3.2 线性回归从零开始实现
Posted AncilunKiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.2 线性回归从零开始实现相关的知识,希望对你有一定的参考价值。
%matplotlib inline
import random
import torch
from d2l import torch as d2l
3.2.1 生成数据集
为了简单起见,使用易于可视化的低维数据。使用线性模型 \\(\\boldsymboly=\\boldsymbolXw+b+\\epsilon\\) 生成数据集及其标签,其中合成的数据集是一个矩阵 \\(\\boldsymbolX\\in\\R^1000\\times2\\),参数 \\(\\boldsymbolw=\\left[2,-3.4\\right]^T、b=4.2\\),噪声项 \\(\\epsilon\\in N(0,0.01^2)\\)。
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
# 真实参数
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print(\'features:\', features[0], \'\\nlable:\', labels[0]) # feature每行包含一个二维数据样本,labels每行包含一个标量标签值
features: tensor([2.1298, 0.0883])
lable: tensor([8.1534])
d2l.set_figsize()
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1) # 用散点图可视化
<matplotlib.collections.PathCollection at 0x23f96379520>

3.2.2 读取数据集
定义一个 data_iter 函数,该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为 batch_size 的小批量,每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features) # 样本总数
indices = list(range(num_examples))
random.shuffle(indices) # 打乱列表元素
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices] # 降低内存小妙招:生成器。区别于return,生成器函数的返回生成一个列表一波返回,而是用一个生成一个返回一个,不用的时候是暂停执行的。
batch_size = 10
for X,y in data_iter(batch_size, features, labels): # 小批量计算大概就是这样,一波一波的读
print(X, \'\\n\', y)
break
# 实际上上述函数效率很低,框架内置的迭代器效率高很多,知其意即可。
tensor([[ 0.2036, 0.4717],
[ 0.3787, -1.5764],
[ 1.1944, 2.7301],
[ 0.2739, -0.4185],
[-2.1039, 0.8665],
[-0.1624, -1.3021],
[ 0.8052, -0.9909],
[ 0.3724, 0.9609],
[ 0.0779, -0.9714],
[-0.8306, -0.5290]])
tensor([[ 3.0043],
[10.3214],
[-2.6861],
[ 6.1683],
[-2.9457],
[ 8.3030],
[ 9.1761],
[ 1.6708],
[ 7.6504],
[ 4.3335]])
3.2.3 初始化模型参数
从均值为 0、标准差为 0.01 的正态分布中抽样随机数来初始化权重,并将偏置初始化为 0。
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True) # 为什么非要把 w 整成(2, 1)的,以至于后面y需要reshape,向量和矩阵效果明明一样的
b = torch.zeros(1, requires_grad=True)
w, b
(tensor([[ 0.0040],
[-0.0168]], requires_grad=True),
tensor([0.], requires_grad=True))
3.2.4 定义模型
定义模型,将模型的输入和参数同模型的输出关联起来。
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b
3.2.5 定义损失函数
此处使用平方损失函数
def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
3.2.6 定义优化算法
定义函数实现小批量随机梯度下降更新,该函数接收模型参数集合、学习率和批量大小作为输入。
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad(): # 节省内存小妙招利用with关键字自动调用 no_grad 函数 使完成运算后参数 requires_grad 均设为 False。
for param in params:
param -= lr * param.grad / batch_size # 为什么要除以 batch_size ?
param.grad.zero_()
3.2.7 训练
在每次迭代中,先读取小批量样本,并通过模型来获得一组预测。计算完损失后,开始反向传播,存储每个参数的梯度。最后,调用优化算法 sgd 来更新模型参数。总的来说:
- 初始化参数
- 重复以下训练,直到完成:
- 计算梯度 \\(\\boldsymbolg\\leftarrow\\partial_(\\boldsymbolw, b)\\frac1|B|\\sum_i\\in Bl(\\boldsymbolx^(i),\\boldsymboly^(i),\\boldsymbolw,b)\\);
- 更新参数 \\((\\boldsymbolw,b)\\leftarrow(\\boldsymbolw,b)-\\eta\\boldsymbolg\\)
# lr 和 num_epochs 都是超参数,需要反复实验调整,此处忽略这些细节,在11章会详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X 和 y 的小批量损失
l.sum().backward() # 转换成标量并计算梯度
sgd([w, b], lr, batch_size) # 沿梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f\'epochepoch + 1, loss float(train_l.mean()):f\')
epoch1, loss 0.033048
epoch2, loss 0.000114
epoch3, loss 0.000047
由于 $ \\boldsymbolw$ 和 \\(b\\) 是自己设置的,所以可以很明确的计算出训练得出的参数和真是参数间的差距
print(f\'w的估计误差: true_w - w.reshape(true_w.shape)\')
print(f\'b的估计误差: true_b - b\')
w的估计误差: tensor([ 6.8665e-05, -2.1100e-04], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0006], grad_fn=<RsubBackward1>)
练习
(1)如果我们将权重初始化为零,会发生什么?算法仍然有效吗?
w = torch.zeros(size=(2, 1), requires_grad=True) # 初始化为 0
b = torch.zeros(1, requires_grad=True)
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X 和 y 的小批量损失
l.sum().backward() # 转换成标量并计算梯度
sgd([w, b], lr, batch_size) # 沿梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f\'epochepoch + 1, loss float(train_l.mean()):f\')
print(f\'w的估计误差: true_w - w.reshape(true_w.shape)\')
print(f\'b的估计误差: true_b - b\')
epoch1, loss 0.033627
epoch2, loss 0.000119
epoch3, loss 0.000047
w的估计误差: tensor([-0.0003, -0.0004], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0006], grad_fn=<RsubBackward1>)
可以跑,特别是对于这个简单的例子,影响很有限。但是对于更复杂的网络来说出现对称性,使隐层无论有多少神经元都等价于只有一个神经元。详细参见《谈谈神经网络权重为什么不能初始化为0》
(2)假设试图为电压和电流的关系建立一个模型。自动微分可以用来学习模型的参数吗?
可以,电压电流也是线性关系 \\(U=wI+b\\)
(3)能基于普朗克定律使用光谱能量密度来确定物体的温度吗?
依据百度百科相关内容,普朗克定律写做能量密度频谱的形式为:
转换得:
(4)计算二阶导数时可能会遇到什么问题?这些问题如何解决?
