记录--超长溢出头部省略打点,坑这么大,技巧这么多?
Posted 林恒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录--超长溢出头部省略打点,坑这么大,技巧这么多?相关的知识,希望对你有一定的参考价值。
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助

在业务中,有这么一种场景,表格下的某一列 ID 值,文本超长了,正常而言会是这样:

通常,这种情况都需要超长省略溢出打点,那么,就会变成这样:

但是,这种展示有个缺点,3 个 ID 看上去就完全一致了,因此,PM 希望能够实现头部省略打点,尾部完全展示,那么,最终希望的效果就会是这样的:

OK,很有意思的一个需求,最开始我以为只是实现一个头部超长溢出打点功能,但是随着实践,发现事情并没有那么简单,下面我们就一探究竟。
利用 direction 实现头部超长溢出打点
正常而言,我们的单行超长溢出打点,都是实现在尾部的,代码也非常简单,像是这样:
<p>Make CSS Ellipsis Beginning of String</p>
p
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;

这里,我们可以通过 direction,将省略打点的位置,从尾部移动至头部:
p
direction: rtl;
结果如下:

简单介绍一下 direction:
direction:CSS 中的direction用于设置文本排列的方向。 rtl 表示从右到左 (类似希伯来语或阿拉伯语), ltr 表示从左到右。
另外两个与排版相关的属性还有:
writing-mode:定义了文本水平或垂直排布以及在块级元素中文本的行进方向。unicode-bidi:它与direction非常类似,两个会经常一起出现。在现代计算机应用中,最常用来处理双向文字的算法是Unicode 双向算法。而unicode-bidi这个属性是用来重写这个算法的。
OK,那么上述需求,是不是简单的添加一个 direction: rtl 就能解决问题呢?我们尝试一下。
direction: rtl 会导致使用下划线 _ 连接的数字内容排版错误
我们给上述的代码,添加一个简单的结构:
<div>
13993199751_18037893546_4477657
</div>
<div>
13993199751_18037893546_4477656
</div>
<div>
13993199751_18037893546_4477655
</div>
div
width: 180px;
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;

~成功了!~看似好像成功了,但是出了一点小问题!
虽然实现了头部打点,但是我们的数字结尾好像不是我们想要的结果,仔细看一下数字的结尾情况:
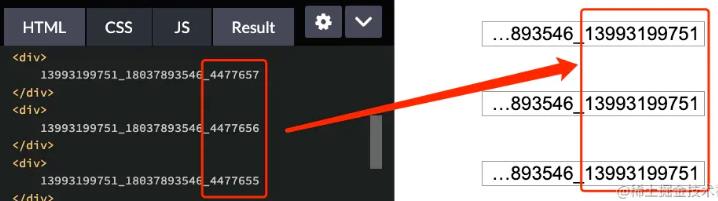
这是什么情况呢?
这是由于 direction 在处理纯数字、非纯数字文本上的规则不一致,我们再来看这么一段测试代码:
<div>
11111_22222_33333_44444
</div>
<div>
11111 22222 33333 44444
</div>
<div>
aaaaa bbbbb ccccc dddddd eeeeee
</div>
<div>
aaaaa_11111_22222_33333_44444
</div>
CSS 层面不考虑溢出情况,仅作用 direction: rtl 。
div
width: 240px;
direction: rtl;
在修改书写方向后,效果如下:

可以看到,这里非常核心的一点在于,对于纯数字的文本内容,数字的排列顺序也会跟着相应的书写顺序,进行反向排列!
而形如 11111_22222_33333_44444 这种用下划线连接的文本,处理的方式也会与 11111 22222 33333 44444 一样,实现了从左往右的排列,改变了原有的顺序。
多方案解决
因为我们的 ID是由纯数字加下划线组成,所以无法绕开这种展示。
那么,基于这个现状,我们可以如何去解决这个问题呢?
方案一:两次 direction 反转
方法一,既然最终展示的文案被反转了,那么我们可以尝试通过多一层的嵌套,进行二次反转可以解决问题。
代码如下:
<div class="g-twice-reverse">
<span>13993199751_18037893546_4477657</span>
</div>
.g-twice-reverse
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;
span
direction: ltr;
;
尝试后的结果如下:

