yolov5+deepsort+slowfast复现
Posted 东血
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov5+deepsort+slowfast复现相关的知识,希望对你有一定的参考价值。
1.运行环境
ubuntu 18.04.1
Cuda 11.5
Python 3.8.15
torch 1.10.1+cu113
torchvision 0.11.2+cu113
2.安装PyTorchVideo
cd /home
git clone https://gitee.com/YFwinston/pytorchvideo.git
cd pytorchvideo
pip install -e .
3.安装yolov5-slowfast-deepsort-PytorchVideo
下载yolov5-slowfast-deepsort-PytorchVideo
使用gitee(推荐)
cd /home
git clone https://gitee.com/YFwinston/yolov5-slowfast-deepsort-PytorchVideo.git
安装
cd /home/yolov5-slowfast-deepsort-PytorchVideo
pip install -r requirements2.txt
下载文件
[yolov5_file](阿里云盘 (aliyundrive.com))
[slowfast_file](阿里云盘 (aliyundrive.com))
我是将ckpt.t7放在了:/user-data/yolov5_file/
我是将SLOWFAST_8x8_R50_DETECTION.pyth放在了:/user-data/slowfast_file/
我是将yolov5l6.pt放在了:/user-data/yolov5_file/
我是将yolov5-master.zip放在了:/user-data/yolov5_file/
mkdir -p /home/yolov5-slowfast-deepsort-PytorchVideo/deep_sort/deep_sort/deep/checkpoint/
cp /user-data/yolov5_file/ckpt.t7 /home/yolov5-slowfast-deepsort-PytorchVideo/deep_sort/deep_sort/deep/checkpoint/ckpt.t7
mkdir -p /root/.cache/torch/hub/checkpoints/
cp /user-data/slowfast_file/SLOWFAST_8x8_R50_DETECTION.pyth /root/.cache/torch/hub/checkpoints/SLOWFAST_8x8_R50_DETECTION.pyth
cp /user-data/yolov5_file/yolov5l6.pt /home/yolov5-slowfast-deepsort-PytorchVideo/yolov5l6.pt
cp /user-data/yolov5_file/yolov5-master.zip /root/.cache/torch/hub/master.zip
4.测试
我将1.mp4存放在了/home/yolov5-slowfast-deepsort-PytorchVideo/demo/中
cd /home/yolov5-slowfast-deepsort-PytorchVideo
mkdir demo
cd /home/yolov5-slowfast-deepsort-PytorchVideo
python yolo_slowfast.py --input ./demo/1.mp4
报错1
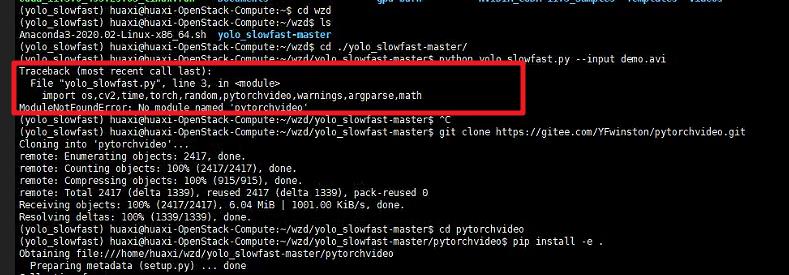
报错2
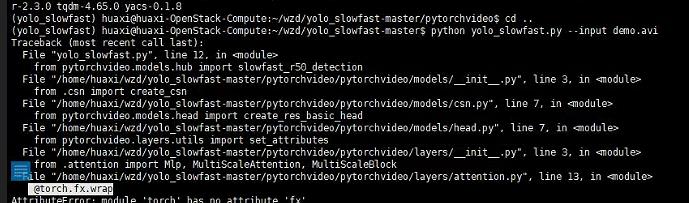
照着这个连接操作
报错3
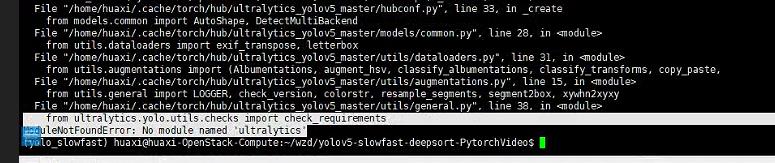

5.替换成自己的数据集
ing
参考文章
视频实时行为检测——基于yolov5+deepsort+slowfast算法
文章目录
前言
前段时间打算做一个目标行为检测的项目,翻阅了大量资料,也借鉴了不少项目,于是打算通过yolov5实现目标检测,deepsort实现目标跟踪以及slowfast实现动作识别,最终实现端到端的目标行为检测模型。
一、核心功能设计
总的来说,我们需要能够实现实时检测视频中的人物,并且能够识别目标的动作,所以我们拆解需求后,整理核心功能如下所示:
- yolov5实现目标检测,确定目标坐标
- deepsort实现目标跟踪,持续标注目标坐标
- slowfast实现动作识别,并给出置信率
- 用框持续框住目标,并将动作类别以及置信度显示在框上
最终效果如下所示:
视频AI行为检测
二、核心实现步骤
1.yolov5实现目标检测
“YOLO”是一种运行速度很快的目标检测AI模型,YOLO将对象检测重新定义为一个回归问题。它将单个卷积神经网络(CNN)应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框。YOLO非常快,它比“R-CNN”快1000倍,比“Fast R-CNN”快100倍。YOLOv5是YOLO比较新的一个版本。
所以我们把视频分解成多幅图像,并利用yolov5算法进行目标检测并逐帧执行时,可以看到目标跟踪框随目标移动。
效果如下所示:

2.deepsort实现目标跟踪
但是,如果视频帧中有多个目标,如何知道一帧中的目标和上一帧是同一个对象?这就是目标跟踪的工作,应用多个检测来识别特定目标随时间的变化,实现目标跟踪。
