记录一次服务器磁盘爆满问题
Posted ZYPLJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录一次服务器磁盘爆满问题相关的知识,希望对你有一定的参考价值。
服务器磁盘满了!!!
事发突然,我在给博客的图片新增的时候,发现上传文件和下载文件一直报错。因为我用的是1Panel面板去管理服务器,话不多说看图:
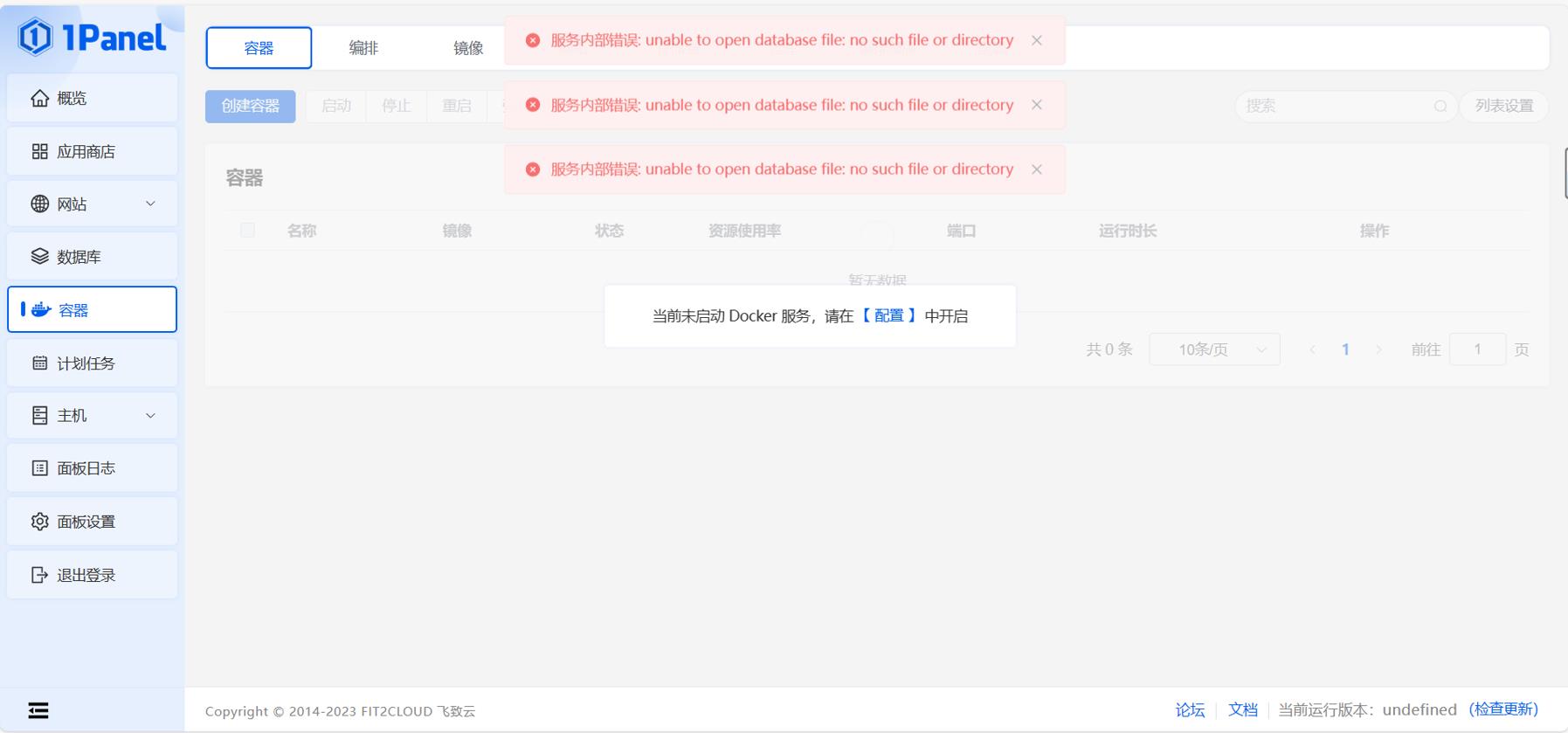
一开始我还不知道发生了什么,一直以为是这个面板出了问题,然后我就一直刷新,强制刷新。发现并无卵用。
然后我就去控制台敲命令,想下个宝塔试试,然后就出现了以下错误,大致意思就是“RPM 数据库无法打开,因为设备空间不足。这通常是由于磁盘空间不足或文件系统损坏导致的。”

然后我就清理缓存文件
yum clean all
然后又修复群文件系统,重建RPM数据库,发现并无卵用,这个时候我已经开始慌了,毕竟数据库和一些博客的数据并没有备份,然后我就开始想办法把数据弄到本地。因为面板肯定是崩了用不了了,我就采用原始的SSH连接,然后用scp命令去下载文件到本地。然后我发现连不上去,很着急,越急这个头脑就越蠢,搞了半天22端口没放开。然后一顿操作也是成功下载了数据到本地

都是些基本操作,可惜博主技术太差,不过还好完美收场。
博客预计26号正常访问
记一次ORACLE的UNDO表空间爆满分析过程
这篇文章是记录一次ORACLE数据库UNDO表空间爆满的分析过程,主要整理、梳理了同事分析的思路。具体过程如下所示:
早上收到一数据库服务器的UNDO表空间的告警邮件,最早一封是7:55发出的(监控作业是15分钟一次),从告警邮件分析,好像是UNDO表空间突然一下子被耗尽了。
|
DB |
Tablespace |
Allocated |
Free |
Used |
% Free |
% Used |
|
192.168.xxx.xxx:1521 |
UNDOTBS1 |
16384 |
190.25 |
16193.75 |
1.16 |
99 |
使用一些SQL分析了undo表空间使用情况,以及undo segment状态等等,非常想定位到是哪个或那些SQL耗尽了UNDO表空间,但是没有一个SQL能实现我的想法,抑或是我不了解。
SELECT UPPER(F.TABLESPACE_NAME) AS "TABLESPACE_NAME",
ROUND(D.MAX_BYTES,2) AS "TBS_TOTAL_SIZE" ,
ROUND(D.AVAILB_BYTES ,2) AS "TABLESPACE_SIZE",
ROUND(D.MAX_BYTES - D.AVAILB_BYTES +USED_BYTES,2) AS "TBS_AVABLE_SIZE",
ROUND((D.AVAILB_BYTES - F.USED_BYTES),2) AS "TBS_USED_SIZE",
TO_CHAR(ROUND((D.AVAILB_BYTES - F.USED_BYTES) / D.AVAILB_BYTES * 100,
2),
‘999.99‘) AS "USED_RATE(%)",
ROUND(F.USED_BYTES, 6) AS "FREE_SIZE(G)"
FROM (SELECT TABLESPACE_NAME,
ROUND(SUM(BYTES) / (1024 * 1024 * 1024), 6) USED_BYTES,
ROUND(MAX(BYTES) / (1024 * 1024 * 1024), 6) MAX_BYTES
FROM SYS.DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) F,
(SELECT DD.TABLESPACE_NAME,
ROUND(SUM(DD.BYTES) / (1024 * 1024 * 1024), 6) AVAILB_BYTES,
ROUND(SUM(DECODE(DD.MAXBYTES, 0, DD.BYTES, DD.MAXBYTES))/(1024*1024*1024),6) MAX_BYTES
FROM SYS.DBA_DATA_FILES DD
GROUP BY DD.TABLESPACE_NAME) D
HERE D.TABLESPACE_NAME = F.TABLESPACE_NAME
AND D.TABLESPACE_NAME=&UNDO_TABLESPACE_NAME
RDER BY 5 DESC;
