算术和逻辑运算指令
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算术和逻辑运算指令相关的知识,希望对你有一定的参考价值。
算术和逻辑运算指令
算术和逻辑指令
1. 算术和逻辑指令
首先增加了更多的 Cpu0 算术运算指令和逻辑运算指令,这些在各个优化步骤中存在的 DAG 转换过程可以使用 Graphviz 来图形化显示,展示出更多的有效信息。不同于上一节,在中,应该专注于 C 代码的操作和 llvm IR 之间的映射以及如何在 td 文件中描述更复杂的 IR 与指令。定义了另外一些寄存器类,需要了解为什么需要它们,如果有些设计没有看懂,可能是对 Cpu0 的硬件不够熟悉,可以结合硬件来理解。
2. 算术运算
1. 简要说明
(1) 乘法和移位运算
C 语言中的加法(+)、减法(-)和乘法(*)运算符通过 add,addu,sub,subu 和 mul 指令来实现,左移(<<) 和右移(>>) 运算符通过 shl,shlv,sra,srav,shr,shrv 指令来实现。C 语言中右移负数位数操作的原语(比如右移 -1 位)是基于实现的,大多数编译器会将其翻译为算术右移。
对应到 llvm IR 中的指令分别是 add,sub,mul,shl,ashr,lshr 等,ashr 表示算术右移,或者说是符号扩展右移;lshr 表示逻辑右移,或者说是零扩展右移。不过,在 DAG node 中,使用 sra 表示 ashr 的 IR 指令,使用 srl 表示 lshr 的 IR 指令,看起来不是很直观,可能是历史设计的问题。
右移操作在不同的阶段的符号表示对应如:
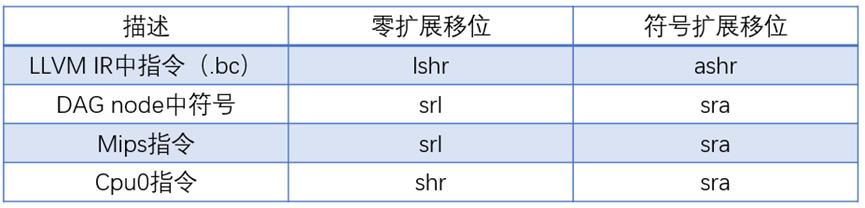
如果认为右移 1 位等效于对右移数字除以 2,在逻辑右移中,对于一些有符号数,结果有可能是错的;在算术右移中,对于一些无符号数,结果也是错的。同理,对于左移操作,也不能单纯的用乘除法取代。比如,有符号数 0xfffffffe(-2)做逻辑右移,得到 0x7fffffff(2G-1),期望得到 -1,却得到一个大数;无符号数 0xfffffffe(4G-2)做算术右移,得到 0xffffffff(4G-1),期望得到 2G-1,却得到 4G-1;有符号的 0x40000000(1G)做逻辑左移,是 0x80000000(-2G),期望的应该是 2G 却得到了 -2G。所以不能用乘除法指令来替代移位指令,必须要设计专用的硬件移位指令。
(2) 除法和求余运算
llvm IR 中的除法是 sdiv 和 udiv 指令,不必多言。求余是 srem 和 urem 指令,这个指令接受一个整型值作为操作数(也可以是整形值元素的向量),它返回一个除法操作的余数。通常情况下数学上有多种对余数的定义,比如最接近 0 的那个余数,或者最接近负无穷大的那个余数,这里的余数定义是与被除数(第一个操作数)一致符号的余数(或能整除时为 0)。srem 是有符号数的求余,urem 是无符号数的求余指令。
除 0 后的余数是未定义行为,除法溢出也是未定义行为,和硬件实现相关。
LLVM 默认会把 带立即数的 除法和求余操作通过一个算法转换为利用有符号高位乘法 mulhs 来实现,但目前没有 mulhs,所以这个通路有问题。(LLVM 这么做的原因是,乘法操作在硬件上通常比除法操作更省资源,所以会尽量把除法转换成乘法来做)
为了支持 mulhs 这种操作,Mips 的做法是用 mult 指令(硬件指令)来将乘法运算结果的高 32 位放到 HI 寄存器,将低 32 位结果放到 LO 寄存器。然后使用 mfhi 和 mflo 硬件指令来将两部分结果移动到通用寄存器中。Cpu0 也在这块采用这种实现方式。
llvm DAG node 中定义了 mulhs 和 mulhu,需要在 DAGToDAG 指令选择期间,将其转换为 mult + mfhi 的动作,这就是接下来实现 selectMULT() 函数的一部分功能。只有将 llvm IR 期间的 mulhs / mulhu 替换为 Cpu0 硬件支持的操作,才不会在后续报错(另外,如果后端能够直接支持 mulh 指令是最好的,但 Cpu0 没有支持)。
