go语言抓取研招网硕士专业目录
Posted 念秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了go语言抓取研招网硕士专业目录相关的知识,希望对你有一定的参考价值。
最近在学go语言,不知道何从下手。突然想到了硕士专业目录,可以用来练习数据库操作,并且具有实际意义。
于是就开始和bing一起编程。想做什么,提问就好了。搜索效率比自己搜索,然后看一些重复无用的博客好多了。
整个过程就是研招网查询,抓包分析,编码,数据库建表,最后抓取所有数据进行保存。
研招网查询

ssdm 省市
yjxkdm 专业领域
zymc 专业名称
xxfs 学习方式
mldm 门类类别
这是点击查询后,post里面需要修改的数据。基本上只需要秀应该省市和专业名称。
下拉选择框的时候,也会有一些get请求。自己使用fiddler抓取分析即可。不过我已经保存了相关的请求和响应包在gitee项目里面。有需要直接看gitee项目即可。
编码
编码,我问bing,它回答,再进行修改即可。需要什么功能,就问什么,然后返回示例代码,进行修改。

数据库建表
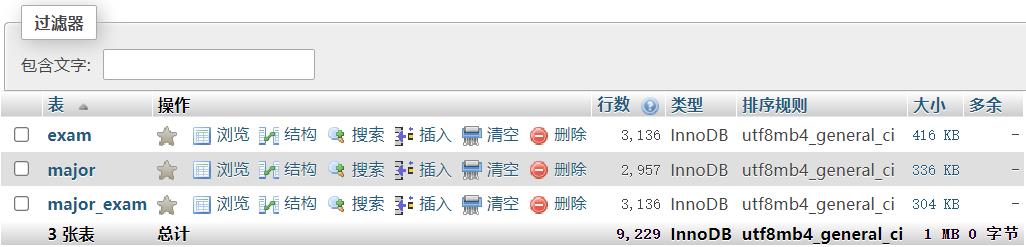
CREATE TABLE major (
id INT NOT NULL AUTO_INCREMENT,
code INT NOT NULL,
school VARCHAR(40) NOT NULL,
college VARCHAR(40) NOT NULL,
major VARCHAR(40) NOT NULL,
num INT NOT NULL,
full INT NOT NULL default 1,
tongkao INT NOT NULL default 0,
PRIMARY KEY (id)
);
CREATE TABLE exam (
id INT NOT NULL AUTO_INCREMENT,
first VARCHAR(40) NOT NULL,
second VARCHAR(40) NOT NULL,
third VARCHAR(40) NOT NULL,
forth VARCHAR(40) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE major_exam (
major_id INT NOT NULL,
exam_id INT NOT NULL,
