HA高可用集群部署
Posted 祝灵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HA高可用集群部署相关的知识,希望对你有一定的参考价值。
HA高可用集群部署
高可用 ZooKeeper 集群部署
zookeeper安装部署
注意:需要安装jdk,但jdk已经在第4章装过,这里直接装zookeeper
#解压并安装zookeeper
[root@master ~]# ls
anaconda-ks.cfg
apache-hive-2.0.0-bin.tar.gz
hadoop-2.7.1.tar.gz
jdk-8u152-linux-x64.tar.gz
mysql-community-client-5.7.18-1.el7.x86_64.rpm
mysql-community-common-5.7.18-1.el7.x86_64.rpm
mysql-community-devel-5.7.18-1.el7.x86_64.rpm
mysql-community-libs-5.7.18-1.el7.x86_64.rpm
mysql-community-server-5.7.18-1.el7.x86_64.rpm
mysql-connector-java-5.1.46.jar
sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
zookeeper-3.4.8.tar.gz
[root@master ~]# tar xf zookeeper-3.4.8.tar.gz -C /usr/local/src/
[root@master ~]# cd /usr/local/src/
[root@master src]# ls
hadoop hive jdk sqoop zookeeper-3.4.8
[root@master src]# mv zookeeper-3.4.8 zookeeper
[root@master src]# ls
hadoop hive jdk sqoop zookeeper
创建zookeeper数据目录
[root@master src]# mkdir /usr/local/src/zookeeper/data
[root@master src]# mkdir /usr/local/src/zookeeper/logs
配置环境变量
[root@master src]# vi /etc/profile.d/zookeeper.sh
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin
修改zoo.cfg配置文件
[root@master src]# cd /usr/local/src/zookeeper/conf/
[root@master conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
#修改
dataDir=/usr/local/src/zookeeper/data
#增加
dataLogDir=/usr/local/src/zookeeper/logs
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
创建myid配置文件
[root@master conf]# cd ..
[root@master zookeeper]# cd data/
[root@master data]# echo "1" > myid
分发Zookeeper集群配置文件
#发送环境变量文件到slave1,slave2
[root@master data]# scp -r /etc/profile.d/zookeeper.sh slave1:/etc/profile.d/
[root@master data]# scp -r /etc/profile.d/zookeeper.sh slave2:/etc/profile.d/
#发送zookeeper配置文件到slave1,slave2
[root@master ~]# scp -r /usr/local/src/zookeeper/ slave1:/usr/local/src/
[root@master ~]# scp -r /usr/local/src/zookeeper/ slave2:/usr/local/src/
修改myid配置
#slave1
[root@slave1 ~]# echo "2" > /usr/local/src/zookeeper/data/myid
#slave2
[root@slave2 ~]# echo "3" > /usr/local/src/zookeeper/data/myid
#查看3个节点
[root@master ~]# cat /usr/local/src/zookeeper/data/myid
1
[root@slave1 ~]# cat /usr/local/src/zookeeper/data/myid
2
[root@slave2 ~]# cat /usr/local/src/zookeeper/data/myid
3
修改文件所属权限
[root@master ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
查看防火墙和selinux,如果没关就关掉
#以master为例,slave1,slave2同样要做
[root@master ~]# systemctl disable --now firewalld
[root@master ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; ve>
Active: inactive (dead)
Docs: man:firewalld(1)
[root@master ~]# vi /etc/selinux/config
SELINUX=disabled
切换hadoop用户,启动zookeeper
[root@master ~]# su - hadoop
[root@slave1 ~]# su - hadoop
[root@slave2 ~]# su - hadoop
#启动zookeeper
[hadoop@master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[hadoop@slave1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[hadoop@slave2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
查看集群
[hadoop@master ~]$ jps
1522 QuorumPeerMain
1579 Jps
[hadoop@slave1 ~]$ jps
1368 Jps
1309 QuorumPeerMain
[hadoop@slave2 ~]$ jps
1330 QuorumPeerMain
1387 Jps
Hadoop HA集群部署
注意:ssh免密登录在第4章已经配过,这里直接配HA
配置密钥加几条:
-
将masterr创建的公钥发给slave1
[hadoop@master ~]$ scp ~/.ssh/authorized_keys root@slave1:~/.ssh/ root@slave1\'s password: authorized_keys 100% 567 672.2KB/s 00:00 -
将slave1的私钥加到公钥里
[hadoop@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
将公钥发给slave2,master
[hadoop@slave1 ~]$ ssh-copy-id slave2 [hadoop@slave1 ~]$ ssh-copy-id master
删除第4章安装的hadoop
#删除环境变量,三个节点都要做
[root@master ~]# rm -rf /etc/profile.d/hadoop.sh
[root@slave1 ~]# rm -rf /etc/profile.d/hadoop.sh
[root@slave2 ~]# rm -rf /etc/profile.d/hadoop.sh
#删除hadoop
[root@master ~]# rm -rf /usr/local/src/hadoop/
[root@slave1 ~]# rm -rf /usr/local/src/hadoop/
[root@slave2 ~]# rm -rf /usr/local/src/hadoop/
配置hadoop环境变量
[root@master ~]# vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/src/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS="Djava.library.path=$HADOOP_INSTALL/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/local/src/jdk
export PATH=$PATH:$JAVA_HOME/bin