...037893546_4477657。不过不用着急,可以尝试再配合 unicode-bidi 属性试一下。最终发现,配合 unicode-bidi: bidi-override 可以实现我们想要的最终效果:.g-twice-reverse
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;
span
direction: ltr;
unicode-bidi: bidi-override;
;
最终结果如下:

完美!这里,我们利用了两层结构:
- 外层的
g-twice-reverse正常设置从右向左的溢出省略打点 - 内容添加一层
span,利用direction: ltr和unicode-bidi: bidi-override的配合,在内部再反向反转排版规则。
当然,这里需要解释一下 unicode-bidi。
bidi-override 的作用是对文本进行覆盖,使得其中的内联元素(inline element)按照我们想要的书写方向展示。而 unicode-bidi: bidi-override 取值的作用是用于覆盖默认的 Unicode 双向算法以控制文本的显示方向。
这里,bidi-override 和 direction 在 <span> 中的组合,实现了更细粒度的文本方向处理。
方案二:通过伪元素破坏其纯数字的性质
上述的方案需要完全理解其思路还是有比较高的成本的,比较烧脑。
有没有更好理解的方案呢?我们继续尝试。
既然上面被反转排版的内容是纯数字或者由下划线连接成的数字,那么我们能不能尝试破坏其纯数字的特性?
譬如,给数组的头部添加一个看不见字母,尝试一下,这里构造两组数据对比一下:
<div class="g-add-letter">
<span>a</span>
<span>546_4477657</span>
</div>
<div class="g-add-letter">
<span>a</span>
<span>13993199751_18037893546_4477657</span>
</div>
.g-twice-reverse
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;
看看效果:

嘿,别说,这个方案看上去真的可行。只是添加一个 <span>a</span> 肯定是不合适的,后面维护的同学肯定一脸懵逼。并且这个 a 字母需要隐藏起来。思来想去,这不是和以前清除浮动的场景非常类似吗?这里使用伪元素再贴切不过,我们再改造下代码:
<div class="g-add-letter">
<span>546_4477657</span>
</div>
<div class="g-add-letter">
<span>13993199751_18037893546_4477657</span>
</div>
.g-add-letter
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;
span::before
content: "a";
opacity: 0;
font-size: 0;
我们通过伪元素,使用在元素前面添加了一个字母 a,并且设置伪元素的 font-size: 0 和 opacity: 0,从外观上,完全看不出有这么个元素,非常好的隐藏了起来,同时,起到了破坏内容其纯数字的性质。
效果如下:

方案三:通过 \\200e LRM 标记位
我们继续优化我们的方案。
上面通过伪元素的方式,已经能够实现在对业务结构影响最小化及代码增量较少的前提下,实现想要的结果。
问题还是在于插入的这个字母 a,一来是不够优雅,二是这种解决方案更像是一种 HACK 的解决方式,随着时间长河的推进,这种代码即便留下了注释,也容易造成可读性上困扰。
所以,我们需要尝试替换掉这个 a 字母。
这里,通过查阅资料,最终找到了这样一个字符 -- \\200e。
\\200e:是左到右标记(Left-to-Right Mark,LRM)的 Unicode 码点。它是 Unicode 字符方向控制工具之一,用于强制将文本的阅读方向指定为从左到右。在前端排版中,特别是处理多语言文本时,由于不同语言书写时有不同的书写方向,因此可以使用 LRM 来指定文本的书写方向,以确保文本能够正确地显示。
这里,通过 \\200e 替换掉 a,这里用 \\200e 的目的与 a 的目的其实是不一样的:
- 在字符串前面通过伪元素添加一个
a,目的是破坏其纯数字的特性 - 在字符串前面通过伪元素添加一个
\\200e,目的是强制控制接下来文本的排版顺序
添加 a 的方案类似于一种 Hack 技巧,而 \\200e 可以理解为就是专门解决这种场景而诞生的特殊字符。
好,看看改造后的代码:
<div class="g-add-letter">
<span>13993199751_18037893546_4477657</span>
</div>
.g-add-letter
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;
span::before
content: "\\200e";
opacity: 0;
font-size: 0;
效果如下:

