Go学习圣经:队列削峰+批量写入 超高并发原理和实操
Posted 疯狂创客圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go学习圣经:队列削峰+批量写入 超高并发原理和实操相关的知识,希望对你有一定的参考价值。
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
GO 学习圣经:底层原理和实操
说在前面:
本文是《Go学习圣经》 的第二部分。
第一部分请参见:Go学习圣经:0基础精通GO开发与高并发架构(1)
现在拿到offer超级难,甚至连面试电话,一个都搞不到。
尼恩的技术社群中(50+),很多小伙伴凭借 “左手云原生+右手大数据”的绝活,拿到了offer,并且是非常优质的offer,据说年终奖都足足18个月。
从Java高薪岗位和就业岗位来看,云原生、K8S、GO 现在对于 高级工程师/架构师来说,越来越重要。尼恩从架构师视角出发,基于自己的尼恩 3高架构师知识体系和知识宇宙,写一本《GO学习圣经》

最终的学习目标
咱们的目标,不仅仅在于 GO 应用编程自由,更在于 GO 架构自由。
前段时间,一个2年小伙伴希望涨薪到18K, 尼恩把GO 语言的项目架构,给他写入了简历,导致他的简历金光闪闪,脱胎换股,完全可以去拿头条、腾讯等30K的offer, 年薪可以直接多 20W。
足以说明,GO 架构的含金量。
另外,前面尼恩的云原生是没有涉及GO的,但是,没有GO的云原生是不完整的。
所以, GO语言、GO架构学习完了之后,咱们在去打个回马枪,完成云原生的第二部分: 《Istio + K8S CRD的架构与开发实操》 , 帮助大家彻底穿透云原生。

本书目录
并发编程
Go 将并发结构作为核心语言的一部分提供。
Go 协程
Go 协程(Goroutine)是 Go 语言中的一种轻量级线程实现。
Go 协程(Goroutine)通过在单个线程内同时运行多个函数来实现并发,从而避免了线程切换的开销,并且能够更加高效地利用系统资源。
与传统的线程模型不同,Go 协程不是由操作系统内核调度的,而是由 Go 运行时(runtime)自己调度的。
为啥是轻量级线程呢?Go 协程(Goroutine)可以避免因为线程调度引起的额外开销,并且能够更好地控制协程的数量和调度机制。
创建一个协程非常简单,只需要在函数调用前面添加 go 关键字即可,例如:
func main()
go func()
fmt.Println("Hello, world!")
()
这段代码会创建一个新的协程,并在其中执行匿名函数中的代码。
这个协程会在后台运行,不会阻塞主线程的执行。
创建Go 协程(Goroutine)
Go 程(goroutine)是由 Go 运行时管理的轻量级线程。
创建一个协程非常简单,只需要在函数调用前面添加 go 关键字即可
go f(x, y, z)
上面的代码,会启动一个新的 Go 协程(Goroutine)去执行 f(x, y, z) 函数, x, y 和 z 的求值发生在当前的 Go协 程中,而 f 的执行发生在新的 Go 协程中。
下面是一个例子
package cocurrent
import (
"fmt"
"time"
)
func say(s string)
for i := 0; i < 5; i++
time.Sleep(100 * time.Millisecond)
fmt.Printf("字符 %s: %d \\n", s, i)
func GoroutineDemo()
go say("sync world ")
say("hello")
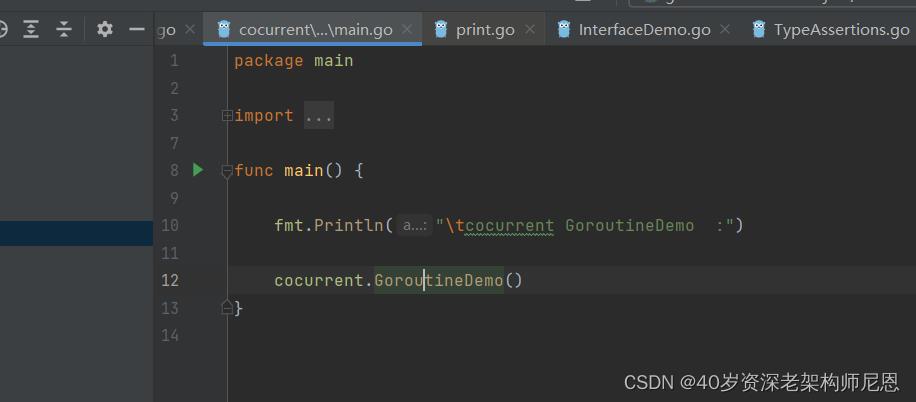
执行的结果
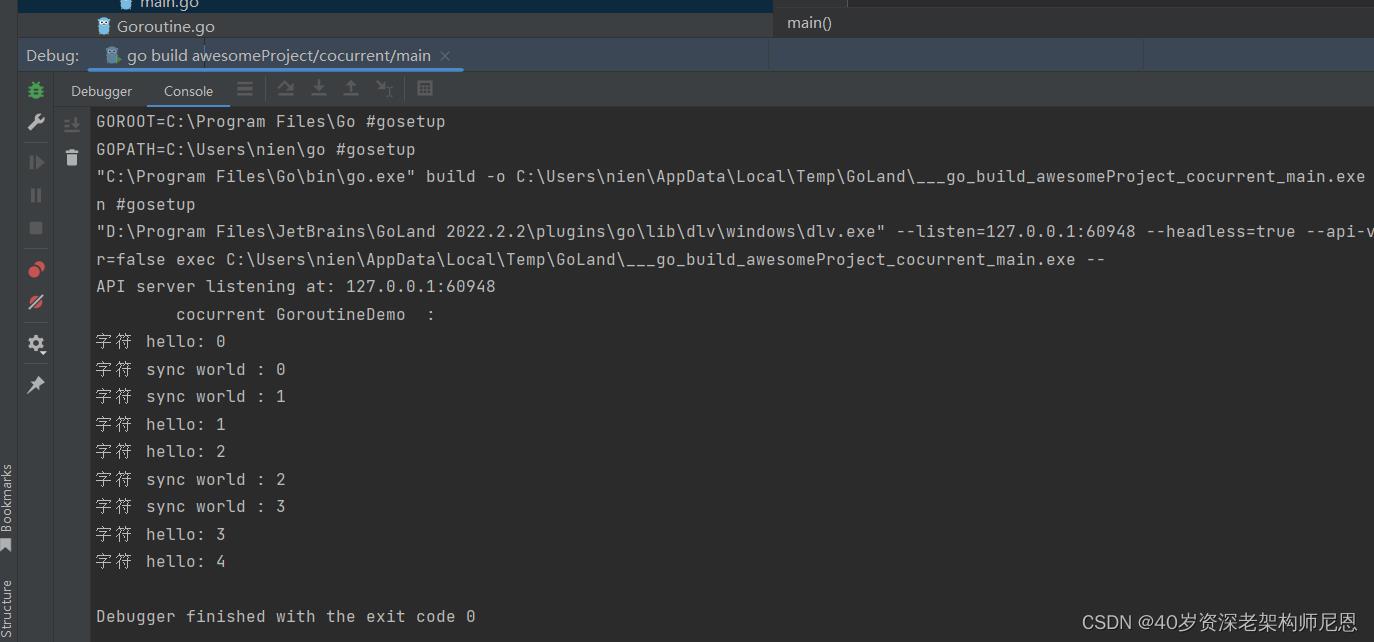
Go 协程在相同的地址空间中运行,因此在访问共享的内存时必须进行同步。
Go标准库 协程同步
Go 标准库中提供了多种同步机制,可以满足不同场景下的需求。以下是 Go 中常用的同步机制:
- Mutex:互斥锁,用于保护临界区(critical section)代码,只允许一个协程进入临界区执行代码,其他协程需要等待。使用 sync.Mutex 类型来定义互斥锁。
- RWMutex:读写锁,用于保证在读操作时允许多个协程同时访问资源,在写操作时只允许一个协程进入临界区修改资源。使用 sync.RWMutex 类型来定义读写锁。
- WaitGroup:等待组,用于等待一组并发协程执行完成后再继续执行。使用 sync.WaitGroup 类型来定义等待组。
- Cond:条件变量,用于在协程之间同步和通信。使用 sync.Cond 类型来定义条件变量。
- Once:单次执行,用于确保某个操作只会被执行一次。使用 sync.Once 类型来定义单次执行。
这些同步机制都可以帮助我们更好地控制协程的执行顺序和并发访问共享资源的安全性。在实际开发中,我们需要根据具体情况选择合适的同步机制,并且要注意避免死锁等问题。
Mutex互斥锁同步
这里涉及的概念叫做 互斥(mutual exclusion) ,我们通常使用互斥锁(Mutex)这一数据结构来提供这种机制。
Go 中的 Mutex(互斥锁)是一种最基本的同步机制,用于保护临界区代码,只允许一个协程进入临界区执行代码,其他协程需要等待。在 Go 标准库中,可以使用 sync.Mutex 类型来定义互斥锁。
Go 标准库中提供了 sync.Mutex 互斥锁类型及其两个方法:
-
Lock -
Unlock我们可以通过在代码前调用
Lock方法,在代码后调用Unlock方法来保证一段代码的互斥执行。参见Inc方法。我们也可以用
defer语句来保证互斥锁一定会被解锁。参见Value方法。
sync.Mutex类似于java 里边的 Lock 显示锁。 关于java显示锁,请参见 尼恩《Java 高并发核心编程 卷2 加强版》
啰嗦一下,sync.Mutex 类型包含两个方法:
- Lock():获得互斥锁,如果当前锁已经被其他协程获得,就会一直等待,直到锁被释放为止。
- Unlock():释放互斥锁,允许其他协程获得锁并进入临界区。
下面是一个使用 Mutex 实现协程同步的例子:
import (
"fmt"
"sync"
)
var counter int
func MutexDemo()
var wg sync.WaitGroup
var mu sync.Mutex
wg.Add(100)
for i := 0; i < 100; i++
go func()
mu.Lock()
counter++
mu.Unlock()
wg.Done()
()
wg.Wait()
fmt.Println("Counter:", counter)
在这个例子中,我们创建了一个计数器 counter,并启动了 100 个协程对其进行累加操作。由于对 counter 的访问是并发的,因此需要使用互斥锁 mu 来保护它,以避免不同协程之间的竞争条件。
在每个协程中,首先使用 mu.Lock() 方法获得互斥锁,然后对 counter 进行加 1 操作,并最终使用 mu.Unlock() 方法释放互斥锁。由于只有一个协程可以同时获得互斥锁并进入临界区,因此可以保证对 counter 的操作是安全的。
最后,我们使用 sync.WaitGroup 来等待所有协程执行完毕,并输出最终的计数器值。
WaitGroup 等待组
在 Go 中,可以使用 sync.WaitGroup 来等待一组协程完成执行。
sync.WaitGroup 类似于java 里边的闭锁。 关于java闭锁,请参见 尼恩《Java 高并发核心编程 卷2 加强版》
sync.WaitGroup 类型提供了三个方法:
- Add(delta int):将 WaitGroup 的计数器加上 delta 值。如果 delta 是负数,则会 panic。
- Done():将 WaitGroup 的计数器减 1。相当于 Add(-1)。
- Wait():阻塞当前协程,直到 WaitGroup 的计数器为 0。
下面是一个使用 sync.WaitGroup 实现并发下载的例子:
import (
"fmt"
"sync"
)
func main()
urls := []string
"https://www.google.com",
"https://www.bing.com",
"https://www.yahoo.com",
"https://www.baidu.com",
"https://www.amazon.com",
"https://www.apple.com",
var wg sync.WaitGroup
for _, url := range urls
wg.Add(1)
go func(url string)
defer wg.Done()
download(url)
(url)
wg.Wait()
fmt.Println("All downloads completed.")
