尚硅谷Hadoop的WordCount案例实操练习出现的bug
Posted 辰南以北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了尚硅谷Hadoop的WordCount案例实操练习出现的bug相关的知识,希望对你有一定的参考价值。
报错日志和exception如下:
点击查看代码
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/D:/Environment/RepMaven/org/slf4j/slf4j-reload4j/1.7.36/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/D:/Environment/RepMaven/org/slf4j/slf4j-log4j12/1.7.30/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory]
2023-05-26 13:55:26,083 WARN [org.apache.hadoop.util.NativeCodeLoader] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-05-26 13:55:26,580 WARN [org.apache.hadoop.metrics2.impl.MetricsConfig] - Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2023-05-26 13:55:26,783 INFO [org.apache.hadoop.metrics2.impl.MetricsSystemImpl] - Scheduled Metric snapshot period at 10 second(s).
2023-05-26 13:55:26,783 INFO [org.apache.hadoop.metrics2.impl.MetricsSystemImpl] - JobTracker metrics system started
2023-05-26 13:55:27,228 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-05-26 13:55:27,351 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2023-05-26 13:55:27,383 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Cleaning up the staging area file:/tmp/hadoop/mapred/staging/yeqiu523558444/.staging/job_local523558444_0001
Exception in thread "main" java.lang.UnsatisfiedLinkError: \'boolean org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(java.lang.String, int)\'
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:793)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1249)
at org.apache.hadoop.fs.FileUtil.list(FileUtil.java:1454)
at org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:601)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1972)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:2014)
at org.apache.hadoop.fs.FileSystem$4.<init>(FileSystem.java:2180)
at org.apache.hadoop.fs.FileSystem.listLocatedStatus(FileSystem.java:2179)