由于调用 backward 函数计算一次梯度后,计算图会被释放。如果想要保留,需要添加 retain_graph=True。所以如果想二次求导(求高阶导倒不是必要得)则需要保留,如2.5.练习(2)
对于高阶导数,仅保留计算图是不够的,还需要使用 creat_graph=True 在保留原图的基础上再建立额外的计算图,之后二阶导直接对前一个grad 调用 backward 函数即可。
另外需要注意在第二次求导前清空梯度,否则会累加。而且需要使用 grad.data.zero_() 而非 grad.zero_(),后者会使 grad_fn=<ZeroBackward0>,导致二阶导为 0。
参考《一文解释 PyTorch求导相关 (backward, autograd.grad)》
x = torch.tensor([1.], requires_grad=True)
y = x**3 # 显然一阶导应该是3 二阶导应该是6
y.backward(retain_graph=True, create_graph=True) # 实际上对于二阶求导retain_graph=True不是必要的
grad1 = x.grad.clone()
x.grad.data.zero_() # 注意清零
x.grad.backward() # 在一阶梯度基础上再次反向传播
grad1, x.grad
(tensor([3.], grad_fn=<CloneBackward0>), tensor([6.], grad_fn=<CopyBackwards>))
(5)为什么再 squared_loss 函数中需要使用 reshape 函数。
因为 y_hat 是向量,而 y 是十行一列的矩阵(虽然不理解为啥非要把 y 搞成矩阵)。
(6)尝试使用不同的学习率,观察损失函数值下降的快慢成都。
num_epochs = 9
for lr in [0.01, 0.02, 0.03, 0.04, 0.05, 0.1, 0.2]:
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
print(f\'lr=lr\')
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X 和 y 的小批量损失
l.sum().backward() # 转换成标量并计算梯度
sgd([w, b], lr, batch_size) # 沿梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f\'epochepoch + 1, loss float(train_l.mean()):f\')