这样,我们算是比较完美的解决了这个问题。
方案四:通过 <bdi> 标签
那么,上述的方案已经是最佳方案了吗?或者说,还有没有不需要添加伪元素的方式?
在查找解法的过程中,还发现了一个非常有意思的标签 -- <bdi>。
<bdi>:是一个 HTML 标签,表示“双向的隔离器”(Bidirectional Isolation)。它是一个比较新的标签,主要用于解决混合显示多个语言文本时的排版问题。
在多语言文本中,由于不同语言之间的书写方向和文本组织方式可能有所不同,如果直接拼合在一起显示,容易导致排版混乱,甚至出现不合法的语言混排现象。而 <bdi> 标签则提供了一种简单的解决方案,可以隔离不同的语言文本,确保它们按照正确的顺序呈现,并避免混乱的语言混排现象。
具体来说,<bdi> 标签可以将一段文本从周围文本隔离开来,创建一个独立的文本环境,使得文本能够按照正确的书写方向呈现。在使用该标签时,可以使用 dir 属性来指定文本的书写方向,可以是从左到右(dir="ltr")或者从右到左(dir="rtl")等。
综上所述,<bdi> 标签的作用是提供一种简单的解决方案来排版混合显示多个语言文本,通过隔离不同的语言文本,确保它们按照正确的顺序呈现,并避免混乱的语言混排现象。
因此,利用 <bdi> 标签,我们可以再进一步省略掉伪元素的部分:
<div class="g-bdi">
<bdi dir="ltr">13993199751_18037893546_4477657</bdi>
</div>
.g-bdi
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
white-space: nowrap;
此种方案就比较纯粹,回归了最初的代码,只是多了一层 <bdi> 并且设置了其内部语言排版方向。
最终,结果如下:

上述四种方案的完整代码,你也可以戳这里:CodePen Demo -- 多种方式解决下划线数字的头部溢出省略打点排版问题
总结一下
本文,我们介绍了一种在头部省略溢出的情境下,对于形如 11111_22222_33333_44444 这种用下划线连接的文本,处理的方式会被对待成 11111 22222 33333 44444 一样的情况,导致了最终排版结果与我们的预期不符。
为了解决这种问题,我们介绍了 4 种不同的解决方案:
- 方案一:两次
direction反转 - 方案二:通过伪元素添加字母,破坏其纯数字的性质
- 方案三:通过
\\200eLRM 标记位 - 方案四:通过
<bdi>标签
上述 4 个方案的思维与处理方式各有优劣。围绕多语言排版涉及了不同的知识,从一个很小的需求中,能够窥探到其中复杂的逻辑。是一个很好的业务实操案例。
本文转载于:
https://juejin.cn/post/7226540105698197563
如果对您有所帮助,欢迎您点个关注,我会定时更新技术文档,大家一起讨论学习,一起进步。

“坑”这么多,为什么我们还要做 Serverless?

