18.高级特性
Posted ColoFly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了18.高级特性相关的知识,希望对你有一定的参考价值。
一、不安全Rust
不安全Rust:涉及Rust的某些安全保障并负责手动维护相关规则。
不安全Rust之所以存在是因为静态分析从本质上讲是保守的。当编译器在判断一段代码是否拥有某种安全保障时,它总是宁可错杀一些合法的程序也不会接受可能非法的代码。另一个需要不安全Rust的原因在于底层计算机硬件固有的不安全属性。
1.1 不安全超能力
我们在代码前关键字unsafe切换到不安全模式,不安全Rust允许你执行4中在安全Rust中不被允许的操作:
解引用裸指针;
调用不安全的函数或方法;
访问或修改可变的静态变量;
实现不安全trait;
需要注意的是,unsafe关键字并不会关闭借用检查器或禁用任何其他Rust安全检查:如果你在不安全代码中使用引用,那么该引用依然会被检查。unsafe关键字仅仅让你可以访问这4种不会被编译器进行内存安全检查的特性。
另外,unsafe并不意味着块种的代码一定就是危险的或一定会导致内存安全问题,它仅仅是将责任转移到程序员手上,需要手动确定unsafe块种的代码会以合法的方式访问内存。
为了尽可能地隔离不安全代码,可以将不安全代码封装在一个安全的抽象种并提供一套安全的API。这种技术可以有效地防止unsafe代码泄漏到任何调用它的地方,因为使用安全抽象总会是安全的。
1.2 解引用裸指针
不安全Rust中有两种类似于引用的新指针类型,它们都叫裸指针(raw pointer)。与引用类似,裸指针要么是可变的,要么是不可变的,它们分别被写作*const T和*mut T。这里的型号是类型名的一部分而不是解引用操作,在裸指针的上下文中,不可变意味着我们不能直接对解引用后的指针赋值。
裸指针与引用、智能指针的区别在于:
允许忽略借用规则,可以同时拥有指向同一个内存地址的可变和不可变指针,或者拥有指向同一个地址的多个可变指针。
不能保证自己总是指向了有效的内存地址。
允许为空。
没有实现任何自动清理机制。
如下19-1演示了如何从一个引用中同时创建出不可变的和可变的裸指针。
//示例19-1
fn main()
let mut num = 5;
let r1 = &num as *const i32; //不可变裸指针
let r2 = &mut num as *mut i32; //可变裸指针
注意,我们没有在这段代码中使用unsafe关键字,但是可以在安全代码内合法创建裸指针,但不能在不安全代码块外解引用裸指针。
在创建裸指针的过程中,我们使用了as来分别将不可变引用和可变引用强制转换为对应的裸指针类型。由于这两个裸指针来自有效的引用,所以我们能够确认它们的有效性。但要记住,这一假设并不是对任意一个裸指针都成立。
示例19-2创建了一个指向内存中任意地址的裸指针。尝试使用任何内存地址的行为是未定义的:这个地址可能有数据,也可能没有数据,编译器可能会通过优化代码来去掉该次内存访问操作,否则程序可能会在运行时出现段错误。
//示例19-2
fn main()
let address = 0x012345usize;
let r = address as *const i32;
我们可以在安全代码中创建裸指针,但却不能通过解引用裸指针来读取其指向的数据。为了使用使用解引用裸指针,我们需要添加一个unsafe块,示例19-3
fn main()
let mut num = 5;
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
unsafe
println!("r1 is: ", *r1);
println!("r2 is: ", *r2);
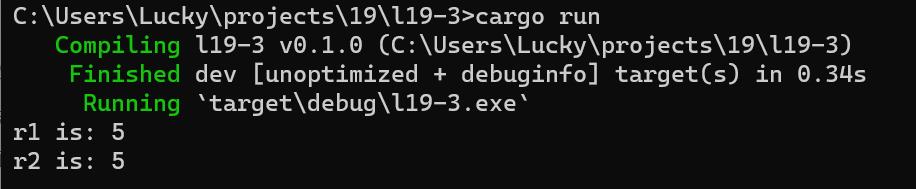
创建一个指针并不会产生任何危害,只有当我们试图访问它指向的值时才可能因为无效的值而导致程序异常。
值得注意的是:我们在示例19-1和示例19-2中同时创建除了指向同一个内存地址num的*const i32和*mut i32裸指针。如果我们尝试同时创建一个指向num的可变引用和不可变引用,那么就会因为Rust的所有权规则而导致编译失败。但在使用裸指针时,我们却可以同时创建指向同一地址的可变指针和不可变指针,并能够通过可变指针来修改数据。这一修改操作会导致潜在的数据竞争。
裸指针的一个主要用途便是与C代码结构进行交互。另外它还可以用来构造一些借用检查器无法理解的安全抽象。
1.3 调用不安全函数或方法
除了在定义前面要标注unsafe,此处的unsafe关键字意味着我们需要在调用该函数时手动满足并维护一些先决条件,因为Rust无法对这些条件进行验证。通过在unsafe代码块中调用不安全函数,我们向Rust表明自己确实理解并实现了相关的约定。
fn main()
unsafe fn dangerous()
unsafe
dangerous();
我们必须在单独的unsafe代码块中调用dangerous。如下我们在unsafe代码块外调用,则会出现报错:
fn main()
unsafe fn dangerous()
dangerous();
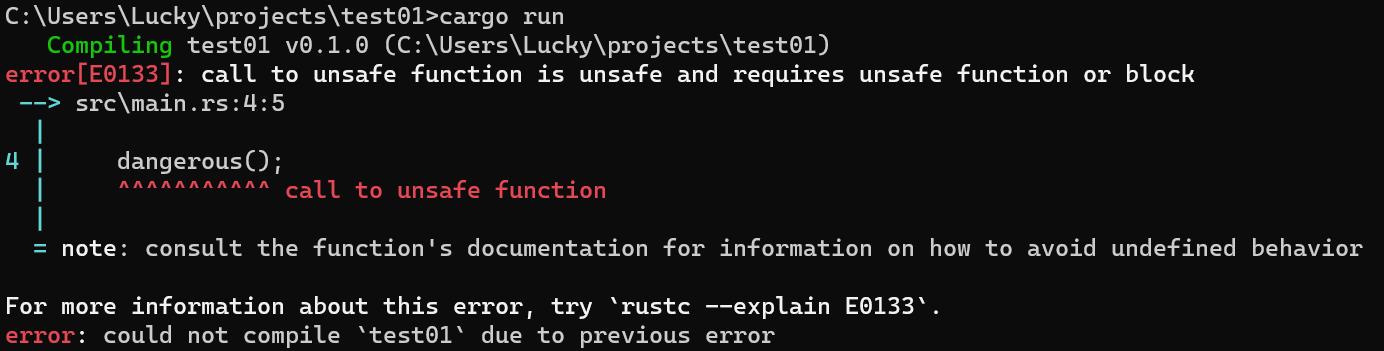
通过在调用dangerous的代码外插入unsafe代码块,我们想Rust表明自己已经阅读过函数的文档,能够理解正确使用它的方式并确认满足了它所要求的约定。
因为不安全函数的函数体也是unsafe代码块,所以你可以在一个不安全函数中执行其他不安全操作而无须添加额外的unsafe代码块。
1、创建不安全代码的安全抽象
函数中包含不安全代码并不意味着我们需要将整个函数都标记为不安全的。将不安全函数封装在安全函数中是一种常见的抽象。如下示例,我们将在标准库中使用不安全代码split_at_mut函数。这个安全方法被定义在可变切片上:它接受一个切片并从给定的索引参数出将其分隔为两个切片。
//示例19-4
fn main()
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
我们无法使用安全Rust函数来实现这个函数。如下示例19-5展示了一个可能的尝试,但它无法通过编译。为了简单,我们将split_at_mut实现为函数而不是方法,并只处理特定类型i32的切片而非泛类型T的切片。
//示例19-5
fn main()
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32])
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
fn main()
