机器学习--识别腐烂水果和不腐烂的水果
Posted chenhuangyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习--识别腐烂水果和不腐烂的水果相关的知识,希望对你有一定的参考价值。
(一)选题背景:
苹果树是优良的经济作物,目前我国苹果树的种植面积较大,产量较高,而且苹果的品种也在不断改良和更新。苹果的种植条件比较宽泛,大部分栽植于北方地区,种植面积大,市场需求量也大,其中陕西洛川、甘肃天水、宜川、新疆阿克苏等地盛产苹果,这几个地方产的苹果品质优良。农场采摘了许多苹果和香蕉,但由于机器人没有辨别程序和天气太热,将苹果和香蕉放在了一起,容易导致苹果和香蕉腐烂变质,导致农民经济收入降低,为了提高效益,机器人应该如何判断水果是否腐烂,于是通过计算机视觉和机器学习设计了一套程序用于判断水果是否腐烂。
(二)机器学习设计案例:从网站中下载相关的数据集,对数据集进行整理,在python的环境中,给数据集中的文件打上标签,对数据进行预处理,利用keras--gpu和tensorflow,通过构建输入层,隐藏层,输出层建立训练模型,导入图片测试模型。
参考来源:机器学习-周志华.关于水果如何分类
数据集来源:kaggle,网址:https://www.kaggle.com/
(三)机器学习的实现步骤:
1.下载数据集

2.导入需要用到的库
import numpy as np
import pandas as pd
import os
import numpy as np
import matplotlib.pyplot as plt
import os
import shutil
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
from tensorflow.keras.models import Sequential, Model
TRAIN_PATH = \'./chenhuangyu/data/dataset/train/\'#设置锻炼数据所在的路径
TEST_PATH = \'./chenhuangyu/data/dataset/test/\' #设置测试数据所在的路径
SIZE = (240, 240)
labels = []
for class_ in os.listdir(TRAIN_PATH):
labels.append(class_)
NUM_LABELS = len(labels)
print(labels)

4.得到每个文件中图片的数量并进行图像预处理
from keras.preprocessing.image import ImageDataGenerator
datagen=ImageDataGenerator(rescale=1./255, validation_split = 0.1)
test_datagen = ImageDataGenerator(rescale=1./255)
train_dataset = datagen.flow_from_directory(batch_size=32,