print(\'----------\')
lr=0.01
epoch1, loss 2.171911
epoch2, loss 0.278664
epoch3, loss 0.036007
epoch4, loss 0.004719
epoch5, loss 0.000656
epoch6, loss 0.000128
epoch7, loss 0.000057
epoch8, loss 0.000048
epoch9, loss 0.000047
----------
lr=0.02
epoch1, loss 0.271833
epoch2, loss 0.004494
epoch3, loss 0.000122
epoch4, loss 0.000048
epoch5, loss 0.000047
epoch6, loss 0.000047
epoch7, loss 0.000047
epoch8, loss 0.000047
epoch9, loss 0.000047
----------
lr=0.03
epoch1, loss 0.033085
epoch2, loss 0.000116
epoch3, loss 0.000047
epoch4, loss 0.000047
epoch5, loss 0.000047
epoch6, loss 0.000047
epoch7, loss 0.000047
epoch8, loss 0.000047
epoch9, loss 0.000047
----------
lr=0.04
epoch1, loss 0.003973
epoch2, loss 0.000049
epoch3, loss 0.000047
epoch4, loss 0.000047
epoch5, loss 0.000047
epoch6, loss 0.000047
epoch7, loss 0.000047
epoch8, loss 0.000047
epoch9, loss 0.000047
----------
lr=0.05
epoch1, loss 0.000493
epoch2, loss 0.000047
epoch3, loss 0.000047
epoch4, loss 0.000047
epoch5, loss 0.000047
epoch6, loss 0.000047
epoch7, loss 0.000047
