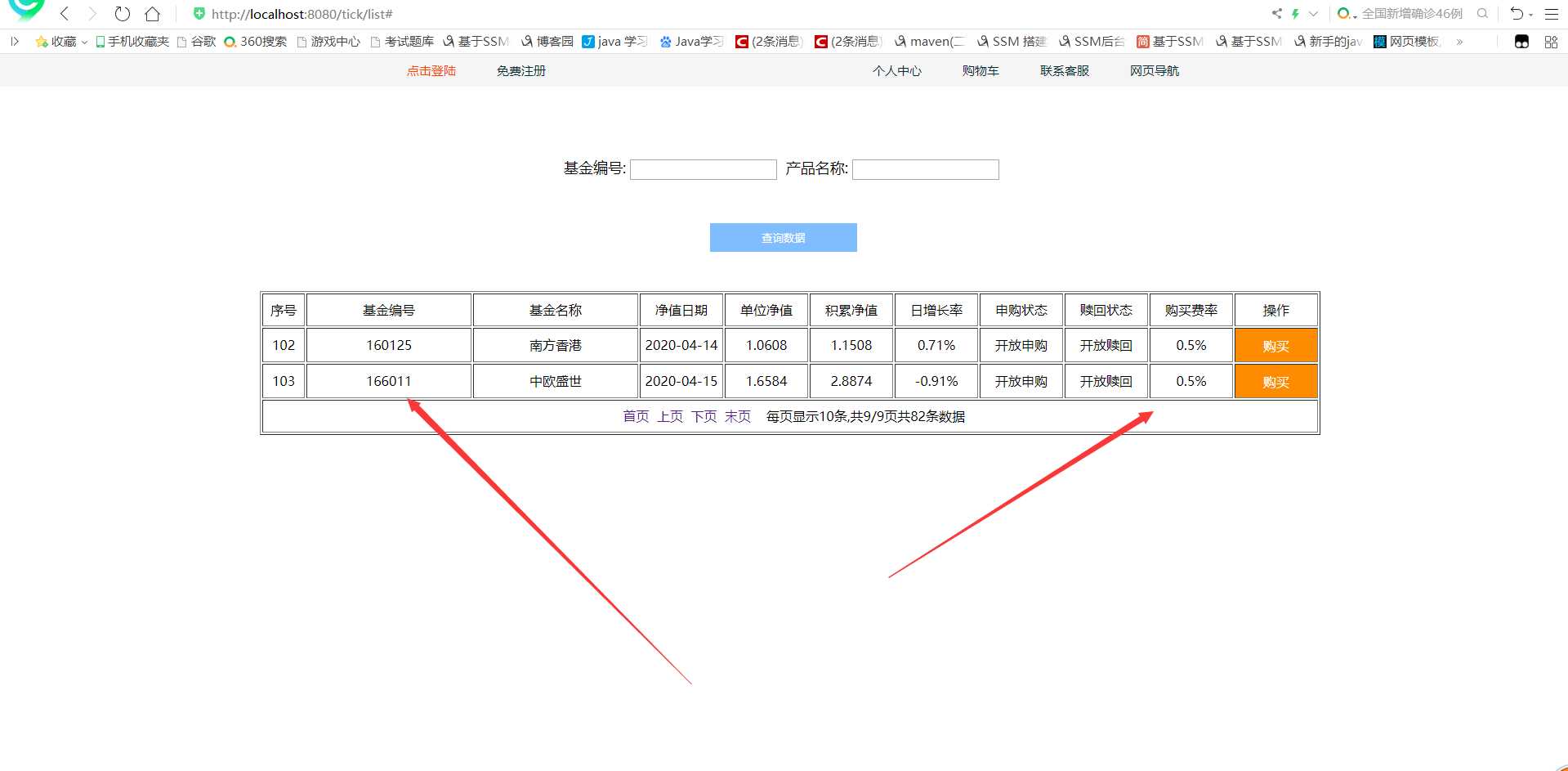
@注:本博客仅为个人学习笔记。 所属人:Yuan
/**
* httClient 请求 GET
* 获取基金网数据1
*/
public static JSONArray testDepartmentList1(String code){
Integer pageIndex = 1;
Integer pageSize=20;
String startTime="2018-1-1";
String endTime = "2020-4-15";
String referer = "http://fundf10.eastmoney.com/f10/jjjz_" + code + ".html";
long time = System.currentTimeMillis();
String url = "http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18306596328894644803_1571038362181&" +
"fundCode=%s&pageIndex=%s&pageSize=%s&startDate=%s&endDate=%s&_=%s";
url = String.format(url,code,pageIndex,pageSize,startTime,endTime,time);
System.out.println("url= " + url);
System.out.println(url);
HttpRequest request = HttpUtil.createGet(url);
request.header("Referer", referer);
String str = request.execute().body();
//获取str的长度
System.out.println("str=" + str);
int length = str.length();
System.out.println("length=" + length);
//indexOf返回某个指定的字符串值在字符串中首次出现的位置
int indexStart = str.indexOf("(");
System.out.println(indexStart);
//截取字符串
str = str.substring(indexStart + 9, length - 90);
System.out.println(str);
//转换为Obj类型
JSONObject jsonObject = JSON.parseObject(str);
System.out.println(jsonObject);
//获取数组
JSONArray jsonArray = jsonObject.getJSONArray("LSJZList");
//计算数组的长度
int size = jsonArray.size();
System.out.println(size);
return jsonArray;
}
以上是关于(Java)记一次通过API递归分页“爬取”网页数据的开发经历的主要内容,如果未能解决你的问题,请参考以下文章