directory=TRAIN_PATH,
shuffle=True,
classes=labels,
target_size=SIZE,
subset="training",
class_mode=\'categorical\')
val_dataset = datagen.flow_from_directory(batch_size=32,
directory=TRAIN_PATH,
shuffle=True,
classes=labels,
target_size=SIZE,
subset="validation",
class_mode=\'categorical\')
‘’‘
-- 图像数据生成器将调整所有图像的大小为target_size
-- x_col是图像名称所在的列
-- y_col是标签所在的列
-- has_ext表示图像的名称包含文件扩展名,例如image_name.jpg
-- 在这里您可以更改targe_size将所有图像调整为不同的形状。
’‘’
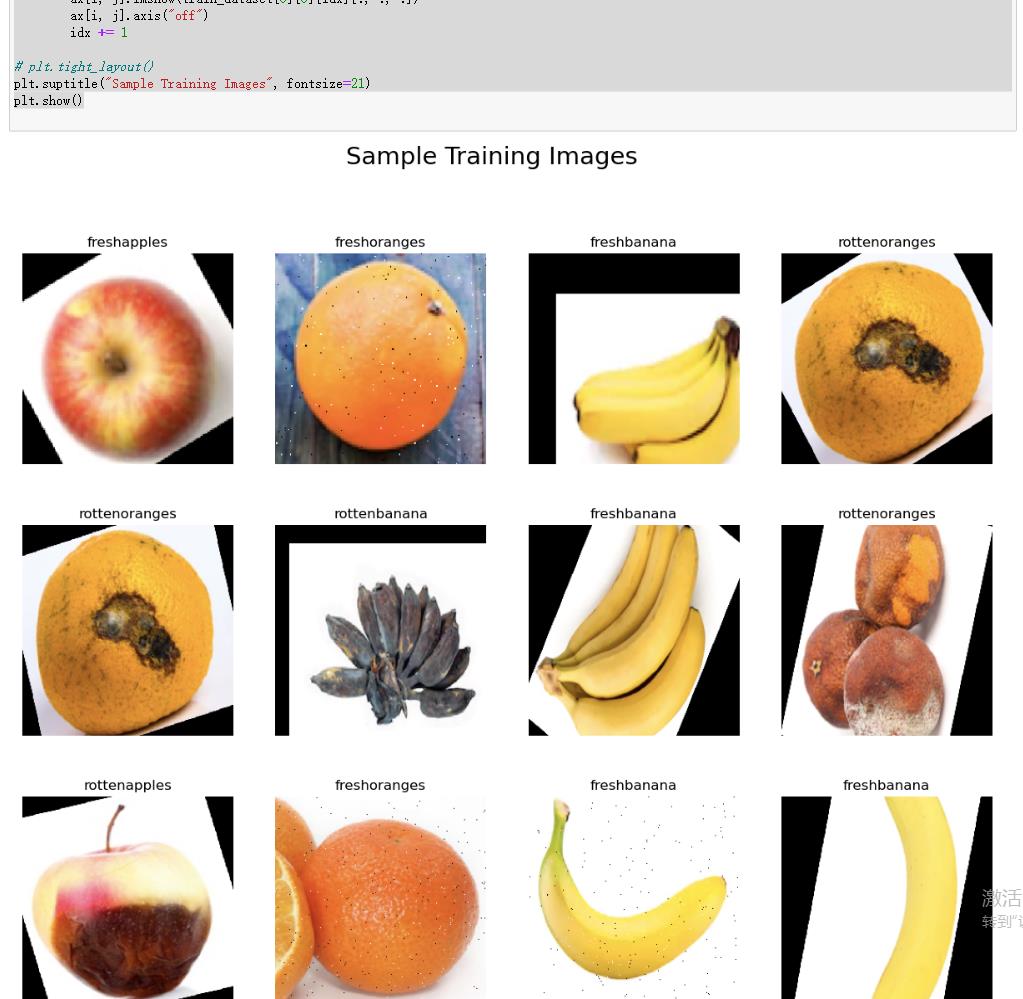
5.导入训练所需要的图片,查看经过处理的图片以及它的标签
fig, ax = plt.subplots(nrows=3, ncols=4, figsize=(15, 12))
idx = 0
for i in range(3):
for j in range(4):
label = labels[np.argmax(train_dataset[0][1][idx])]
ax[i, j].set_title(f"label")
ax[i, j].imshow(train_dataset[0][0][idx][:, :, :])
ax[i, j].axis("off")
idx += 1
# plt.tight_layout()
plt.suptitle("Sample Training Images", fontsize=21)
plt.show()
8.构建神经网络并对模型进行训练
model = tf.keras.Sequential() #构建神经网络
# 1.Conv2D层,32个过滤器
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3,3), activation=\'relu\', input_shape = (240,240,3)))
model.add(tf.keras.layers.MaxPool2D((2,2)))
model.add(tf.keras.layers.Dropout(0.2))
# 2.Conv2D层,64个过滤器
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3,3), activation=\'relu\'))
model.add(tf.keras.layers.MaxPool2D((2,2)))
model.add(tf.keras.layers.Dropout(0.2))
#3.Conv2D层,128个过滤器
