用一杯星巴克的钱,训练自己私有化的ChatGPT
Posted 海豚调度
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用一杯星巴克的钱,训练自己私有化的ChatGPT相关的知识,希望对你有一定的参考价值。

文章摘要:用一杯星巴克的钱,自己动手2小时的时间,就可以拥有自己训练的开源大模型,并可以根据不同的训练数据方向加强各种不同的技能,医疗、编程、炒股、恋爱,让你的大模型更“懂”你…..来吧,一起尝试下开源DolphinScheduler加持训练的开源大模型!
导读
让人人都拥有自己的ChatGPT
ChatGPT的诞生无疑让我们为人工智能的未来充满期待,它以其精细的表达和强大的语言理解能力,震撼了全球。但是在使用ChatGPT的时候,因为它是SaaS,所以个人隐私泄露,企业数据安全问题是每一个人、每一个企业都担心的问题。而现在越来越多的开源大模型出现,让个人/企业拥有自己的大模型成为可能,但是,开源大模型上手、优化、使用要求门槛都比较高,很难让大家简单的使用起来。为此,我们借助Apache DolphinScheduler,一键式地支持了开源大模型训练、调优和部署,让大家可以在极低的成本和技术储备下,用自己的数据训练出专属于自己的大模型。当然,开源大模型的功力距离ChatGPT还有距离,但是经过测试我们看到7、8成的功力还是有的,而且这是可以根据你的场景和领域知识特殊训练过的,针对性更强。同时,我们坚信将来随着技术发展,开源大模型的能力会越来越强,让用户体验越来越好。来吧,我们准备开始。
面向人群——每一个屏幕面前的你
我们的目标是,不仅专业的AI工程师,更是任何对GPT有需求和兴趣的人,都能享受到拥有更“懂”自己的模型的乐趣。我们相信,每一个人都有权利和能力去塑造自己的AI助手,而Apache DolphinScheduler可见即所得的工作流程为此提供了可能。顺带介绍下Apache DolphinScheduler,这是一个Star超过1万个的大数据和AI的调度工具,它是Apache开源基金会旗下的顶级项目,这意味着你可以免费使用它,也可以直接修改代码而不用担心任何商业问题。
无论你是业界专家,寻求用专属于你的数据来训练模型,还是AI爱好者,想尝试理解并探索深度学习模型的训练,我们下面的这个工作流程都将为你提供便捷的服务。它为你解决了复杂的预处理、模型训练、优化等步骤,只需1-2个小时几个简单的操作,加上20小时的运行时间,就可以构建出更“懂”你的ChatGPT大模型:
https://weixin.qq.com/sph/AHo43o
那么,我们一起开启这个神奇的旅程吧!让我们把AI的未来带到每一个人的手中。
仅用三步,构造出更“懂”你的ChatGPT
- 用低成本租用一个拥有3090级别以上的GPU显卡
- 启动DolphinScheduler
- 在DolphinScheduler页面点击训练工作流和部署工作流,直接体验自己的ChatGPT吧
1. 准备一台3090显卡的主机
首先需要一个3090的显卡,如果你自己有台式机可以直接使用,如果没有,网上也有很多租用GPU的主机,这里我们以使用AutoDL为例来申请,打开 https://www.autodl.com/home,注册登录,后可以在算力市场选择对应的服务器,根据屏幕中的1,2,3步骤来申请:

这里,建议选择性价比较高的RTX3090,经过测试支持1-2个人在线使用3090就可以了。如果想训练速度和响应速度更快,可以选择更强的显卡,训练一次大约需要20小时左右,使用测试大概2-3个小时,预算40元就可以搞定了。
镜像
点击社区镜像,然后在下面红框出输入 WhaleOps/dolphinscheduler-llm/dolphinscheduler-llm-0521 之后,即可选择镜像,如下如所示,目前只有V1版本的,后面随着版本更新,有最新可以选择最新
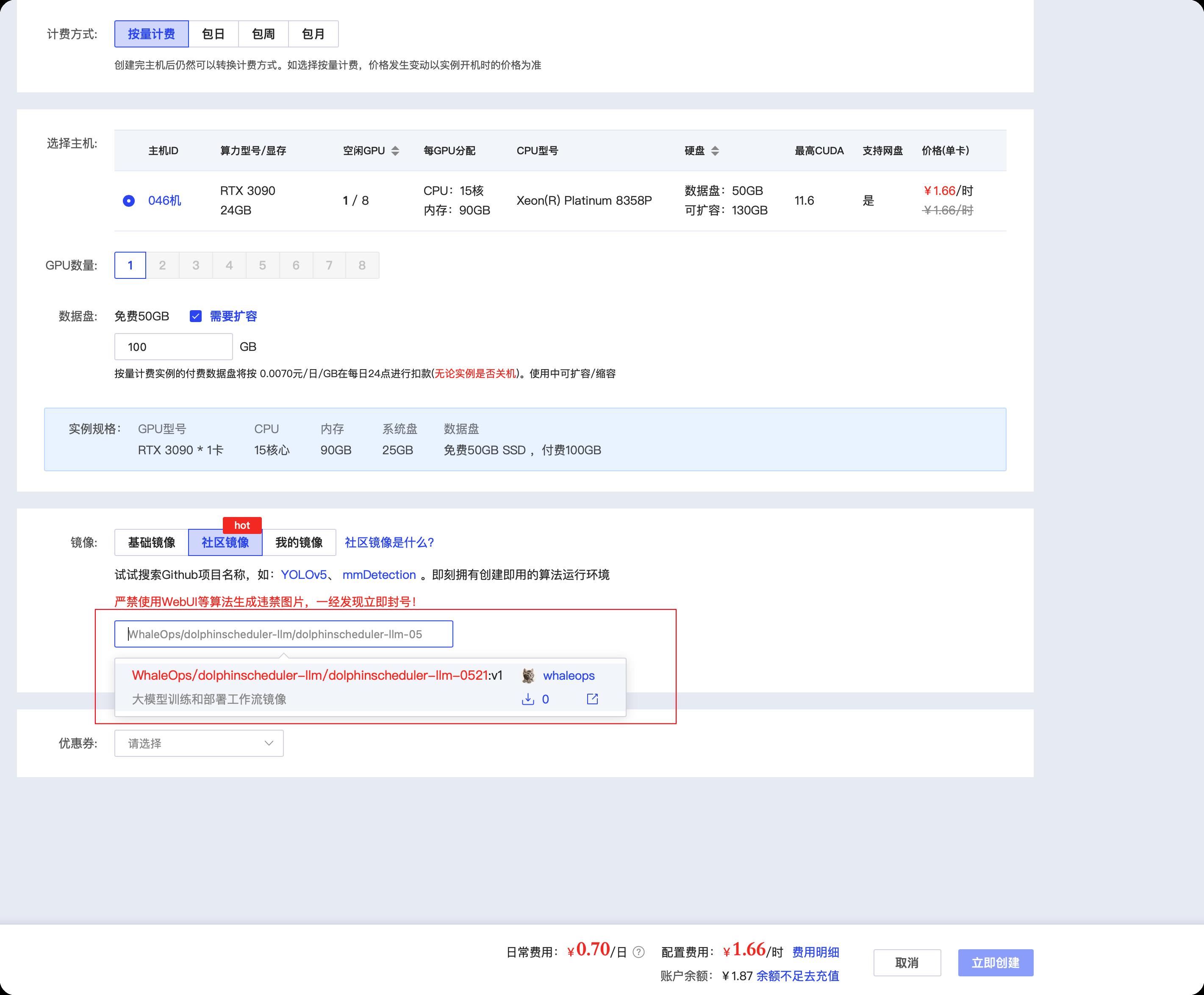
如果需要多次训练模型,建议硬盘扩容一下,建议100G即可。
创建后,等待下图所示的进度条创建完成即可。

2. 启动DolphinScheduler
为了可以在界面上部署调试自己的开源大模型,需要启动DolphinScheduler这个软件,我们要做以下配置工作:
进入服务器
进入服务器的方式有两种,可以按照自己的习惯进行:
通过JupyterLab页面登录(不懂代码的请进)
点击如下JupyterLab按钮
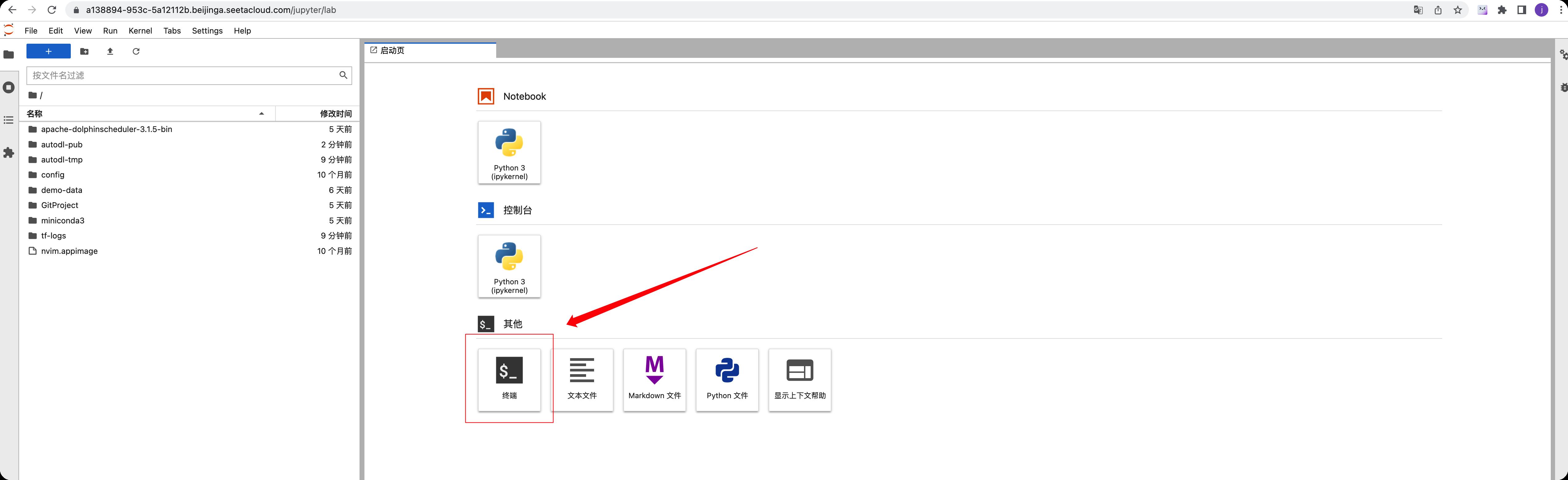
页面跳转到JupyterLab,后可以点击这里的终端进入
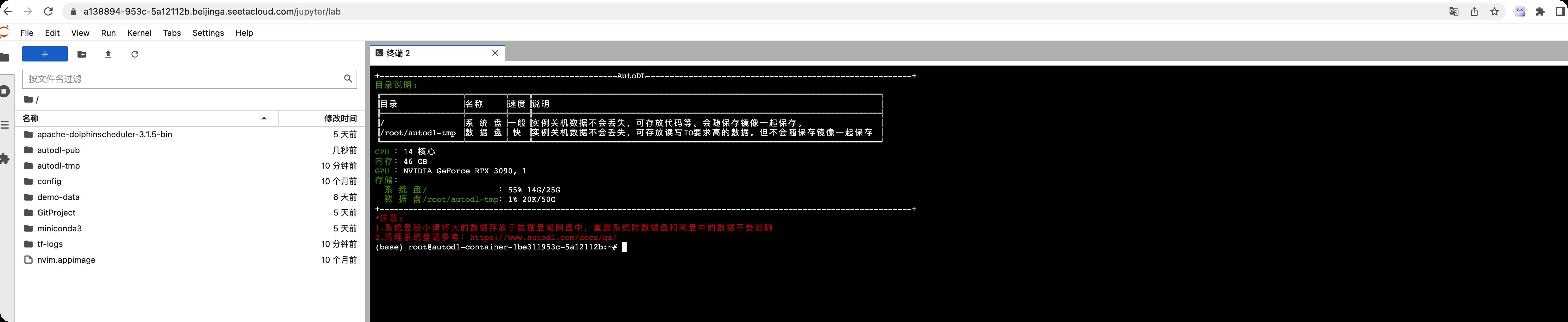
通过终端登录(懂代码的请进)
我们可以从下图这个按钮获取SSH连接命令