epoch8, loss 0.000047
epoch9, loss 0.000048
----------
lr=0.1
epoch1, loss 0.000048
epoch2, loss 0.000047
epoch3, loss 0.000047
epoch4, loss 0.000047
epoch5, loss 0.000048
epoch6, loss 0.000047
epoch7, loss 0.000047
epoch8, loss 0.000047
epoch9, loss 0.000047
----------
lr=0.2
epoch1, loss 0.000048
epoch2, loss 0.000048
epoch3, loss 0.000048
epoch4, loss 0.000050
epoch5, loss 0.000047
epoch6, loss 0.000047
epoch7, loss 0.000049
epoch8, loss 0.000050
epoch9, loss 0.000047
----------
可以看到学习率越大下降越快,学习率过大的后果看不出来,据说后期不容易收敛。
(7)如果样本个数不能被批量大小整除,data_iter 函数的行为会有什么变化?
epoch = 1
for X,y in data_iter(3, features, labels): # 小批量计算大概就是这样,一波一波的读
if epoch >= 332:
print(X)
epoch += 1
tensor([[-0.2145, -1.6637],
[ 1.6249, 1.2820],
[ 0.6924, 0.1186]])
tensor([[ 0.1038, -1.1218],
[-0.9398, -0.2272],
[ 0.4261, 0.1190]])
tensor([[0.5700, 0.4233]])
\\(1000\\div3=333\\dots1\\)
可以看到,最后一组由余下的组成。
Softmax 回归的从零开始实现 pytorch
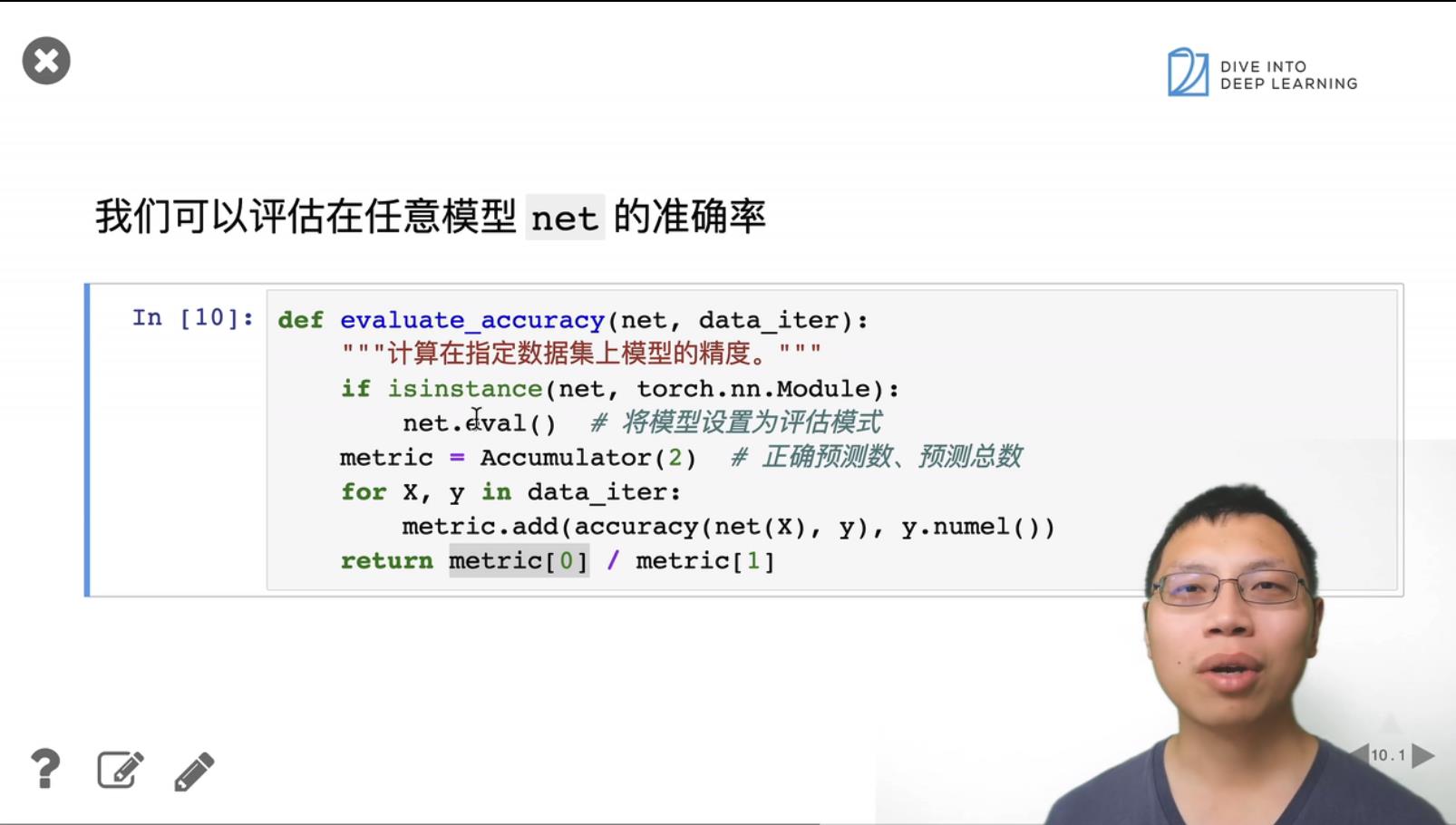
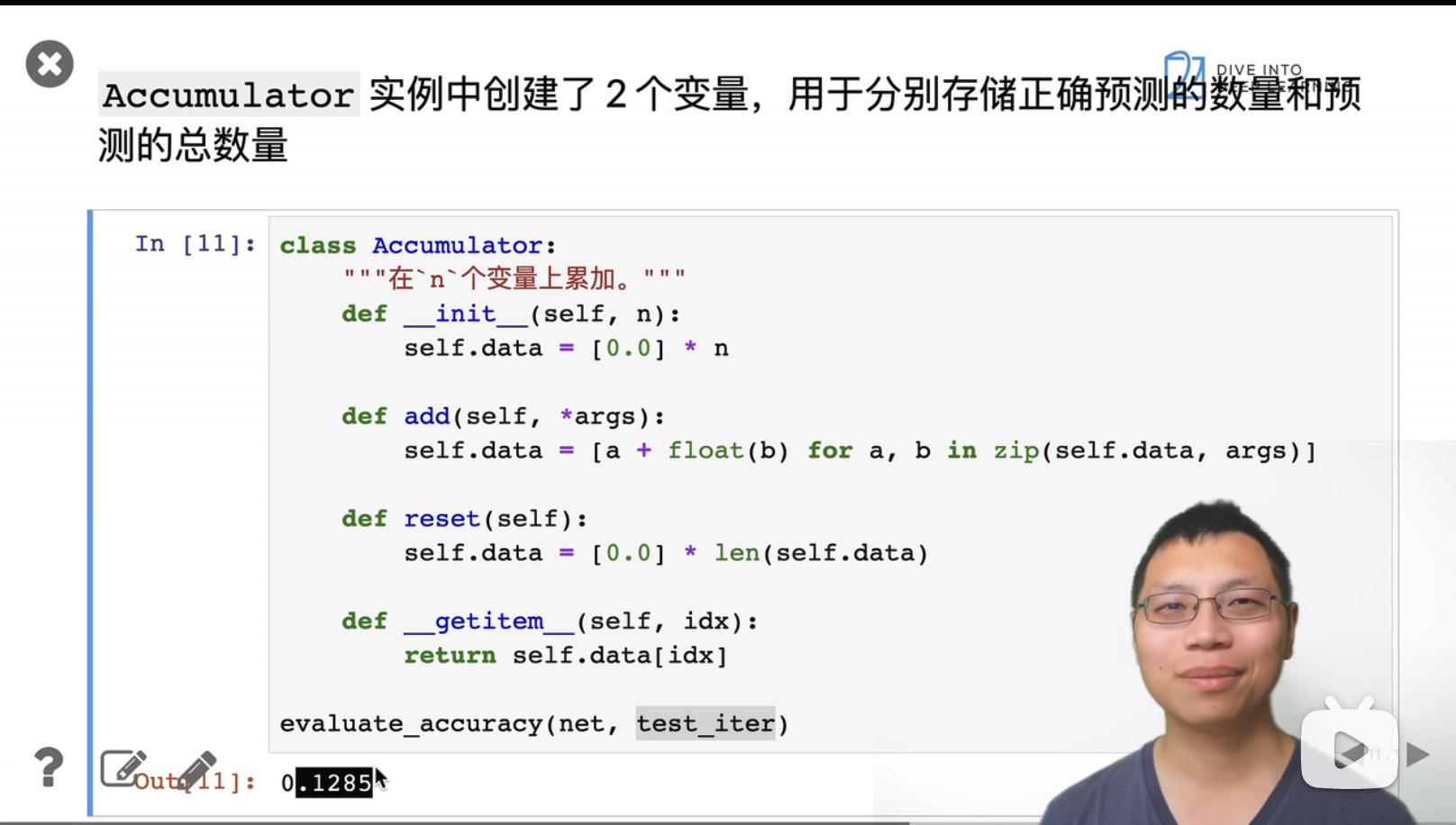
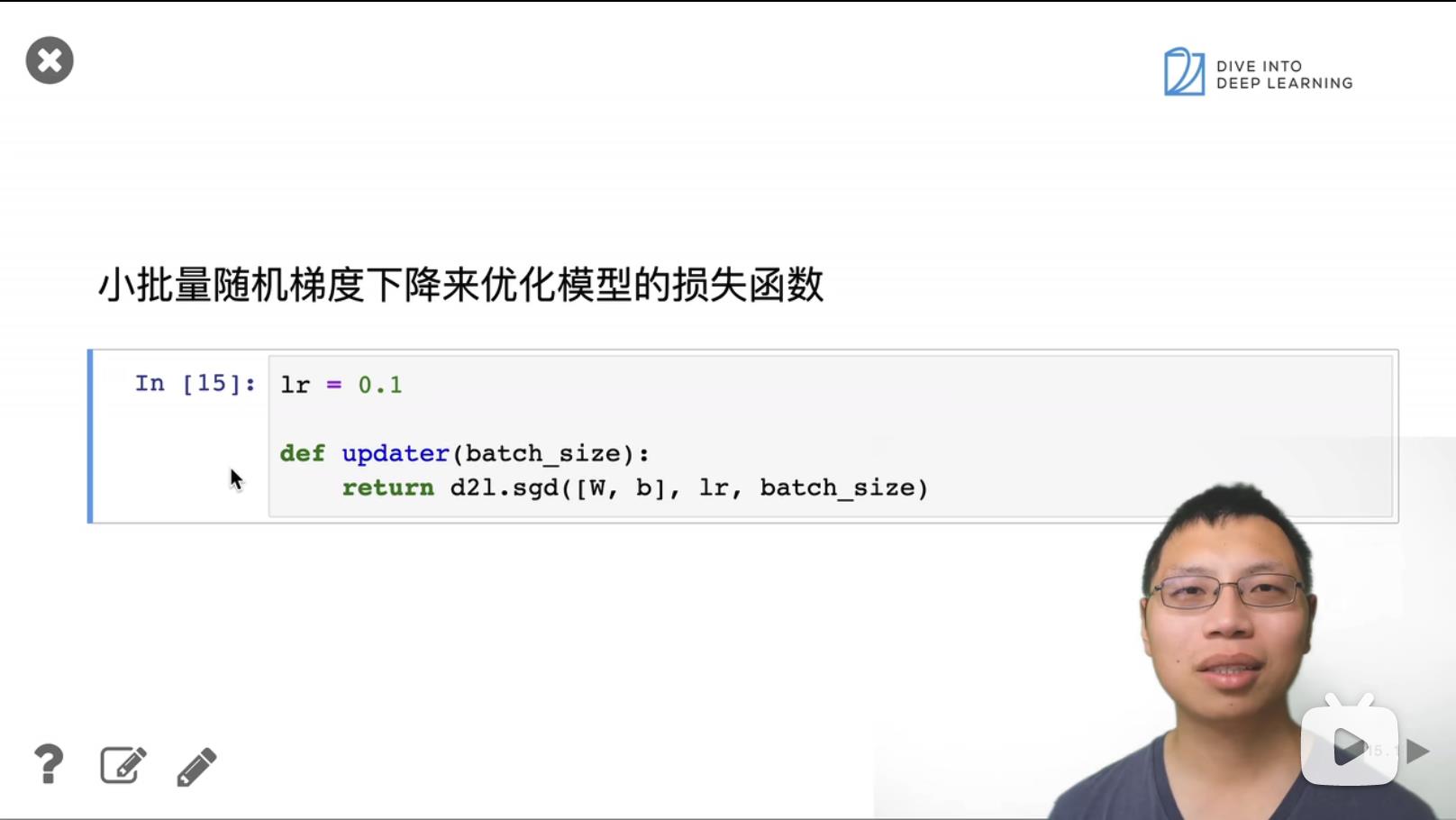
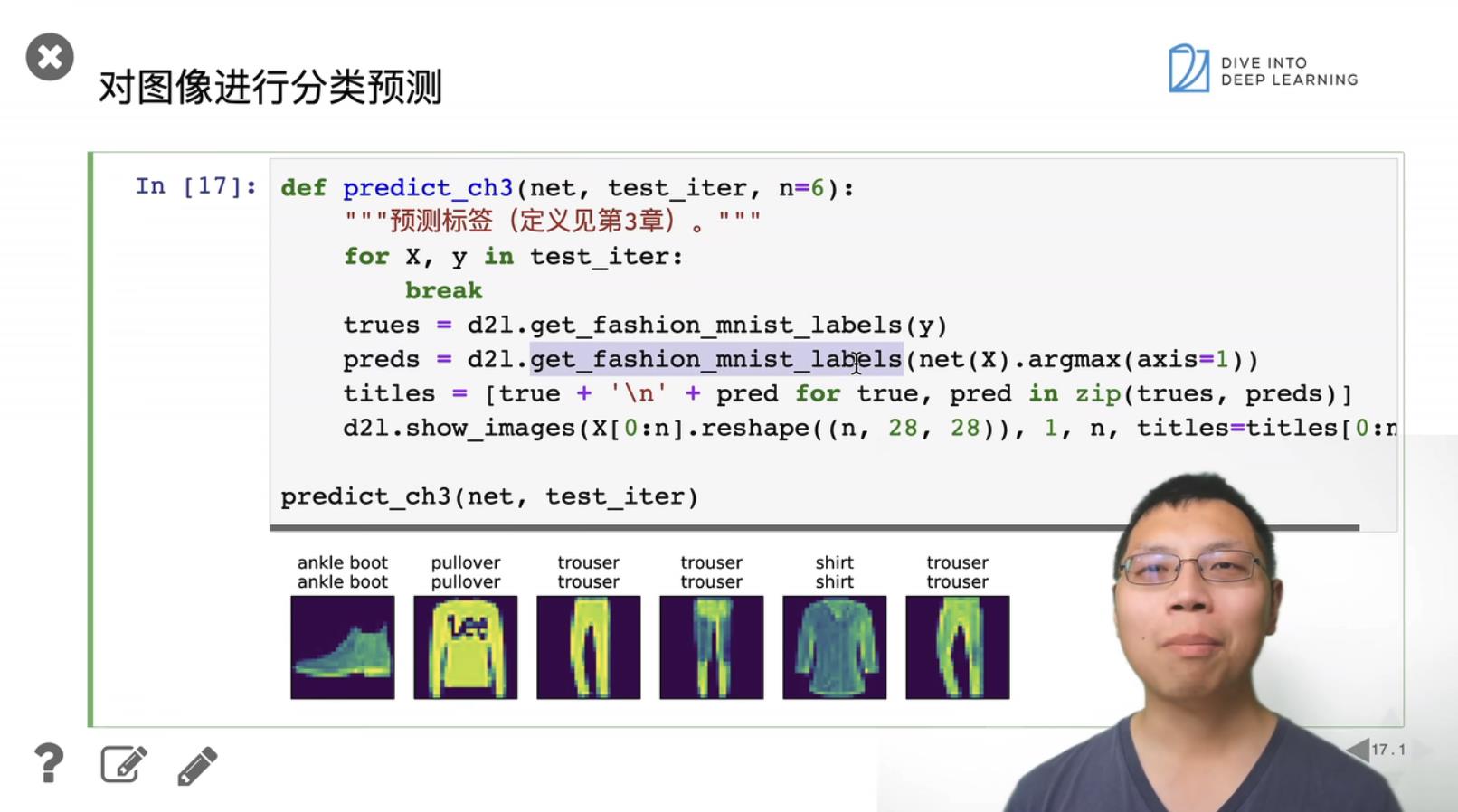
1. Softmax 回归的从零开始实现