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
这个函数会首先取得整个切片的长度,并通过断言检查给定的参数是否小于或等于当前切片的而长度。如果给定的参数大于切片的长度,那么函数就会在尝试使用该索引前触发panic。
接着,我们会返回一个包含两个可变切片的元组:一个从原切片的起始位置到mid索引的位置,另一个则从mid索引的位置到原切片的末尾。
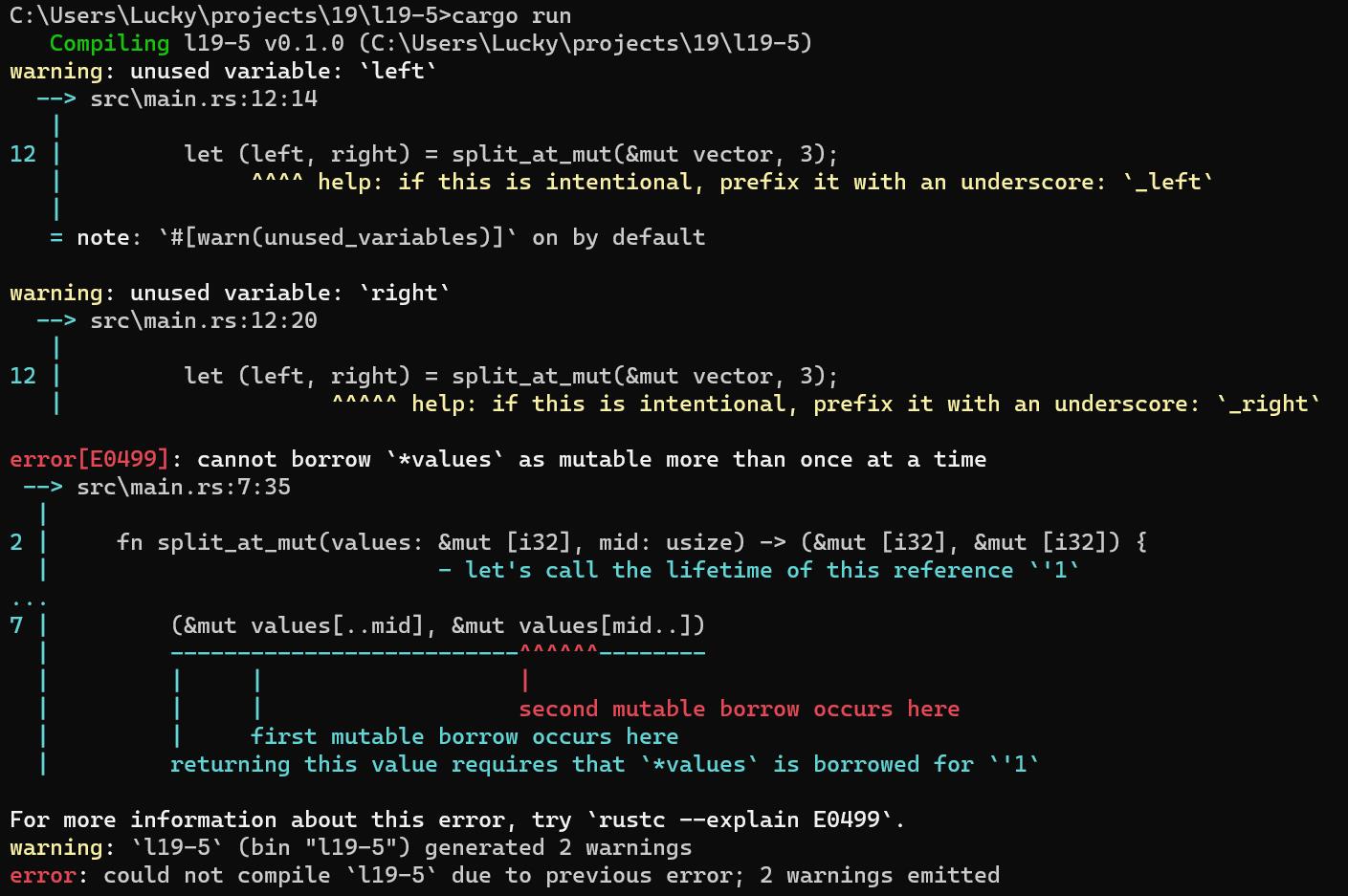
Rust的借用借用检查器无法理解我们正在借用一个切片的不同部分,它只知道我们借用了两次同一个切片。借用一个切片的不同部分从原理上没问题,因为两个切片没有交叉的地址,但Rust没有足够智能理解这些信息。当我们能够确定某段代码的正确性而Rust却不能时,不安全代码就可以使用了。
示例19-6展示了如何使用unsafe代码、裸指针及一些不安全函数来实现split_at_mut。
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32])
let len = values.len(); //1
let ptr = values.as_mut_ptr(); //2
assert!(mid <= len); //3
unsafe //4
(
slice::from_raw_parts_mut(ptr, mid), //5
slice::from_raw_parts_mut(ptr.add(mid), len - mid), //6
)
fn main()
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
我们使用len方法来得到切片的长度1,并使用as_mut_ptr方法来访问切片包含的裸指针2。在本例中,由于我们使用了可变的i32类型的切片,所以as_mut_ptr会返回一个类型为*mut i32的裸指针,这个指针被存储在变量ptr中。
随后的断言语句保证了mid索引一定会位于合法的切片长度内3。继续往下的部分就是不安全代码4:slice::from_raw_parts_mut函数接收一个裸指针和长度来创建一个切片。这里的代码使用该函数从ptr处创建了一个拥有mid哥元素的切片5,接着我们又在ptr上使用mid作为偏移量参数调用offset方法得到了一个从mid处开始的裸指针,并基于它创建了另外一个起始于mid处且拥有剩余所有元素的切片6。
由于函数slice::from_raw_parts_mut接收一个裸指针作为参数并承认该指针的合法性,所以它是不安全的。裸指针的add方法也是不安全的,因为它是必须承认此地址的偏移量也是一个有效的指针。
因此,我们必须在unsafe代码块中调用slice::from_raw_parts_mut和add函数。通过审查代码并添加mid必须小于等于len的断言,我们可以确认unsafe代码块中的裸指针都会指向有效的切片数据且不会产生任何的数据竞争。
因为代码没有将split_at_mut函数标记为unsafe,所以我们可以在安全Rust中调用该函数。我们创建了一个对不安全代码的安全抽象,并在实现时以安全的方式使用了unsafe代码,因为它仅仅创建了指向访问数据的有效指针。
与之相反,示例19-7中对slice::from_raw_parts_mut的调用则很可能导致崩溃。这个代码试图用一个随意的内存地址来创建拥有10000个元素的切片。
fn main()
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe slice::from_raw_parts_mut(r, 10000) ;
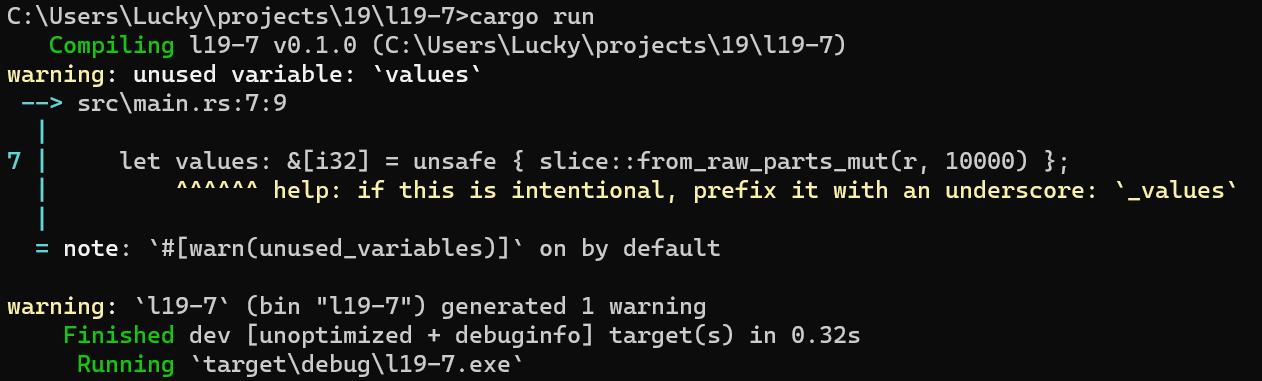
由于我们没有拥有这个随意地址的内存,所以无法保证这段代码的切片中包含有效的i32值,尝试使用该slice会导致不确定的行为。
2、使用extern函数调用外部代码
某些场景下,Rust代码可能需要与另一种语言进行交互,因此Rust提供了extern关键字来简化创建和使用外部函数接口(Foreign Function Interface,FFI)的过程。FFI是编程语言定义函数的一种方式,它允许其他编程语言来调用这个函数。
示例19-8集成了C标准库的abs函数。任何在extern块中声明的函数都是不安全的。因为其他语言并不会强制执行Rust遵守的规则,而Rust又无法对它们进行检查,所以在调用外部函数的过程中,保证安全的责任也同样落在开发者的肩上。
//示例19-8:声明并调用在另外一种语言中定义的extern函数
extern "C"
fn abs(input: i32) -> i32;
fn main()
unsafe
println!("Absolute value of -3 according to C: ", abs(-3));
这段代码在extern "C"块中列出了我们想要调用的外部函数名称及签名,其中"C"指明了外部函数使用的应用二进制接口(Application Binary Interface,ABI):它被用来定义函数在汇编层面的调用方式。
1.4 访问或修改一个可变静态变量
Rust支持全局变量,但在使用它们的过程中可能会因为Rust的所有权机制而产生某些问题。如果两个线程同时访问一个可变的全局变量,那么就会造成数据竞争。
在Rust中,全局变量也称为静态变量。示例19-9声明并使用了一个静态变量,它的值是一个字符串切片。
static HELLO_WORLD: &str = "Hello, world";
fn main()
println!("name is : ", HELLO_WORLD);

通常静态变量的名称采用SCREAMING_SNAKE_CASE格式。静态变量智能存储拥有\'static生命周期的引用,这意味着Rust编译器可以自己计算出它的生命周期而无需手动标准,访问一个不可变静态变量是安全的。
常量和不可变静态变量看起来是相似的,但它们之间存在一个微妙的区别:静态变量的值在内存中拥有固定的地址,使用它的值总是会访问到同样的变量。与之相反的是,常量则允许在任何被使用到的时候复制其数据。
常量和静态变量之间的另外一个区别在于静态变量是可变的。需要注意的是,访问和修改可变的静态变量是不安全的。示例19-10展示了如何生命、访问和修该一个名为COUNTER的可变静态变量。
//示例19-10:从一个可变静态变量中读或写都是不安全的
static mut COUNTER: u32 = 0;
fn add_to_count(inc: u32)
unsafe
COUNTER += inc;
fn main()
add_to_count(3);
