通过Python实践K-means算法
Posted jums
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过Python实践K-means算法相关的知识,希望对你有一定的参考价值。
前言:
今天在宿舍弄了一个下午的代码,总算还好,把这个东西算是熟悉了,还不算是力竭,只算是知道了怎么回事。今天就给大家分享一下我的代码。代码可以运行,运行的Python环境是Python3.6以上的版本,需要用到Python中的numpy、matplotlib包,这一部分代码将K-means算法进行了实现。当然这还不是最优的代码,只是在功能上已经实现了该算法的功能。
代码部分:
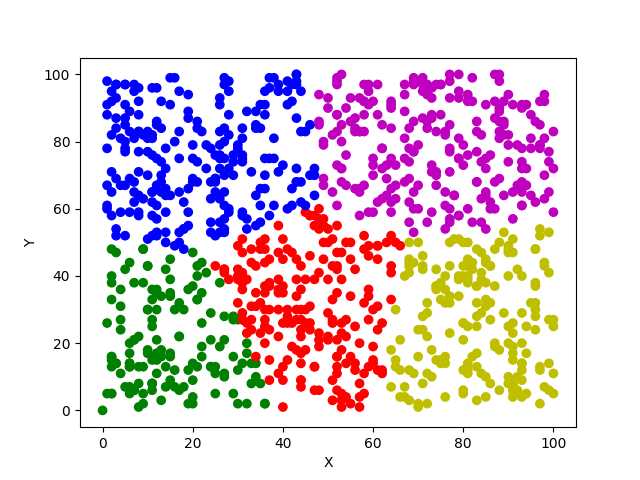
1 import numpy as np 2 import random 3 from matplotlib import pyplot as plt 4 5 class K_means(object): 6 def __init__(self,X,k,maxIter): 7 self.X = X#数据集 是一个矩阵 8 self.k = k#所需要分的类的数 9 self.maxIter = maxIter#所允许的程序执行的最大的循环次数 10 11 def K_means(self): 12 row,col = self.X.shape#得到矩阵的行和列 13 14 dataset = np.zeros((row,col + 1))#新生成一个矩阵,行数不变,列数加1 新的列用来存放分组号别 矩阵中的初始值为0 15 dataset[:,:-1] = self.X 16 print("begin:dataset: " + repr(dataset)) 17 # centerpoints = dataset[0:2,:]#取数据集中的前两个点为中心点 18 centerpoints = dataset[np.random.randint(row,size=k)]#采用随机函数任意取两个点 19 20 centerpoints[:,-1] = range(1,self.k+1) 21 oldCenterpoints = None #用来在循环中存放上一次循环的中心点 22 iterations = 1 #当前循环次数 23 24 while not self.stop(oldCenterpoints,centerpoints,iterations): 25 print("corrent iteration:" + str(iterations)) 26 print("centerpoint: " + repr(centerpoints)) 27 print("dataset: " + repr(dataset)) 28 29 oldCenterpoints = np.copy(centerpoints)#将本次循环的点拷贝一份 记录下来 30 iterations += 1 31 32 self.updateLabel(dataset,centerpoints)#将本次聚类好的结果存放到矩阵中 33 34 centerpoints = self.getCenterpoint(dataset)#得到新的中心点,再次进行循环计算 35 36 np.save("kmeans.npy", dataset) 37 return dataset 38 39 def stop(self,oldCenterpoints,centerpoints,iterations): 40 if iterations > self.maxIter: 41 return True 42 return np.array_equal(oldCenterpoints,centerpoints)#返回两个点多对比结果 43 44 45 def updateLabel(self,dataset,centerpoints): 46 row,col = self.X.shape 47 for i in range(0,row): 48 dataset[i,-1] = self.getLabel(dataset[i,:-1],centerpoints) 49 #[i,j] 表示i行j列 50 51 #返回当前行和中心点之间的距离最短的中心点的类别,即当前点和那个中心点最近就被划分到哪一部分 52 def getLabel(self,datasetRow,centerpoints): 53 label = centerpoints[0, -1]#先取第一行的标签值赋值给该变量 54 minDist = np.linalg.norm(datasetRow-centerpoints[0, :-1])#计算两点之间的直线距离 55 for i in range(1, centerpoints.shape[0]): 56 dist = np.linalg.norm(datasetRow-centerpoints[i, :-1]) 57 if dist < minDist:#当该变距离中心点的距离小于预设的最小值,那么将最小值进行更新 58 minDist = dist 59 label = centerpoints[i,-1] 60 print("minDist:" + str(minDist) + ",belong to label:" + str(label)) 61 return label 62 63 def getCenterpoint(self,dataset): 64 newCenterpoint = np.zeros((self.k,dataset.shape[1]))#生成一个新矩阵,行是k值,列是数据集的列的值 65 for i in range(1,self.k+1): 66 oneCluster = dataset[dataset[:,-1] == i,:-1]#取出上一次分好的类别的所有属于同一类的点,对其求平均值 67 newCenterpoint[i-1, :-1] = np.mean(oneCluster,axis=0)#axis=0表示对行求平均值,=1表示对列求平均值 68 newCenterpoint[i-1, -1] = i#重新对新的中心点进行分类,初始类 69 70 return newCenterpoint 71 72 #将散点图画出来 73 def drawScatter(self): 74 plt.xlabel("X") 75 plt.ylabel("Y") 76 dataset = self.K_means() 77 x = dataset[:, 0] # 第一列的数值为横坐标 78 y = dataset[:, 1] # 第二列的数值为纵坐标 79 c = dataset[:, -1] # 最后一列的数值用来区分颜色 80 color = ["none", "b", "r", "g", "y","m","c","k"] 81 c_color = [] 82 83 for i in c: 84 c_color.append(color[int(i)])#给每一种类别的点都涂上不同颜色,便于观察 85 86 plt.scatter(x=x, y=y, c=c_color, marker="o")#其中x表示横坐标的值,y表示纵坐标的 87 # 值,c表示该点显示出来的颜色,marker表示该点多形状,‘o’表示圆形 88 plt.show() 89 90 91 if __name__ == ‘__main__‘: 92 93 94 ‘‘‘ 95 关于numpy中的存储矩阵的方法,这里不多介绍,可以自行百度。这里使用的是 96 np.save("filename.npy",X)其中X是需要存储的矩阵 97 读取的方法就是代码中的那一行代码,可以不用修改任何参数,导出来的矩阵和保存之前的格式一模一样,很方便。 98 ‘‘‘ 99 # X = np.load("testSet-kmeans.npy")#从文件中读取数据 100 #自动生成数据 101 X = np.zeros((1,2)) 102 for i in range(1000): 103 X = np.row_stack((X,np.array([random.randint(1,100),random.randint(1,100)]))) 104 k = 5 #表示待分组的组数 105 106 kmeans = K_means(X=X,k=k,maxIter=100) 107 kmeans.drawScatter()
显示效果:
以上是关于通过Python实践K-means算法的主要内容,如果未能解决你的问题,请参考以下文章