导语 | Serverless 近年来炙手可热,在传统的 IT 架构已不适应当今快速发展的数字经济环境的背景下,Serverless 和 FaaS 是不是解决问题的银弹?在实际应用中,Serverless 的表现又是如何?本次演讲将分享 Serverless 的落地场景、问题与优势,探讨如何利用 Serverless 助力业务发展。本文由同程艺龙机票事业群CTO、腾讯云TVP 王晓波在 Techo TVP 开发者峰会 ServerlessDays China 2021上的演讲《Serverless 落地应用的趋势》整理而成,向大家分享。
点击可观看精彩演讲视频
一、架构设计的过程就是挖坑与填坑
我是做OTA的,我们产品就是机票、火车票、酒店等等,最近有一个机票盲盒挺热的,那个是我们原创的,也是在 Serverless 上做的。今天主要讲 Serverless 的原因是,五年前我们做了自己的 Serverless,为什么做呢?我们当时也没发现这个有多高大上,是因为被业务逼的:一是能不能以最快的速度上线?最好早上想出一个绝妙的idea,下午就上线。我们说不行,得加个设计、服务器部署……业务说,什么意思,不就写行代码吗?于是,我们被逼得不行了,KPI被压得很紧,我们这时候想到,如果我们去做不用关心服务器、不用关心部署和框架,甚至不用关心开发过程的办法,于是就去做了 Serverless。
五年前因为各种原因,也没有真正可以生产的 Serverless,于是我们自己开始从零做起,但自己做是比较简单的,因为我们不需要对外销售或者对外服务,我们只服务自己,不通的地方用行政命令就能解决;但对外,这件事就做不到了。落地趋势上来说,这五年我们一直把应用放上去,也有很多应用拿了出来,在分享的开始,我们一起来想这么几个问题:我们为什么要用 Serverless,只是为了让我们的架构设计好看一点吗?我们的架构师喜欢“追星”,怕落伍于时代?还是说我们真正要解决什么问题?第二是,Serverless 到底解决什么问题?一开始大家想到它可以弹性计算,弹性计算省的前真的比业务更重要吗?有些问题把它想到极致点的时候,可能更加容易解决,并不一定非得用一个技术去解决。另外,Serverless 怎么助力业务?难道只是为了更快的需求变现吗?那我们多招些程序员不是更快吗,如果HR同学足够努力,那 Serverless 就不用做了,因为有足够的工程师帮助变现。
带着这些问题我们再去想用 Serverless 做什么?来看架构设计的过程,其实架构设计的过程本身,我认为就是一个填坑与挖坑的过程。我们觉得单体应用不好,所以从单体的坑里爬出来,去旁边挖了一个微服务的坑,用挖出的土把单体的坑填了。当我们觉得微服务很难治理的时候,在旁边挖了一个service mesh的坑,又把这些土填回微服务的坑。后来我们又觉得 Serverless 很火,于是又挖了一个坑,挖到一半突然觉得隔壁单体的坑看起来不错,因为这么多微服务拉不起来,而单体就一个,我们是不是应该回归单体呢?于是就出来这么多填坑和挖坑的故事,也正好是刚才我们提到的,我们为什么去想 Serverless?因为在填坑和挖坑背景之下就是我们要解决业务应用难题的时候,在每一个时代,整个基础设施是不一样的,所以我们在那个时代填那个时代的坑的时候,发现因为基础设施落后,我们在架构上想了很多办法;当基础设施在提高的时候,于是我们架构设计又开始回归,这是不停循环的过程。
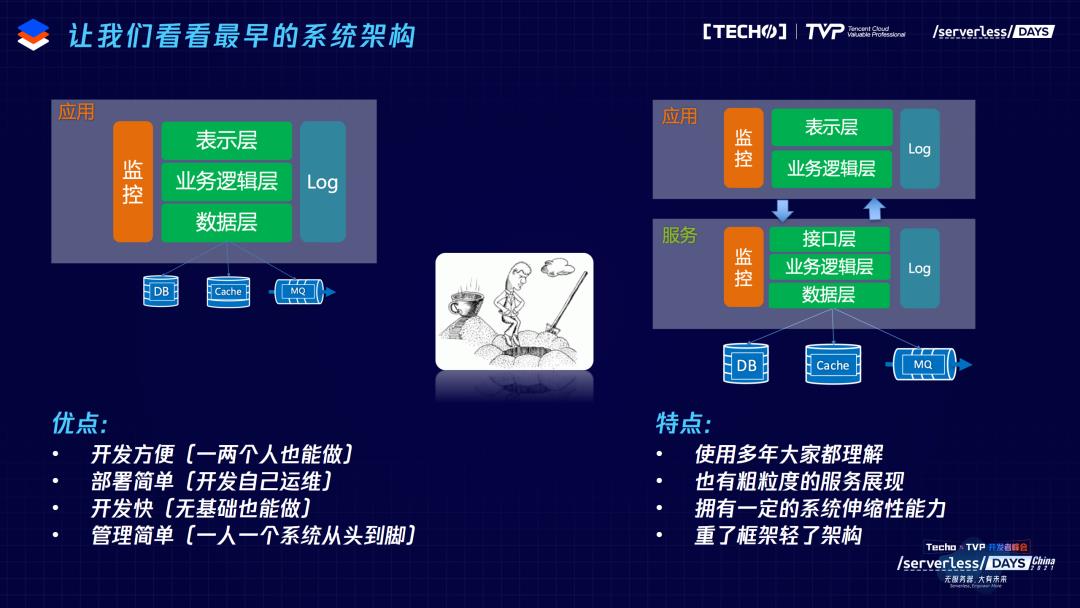
回到原点,最早的时候应用怎么做?其实很简单,只需应用+数据库,最多在数据库上再放点缓存,运维也很简单,只需要看生死。但随着坑越挖越大,业务需求越来越多,系统规模越来越大,麻烦出现了。最早我们把前后拆开来,把一些服务单独部署出来,服务化、总线开始出现,这个时候架构本身意义上来说,它并没有大的变化,只是把原来完整的整体切分出多个个体。这个情况很多新的程序员还没有切身感受——什么是单体应用?现在的其实跟当年真正的单体应用差很多,我毕业时,一个单体运转起来上百G的内存就没了,非常依赖CPU的性能,成千上万的应用卡在代码里,根本分不清。但是到我们服务化之后,又出现问题,简单的服务化可能带来的是什么?更多的被部署,调用了无序,各种麻烦出来了,我们的问题是看到这么一张图(见下图),我们的运维、架构师看到所有应用的时候,就像看到那几个小孩把东西弄得杂乱无章,为什么?因为应用从1到10很简单,但拆成上万个应用的时候,可以想象刚才那种模式的大缺点是互相没有关系、不知道互相做了什么,这就带来大量重复的劳动,然后链路上到底哪一块是我们真正的压力?再下来,原来很简单的一句SQL,是否现在没法用了?一系列的问题带来了刚才架构的凌乱。