unsafe
println!("COUNTER: ", COUNTER);

和正常变量一样,我们使用mut关键字来指定静态变量的可变性。任何读写COUNTER的代码都必须位于unsafe代码块中。上述代码结果如上,因为它是单线程的。如果是多线程的则可能会出现数据竞争。
在拥有可全局访问的可变数据时,我们很难保证没有数据竞争发生,这也是Rust会将可变静态变量当作不安全的原因,我们应当尽可能使用之前学习的并发技术或线程安全的智能指针,从而使编译器能够对线程中的数据访问进行安全检查。
1.5 实现不安全trarit
最后一个只能在unsafe中执行的操作是实现某个不安全trait。当某个trait中存在至少一个方法拥有编译器无法校验的不安全因素时,我们就生成这个trait是不安全的。可以在trait定义的前面加上unsafe关键字来生命一个不安全trait,同时该trait也只能在unsafe代码块中实现,如下示例19-11
unsafe trait Foo
// 某些方法
unsafe impl Foo for i32
// 对应的方法实现
fn main()
通过使用unsafe impl,我们向Rust保证我们会手动维护好那些编译器无法验证的不安全因素。Rust无法验证我们的类型是否能够安全地跨线程传递,或安全地从多个线程中访问。因此,我们需要手动执行这些审查并使用unsafe关键字来实现这些trait。
二、高级trait
2.1 在trait的定义中关联类型指定占位类型
关联类型是trait中的类型占位符,它可以被用于trait的方法签名中。trait的实现者需要根据特定的场景来为关联类型指定具体的类型。通过这一技术,我们可以定义出包含某些类型的trait,而无须再实现前确定它们的具体类型是什么。
标准库中的Iterator就是一个带有关联类型的trait示例,它拥有一个名为Item的关联类型,并使用该类型来替代迭代中出现的值类型。Iterator trait的定义如示例19-12:
//示例19-12:含有关联类型Item的Iterator trait的定义
pub trait Iterator
type Item;
fn next(&mut self) -> Option<Self::Item>;
Item是一个占位符,而next方法的定义则表明它会返回类型为Option<Self::Item>的值。Iterator trait的实现者需要为Item指定具体的类型,并在实现的next方法中返回一个包含该类型的Option。
关联类型看起来像一个类似泛型的概念,因为它允许顶一个函数而不指定其可以处理的类型。让我们通过在一个 Counter 结构体上实现 Iterator trait 的例子来检视其中的区别。这个实现中指定了 Item 的类型为 u32:
impl Iterator for Counter
type Item = u32;
fn next(&mut self) -> Option<Self::Item>
// --省略--
这个越发类似于泛型
//示例19-13:一个使用泛型的假想Iterator trait定义
pub trait Iterator<T>
fn next(&mut self) -> Option<T>;
其区别在于,如果我们使用了示例19-13的泛型版本,那么就需要再每次实现该trait的过程中标注类型;因为我们既可以实现Iterator<String> for Counter,也可以实现其他任意的迭代类型,从而使得Counter可以拥有多个不同版本的Iterator实现。换句话说,当trait拥有泛型参数时,我们可以为一个类型同时多次实现trait,并在每次实现中改变具体的泛型参数。当我们在Counter上使用next方法时,也必须提供类型标准来指明想要使用的Iterator实现。
借助关联类型,我们不需要再使用该trait的方法时标注类型,因为我们不能为单个类型多次实现这样的trait。对于示例19-12中使用了关联类型的trait定义,由于我们只能实现一次impl Iterator for Counter,所以Counter就只能拥有一个特定的Item类型。我们不需要在每次调用Counter的next方法时来显示地生命这是一个u32类型的迭代器。
2.2 默认泛型参数和运算符重载
当使用泛型类型参数时,可以为泛型指定一个默认的具体类型。当使用的默认类型就能工作时,该trait的实现者可以不用再指定另外的具体类型。可以在定义泛型时通过语法<PlaceholderType=ConcreteType>来为泛型指定默认类型。
这个技术常常被应用在运算符重载中。运算符重载是我们可以在某些特定的情形下自定义运算符的具体行为。虽然Rust并不允许创建自定义运算符及重载任意运算符,不过 std::ops 中所列出的运算符和相应的 trait 可以通过实现运算符相关 trait 来重载。
//示例19-14:实现Add trait重载Point实例的+运算符
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point
x: i32,
y: i32,
impl Add for Point
type Output = Point;
fn add(self, other: Point) -> Point
Point
x: self.x + other.x,
y: self.y + other.y,
fn main()
assert_eq!(
Point x: 1, y: 0 + Point x: 2, y: 3 ,
Point x: 3, y: 3
);
Add方法将两个Point实例的x值和y值分别相加来创建一个新的Point。Add trait有一个叫做Output的关联类型,它用来决定Add方法的返回值类型。
这里的Add trait使用了默认泛型参数,它的定义如下:
#![allow(unused)]
fn main()
trait Add<Rhs=Self>
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
它定义的trait中带有一个方法和一个关联类型。比较陌生的部分是尖括号中的Rhs=Self:这个语法叫做默认类型参数。Rhs是一个泛型类型参数,它用于定义add方法中的rhs参数。如果实现Add trait时不指定Rhs的具体类型,Rhs的类型将是默认的Self类型,也就是在其上实现Add的类型。
当为 Point 实现 Add 时,使用了默认的 Rhs,因为我们希望将两个 Point 实例相加。让我们看看一个实现 Add trait 时希望自定义 Rhs 类型而不是使用默认类型的例子。