select usn,xacts,rssize/1024/1024/1024,hwmsize/1024/1024/1024,shrinks
from v$rollstat order by rssize;
既然直接入手,无法定位,那就曲线分析,首先检查、分析了一下redo log,发现在7点这段时间,日志切换了83次之多,横向、纵向对比,明显异常,如下截图所示:
SELECT
TO_CHAR(FIRST_TIME,‘YYYY-MM-DD‘) DAY,
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘00‘,1,0)),‘99‘) "00",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘01‘,1,0)),‘99‘) "01",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘02‘,1,0)),‘99‘) "02",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘03‘,1,0)),‘99‘) "03",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘04‘,1,0)),‘99‘) "04",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘05‘,1,0)),‘99‘) "05",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘06‘,1,0)),‘99‘) "06",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘07‘,1,0)),‘99‘) "07",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘08‘,1,0)),‘99‘) "0",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘09‘,1,0)),‘99‘) "09",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘10‘,1,0)),‘99‘) "10",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘11‘,1,0)),‘99‘) "11",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘12‘,1,0)),‘99‘) "12",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘13‘,1,0)),‘99‘) "13",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘14‘,1,0)),‘99‘) "14",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘15‘,1,0)),‘99‘) "15",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘16‘,1,0)),‘99‘) "16",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘17‘,1,0)),‘99‘) "17",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘18‘,1,0)),‘99‘) "18",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘19‘,1,0)),‘99‘) "19",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘20‘,1,0)),‘99‘) "20",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘21‘,1,0)),‘99‘) "21",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘22‘,1,0)),‘99‘) "22",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘23‘,1,0)),‘99‘) "23"