at org.apache.hadoop.fs.ChecksumFileSystem.listLocatedStatus(ChecksumFileSystem.java:783)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:320)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:279)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:404)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:310)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:327)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:200)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1571)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1568)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:712)
at java.base/javax.security.auth.Subject.doAs(Subject.java:439)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1878)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1568)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1589)
at com.atgui.mapreduce.wordcount.WordCountDriver.main(WordCountDriver.java:47)
点击查看代码
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
点击查看代码
package com.atgui.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException
// 1 获取一行
// atguigu atguigu
String line = value.toString();
// 2 切割
// atguigu
// atguigu
String[] words = line.split(" ");
// 3 循环写出
for (String word : words)
// 封装outK
outK.set(word);
// 写出
context.write(outK, outV);
点击查看代码
package com.atgui.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import org.w3c.dom.Text;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable>
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException
int sum = 0;
// atguigu,(1,1)
for (IntWritable value : values)
sum += value.get();
outV.set(sum);
// 写出
context.write(key, outV);
点击查看代码
package com.atgui.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver
// static
// try
// System.load("D:\\\\Environment\\\\hadoop-3.1.0\\\\bin\\\\hadoop.dll");
// catch (UnsatisfiedLinkError e)
// System.err.println("Native code library failed to load.\\n" + e);