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin
配置 hadoop-env.sh 配置文件
[root@master ~]# tar -xf hadoop-2.7.1.tar.gz -C /usr/local/src/
[root@master ~]# mv /usr/local/src/hadoop-2.7.1/ /usr/local/src/hadoop
[root@master ~]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# vi hadoop-env.sh
#在最下面添加如下配置:
export JAVA_HOME=/usr/local/src/jdk
配置 core-site.xml 配置文件
[root@master hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
<description>ms</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
配置 hdfs-site.xml 配置文件
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master,slave1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.master</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.slave1</name>
<value>slave1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.master</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.slave1</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/src/hadoop/tmp/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/src/hadoop/tmp/hdfs/dn</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/src/hadoop/tmp/hdfs/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
配置mapred-site.xml配置文件
[root@master ~]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置yarn-site.xml配置文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
配置slaves配置文件
[root@master hadoop]# vi slaves
#删除localhost添加以下
master
slave1
slave2
创建数据存放目录
#namenode、datanode、journalnode 等存放数据的公共目录为/usr/local/src/hadoop/tmp
[root@master hadoop]# mkdir -p /usr/local/src/hadoop//tmp/hdfs/nn,dn,jn
[root@master hadoop]# mkdir -p /usr/local/src/hadoop/tmp/logs
分发文件到其他节点
#分发环境变量文件
[root@master hadoop]# scp -r /etc/profile.d/hadoop.sh slave1:/etc/profile.d/
hadoop.sh 100% 601 496.6KB/s 00:00
[root@master hadoop]# scp -r /etc/profile.d/hadoop.sh slave2:/etc/profile.d/
hadoop.sh 100% 601 314.7KB/s 00:00
#分发hadoop配置目录
[root@master hadoop]# scp -r /usr/local/src/hadoop/ slave1:/usr/local/src/
[root@master hadoop]# scp -r /usr/local/src/hadoop/ slave2:/usr/local/src/
修改目录所有者和所有者组
[root@master ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
生效环境变量
#在切换hadoop用户时会自动导入,为了以防万一,还是手动source一下
[root@master ~]# source /etc/profile.d/hadoop.sh
[root@slave1 ~]# source /etc/profile.d/hadoop.sh
[root@slave2 ~]# source /etc/profile.d/hadoop.sh
HA高可用集群启动
HA的启动
启动journalnode守护进程
#切换hadoop用户
[hadoop@master ~]$ hadoop-daemons.sh start journalnode
master: starting journalnode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-journalnode-master.out
slave1: starting journalnode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-journalnode-slave1.out
slave2: starting journalnode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-journalnode-slave2.out
初始化namenode
[hadoop@master ~]$ hdfs namenode -format
............
23/05/28 13:58:27 INFO namenode.FSImage: Allocated new BlockPoolId: BP-793703415-192.168.88.10-1685253507647
23/05/28 13:58:27 INFO common.Storage: Storage directory /usr/local/src/hadoop/tmp/hdfs/nn has been successfully formatted.
23/05/28 13:58:28 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
23/05/28 13:58:28 INFO util.ExitUtil: Exiting with status 0
23/05/28 13:58:28 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.88.10
************************************************************/
注册ZNode
#要先启动zookeeper不然会报错
[hadoop@master ~]$ zkServer.sh start
[hadoop@slave1 ~]$ zkServer.sh start
[hadoop@slave2 ~]$ zkServer.sh start
[hadoop@master ~]$ hdfs zkfc -formatZK
......
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: Opening socket connection to server slave2/192.168.88.30:2181. Will not attempt to authenticate using SASL (unknown error)
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: Socket connection established to slave2/192.168.88.30:2181, initiating session
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: Session establishment complete on server slave2/192.168.88.30:2181, sessionid = 0x38860f220b90000, negotiated timeout = 30000
23/05/28 14:01:08 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
23/05/28 14:01:08 INFO ha.ActiveStandbyElector: Session connected.