然后,来讨论一下如果求余操作的操作数不是立即数的情况。这时,LLVM 就会乖乖的生成除法求余的 node 了,这个 node 是 ISD::SDIVREM 和 ISD::UDIVREM,是除法和求余操作统一的 node。刚好 Cpu0 支持一个 div 指令,这个指令的功能是将一个除法操作的商放到 LO 寄存器,将余数(满足上边说的那种规则的余数)放到 HI 寄存器。只需要使用 mfhi 和 mflo 指令将这两部分按需求取出来就好。
求余操作在不同阶段的符号表示如:
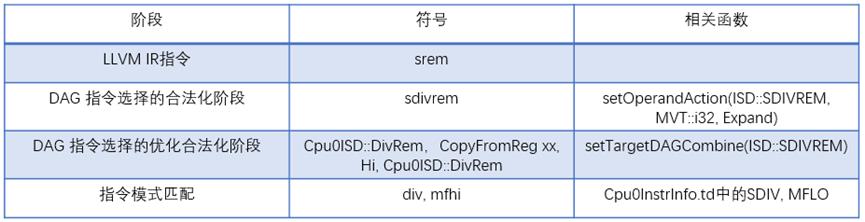
在Cpu0ISelLowering.cpp 中,注册了 setOperationAction(ISD::SREM, MVT::i32, Expand) 等操作,将 ISD::SREM lowering 到 ISD::SDIVREM(有关于 Expand 的参考资料,可以查看 http://llvm.org/docs/WritingAnLLVMBackend.html#expand)。然后实现了 PerformDAGCombine() 函数,将 ISD::SDIVREM 根据它是除法还是求余(通过 SDNode->hasAnyUseOfValue(0) 来判断)操作,选择生成 div + mflo / mfhi 的 机器相关的 DAG,进而指令选择到机器汇编指令。
2. 文件修改
(1) Cpu0Subtarget.cpp
这个文件中新增了一个控制溢出处理方式的命令行选项:-cpu0-enable-overflow,默认是 false,如果在调用 llc 时的命令行中使用这个选项,则为 true。false 时,表示当算术运算出现溢出时,会触发 overflow 异常,true 时,表示算术运算出现溢出时,会截断运算结果。将 add 和 sub 指令设计为溢出时触发 overflow 异常,把 addu 和 subu 设计为不会触发异常,而是截断结果。
在 subtarget 中,将命令行选项的结果传入 EnableOverflow 类属性。
(2) Cpu0InstrInfo.td
新增了不少指令和节点的描述。
四则运算指令 subu,add,sub,mul,mult,multu,div,divu,其中 mult 和 mul 的区别是,mult 可以处理 64 位运算结果,为了能保存 64 位结果,Cpu0 引入两个寄存器 Hi 和 Lo,专用于保存 mult 的高 32 位和低 32 位运算结果(当然它还可以保存 div 的商和余数)。mult 和 multu 表示对符号扩展的值和对零扩展的值分别处理。
移位指令 rol,ror,sra,shr,srav,shlv,shrv,rolv,rorv,因为移位需要考虑是否是循环移位、逻辑移位还是算术移位等问题,所以衍生出多个指令,带 v 结尾的指令表示移位值存在寄存器中作为操作数。
其他辅助指令 mfhi,mflo,mthi,mtlo,mfc0,mtc0,c0mov,为了能将乘除法的结果返回到寄存器,需要提供 Hi 和 Lo 寄存器与通用寄存器之间的 move。C0 是一个协处理寄存器,目前还没有用途,一并实现。
(3) Cpu0ISelLowering.h/.cpp
在这里特殊处理除法和求余运算的 lowering 操作,实现了一个 performDivRemCombine 动作,这是因为在 DAG 中,除法和求余的节点是同一个节点,叫 ISD::SDIVREM,节点中有个值来表示这个节点是计算商还是计算余数,虽然 Cpu0 后端本身并不关心要计算哪个值,因为都是通过 div 来计算的,但 DAG 一级还是会根据 C 代码的逻辑来区分的。当然输出也需要考虑把哪个值(Hi 或 Lo)返回。div 运算会将商放到 Lo 寄存器,将余数放到 Hi 寄存器。
这里还设计了类型合法化的声明,使用 setOperationAction 函数,指定将 div 和 rem 在对 i32 类型下的操作做 expand,其实是指定使用 LLVM 内置的函数来展开实现(位于 TargetLowering.cpp 中)。
(4) Cpu0RegisterInfo.td
实现了 Hi 和 Lo 寄存器,以及 HILO 寄存器组。
(5) Cpu0Schedule.td
实现了乘除法和 HILO 操作的指令行程类。
(6) Cpu0SEISelDAGToDAG.h/.cpp