这里有两个存放不同单元值的结构体,Millimeters 和 Meters。我们希望能够将毫米值与米值相加,并让 Add 的实现正确处理转换。可以为 Millimeters 实现 Add ,并将 Meters 作为 Rhs,如示例 19-15 所示。
//示例19-15:为Millimeters实现Add trait,从而使Millimeters和Meters可以相加
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters
Millimeters(self.0 + (other.0 * 1000))
为了使 Millimeters 和 Meters 能够相加,我们指定 impl Add<Meters> 来设定 Rhs 类型参数的值而不是使用默认的 Self。
默认参数类型主要用于如下两个方面:
扩展类型而不破坏现有代码;
在大部分用户都不需要的特定情况下进行自定义;
2.3 用于消除歧义的完全限定语法:调用相同名称的方法
Rust既不会组织两个trait拥有相同名称的方法,也不会组织你为同一个类型实现这样的两个trait。但当你调用这些同名方法时,你需要明确告诉Rust你期望调用的具体对象。示例19-16,它定义了两个拥有同名方法fly的trait:Pilot和Wizard,并未类型Human实现了这两个trait,而Human本身也正好实现了fly方法。每个fly方法都执行了不同的操作 。
//示例19-16:定义两个拥有同名方法fly的trait,并未本就拥有fly方法的Human类型实现了两个trait。
trait Pilot
fn fly(&self);
trait Wizard
fn fly(&self);
struct Human;
impl Pilot for Human
fn fly(&self)
println!("This is your captain speaking.");
impl Wizard for Human
fn fly(&self)
println!("Up!");
impl Human
fn fly(&self)
println!("*waving arms furiously*");
fn main()
当我们在Human的实例上调用fly时,编译器会默认调用直接实现在类型上的方法,如示例19-17。
//示例19-17:在Human示例上调用fly
trait Pilot
fn fly(&self);
trait Wizard
fn fly(&self);
struct Human;
impl Pilot for Human
fn fly(&self)
println!("This is your captain speaking.");
impl Wizard for Human
fn fly(&self)
println!("Up!");
impl Human
fn fly(&self)
println!("*waving arms furiously*");
fn main()
let person = Human;
person.fly();
我们会出现显示如下,这表明Rust调用了在Human上的fly方法实现。

为了调用实现Pilot trait或Wizard trait中的fly方法,我们需要使用更加显式的语法来指定具体的fly方法,如下所示:
//示例19-18:指定我们想要调用那个trait的fly方法
trait Pilot
fn fly(&self);
trait Wizard
fn fly(&self);
struct Human;
impl Pilot for Human
fn fly(&self)
println!("This is your captain speaking.");
impl Wizard for Human
fn fly(&self)
println!("Up!");
impl Human
fn fly(&self)
println!("*waving arms furiously*");
fn main()
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
在方法名的前面指定trait名称向Rust清晰地表明了我们想要调用哪个fly实现。
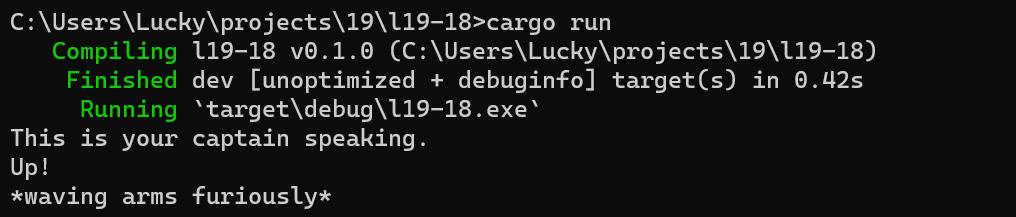
当你拥有两种实现了同一trait的类型时,对于fly等需要接收self作为参数的方法,Rust可以自动地根据self的类型推导出具体的trait实现。
然而,因为trait中的关联函数没有self参数,所以当在同一作用域下有两个实现了此种trait的类型时,Rust无法推导出你究竟想要调用哪一个具体类型,除非使用完全限定语法。示例19-19中的Animal trait拥有关联函数baby_name,而示例中定义的Dog结构体在拥有独立关联函数baby_name
的同时实现了Animal trait。
//示例19-19:一个带关联函数的trait和一个带同名关联函数的类型,并在这个类型实现了trait
trait Animal
fn baby_name() -> String;
struct Dog;
impl Dog
fn baby_name() -> String
String::from("Spot")
impl Animal for Dog
fn baby_name() -> String
String::from("puppy")
fn main()
println!("A baby dog is called a ", Dog::baby_name());
使用这段代码的动物收容所希望将所有的小狗都叫作Spot,他们在Dog的关联函数baby_name中实现了这一需求。另外,Dog类型还同时实现了用于描述动物的通用Animal trait。Dog在实现该trait的baby_name函数时将小狗称为puppy。
随后的代码在main函数中使用语句Dog::baby_name()来直接调用了Dog的关联函数,如下所示:

这与我们预期的结果有些出入,我们希望的是调用在Dog上实现的Animal trait的baby_name函数来打印出A baby dog is called a puppy。示例19-18中指定trait名称的技术无法解决这一需求,将main函数修改为示例19-20中的代码会导致编译时错误。
//示例19-20:尝试调用Animal trait中的baby_name函数,但Rust并不知道应该使用哪一个实现
trait Animal
fn baby_name() -> String;
struct Dog;
impl Dog
fn baby_name() -> String
String::from("Spot")