FOREIGN KEY (major_id) REFERENCES major(id),
FOREIGN KEY (exam_id) REFERENCES exam(id)
);
读者应根据需要自行修改。
最后进行请求数据,进行处理,然后保存


可以看见,计算机专硕大概有不到3000个选择。major表的行数,就是所有大学所有学院相关专业以及研究方向的数量。至于招生人数,也是可以自己统计的。
爬研招网院校信息——python爬虫
使用的Python库包:Beautifulsoup
爬取的网站:https://yz.chsi.com.cn/zsml/queryAction.do
爬取内容:爬取院校名称、考试方式、专业、学习方式、研究方向、指导老师、招生人数。
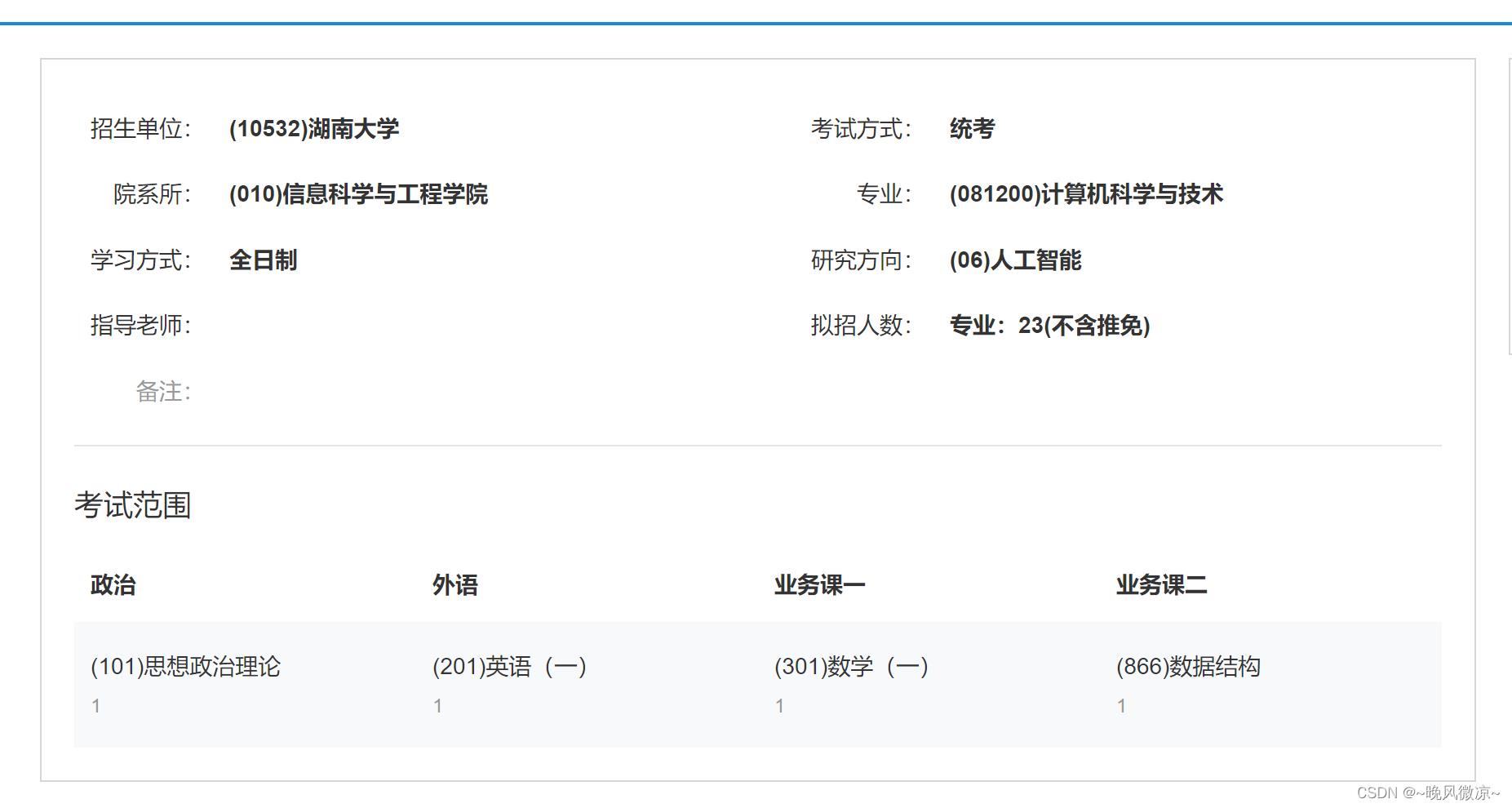
效果如下:
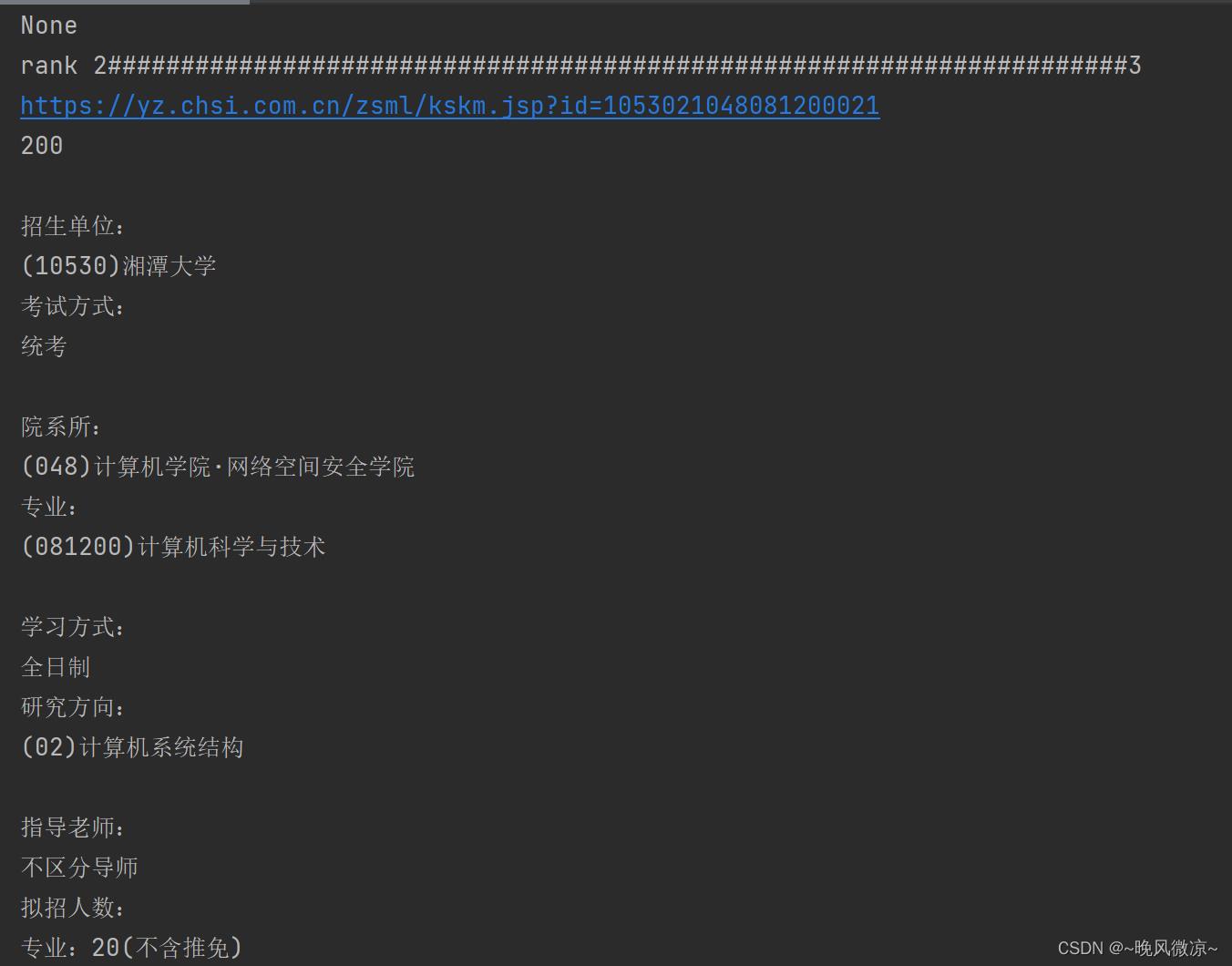
关键点:
1.Beautifulsoup里的find_all函数的使用
find_all('tag名称",“所对应的属性值”)
2.td.a[‘href’]
对应a标签里的href的值。
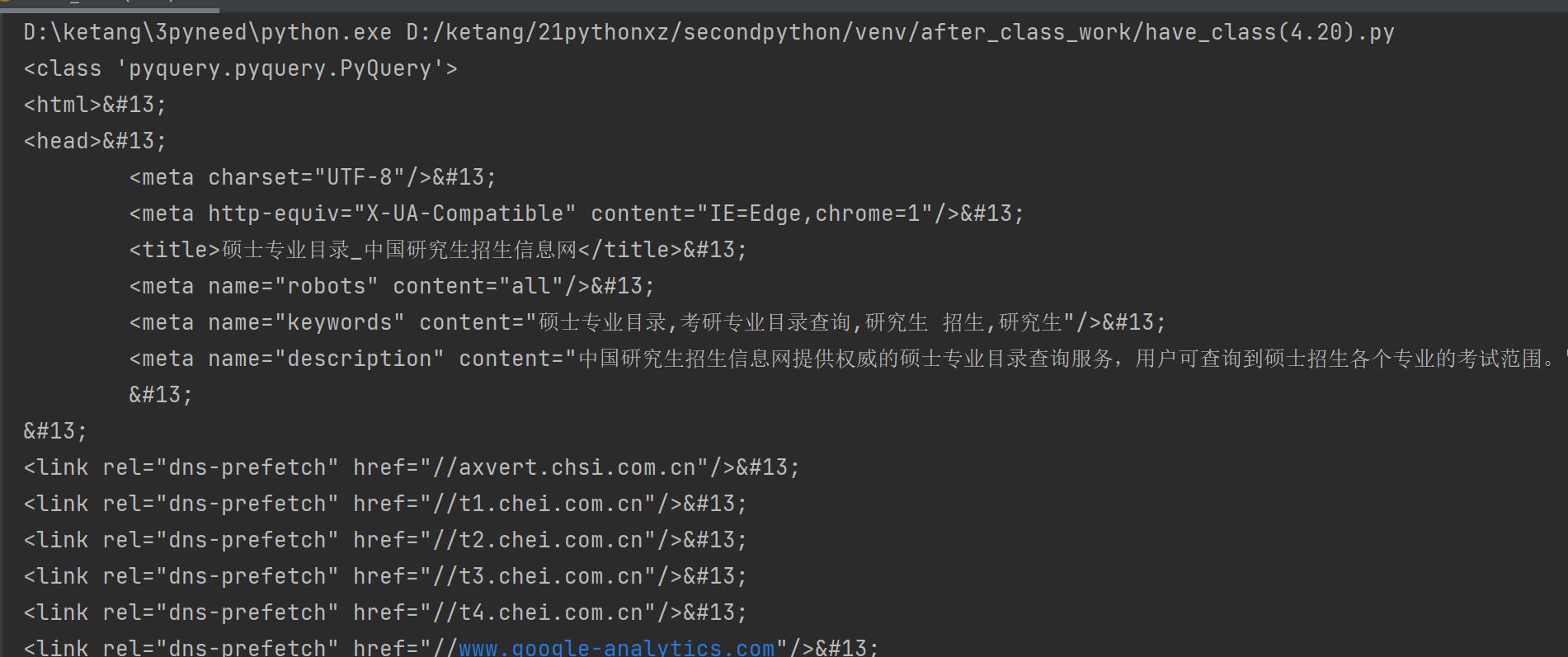
第一步,得到要爬取网页的html

结果展现:
第二步:
爬取得到每一项对应的各自的URL
for td in tds:
num+=1
if((num-5)%6==0):
numtrue+=1
print("rank ######################################################################3".format(numtrue))
# print(td)
href='https://yz.chsi.com.cn'
tmp=td.a['href']
href+=tmp
# print(tmp)
print(href)#nice爬取到了要读的网页
get_info(href)
# print(url)
第三步:
对每一个单独的链接进行处理
"""爬取单页内容里的具体信息"""
def get_info(url):
response = requests.get(url,headers=headers)
time.sleep(3)
#查看响应状态码
status_code = response.status_code