// System.exit(1);
//
//
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\\\Environment\\\\input\\\\inputword"));
FileOutputFormat.setOutputPath(job,new Path("D:\\\\Environment\\\\hadoop\\\\output1"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result? 0 : 1);
询问Claude,回答如下:
这个错误是由于WordCount程序在Windows系统上运行时,尝试调用了Hadoop的NativeIO类的access0方法,但无法找到正确的JNI库导致的UnsatisfiedLinkError异常。
NativeIO类是Hadoop用来执行一些本地文件操作的类,它依赖于JNI来调用Windows的API。在Windows上运行Hadoop程序时,需要从Hadoop发行包中copy出对应的winutils.exe和hadoop.dll两个文件,并设置相关环境变量,Hadoop程序才能正确加载这两个文件,执行本地文件操作。
所以,导致这个错误的原因是:
-
没有从Hadoop发行包中获取winutils.exe和hadoop.dll两个文件。
-
获取了这两个文件,但环境变量设置不正确,Hadoop无法加载它们。
解决方案:在你的driver类中加下面代码,如果可以执行就说明是hadoop.dll的问题
static
try
System.load("D:\\\\Environment\\\\hadoop-3.1.0\\\\bin\\\\hadoop.dll");
catch (UnsatisfiedLinkError e)
System.err.println("Native code library failed to load.\\n" + e);
System.exit(1);
尚硅谷大数据Hadoop教程-笔记02HDFS
视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优)
- 尚硅谷大数据Hadoop教程-笔记01【入门】
- 尚硅谷大数据Hadoop教程-笔记02【HDFS】
- 尚硅谷大数据Hadoop教程-笔记03【MapReduce】
- 尚硅谷大数据Hadoop教程-笔记04【Yarn】
- 尚硅谷大数据Hadoop教程-笔记04【生产调优手册】
- 尚硅谷大数据Hadoop教程-笔记04【源码解析】
目录
P039【039_尚硅谷_Hadoop_HDFS_课程介绍】04:23
P040【040_尚硅谷_Hadoop_HDFS_产生背景和定义】04:11
P041【041_尚硅谷_Hadoop_HDFS_优缺点】05:28
P042【042_尚硅谷_Hadoop_HDFS_组成】09:09
P043【043_尚硅谷_Hadoop_HDFS_文件块大小】08:01
P044【044_尚硅谷_Hadoop_HDFS_Shell命令上传】09:48
P045【045_尚硅谷_Hadoop_HDFS_Shell命令下载&直接操作】16:41
P046【046_尚硅谷_Hadoop_HDFS_API环境准备】08:20
P047【047_尚硅谷_Hadoop_HDFS_API创建文件夹】10:54
P048【048_尚硅谷_Hadoop_HDFS_API上传】06:42
P049【049_尚硅谷_Hadoop_HDFS_API参数的优先级】05:08
P050【050_尚硅谷_Hadoop_HDFS_API文件下载】08:24
P051【051_尚硅谷_Hadoop_HDFS_API文件删除】04:12
P052【052_尚硅谷_Hadoop_HDFS_API文件更名和移动】05:03
P053【053_尚硅谷_Hadoop_HDFS_API文件详情查看】07:57
P054【054_尚硅谷_Hadoop_HDFS_API文件和文件夹判断】03:20
P055【055_尚硅谷_Hadoop_HDFS_写数据流程】11:38
P056【056_尚硅谷_Hadoop_HDFS_节点距离计算】04:31
P057【057_尚硅谷_Hadoop_HDFS_机架感知(副本存储节点选择)】06:07
P058【058_尚硅谷_Hadoop_HDFS_读数据流程】05:04
