python之路--ORM
Posted 一个很善良的抱爱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之路--ORM相关的知识,希望对你有一定的参考价值。
一 . ORM
ORM是“对象-关系-映射”的简称。(Object Relational Mapping,简称ORM)
二. 单表操作
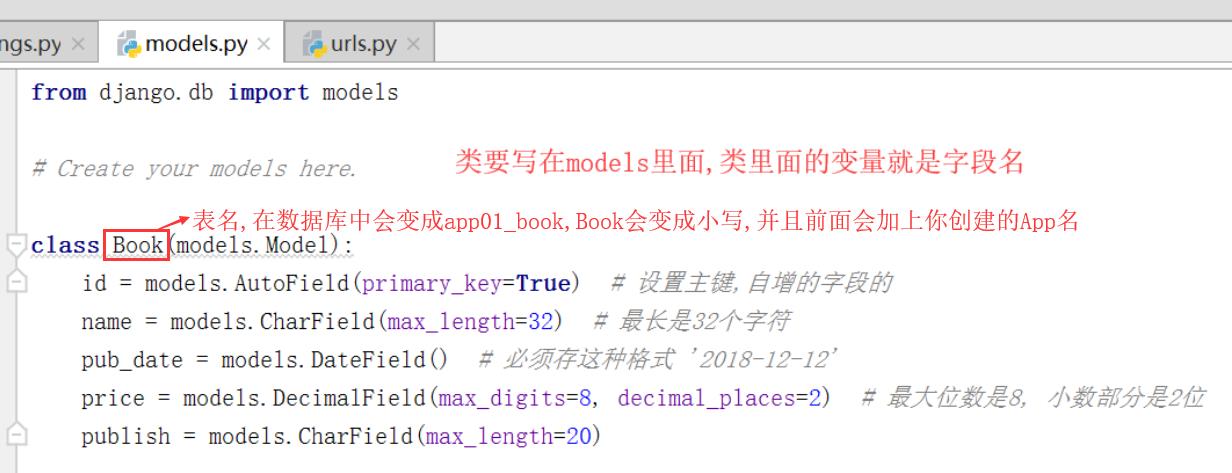
要想将模型转为mysql数据库中的表,需要在setting里面写上这个,把原来带的替换掉
DATABASES = {
\'default\': {
\'ENGINE\': \'django.db.backends.mysql\',
\'NAME\': \'book\', # 要连接的数据库名,连接前需要创建好
\'USER\': \'root\', # 连接数据库的用户名
\'PASSWORD\': \'666\', # 连接数据库的密码
\'HOST\': \'127.0.0.1\', # 连接主机,默认本机
\'PORT\': 3306 # 端口 默认3306
}
}
还需在项目名下的__init__的文件中写 : 写成这个的目的是将django默认的驱动MySQLdb 改为 pyMySQL,因为MySQLdb对于py3有很大的问题.
import pymysql
pymysql.install_as_MySQLdb()
通过两条数据库迁移命令在指定数据库建表
python manage.py makemigrations #生成记录,每次修改了models里面的内容或者添加了新的app,新的app里面写了models里面的内容,都要执行这两条
python manage.py migrate #执行上面这个语句的记录来创建表,生成的表名字前面会自带应用的名字,例如:你的book表在mysql里面叫做 app01_book 表
然后需要在python里面查看呢表中内容,需要进行下列操作
如果想打印ORM转换过程中的SQL语句,需要在setting中设置配置:
LOGGING = { \'version\': 1, \'disable_existing_loggers\': False, \'handlers\': { \'console\':{ \'level\':\'DEBUG\', \'class\':\'logging.StreamHandler\', }, }, \'loggers\': { \'django.db.backends\': { \'handlers\': [\'console\'], \'propagate\': True, \'level\':\'DEBUG\', }, } }
三 . 增删改查相关操作
在python中ORM三种对应关系
类----------------->表
类对象----------->行(记录) # 可以进行增删改查操作 (.create, .delete(), .update(), .filter(id=1), )
类属性----------->表字段
# 增加
# 方法一
book_obj = models.Book(name=\'吴彦祖\', gender=\'男\') # 如果是日期个格式必须写2018-01-01 这种格式
book_obj.save()
# 方法二
models.Book.objects.create(name=\'吴彦祖\',gender=\'男\')
# 这里的Book是models.py文件里面的类名
# 批量增加
obj_list = []
for i in range(100):
obj = models.UserMsg(
username= \'daniel%s\' %i,
password=\'abc%s\' %i
)
obj_list.append(obj)
models.UserMsg.objects.bulk_create(obj_list)
# 查询
obj = models.Book.objects.filter(id=1) # 查询id=1的对象 即使是筛选出来的只有一个,那么也要在后面加上[索引],因为装在列表里.
