Python 基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控
Posted 授客的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控相关的知识,希望对你有一定的参考价值。
基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控
By: 授客 QQ:1033553122
1.测试环境
python 3.4
zookeeper-3.4.13.tar.gz
下载地址1:
http://zookeeper.apache.org/releases.html#download
https://www.apache.org/dyn/closer.cgi/zookeeper/
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
下载地址2:
https://pan.baidu.com/s/1dnBgHvySE9pVRZXJVmezyQ
kafka_2.12-2.1.0.tgz
下载地址1:
http://kafka.apache.org/downloads.html
下载地址2:
https://pan.baidu.com/s/1VnHkJgy4iQ73j5rLbEL0jw
pykafka-2.8.0.tar.gz
下载地址1:
https://pypi.org/project/pykafka/
2.实现功能
实时采集Kafka生产者主题生产速率,主题消费速率,主题分区偏移,消费组消费速率,支持同时对多个来自不同集群的主题进行实时采集,支持同时对多个消费组实时采集
3.使用前提
1、“主题消费速率”&“消费组消费速率” 统计 依赖“消费组”,所以要统计消费速率,必须存在消费组才能统计;
2、“主题消费速率”&“消费组消费速率” 统计 依赖消费者自动、手动提交“offset”,所以所以要统计消费速率,必须确保消费者消费时,会提交消息的offset
3、Kafka版本大于等于0.10.1.1
4.使用方法
influxDB主机配置
KafkaMonitor\\conf\\influxDB.conf
[INFLUXDB]
influxdb_host = 10.203.25.106
influxdb_port = 8086
brokers集群配置
KafkaMonitor\\conf\\brokers.conf
[CLUSTER1]
broker1 = 127.0.0.1:9092
[bus]
#broker1 =10.202.xxx.xx:9096,10.202.xx.xx:9096,10.202.xxx.x:9096
格式说明:
[集群名称]
自定义brokers标识 = broker ip:port配置(如果有多个broker,用英文逗号分隔)
如果不想对指定集群进行监控(不监控该集群的主题生产、消费速率,主题分区偏移,消费组消费速率),用 # 号注释掉 该集群的“自定义brokers标识” 所在行即可,如上
topics主题配置
KafkaMonitor\\conf\\brokers.conf
[CLUSTER1]
topic1 = MY_TOPIC1
[bus]
topic1=NEXT_MARM_CORE_REPORT
#topic2=NEXT_MARM_CORE_EVENT
格式说明:
[集群名称]
自定义topic 标识 = topic名称
如果不想对指定主题进行监控(不监控该主题的生产、消费速率,主题分区偏移,该主题相关消费组消费速率),用 # 号注释掉 该集群的“自定义 topic标识” 所在行即可,如上
注意:每个集群名称下的 自定义 topic 标识不能重复
consumer_groups消费组配置
KafkaMonitor\\conf\\consumer_groups.conf
[CLUSTER1]
groupID1 = MY_TOPIC1|MY_GROUP1:5000
[bus]
#groupID1=NEXT_MARM_CORE_EVENT|NEXT_MARM_CORE_TASK
groupID2=NEXT_MARM_CORE_REPORT|NEXT_MARM_CORE_REPORT,NEXT_MARM_CORE_REPORTTAG
格式说明:
[集群名称]
自定义consumer_groups 标识 = 主题名称|消费该主题的消费组名称[:提交msg offset的时间间隔(单位为 毫秒)](如果有多个消费组,彼此之间用逗号分隔)
注意:
1、如果有为消费组设置提交msg offset的时间间隔,并且该时间间隔大于统一设置的数据采集频率,那么该消费组的数据采集频率将自动调整为对应的 提交msg offset的时间间隔/1000 + 1
2、主题消费速率的统计依赖消费该主题的所有消费组的数据信息,所以,同一个主题,不要配置在多个“自定义consumer_groups 标识”配置值中
3、主题消费速率数据采集频率取最大值 max(统一设置的数据采集频率,max(消费该主题的消费组提交msg offset的时间间隔/1000 + 1))
如果不想对指定消费组进行监控(不监控该消费组消费速率,消费组关联的主题消费速率),用 # 号注释掉 该集群的“自定义consumer_groups 标识” 所在行即可,如上,,或者把对应消费组及其提交msg offset的时间间隔信息删除即可。
运行程序
python main.py 采集频率(单位 秒) 采集时长
eg:
每5秒采集一次,总共采集120秒
python main.py 5 120
注意:
如果(根据配置自动调整后的)采集频率时间间隔大于单次程序采样耗时,则处理完成后立即进行下一次采样,忽略采样频率设置,实际采集时长变长,但是采集次数不变 int(采集时长/采样频率)
grafana图表配置
数据源配置

说明:Database db_+brokers.conf中配置的集群名称
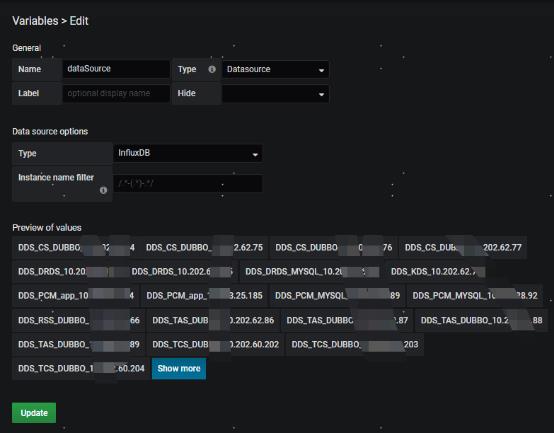
Dashboard变量配置


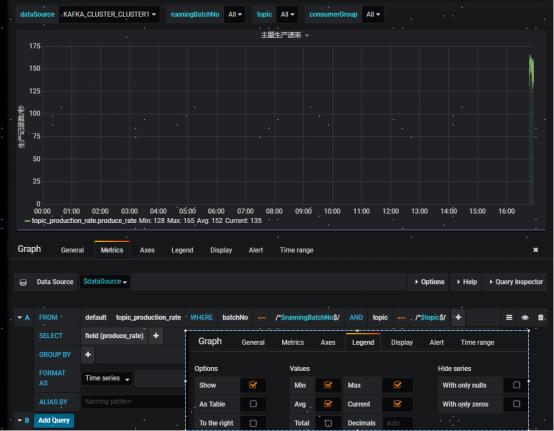
Dashboard Pannel主要配置项
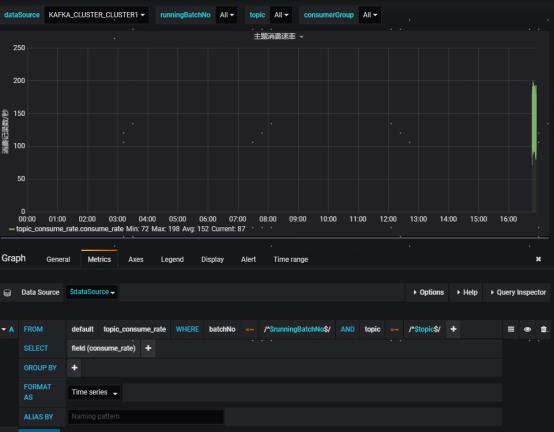



效果展示

参考链接:
https://pykafka.readthedocs.io/en/latest/index.html
源码下载地址:
https://gitee.com/ishouke/KafkaMonitor
以上是关于Python 基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控的主要内容,如果未能解决你的问题,请参考以下文章