实现了 selectMULT() 函数,用来处理乘法的高低位运算。在 ISD 中的乘法是区分 MUL 和 MULH 的,也就是用两个不同的 Node 来分别处理乘法返回低 32 位和高 32 位。
selectMULT() 会放到 trySelect() 接口函数中,专用来处理 MULH 的特殊情况,并将 Hi 作为返回值创建新的 Node。
(7) Cpu0SEInstrInfo.h/.cpp
实现了 copyPhysReg() 函数,用来生成一些寄存器 move 的操作,会根据要移动的寄存器类型,生成不同的指令来处理。这个函数是基类的虚函数,直接覆盖实现,不需要考虑调用问题。
如果目的寄存器和源寄存器都是通用寄存器,会使用 addu 来完成,这是一种通用做法。如果源寄存器是 Hi 或 Lo,会选择生成 mfhi 或 mflo 来处理。反之,如果目的寄存器是 Hi 或 Lo,会选择生成 mthi 和 mtlo 来处理。
这里作为最后的指令选择阶段,会使用 BuildMI 直接生成 MI 结构。
3. 检验成果
构建编译器之后。执行(test.ll 换成具体文件名):
clang -target mips-unknown-linux-gnu test.c -emit-llvm -S -o test.ll
观察 llvm IR 的结果。执行:
llc -march=cpu0 -relocation-model=pic -filetype=asm test.ll -o test.s
观察输出汇编的结果。
1)乘法和移位操作
提供了一个 ch3_1_math.c 的例子,可以查看加减乘除法和移位运算符的输出结果。
对于将变量移位一个字面常量的位数的操作(如 a >> 2),会 lowering 为带立即数操作数的移位操作;对于将字面常量移位一个变量指定的位数的操作,(如 1 << b),会 lowering 为带寄存器操作数的移位操作,并将字面常量通过 addi 移入要移位的寄存器中。
记得 -cpu0-enable-overflow 编译选项,它可以让编译器生成 addu 和 subu指令(这两个指令是会截断加减法结果的)或者 add 和 sub(这两个指令是会抛出溢出错误的)。
使用 ch3_1_addsuboverflow.c 示例,不加该选项(默认是 false),可以查看汇编代码中,是否生成了 addu 和 subu 指令。然后执行:
llc -march=cpu0 -relocation-model=pic -filetype=asm -cpu0-enable-overflow=true ch3_1_addsuboverflow.ll -o ch3_1_addsuboverflow.s
再次查看汇编输出,发现生成了 add 和 sub 来替代 addu 和 subu。
现代 CPU 中的习惯做法是使用截断上溢的加减法。不过,提供了这个选项,就可以允许程序员生成需要抛出溢出异常的加减法,这可能有助于调试程序和修复 bug。
编译 ch3_1_rotate.c 这个例子,clang 会将某种 c 语言的组合解析为循环移位(如 (a << 30) | (a >> 2) 这种)。最后的汇编代码中会生成 rol 指令。
不过,对于 rolv 和 rorv 这两个指令,因为它们依赖于逻辑运算 or 指令来做后续的数值运算,所以当前还无法测试,也就是说,移位操作是寄存器的逻辑代码(如 (a << n) | (a >> (32 - n))),还无法正常输出汇编指令。实现了下一小节内容之后,可以再回来测试这块功能。
2)除法和求余操作
先执行一下 ch3_1_mult_mod.c 这个例子,这个例子中是个求余操作,但因为上边叙述的,LLVM 对待字面常量的输入做求余时,会转换成乘法来执行,所以这个例子的汇编输出将会是 mult 和 mul 来实现的求余动作。
然后再看一下 ch3_1_mod.c 这个例子,将字面常量替换成一个变量,查看汇编输出,会发现使用了 div 来实现求余动作。需要注意的是,编译器在开优化的情况下,会做常量传播优化,将变量直接替换为立即数,并再次通过 mult 和 mul 来实现。可以使用 volatile 来修饰变量,从而避免编译器优化。
同理可以再试一下 ch3_1_mult_div.c 和 ch3_1_div.c 这两个例子,可以得到类似的结果。
3. 逻辑运算