P059【059_尚硅谷_Hadoop_HDFS_NN和2NN工作机制】13:28
P060【060_尚硅谷_Hadoop_HDFS_FsImage镜像文件】09:33
P061【061_尚硅谷_Hadoop_HDFS_Edits编辑日志】04:49
P062【062_尚硅谷_Hadoop_HDFS_检查点时间设置】
P063【063_尚硅谷_Hadoop_HDFS_DN工作机制】07:36
P064【064_尚硅谷_Hadoop_HDFS_数据完整性】07:07
P065【065_尚硅谷_Hadoop_HDFS_掉线时限参数设置】04:44
P066【066_尚硅谷_Hadoop_HDFS_总结】03:44
03_尚硅谷大数据技术之Hadoop(HDFS)V3.3
P039【039_尚硅谷_Hadoop_HDFS_课程介绍】04:23


P040【040_尚硅谷_Hadoop_HDFS_产生背景和定义】04:11
HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。

能追加数据,不能修改原来的数据。

P041【041_尚硅谷_Hadoop_HDFS_优缺点】05:28
HDFS优点
- 高容错性;
- 适合处理大数据,GB、TB、PB;
- 可构建在廉价机器上,通过多副本机制提高可靠性。
HDFS缺点
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的;
- 无法高效的对大量小文件进行存储;
- 不支持并发写入、文件随机修改。仅支持数据append(追加)。
P042【042_尚硅谷_Hadoop_HDFS_组成】09:09
hadoop官方文档网站:Index of /docs
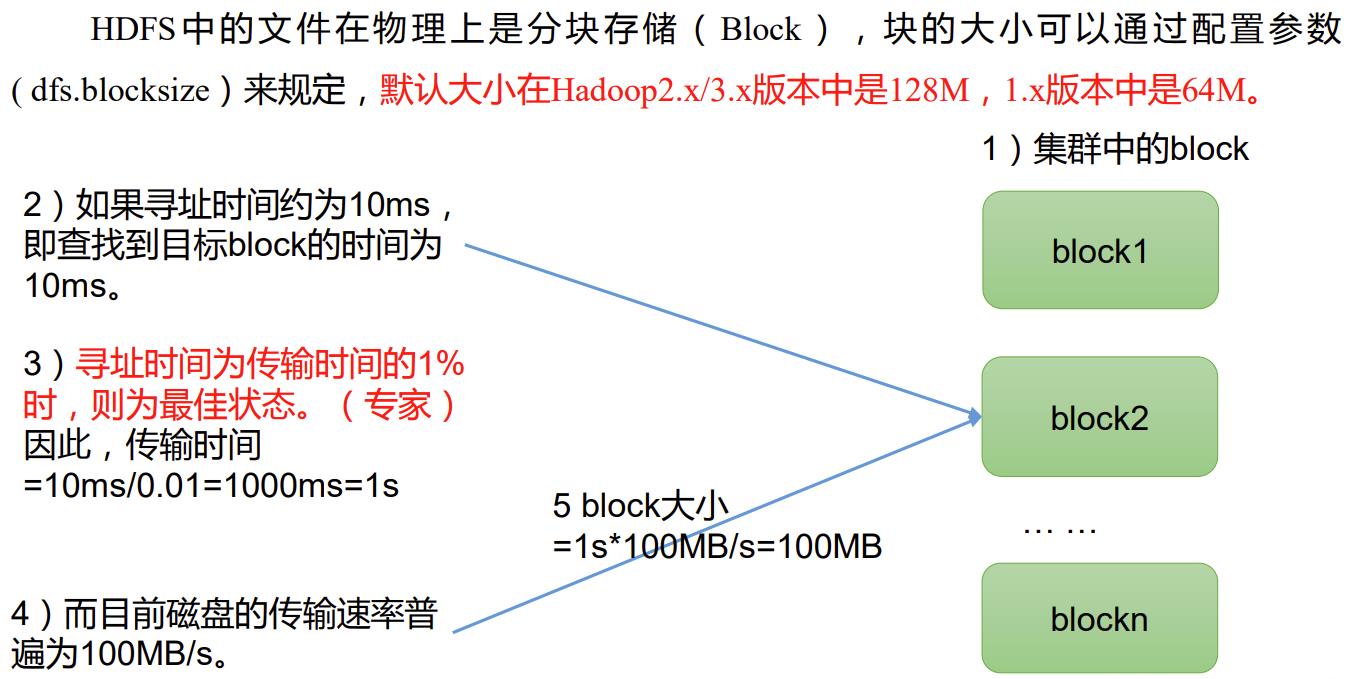
P043【043_尚硅谷_Hadoop_HDFS_文件块大小】08:01
思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
P044【044_尚硅谷_Hadoop_HDFS_Shell命令上传】09:48
hadoop fs 具体命令 OR hdfs dfs 具体命令,两个是完全相同的。
连接成功
Last login: Wed Mar 22 11:45:28 2023 from 192.168.88.1
[atguigu@node1 ~]$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] -n name | -d [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]]
[-setfattr -n name [-v value] | -x name <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
[atguigu@node1 ~]$ hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] -n name | -d [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]]
[-setfattr -n name [-v value] | -x name <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
[atguigu@node1 ~]$
1)-moveFromLocal:从本地剪切粘贴到HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
输入:
shuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
输入:
weiguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
3)-put:等同于copyFromLocal,生产环境更习惯用put
[atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
输入:
wuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
4)-appendToFile:追加一个文件到已经存在的文件末尾