那为什么被如此吐槽的单体应用在今天还有大量的新增呢?甚至很多创业公司就是单体起家的,因为它能实现快速迭代。我们需要的并不是庞大而复杂的技术架构或者业务架构,我们真正要服务的是整个业务的快速变现和快速试错。这样的过程中,在量独大的情况下,这个场景下单体非常适合。但单体变大又带来很多麻烦,怎么办?微服务治理真能把它治理好吗?看起来这样的微服务架构是很好,但是很复杂,复杂到可能几个程序员都搞不定,或者随着时间推移一样会带来下一件事情——你的微服务越来越大,越来越像原来你所讨厌的那个单体的形象——很大,跑不动,所有的都在一起。但微服务里依然在发生,为什么?因为没有真正的方法论去控制微服务有多“微”,或者有多小,或者什么时候该再起一个服务?举个例子,我见过很多奇怪的服务,比如在正常的情况下,出现订单服务,突然在某一天有紧急需求,在没有控制、迫不得已的情况下,新做了个列表,改名为新订单查询接口,下单接口也同理,也许会出现新下单接口、新新下单接口、新新新下单接口……也许还会出现“老下单接口”、临时下单接口等等。我们有十年左右的微服务积累,发现了很大的问题,我们积累了很多微服务,最早的到现在都没有下线,因为不知道哪个老旧项目是否还需要。公司的运维都说:你们的微服务只有上线,没有下线。它们不停膨胀,名字乱七八糟,这样的微服务又比单体好到哪里?单体是在一个代码加,部署在一个实例里,现在只是部署在不同的服务器上,让不同服务器膨胀而已,最后的结果对于我们快速的变现、很好的运维、质量保障,对整个体系没有任何好处。