impl Animal for Dog
fn baby_name() -> String
String::from("puppy")
fn main()
println!("A baby dog is called a ", Animal::baby_name());
由于Animal::baby_name是一个没有self参数的关联函数而不是方法,所以Rust无法推断出我们想要调用哪一个Animal::baby_name的实现。尝试编译这段代码会出现如下所示的错误:
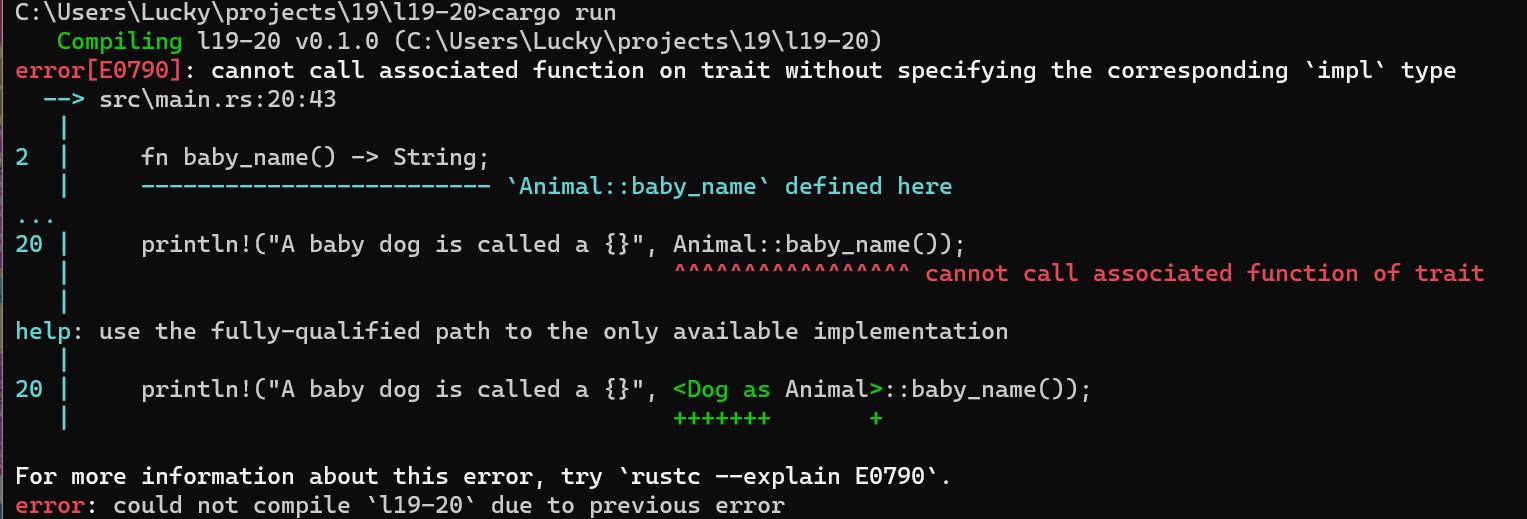
为了消除歧义并指示Rust使用Dog为Animal trait实现的baby_name函数,我们需要使用完全限定语法。如下所示19-21
//示例19-21:使用完全限定语法来调用Dog为Animal trait实现的baby_name函数
trait Animal
fn baby_name() -> String;
struct Dog;
impl Dog
fn baby_name() -> String
String::from("Spot")
impl Animal for Dog
fn baby_name() -> String
String::from("puppy")
fn main()
println!("A baby dog is called a ", <Dog as Animal>::baby_name());
这段代码在尖括号中提供的类型标注表明我们希望将Dog类型视作Animal,并调用Dog为Animal trait实现的baby_name函数。结果如下:
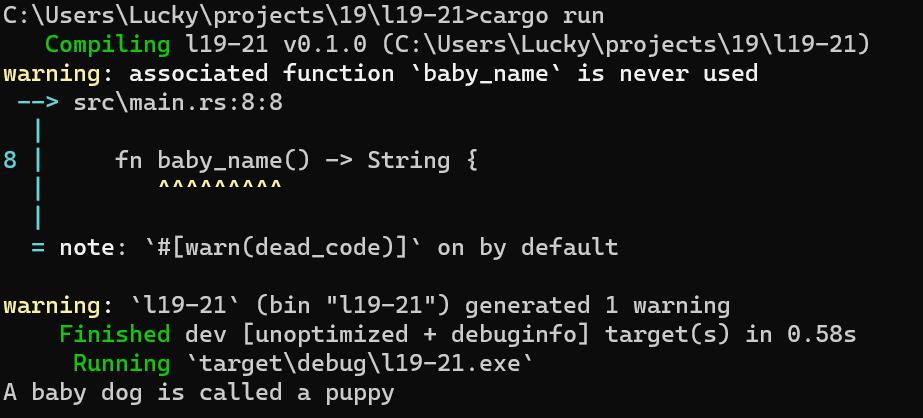
一般来说,完全限定语法被定义为如下所示的形式:
<Type as Trait>::function(receiver_if_method, next_arg, ...);
对于关联函数而言,上面的形式会缺少receiver而只保留剩下的参数列表。你可以在任何调用函数或方法的地方使用完全限定语法,而Rust允许你忽略那些能够从其他上下文信息中推导出来的部分。只有当代码存在多个同名实现,且Rust也无法区分出你期望调用哪个具体实现时,你才需要使用这种较为繁琐的显式语句。
2.4 用于在trait中附带另外一个trait功能的超trait
但我们需要在一个trait中使用另一个trait的功能。在这种情况下,我们需要使当前trait的功能依赖于另外一个同时被实现的trait,这个被以来的trait也就是当前trait的supertrait。
//示例19-22:实现使用了Display功能的OutlinePrint trait
use std::fmt;
trait OutlinePrint: fmt::Display
fn outline_print(&self)
let output = self.to_string();
let len = output.len();
println!("", "*".repeat(len + 4));
println!("**", " ".repeat(len + 2));
println!("* *", output);
println!("**", " ".repeat(len + 2));
println!("", "*".repeat(len + 4));
fn main()
由于这段代码定义注明了OutlinePrint依赖Display trait,所以我们能够在随后的方法中使用to_string函数,任何实现了Display trait的类型都会自动拥有这一函数。如果你尝试去掉trait名后的冒号与Display trait并继续使用to_string,那么Rust就会因为无法在当前作用域内找到&self的to_string方法而抛出错误。
use std::fmt;
trait OutlinePrint: fmt::Display
fn outline_print(&self)
let output = self.to_string();
let len = output.len();
println!("", "*".repeat(len + 4));
println!("**", " ".repeat(len + 2));
println!("* *", output);
println!("**", " ".repeat(len + 2));
println!("", "*".repeat(len + 4));
struct Point
x: i32,
y: i32,
impl OutlinePrint for Point
fn main()
let p = Point x: 1, y: 3 ;
p.outline_print();
编译后出现的错误提示信息指出了Point类型没有实现必要的Display trait约束:
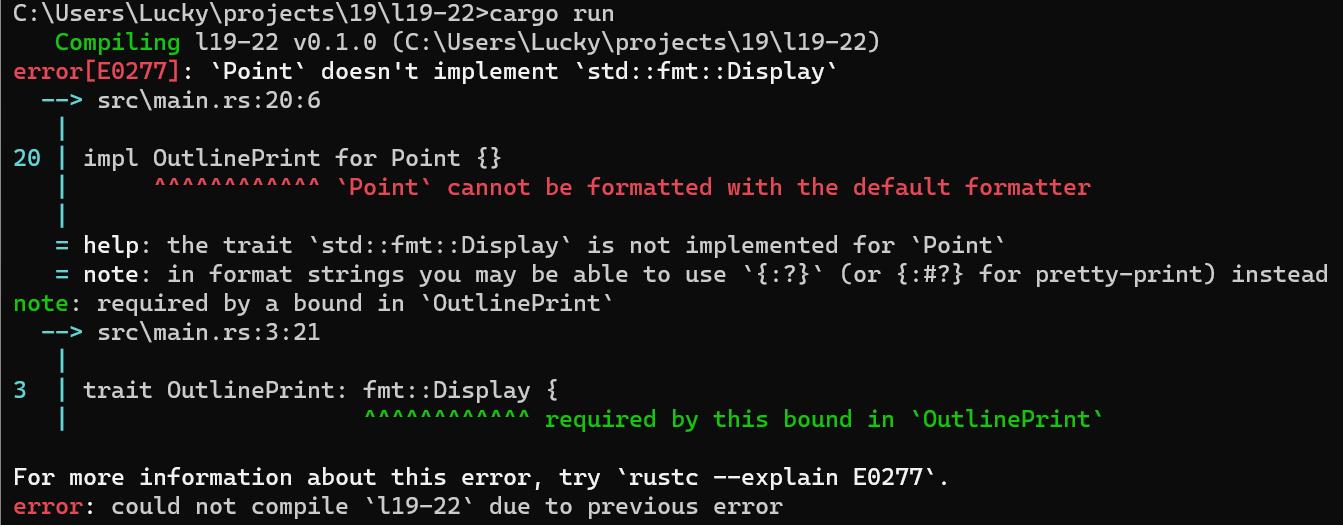
为了解决这一问题,让我们为Point类型实现Display来满足OutlinePoint要求的约束,如下所示:
trait OutlinePrint: fmt::Display
fn outline_print(&self)
let output = self.to_string();
let len = output.len();
println!("", "*".repeat(len + 4));
println!("**", " ".repeat(len + 2));
println!("* *", output);
println!("**", " ".repeat(len + 2));
println!("", "*".repeat(len + 4));
struct Point
x: i32,
y: i32,
impl OutlinePrint for Point
use std::fmt;
impl fmt::Display for Point
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result
write!(f, "(, )", self.x, self.y)
fn main()
let p = Point x: 1, y: 3 ;
p.outline_print();
那么在Point上实现OutlinePrint trait将能成功编译,并可以在Point实例上调用outline_print来显示位于星号框中的点值。
![[Pasted image 20230520200427.png]]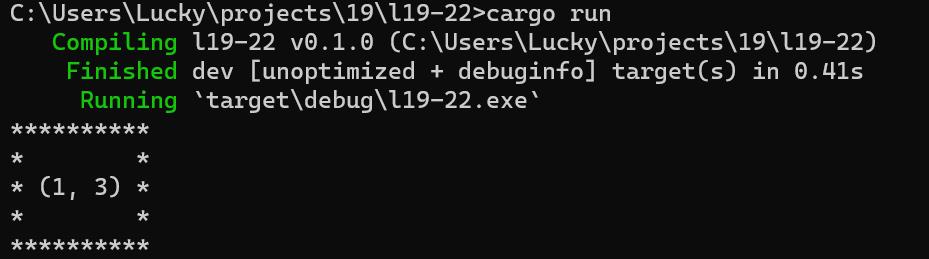