Deepsort是实现目标跟踪的算法,从sort(simple online and realtime tracking)演变而来,其使用卡尔曼滤波器预测所检测对象的运动轨迹,匈牙利算法将它们与新的检测目标相匹配。Deepsort易于使用且运行速度快,成为AI目标检测跟踪之热门算法。
首先来看一下DeepSORT的核心流程:
预测(track)——>观测(detection+数据关联)——>更新
- 预测:预测下一帧的目标的bbox,即后文中的tracks
- 观测:对当前帧进行目标检测,仅仅检测出目标并不能与上一帧的目标对应起来,所以还要进行数据关联
- 更新:预测Bbox和检测Bbox都会有误差,所以进行更新,更新后的跟踪结果通常比单纯预测或者单纯检测的误差小很多。

3.slowfast动作识别
我们将视频序列和检测框信息输入行为分类模型,输出每个检测框的行为类别,达到行为检测的目的。
而行为分类模型我们采用的是slowfast算法,其包括一个Slow路径,以低帧速率操作,以捕捉空间语义,以及一个Fast路径,以高帧速率操作,以精细的时间分辨率捕捉运动。快速路径可以通过减少信道容量而变得非常轻量级,同时还可以学习有用的时间信息用于视频识别。

三、核心代码解析
1.参数
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--input', type=str, default="test/test1.mp4", help='test imgs folder or video or camera')
parser.add_argument('--output', type=str, default="output/out1.mp4", help='folder to save result imgs, can not use input folder')
# object detect config
parser.add_argument('--imsize', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou', type=float, default=0.4, help='IOU threshold for NMS')
parser.add_argument('--device', default=0, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--classes', default=0,nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
config = parser.parse_args()
print(config)
main(config)
从__main__开始分析,设置了输入输出参数以及目标检测的一些参数,包括输入路径、输出路径、尺寸大小、置信度、iou值、以及目标检测的类别,其中0是人。
2.主函数
对输入的config参数解析并使用,模型使用yolov5l6,权重下载到本地
model = torch.hub.load('ultralytics/yolov5', 'yolov5l6') #加载yolov5模型
model.conf = config.conf
model.iou = config.iou
model.max_det = 200
model.classes = config.classes
device = config.device
imsize = config.imsize
video_model = slowfast_r50_detection(True).eval().to(device) #加载slowfast_r50_detection模型
# video_model = slowfast_r50_detection(False).eval().to(device)
# video_model.load_state_dict(torch.load("SLOWFAST_8x8_R50_DETECTION.pyth")['model_state'])
加载Slowfast、Deepsort模型,使用的Slowfast是在AVA2.2上训练的,通过AvaLabeledVideoFramePaths函数获得id到动作的mapping
deepsort_tracker = DeepSort("deep_sort/deep_sort/deep/checkpoint/ckpt.t7") #加载DeepSort模型
ava_labelnames,_ = AvaLabeledVideoFramePaths.read_label_map("selfutils/temp.pbtxt") #加载类别标签
ava_labelnames_abnormal,_ = AvaLabeledVideoFramePaths.read_label_map("selfutils/ava_action_abnormal.pbtxt") #加载类别标签
coco_color_map = [[random.randint(0, 255) for _ in range(3)] for _ in range(80)]
读取视频和载入视频
vide_save_path = config.output
video=cv2.VideoCapture(config.input) #读取视频
width,height = int(video.get(3)),int(video.get(4))
video.release() #释放资源
outputvideo = cv2.VideoWriter(vide_save_path,cv2.VideoWriter_fourcc(*'mp4v'), 25, (width,height))
print("processing...")