23/05/28 14:01:08 INFO zookeeper.ZooKeeper: Session: 0x38860f220b90000 closed
23/05/28 14:01:08 INFO zookeeper.ClientCnxn: EventThread shut down
启动hdfs
[hadoop@master ~]$ start-all.sh
同步master数据
#复制 namenode 元数据到其它节点(在 master 节点执行)
[hadoop@master ~]$ scp -r /usr/local/src/hadoop/tmp/hdfs/nn/* slave1:/usr/local/src/hadoop/tmp/hdfs/nn/
VERSION 100% 204 189.8KB/s 00:00
seen_txid 100% 2 1.3KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 38.1KB/s 00:00
fsimage_0000000000000000000 100% 353 378.0KB/s 00:00
edits_inprogress_0000000000000000001 100% 1024KB 5.0MB/s 00:00
in_use.lock 100% 11
6.4KB/s 00:00
[hadoop@master ~]$ scp -r /usr/local/src/hadoop/tmp/hdfs/nn/* slave2:/usr/local/src/hadoop/tmp/hdfs/nn/
VERSION 100% 204 294.1KB/s 00:00
seen_txid 100% 2 2.2KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 65.8KB/s 00:00
fsimage_0000000000000000000 100% 353 554.6KB/s 00:00
edits_inprogress_0000000000000000001 100% 1024KB 6.7MB/s 00:00
in_use.lock 100% 11 8.9KB/s 00:00
在slave1上启动resourcemanager和namenode进程
[hadoop@slave1 ~]$ yarn-daemons.sh start resourcemanager
[hadoop@slave1 ~]$ hadoop-daemon.sh start namenode
[hadoop@slave1 ~]$ jps
1489 JournalNode
1841 DFSZKFailoverController
1922 NodeManager
2658 NameNode
2738 Jps
1702 DataNode
2441 ResourceManager
1551 QuorumPeerMain
启动MapReduce任务历史服务器
[hadoop@master ~]$ yarn-daemon.sh start proxyserver
starting proxyserver, logging to /usr/local/src/hadoop/logs/yarn-hadoop-proxyserver-master.out
[hadoop@master ~]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/src/hadoop/logs/mapred-hadoop-historyserver-master.out
查看端口和进程
[hadoop@master ~]$ jps
3297 JobHistoryServer
2260 DataNode
2564 DFSZKFailoverController
2788 NodeManager
2678 ResourceManager
2122 NameNode
3371 Jps
1727 JournalNode
1919 QuorumPeerMain
[hadoop@slave1 ~]$ jps
1489 JournalNode
1841 DFSZKFailoverController
1922 NodeManager
2658 NameNode
2738 Jps
1702 DataNode
2441 ResourceManager
1551 QuorumPeerMain
[hadoop@slave2 ~]$ jps
1792 NodeManager