2.5 使用newtype模式在外部类型上实现外部trait
“为类型实现trait”提高过孤儿规则:只有当类型和对应trait中的任意一个定义在本地包内时,我们才能够为该类型实现这一trait。但实际上,我们可以通过newtype模式巧妙绕过这一规则。这个元组结构体只有一个字段,是我们想要实现trait的类型的瘦封装(thin wrapper)。由于封装后的类型位于本地包内,所以我们可以为这个类型实现对应的trait。
newtype是一个来自Haskell编程语言的术语,使用这一模式不会导致任何额外的运行时开销,封装后的类型会在编译过程中被优化掉。
例如,孤儿规则会组织我们直接为Vec<T>实现Display,因为Display trait与Vec<T>类型都被定义为在外部包中。为了解决这一问题,我们可以首先创建一个持有Vec<T>实例的Wrapper结构体,接着,我们便可以为Wrapper实现Display并使用Vec<T>值了。
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result
write!(f, "[]", self.0.join(", "))
fn main()
let w = Wrapper(vec![String::from("hello"),
String::from("world")]);
println!("w = ", w);
这段代码在实现Display的过程中使用了self.0来访问内部的Vec<T>,因为Wrapper是一个元组结构体,而Vec<T>是袁祖中序号为0的元素。接着,我们就可以使用Wrapper中的Display功能了。
因为Wrapper是一个新的类型,所以它没有自己内部值的方法。为了让Wrapper的行为与Vec<T>完全一致,我们需要在Wrapper中实现所有Vec<T>的方法,并将这些方法委托给self.0。
三、高级类型
3.1 使用newtype模式实现类型安全与抽象
newtype模式在一些我们还没有介绍过的任务中同样有用,它可以被用来静态地保证各种值之间不会被混淆及表明使用的单位。
newtype模式的另外一个用途是为类型的某些细节提供抽象能力。
newtype模式还可以被用来隐藏内部实现。
3.2 使用类型别名创建同义类型
除了newtype模式,Rust还提供了创建类型别名的功能,它可以为现有的类型生成另外的名称,这一特性需要用到type关键字。例如我们可以像下面一样创建i32的别名Kilometers:
type Kilometers = i32;
现在,别名Kilometers被视作i32的同义词;Kilometers累哦行的值实际上等价于i32类型的值:
fn main()
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = ", x + y);

也正是由于Kilometers和i32是同一类型,所以我们可以把两个类型的值相关加,甚至是将Kilometers类型的值传递给i32类型作为参数的函数。
类型别名的最主要用途是时间少代码字符重复,使得代码更加易于管理。
3.3 永不返回的Never类型
Rust有一个名为!的特殊类型,它在类型系统中的属于为空类型,因为它没有任何值,它也成为never类型,因为它在从不返回的函数中充当返回值的类型:
fn bar() -> !
panic!();
这段代码可以读作“函数bar永远不会返回值”。不会返回值的函数也称为发散函数。
3.4 动态大小类型和Sized trait
通常而言,Rust需要在编译时获得一些特定的信息来完成自己的工作,比如应该为一个特定类型的值分类多少空间等。但Rust的类型系统中又同时存在:动态大小类型(Dynamically Sized Type,DST)。这种类型使我们可以在编写代码时使用只有在运行时才能确定大小的值。
四、高级函数与闭包
4.1 函数指针
函数指针实现将普通函数传递给其他函数。函数会在传递传递的过程中被强制转换为fn类型,注意这里使用了小写字符f从而避免与Fn闭包trait混淆。fn类型也称为函数指针,将参数声明为函数指针时使用的语法与闭包类似。
//示例19-27:使用fn类型来接收函数指针作为参数
fn add_one(x: i32) -> i32
x + 1
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32
f(arg) + f(arg)
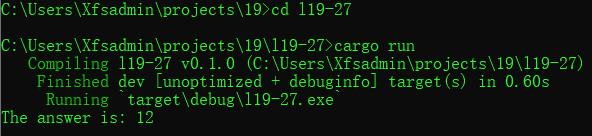
fn main()
let answer = do_twice(add_one, 5);
println!("The answer is: ", answer);
运行结果如下,其中函数to_twice的参数f被定义为了fn类型,它会接收i32类型作为参数,并返回一个i32作为结果。随后do_twice函数体中的代码调用了两次f。在main函数中,我们将函数add_one作为第一个参数传递给do_twice。
与闭包不同,fn是一个类型而不是一个trait。因此,我们可以直接指定fn为参数类型,而不用声明一个以Fn trait为约束的泛型参数。
由于函数指针实现了全部3种闭包trait(Fn、FnMut以及FnOnce),所以我们可以把函数指针用作参数传递给一个接受闭包的函数。这是因为这样,我们倾向使用搭配闭包trait的泛型来编写函数,这样的函数可以同时处理闭包与普通函数。
在某些情况下,我们可能只想接收fn而不想接收闭包,比如与某种不支持闭包的外部代码及逆行交互时:C函数可以接收函数作为参数,但它没有闭包。
4.2 返回闭包
由于闭包使用了trait来进行表达,所以你无法在函数中直接返回一个闭包。
五、宏
术语宏(macro)其实是Rust中的某一组相关功能的集合,其中包括macro_rules!的声明宏,和三种过程宏:
用于结构体或美剧的自定义#[derive]宏,它可以指定随derive属性自动添加的代码;
用于为任意条目添加自定义属性的属性宏;
类似于函数的函数宏,它可以接收并处理一段标记序列;
5.1 宏与函数之间的差别
从根本上讲,宏是一种用于编写其他代码的代码编写方式,也称为“元编程”。元编程可以极大程度地减少你需要编写和维护的代码数量,这也是函数的功能之一。但宏有一些函数不具备的能力。
函数在定义签名时必须声明自己参数的个数与类型,而宏则能够处理可变数量的参数。由于编译器会在解释代码前展开宏,所以宏可以被用来执行某些较为特殊的任务,比如为类型实现trairt等。之所以函数无法做到这一点,是因为trait需要在编译时实现,而函数则是在运行时调用执行。