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3,3), activation=\'relu\'))
model.add(tf.keras.layers.MaxPool2D((2,2)))
model.add(tf.keras.layers.Dropout(0.2))
#将输入层的数据压缩
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation=\'relu\'))
model.add(tf.keras.layers.Dense(64, activation=\'relu\'))
model.add(tf.keras.layers.Dense(6, activation=\'softmax\'))
# 模型编译
model.compile(optimizer=\'adam\', loss = \'categorical_crossentropy\', metrics=[\'accuracy\'])
9.总结模型
model.summary()

#设置训练次数为12次
history = model.fit_generator(generator=train_dataset, steps_per_epoch=len(train_dataset), epochs=12, validation_data=val_dataset, validation_steps=len(val_dataset))

#保存模型
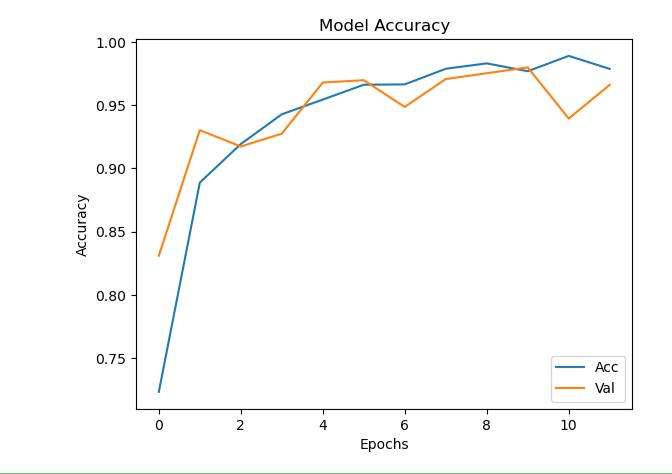
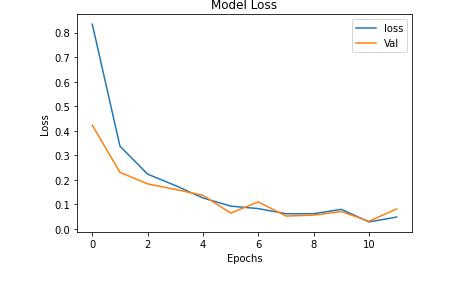
9.绘制损失曲线和精度曲线图
import matplotlib.pyplot as plt
plt.plot(history.history[\'accuracy\'])
plt.plot(history.history[\'val_accuracy\'])
plt.title(\'Model Accuracy\')
plt.xlabel(\'Epochs\')
plt.ylabel(\'Accuracy\')
plt.legend([\'Acc\',\'Val\'], loc = \'lower right\')
plt.plot(history.history[\'loss\'])
plt.plot(history.history[\'val_loss\'])
plt.title(\'Model Loss\')
plt.xlabel(\'Epochs\')
plt.ylabel(\'Loss\')
plt.legend([\'loss\',\'Val\'], loc = \'upper right\')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(TEST_PATH,
batch_size=1,
target_size=SIZE,
shuffle = False,
classes=labels,