print(status_code)
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
# print(content)
trs=content.find_all('tr')
for tr in trs:
# print(tr)
for t in tr:
if(t.string!='None'):
print(t.string,end="")
完整代码如下:
"""研招网,details可看exercise_test.py"""
"""进度:完成!"""
import requests
import bs4
import time
import re
#反boss反爬取
headers =
'authority': 'static.zhipin.com',
'method':'GET',
'path': '/v2/web/geek/js/socket.js?t=1645165512072',
'scheme': 'https',
'accept':'*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie':'JSESSIONID=39A7A6D5A79E81F63B47E478AAD6967F; aliyungf_tc=423706e2a0ceab40a6b543a78fd720f683763f45f249d573ee2a8246cb7cfb25; acw_tc=781bad0c16507162723057775e186596e7b7638cfc53c51d0a171165393d2a; CHSICC_CLIENTFLAGZSML=34a470f172525ff109a64ba7033c0113; _gid=GA1.3.925681405.1650716296; _ga_YZV5950NX3=GS1.1.1650716283.6.1.1650716284.0; _ga=GA1.3.640078954.1650460515',
'referer': 'https://www.zhipin.com/',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': "Windows",
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
#抓取页码内容,返回响应对象
"""爬取对应的每个网页链接"""
url = "https://yz.chsi.com.cn/zsml/querySchAction.do?ssdm=43&dwmc=%E6%B9%98%E6%BD%AD%E5%A4%A7%E5%AD%A6&mldm=08&mlmc=&yjxkdm=0812&xxfs=1&zymc=";
response = requests.get(url,headers=headers)
time.sleep(3)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
# print(content)
tds = content.find_all('td',class_="ch-table-center")
num = 0
numtrue = 0
"""爬取单页内容里的具体信息"""
def get_info(url):
response = requests.get(url,headers=headers)
time.sleep(3)
#查看响应状态码
status_code = response.status_code
print(status_code)
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
# print(content)
trs=content.find_all('tr')
for tr in trs:
# print(tr)
for t in tr:
if(t.string!='None'):
print(t.string,end="")
for td in tds:
num+=1
if((num-5)%6==0):
numtrue+=1
print("rank ######################################################################3".format(numtrue))
# print(td)
href='https://yz.chsi.com.cn'
tmp=td.a['href']
href+=tmp
# print(tmp)
print(href)#nice爬取到了要读的网页
get_info(href)
# print(url)
以上是关于go语言抓取研招网硕士专业目录的主要内容,如果未能解决你的问题,请参考以下文章