1577 QuorumPeerMain
2282 Jps
1515 JournalNode
1647 DataNode
查看网页显示
-
master:50070
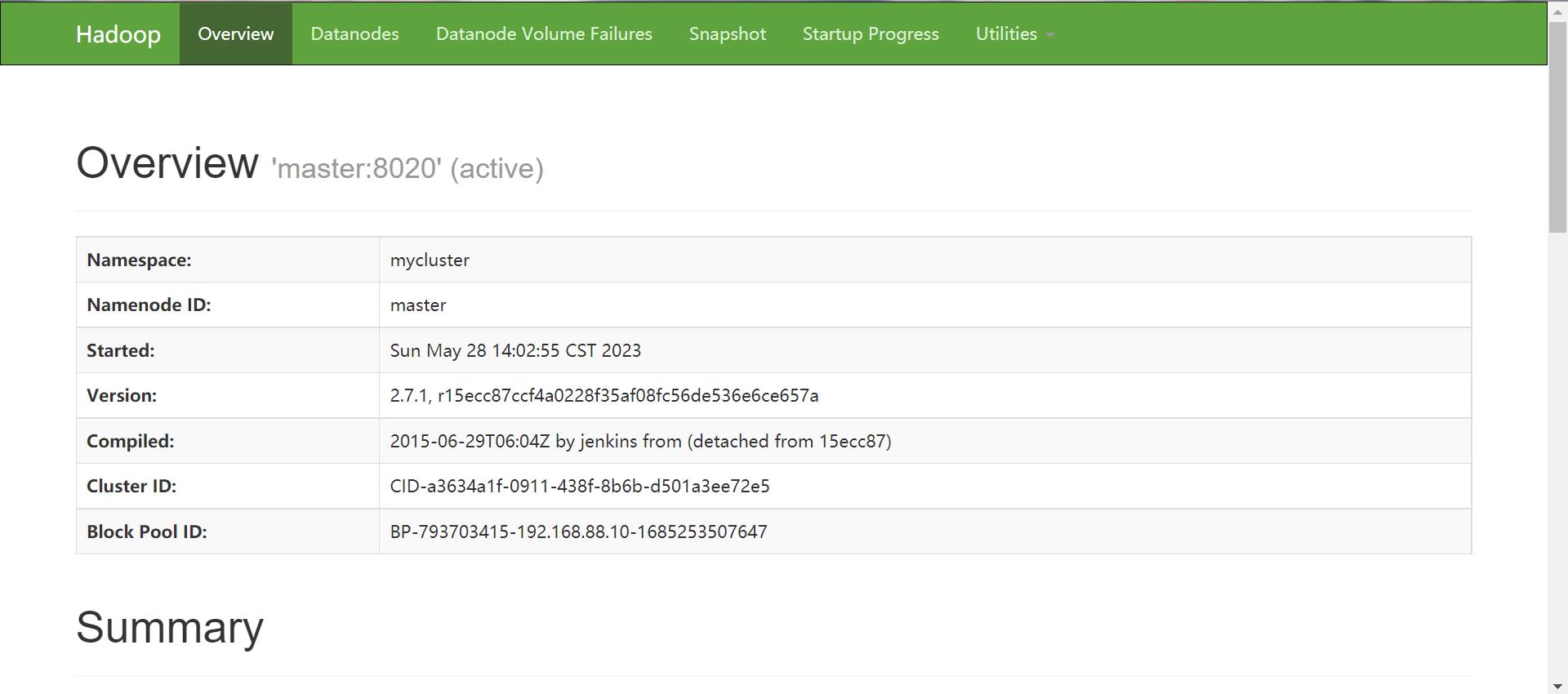
-
slave1:50070
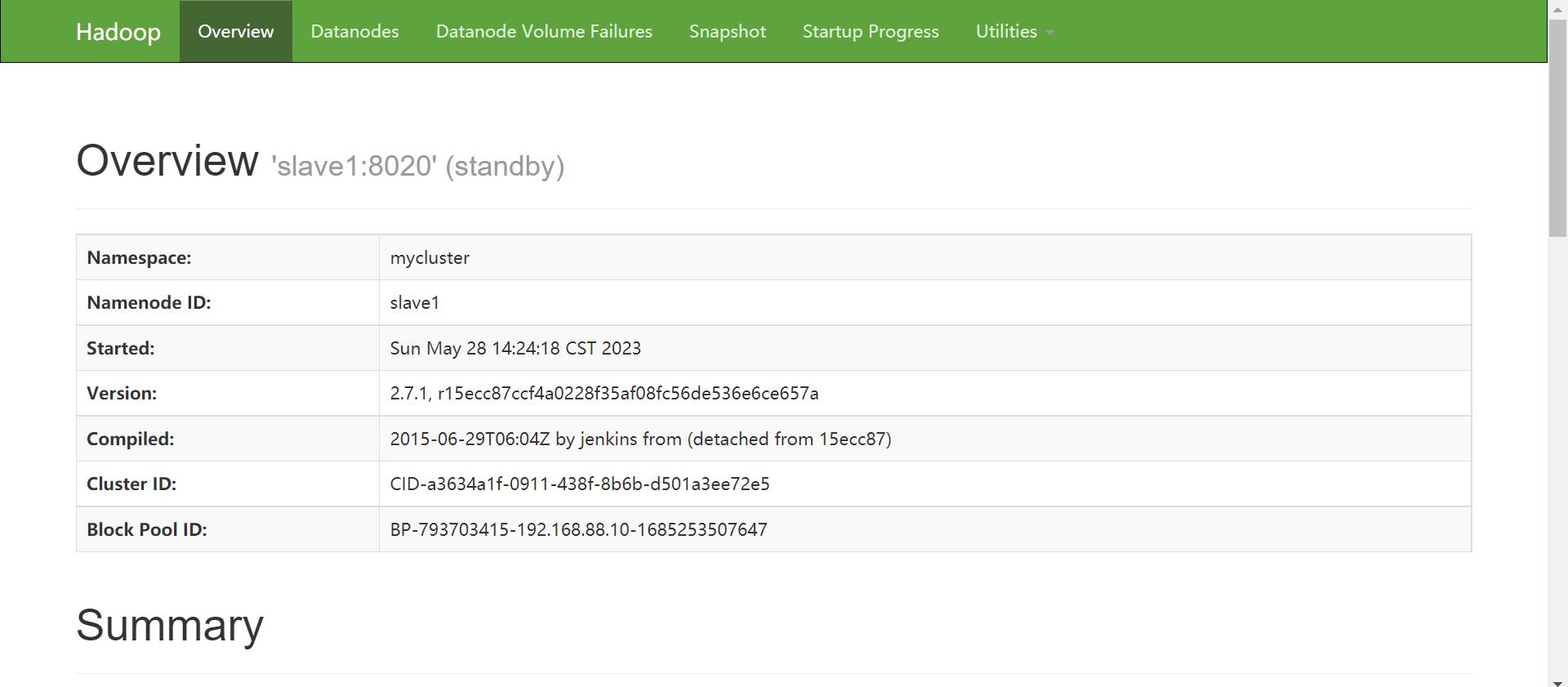
-
master:8088
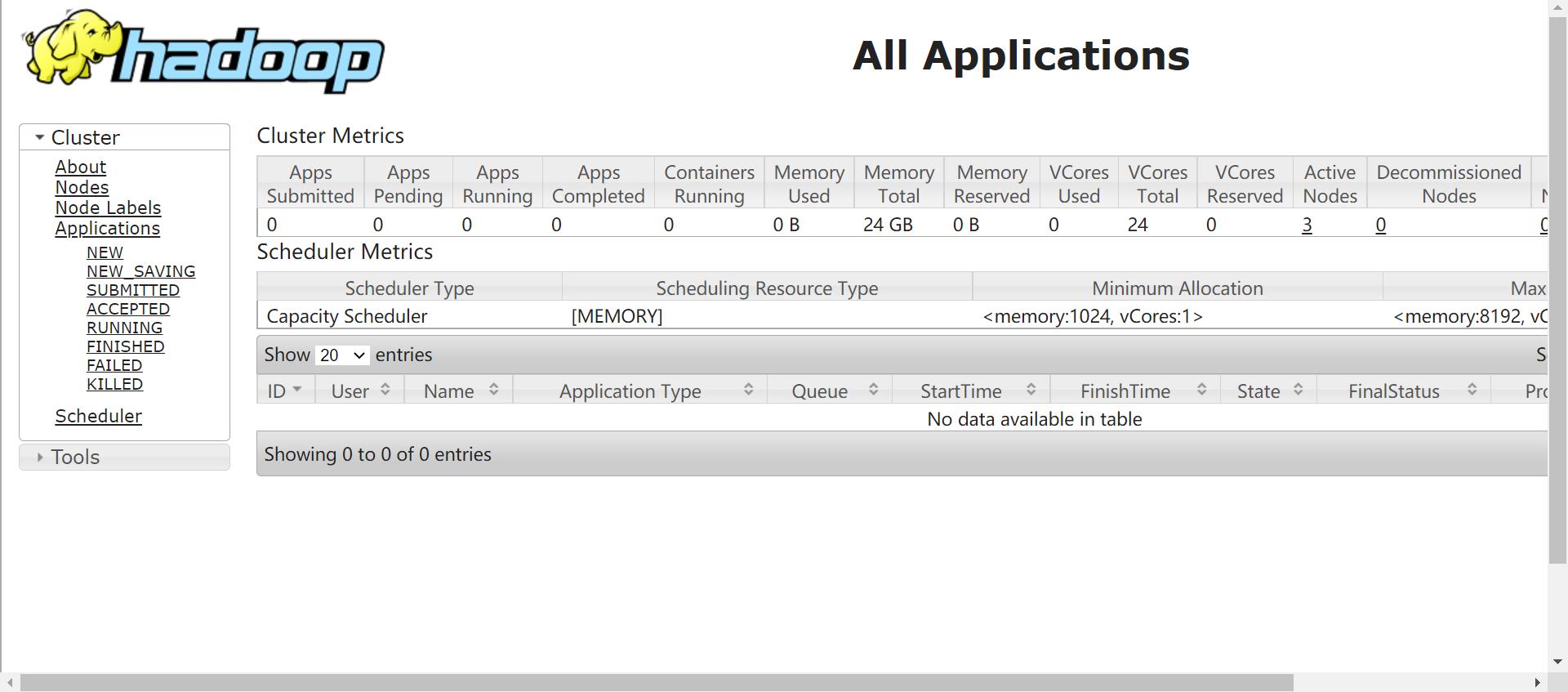
HA的测试
创建一个测试文件
[hadoop@master ~]$ vi rainmom.txt
Hello World
Hello Hadoop
在hdfs创建文件夹
[hadoop@master ~]$ hadoop fs -mkdir /input
将rainmom.txt传输到input上
[hadoop@master ~]$ hadoop fs -put ~/rainmom.txt /input
进入到jar包测试文件目录下,测试mapreduce
[hadoop@master ~]$ cd /usr/local/src/hadoop/share/hadoop/mapreduce/
[hadoop@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input/rainmom.txt /output
.....
23/05/28 14:35:37 INFO mapreduce.Job: Running job: job_1685253795384_0001
23/05/28 14:35:48 INFO mapreduce.Job: Job job_1685253795384_0001 running in uber mode : false
23/05/28 14:35:48 INFO mapreduce.Job: map 0% reduce 0%
23/05/28 14:35:57 INFO mapreduce.Job: map 100% reduce 0%
23/05/28 14:36:09 INFO mapreduce.Job: map 100% reduce 100%
23/05/28 14:36:10 INFO mapreduce.Job: Job job_1685253795384_0001 completed successfully
....
查看hdfs下的传输结果
[hadoop@master ~]$ hadoop fs -ls -R /output
-rw-r--r-- 2 hadoop supergroup 0 2023-05-28 14:36 /output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 25 2023-05-28 14:36 /output/part-r-00000
查看文件测试的结果
[hadoop@master ~]$ hadoop fs -cat /output/part-r-00000
Hadoop 1
Hello 2
World 1
高可用性验证
自动切换服务状态
#格式:hdfs haadmin -failover --forcefence --forceactive 主 备
[hadoop@master ~]$ hdfs haadmin -failover --forcefence --forceactive slave1 master
#这里注意一点,执行这条命令,会出现:forcefence and forceactive flags
not supported with auto-failover enabled.的提示,这句话表示,配置了自动切换之后,就不能进行手动切换了,
故此次切换失败, 该意思是在配置故障自动切换(dfs.ha.automatic-failover.enabled=true)之后,
无法手动进行,可将该参数更改为false(不需要重启进程)后,重新执行该命令即可。
# dfs.ha.automatic-failover.enabled参数需要在hdfs-site.xml或者core-site.xml中修改
[hadoop@master ~]$ vi /usr/local/src/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
#查看状态
[hadoop@master ~]$ hdfs haadmin -getServiceState slave1
standby
