python之路4-文件操作
Posted 在路上2019
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之路4-文件操作相关的知识,希望对你有一定的参考价值。
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
f = open(\'lyrics\',\'r\',encoding=\'utf-8\') read_line = f.readline()#读取一行 print(read_line) print(\'我是分割线\'.center(50,\'-\')) data = f.read()#读取全部 print(data)
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \\r \\n \\r\\n自动转换成 \\n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open(\'lyrics\',\'r\',encoding=\'utf-8\') as f:
data = f.read()
print(data)
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
字符编码与转码
需知:
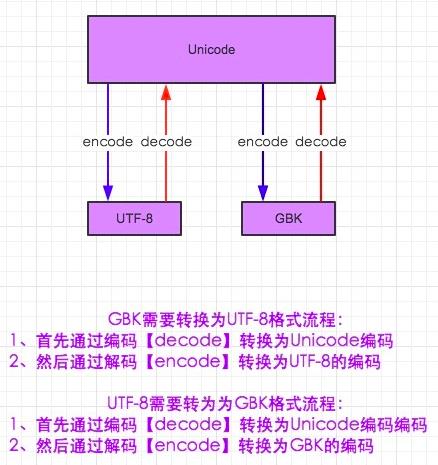
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
#python2
msg = "我爱北京天安门"
msg_gb2312 = msg.decode("utf-8").encode("gb2312")
#python3
msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔
以上是关于python之路4-文件操作的主要内容,如果未能解决你的问题,请参考以下文章