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:
liubei
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt

P045【045_尚硅谷_Hadoop_HDFS_Shell命令下载&直接操作】16:41
HDFS直接操作
1)-ls: 显示目录信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:显示文件内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt
4)-mkdir:创建路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在HDFS目录中移动文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:显示一个文件的末尾1kb的数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:删除文件或文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du统计文件夹的大小信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录
11)-setrep:设置HDFS中文件的副本数量
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
P046【046_尚硅谷_Hadoop_HDFS_API环境准备】08:20


P047【047_尚硅谷_Hadoop_HDFS_API创建文件夹】10:54
idea,ctrl+p+enter:查看参数。

package com.atguigu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 客户端代码常用套路
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
* HDFS zookeeper
*/
public class HdfsClient
//创建目录
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException
//连接的集群nn地址
URI uri = new URI("hdfs://node1:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
//用户
String user = "atguigu";
//1、获取到了客户端对象
FileSystem fileSystem = FileSystem.get(uri, configuration, user);
//2、创建一个文件夹
fileSystem.mkdirs(new Path("/xiyou/huaguoshan"));
//3、关闭资源
fileSystem.close();

package com.atguigu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 客户端代码常用套路
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
* HDFS zookeeper
*/
public class HdfsClient
private FileSystem fs;
@Before
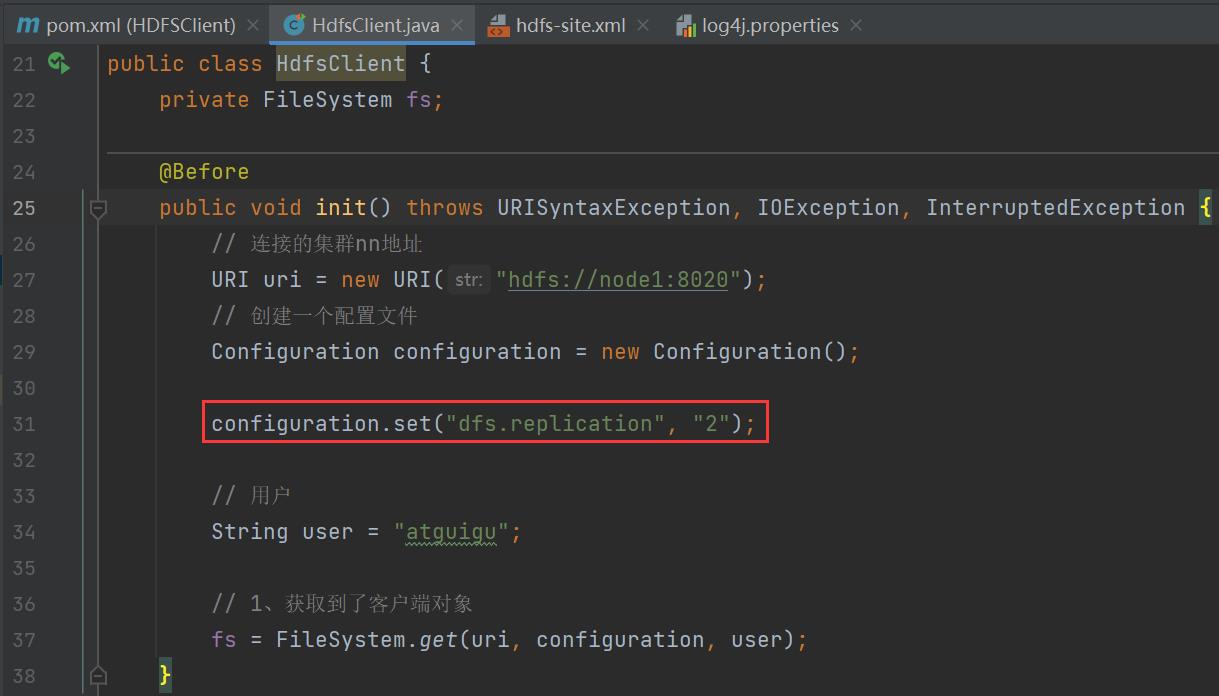
public void init() throws URISyntaxException, IOException, InterruptedException
// 连接的集群nn地址
URI uri = new URI("hdfs://node1:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
// 用户
String user = "atguigu";
// 1、获取到了客户端对象
fs = FileSystem.get(uri, configuration, user);
@After
public void close() throws IOException