[hadoop@master ~]$ hdfs haadmin -getServiceState master
active
手动切换服务状态
#在 maste 停止并启动 namenode
[hadoop@master ~]$ hadoop-daemon.sh stop namenode
stopping namenode
#查看状态
[hadoop@master ~]$ hdfs haadmin -getServiceState master
23/05/28 14:53:55 INFO ipc.Client: Retrying connect to server: master/192.168.88.10:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From master/192.168.88.10 to master:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[hadoop@master ~]$ hdfs haadmin -getServiceState slave1
active
#重新启动
[hadoop@master ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.out
#再次查看状态
[hadoop@master ~]$ hdfs haadmin -getServiceState slave1
active
[hadoop@master ~]$ hdfs haadmin -getServiceState master
standby
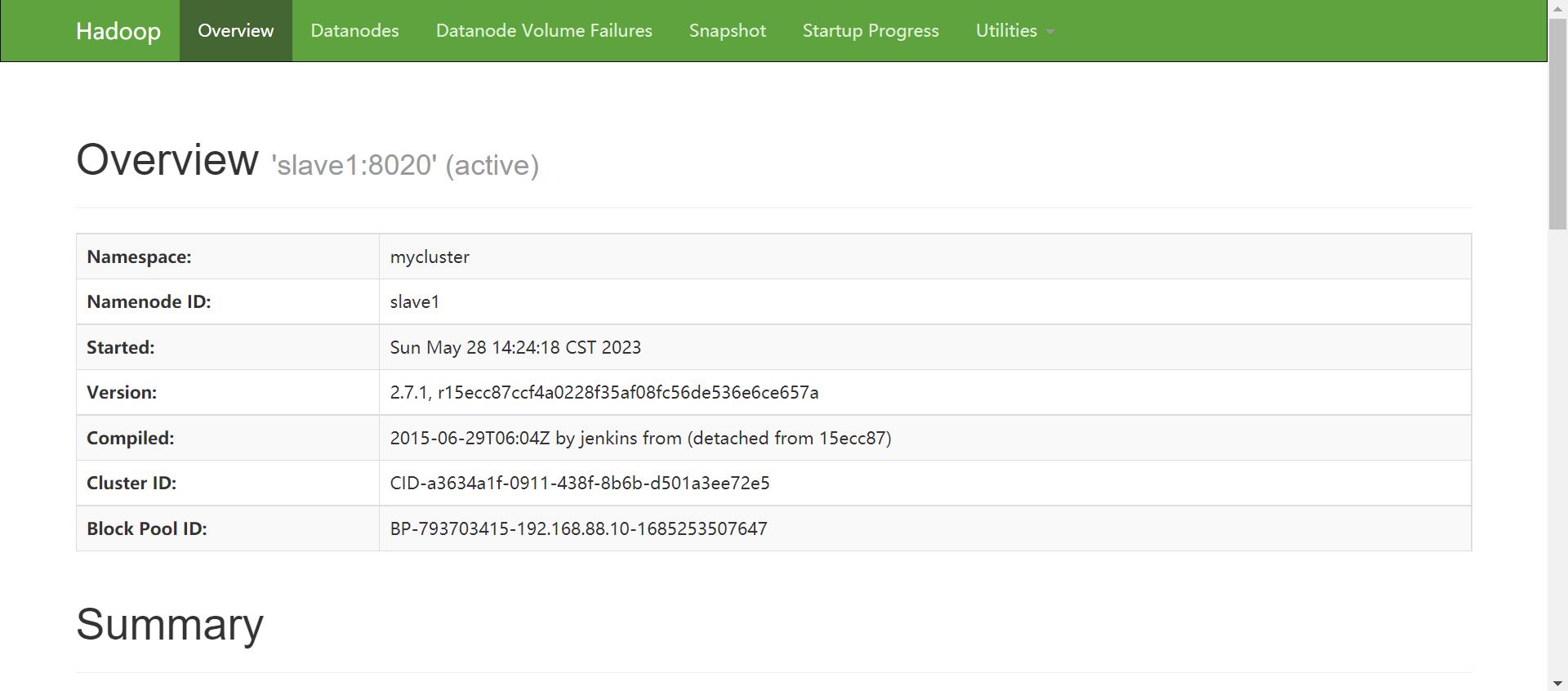
查看web服务端
-
master:50070

-
slave1:50070
Rancher 2.2.2 - HA 部署高可用k8s集群
对于生产环境,需以高可用的配置安装 Rancher,确保用户始终可以访问 Rancher Server。当安装在Kubernetes集群中时,Rancher将与集群的 etcd 集成,并利用Kubernetes 调度实现高可用。
为确保高可用,本文所部署的 Kubernetes 集群将专用于运行 Rancher ,Rancher 运行起来后,可再创建或导入集群以运行具体的工作负载。
一、推荐架构
- Rancher的DNS 应解析到 4层(TCP) 负载均衡上。
- 负载均衡应将端口 TCP/80 和 TCP/443 转发到 Kubernetes 集群中的所有3个节点。
- Ingress-controller 将 HTTP 重定向到HTTPS并终止端口 TCP/443 上的 SSL/TLS(SSL数字证书在这里部署)。
- Ingress-controller 将流量转发到 pod 的 TCP/80 端口。
下面是一张从官网拉过来的图片,更直观一些。

二、准备工作
1. 服务器准备
- 1台 Linux服务器,配置不用很高,用于四层负载均衡
- 3台 Linux服务器,Rancker-server-node 节点
- n台 Linux服务器,Rancker-agent-node 节点(n<=50)
节点服务器的硬件配置,可根据实际情况依据该表自行选择。
| 规模 | 集群 | 节点 | CPU | 内存 |
|---|---|---|---|---|
| 小 | 最多5个 | 高达50 | 2 | 8 GB |
| 中 | 最多15个 | 最多200 | 4 | 16 GB |
| 大 | 高达50 | 最多500个 | 8 | 32 GB |
| 超大 | 最多100个 | 高达1000 | 32 | 128 GB |
| 更大规模 | 100+ | 1000+ | 联系 Rancher | 联系 Rancher |
2.工具安装
这些工具软件将在部署过程中用到,需提前安装好,并确保通过 $PATH 变量可以找到。
安装 kubectl
这是一个 kubernetes 命令行工具,安装参考 K8S 官网
这里要注意的是,官网的安装过程是到谷歌云平台下载,这里我门修改下载链接为 RANCHER 提供的镜像地址。
# 下载目前最新版
wget https://www.cnrancher.com/download/kubernetes/linux-amd64-v1.14.1-kubectl
# 设置执行权限
chmod +x ./linux-amd64-v1.14.1-kubectl
# 将其移动到 /usr/locak/bin/kubectl
sudo mv ./linux-amd64-v1.14.1-kubectl /usr/local/bin/kubectl