video = pytorchvideo.data.encoded_video.EncodedVideo.from_path(config.input) # 载入视频
首先对视频进行抽帧处理,通过get_clip()对一秒内的视频进行抽帧,只保留视频图片,将tensor转numpy数组,BGR格式
a=time.time()
for i in range(0,math.ceil(video.duration),1): #截视频
video_clips=video.get_clip(i, i+1-0.04)
video_clips=video_clips['video']
if video_clips is None:
continue
img_num=video_clips.shape[1]
imgs=[]
for j in range(img_num):
imgs.append(tensor_to_numpy(video_clips[:,j,:,:]))
# "video": A tensor of the clip's RGB frames with shape: (channel, time, height, width).
# 将tensor转为numpy数组,BGR格式
通过yolov5网络进行目标检测
yolo_preds=model(imgs, size=imsize)
# 每25帧后插入1帧作为预测图像
yolo_preds.files=[f"img_i*25+k.jpg" for k in range(img_num)]
print(i,video_clips.shape,img_num)
使用预训练的Deepsort权重,以yolo预测结果作为输入,用Deepsort的结果代替yolo预测的结果,这里Deepsort是用来给相同id的目标分配动作label的。
deepsort_outputs=[]
for j in range(len(yolo_preds.pred)):
temp=deepsort_update(deepsort_tracker,yolo_preds.pred[j].cpu(),yolo_preds.xywh[j][:,0:4].cpu(),yolo_preds.imgs[j])
if len(temp)==0:
temp=np.ones((0,8))
deepsort_outputs.append(temp.astype(np.float32))
yolo_preds.pred=deepsort_outputs
通过ava_inference_transform()函数对预测输入进行预处理,然后通过调用Slowfast模型进行预测,最后为每个id分配动作类别
id_to_ava_labels=
if yolo_preds.pred[img_num//2].shape[0]:
inputs,inp_boxes,_=ava_inference_transform(video_clips,yolo_preds.pred[img_num//2][:,0:4],crop_size=imsize)
inp_boxes = torch.cat([torch.zeros(inp_boxes.shape[0],1), inp_boxes], dim=1)
if isinstance(inputs, list): #判断类型
inputs = [inp.unsqueeze(0).to(device) for inp in inputs]
else:
inputs = inputs.unsqueeze(0).to(device)
with torch.no_grad():
slowfaster_preds = video_model(inputs, inp_boxes.to(device)) #预测动作
slowfaster_preds = slowfaster_preds.cpu()
for tid,avalabel,avapred in zip(yolo_preds.pred[img_num//2][:,5].tolist(),np.argmax(slowfaster_preds,axis=1).tolist(),torch.max(slowfaster_preds,axis=1).values.tolist()):
# if(avalabel in ava_labelnames_abnormal):
# id_to_ava_labels[tid]=ava_labelnames[avalabel+1]+'_abnormal'
id_to_ava_labels[tid]=[ava_labelnames[avalabel+1],avapred] # print(avalabel)
# print(avalabel)
# print(ava_labelnames[avalabel+1])
if((avalabel+1) in ava_labelnames_abnormal):
isnormal=False
else:
isnormal=True
save_yolopreds_tovideo(yolo_preds,id_to_ava_labels,coco_color_map,outputvideo,isnormal)
print("total cost: :.3fs, video clips length: s".format(time.time()-a,video.duration))
outputvideo.release()
print('saved video to:', vide_save_path)
3.将结果保存成视频
def save_yolopreds_tovideo(yolo_preds,id_to_ava_labels,color_map,output_video,isnormal):
for i, (im, pred) in enumerate(zip(yolo_preds.imgs, yolo_preds.pred)):
im=cv2.cvtColor(im,cv2.COLOR_BGR2RGB)
if pred.shape[0]:
for j, (*box, cls, trackid, vx, vy) in enumerate(pred):
if int(cls) != 0:
ava_label = ''
ava_pred=0.0
elif trackid in id_to_ava_labels.keys():
ava_label = id_to_ava_labels[trackid][0].split(' ')[0]
ava_pred=id_to_ava_labels[trackid][1]
else:
ava_label = 'Unknow'
ava_pred=0.0
if(isnormal):
text = ':.4f '.format(ava_pred,yolo_preds.names[int(cls)],ava_label)
color = [40,113,62]
else:
text = ':.4f '.format(ava_pred,yolo_preds.names[int(cls)],ava_label,'abnormal')
color = [43,44,124]
# print(cls)
im = plot_one_box(box,im,color,text)
output_video.write(im.astype(np.uint8))
总结
基于yolov5+deepsort+slowfast算法的视频实时行为检测就介绍到这里了!!!
如果该文章对您有所帮助,麻烦点赞,关注,收藏三连支持下!
创作不易,白嫖不好,各位的支持和认可,是我创作的最大动力!
如果本篇博客有任何错误,请批评指教,不胜感激 !!!
参考
Yolov5+SlowFast: 基于PytorchVideo的实时行为检测算法
YOLOv5算法详解
pytorch yolo5+Deepsort实现目标检测和跟踪
Yolov5+Deepsort+Slowfast实现实时动作检测
以上是关于yolov5+deepsort+slowfast复现的主要内容,如果未能解决你的问题,请参考以下文章