宏的缺点在于:宏的定义要比函数定义复杂很多,因此你需要编写的是用于生成Rust代码的Rust代码。正是由于这种间接性,宏定义通常要比函数定义更加难以阅读、理解及维护。
宏和函数间的最后一个重要区别在于:当你在某个文件中调用宏时,你必须提前定义宏或将宏引入当前作用域中,而函数则可以在任意位置定义并在任意位置使用。
5.2 用于通用元编程的声明宏
Rust中最常见的宏形式是声明宏,也被称为“模板宏”。从核心形式上讲,声明宏要求你编写出类似于match表达式的内容。
为了定义一个宏,我们需要用到macro_rules!。
#[macro_export]
macro_rules! vec
( $( $x:expr ),* ) =>
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
;
5.3 用于从属性生成代码的过程宏
过程宏会接收并操作输入的Rust代码,并生成另外一些Rust代码作为结果,这与声明宏根据模式匹配来替换代码的行为有所不同。
当创建过程宏时,宏的定义必须单独放在它自己的包中,并使用特殊的包类型。使用过程宏的如下示例19-29,其中some_attribute是一个用来指定过程宏类型的占位符。
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream
这个定义了过程宏的函数接收一个TokenStream作为输入,并生成一个TokenStream作为输出。TokenStream类型在proc_macro包中定义,表示一段标记序列。这也是过程宏的核心所在:需要被宏处理的源代码组成了输入的TokenStream,而宏生成的代码则组成了输出的TokenStream。函数附带的属性决定了我们究竟创建的是哪一种过程宏。同一个包中可以拥有多种不同类型的过程宏。
5.4 属性宏
属性宏与自定义派生宏类似,它们允许你创建新的属性,而不是为derive属性生成代码。属性宏在某种程度上也更加灵活:derive只能用于结构体和美剧,而属性则可以同时北用于其他条目。
5.5 函数宏
函数宏可以定义出类似于函数调用的宏,但它们远比普通函数更加灵活。但是,macro_rules! 宏只能使用类似于match的语法来进行定义,而函数宏则可以接收一个TokenStream作为参数,并与另外两种过程宏一样在定义中使用Rust代码来操作TokenStream。
23.Flink-高级特性-新特性-Streaming Flie Sink介绍代码演示Flink-高级特性-新特性-FlinkSQL整合Hive添加依赖和jar包和配置
23.Flink-高级特性-新特性-Streaming Flie Sink
23.1.介绍
23.2.代码演示
24.Flink-高级特性-新特性-FlinkSQL整合Hive
24.1.介绍
24.2.版本
24.3.添加依赖和jar包和配置
24.4.FlinkSQL整合Hive-CLI命令行整合
24.5.FlinkSQL整合Hive-代码整合
23.Flink-高级特性-新特性-Streaming Flie Sink
23.1.介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/streamfile_sink.html
https://blog.csdn.net/u013220482/article/details/100901471
23.2.代码演示
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* 演示Flink StreamingFileSink将流式数据写入到HDFS 数据一致性由Checkpoint + 两阶段提交保证
*
* @author tuzuoquan
* @date 2022/6/21 20:05
*/
public class StreamingFileSinkDemo
public static void main(String[] args) throws Exception
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//开启Checkpoint
//===========类型1:必须参数=============
//设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier!
env.enableCheckpointing(1000);
if (SystemUtils.IS_OS_WINDOWS)
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
else
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));
//===========类型2:建议参数===========
//设置两个Checkpoint 之间最少等待时间,如设置Checkpoint之间最少是要等 500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)
//如:高速公路上,每隔1s关口放行一辆车,但是规定了两车之前的最小车距为500m
//默认是0
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//设置如果在做Checkpoint过程中出现错误,是否让整体任务失败:true是 false不是
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);//默认是true
//默认值为0,表示不容忍任何检查点失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);
//设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//===================类型3:直接使用默认即可===============================
//设置checkpoint的执行模式为EXACTLY_ONCE(默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时时间,如果 Checkpoint在 60s内尚未完成说明该次Checkpoint失败,则丢弃。
//默认10分钟
env.getCheckpointConfig().setCheckpointTimeout(60000);
//设置同一时间有多少个checkpoint可以同时执行
//默认为1
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