// 3、关闭资源
fs.close();
/*
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException
//连接的集群nn地址
URI uri = new URI("hdfs://node1:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
//用户
String user = "atguigu";
//1、获取到了客户端对象
FileSystem fileSystem = FileSystem.get(uri, configuration, user);
//2、创建一个文件夹
fileSystem.mkdirs(new Path("/xiyou/huaguoshan"));
//3、关闭资源
fileSystem.close();
*/
//创建目录
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException
// //连接的集群nn地址
// URI uri = new URI("hdfs://node1:8020");
// //创建一个配置文件
// Configuration configuration = new Configuration();
//
// //用户
// String user = "atguigu";
//
// //1、获取到了客户端对象
// FileSystem fileSystem = FileSystem.get(uri, configuration, user);
//2、创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan2"));
// //3、关闭资源
// fileSystem.close();
P048【048_尚硅谷_Hadoop_HDFS_API上传】06:42
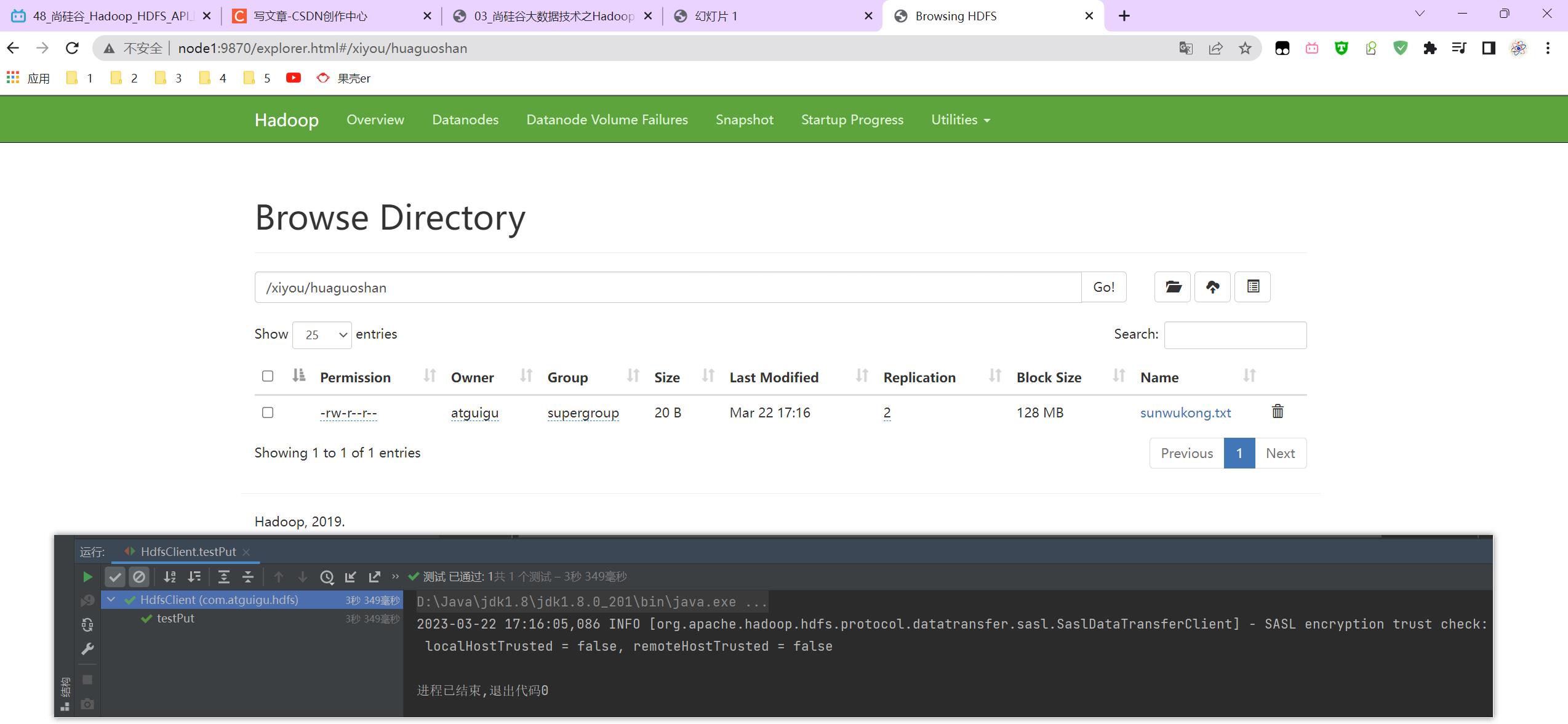
package com.atguigu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 客户端代码常用套路
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
* HDFS zookeeper
*/
public class HdfsClient
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException
// 连接的集群nn地址
URI uri = new URI("hdfs://node1:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
// 用户
String user = "atguigu";
// 1、获取到了客户端对象
fs = FileSystem.get(uri, configuration, user);
@After
public void close() throws IOException
// 3、关闭资源
fs.close();
// 上传
@Test
public void testPut() throws IOException
// 参数解读,参数1:表示删除原数据、参数2:是否允许覆盖、参数3:原数据路径、参数4:目的地路径
fs.copyFromLocalFile(false, true, new Path("D:\\\\bigData\\\\file\\\\sunwukong.txt"), new Path("hdfs://node1/xiyou/huaguoshan"));
P049【049_尚硅谷_Hadoop_HDFS_API参数的优先级】05:08
将hdfs-site.xml拷贝到项目的resources资源目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!--副本数-->
</property>
</configuration>
参数优先级排序,hdfs-default.xml => hdfs-site.xml=> 在项目资源目录下的配置文件 => 代码里面的配置。
- 客户端代码中设置的值
- ClassPath下的用户自定义配置文件
- 然后是服务器的自定义配置(xxx-site.xml)
