lucene+1
Posted daitu66
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene+1相关的知识,希望对你有一定的参考价值。
测试代码:
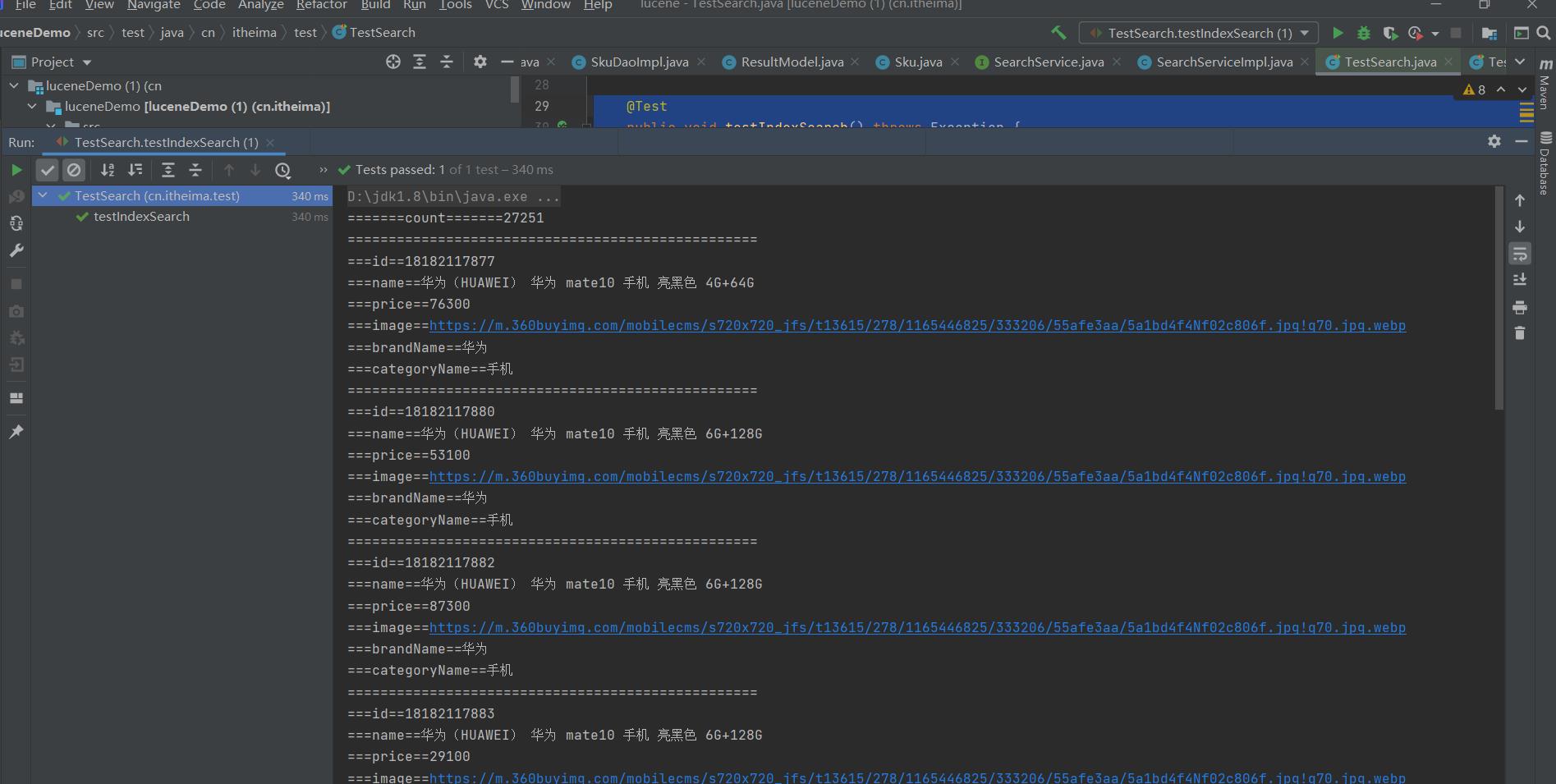
@Test public void testIndexSearch() throws Exception //1. 创建分词器(对搜索的关键词进行分词使用) //注意: 分词器要和创建索引的时候使用的分词器一模一样 Analyzer analyzer = new StandardAnalyzer(); //2. 创建查询对象, //第一个参数: 默认查询域, 如果查询的关键字中带搜索的域名, 则从指定域中查询, 如果不带域名则从, 默认搜索域中查询 //第二个参数: 使用的分词器 QueryParser queryParser = new QueryParser("name", analyzer); //3. 设置搜索关键词 //华 OR 为 手 机 Query query = queryParser.parse("华为手机"); //4. 创建Directory目录对象, 指定索引库的位置 Directory dir = FSDirectory.open(Paths.get("E:\\\\dir")); //5. 创建输入流对象 IndexReader indexReader = DirectoryReader.open(dir); //6. 创建搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //7. 搜索, 并返回结果 //第二个参数: 是返回多少条数据用于展示, 分页使用 TopDocs topDocs = indexSearcher.search(query, 10); //获取查询到的结果集的总数, 打印 System.out.println("=======count=======" + topDocs.totalHits); //8. 获取结果集 ScoreDoc[] scoreDocs = topDocs.scoreDocs; //9. 遍历结果集 if (scoreDocs != null) for (ScoreDoc scoreDoc : scoreDocs) //获取查询到的文档唯一标识, 文档id, 这个id是lucene在创建文档的时候自动分配的 int docID = scoreDoc.doc; //通过文档id, 读取文档 Document doc = indexSearcher.doc(docID); System.out.println("=================================================="); //通过域名, 从文档中获取域值 System.out.println("===id==" + doc.get("id")); System.out.println("===name==" + doc.get("name")); System.out.println("===price==" + doc.get("price")); System.out.println("===image==" + doc.get("image")); System.out.println("===brandName==" + doc.get("brandName")); System.out.println("===categoryName==" + doc.get("categoryName")); //10. 关闭流
Lucene 实战(第2版)
《lucene实战(第2版)》基于apache的lucene3.0,从lucene核心、lucene应用、案例分析3个方面详细系统地介绍了lucene,包括认识lucene、建立索引、为应用程序添加搜索功能、高级搜索技术、扩展搜索、使用tika提取文本、lucene的高级扩展、使用其他编程语言访问lucene、lucene管理和性能调优等内容,最后还提供了三大经典成功案例,为读者展示了一个奇妙的搜索世界。
《lucene实战(第2版)》适合于已具有一定java编程基本的读者,以及希望能够把强大的搜索功能添加到自己的应用程序中的开发人员。lucene实战(第2版)》对于从事搜索引擎工作的工程技术人员,以及在java平台上进行各类软件开发的人员和编程爱好者,也具有很好的学习参考价值。
以上是关于lucene+1的主要内容,如果未能解决你的问题,请参考以下文章