func download(url string)
fmt.Printf("Downloading %s...\\n", url)
// 模拟下载操作
在这个例子中,我们定义了一个 urls 列表,包含了需要下载的网址。
然后创建了一个 sync.WaitGroup 对象 wg,并通过调用 wg.Add(1) 把计数器置为 1。
接着使用 for 循环遍历 urls 列表,对每个网址都启动一个新的协程,并在协程中调用 download() 函数来下载网页内容。
在协程中,通过 defer wg.Done() 将 WaitGroup 的计数器减 1,表示当前协程已经完成了下载任务。
最后,主程序调用 wg.Wait() 来等待所有协程执行完毕,并输出提示信息表示所有下载任务都已经完成了。
Cond(条件变量)
Go 中的 Cond(条件变量)是一种同步机制,用于在协程之间同步和通信。
Cond 是基于 Mutex 和 WaitGroup 实现的,它可以让一个或多个协程等待某个条件满足后再执行下一步操作。
在 Go 标准库中,可以使用 sync.Cond 类型来定义条件变量。
sync.Cond 类型包含三个方法:
- Broadcast():唤醒所有正在等待条件变量的协程。
- Signal():唤醒一个正在等待条件变量的协程。
- Wait():阻塞当前协程,并解锁 Mutex,直到收到 Broadcast 或 Signal 信号后才会被唤醒并重新获得 Mutex。
下面是一个使用 Cond 实现生产者-消费者模型的例子:
import (
"fmt"
"sync"
)
const capacity = 5
var queue []int
var mu sync.Mutex
var cond = sync.NewCond(&mu)
func main()
var wg sync.WaitGroup
wg.Add(2)
// 生产者协程
go func()
defer wg.Done()
for i := 0; i < capacity*2; i++
mu.Lock()
for len(queue) == capacity
cond.Wait()
queue = append(queue, i)
fmt.Println("Produce:", i)
if len(queue) == 1
cond.Signal()
mu.Unlock()
()
// 消费者协程
go func()
defer wg.Done()
for i := 0; i < capacity*2; i++
mu.Lock()
for len(queue) == 0
cond.Wait()
item := queue[0]
queue = queue[1:]
fmt.Println("Consume:", item)
if len(queue) == capacity-1
cond.Signal()
mu.Unlock()
()
wg.Wait()
在这个例子中,我们定义了一个长度为 5 的队列,然后创建了两个协程,一个用来生产数据,另一个用来消费数据。
在协程中,使用 sync.Mutex 和 sync.Cond 对象来保护和同步共享资源。
在生产者协程中,首先调用 mu.Lock() 获取互斥锁,然后使用 for 循环判断队列是否已满,
- 如果已满则调用 cond.Wait() 阻塞当前协程,等待消费者协程唤醒。
- 如果队列未满,则将数据插入队列并打印生产的数据。
在插入数据后,如果队列原来为空,则调用 cond.Signal() 唤醒一个正在等待条件变量的协程。最后,使用 mu.Unlock() 释放互斥锁。
在消费者协程中,首先调用 mu.Lock() 获取互斥锁,然后使用 for 循环判断队列是否为空
- 如果为空则调用 cond.Wait() 阻塞当前协程,等待生产者协程唤醒。
- 如果队列非空,则取出队头元素并打印消费的数据。
在取出数据后,如果队列原来已满,则调用 cond.Signal() 唤醒一个正在等待条件变量的协程。
最后,使用 mu.Unlock() 释放互斥锁。
channel 通道
除了标准库 sync 包提供了协程 同步能力,还可以使用channel 来实现。
channel 是一种特殊的数据类型,可以用来在协程之间传递数据,并且能够实现阻塞式等待和唤醒功能。
channel 通道(/信道)的两个基本操作
和映射与切片一样,channel 通道在使用前必须创建:
ch := make(chan int)
使用 make 函数创建 channel 时,第一个参数为 channel 类型,第二个参数为缓冲区大小(可选)。注意,第二个参数是可选的。
channel 通道在创建的时候, 类型参数表示 通道里边 值的类型。所以,通道是带有类型的管道,你可以通过它用信道操作符 <- 来发送或者接收值。
ch <- v // 将 v 发送至信道 ch。
v := <-ch // 从 ch 接收值并赋予 v。
“箭头” <- 就是数据流的方向。默认情况下,发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步。
在使用 channel 进行同步时,一般有两种基本的操作:
- 发送数据到 channel:通过 channel 的 <- 操作符向其中发送一个值,例如:
ch <- "hello"
- 从 channel 接收数据:通过 channel 的 <- 操作符从其中接收一个值,例如:
msg := <- ch
当调用 <- 操作符时,如果 channel 中没有数据可用,则当前协程会被阻塞,直到有数据可用为止。
下面是一个使用 channel 实现协程同步的例子:
func main()
ch := make(chan string)
go func()
fmt.Println("Sending message...")
ch <- "Hello, world!"
fmt.Println("Message sent!")
()
msg := <- ch
fmt.Println("Received message:", msg)
在这个例子中,我们创建了一个字符串类型的 channel,然后启动了一个新的协程。
在协程中,先打印一条信息表示正在发送消息,然后将消息发送到 channel 中。发送完成后,再打印一条信息表示消息已经发送完毕。
在主程序中,我们等待从 channel 中接收到消息,并将其保存到变量 msg 中。接收到消息后,再打印一条信息表示已经接收到了消息,并输出这个消息的内容。
注意,在这个例子中,主程序会被阻塞,直到从 channel 中接收到了消息为止。就是这句:
msg := <- ch
这是因为主程序使用 <- ch 操作符从 channel 中接收数据时,如果 channel 中没有数据可用,它会一直阻塞等待,直到有数据可用为止。
附录:make 函数如何使用?
在 Go 中,make 函数用于创建一个类型为 slice、map 或 channel 的对象,并返回其引用。make 函数的语法如下:
make(Type, size)
其中 Type 表示要创建的对象类型,size 则表示对象大小或缓冲区大小(仅适用于 channel)。具体来说,make 函数有以下三种用法:
-
创建 slice:使用 make 函数创建 slice 时,第一个参数为 slice 类型,第二个参数为 slice 的长度(数量),第三个参数为 slice 的容量(可选)。例如:
// 创建长度为 10,容量为 20 的 int 类型 slice s := make([]int, 10, 20) -
创建 map:使用 make 函数创建 map 时,第一个参数为 map 类型,不需要指定大小。例如:
// 创建 string 到 int 的映射表 m := make(map[string]int) -
创建 channel:使用 make 函数创建 channel 时,第一个参数为 channel 类型,第二个参数为缓冲区大小(可选)。例如:
// 创建一个无缓冲的 channel ch := make(chan string) // 创建一个可以缓存 10 个字符串的 channel ch := make(chan string, 10)
除此之外,make 函数还可以用于创建一些类型的值,例如 string、array 和 struct 等。
但是,在这些情况下,通常更推荐使用字面量语法来创建相应的值。
range遍历 和 通道关闭 close
在 Go 中,可以使用 close 函数来关闭通道。关闭通道后,发送方不能再向通道中发送数据,但是接收方仍然可以从通道中接收数据,直到通道中所有的数据都被读取完毕。
如果要关闭通道,生产者/发送者可通过 close 函数关闭一个信道,来表示没有需要发送的值了。
close函数的使用方法,非常简单,具体如下:
close(ch)
消费者/接收者如何判定呢?