- 服务器的默认配置(xxx-default.xml)
P050【050_尚硅谷_Hadoop_HDFS_API文件下载】08:24

//文件下载
@Test
public void testGet() throws IOException
//参数的解读,参数一:原文件是否删除、参数二:原文件路径HDFS、参数三:Windows目标地址路径、参数四:crc校验
// fs.copyToLocalFile(false, new Path("hdfs://node1/xiyou/huaguoshan2/sunwukong.txt"), new Path("D:\\\\bigData\\\\file\\\\download"), false);
fs.copyToLocalFile(false, new Path("hdfs://node1/xiyou/huaguoshan2/"), new Path("D:\\\\bigData\\\\file\\\\download"), false);
// fs.copyToLocalFile(false, new Path("hdfs://node1/a.txt"), new Path("D:\\\\"), false);
P051【051_尚硅谷_Hadoop_HDFS_API文件删除】04:12
//删除
@Test
public void testRm() throws IOException
//参数解读,参数1:要删除的路径、参数2:是否递归删除
//删除文件
//fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"),false);
//删除空目录
//fs.delete(new Path("/xiyou"), false);
//删除非空目录
fs.delete(new Path("/jinguo"), true);
P052【052_尚硅谷_Hadoop_HDFS_API文件更名和移动】05:03
//文件的更名和移动
@Test
public void testmv() throws IOException
//参数解读,参数1:原文件路径、参数2:目标文件路径
//对文件名称的修改
fs.rename(new Path("/input/word.txt"), new Path("/input/ss.txt"));
//文件的移动和更名
fs.rename(new Path("/input/ss.txt"), new Path("/cls.txt"));
//目录更名
fs.rename(new Path("/input"), new Path("/output"));
P053【053_尚硅谷_Hadoop_HDFS_API文件详情查看】07:57
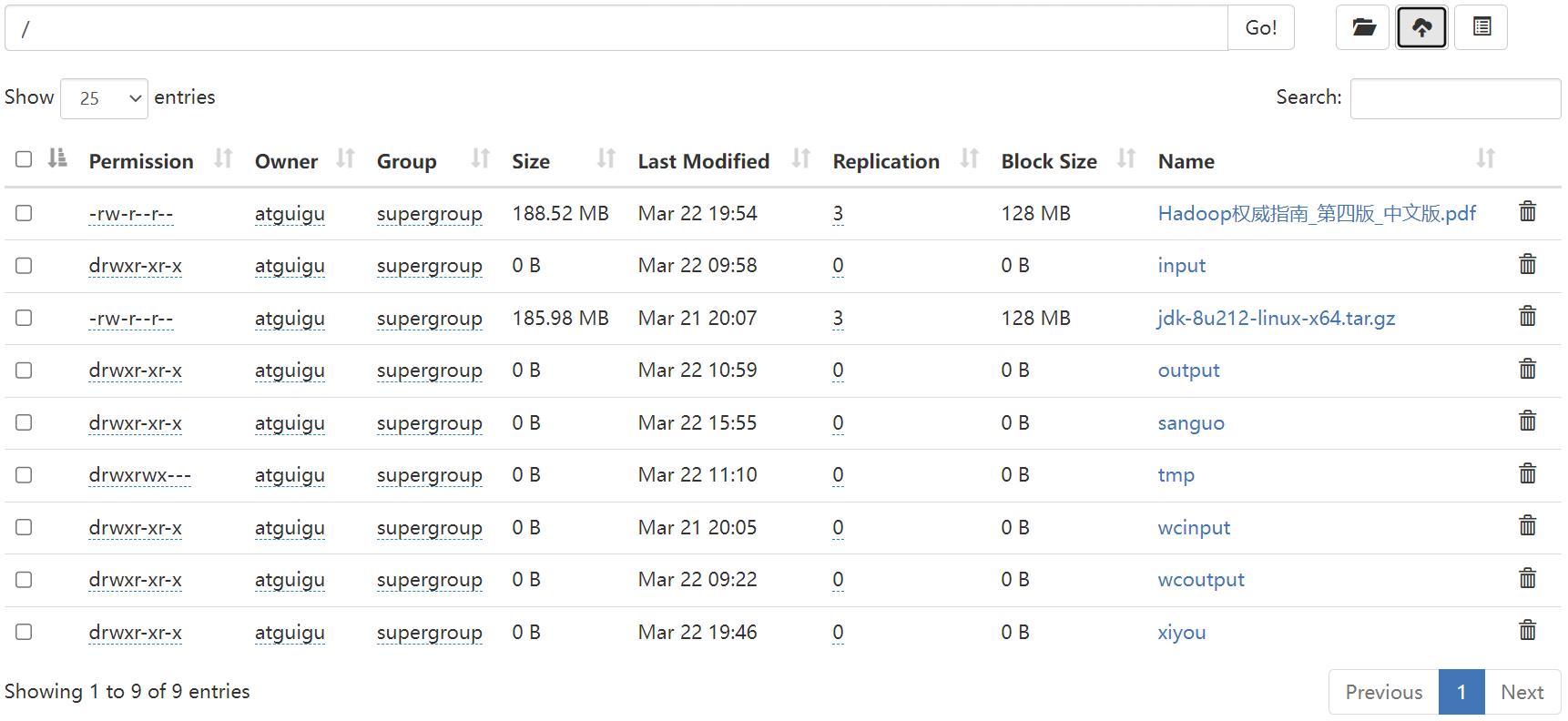

//获取文件详细信息
@Test
public void fileDetail() throws IOException
//获取所有文件信息
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//遍历文件
while (listFiles.hasNext())
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========== " + fileStatus.getPath() + " =========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
//获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
P054【054_尚硅谷_Hadoop_HDFS_API文件和文件夹判断】03:20

//判断是文件夹还是文件
@Test
public void testFile() throws IOException
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus)
if (status.isFile())
System.out.println("文件:" + status.getPath().getName());
else
System.out.println("目录:" + status.getPath().getName());