class_mode=\'categorical\')
10.测试模型
filenames = test_generator.filenames
nb_samples = len(filenames)
loss, acc = model.evaluate(test_generator,steps = (nb_samples), verbose=1)
print(\'accuracy test: \',acc)
print(\'loss test: \',loss)

predictions = model.predict(test_generator)
files=test_generator.filenames
class_dict=test_generator.class_indices # a dictionary of the form class name: class index
rev_dict=
for key, value in class_dict.items():
rev_dict[value]=key
for i, p in enumerate(predictions):
index=np.argmax(p)
klass=rev_dict[index]
prob=p[index]

11.显示图片
fig, ax = plt.subplots(nrows=3, ncols=4, figsize=(12, 10))
idx = 0
for i in range(3):
for j in range(4):
predicted_label = labels[np.argmax(predictions[idx])]
ax[i, j].set_title(f"predicted_label")
ax[i, j].imshow(test_generator[idx][0].reshape(240,240,3))
ax[i, j].axis("off")
idx += 200
# plt.tight_layout()
plt.suptitle("Test Dataset Predictions", fontsize=20)
plt.show()
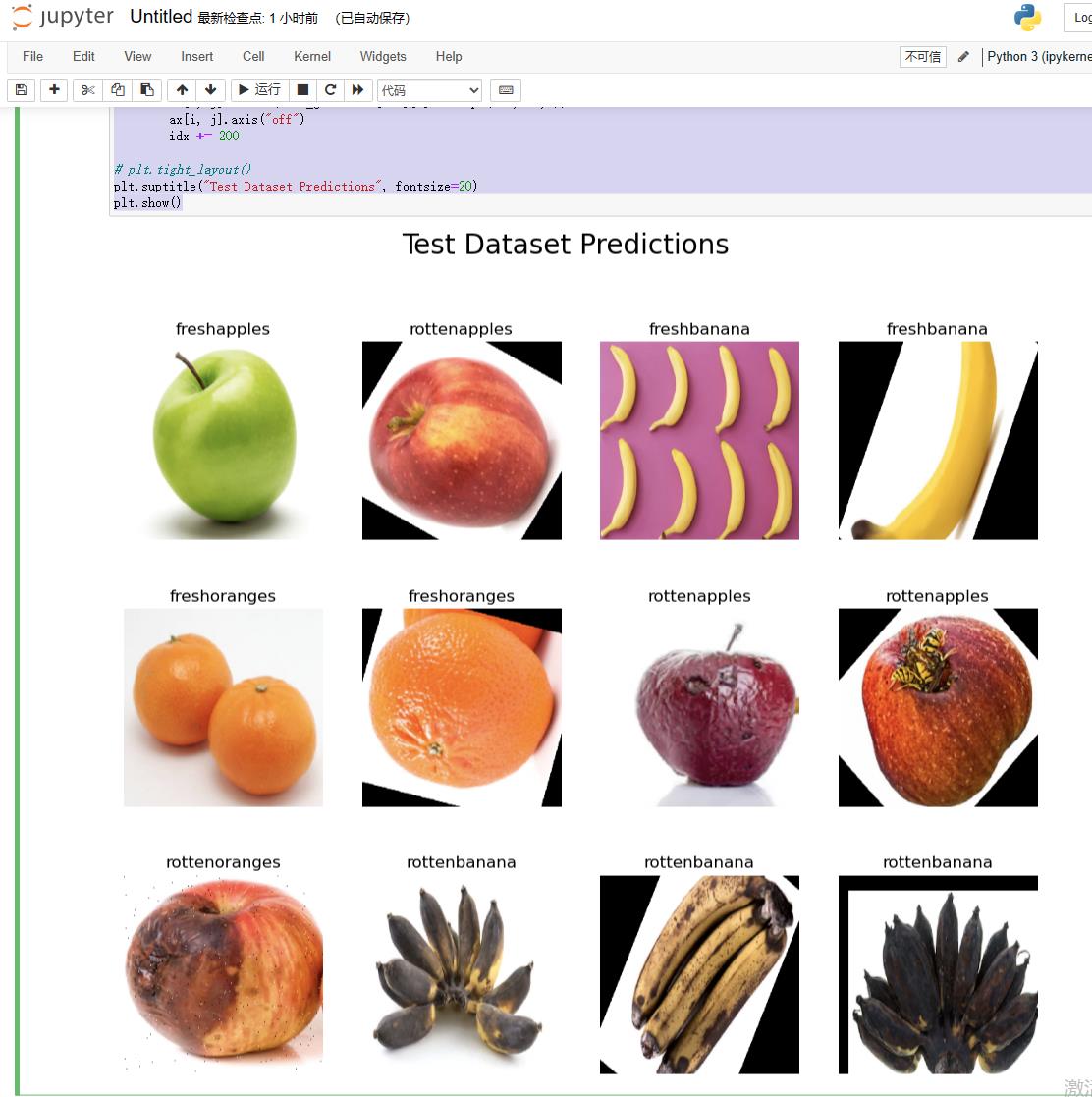
#预测比较准确
四)收获:本次的程序设计主要内容是机器学习,通过本次课程设计,是我对机器学习的理解更加深刻,同时,使我掌握了机器学习的步骤 1.提出问题2.理解数据,3.导入数据,4.查看数据,5.数据清洗(数据预处理:缺失值处理、重复值处理、数据类型的转换、字符串数据的规整),特征提取(特征工程.),特征选择,6.构建模型 ,7.选择算法(逻辑回归(logisic regression)随机森林(Random Forests Model)支持向量机(Support Vector Machines)Gradient Boosting ClassifierK-nearest neighbors) 8.评论模型,9撰写报告
总结:这次试验的缺陷 ,识别的水果种类比较少,可以适当的改进升级提高识别的种类,训练次数较少和精度不够高.