并通过终端链接
导入DolphinScheduler的元数据
在DolphinScheduler中,所有的元数据都存储在数据库中,包括工作流的定义,环境配置,租户等信息。为了方便大家在使用时能够启动DolphinScheduler时候就能够看到这些工作流,我们可以直接导入已经做好的工作流定义数据,照屏幕copy进去。
修改导入MySQL的数据的脚本
通过终端如下命令,进入到以下目录
cd apache-dolphinscheduler-3.1.5-bin
敲击命令,vim import_ds_metadata.sh 打开 import_ds_metadata.sh 文件
文件内容如下
#!/bin/bash
# 设置变量
# 主机名
HOST="xxx.xxx.xxx.x"
# 用户名
USERNAME="root"
# 密码
PASSWORD="xxxx"
# 端口
PORT=3306
# 导入到的数据库名
DATABASE="ds315_llm_test"
# SQL 文件名
SQL_FILE="ds315_llm.sql"
mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD -e "CREATE DATABASE $DATABASE;"
mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD $DATABASE < $SQL_FILE
把 xxx.xxx.xxx.x 和 xxxx 修改成你公网上一个mysql的一个数据库的数据(可以自己在阿里云、腾讯云申请或者自己安装一个),然后执行
bash import_ds_metadata.sh
执行后,如果有兴趣可在数据库中看到相应的元数据(可连接mysql查看,不懂代码的略过)。
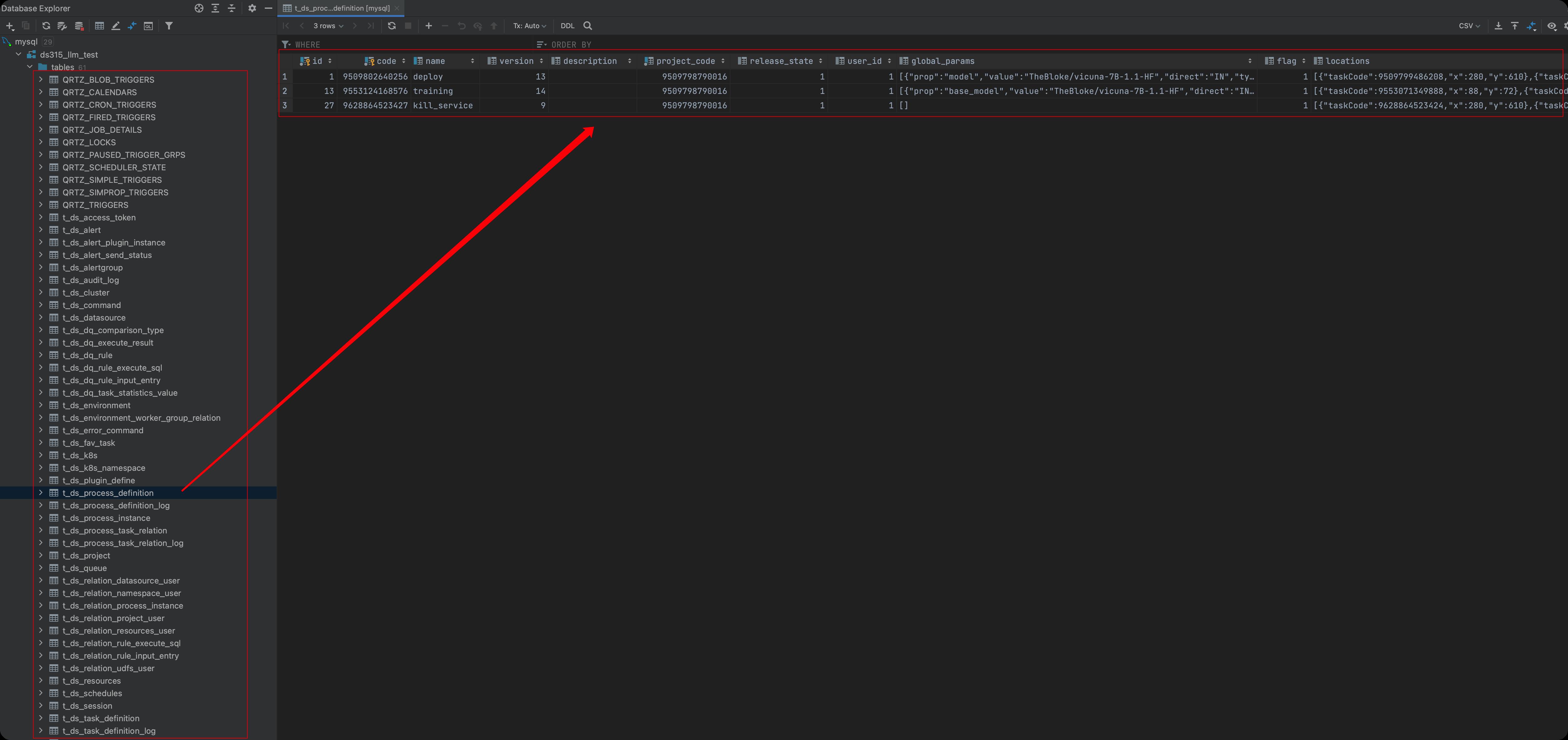
启动DolphinScheduler
在服务器命令行里,打开下面的文件,修改配置到DolphinScheduler连接刚才的数据库
/root/apache-dolphinscheduler-3.1.5-bin/bin/env/dolphinscheduler_env.sh
修改数据库部分的相关配置,其他部分不用修改,把’HOST’和’PASSWORD’的值改为刚才导入的数据库的相关配置值 xxx.xxx.xxx.x 和 xxxx:
......
export DATABASE=mysql
export SPRING_PROFILES_ACTIVE=$DATABASE
export SPRING_DATASOURCE_URL="jdbc:mysql://HOST:3306/ds315_llm_test?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="xxxxxx"
......
配置完成后执行(也在这个目录下 /root/apache-dolphinscheduler-3.1.5-bin )
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
执行完成后,我们可以通过 tail -200f standalone-server/logs/dolphinscheduler-standalone.log 查看日志,这时候,DolphinScheduler就正式启动了!
启动服务后,我们可以在AutoDL控制台中点击自定义服务(红框部分)会跳转到一个网址:
打开网址后发现是404,别着急,我们补充一下url的后缀 /dolphinscheduler/ui 即可

AutoDL模块开放一个6006的端口,我们将DolphinScheduler的端口配置成6006之后,可以通过上面的入口进入,但是因为跳转的url补全,所以404,因此我们补全URL即可
登录用户名密码
用户名: admin
密码: dolphinscheduler123
登录后点击 项目管理,即可看到我们预置的项目 vicuna,再次点击 vicuna后,我们即可进入该项目。

3. 开源大模型训练与部署
工作流定义
进入vicuna项目后,点击工作流定义,我们可以看到三个工作流,Training,Deploy,Kill_Service,下面解释下这几个功能的用途和内部选择大模型和训练你自己的数据的配置:

我们可以点击下面的运行按钮运行对应的工作流
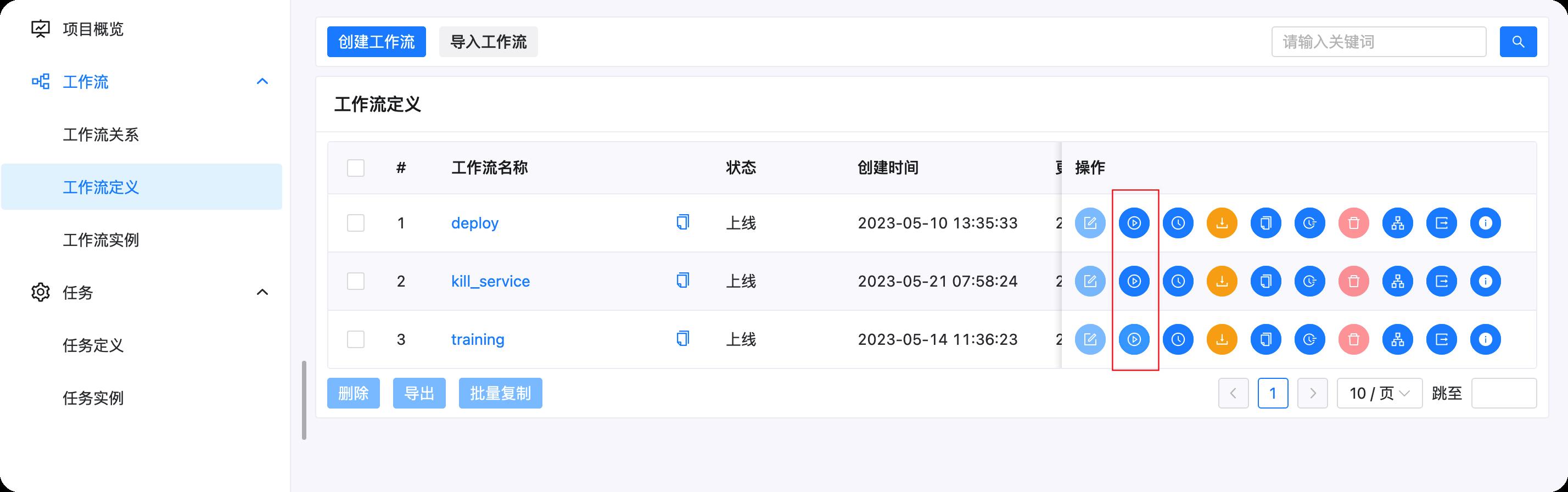
Training
点击后可以看到工作流的定义,包含两个,一个是通过lora finetune模型,一个是将训练出来的模型与基础模型进行合并,得到最终的模型。
具体的任务定义,可以双击对应的图标查看。

该工作流具有以下参数(点击运行后弹出)
- base_model: 基础模型,根据个人情况选择自行下载,注意开源大模型仅为学习和体验用途,目前默认为
TheBloke/vicuna-7B-1.1-HF - data_path: 你要训练的个性化数据和领域数据的路径,默认为
/root/demo-data/llama_data.json - lora_path: 训练出来的lora权重的保持路径
/root/autodl-tmp/vicuna-7b-lora-weight - output_path: 将基础模型和lora权重合并之后,最终模型的保存路径,记下来部署的时候需要用到
- num_epochs: 训练参数,训练的轮次,可以设为1用于测试,一般设为3~10即可
- cutoff_len: 文本最大长度,默认1024
- micro_batch_size: batch_size

Deploy
部署大模型的工作流,会先引用kill_service杀死已经部署的模型,在依次启动 controller,然后添加模型,然后打开gradio网页服务。

启动参数如下

- model: 模型路径,可以为huggingface的模型id,也可以为我们训练出来的模型地址,即上面training工作流的output_path。默认为
TheBloke/vicuna-7B-1.1-HF使用默认,将直接部署vicuna-7b的模型
Kill_service
这个工作流用于杀死已经部署的模型,释放显存,这个工作流没有参数,直接运行即可。
如果一些情况下,我们要停掉正在部署的服务(如要重新训练模型,显存不够时)我们可以直接执行kill_service工作流,杀死正在部署的服务。
看过经过几个实例,你的部署就完成了,下面我们实操一下:
大模型操作实例演示
训练大模型
启动工作流
可以直接执行training的工作流,选择默认参数即可
启动后,可以点击下图红框部分工作流实例,然后点击对应的工作流实例查看任务执行情况
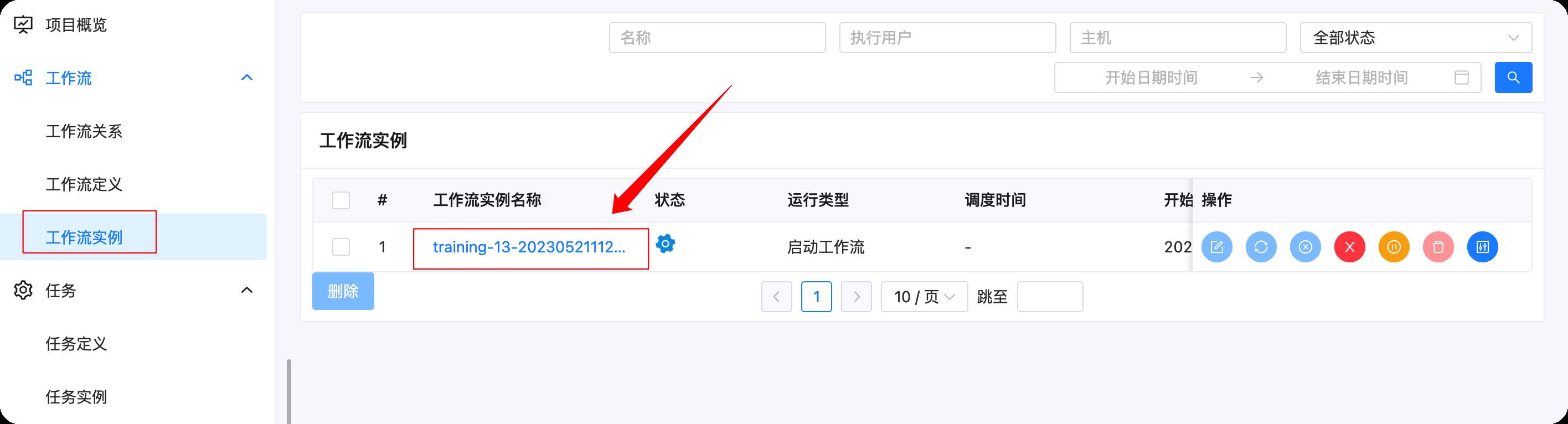
右键对应的任务,可以查看对应的日志,如下
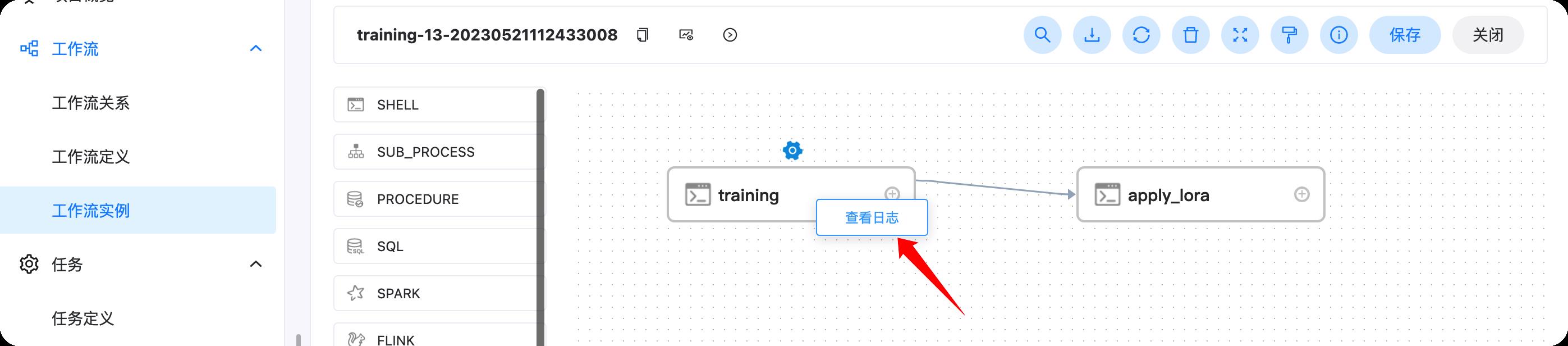
也可以在左边栏最下面的任务实例栏中,查看对应的任务状态和日志等信息
在训练过程中,也可以通过查看日志查看具体训练的进度(包括当前的训练步数,loss指标,剩余时间等),有个进度条一直显示目前在第几个step,step = 数据量 * epoch / batchsize

训练完成后日志如下


更新自己个性化训练数据
我们默认的数据是在 /root/demo-data/llama_data.json ,当前数据来源于下面华佗,一个使用中文医学数据finetune的医学模型,对,我们样例是训练一个家庭医生出来:

如果自己有特定领域的数据,可以指向自己的数据,数据格式如下
一行一个json,字段含义为
instruction****: 指令,为给模型指令input: 输入output: 期望模型的输出
如以下
"instruction": "计算算数题", "input": "1+1等于几", "output": "2"
温馨提示,可以将 instruction 和 input 合并为 instruction , input为空也可以。
按照格式制作数据,训练时修改data_path 参数执行自己的数据即可。
注意事项
第一次执行训练,会从你指定的位置拉取基础模型,例如TheBloke/vicuna-7B-1.1-HF ,会有下载的过程,稍等下载完成即可,这个模型下载是由用户指定的,你也可以任选下载其他的开源大模型(注意使用时遵守开源大模型的相关协议)。
因为网络问题,第一次执行Training的时候,有可能会下载基础模型到一半失败,这个时候可以点击重跑失败任务,即可重新继续训练,操作如下所示

如果要停止训练,可以点击停止按钮停止训练,会释放训练占用的显卡显存

部署工作流
在工作流定义页面,点击运行deploy工作流,如下如所示即可部署模型

如果自己没有训练出来的模型的话,也可以执行默认参数 TheBloke/vicuna-7B-1.1-HF,部署vicuna-7b的模型,如下图所示:

如果在上一步我们进行了模型训练,我们可以部署我们的模型了,部署之后就可以体验我们自己的大模型了,启动参数如下,填入上一步的模型的output_path即可
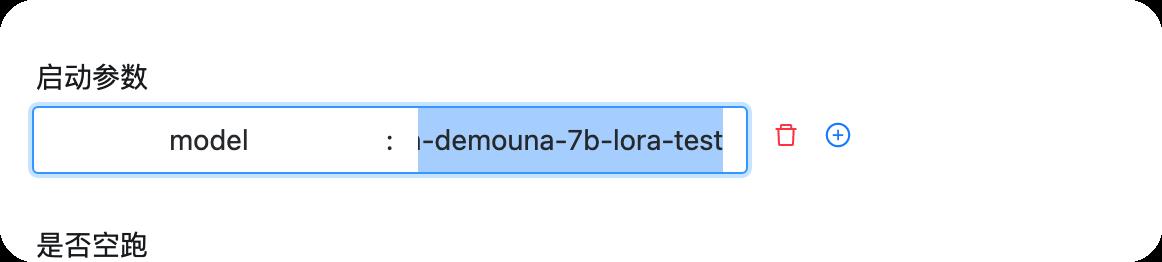
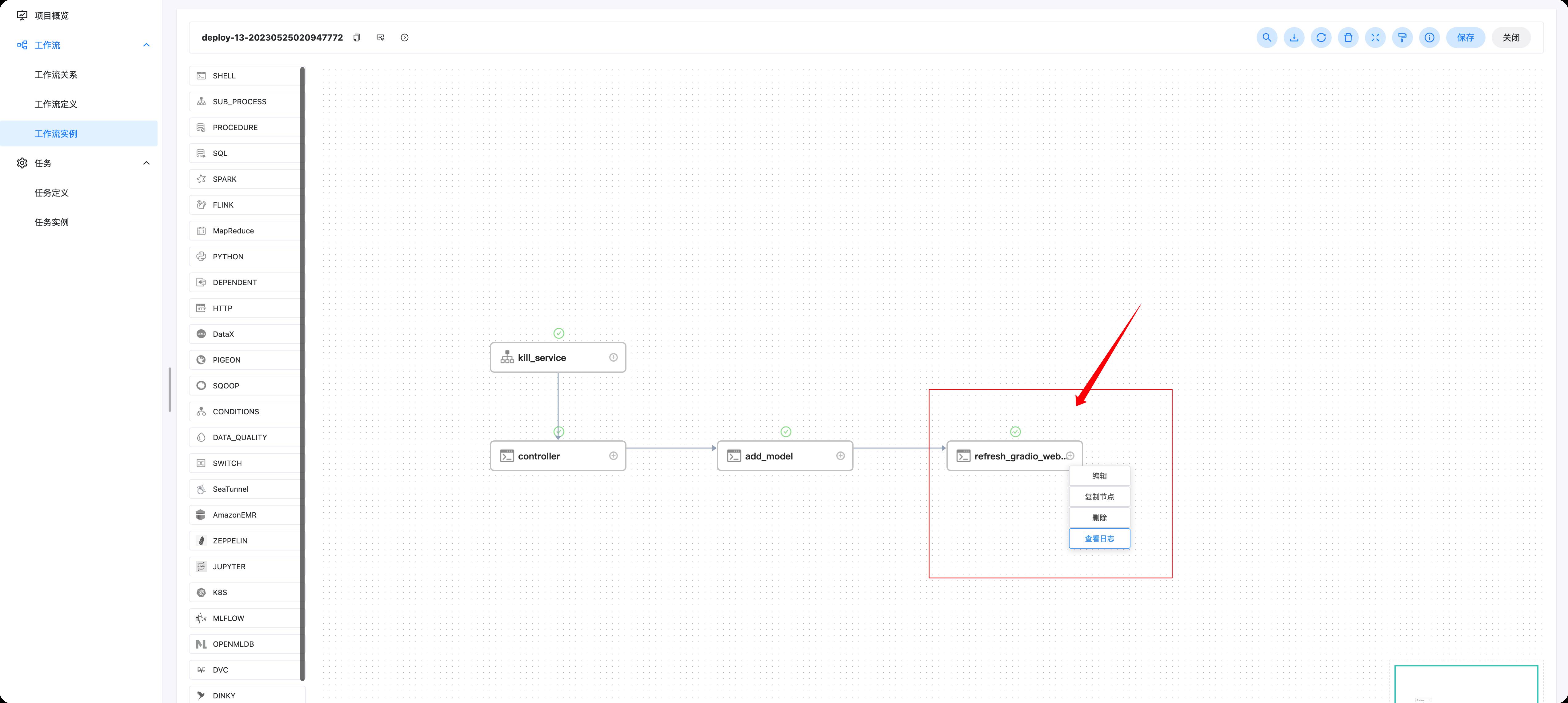
下面我们进入部署的工作流实例,如下图所示,先点击工作流实例,然后点击deploy前缀的工作流实例即可

右键点击refresh_gradio_web_service后可以查看任务日志,找到我们大模型链接的位置,操作如下
在日志的最后,我们可以看到一个链接,可以公网访问,如下
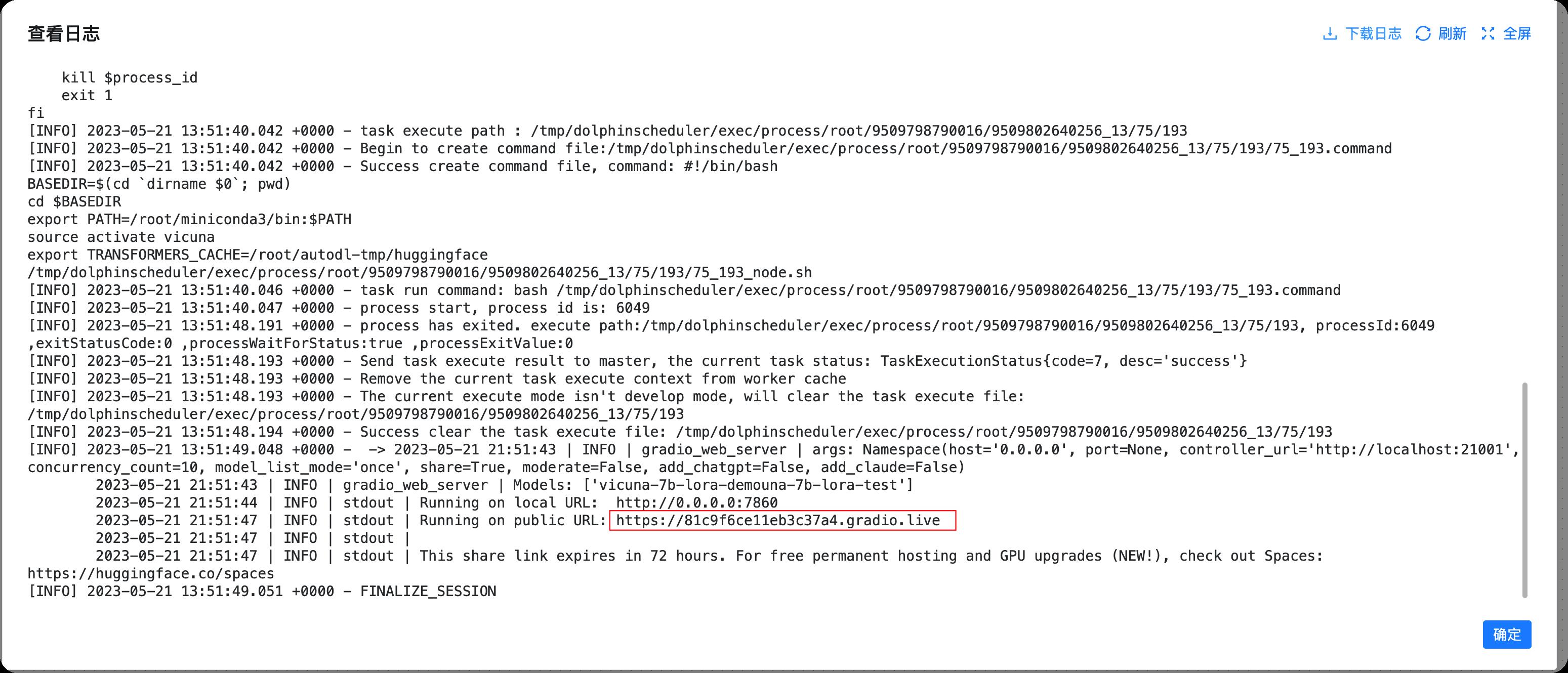
这里有两个链接,一个是0.0.0.0:7860 因为AutoDL只开放了6006端口,并且已经用于dolphinscheduler,所以我们暂时无法访问该接口,我们可以直接访问下面的链接
[https://81c9f6ce11eb3c37a4.gradio.live](https://81c9f6ce11eb3c37a4.gradio.live) 这个链接每次部署都会不一样,因此需要从日志找重新找链接。
进入后,即可看到我们的对话页面
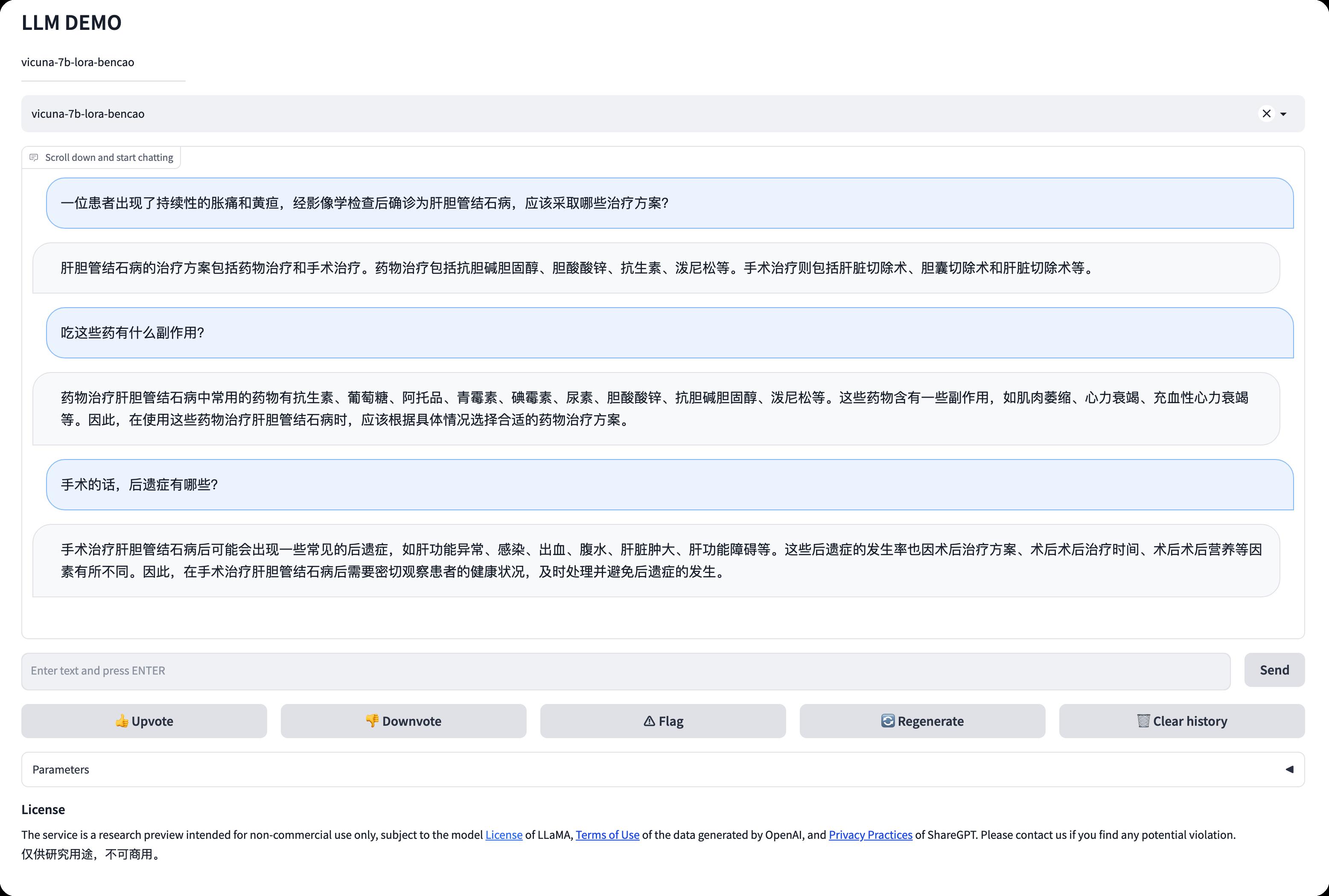
对!就这样你就拥有了你自己的ChatGPT了!而且它的数据仅服务于你自己!而且!你只花了不到一杯咖啡的钱哦~~
体验一下,你自己的私有化ChatGPT吧!
总结
在这个以数据和技术驱动的世界中,拥有一个专属的ChatGPT模型具有无法估量的价值。随着人工智能和深度学习的日益发展,我们正处在一个可塑造个性化AI助手的时代。而训练和部署属于自己的ChatGPT模型,可以帮助我们更好地理解AI,以及它如何改变我们的世界。
总的来说,自训练和部署ChatGPT模型可以帮助你更好地保护数据安全和隐私、满足特定的业务需求、节约技术成本,同时通过工作流工具如DolphinScheduler使训练过程自动化,并更好地遵守当地的法律法规。这都使得自训练和部署ChatGPT模型成为一个值得考虑的选择。
附注意事项:
数据安全与隐私
当你使用公共API服务使用ChatGPT时,你可能会对数据的安全性和隐私有所顾虑。这是一个合理的担忧,因为你的数据可能会在网络中被传播。通过自己训练和部署模型,你可以确保你的数据仅在你自己的设备或你租用的服务器上存储和处理,保障数据安全与隐私。
特定领域知识
对于具有特定业务需求的组织或个人来说,通过训练自己的ChatGPT模型,可以确保模型具有与业务相关的最新和最相关的知识。无论你的业务领域是什么,一个专门针对你的业务需求训练的模型都会比通用模型更有价值。
投入成本
使用OpenAI的ChatGPT模型可能会带来一定的费用,同时如果要自己训练和部署模型,也需要投入一定的资源和技术成本,40元就可以体验调试大模型,如果长期运行建议自己采购3090显卡,或者年租云端服务器。因此,你需要根据自己的具体情况,权衡利弊,选择最适合自己的方案。
DolphinScheduler
通过使用Apache DolphinScheduler的工作流,你可以使整个训练过程自动化,大大降低了技术门槛。即使你不具备深厚的算法知识,也可以依靠这样的工具,顺利地训练出自己的模型。支持大模型训练的同时,它也支持大数据调度、机器学习的调度,帮助你和你的企业非技术背景的员工简单上手的做好大数据处理、数据准备、模型训练和模型部署,而且,它是开源且免费的。
开源大模型法律法规约束
DolphinScheduler只是可视化AI工作流,本身不提供任何开源大模型。用户在使用下载开源大模型时,你需要注意自行选择不同的开源大模型使用约束条件,本文中的开源大模型所举的例子仅供个人学习体验使用,使用大模型时需要注意遵守开源大模型开源协议合规性。同时,不同国家都不同严格的数据存储和处理规定,在使用大模型时,你必须对模型进行定制和调整,以适应你所在地的具体法律法规和政策。这可能包括对模型输出的内容进行特定的过滤等,以满足当地的隐私和敏感信息处理规定。
本文由 白鲸开源 提供发布支持!
爬虫中的恋爱学心理你get了吗?一杯星巴克温暖你的整个冬天——爬虫bs4解析从入门到入坑