新增一些逻辑运算,比如位运算 &, |, ^, ! 和比较运算 ==, !=, <, <=, >, >=。实现部分并不复杂。
1. 简要说明
需要说明的一个设计是,在 cpu032I 中使用 cmp 指令完成比较操作,但在 cpu032II 中使用 slt 指令作为替代,slt 指令比 cmp 指令有优势,它使用通用寄存器来代替 $sw 寄存器,能够使用更少的指令来完成比较运算。
比较运算 cmp 指令返回的值是 $sw 寄存器编码值,所以要针对需要做一次转换,比如说要计算 a < b,指令中是 cmp $sw, a, b,要将 $sw 中的值分析出来,并最终将比较结果放到一个新的寄存器中。
虽然 slt 指令返回一个普通寄存器的值,但因为它计算的是小于的结果,所以如果需要计算 a >= b,那就要对其结果做取反的运算。这种操作会在下边详细叙述。
以下是比较运算的 LLVM IR、DAG node 和汇编的两种实现:
1.等于 ==
LLVM IR:
%cmp = icmp eq i32 %0, %1
%conv = zext i1 %cmp to i32
DAG node:
%cmp = (setcc %0, %1, seteq)
and %cmp, 1
汇编:
// cpu032I
cmp $sw, $3, $2
andi $2, $sw, 2
shr $2, $2, 1
andi $2, $2, 1
// cpu032II
xor $2, $3, $2
sltiu $2, $2, 1
andi $2, $2, 1
2.不等于 !=
LLVM IR:
%cmp = icmp ne i32 %0, %1
%conv = zext i1 %cmp to i32
DAG node:
%cmp = (setcc %0, %1, setne)
and %cmp, 1
汇编:
// cpu032I
cmp %sw, $3, $2
andi $2, $sw, 2
shr $2, $2, 1
xori $2, $2, 1
andi $2, $2, 1
// cpu032II
xor $2, $3, $2
sltu $2, $zero, $2
andi $2, $2, 1
3.小于 <
LLVM IR:
%cmp = icmp lt i32 %0, %1
%conv = zext i1 %cmp to i32
DAG node:
%cmp = (setcc %0, %1, setlt)
and %cmp, 1
汇编:
// cpu032I
cmp $sw, $3, $2
andi $2, $sw, 1
andi $2, $2, 1
// cpu032II
slt $2, $3, $2
andi $2, $2, 1
4.小于等于 <=
LLVM IR:
%cmp = icmp le i32 %0, %1
%conv = zext i1 %cmp to i32
DAG node:
%cmp = (setcc %0, %1, setle)
and %cmp, 1
汇编:
// cpu032I
cmp $sw, $2, $3
andi $2, $sw, 1
xori $2, $2, 1
andi $2, $2, 1
// cpu032II
slt $2, $3, $2
xori $2, $2, 1
andi $2, $2, 1
5.大于 >
LLVM IR:
%cmp = icmp gt i32 %0, %1
%conv = zext i1 %cmp to i32
DAG node:
%cmp = (setcc %0, %1, setgt)
and %cmp, 1
汇编:
// cpu032I
cmp $sw, $2, $3
andi $2, $sw, 1
andi $2, $2, 1
// cpu032II
slt $2, $3, $2
andi $2, $2, 1
6.大于等于 >=
LLVM IR:
%cmp = icmp ge i32 %0, %1
%conv = zext i1 %cmp to i32
DAG node:
%cmp = (setcc %0, %1, setle)
and %cmp, 1
汇编:
// cpu032I
cmp $sw, $3, $2
andi $2, $sw, 1
xori $2, $2, 1
andi $2, $2, 1
// cpu032II
slt $2, $3, $2