改进:可以进行多次训练,提高次数
#全代码
import numpy as np
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import shutil
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
from tensorflow.keras.models import Sequential, Model
TRAIN_PATH = \'./chenhuangyu/data/dataset/train/\'
TEST_PATH = \'./chenhuangyu/data/dataset/test/\'
SIZE = (240, 240)
labels = []
for class_ in os.listdir(TRAIN_PATH):
labels.append(class_)
NUM_LABELS = len(labels)
print(labels)
from keras.preprocessing.image import ImageDataGenerator
datagen=ImageDataGenerator(rescale=1./255, validation_split = 0.1)
test_datagen = ImageDataGenerator(rescale=1./255)
train_dataset = datagen.flow_from_directory(batch_size=32,
directory=TRAIN_PATH,
shuffle=True,
classes=labels,
target_size=SIZE,
subset="training",
class_mode=\'categorical\')
val_dataset = datagen.flow_from_directory(batch_size=32,
directory=TRAIN_PATH,
shuffle=True,
classes=labels,
target_size=SIZE,
subset="validation",
class_mode=\'categorical\')
fig, ax = plt.subplots(nrows=3, ncols=4, figsize=(15, 12))
idx = 0
for i in range(3):
for j in range(4):
label = labels[np.argmax(train_dataset[0][1][idx])]
ax[i, j].set_title(f"label")
ax[i, j].imshow(train_dataset[0][0][idx][:, :, :])
ax[i, j].axis("off")
idx += 1
plt.suptitle("Sample Training Images", fontsize=21)
plt.show()
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3,3), activation=\'relu\', input_shape = (240,240,3)))
model.add(tf.keras.layers.MaxPool2D((2,2)))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3,3), activation=\'relu\'))
model.add(tf.keras.layers.MaxPool2D((2,2)))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3,3), activation=\'relu\'))
model.add(tf.keras.layers.MaxPool2D((2,2)))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation=\'relu\'))
model.add(tf.keras.layers.Dense(64, activation=\'relu\'))
model.add(tf.keras.layers.Dense(6, activation=\'softmax\'))
model.compile(optimizer=\'adam\', loss = \'categorical_crossentropy\', metrics=[\'accuracy\'])
model.summary()
history = model.fit_generator(generator=train_dataset, steps_per_epoch=len(train_dataset), epochs=12, validation_data=val_dataset, validation_steps=len(val_dataset))
import matplotlib.pyplot as plt
plt.plot(history.history[\'accuracy\'])
plt.plot(history.history[\'val_accuracy\'])
plt.title(\'Model Accuracy\')
plt.xlabel(\'Epochs\')
plt.ylabel(\'Accuracy\')
plt.legend([\'Acc\',\'Val\'], loc = \'lower right\')
learning_rate = history.history[\'lr\']
plt.plot(history.history[\'lr\'])
plt.title(\'Learning Rate\')
plt.xlabel(\'Epochs\')
plt.ylabel(\'Learning Rate\')
plt.legend([\'loss\',\'Val\'], loc = \'upper right\')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(TEST_PATH,
batch_size=1,
target_size=SIZE,
shuffle = False,
classes=labels,
class_mode=\'categorical\')
filenames = test_generator.filenames
nb_samples = len(filenames)
loss, acc = model.evaluate(test_generator,steps = (nb_samples), verbose=1)
print(\'accuracy test: \',acc)
print(\'loss test: \',loss)
predictions = model.predict(test_generator)
files=test_generator.filenames
class_dict=test_generator.class_indices # a dictionary of the form class name: class index
rev_dict=
for key, value in class_dict.items():
rev_dict[value]=key
for i, p in enumerate(predictions):
index=np.argmax(p)
klass=rev_dict[index]
prob=p[index]
fig, ax = plt.subplots(nrows=3, ncols=4, figsize=(12, 10))
idx = 0
for i in range(3):
for j in range(4):
predicted_label = labels[np.argmax(predictions[idx])]
ax[i, j].set_title(f"predicted_label")
ax[i, j].imshow(test_generator[idx][0].reshape(240,240,3))
ax[i, j].axis("off")
idx += 200
# plt.tight_layout()
plt.suptitle("Test Dataset Predictions", fontsize=20)
plt.show()
深度学习100例 | 第4例:水果识别 - PyTorch实现
文章目录
大家好,我是K同学啊,今天讲《深度学习100例》PyTorch版的第4个例子,前面一些例子主要还是以带大家了解PyTorch为主,建议手动敲一下代码,只有自己动手了,才能真正体会到里面的内容,光看不练是没有用的。今天的重点是在PyTorch调用VGG-16算法模型。先来了解一下PyTorch与TensorFlow的区别
PyTorch VS TensorFlow:
TensorFlow:简单,模块封装比较好,容易上手,对新手比较友好。在工业界最重要的是模型落地,目前国内的大部分企业支持TensorFlow模型在线部署,不支持Pytorch。PyTorch:前沿算法多为PyTorch版本,如果是你高校学生or研究人员,建议学这个。相对于TensorFlow,Pytorch在易用性上更有优势,更加方便调试。
当然如果你时间充足,我建议两个模型都是需要了解一下的,这两者都还是很重要的。
🍨 本文的重点:将讲解如何使用PyTorch构建神经网络模型(将对这一块展开详细的讲解)
🍖 我的环境:
- 语言环境:Python3.8