安装 RKE
RKE 全称 Rancher Kubernetes Engine,是一个用于构建 kubernets 集群的命令行工具。网络原因,我们切换到 Rancher 提供的镜像地址下载安装
# 下载目前最新版
wget https://www.cnrancher.com/download/rke/v0.1.18-rke_linux-amd64
# 设置执行权限
chmod +x v0.1.18-rke_linux-amd64
# 将其移动到 /usr/locak/bin/kubectl
sudo cp v0.1.18-rke_linux-amd64 /usr/local/bin/rke
# 验证安装
rke --version # rke version v0.1.18
安装 helm
helm 是Kubernetes的包管理器。Helm版本需高于 v2.12.1。
# 网络原因,切换到 Rancher 提供的镜像连接
wget https://www.cnrancher.com/download/helm/helm-v2.13.1-linux-amd64.tar.gz
# 解压
tar -zxvf helm-v2.0.0-linux-amd64.tgz
# 移动到 /usr/local/bin/helm
mv linux-amd64/helm /usr/local/bin/helm
三、创建节点和负载均衡
这些节点须在同一个网络区域或数据中心。
1. 节点准备
操作系统
所有节点安装 ubuntu 18.04(64-bit x86)
网络要求
注意参考 官网放行相关端口。本文 ip 清单(仅用于演示):
| NODE | IP | 备注 |
|---|---|---|
| NODE-LB | 公网 168.168.168.1 / 内网 10.0.0.1 | 四层负载均衡 |
| NODE-SERVER | 公网 168.168.168.6 / 内网 10.0.0.6 | local 集群 |
| NODE-SERVER | 公网 168.168.168.7 / 内网 10.0.0.7 | local 集群 |
| NODE-SERVER | 公网 168.168.168.8 / 内网 10.0.0.8 | local 集群 |
| NODE-WORKER | 公网 168.168.168.16 / 内网 10.0.0.16 | 工作负载 |
| NODE-WORKER | 公网 168.168.168.17 / 内网 10.0.0.17 | 工作负载 |
| NODE-WORKER | 公网 168.168.168.18 / 内网 10.0.0.18 | 工作负载 |
docker-ce
并安装最新stable版 docker-ce:18.09.6
# 删除旧版本docker
sudo apt-get remove docker docker-engine docker.io containerd runc
# 更新 apt
$ sudo apt-get update
# 安装工具包
$ sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
# 添加Docker官方 GPG key
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加 stable apt 源
$ sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 安装 Docker CE
$ sudo apt-get update
$ sudo apt-get install docker-ce docker-ce-cli containerd.io
# 将当前用户加入"docker"用户组,加入到该用户组的账号在随后安装过程会用到。用于节点访问的SSH用户必须是节点上docker组的成员:
$ sudo usermod -aG docker $USER
2. 配置四层负载均衡
RKE 将会在每个节点上配置一个 Ingress-controller pod,这个 pod 将绑定到该节点的 TCP/80 和 TCP/443 端口,作为 Rancher-server 的HTTPS流量入口点。
将负载均衡器配置为基本的第4层TCP转发器,这里采用 NGINX 作四层负载均衡。
*安装 Nginx
sudo apt-get install nginx