在消费的时候, 可以通过接收表达式返回的第二个参数,来测试信道是否被关闭, 两个返回值版本的接收表达式如下:
v, ok := <-ch
若两个返回值中,如果没有值可以接收、且信道已被关闭,第一个值为0值,第二个值 ok 会被设置为 false。
其中 ok 是一个 bool 类型,可以通过它来判断 channel 是否已经关闭,如果 channel 关闭该值为 false ,此时 v 接收到的是 channel 类型的零值。比如:channel 是传递的 int, 那么 v 就是 0 ;如果是结构体,那么 v 就是结构体内部对应字段的零值。
注意:
- 只有发送者才能关闭信道,而接收者不能。
- 向一个已经关闭的信道发送数据会引发程序恐慌(panic)。
在 Go 中,可以使用 range 来遍历通道中的数据。使用 range 遍历通道时,会一直等待通道中有新的数据可读取,直到通道被关闭或者显式地使用 break 终止循环。
简单来说,循环 for i := range c 会不断从信道接收值,直到它被关闭。
还要注意: 信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个 range 循环。
下面是一个使用 range 遍历通道的示例:
import (
"fmt"
"time"
)
func main()
ch := make(chan int)
go func()
for i := 0; i < 5; i++
ch <- i
time.Sleep(time.Second)
close(ch)
()
for x := range ch
fmt.Println("Received:", x)
fmt.Println("Done")
在这个例子中,我们创建了一个无缓冲的 channel ch,并启动了一个协程向 ch 中发送数据。
在主程序中,使用 range 遍历 ch 中的数据,并打印接收到的数据。
当协程向 ch 中发送完数据后,通过 close 函数关闭 ch。
在使用 range 遍历通道时,如果通道未关闭,则循环会一直等待直到通道被关闭。当通道被关闭后,循环会自动终止,无需使用其他方式来判断通道是否已经关闭。同时,如果在循环中使用 break 终止循环,则需要注意在终止前将通道关闭,否则可能会导致死锁等问题。
需要注意的是,使用 range 遍历通道时,如果通道中已经没有数据可读取,则循环会被阻塞,直到有新的数据可读取或者通道被关闭。因此,在使用 range 遍历通道时,需要确保在发送方将所有数据发送完毕后及时关闭通道,否则可能会导致循环一直阻塞等待。
close Channel 的一些说明
channel 不需要通过 close 来释放资源,这个是它与 socket、file 等不一样的地方,对于 channel 而言,唯一需要 close 的就是我们想通过 close 触发 channel 读事件。
- close channel对 channel阻塞无效,写了数据不读,直接 close,还是会阻塞的。
- 如果 channel 已经被关闭,继续往它发送数据会导致 panic
send on closed channel - closed 的 channel,再次关闭 close 会 panic
- close channel 的推荐使用姿势是在发送方来执行,因为 channel 的关闭只有接收端能感知到,但是发送端感知不到,因此一般只能在发送端主动关闭。而且大部分时候可以不执行 close,只需要读写即可。
- 从一个已经 close 的 channel中读取数据,是可以读取的,读到的数据为 0
- 读取的 channel 如果被关闭,并不会影响正在读的数据,它会将所有数据读取完毕,在读取完已发送的数据后会返回元素类型的零值(zero value)。
多通道查询select 语句/通道的多路复用
select 语句使一个 Go 程可以等待多个channel通信操作。
select 会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
在 Go 中,可以使用 select 语句来等待多个 channel 中的数据,并执行相应的操作。
当有多个 channel 中的数据可读取时,select 语句会随机选择一个可用的 channel,并执行对应的操作。
下面是一个示例代码,演示如何使用 select 语句查询多个 channel 中的数据:
import (
"fmt"
"time"
)
func main()
ch1 := make(chan int)
ch2 := make(chan string)
go func()
for i := 0; i < 5; i++
ch1 <- i
time.Sleep(time.Second)
()
go func()
for i := 0; i < 5; i++
ch2 <- fmt.Sprintf("Message %d", i)
time.Sleep(time.Second)
()
for i := 0; i < 10; i++
select
case x := <-ch1:
fmt.Println("Received from ch1:", x)
case x := <-ch2:
fmt.Println("Received from ch2:", x)
fmt.Println("Done")
在这个示例代码中,我们创建了两个 channel ch1 和 ch2,分别用于发送 int 类型和 string 类型的数据。
在两个协程中,分别向 ch1 和 ch2 中发送数据,并间隔一秒钟。
在主函数中,使用 select 语句查询 ch1 和 ch2 中的数据,并打印接收到的数据。在循环中共查询 10 次,由于两个协程的间隔时间不同,因此可能会先从 ch1 中接收到数据,也可能会先从 ch2 中接收到数据。最后,当所有数据被读取完毕后,程序输出 Done。
需要注意的是,在使用 select 语句查询多个 channel 时,如果多个 channel 同时有数据可读取,则随机选择一个 channel,并执行对应的操作。
因此,在设计程序逻辑时,需要考虑到 channel 的使用顺序可能会发生变化。此外,如果在 select 语句中同时等待多个 channel,而其中一个 channel 被关闭了,则程序仍然会等待其它的 channel,并在有数据可读取时执行相应的操作。
Go的select 和 OS的select 对比
Go语言中的select 和操作系统中的系统调用select比较相似。
C语言的select系统调用可以同时监听多个文件描述符的可读或者可写的状态,Go 语言的select可以让Goroutine同时等待多个Channel可读或可写,在多个文件或Channel状态改变之前,select会一直阻塞当前线程或Goroutine。
select是与switch相似的控制结构,不过select的case中的表达式必须都是channel的收发操作。当select中的多个case同时被触发时,会随机执行其中一个。
通常情况下,select语言会阻塞goroutine并等待多个Channel中的一个达到可以收发的状态。但如果有default语句,可以实现非阻塞,就是当多个channel都不能执行的时候,运行default。