输入为一个向量784, 也就是图片的像素长x宽。
784 = 28 * 28

keepdim表示保持维度。以0的方向相加,表示去掉row的维度,也就是结果为1row;以1的方向相加,表示去掉col的维度,也就是结果为1col。

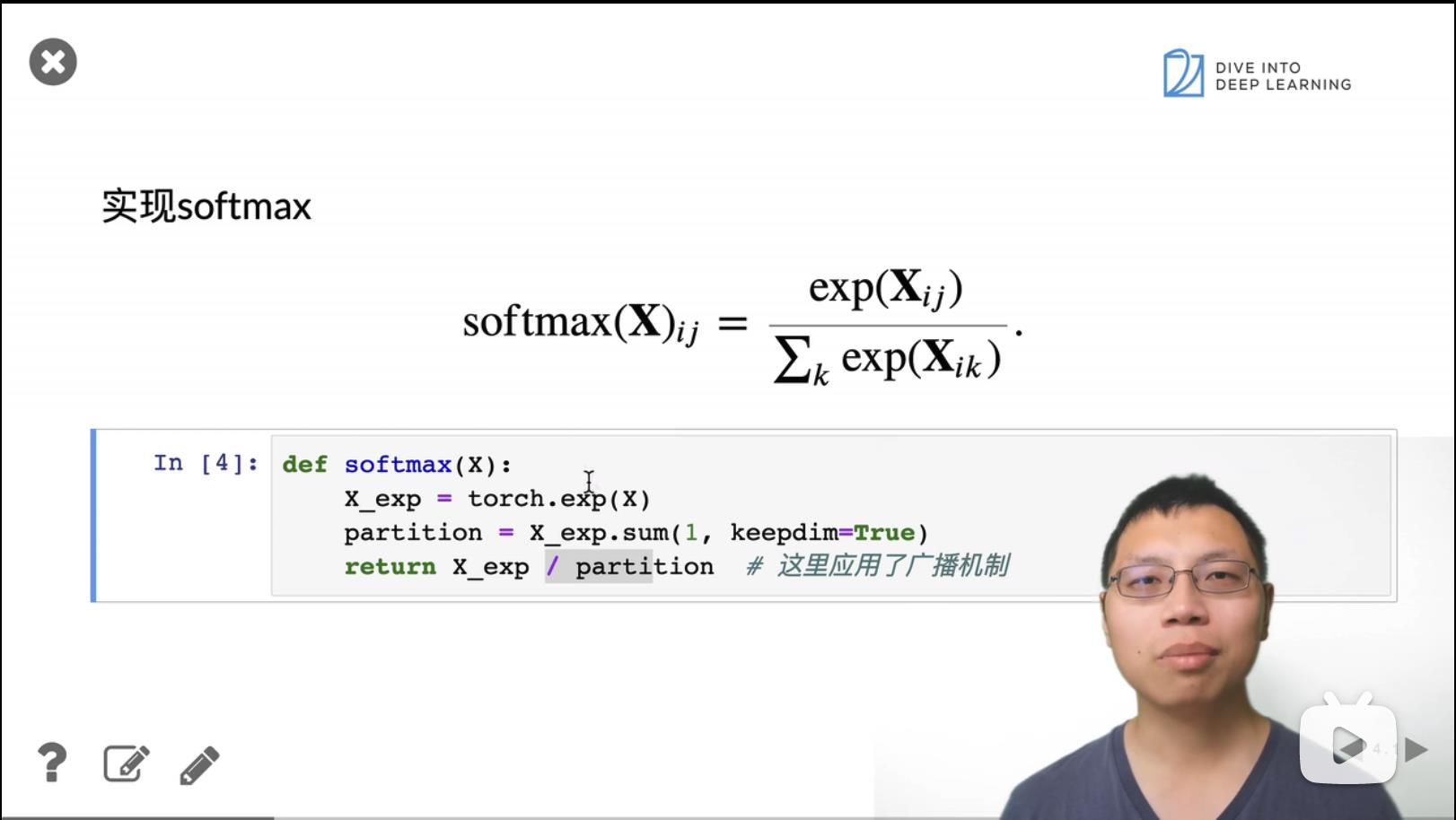
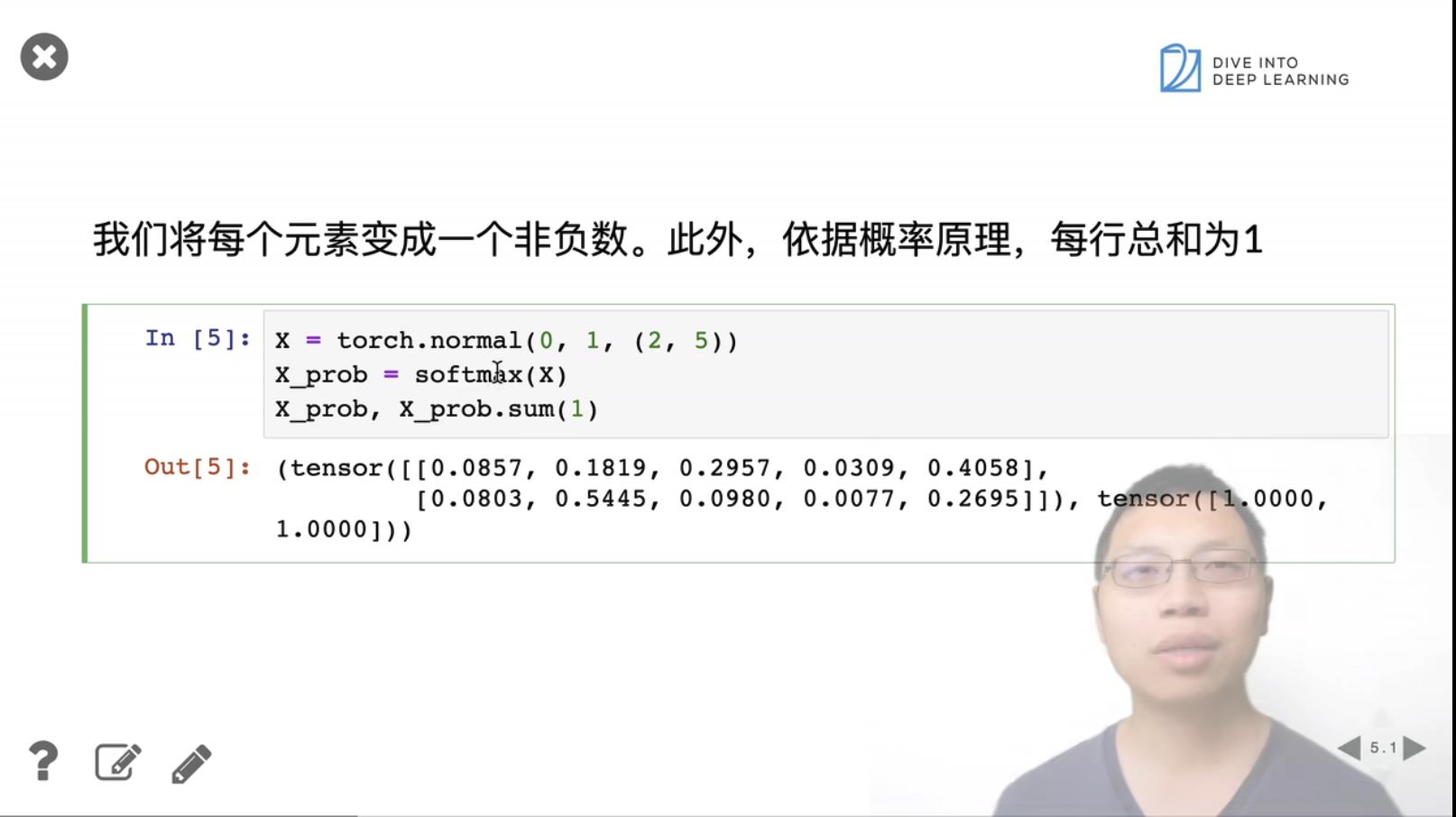
X.reshape((-1, W.shape[0])), 维度改变为bathSize * 784, bathSize = 256

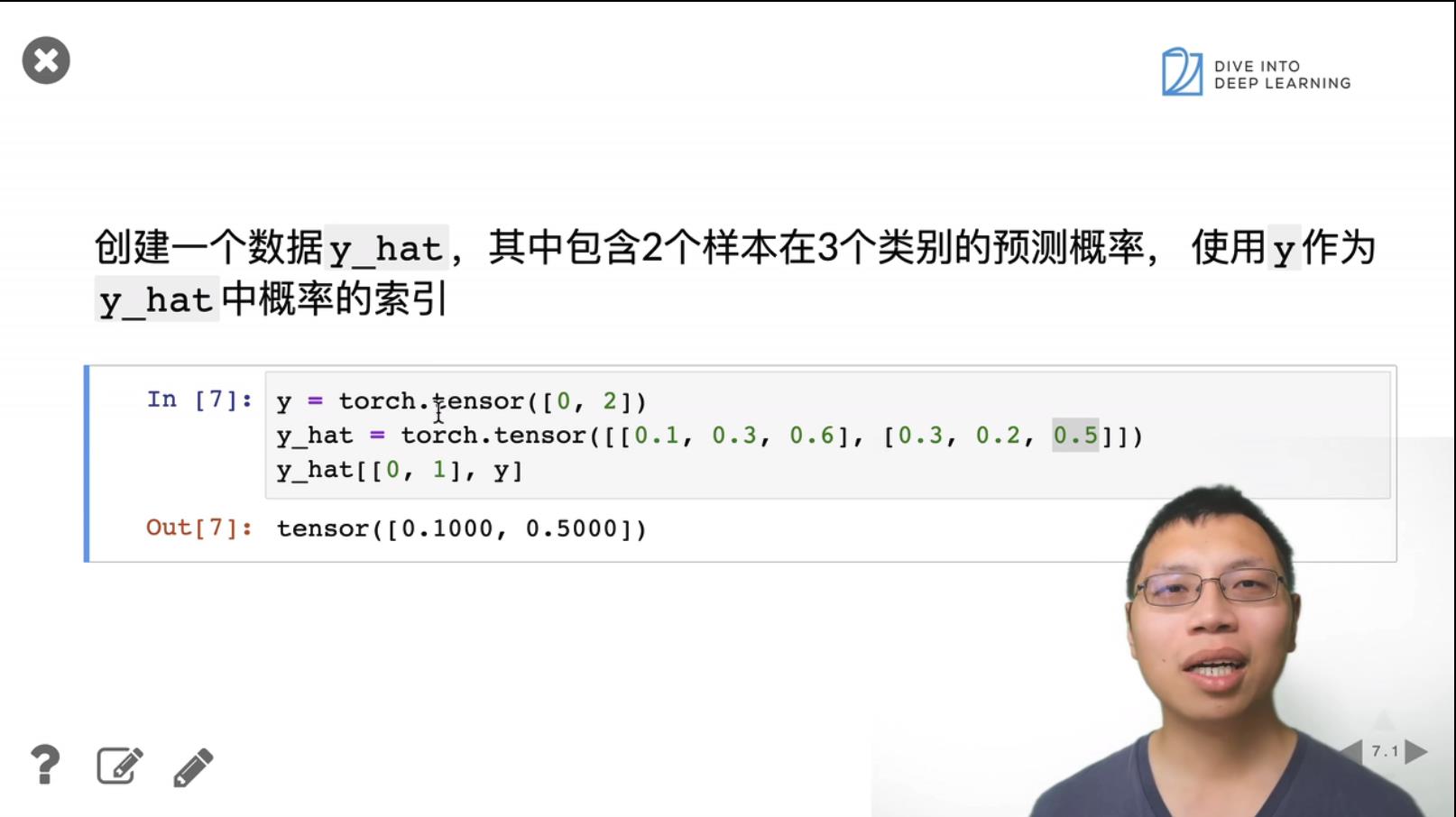

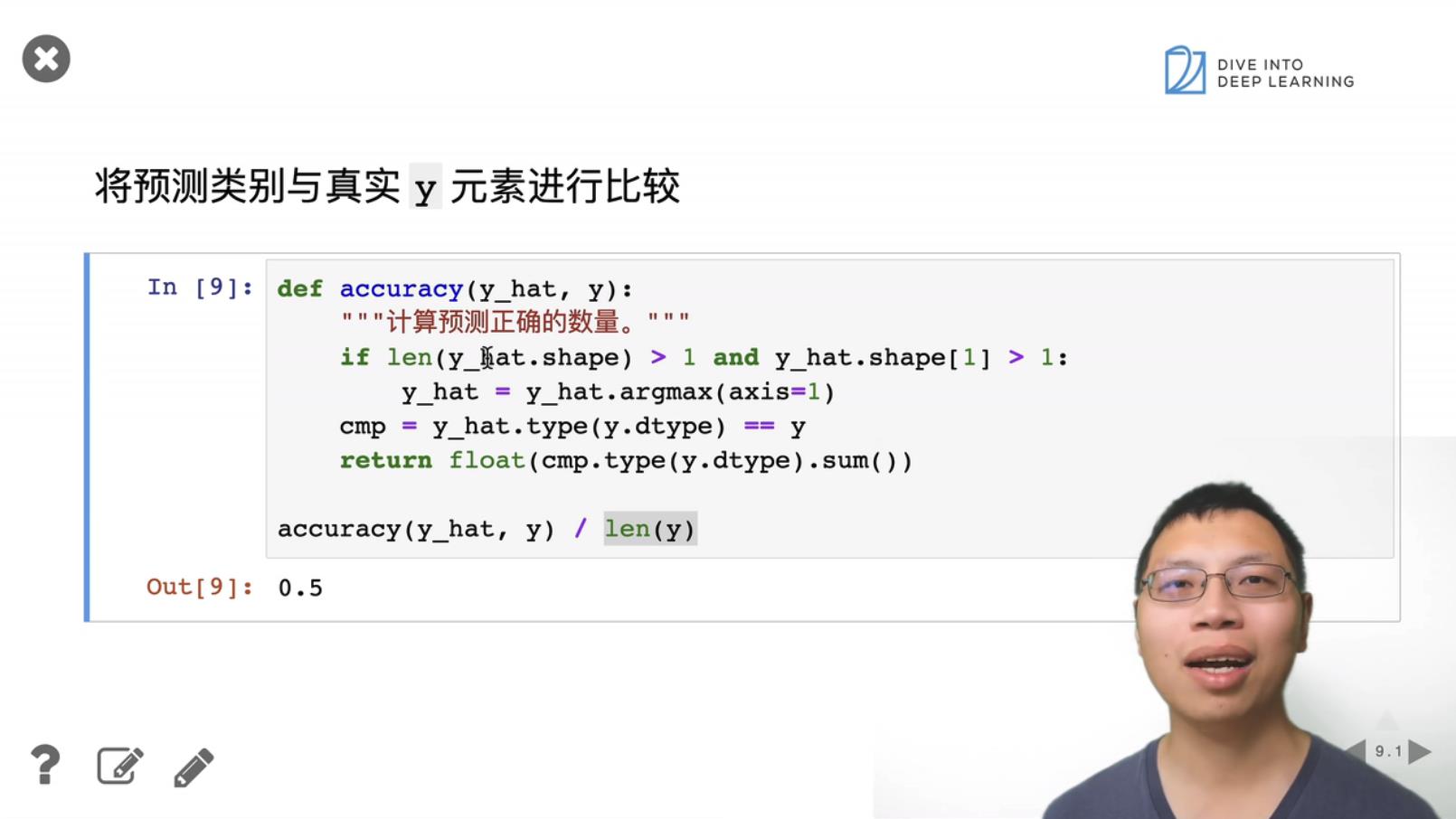





2. Softmax 回归的简洁实现 pytorch
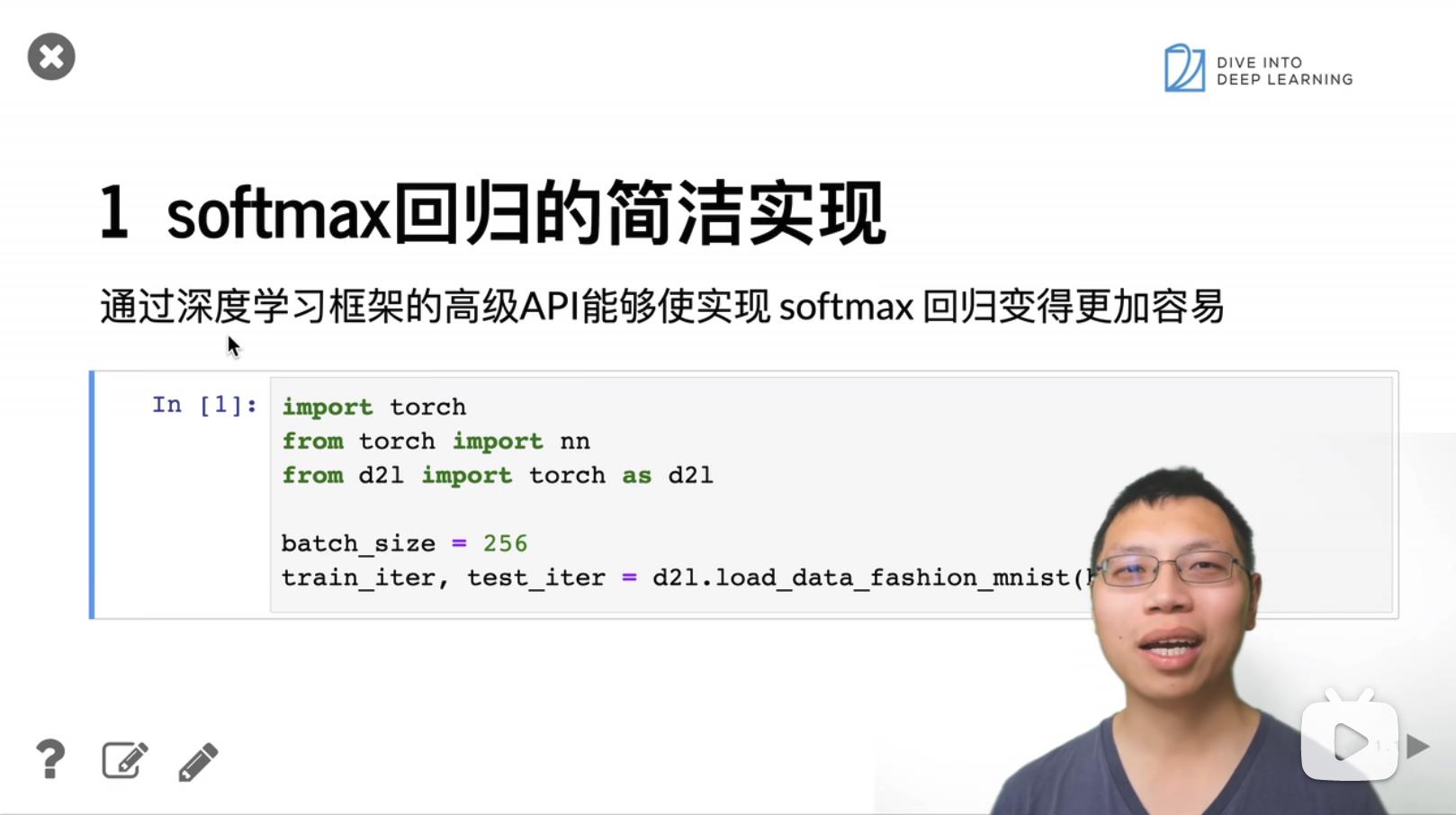
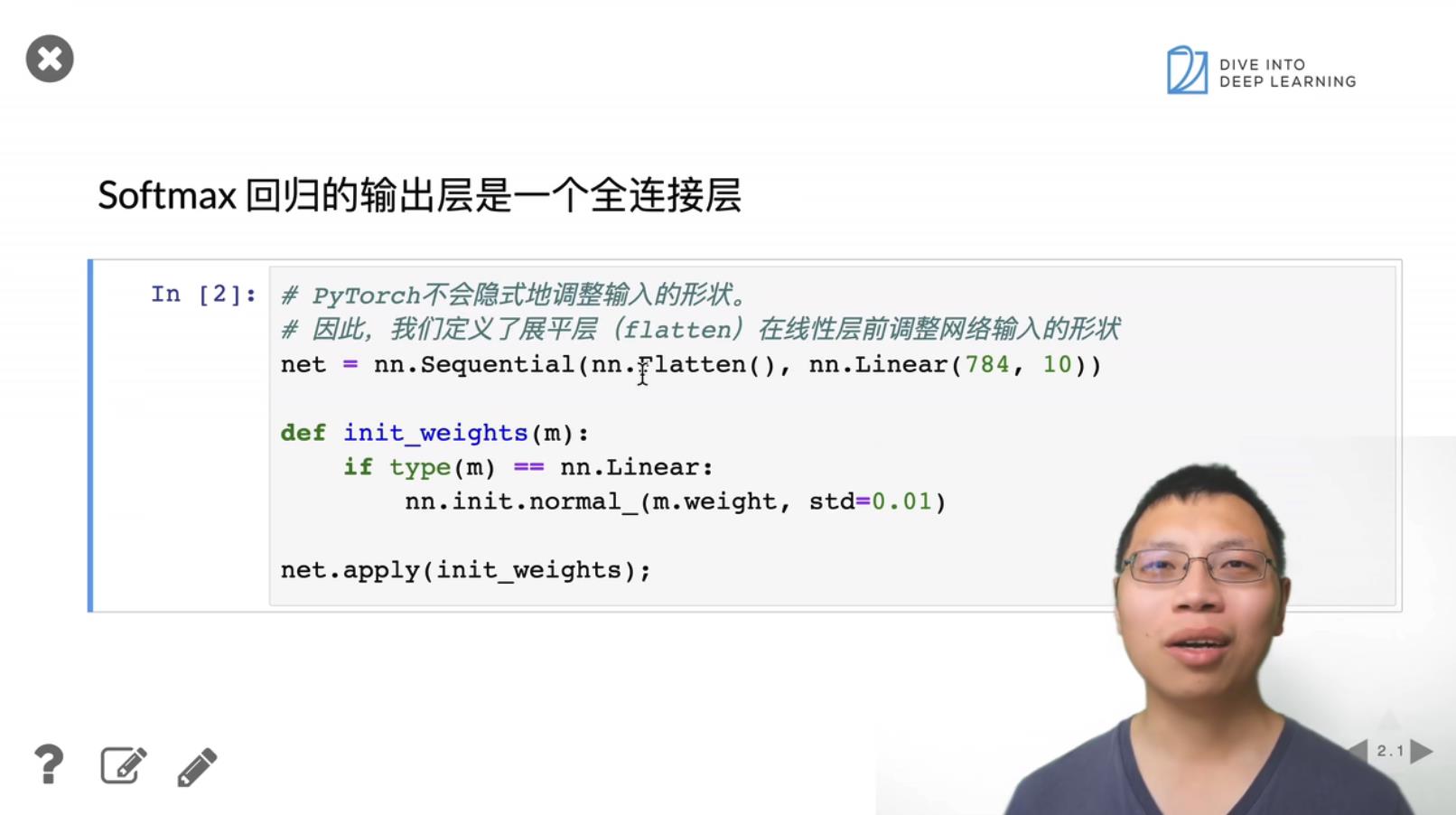


参考
https://www.bilibili.com/video/BV1K64y1Q7wu
以上是关于3.2 线性回归从零开始实现的主要内容,如果未能解决你的问题,请参考以下文章