微服务带来的是虚假的繁荣景象,链路、扩容都有问题,其实在真实业务情况下,扩容从来不是因为某一个服务器,或者某一个部署不够,拉起不够,最大的问题永远来自于链路无法更新、链路上有很多单节点问题,或者有些点就是无法扩容的。再好的微服务与基础设施一样无法扩容。这样的麻烦点带来一个问题,在现有的微服务体系或单体体系,如何更高速地让你的应用成长、业务变现更快?这个情况下,我们的架构到底出了什么样的问题,所以导致我们现在不管怎么做,都快不起来?
总结一下,第一个是我们可不可能用一两个小时写个服务并上线?为什么不能呢?因为受制于开发过程,或受制于服务基础设施对开发过程的支持问题。第二个是研发是否需要关注每个服务器?代码同学可能不愿意想,但整个轮子是自己造的,一系列的事情都要被考虑,在DevOps里是一个很大的问题。因为这两点,整个需求的前置条件就越来越多。再下来,开发人员可以像操作IDE那样完成他不熟悉的技能吗?如果一直用同一种编程语言可能没问题,但如果没有很好的培训体系,或没有单一的技术架构体系下,这也是一个麻烦点,我们真的有那么多全栈工程师吗?接着是运维智能化,今天我们看到的运维都是人在运维,是真的“人工”智能。这些加起来,尤其是第一第二点,是我们最大的“坑点”所在。

程序员可以安静地写代码吗?今天的程序员真正写程序的时候,真的很痛苦。左边的框架是JAVA的,有一系列的问题,正好是在阻止程序员的变现速度,在写每一行代码的时候需要考虑的太多了:各种组件怎么用,各种规则怎么办,各种配置在哪里,各种工程结构在哪里?其实很多业务代码很少,但根本没有办法快速上线。

那我们程序员真的幸福吗?其实很多情况下,我们程序员叫重构,每个程序员在工作时,听到最多的一句话就是我们需要再迭代一下,迭代一下就是代码需要重做一下,或者重写了。为什么会出现这样的问题?因为我们的业务逻辑不够纯粹,或者业务逻辑纯粹之后独立部署的比较少,都是互相关联的状态。当业务逻辑不够独立或者设计不太完美的情况下,我们试图做成完美服务体系的时候,一个业务点发生变化会带来一系列变化,导致的问题是大量重构和重写。我想在这里引出 Serverless 的一个点,既然我们避免不了重构,也避免不了业务变化,业务确实一直在变化,重构一直在发生,不如让我们更加开心地、更爽地去重构、去变化。既然我们的代码用了一段时间一定会变成没用的,那就让它自然死亡,不要变成僵尸,这也是触发我们去做 Serverless 的一个点,让我们代码转换速度变得更快,让我们废弃代码或者重新做成代码成本越来越低,我重新做它的时候并没有让整个工程都去重构,这样的事情实现的时候,也让我们的代码业务逻辑片断不停地被重新迭代。
二、为什么要做 Serverless 架构?
剩下的就是刚才说的各种环境依赖,这也是我们做 Serverless 很大的点。整个环境依赖状态下,我们一直忽略了生产中一个很大的问题——整个开发过程。这件事情其实被我们所有架构师忽略,或者大部分技术分享的时候也很少提及。大部分时间下,我们一直在集中生产,怎么让生产更稳定,怎么做故障的转移、自愈,怎么做弹性、扩容,却很少想到我们怎么更舒服地开发、写代码。因为任何一个架构做出来,一定要从写代码、调试、测试开始,但我们回头看看今天的开发测试过程,如果把整个框架的可扩展性、整个架构可扩展性排除外,今天开发过程是不如单体状态下的,因为太麻烦了。本来我自己本地就可以跑起来的代码不得不依赖一个开发环境,本来很容易做的测试的状态不得不依赖测试环境,而测试环境又互相依赖和冲突,以至于测试没有办法真正把环境更好地测试。如果把这些都隔离出来,每个程序员、每个开发、每个测试都有完整独立的环境,可以解决这个环境,但是可以想象这个成本会有多大,而且要保证这个环境的代码是同步的?

