python爬虫之处理验证码
Posted Distance
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之处理验证码相关的知识,希望对你有一定的参考价值。
云打码实现处理验证码
处理验证码,我们需要借助第三方平台来帮我们处理,个人认为云打码处理验证码的准确度还是可以的
首先第一步,我们得先注册一个云打码的账号,普通用户和开发者用户都需要注册一下
然后登陆普通用户,登陆之后的界面是这样的,

你需要有几分才可以使用它.
第二步登陆开发者用户:
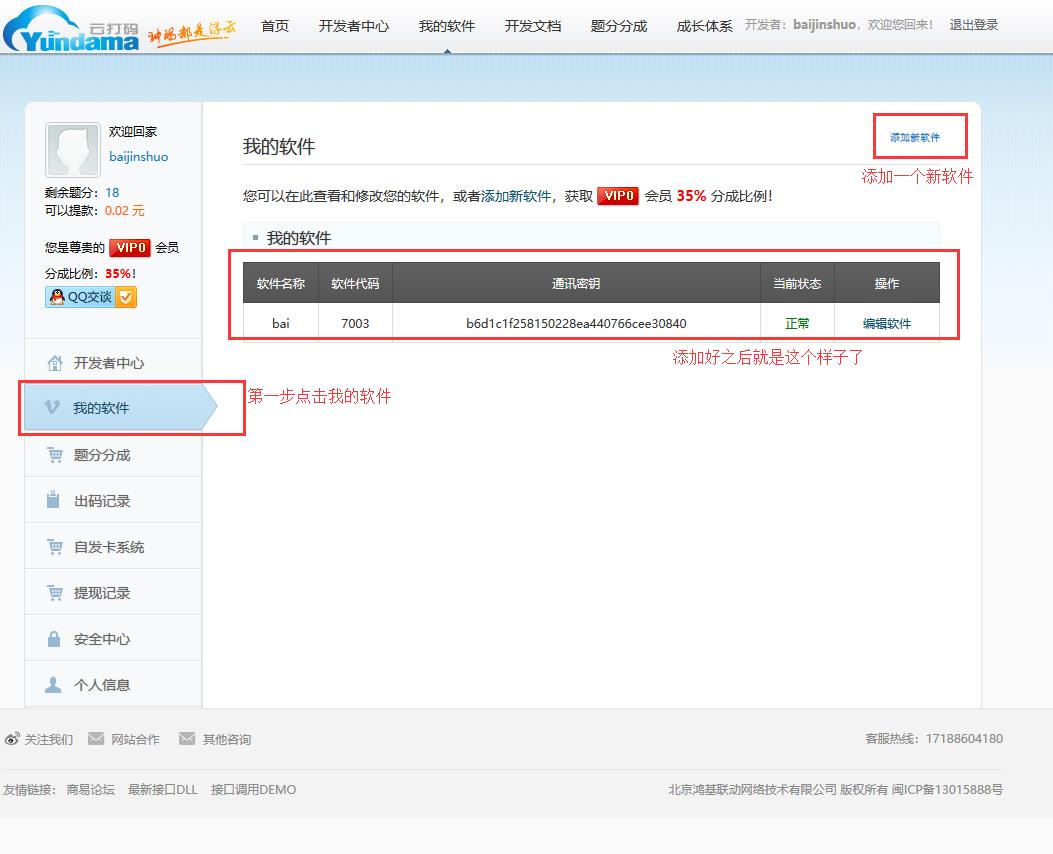
然后点击开发文档

进入之后点击下载python相关的模块

下载之后我们解压之后发现是里面有三个文件:
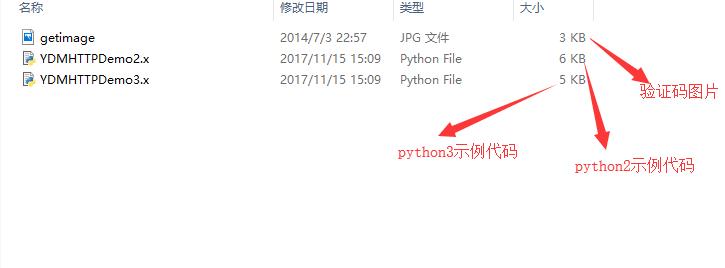
这里以python3的代码为例:
import http.client, mimetypes, urllib, json, time, requests
######################################################################
class YDMHttp:
apiurl = \'http://api.yundama.com/api.php\'
username = \'\'
password = \'\'
appid = \'\'
appkey = \'\'
def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey
def request(self, fields, files=[]):
response = self.post_url(self.apiurl, fields, files)
response = json.loads(response)
return response
def balance(self):
data = {\'method\': \'balance\', \'username\': self.username, \'password\': self.password, \'appid\': self.appid, \'appkey\': self.appkey}
response = self.request(data)
if (response):
if (response[\'ret\'] and response[\'ret\'] < 0):
return response[\'ret\']
else:
return response[\'balance\']
else:
return -9001
def login(self):
data = {\'method\': \'login\', \'username\': self.username, \'password\': self.password, \'appid\': self.appid, \'appkey\': self.appkey}
response = self.request(data)
if (response):
if (response[\'ret\'] and response[\'ret\'] < 0):
return response[\'ret\']
else:
return response[\'uid\']
else:
return -9001
def upload(self, filename, codetype, timeout):
data = {\'method\': \'upload\', \'username\': self.username, \'password\': self.password, \'appid\': self.appid, \'appkey\': self.appkey, \'codetype\': str(codetype), \'timeout\': str(timeout)}
file = {\'file\': filename}
response = self.request(data, file)
if (response):
if (response[\'ret\'] and response[\'ret\'] < 0):
return response[\'ret\']
else:
return response[\'cid\']
else:
return -9001
def result(self, cid):
data = {\'method\': \'result\', \'username\': self.username, \'password\': self.password, \'appid\': self.appid, \'appkey\': self.appkey, \'cid\': str(cid)}
response = self.request(data)
return response and response[\'text\'] or \'\'
def decode(self, filename, codetype, timeout):
cid = self.upload(filename, codetype, timeout)
if (cid > 0):
for i in range(0, timeout):
result = self.result(cid)
if (result != \'\'):
return cid, result
else:
time.sleep(1)
return -3003, \'\'
else:
return cid, \'\'
def report(self, cid):
data = {\'method\': \'report\', \'username\': self.username, \'password\': self.password, \'appid\': self.appid, \'appkey\': self.appkey, \'cid\': str(cid), \'flag\': \'0\'}
response = self.request(data)
if (response):
return response[\'ret\']
else:
return -9001
def post_url(self, url, fields, files=[]):
for key in files:
files[key] = open(files[key], \'rb\');
res = requests.post(url, files=files, data=fields)