# /usr/sbin/nginx:主程序
# /etc/nginx:存放配置文件
# /usr/share/nginx:存放静态文件
# /var/log/nginx:存放日志
更新配置文件 /etc/nginx/nginx.conf
worker_processes 4;
worker_rlimit_nofile 40000;
events {
worker_connections 8192;
}
stream {
upstream rancher_servers_http {
least_conn;
server 10.0.0.6:80 max_fails=3 fail_timeout=5s;
server 10.0.0.7:80 max_fails=3 fail_timeout=5s;
server 10.0.0.8:80 max_fails=3 fail_timeout=5s;
}
server {
listen 80;
proxy_pass rancher_servers_http;
}
upstream rancher_servers_https {
least_conn;
server 10.0.0.6:443 max_fails=3 fail_timeout=5s;
server 10.0.0.7:443 max_fails=3 fail_timeout=5s;
server 10.0.0.8:443 max_fails=3 fail_timeout=5s;
}
server {
listen 443;
proxy_pass rancher_servers_https;
}
}
注意:将local群集专用于Rancher。
勿将此负载均衡(即local群集Ingress)对 Rancher 以外的应用程序进行负载转发。
四、使用 RKE 安装 kubernetes
下面使用 RKE(Kubernetes Engine) 安装高可用的 Kubernetes。
1. NODE-SERVER 之间建立 ssh 信任
我们目前有三台服务器用作 local 集群,首先要确保我们主机能够通过 ssh 访问到另外两台主机并执行相关操作。比如执行 docker 命令,还记得前面我们加入 docker 用户组的用户吧。
# 根据需求配置相关信息生成 rsa 公钥密钥
ssh-keygen
# 复制当前主机上的公钥到另外两台上面,实现免密码登录
ssh-copy-id -i ~/.ssh/id_rsa.pub user@x.x.x.x
# 要注意这里也要跟自己注册注册一下 :ssh-copy-id -i ~/.ssh/id_rsa.pub user@本机ip
2. 编写 rancher-cluster.yml 文件
这里需要注意,这个文件没有明确配置rsa文件名,默认会使用 $HOME/.ssh/id_rsa 建立连接。内容如下
nodes:
- address: 168.168.168.6
internal_address: 10.0.0.6
user: ubuntu
role: [controlplane,worker,etcd]
- address: 168.168.168.7
internal_address: 10.0.0.7
user: ubuntu
role: [controlplane,worker,etcd]
- address: 168.168.168.8
internal_address: 10.0.0.8
user: ubuntu
role: [controlplane,worker,etcd]
services:
etcd:
snapshot: true
creation: 6h
retention: 24h
3. 运行 RKE 构建 kubernetes 集群
rke up --config ./rancher-cluster.yml
# 验证:返回类似下面的消息则说明执行成功,有问题欢迎留言交流。
# Finished building Kubernetes cluster successfully.
执行成功会在当前目录生成一个文件 kube_config_rancher-cluster.yml,将该文件复制到 .kube/kube_config_rancher-cluster.yml。
或者
export KUBECONFIG=$(pwd)/kube_config_rancher-cluster.yml
4. 测试集群
kubectl get nodes
# 返回下面信息说明集群创建成功
NAME STATUS ROLES AGE VERSION
168.168.168.6 Ready controlplane,etcd,worker 13m v1.13.5