紧接着的运维部署也极其恐怖,现在很多公司一直在说DevOps,但真正情况下我们运维和开发是分离的,这个分离不是人的分离,人在哪个组织架构并不重要,重要的是人看事物的角度是否一致,很多情况下运维和研发是不一致的角度,运维看到的是一个个铁壳服务器,研发同学看到的是一行行代码,两者之间没有很好的共同的视角,导致很多问题是Dev和Ops分开的状态。

这件事情在 Serverless 角度也是这个状态。在 Serverless 眼中,就是硬币的两个面,如果我们把基础研发和业务系的研发看成两个面,代表了不同的角度。我们先来看基础系的同学,今天很多 Serverless 框架或者 Serverless 工具都是基于相同的理念做出来的,大量的工程师是基础架构研发团队出身,我也是这样,三年前一直在从事基础架构,从基础架构程序员到架构师再到CTO,所以在基础架构同学眼里,永恒的一件事情是什么?我做的这个东西在没有出问题的时候,在向别人介绍的时候,都是银弹,你用我的能解决所有问题,包治百病!等到故障出现的时候就说你们用错了,我不是银弹!从基础架构同学眼里看业务同学,永远是CRUD,“云程序弹性工作我已经完成了,不是可以快速拉起吗?”如果转化到业务的视角,个人经历来说,正好这三年我做业务去了,我刚到业务团队时想:这不是很简单吗?指挥几百个基础架构的人都这么轻松,指挥上千个业务同学更简单。其实不是这样的,业务更注重的是模型。业务模型的变化带来程序的变化,也就是,让自己试图变成运营和产品。再下来业务逻辑代码是不是一定的?如果找不到对应代码,未来维护非常麻烦,某个业务点的改动一定会针对代码,中间出现断层就麻烦了。工程进度也越快越好,因为所有人都催你赶紧上线。一条 SQL 到一个服务的距离到底有多远?一个代码脚本能不能就是一个微服务?如果重构是天性,能不能让重构变得廉价?今天 Serverless 就在完成这几件事,更轻地做服务,让重构变得更廉价。

如果基于 Serverless 架构,从研发人员的角度看,整个编码过程到线上过程其实是比较完整的闭环状态。这是我们当年自己做平台的时候,梳理出的每一个脚本联系的关系。还有整个编程过程,SDK是不是可以做得更好,面向无服务状态?比如我们去数据库拉下数据也好,是不是能把类似于SQL的传统写法去掉?既然是无服务器架构,开发过程为什么还要面向服务器,还要问“我的DB服务器在哪里”,完全可以把它变成一个对象。

最后还有整个Gateway弹性扩容的能力和云化IDE。这些事情是我们当时第一个就去做的,甚至比框架还要早,我们想解决的是开发效率的问题,云化IDE让大家通过浏览器就可以编程。这件事其实一开始是极其失败的,所有编程的同学都说,工具在你这里都变成私有的状态了。但我们尝试至今,整个 Serverless 还是不错的,它最好的状态是节省了大量开发的效率问题,当然真正的开发过程没有那么多,还要写代码,但开发周边的事都被省下来了。