return res.text
######################################################################
# 用户名
username = \'username\'
# 密码
password = \'password\'
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = 1
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = \'22cc5376925e9387a23cf797cb9ba745\'
# 图片文件
filename = \'getimage.jpg\'
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = 1004
# 超时时间,秒
timeout = 60
# 检查
if (username == \'username\'):
print(\'请设置好相关参数再测试\')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print(\'uid: %s\' % uid)
# 查询余额
balance = yundama.balance();
print(\'balance: %s\' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
print(\'cid: %s, result: %s\' % (cid, result))
######################################################################
原装代码
使用示例代码中的源码文件中的代码进行修改,让其识别验证码图片中的数据值
#该函数就调用了打码平台的相关的接口对指定的验证码图片进行识别,返回图片上的数据值
def getCode(codeImg):
# 云打码平台普通用户的用户名
username = \'baijinshuo\'
# 云打码平台普通用户的密码
password = \'bjs146531\'
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = 6003
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = \'1f4b564483ae5c907a1d34f8e2f2776c\'
# 验证码图片文件
filename = codeImg
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = 3000
# 超时时间,秒
timeout = 20
# 检查
if (username == \'username\'):
print(\'请设置好相关参数再测试\')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print(\'uid: %s\' % uid)
# 查询余额
balance = yundama.balance();
print(\'balance: %s\' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
print(\'cid: %s, result: %s\' % (cid, result))
return result
import requests
from lxml import etree
import json
import time
import re
#1.对携带验证码的页面数据进行抓取
url = \'https://www.douban.com/accounts/login?source=movie\'
headers = {
\'User-Agent\': \'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Mobile Safari/537.36\'
}
page_text = requests.get(url=url,headers=headers).text
#2.可以将页面数据中验证码进行解析,验证码图片下载到本地
tree = etree.HTML(page_text)
codeImg_url = tree.xpath(\'//*[@id="captcha_image"]/@src\')[0]
#获取了验证码图片对应的二进制数据值
code_img = requests.get(url=codeImg_url,headers=headers).content
#获取capture_id
\'<img id="captcha_image" src="https://www.douban.com/misc/captcha?id=AdC4WXGyiRuVJrP9q15mqIrt:en&size=s" alt="captcha" class="captcha_image">\'
c_id = re.findall(\'<img id="captcha_image".*?id=(.*?)&.*?>\',page_text,re.S)[0]
with open(\'./code.png\',\'wb\') as fp:
fp.write(code_img)
#获得了验证码图片上面的数据值
codeText = getCode(\'./code.png\')
print(codeText)
#进行登录操作
post = \'https://accounts.douban.com/login\'
data = {
"source": "movie",
"redir": "https://movie.douban.com/",
"form_email": "15027900535",
"form_password": "bobo@15027900535",
"captcha-solution":codeText,
"captcha-id":c_id,
"login": "登录",
}
print(c_id)
login_text = requests.post(url=post,data=data,headers=headers).text
with open(\'./login.html\',\'w\',encoding=\'utf-8\') as fp:
fp.write(login_text)
以上是关于python爬虫之处理验证码的主要内容,如果未能解决你的问题,请参考以下文章