168.168.168.7 Ready controlplane,etcd,worker 13m v1.13.5
168.168.168.8 Ready controlplane,etcd,worker 13m v1.13.5
5. 保存好相关配置文件
当排除故障、升级群集时需要用到以下文件,请将其副本保存在一个安全的位置。
rancher-cluster.yml:RKE集群配置文件。kube_config_rancher-cluster.yml:群集的Kubeconfig文件,此文件包含完全访问群集的凭据。rancher-cluster.rkestate:Kubernetes群集状态文件,此文件包含完全访问群集的凭据。
6. 初始化 Helm
一开始,我们安装了 Helm ,Helm 是 Kubernetes 首选的包管理工具。为了能够使用 Helm,需要在群集上安装服务器端组件 tiller。
Kubernetes APIServer 开启了 RBAC 访问控制,所以需要创建 tiller 使用的service account: tiller 并分配合适的角色给它。
# 在 kube-system 命名空间下创建一个 serviceaccount ,并将角色绑定给 tiller
kubectl -n kube-system create serviceaccount tiller
# 然后, heml 就可以在集群上安装 tiller 了
# 同样,网络原因,我们需要配置一个镜像仓库地址
helm init --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.13.1 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 输出:$HELM_HOME has been configured at /home/ubuntu/.helm.
7. 测试 tiller 安装是否成功
kubectl -n kube-system rollout status deploy/tiller-deploy
# 输出 deployment "tiller-deploy" successfully rolled out
helm version
# Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
# Server: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
五、安装 Rancher
这里注意选择 stable 版本,首先添加 heml 源仓库。
helm repo add rancher-stable https://releases.rancher.com/server-charts/stable
1. 部署 Rancher 并配置 SSL 数字证书
helm install rancher-stable/rancher --name rancher --namespace cattle-system --set hostname=cloud.jfjbapp.cn --set ingress.tls.source=secret
2. 将通过 CA 机构签发的数字证书准备好,
3. 检查 rancher 是否成功可用
kubectl -n cattle-system rollout status deploy/rancher
Waiting for deployment "rancher" rollout to finish: 0 of 3 updated replicas are available...
deployment "rancher" successfully rolled out
4. 访问 Rancher UI
浏览器打开 https://your.doamin,为 admin账户设置初始密码,并登入系统。提示设置server-url,确保你的地址无误,确认即可。随后稍等皮片刻,待系统完成初始化。
如果出现local集群一直停留在等待状态,并提示 Waiting for server-url setting to be set,可以尝试点击 全局->local->升级->添加一个成员角色(admin/ClusterOwner)->保存即可。
六、结语
至此,已完成 Rancher 2.2.2 的 HA 安装,后续再做一些安全加固,检查各项配置确保无安全风险,即可开始提供服务。随后会抽空再写一篇文章简单介绍微服务架构应用的部署。
以上是关于HA高可用集群部署的主要内容,如果未能解决你的问题,请参考以下文章