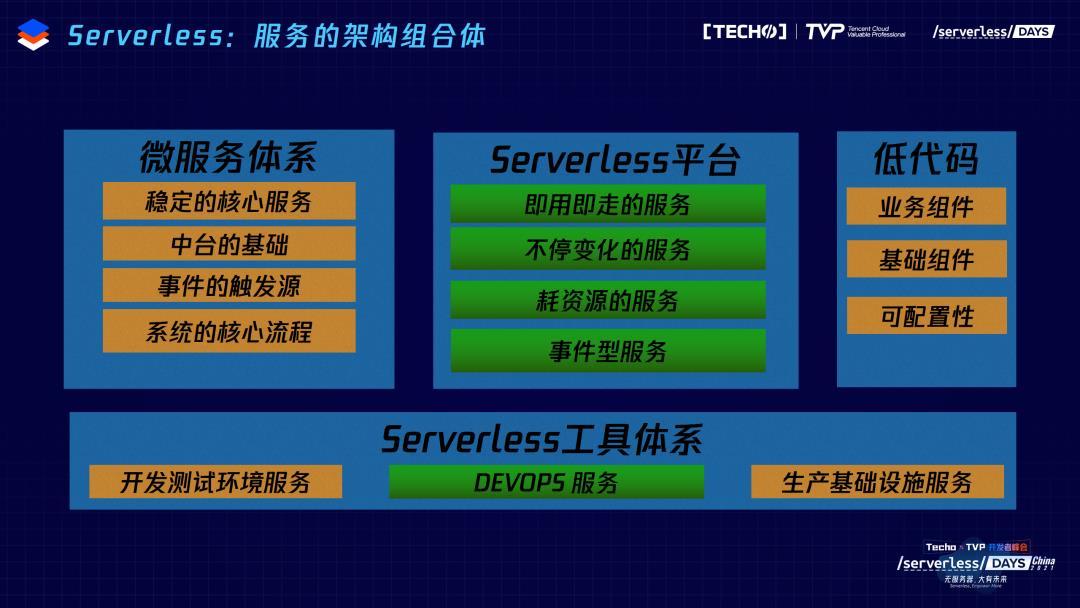
我们是比较多栈的,现在前端所有东西的中间层全部在 Serverless 上;另外还有很轻的服务,在服务过程中很多情况下会面临一个问题,当服务很轻的时候,几百上千行代码就能解决,这些我们都放在 Serverless 平台上处理,可以快速增删;还有弹性极致的问题,每次实时计算的节点会有很多,每个人搜索的时候计算的数据量都是不一样的,我们就用了大量计算脚本跑在 Serverless 平台上。这是我们整个 Serverless 平台的结构,不可变的、重的沉淀在微服务体系,在这个基础上再通过事件触发,联动整个 Serverless 平台的脚本,我们低代码平台也是这样的。
最后,Serverless 核心的价值一定不是省下那几台服务器的钱,更多是整个变现速度的提升,谢谢大家。
讲师简介

王晓波
同程艺龙机票事业群CTO、腾讯云TVP
同程艺龙机票事业群CTO、腾讯云TVP,专注于云计算,高并发互联网架构设计、分布式电子商务交易平台设计、大数据分析平台设计、高可用性系统设计。完成同程基础架构建设,私有云系统建设,主要基础中间件研发。拥有十多年丰富的业务技术架构,基础架构经验,深刻理解技术驱动力的重要性。
推荐阅读
连接人与万物,腾讯云 Serverless 助力打造更友好的世界
创下国内 Serverless 峰会新记录!第二届 Techo TVP 开发者峰会闪耀北京
腾讯云以 Serverless 之名,助力企业加速实现云端创新
点击观看峰会的精彩总结视频????
???? 错过了直播懊悔不已?本次峰会所有嘉宾的演讲视频回顾上线啦,点击「阅读原文」即可观看~
???? 看视频不过瘾还想要干货PPT?关注本公众号,在后台回复关键词「serverless」即可获取!

以上是关于记录--超长溢出头部省略打点,坑这么大,技巧这么多?的主要内容,如果未能解决你的问题,请参考以下文章