- 编译器:Jupyter Lab
- 深度学习环境:
- torch==1.10.0+cu113
- torchvision==0.11.1+cu113
- 创作平台:🔗 极链AI云
- 创作教程:🔎 操作手册

深度学习环境配置教程:小白入门深度学习 | 第四篇:配置PyTorch环境
👉 往期精彩内容
- 🔥 本文选自专栏:《深度学习100例》Pytorch版
- ✨ 镜像专栏:《深度学习100例》TensorFlow版
一、导入数据
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.models as models
import torch.nn.functional as F
import torch.nn as nn
import torch,torchvision
获取类别名字
import os,PIL,random,pathlib
data_dir = './04-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\\\")[1] for path in data_paths]
classeNames
['Apple',
'Banana',
'Carambola',
'Guava',
'Kiwi',
'Mango',
'muskmelon',
'Orange',
'Peach',
'Pear',
'Persimmon',
'Pitaya',
'Plum',
'Pomegranate',
'Tomatoes']
加载数据文件
total_datadir = './04-data/'
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 12000
Root location: ./04-data/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
划分数据
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x24bbdb84ac0>,
<torch.utils.data.dataset.Subset at 0x24bbdb84610>)
train_size,test_size
(9600, 2400)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=16,
shuffle=True,
num_workers=1)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=16,
shuffle=True,
num_workers=1)
print("The number of images in a training set is: ", len(train_loader)*16)
print("The number of images in a test set is: ", len(test_loader)*16)
print("The number of batches per epoch is: ", len(train_loader))
The number of images in a training set is: 9600
The number of images in a test set is: 2400
The number of batches per epoch is: 600
for X, y in test_loader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
Shape of X [N, C, H, W]: torch.Size([16, 3, 224, 224])
Shape of y: torch.Size([16]) torch.int64
二、自建模型
nn.Conv2d()函数:
- 第一个参数(in_channels)是输入的channel数量,彩色图片为3,黑白图片为1。
- 第二个参数(out_channels)是输出的channel数量
- 第三个参数(kernel_size)是卷积核大小
- 第四个参数(stride)是步长,就是卷积操作时每次移动的格子数,默认为1
- 第五个参数(padding)是填充大小,默认为0
这里大家最难理解的可能就是nn.Linear(24*50*50, len(classeNames))这行代码了,在理解它之前你需要先补习一下👉卷积计算 的相关知识,然后可参照下面的网络结构图来进行理解

class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*25*25, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device".format(device))
model = Network_bn().to(device)
model
Using cuda device
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=60000, out_features=15, bias=True)
)
三、模型训练
1. 优化器与损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001, weight_decay=0.0001)
loss_model = nn.CrossEntropyLoss()
from torch.autograd import Variable
def test(model, test_loader, loss_model):
size = len(test_loader.dataset)
num_batches = len(test_loader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in test_loader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_model(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \\n Accuracy: (100*correct):>0.1f%, Avg loss: test_loss:>8f \\n")
return correct,test_loss
def train(model,train_loader,loss_model,optimizer):
model=model.to(device)
model.train()
for i, (images, labels) in enumerate(train_loader, 0):
images = Variable(images.to(device))
labels = Variable(labels.to(device))
optimizer.zero_grad()
outputs = model(images)
loss = loss_model(outputs, labels)
loss.backward()
optimizer.step()
if i % 1000 == 0:
print('[%5d] loss: %.3f' % (i, loss))
2. 模型的训练
test_acc_list = []
epochs = 30
for t in range(epochs):
print(f"Epoch t+1\\n-------------------------------")
train(model,train_loader,loss_model,optimizer)
test_acc,test_loss = test(model, test_loader, loss_model)
test_acc_list.append(test_acc)
print("Done!")
Epoch 1
-------------------------------
[ 0] loss: 2.780
Test Error:
Accuracy: 85.8%, Avg loss: 0.440920
Epoch 2
-------------------------------
[ 0] loss: 0.468
Test Error:
Accuracy: 89.2%, Avg loss: 0.377265
......
Epoch 29
-------------------------------
[ 0] loss: 0.000
Test Error:
Accuracy: 91.2%, Avg loss: 0.885408
Epoch 30
-------------------------------
[ 0] loss: 0.000
Test Error:
Accuracy: 91.8%, Avg loss: 0.660563
Done!
四、结果分析
import numpy as np
import matplotlib.pyplot as plt
x = [i for i in range(1,31)]
plt.plot(x, test_acc_list, label="Accuracy", alpha=0.8)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()

以上是关于机器学习--识别腐烂水果和不腐烂的水果的主要内容,如果未能解决你的问题,请参考以下文章