非阻塞查询
select 默认是阻塞的,如果所有的通道都没有数据,那么 函数就会被阻塞。
如何不进行阻塞呢? 在 Go 中,select 语句还可以使用 default 分支,用于在没有任何 channel 可读取时执行默认操作。当所有被查询的 channel 都没有数据可读取时,select 会立即执行 default 分支,从而实现不会被阻塞。
换句话来说,当 select 中的其它分支都没有准备好时,default 分支就会执行。所以,为了在尝试在接收时不发生阻塞,可使用 default 分支, 使用的方式如下:
select
case i := <-c:
// 使用 i
default:
// 从 c 中接收会阻塞时执行
下面是一个示例代码,演示如何使用 default 分支:
import (
"fmt"
"time"
)
func main()
ch := make(chan int)
go func()
time.Sleep(time.Second * 3)
close(ch)
()
for
select
case x, ok := <-ch:
if !ok
fmt.Println("Channel closed")
return
fmt.Println("Received:", x)
default:
fmt.Println("No data received")
time.Sleep(time.Second)
fmt.Println("Done")
在这个示例代码中,我们创建了一个无缓冲的通道 ch,并在一个协程中等待 3 秒钟后关闭通道。
在主函数中,使用 select 语句监听 ch 中的数据,并打印接收到的数据。
由于 ch 一开始并没有数据可读取,因此 select 会立即执行 default 分支,并打印提示信息。在 ch 被关闭后,通过判断第二个返回值 ok 的值来确定通道是否已经关闭。如果通道已经关闭,则跳出循环并输出结束信息。
需要注意的是,在使用 default 分支时,需要考虑到程序的实际需求,并合理设置等待时长。
如果等待时间过短,则可能会频繁地执行 default 分支,导致性能损失;如果等待时间过长,则可能会导致数据延迟等问题。
此外,在使用 default 分支时,需要注意区分通道中的零值和通道已经关闭两种情况,以避免出现不必要的错误。
带缓冲的通道
在 Go 中,可以使用带缓冲的 channel 来实现协程之间的同步和通信。channel 可以是 带缓冲的。
如何创建带缓冲通道呢? 将缓冲长度作为第二个参数提供给 make 来初始化一个带缓冲的信道
在创建带缓冲的 channel 时,需要在 channel 类型后面添加一个整数,表示缓冲区大小。例如:
// 创建一个可以缓存 10 个字符串的 channel
ch := make(chan string, 10)
在这个例子中,我们创建了一个可以缓存 10 个字符串的 channel ch。
- 当有协程向 ch 发送数据时,如果缓冲区未满,则可以直接将数据写入缓冲区;否则,发送操作会被阻塞,直到有协程从 ch 中读取数据为止。
- 同样地,当有协程从 ch 中读取数据时,如果缓冲区非空,则可以直接从缓冲区读取数据;否则,接收操作会被阻塞,直到有协程向 ch 中发送数据为止。
带缓冲的通道的特点是:
- 仅当信道的缓冲区填满后,向其发送数据时才会阻塞。
- 当缓冲区为空时,接受方会阻塞。
带缓冲的 channel 是一种有固定缓冲区大小的 channel,当缓冲区满时,向 channel 发送数据会被阻塞,直到有协程从 channel 中接收数据为止。相反,当缓冲区为空时,从 channel 接收数据也会被阻塞,直到有协程向 channel 中发送数据为止。
下面是一个使用带缓冲的 channel 实现生产者-消费者模型的例子:
import (
"fmt"
)
const capacity = 5
func main()
ch := make(chan int, capacity)
done := make(chan bool)
// 生产者协程
go func()
for i := 0; i < capacity*2; i++
ch <- i
fmt.Println("Produce:", i)
done <- true
()
// 消费者协程
go func()
for i := 0; i < capacity*2; i++
item := <-ch
fmt.Println("Consume:", item)
done <- true
()
<-done
<-done
在这个例子中,我们创建了一个缓冲区大小为 5 的 channel ch,然后创建了两个协程,一个用来生产数据(向 ch 中发送数据),另一个用来消费数据(从 ch 中接收数据)。
当所有数据都被生产和消费完毕后,使用两个 done channel 来通知主程序结束。
在生产者协程中,首先向 ch 中发送数据,并打印生产的数据。如果缓冲区已满,则发送操作会被阻塞,等待消费者协程从 ch 中读取数据。在最后一个数据被生产和发送完毕后,通过 done channel 向主程序发送结束信号。
在消费者协程中,首先从 ch 中接收数据,并打印消费的数据。如果缓冲区为空,则接收操作会被阻塞,等待生产者协程向 ch 中发送数据。在最后一个数据被消费完毕后,通过 done channel 向主程序发送结束信号。
Java BlockingQueue 和 Go channel 对比学习
Java 中的 BlockingQueue 和 Go 中的 channel 都是用于实现线程之间的通信的工具,但是它们在一些方面存在差异 , 主要有3点:
- 1:实现方式
Java 中的 BlockingQueue 是一个接口,它有多个不同的实现类,如 ArrayBlockingQueue、LinkedBlockingQueue 等。这些实现类都是基于数组或链表等数据结构实现的,提供了一些阻塞式的队列操作方法。
Go 中的 channel 是语言内置的类型,直接由编译器实现。在底层,channel 是使用 waitgroup、mutex、cond 等同步原语实现的,而不是基于数据结构实现的。
- 2:缓存机制
Java 的 BlockingQueue 有两种类型:有界阻塞队列和无界阻塞队列。有界阻塞队列的大小是固定的,当队列元素数量达到上限时,生产者线程会被阻塞,直到队列中有空位。无界阻塞队列没有容量限制,在添加元素时不会被阻塞,但是获取元素时可能会被阻塞。
Go 的 channel 也可以分为两种类型:带缓存的 channel 和非缓存的 channel。带缓存的 channel 可以缓存一定数量的元素,当缓冲区满时,发送操作会被阻塞。非缓存的 channel 不允许缓存元素,每个元素只能被发送和接收一次。
- 3:阻塞机制
Java 的 BlockingQueue 提供了多种阻塞式队列操作方法,如 put 和 take 等。其中,put 方法会在队列已满时阻塞直到有空位,而 take 方法会在队列为空时阻塞直到有元素可取。
Go 的 channel 通过阻塞操作实现协程之间的同步和通信。当发送或接收操作无法进行时,协程会被阻塞,并暂停执行,直到对应的操作可以进行为止。
Java 的 BlockingQueue 和 Go 的 channel 在实现方式和应用场景不同,但是它们也有一些相同点。主要有4点:
- 1:用途相同
Java 的 BlockingQueue 和 Go 的 channel 都是用于协程之间的通信和同步。它们允许多个协程在不同的时间段进行读写操作,并提供了阻塞式的方法来确保线程安全和正确性。
- 2:阻塞机制相同
Java 的 BlockingQueue 和 Go 的 channel 都通过阻塞操作来实现协程之间的同步。当队列为空或已满时,生产者线程和消费者线程都会被阻塞,直到对应的条件得到满足为止。
- 3:线程安全性相同
Java 的 BlockingQueue 和 Go 的 channel 都是线程安全的。它们都提供了阻塞式的方法,可以确保多个协程在不同的时间段进行读写操作时不会发生竞态条件等问题。
- 4:可靠性相同
Java 的 BlockingQueue 和 Go 的 channel 都是可靠的。它们都能够确保协程之间的通信和同步。同时,在使用过程中也可以通过异常捕获等方法来处理潜在的错误,并保证程序的正确性和健壮性。
综上所述,Java 的 BlockingQueue 和 Go 的 channel 在用途、阻塞机制、线程安全性和可靠性等方面存在相同点,这些共同点也是它们成为编写多线程程序时的优秀工具的原因之一。
SynchronousQueue VS 无缓冲channel
go 中channel 分为缓冲通道和非缓冲通道(容量为0)。
Go 语言的无缓冲channel,只有在发送操作和接收操作配对上了,发送方和接收方才能得以继续执行,否则将会阻塞在发送或者接收操作。
Go 语言的无缓冲channel,本质上就是以同步的方式来传递数据。
所以, Go 语言的无缓冲channel 正是 Java 中的 SynchronousQueue 具有的特性。
| 零容量 无缓冲 | 有限容量 | |
|---|---|---|
| Go | unbuffered channel | buffered channel |
| Java | SynchronousQueue | LinkedBlockingQueue |
LinkedBlockingQueue VS 缓冲通道 buffered channel
缓冲通道,顾名思义,就是能起到缓冲作用的数据类型。
相对于非缓冲通道发送操作如果没有配对的接收操作则会阻塞的情况,缓冲通道在容量未满的时候允许发送操作发送成功之后立即执行后续的操作而不阻塞。
Java 中的 LinkedBlockingQueue 也具有这一特性,从命名来看就是底层基于链表的阻塞队列。
操作对比
Go中,可以使用 len 获取通道的 长度,cap 函数 获取通道的 容量,下面是一个例子:
unbufChan := make(chan int) // 创建一个非缓冲通道
fmt.Printf("容量为%d\\n", cap(unbufChan)) // 容量为0
fmt.Printf("长度为%d\\n", len(unbufChan)) // 长度为0
bufChan := make(chan int, 8) // 创建一个缓冲通道
fmt.Printf("容量为%d\\n", cap(bufChan)) // 容量为8
fmt.Printf("长度为%d\\n", len(bufChan)) // 长度为0
bufChan <- 1
fmt.Printf("容量为%d\\n", cap(bufChan)) // 容量为8
fmt.Printf("长度为%d\\n", len(bufChan)) // 长度为1
对于 Go 语言的非缓冲通道,其容量也总是为0
其中队列(或通道)的长度代表它当前包含的元素值的个数。当队列(或通道)已满时,其长度与容量相同。
SynchronousQueue VS 无缓冲channel 的长度和 容量比较:
| 容量 | 长度 | 剩余容量 | |
|---|---|---|---|
| SynchonousQueue | 0 | 0 | 0 |
| unbuffered channel | 0 | 0 | 0 |
LinkedBlockingQueue VS 缓冲通道 buffered channel 的长度和 容量比较:
| 容量 | 长度 | 剩余容量 | |
|---|---|---|---|
| LinkedBlockingQueue | 构造函数指定的capacity | size() | remainingCapacity() |
| buffered channel | cap(ch) | len(ch) | cap(ch) - len(ch) |
其中队列(或通道)的长度代表它当前包含的元素值的个数。当队列(或通道)已满时,其长度与容量相同。
go rocketmq 编程
Apache RocketMQ 是一个开源的、分布式的消息中间件系统,支持高吞吐量和高可用性的消息传递。
在 Go 编程中,可以使用 Apache RocketMQ 的 Go 客户端来实现与 RocketMQ 的交互。
golang 模块安装
go get github.com/apache/rocketmq-client-go/v2
尼恩提示:
在 goland 工具中的 模块安装过程,请参考后面的附录。
实例:使用 RocketMQ 的 Go 客户端来发送和接收消息
下面是一个简单的示例代码,演示如何使用 RocketMQ 的 Go 客户端来发送和接收消息:
package batchprocess
import (
"context"
"fmt"
"github.com/apache/rocketmq-client-go/v2"
"log"
"time"
"github.com/apache/rocketmq-client-go/v2/consumer"
"github.com/apache/rocketmq-client-go/v2/primitive"
"github.com/apache/rocketmq-client-go/v2/producer"
)
// 创建生产者
const NAME_NODE = "192.168.56.121:9876"
const TOPIC = "test"
func RocketMQDemo()
producer, err := rocketmq.NewProducer(
producer.WithNameServer([]stringNAME_NODE),
producer.WithRetry(2),
)
if err != nil
fmt.Println("create producer error:", err)
return
err = producer.Start()
if err != nil
fmt.Println("start producer error:", err)
return
defer producer.Shutdown()
// 发送消息
for i := 0; i < 10; i++
msg := &primitive.Message
Topic: TOPIC,
Body: []byte("Hello RocketMQ"),
res, err := producer.SendSync(context.Background(), msg)
if err != nil
log.Printf("send message error: %v\\n", err)