📢📢📢📣📣📣
🌻🌻🌻Hello,大家好我叫是Dream呀,一个有趣的Python博主,小白一枚,多多关照😜😜😜
🏅🏅🏅CSDN Python领域新星创作者,大二在读,欢迎大家找我合作学习
💕入门须知:这片乐园从不缺乏天才,努力才是你的最终入场券!🚀🚀🚀
💓最后,愿我们都能在看不到的地方闪闪发光,一起加油进步🍺🍺🍺
🍉🍉🍉“一万次悲伤,依然会有Dream,我一直在最温暖的地方等你”,唱的就是我!哈哈哈~🌈🌈🌈
🌟🌟🌟✨✨✨
前言:越来越发现学爬虫就像找女朋友一样,慢慢来,找到合适的机会才能拿下!让我们来先把爬虫拿下吧!
爬虫BeautifulSoup模块从入门到入坑
一、拿下她的必要准备
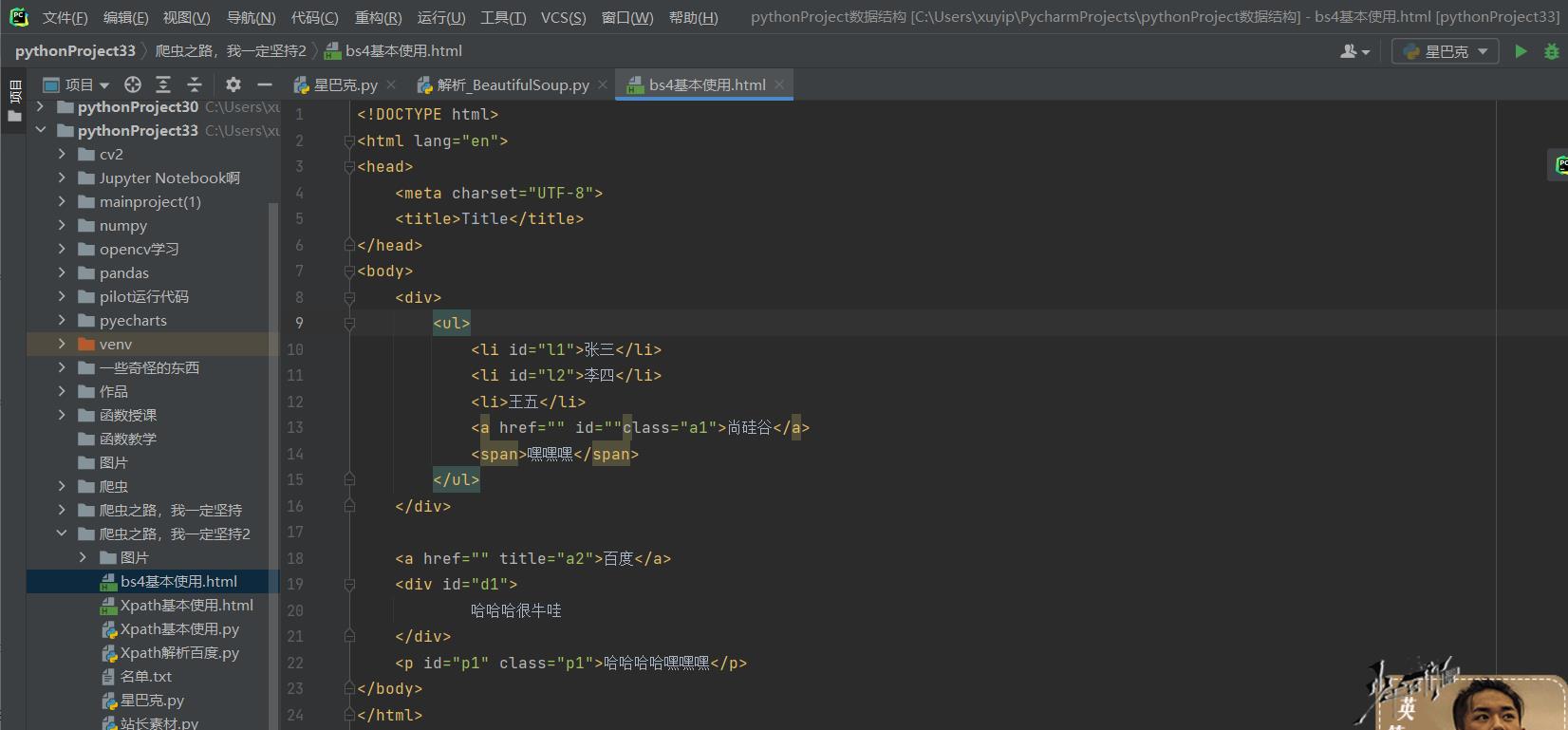
1.构建页面:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<a href="" id=""class="a1">尚硅谷</a>
<span>嘿嘿嘿</span>
</ul>
</div>
<a href="" title="a2">百度</a>
<div id="d1">
哈哈哈很牛哇
</div>
<p id="p1" class="p1">哈哈哈哈嘿嘿嘿</p>
</body>
</html>
2.知识储备:
# -*-coding:utf-8 -*-
# @Author:到点了,心疼徐哥哥
# 奥利给干!!!
from bs4 import BeautifulSoup
# 通过解析本地文件 来将bs4基础语法进行讲解
# 默认打开的文件的编码格式为gbk 打开文件时需要指定编码
soup = BeautifulSoup(open('bs4基本使用.html',encoding='utf-8'),'lxml')
# print(soup)
# 根据标签名查找节点
# 找到的是第一个符合条件的数据
# print(soup.a)
# 获取标签的属性和属性值
# print(soup.a.attrs)
# bs4的一些函数
# (1)find
# 返回的是第一个符合条件的数据
# print(soup.find('a'))
# 根据title的值来找到对应的
# print(soup.find('a',title="a2")) # <a href="" title="a2">百度</a>
# print(soup.find('a',class="a1")) # class是关键字,不能用。相当于古代皇帝叫这个名字,你不能用
# 根据class的值来找到对应的标签对象,注意的是class需要添加下划线
# print(soup.find('a',class_="a1")) # <a class="a1" href="" id="">尚硅谷</a>
# (2)find_all # 返回的是一个列表,并且返回所有的a标签
# print(soup.find_all('a'))# [<a class="a1" href="" id="">尚硅谷</a>, <a href="" title="a2">百度</a>]
# 如果想要获取的是多个标签的数据,那么需要在find_all的参数中添加的是列表的数据。
# print(soup.find_all(['a','span'])) # [<a class="a1" href="" id="">尚硅谷</a>, <span>嘿嘿嘿</span>, <a href="" title="a2">百度</a>]
# limit查找前几个数据
# print(soup.find_all('li',limit=2)) # [<li>张三</li>, <li>李四</li>]
# (3)select(推荐)
# select方法返回列表和多个数据
# print(soup.select('a')) # [<a class="a1" href="" id="">尚硅谷</a>, <a href="" title="a2">百度</a>]
# 可以通过.代表class 我们把这种操作叫做类选择器
# print(soup.select('.a1')) # [<a class="a1" href="" id="">尚硅谷</a>]
# print(soup.select('#l1')) # [<li id="l1">张三</li>]
# 属性选择器
# 查找li标签中有id的标签
# print(soup.select('li[id]')) # [<li id="l1">张三</li>, <li id="l2">李四</li>]
# 查找到li标签中id为l2的标签
# print(soup.select('li[id="l2"]')) # [<li id="l2">李四</li>]
# 层级选择器
# 后代选择器
# 找到的是div下面的li
# print(soup.select('div li')) # [<li id="l1">张三</li>, <li id="l2">李四</li>, <li>王五</li>]
# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中。如果不加空格不会输出内容 但是bs4中 不会报错 会显示内容
# print(soup.select('div > ul > li')) # [<li id="l1">张三</li>, <li id="l2">李四</li>, <li>王五</li>]
# 找到a标签和li标签
# print(soup.select('a,li')) # [<li id="l1">张三</li>, <li id="l2">李四</li>, <li>王五</li>, <a class="a1" href="" id="">尚硅谷</a>, <a href="" title="a2">百度</a>]
# 节点信息
# 获取节点内容
# obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
# print(obj.string)
# print(obj.get_text())
# 节点属性
# obj = soup.select('#p1')[0]
# name是标签的名字
# print(obj.name)
# 将属性值作为一个字典返回
# print(obj.attrs)
# 获取节点的属性
obj = soup.select('#p1')[0]
print(obj.attrs.get('class'))
二、冬天的第一杯星巴克送给你!
1.开启寻她之路
首先,进入星巴克官网:星巴克,然后进入主页的菜单界面,找到星巴克的一些种类!
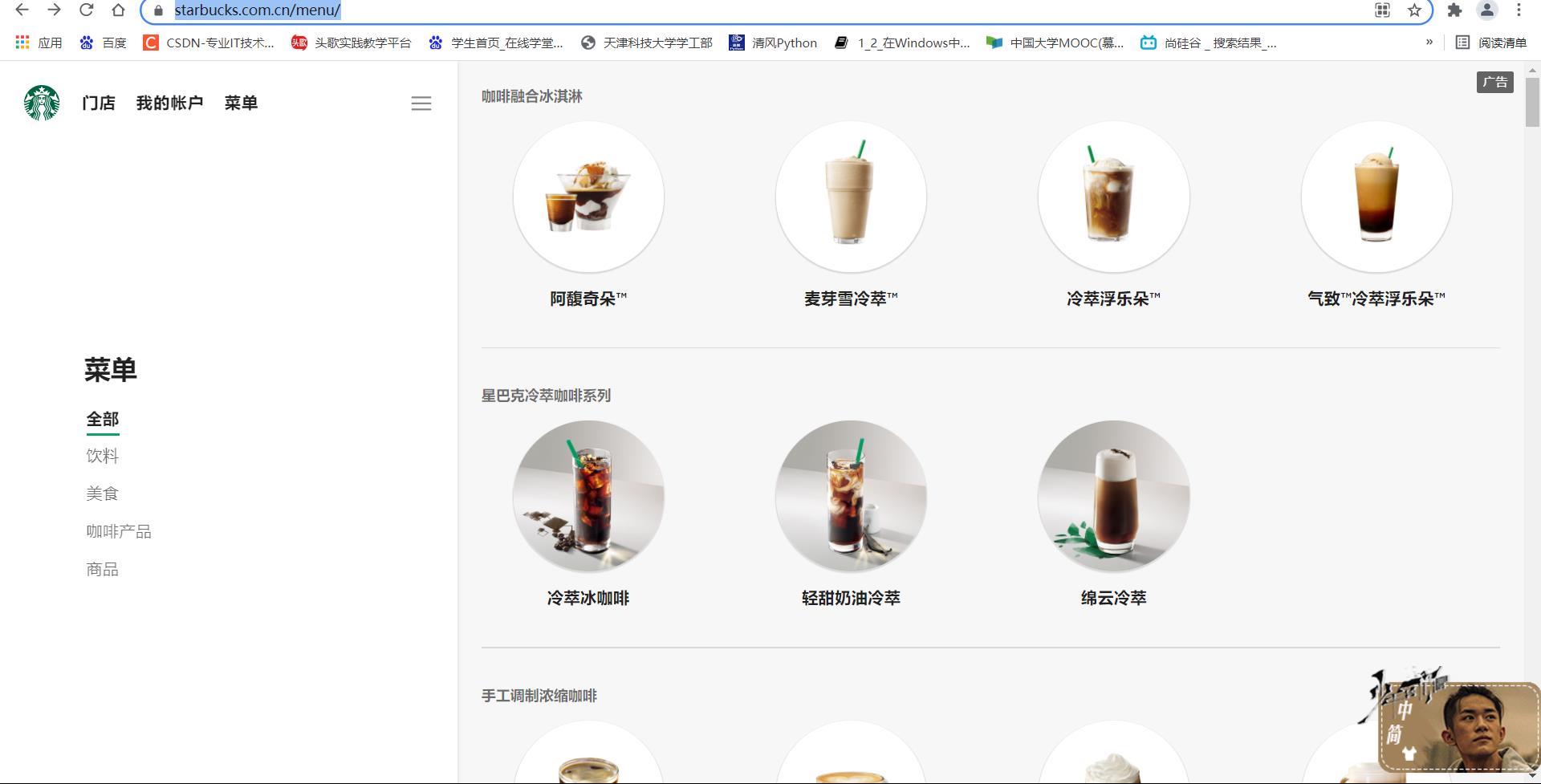
2.找到我喜欢的那个她
单击右键进行检查然后刷新界面:

在解析的网络模块数据中,我们看到了menu这个东西,我深深地被她吸引了,所以说我打算试一试,看看到底是啥吸引了我!
在她的预览中心,我们可以看到,有很多不同种类的咖啡:
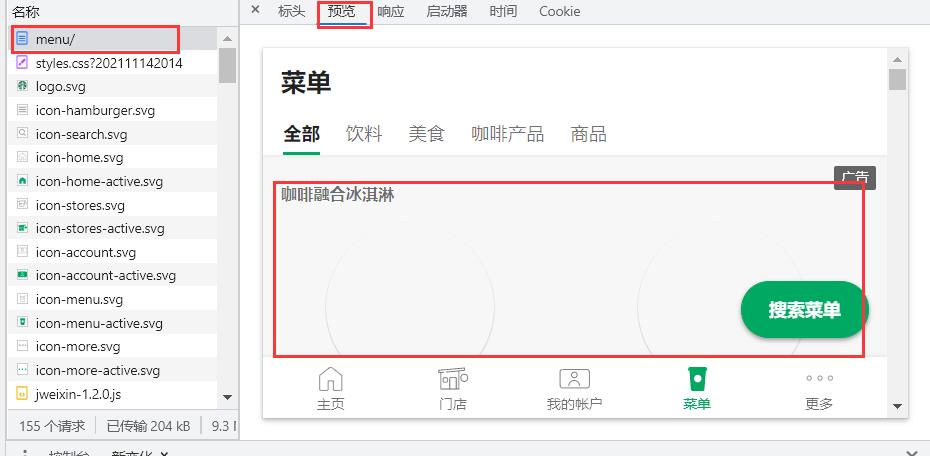
然后在标头中找到我们需要的接口,来对她进行更深一步的了解:

3.更加深入的了解她的内心
1.尝试直接进入,看看她是否对我有防备
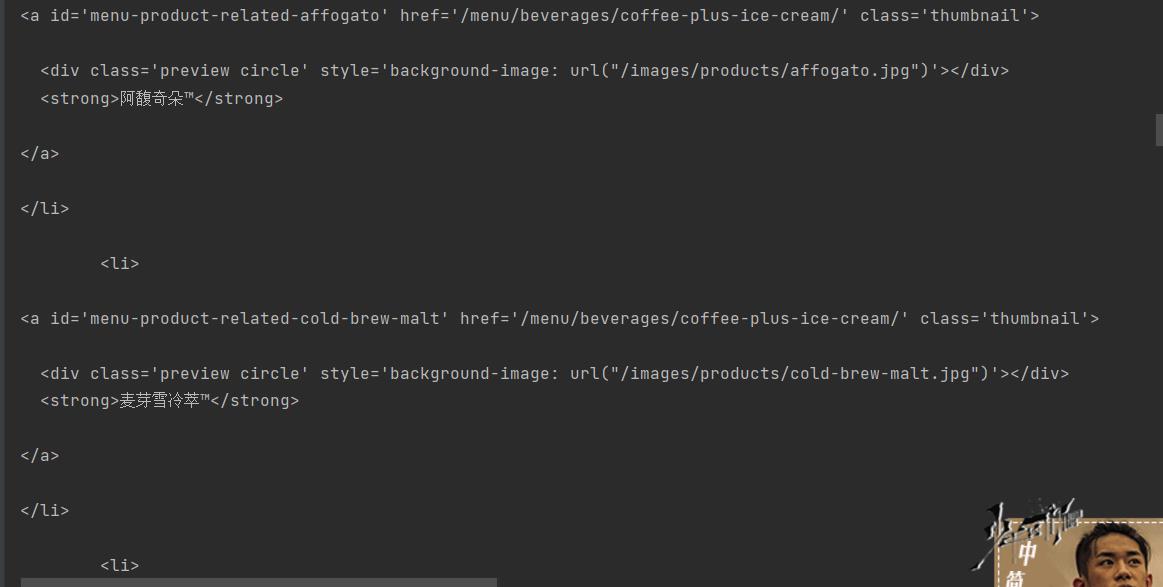
通过给定的接口直接进入:
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)
得到我们的数据:
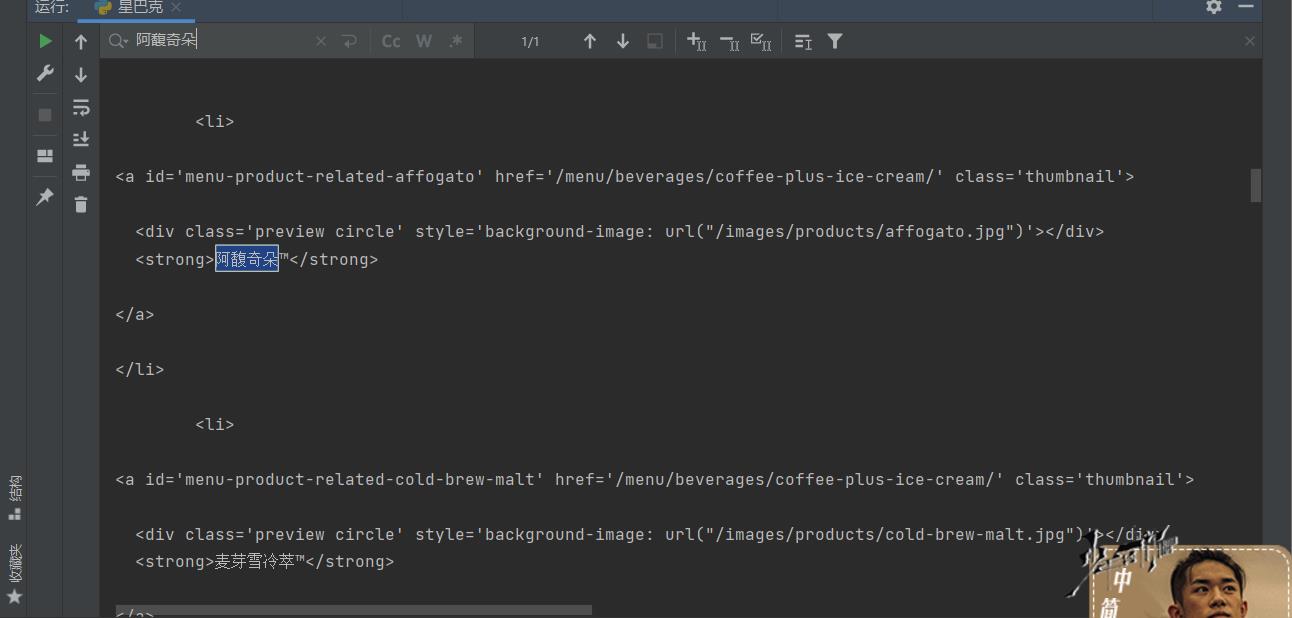
点击ctrl+F搜索一下之前页面上的第一杯奶茶:阿馥奇朵看看有没有:
我们可以看到找到了!
2.更加一步解析她的内心
对她大概有了一个了解之后,我们要深入到她的各个品性中去,我们她的每一个品性进行深入了解!
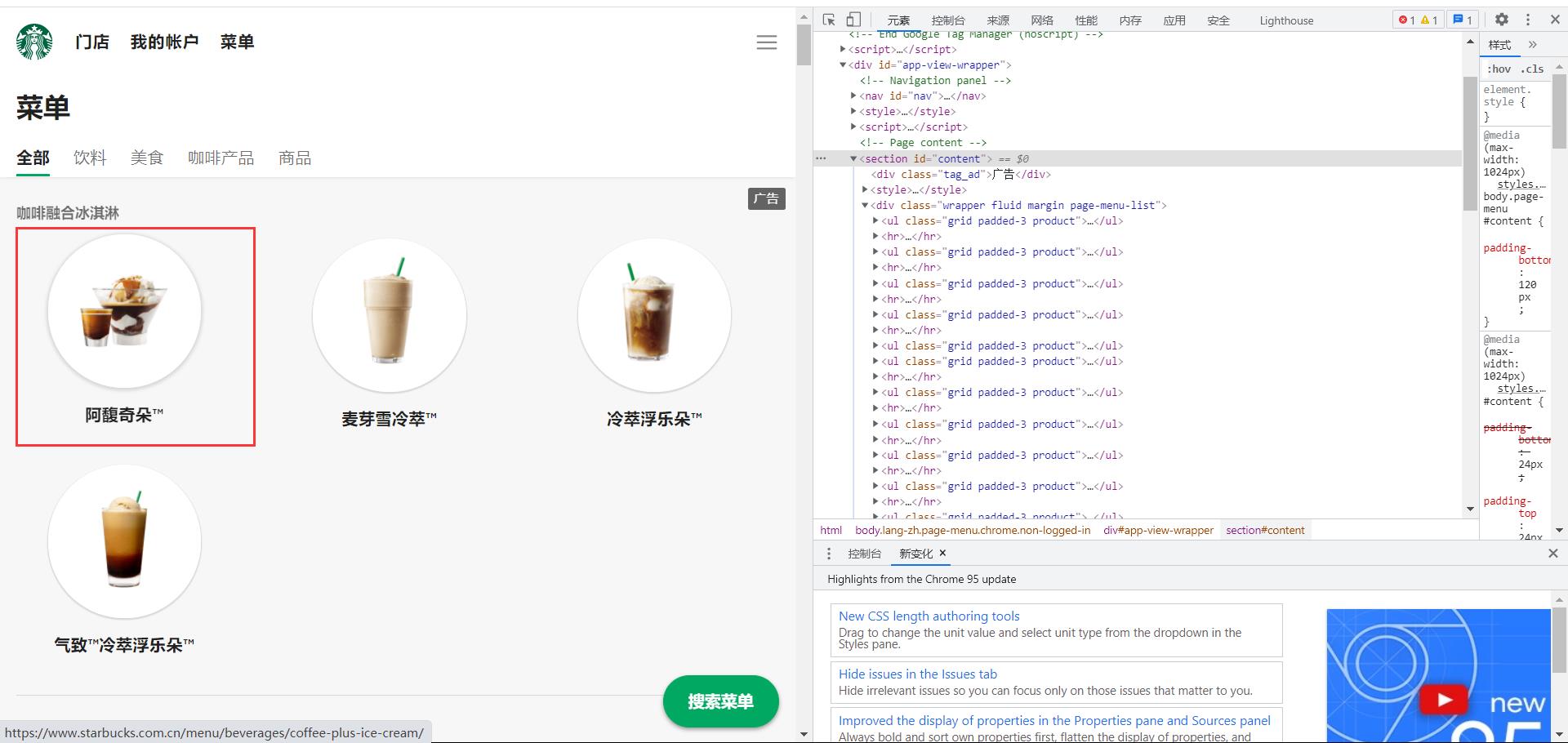
进一步分析,我们可以获取各类咖啡的不同解析位置:

这些标签里面的的小标签分别代表不同类型咖啡里面的不同名称。
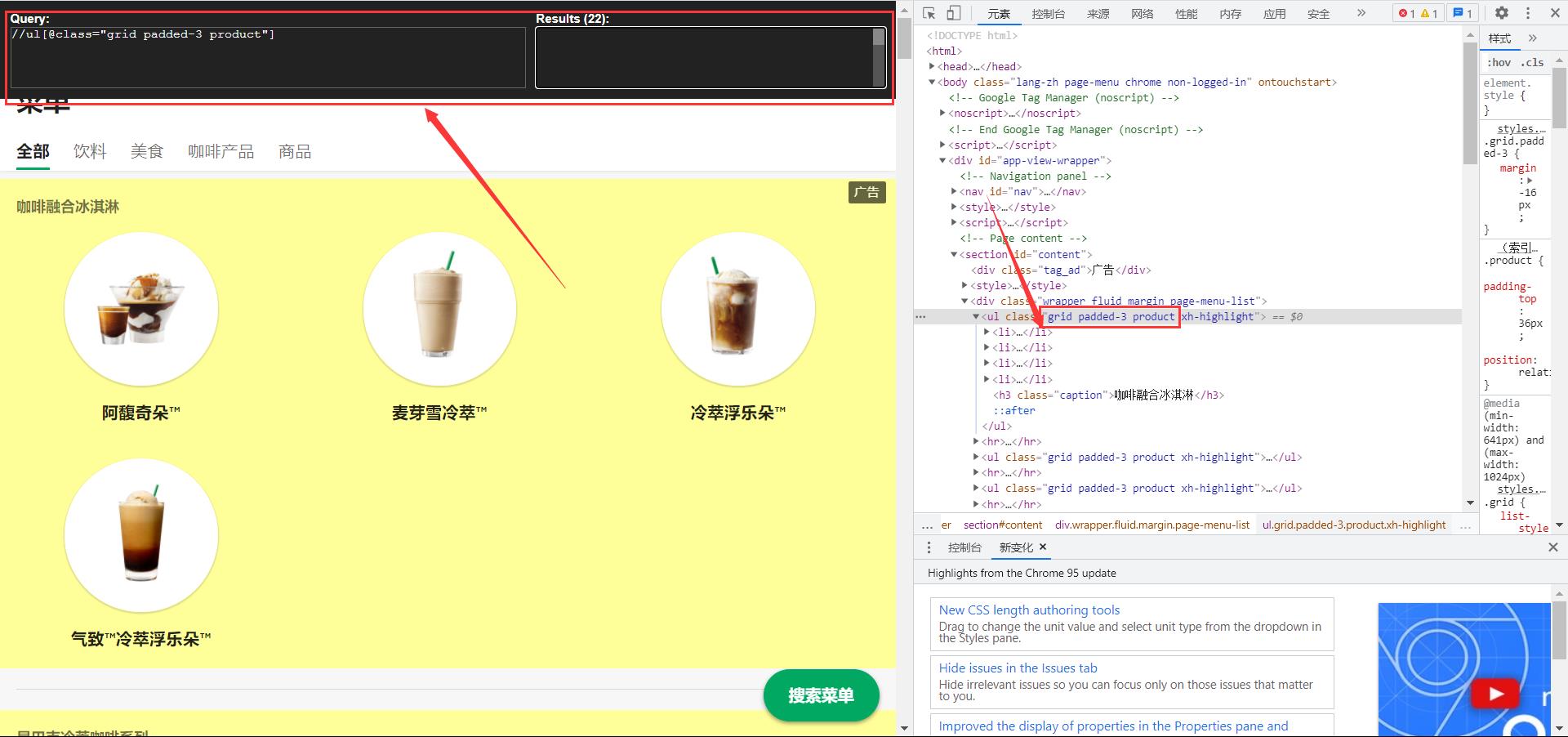
进一步使用我的Xpath获取数据具体内容:
xpath不懂的同学自觉看:❤️1024不孤单!❤️Xpath爬虫——你最忠实的伴侣:老规矩给我一分钟,万字教你入手Xpath!⚡
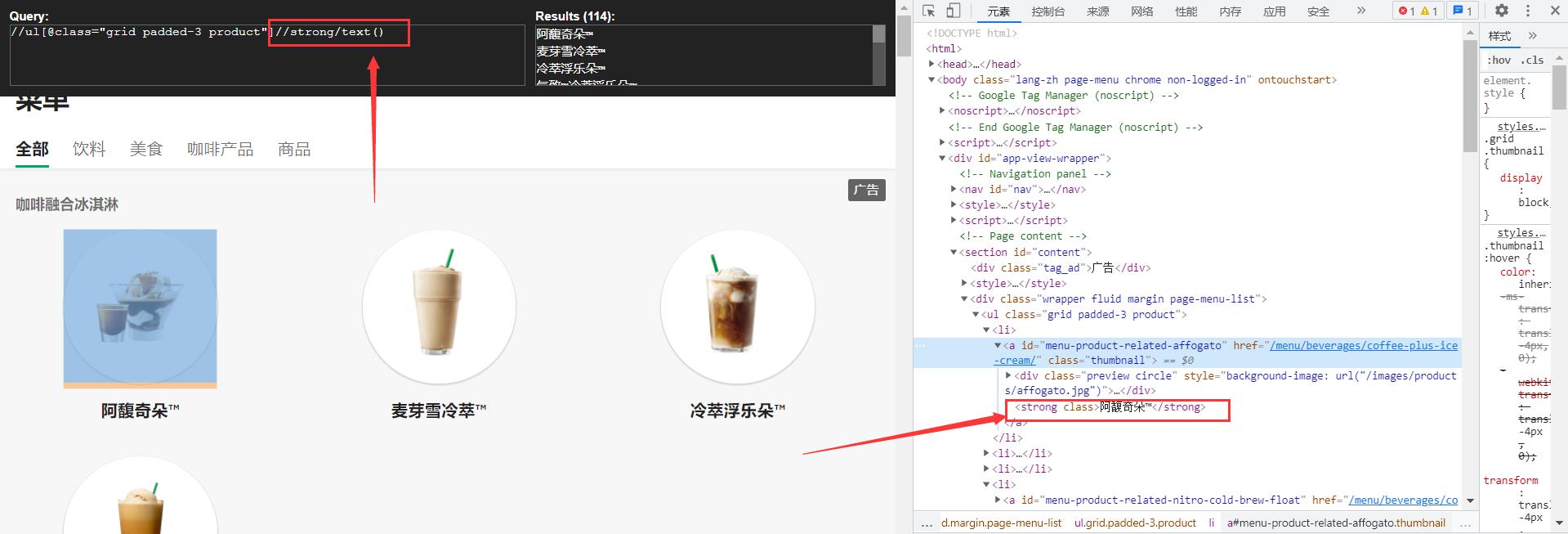
获取具体内容:
4.初步打开心扉
按照我们刚才的步骤,使用bs4整理一下我们的思路代码:
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
# print(content)
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
name_list = soup.select('ul[class="grid padded-3 product"] strong')
print(name_list)
得到:
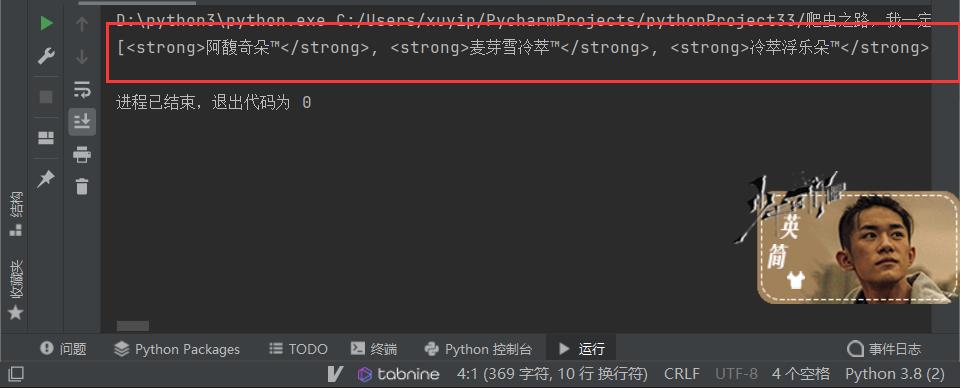
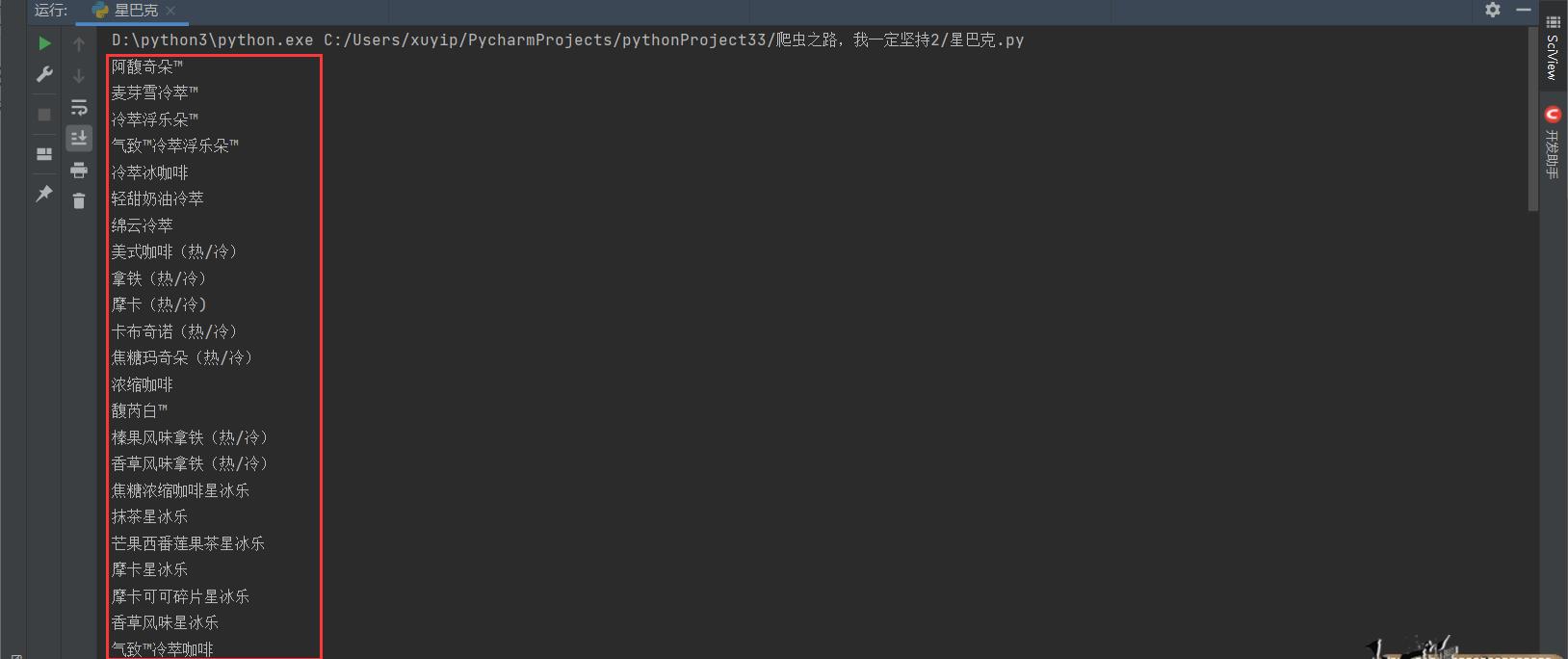
5.分析完毕,直接拿下!!!
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
# print(content)
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
name_list = soup.select('ul[class="grid padded-3 product"] strong')
# print(name_list)
for name in name_list:
print(name.string)
获取其中的字符串:
for name in name_list:
print(name.string)
# 或者
print(name.get_text())
❤️往期文章推荐❤️:
还看不懂Python OpenCV?不,我不允许!隔壁大爷都说看得懂!❤️环境配置+问题分析+视频图像入门❤️万字只为你~
Python OpenCV实战画图——这次一定能行!爆肝万字,建议点赞收藏~❤️❤️❤️
❤️大家中秋节快乐❤️接下来请欣赏Python Opencv实战之图像阈值和模糊处理,万字实战,收藏起来吧~
Python OpenCV ❤️超级有趣❤️ 颜色转换 + 几何变换,一网打尽⚡⚡⚡~
Python OpenCV图像处理:❤️转换+梯度❤️边缘检测+图像融合,aplacian金字塔合成新物种
🌲🌲🌲 好啦,这就是今天要分享给大家的全部内容了
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了~

以上是关于用一杯星巴克的钱,训练自己私有化的ChatGPT的主要内容,如果未能解决你的问题,请参考以下文章