xori $2, $2, 1
andi $2, $2, 1
2. 文件修改
1)Cpu0InstrInfo.td
针对这些逻辑运算设计它们的 pattern 等信息。
这里反复使用了一个 Pat 类,这个类用来将一个 node 操作和一个或一组指令关联起来(通常用于窥孔优化)。
特殊处理的比较操作,会对应到一组指令中。举个例子,使用 cmp 来计算 a == b,那么首先,使用 cmp $sw, a, b 将比较结果的 flag 放到 $sw 寄存器中,$sw 寄存器的最低两位分别是 Z (bit 1)和 N (bit 0),如果 a 与 b 相等,那么 Z = 1, N = 0,如果 a 与 b 不相等,那么 Z = 1, N 可为 0 或 1。这样,后边只需要对 $sw 寄存器做与 0b10 的与运算,提取这两位,然后右移 1 位拿到 Z 的值,它的值赋给另一个寄存器,这便是 a == b 的结果。
再举个 slt 的例子,使用 slt 计算 a <= b,因为 slt 返回的结果是 a < b 的结果,所以将两个操作数交换,先使用 slt res, b, a 计算 b < a,将结果 res 再做一次与 0b1 的异或操作,结果调转,就得到了 a <= b 的结果。
将两种比较的方式都实现,并在 def 时使用 HasSlt 和 HasCmp 来选择定义。
Cpu032II 中是同时包含有 slt 和 cmp 指令的,但默认是优先选择 slt 指令。其小于运算不需要做这种映射,因为 slt 指令本身就是计算小于结果的。
2)Cpu0ISelLowering.cpp
声明了类型合法化的方案,Cpu0 无法处理 sext_inreg,将其替换为 shl/sra 操作。
3. 检验成果
首先是逻辑运算,使用示例程序 ch3_2_logic.c 进行编译,检查汇编输出。
build/bin/clang -target mips-unknown-linux-gnu -c ch4_2_logic.cpp -emit-llvm -o ch4_2_logic.bc
build/bin/llc -march=cpu0 -mcpu=cpu032I -relocation-model=pic -filetype=asm ch4_2_logic.bc -o -
当指定 -mcpu=cpu032I 时,汇编输出的内容中,实现比较操作的是 cmp 指令。
build/bin/llc -march=cpu0 -mcpu=cpu032II -relocation-model=pic -filetype=asm ch4_2_logic.bc -o -
4. 小结
增加了 20 多条算术和逻辑运算指令,增加了大概几百行代码。
CPU类
CPU:执行算术运算或者逻辑运算时,常将源操作数和结果暂存在-( 累加器 (AC) )中。
在程序运行过程中,CPU需要将指令从内存中取出并加以分析和执行。CPU依据( 指令和数据的寻址方式 )来区分在内存中以二进制编码形式存放的指令和数据。
属于CPU中算术逻辑单元的部件是( 加法器 )。
在CPU中,常用来为ALU执行算术逻辑运算提供数据并暂存运算结果的寄存器是( 累加寄存器 )。
指令寄存器的位数取决于( 指令字长 )
在CPU中,( 控制器 )不仅要保证指令的正确执行,还要能够处理异常事件。
若某条无条件转移汇编指令采用直接寻址,则该指令的功能是将指令中的地址码送入( PC (程序计数器) )。
在CPU中用于跟踪指令地址的寄存器是( 程序计数器(PC) )。
以下关于CPU的叙述中,错误的是( 程序计数器PC除了存放指令地址,也可以临时存储算术/逻辑运算结果 ) 。
在程序的执行过程中, Cache与主存的地址映射是由( 硬件自动 )完成的。注:(主存即使内存的意思)
在程序执行过程中,Cache与主存的地址映像由( 硬件自动完成 )
位于CPU与主存之间的高速缓冲存储器(Cache)用于存放部分主存数据的拷贝, 主存地址与Cache地址之间的转换工作由( 硬件 )完成。
在程序的执行过程中,Cache与主存的地址映像由( 专门的硬件自动完成 ).
计算机中CPU对其访问速度最快的是 ( 通用寄存器 ) 。
以下关于Cache的叙述中,正确的是( Cache的设计思想是在合理成本下提高命中率 )。
以上是关于算术和逻辑运算指令的主要内容,如果未能解决你的问题,请参考以下文章