FROM
V$LOG_HISTORY
GROUP BY
TO_CHAR(FIRST_TIME,‘YYYY-MM-DD‘)
ORDER BY 1 DESC;
生成了实例在7:00~8:00时间段的AWR报告,从下面指标我们可以看出,数据库实例在这段时间呢,其实是非常空闲的,因为DB Time为9.74(mins)
另外,从Time Model Statistics部分来看,主要时间花在background elapsed time,而不是DB Time,我们可以判断时间主要耗费在后台进程,而不是前台进程。另外sql execute elapsed time耗用了DB Time的70.36的时间。
然后我们来看SQL order by Gets部分信息, 第一个SQL是删除WRH$_SQL_PLAN的记录,当然也有删除wrh$_sqltext、WRH$_SEG_STAT_OBJ表记录的SQL,如下所示
DELETE
FROM WRH$_SQL_PLAN tab
WHERE (:beg_snap <= tab.snap_id
AND tab.snap_id <= :end_snap
AND dbid = :dbid)
AND NOT EXISTS
(SELECT 1
FROM WRM$_BASELINE b
WHERE (tab.dbid = b.dbid)
AND (tab.snap_id >= b.start_snap_id)
AND (tab.snap_id <= b.end_snap_id)
)
DELETE
FROM wrh$_sqltext tab
WHERE (tab.dbid = :dbid
AND :beg_snap <= tab.snap_id
AND tab.snap_id <= :end_snap
AND tab.ref_count = 0)
AND NOT EXISTS
(SELECT 1
FROM WRM$_BASELINE b
WHERE (b.dbid = :dbid2
AND tab.snap_id >= b.start_snap_id
AND tab.snap_id <= b.end_snap_id)
);
DELETE
FROM WRH$_SEG_STAT_OBJ tab
WHERE (:beg_snap <= tab.snap_id
AND tab.snap_id <= :end_snap
AND dbid = :dbid)
AND NOT EXISTS
(SELECT 1
FROM WRM$_BASELINE b
WHERE (tab.dbid = b.dbid)
AND (tab.snap_id >= b.start_snap_id)
AND (tab.snap_id <= b.end_snap_id)
);
查看SQL ordered by Reads部分信息,发现主要也是删除系统表WRH$_SQL_PLAN记录 (这个表是非常大的)
DELETE
FROM WRH$_SQL_PLAN tab
WHERE (:beg_snap <= tab.snap_id
AND tab.snap_id <= :end_snap
AND dbid = :dbid)
AND NOT EXISTS
(SELECT 1
FROM WRM$_BASELINE b
WHERE (tab.dbid = b.dbid)
AND (tab.snap_id >= b.start_snap_id)
AND (tab.snap_id <= b.end_snap_id)
)
然后我们查看AWR报告的Tablespace IO Stats部分,IO主要集中在SYSAUX,UNDOTBS1这两个表空间,然后你会发现那个表WRH$_SQL_PLAN就是在SYSAUX下
所以,上面种种证据显示,让我们几乎可以断定主要是下面这个SQL导致了UNDO表空间使用的暴增。当然分析过程中,还有一些旁听佐证。在此感觉没有必要一一列举了。
DELETE
FROM WRH$_SQL_PLAN tab
WHERE (:beg_snap <= tab.snap_id
AND tab.snap_id <= :end_snap
AND dbid = :dbid)
AND NOT EXISTS
(SELECT 1
FROM WRM$_BASELINE b
WHERE (tab.dbid = b.dbid)
AND (tab.snap_id >= b.start_snap_id)
AND (tab.snap_id <= b.end_snap_id)
)
以上是关于记录一次服务器磁盘爆满问题的主要内容,如果未能解决你的问题,请参考以下文章