else
log.Printf("send message success: %v\\n", res)
time.Sleep(time.Second)
// 创建消费者
c, err := rocketmq.NewPushConsumer(
consumer.WithNameServer([]stringNAME_NODE),
consumer.WithGroupName("test-group"),
)
if err != nil
fmt.Println("create consumer error:", err)
return
err = c.Subscribe(TOPIC, consumer.MessageSelector,
func(ctx context.Context, msgs ...*primitive.MessageExt) (consumer.ConsumeResult, error)
for _, msg := range msgs
log.Printf("receive message: topic=%s, body=%s\\n",
msg.Topic, string(msg.Body))
return consumer.ConsumeSuccess, nil
)
if err != nil
fmt.Println("subscribe error:", err)
return
err = c.Start()
if err != nil
fmt.Println("start consumer error:", err)
return
defer c.Shutdown()
time.Sleep(time.Second * 10)
在这段代码中,首先生产者并用其向 RocketMQ 中的 test 主题发送了一条消息。然后创建了一个消费者,订阅了 test 主题,并在回调函数中处理接收到的消息。
在这个示例中,首先创建了一个 RocketMQ 生产者,并通过 WithNameServer 和 WithRetry 分别设置了 NameServer 地址和重试次数等配置项。
然后,在循环中创建了一个消息对象,并调用 SendSync 方法发送同步消息。该方法的第一个参数是上下文对象,可以使用 context.Background() 创建;第二个参数是消息对象。如果发送成功,则返回一个 SendResult 对象,否则返回一个非空的错误对象。
最后,使用 time.Sleep() 方法等待一秒钟,以便观察发送结果。在真实的应用程序中,可以根据需要调整等待时间。
综上所述,在 RocketMQ 的 Go 版本客户端 rocketmq-client-go 中,可以使用 SendSync 方法发送同步消息,并通过返回值和错误对象获取发送结果。
需要注意的是: 在使用 RocketMQ 的 Go 客户端时,必须先安装和配置好 RocketMQ 的服务端,并将 Go 客户端库引入到项目中。同时,也需要根据实际情况进行配置和参数设置,以确保程序能够正常运行。
消息发送和接受的验证
启动 rocketmq
使用尼恩的一键启动环境
启动之后的效果
启动 go 实例
package main
import (
"crazymakercircle.com/awesomeProject/batchprocess"
"fmt"
)
func main()
fmt.Println("\\tcocurrent RocketMQDemo :")
//cocurrent.GoroutineDemo()
fmt.Println("\\tcocurrent MutexDemo :")
batchprocess.RocketMQDemo()
使用goland 直接执行
发送消息效果
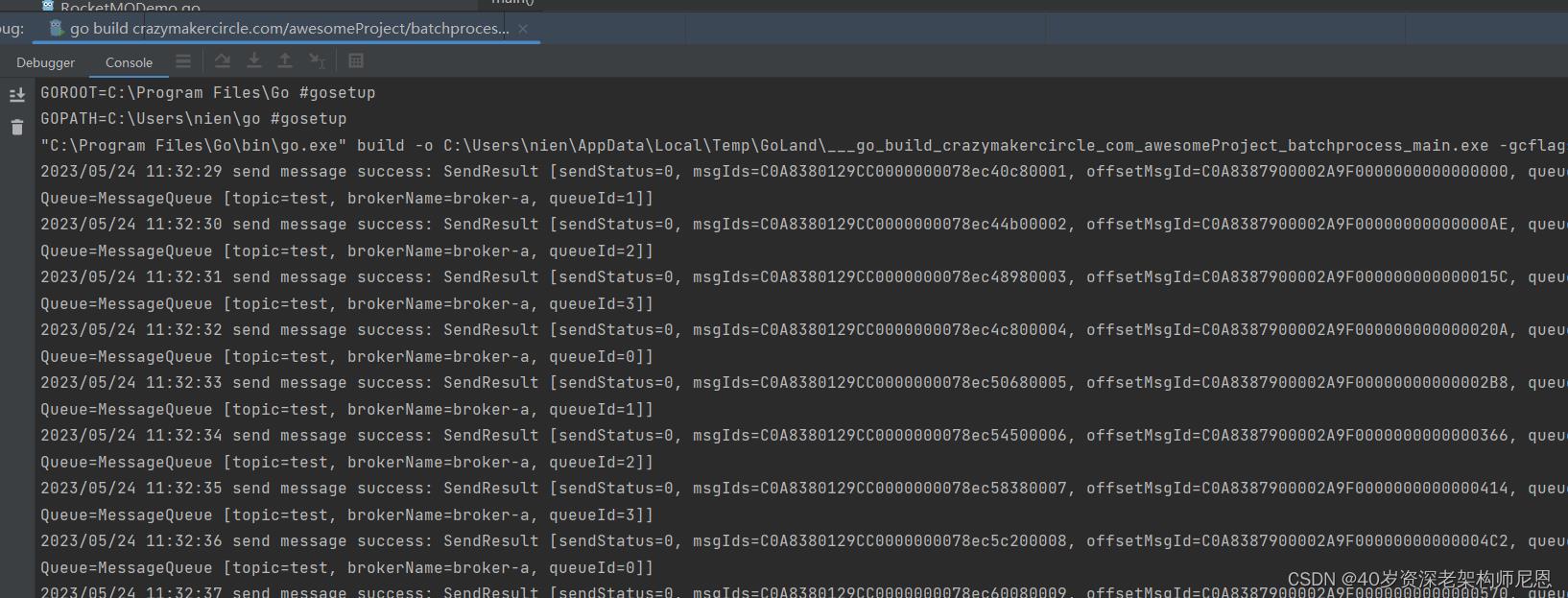
消费消息效果
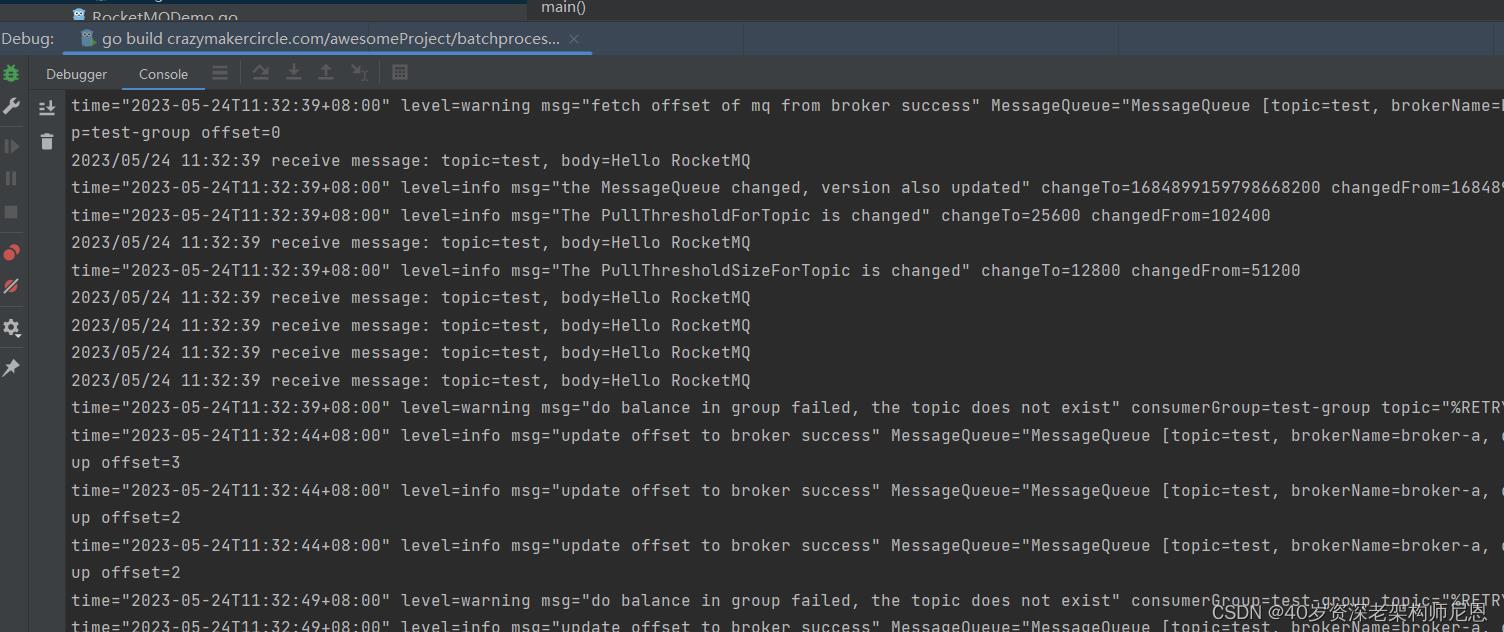
附录:Go 模块的安装和使用
Go 模块是 Go 语言1.11版本后引入的官方包管理工具,可以自动管理依赖项和版本。
一个模块是一些以版本作为单元相关的包的集合。模块记录精确的依赖要求并创建可复制的构建。
通常,版本控制存储库仅包含在存储库根目录中定义的一个模块。(单个存储库中支持多个模块,但是通常,与每个存储库中的单个模块相比,这将导致正在进行的工作更多)。
总结存储库,模块和软件包之间的关系:
-
一个存储库包含一个或多个Go模块。
-
每个模块包含一个或多个Go软件包。
-
每个软件包都在一个目录中包含一个或多个Go源文件。
下面是使用 Go 模块安装和管理第三方库的步骤:
启用 Go 模块
在使用 Go 模块之前,需要先启用 Go 模块功能。
可以通过设置 GO111MODULE 环境变量来控制 Go 是否使用模块。要启用模块,请将该环境变量设置为 on,例如:
$ export GO111MODULE=on
创建新项目
在开始开发项目之前,需要创建一个新的项目目录,并在其中初始化 Go 模块。
可以使用 go mod init 命令来完成初始化操作,例如:
$ go mod init crazymakercircle.com/awesomeProject
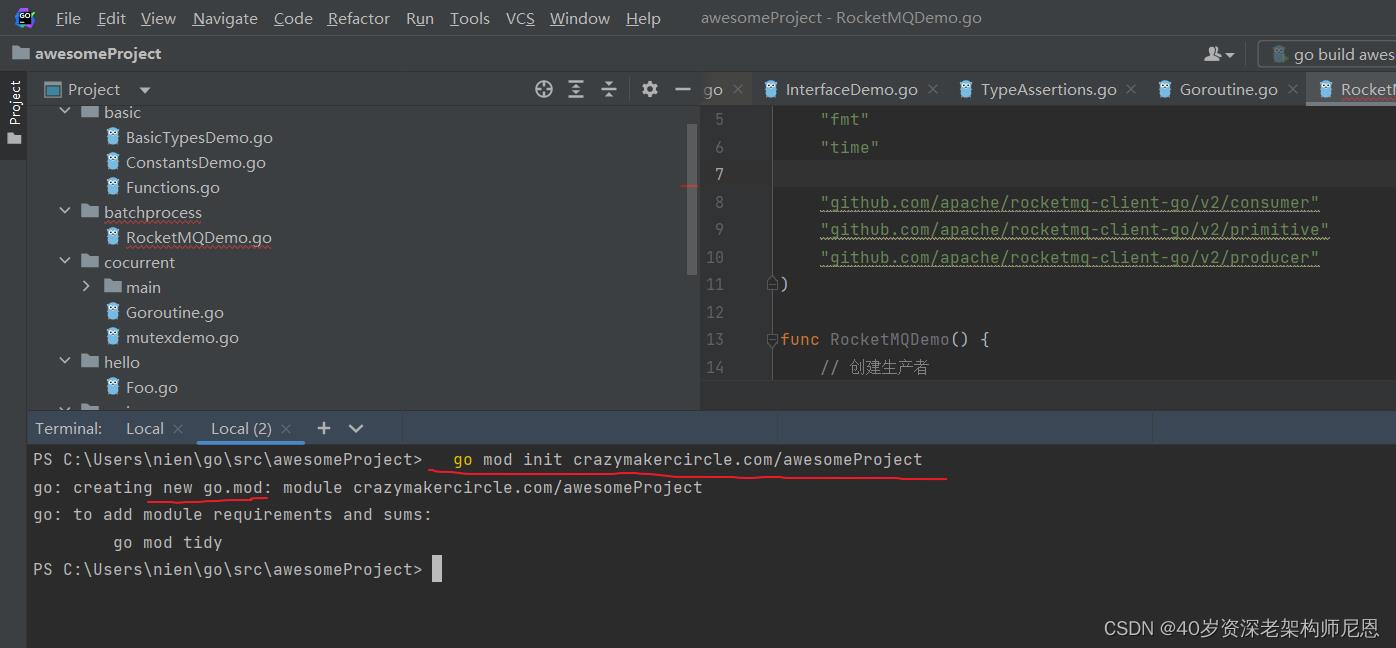
这个命令会创建一个新的 Go 模块,并在当前目录中生成一个名为 go.mod 的文件。
打开看看
go.mod
模块由Go源文件树定义,该go.mod文件在树的根目录中。模块源代码可能位于GOPATH之外。
在 Go 1.11 版本之后,Go 引入了官方的包管理工具 Go modules。使用 Go modules 可以更好地管理项目中的依赖项和版本,避免了 GOPATH 和 vendor 目录等传统的包管理方式中存在的一些问题。
在使用 Go modules 时,需要在项目根目录中创建一个名为 go.mod 的文件,并在其中定义模块路径和依赖项等信息。
下面是一个示例的 go.mod 文件:
module example.com/myproject
go 1.16
require (
github.com/gin-gonic/gin v1.7.4
github.com/go-sql-driver/mysql v1.6.0
)
在这个文件中,第一行指定了当前模块的名称,即 example.com/myproject。
注意,这个名称应该是唯一的,以便其他项目可以引用该模块。
第二行指定了所使用的 Go 版本,即 go 1.16。
下面的 require 块定义了所有依赖项及其版本信息。
每个依赖项都由一个完整的包名称和版本号组成,例如 github.com/gin-gonic/gin v1.7.4。这个版本号表示需要使用的确切版本,也可以使用语义化版本号范围来指定版本,例如 github.com/gin-gonic/gin v1.7.x。
mod文件 有四种指令:module,require,replace,exclude。
在 Go modules 中,一个模块可以包含多个软件包,每个软件包都有一个唯一的导入路径。这个导入路径由模块路径和从 go.mod 到软件包目录的相对路径共同确定。
假设有一个名为 example.com/myproject 的模块,其中包含两个软件包 foo 和 bar,它们的目录结构如下:
myproject/
|- go.mod
|- foo/
|- foo.go
|- bar/
|- bar.go
在这个例子中,软件包 foo 的导入路径为 example.com/myproject/foo,软件包 bar 的导入路径为 example.com/myproject/bar。
这个导入路径由模块路径 example.com/myproject 和相对路径 foo 或 bar 共同组成。
注意,在 Go modules 中,所有软件包的导入路径都将模块路径共享为公共前缀。这个公共前缀可以帮助防止命名冲突和混淆。
总之,模块中所有软件包的导入路径是由模块路径和从 go.mod 到软件包目录的相对路径共同决定的。对于不同的软件包,它们的相对路径是不同的,但它们共享相同的模块路径前缀。
安装第三方库
在 Go 模块中安装第三方库与在传统的 GOPATH 中安装方式略有不同。可以使用 go get 命令来安装第三方库并将其添加到当前项目的依赖项中,例如:
$ go get github.com/gin-gonic/gin@v1.7.4
这个命令会下载指定版本的 gin 库,并将其添加到当前项目的依赖项中。
go get github.com/apache/rocketmq-client-go/v2
此外,还可以使用 go get 命令下载最新版本的库,并将其添加到依赖项中,例如:
$ go get github.com/gin-gonic/gin
这个命令会下载指定版本的 rocketmq-client-go库,并将其添加到当前项目的依赖项中。
比如,安装 RocketMQ client 依赖
go get github.com/apache/rocketmq-client-go/v2
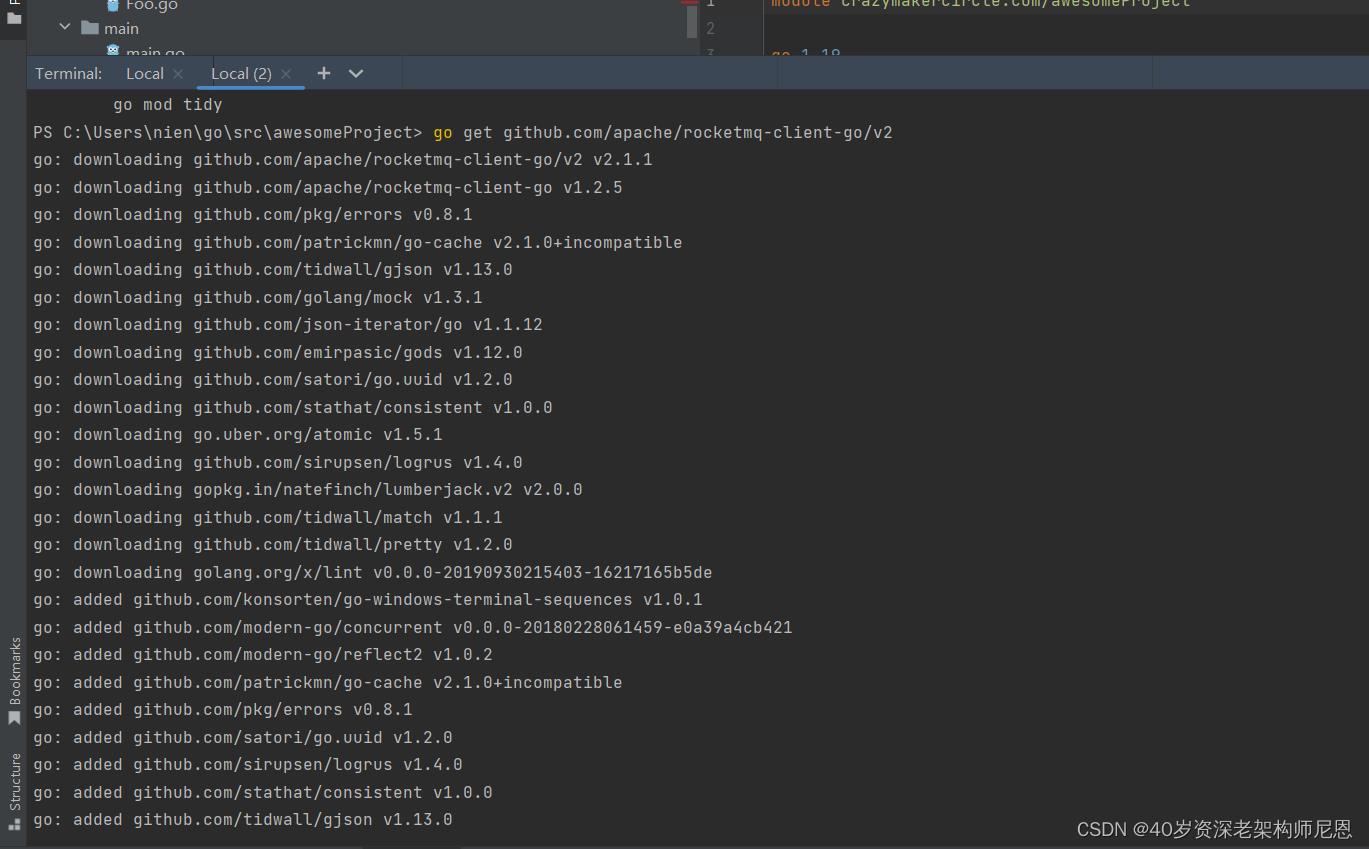
如果下载不来,或者设置代理试试,打开你的终端并执行(Go 1.13 及以上)
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.cn,direct
下载依赖项
当安装了第三方库后,还需要将其下载到本地计算机上。
可以使用 go mod download 命令来下载所有依赖项,例如:
$ go mod download
这个命令会下载当前项目依赖的所有库及其版本。
管理依赖项
在开发过程中,可能需要升级或删除某些依赖项。可以使用 go mod tidy 命令来清理不再使用的依赖项,例如:
$ go mod tidy
这个命令会分析项目代码并移除未使用的库。
同时,还可以使用 go get -u 命令来升级依赖项到最新版本,例如:
$ go get -u github.com/gin-gonic/gin
这个命令会下载并安装 gin 库的最新版本,并更新 go.mod 文件中的版本号。
综上所述,使用 Go 模块安装和管理第三方库非常方便,可以自动解决依赖关系和版本问题,大大简化了项目的依赖管理。
GoLand 中使用 Go 模块(go mod)管理依赖项
在 GoLand 中使用 Go 模块(go mod)管理依赖项,可以通过以下步骤进行操作:
打开或创建一个 Go 项目
在 GoLand 中打开或创建一个 Go 项目,并确保该项目启用了 Go 模块功能。
要启用 Go modules,可以通过菜单栏中的 File > Settings > Go > Go Modules 来启用 Go modules。
在这个对话框中,可以选择全局或项目级别的 Go modules 设置。建议选择项目级别的设置,以避免影响其他项目。
初始化 Go modules
在启用 Go modules 后,需要初始化 Go modules。可以在终端中切换到项目目录,然后执行以下命令来初始化 Go modules:
go mod init crazymakercircle.com/awesomeProject
这个命令会创建一个新的 Go 模块,并在当前目录中生成一个名为 go.mod 的文件。
添加依赖项
在 GoLand 中添加依赖项非常简单。可以使用 go get 命令来安装第三方库并将其添加到当前项目的依赖项中。例如,在 GoLand 的终端窗口中输入以下命令:
$ go get github.com/gin-gonic/gin
这个命令会下载并安装 Gin HTTP 框架,并将其添加到 go.mod 文件中。在此之后,即可在代码中引用 gin 库。
比如,安装 RocketMQ client 依赖
go get github.com/apache/rocketmq-client-go/v2
解决require内依赖全部飘红问题
解决go.mod文件中require内依赖全部飘红
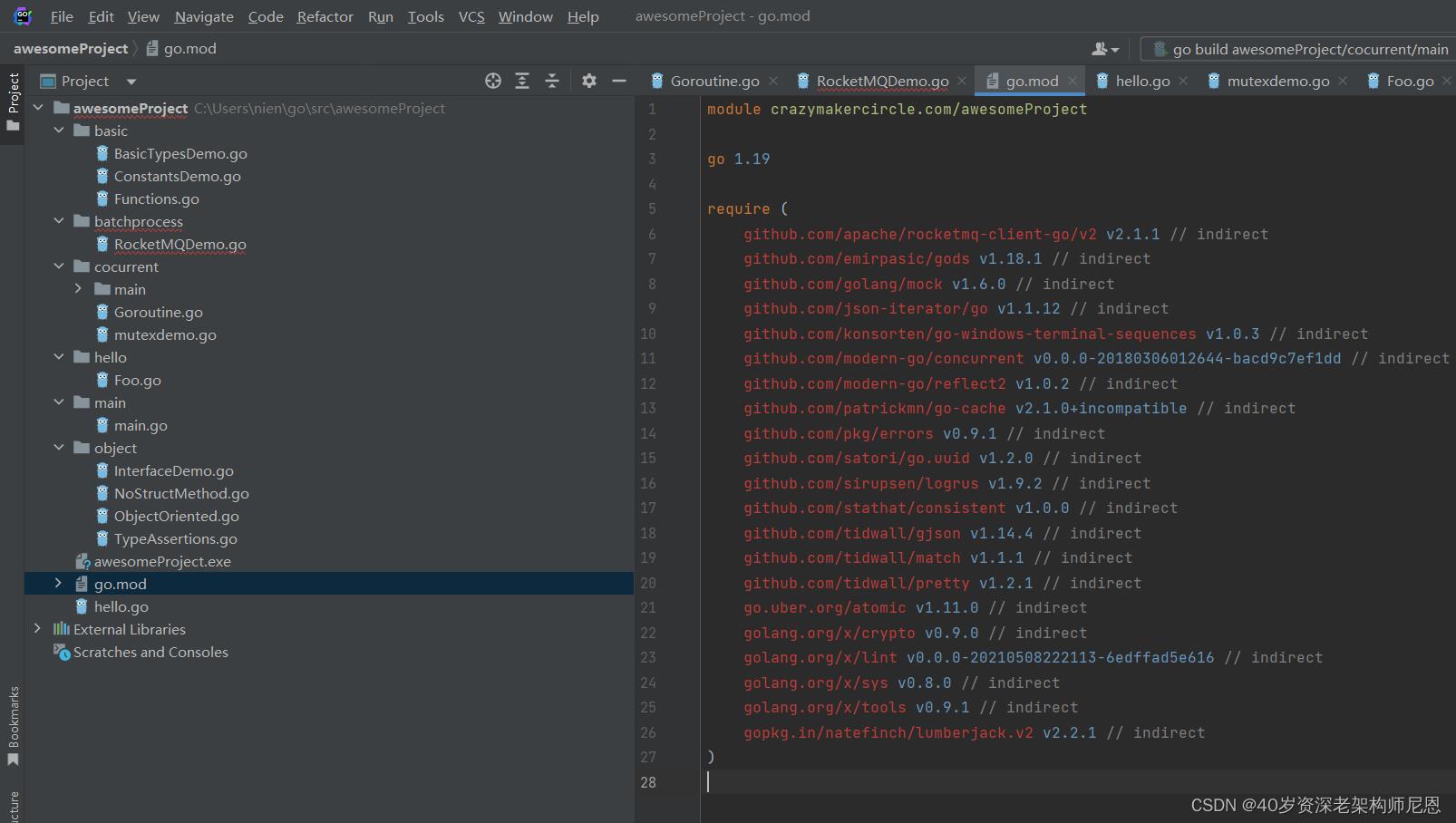
设置 go 模块化,并设置环境变量 GOPROXY=https://goproxy.cn,direct
ok了
管理依赖关系
在开发过程中,可能需要升级或删除某些依赖项。可以使用 go get -u 命令来升级依赖项到最新版本,并更新 go.mod 文件中的版本号,例如:
$ go get -u github.com/gin-gonic/gin
除此之外,还可以使用 GoLand 自带的依赖关系管理工具,包括自动生成和维护 go.mod 和 go.sum 文件、自动提示缺失的依赖项以及检查依赖项的版本等。
比如:
go get -u github.com/apache/rocketmq-client-go/v2
构建和运行项目
在完成依赖项的添加和管理后,即可构建和运行项目。可以使用 GoLand 的集成工具来构建和运行项目,例如:
- 点击菜单栏中的 Run 按钮或使用快捷键 Shift + F10 来运行程序;
- 在编辑器窗口中右键单击并选择 Run \'main\' 选项来运行程序;
- 在终端中输入
go build命令来编译项目,并使用./<executable>命令来运行可执行文件。
综上所述,GoLand 提供了便捷的工具来支持使用 Go 模块管理依赖项,包括自动化生成和维护 go.mod 和 go.sum 文件、自动提示缺失的依赖项以及检查依赖项的版本等,大大简化了
1W字长文:K8S Ingress 原理和实操
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
K8S Ingress原理和实操
背景:
云原生时代如火如荼,掌握云原生的架构和开发,是Java开发高薪的必备技能。
SVC、Ingress原理和实操,是云原生的基础知识。
这里尼恩给大家 调优,做一下Ingress 的系统化、体系化的梳理。
在面试之前,也可以复习一下,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
在这里也一并把这些宝贵内容作为“K8S云原生学习”重要的内容,收入尼恩的《K8S学习圣经》,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
先介绍一下svc作用与不足,再介绍Ingress原理和实操
svc的作用与不足
service的作用体现在两个方面:
- 对集群内部,它不断跟踪pod的变化,更新endpoint中对应pod的对象,提供了ip不断变化的pod的服务发现机制;