//注意:下面的操作将上面的2步合成了1步,直接切割单词并记为1返回
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>()
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
String[] arr = value.split(" ");
for (String word : arr)
out.collect(Tuple2.of(word, 1));
);
SingleOutputStreamOperator<String> result = wordAndOne.keyBy(t -> t.f0).sum(1)
.map(new MapFunction<Tuple2<String, Integer>, String>()
@Override
public String map(Tuple2<String, Integer> value) throws Exception
return value.f0 + ":" + value.f1;
);
//TODO 3.sink
result.print();
//使用StreamingFileSink将数据sink到HDFS
OutputFileConfig config = OutputFileConfig
.builder()
//设置文件前缀
.withPartPrefix("prefix")
//设置文件后缀
.withPartSuffix(".txt")
.build();
StreamingFileSink<String> streamingFileSink = StreamingFileSink.
forRowFormat(new Path("hdfs://node1:8020/FlinkStreamFileSink/parquet"), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
//每隔15分钟生成一个新文件
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
//每隔5分钟没有新数据到来,也把之前的生成一个新文件
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.withOutputFileConfig(config)
.build();
result.addSink(streamingFileSink);
//TODO 4.execute
env.execute();
24.Flink-高级特性-新特性-FlinkSQL整合Hive
24.1.介绍

24.2.版本
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/

24.3.添加依赖和jar包和配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<artifactId>hadoop-hdfs</artifactId>
<groupId>org.apache.hadoop</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
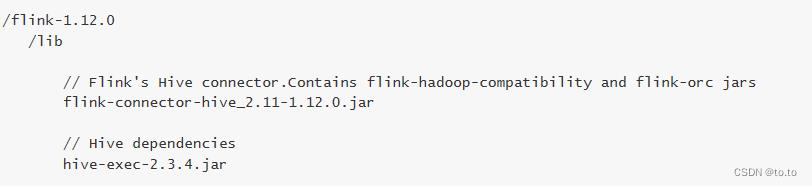
上传资料hive中的jar包到flink/lib中

24.4.FlinkSQL整合Hive-CLI命令行整合
1.修改hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node3:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node3</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
</configuration>
2.启动元数据服务
nohup /export/server/hive/bin/hive --service metastore &
3.修改flink/conf/sql-client-defaults.yaml
catalogs:
- name: myhive
type: hive
hive-conf-dir: /export/server/hive/conf
default-database: default
4.分发
5.启动flink集群
/export/server/flink/bin/start-cluster.sh
6.启动flink-sql客户端-hive在哪就在哪启动
/export/server/flink/bin/sql-client.sh embedded
7.执行sql:
show catalogs;
use catalog myhive;
show tables;
select * from person;
24.5.FlinkSQL整合Hive-代码整合
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.catalog.hive.HiveCatalog;
/**
* @author tuzuoquan
* @date 2022/6/21 23:15
*/
public class HiveDemo
public static void main(String[] args)
//TODO 0.env
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//TODO 指定hive的配置
String name = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "./conf";
//TODO 根据配置创建hiveCatalog
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
//注册catalog
tableEnv.registerCatalog("myhive", hive);
//使用注册的catalog
tableEnv.useCatalog("myhive");
//向Hive表中写入数据
String insertSQL = "insert into person select * from person";
TableResult result = tableEnv.executeSql(insertSQL);
System.out.println(result.getJobClient().get().getJobStatus());
以上是关于18.高级特性的主要内容,如果未能解决你的问题,请参考以下文章