obj = models.Book.objects.all() # 查询所有的数据
# 上面的obj都是一个类似于用列表装的对象,要想取出来,可以使用for循环,或者后面加上[索引],
# 然后想要取到对应的字段,直接点字段就可以, 例如obj[0].name 就是取到该行的name字段的数据.
# 删除
models.Book.objects.all().delete() # 删除所有数据
models.Book.objects.filter(id=1).delete() # 删除id=1的数据
# 改
models.Book.objects.filter(id=1).update(name=\'刘德华\') # 把id=1的姓名改为刘德华
四 . mdels.py的__str__方法
from django.db import models
# Create your models here.
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2,)
pub_date = models.DateTimeField() #必须存这种格式"2012-12-12"
publish = models.CharField(max_length=32)
def __str__(self): #后添加这个str方法,也不需要重新执行同步数据库的指令
return self.name #当我们打印这个类的对象的时候,显示name值
# 这时候你要打印query set对象的时候就会显示name名字,看着明白些
五 . 查询表记录(重点)
Book.objects调用下面这些方法:
# 调用这些方法必须是queryset类型的,也就是说调用完下列方法后结果还是queryset类型的可以继续调用下列的方法
Q <1> all() : # 结果是queryset类型
Q <2> filter(**kwargs): 里面的关键字参数用逗号隔开,表示and的意思# 结果是queryset类型
<3> get(**kwargs): 结果是model对象,相当于queryset对象[索引]之后的,返回的结果有且只有一个
Q <4> exclude(**kwargs): 排除的意思,除了括号里面的都要, # 结果是queryset类型
Q <5> order_by(*字段): 排序,默认升序,前面加负号(-)就是降序,括号里面要加引号
# 写两个参数就是第一个参数相同的情况下,按照第二个参数排序. # 结果是queryset类型
Q <6>reverse(): 对查询结果反向排序,可以在order_by后面直接写 # 结果是queryset对象
Q <7>count(): 匹配查询(queryset)对象, # 结果是queryset类型
<8>first(): 返回第一条记录 是model对象
<9>last(): 返回最后一条记录 是model对象
<10>exists(): 如果有数据就返回True,没有就返回False
Q <11>values(*字段): 用的比较多,返回可迭代字典的序列 # 是一个特殊的queryset类型
Q <12>values_list(*字段): 和values很像,返回的是一个元组序列 # 是一个特殊的queryset类型
Q <13> distinct(): 一定要写在values或者values_list后面进行去重, 例: values(\'name\').distinct()
# 序号前面有Q的都是Queryset类型
values(*字段)的用法
all_books = models.Book.objects.all().values(\'name\',\'id\')
print(all_books) #<QuerySet [{\'name\': \'九阳神功\', \'id\': 1}, {\'name\': \'吸星大法\', \'id\': 2}]>
values_list(*字段)的用法
all_books = models.Book.objects.all().values_list(\'id\',\'name\')
print(all_books) #<QuerySet [(1, \'九阳神功\'), (2, \'吸星大法\')]>
# 里面是元组
distinct()的用法
# all_books = models.Book.objects.all().distinct() #这样写是表示记录中所有的字段重复才叫重复.
# all_books = models.Book.objects.all().distinct(\'price\') #报错,不能在distinct里面加字段名称
# all_books = models.Book.objects.all().values(\'price\').distinct() 如果values 中有两个参数,那么需要这两个都重复才去掉
# 打印结果<QuerySet [(Decimal(\'33.00\'),), (Decimal(\'111.00\'),)]>
基于双下划线的模糊查询
Book.objects.filter(price__in=[100,200,300]) #price值等于这三个里面的任意一个的对象
Book.objects.filter(price__gt=100) #大于,大于等于是price__gte=100,不支持price>100这种参数
Book.objects.filter(price__lt=100) # 小于
Book.objects.filter(price__range=[100,200]) #sql的between and,大于等于100,小于等于200
Book.objects.filter(title__contains="python") #title值中包含python的
Book.objects.filter(title__icontains="python") #不区分大小写
Book.objects.filter(title__startswith="py") #以什么开头,istartswith 不区分大小写
Book.objects.filter(pub_date__year=2012) # 查找2012年的数据
# 得到的都是queryset类型
# __month 查找月 __day 查找日
# 如果明明有要找的日期,但是报错,在setting的配置文件中把 USE_TZ 改为 False,这是由于mysql数据库和django的数据库时区不同导致的
以上是关于python之路--ORM的主要内容,如果未能解决你的问题,请参考以下文章