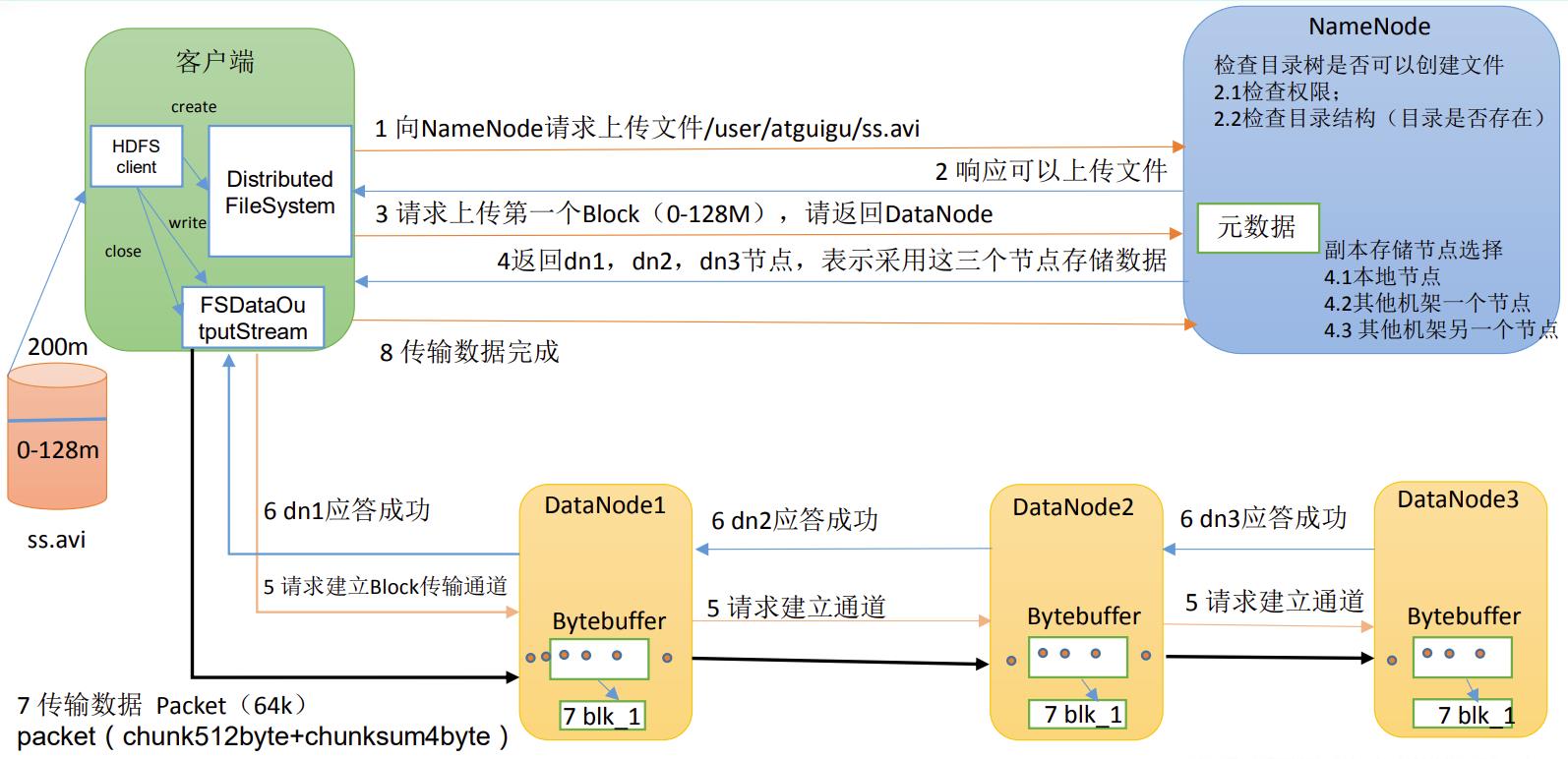
P055【055_尚硅谷_Hadoop_HDFS_写数据流程】11:38
HDFS写数据流程,剖析文件写入。
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
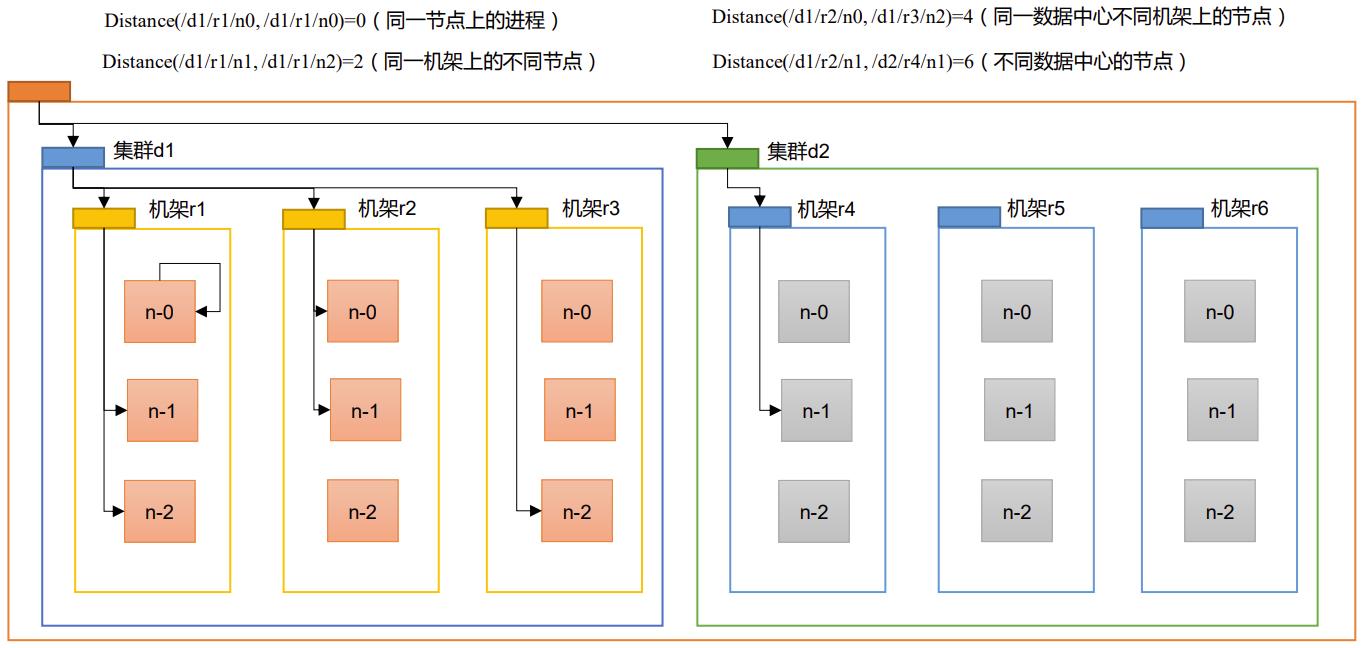
P056【056_尚硅谷_Hadoop_HDFS_节点距离计算】04:31
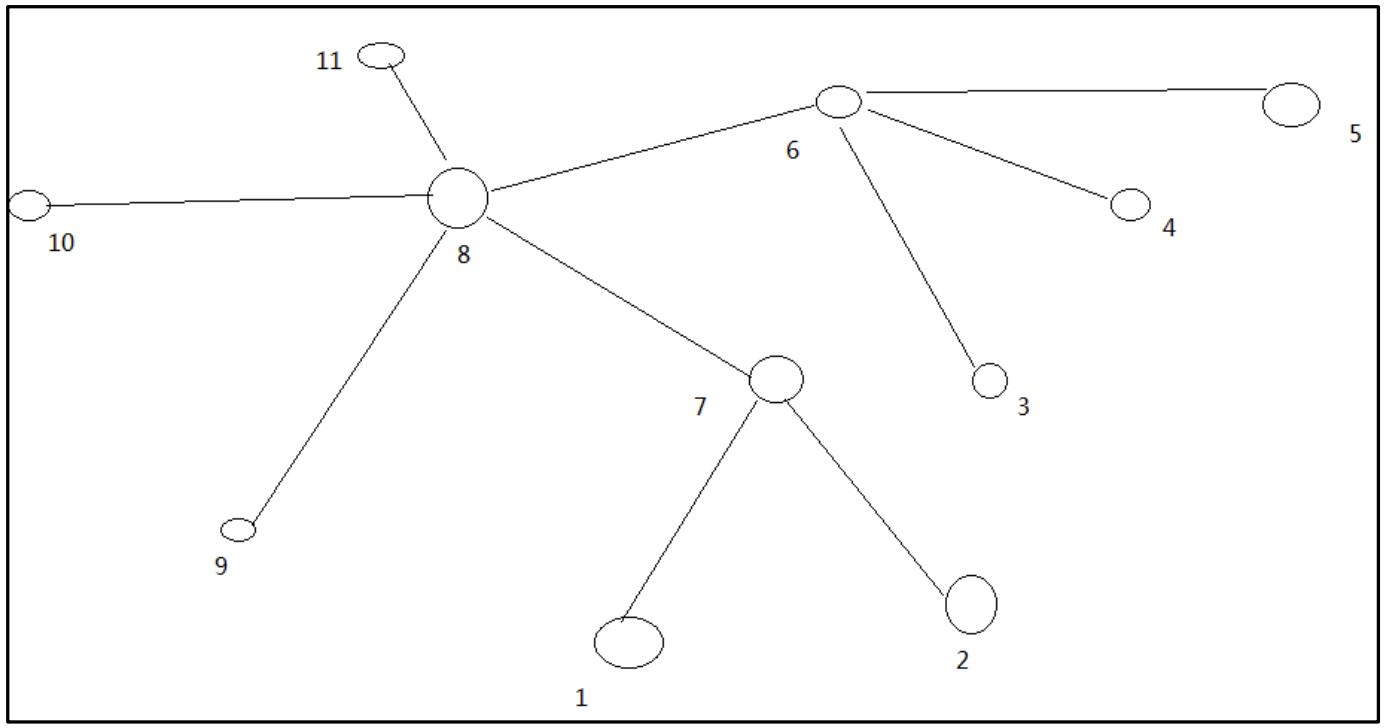
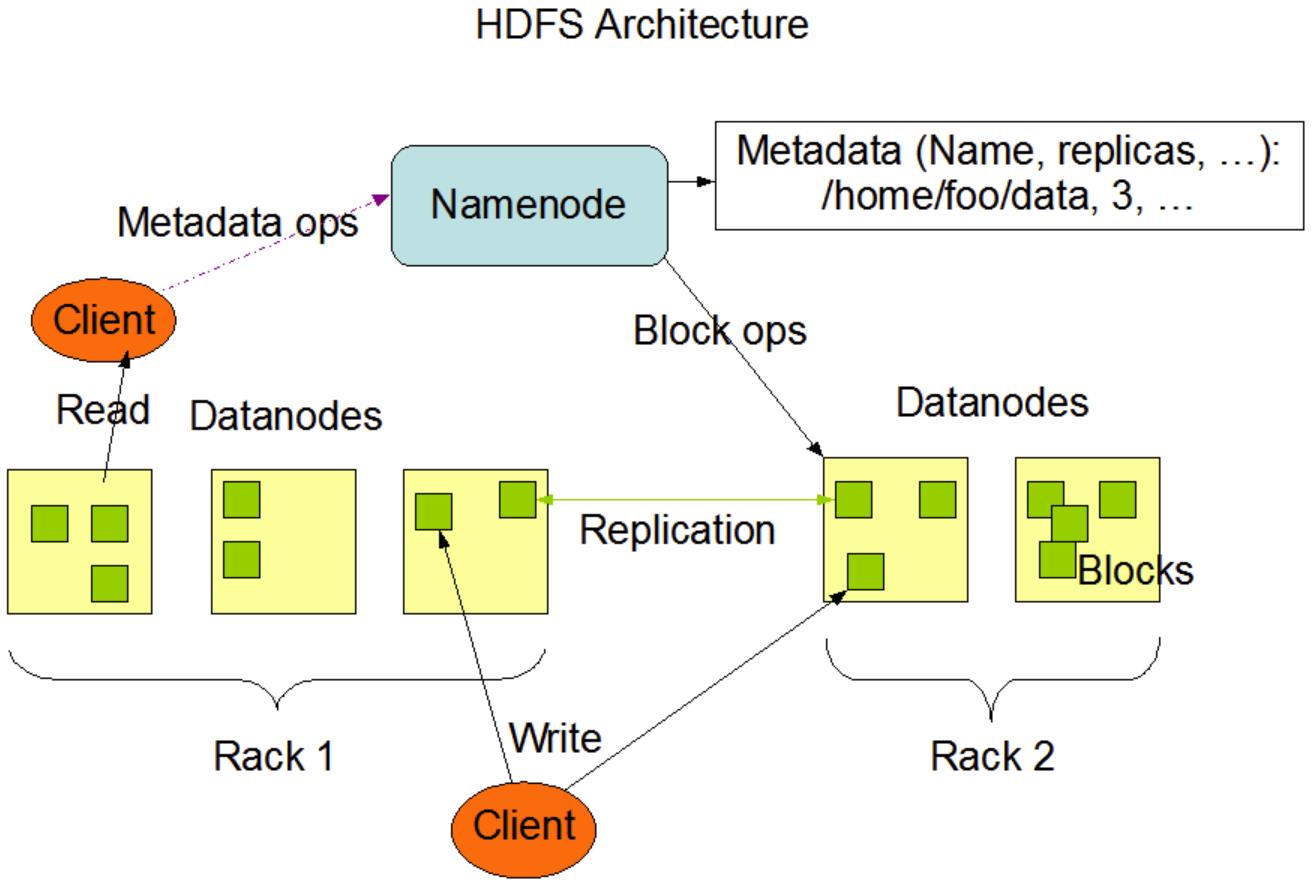
P057【057_尚硅谷_Hadoop_HDFS_机架感知(副本存储节点选择)】06:07
Apache Hadoop 3.1.3 – HDFS Architecture
- 第一个副本在Client所处的节点上;如果客户端在集群外,随机选一个。
- 第二个副本在另一个机架的随机一个节点。
- 第三个副本在第二个副本所在机架的随机节点。

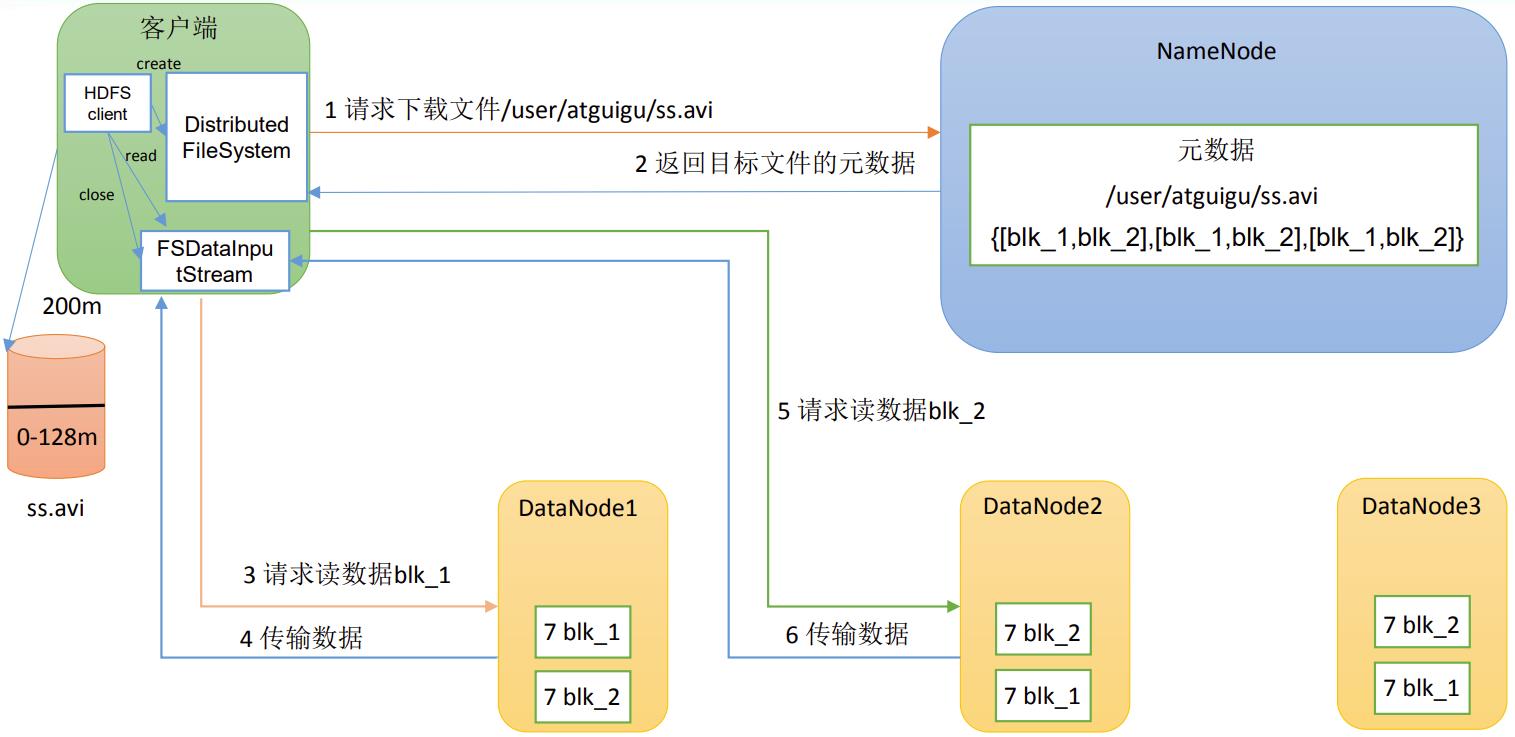
P058【058_尚硅谷_Hadoop_HDFS_读数据流程】05:04
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
P059【059_尚硅谷_Hadoop_HDFS_NN和2NN工作机制】13:28
第5章

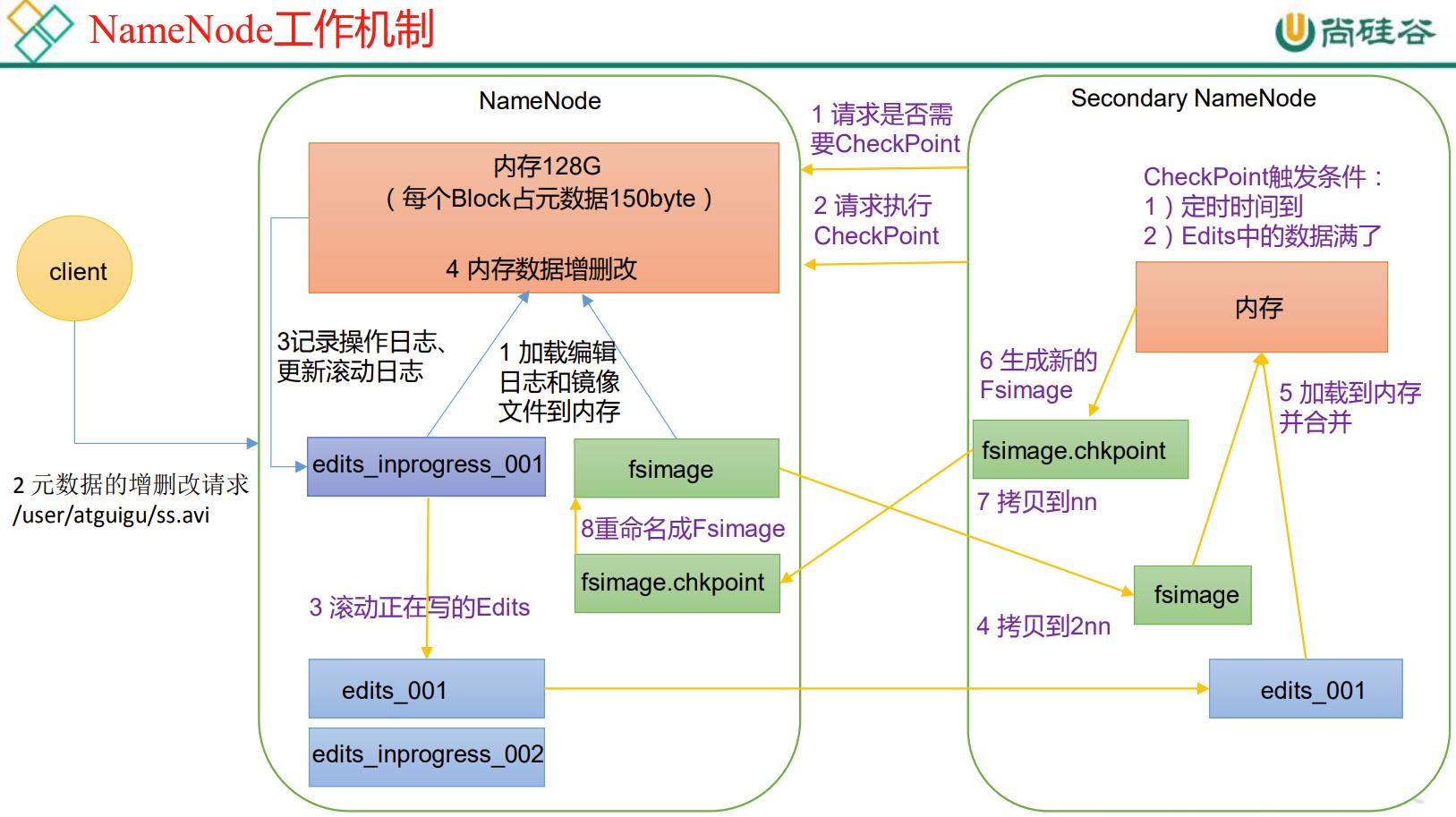
P060【060_尚硅谷_Hadoop_HDFS_FsImage镜像文件】09:33
1)oiv查看Fsimage文件
(1)查看oiv和oev命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[atguigu@hadoop102 current]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[atguigu@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml
将显示的xml文件内容拷贝到Idea中创建的xml文件中,并格式化。部分显示结果如下。
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id>
<type>DIRECTORY</type>
<name>atguigu</name>
<mtime>1512790549080</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16389</id>
<type>FILE</type>
<name>wc.input</name>
<replication>3</replication>
<mtime>1512722322219</mtime>
<atime>1512722321610</atime>
<perferredBlockSize>134217728</perferredBlockSize>
<permission>atguigu:supergroup:rw-r--r--</permission>
<blocks>
<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>59</numBytes>
</block>
</blocks>
</inode >
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么?
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
P061【061_尚硅谷_Hadoop_HDFS_Edits编辑日志】04:49
2)oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[atguigu@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml
将显示的xml文件内容拷贝到Idea中创建的xml文件中,并格式化。显示结果如下。
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>129</TXID>
</DATA>
</RECORD>
<RECORD>