- 对集群外部,他类似负载均衡器,可以在集群内外部对pod进行访问。
在Kubernetes中,Pod的IP地址和service的ClusterIP仅可以在集群网络内部做用,对于集群外的应用是不可见的。
为了使外部的应用能够访问集群内的服务,Kubernetes目前提供了以下几种方案:
-
NodePort:将service暴露在节点网络上,NodePort背后就是Kube-Proxy,Kube-Proxy是沟通service网络、Pod网络和节点网络的桥梁。
测试环境使用还行,当有几十上百的服务在集群中运行时,NodePort的瑞口管理就是个灾难。因为每个端口只能是一种服务,端口范围只能是 30000-32767。
-
LoadBalancer:通过设置LoadBalancer映射到云服务商提供的LoadBalancer地址。这种用法仅用于在公有云服务提供商的云平台上设置Servic的场景。
受限于云平台,且通常在云平台部署LoadBalancer还需要额外的费用。
Ingress 的来源
Ingress:只需一个或者少量的公网IP和LB,即可同时将多个HTTP服务暴露到外网,七层反向代理。
可以简单理解为service的service,它其实就是一组基于域名和URL路径,把用户的请求转发到一个或多个service的规则。
Ingress解决的是新的服务加入后,域名和服务的对应问题,基本上是一个ingress的对象,通过yaml进行创建和更新进行加载。工作机制大致可以用下图表示:
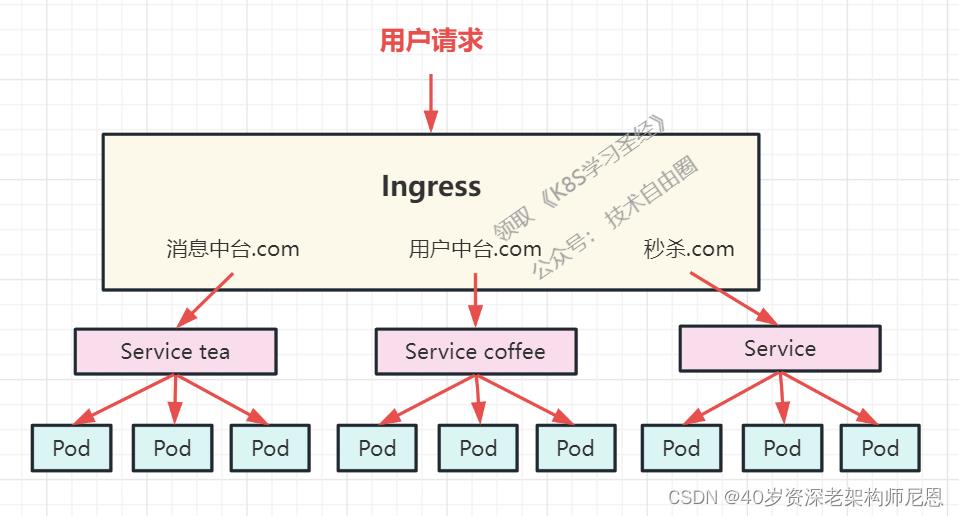
ingress相当于一个7层的负载均衡器,是k8s对反向代理的一个抽象。
大概的工作原理也确实类似于Nginx,可以理解成在 Ingress 里建立一个个映射规则 , ingress Controller 通过监听 Ingress这个api对象里的配置规则并转化成 Nginx 的配置(kubernetes声明式API和控制循环) , 然后对外部提供服务。
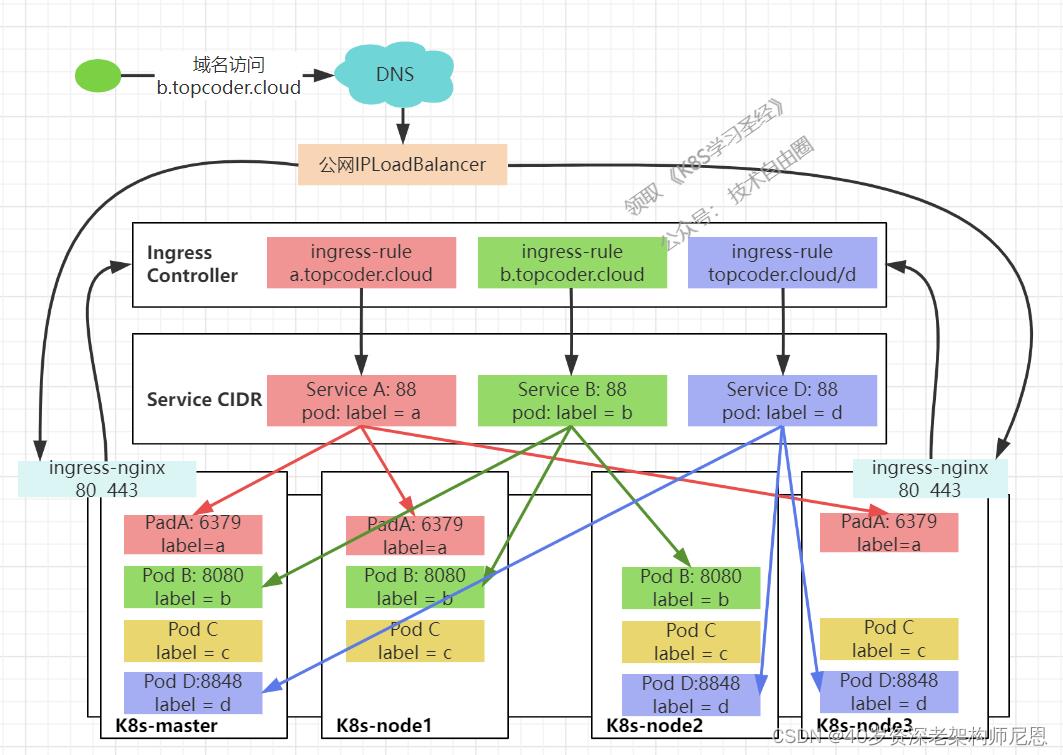
Ingress的构成
Ingress资源对象,用于将不同URL的访问请求转发到后端不同的Service,以实现HTTP层的业务路由机制。
Kubernetes使用一个Ingress策略定义和一个具体的Ingress Controller,两者结合并实现了一个完整的Ingress负载均衡器。
Ingress Controller将基于Ingress规则将客户请求直接转发到Service对应的后端Endpoint上,这样会跳过kube-proxy的转发功能,kube-proxy 不再起作用。
在定义Ingress策略之前,需要先部署Ingress Controller,以实现为所有后端Service提供一个统一的入口。
Ingress Controller需要实现基于不同HTTP URL向后转发的负载分发机制,并可以灵活设置7层的负载分发策略。如果公有云服务商提供该类型的HTTP路由LoadBalancer,则可以设置其为Ingress Controller.
在Kubernetes中,Ingress Controller将以Pod的形式运行,监控apiserver的/ingress端口后的backend services, 如果service发生变化,则Ingress Controller 应用自动更新其转发规则
什么是Ingress Controller?
在定义Ingress策略之前,需要先部署Ingress Controller,为所有后端Service都提供一个统一的入口。
Ingress Controller需要实现基于不同HTTP URL向后转发的负载分发规则,并可以灵活设置7层负载分发策略。
An API object that manages external access to the services in a cluster, typically HTTP. Ingress can provide load balancing, SSL termination and name-based virtual hosting.
引用官方关于ingress的介绍我们可以得知,ingress是一种通过http协议暴露kubernetes内部服务的api对象,即充当Edge Router边界路由器的角色对外基于七层的负载均衡调度机制,
Ingress 能够提供以下几个功能:
- 负载均衡,将请求自动负载均衡到后端的Pod上;
- SSL加密,客户端到Ingress Controller为https加密,到后端Pod为明文的http;
- 基于名称的虚拟主机,提供基于域名或URI更灵活的路由方式
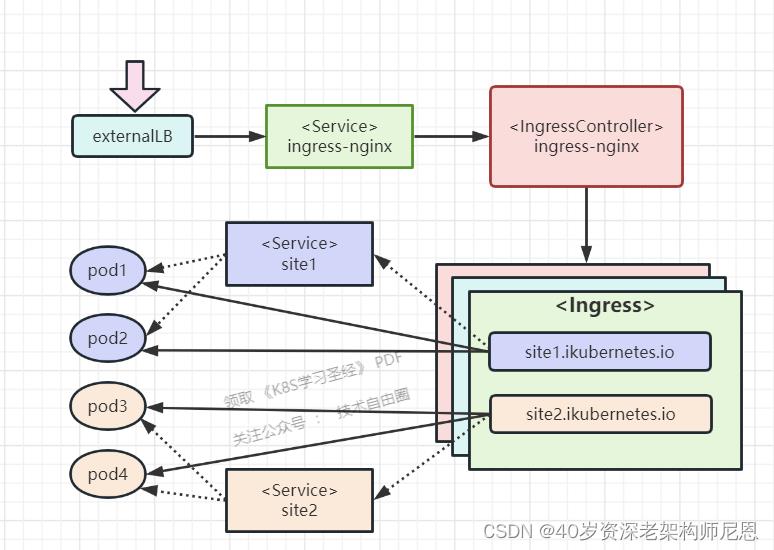
在Kubernetes中,Ingress Controller将以Pod的形式运行,监控API Server的/ingress接口后端的backend services,如果Service发生变化,则Ingress Controller应自动更新其转发规则。
Ingress包含的组件有:
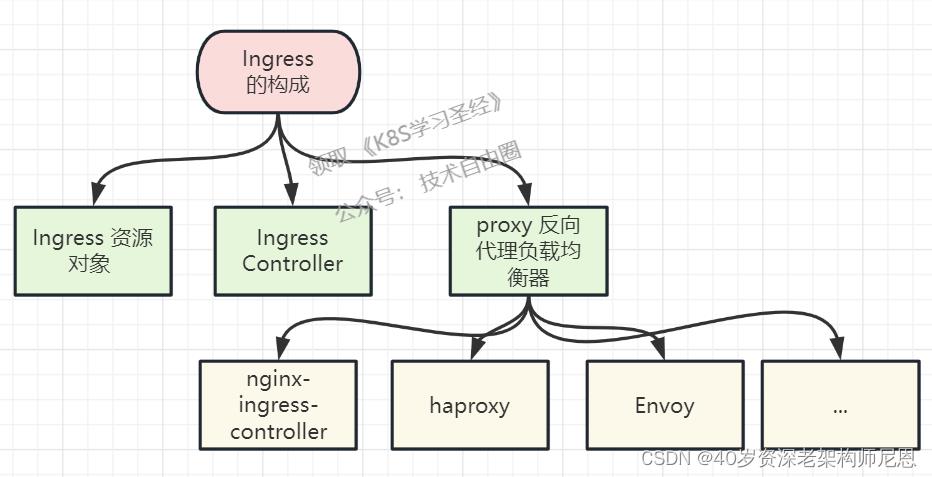
-
Ingress 资源对象 ,kubernetes的一个资源对象,用于编写 资源 配置规则;
Ingress配置规则 控制器通过service服务发现机制,动态实现后端Pod路由转发规则的实现;
-
Ingress Controller,Ingress控制器,
ingress-controller,调用k8s的api动态感知集群中Pod的变化而动态更新配置文件,并重载proxy 反向代理负载均衡器 的配置
ingress-controller监听apiserver,获取服务新增,删除等变化,并结合ingress规则动态更新到反向代理负载均衡器上,并重载配置使其生效
-
proxy 反向代理负载均衡器 ,接收并按照ingress定义的规则进行转发,通常为nginx,haproxy,traefik等,常用的是 Ingress-nginx
反向代理负载均衡器,实现七层转发的Edge Router 边沿路由器,proxy 通过ingress-controller,proxy 需要ingress-controller监听apiserver,感知集群中Pod的变化而动态更新配置文件,
通常以DaemonSets或Deployments的形式部署,并对外暴露80和443端口,
对于DaemonSets来说,一般是以hostNetwork或者hostPort的形式暴露,
对于Deployments来说则以NodePort的方式暴露,控制器的多个节点则借助外部负载均衡ExternalLB以实现统一接入;
从 开发人员的角度讲,ingress包括:ingress controller和ingress resources
ingress resources:这个就是一个类型为Ingress的k8s api对象了,这部分则是面向开发人员。Ingress解决的是新的服务加入后,域名和服务的对应问题,基本上是一个ingress的对象,通过yaml进行创建和更新进行加载。
ingress controller:包括 proxy+ Controller 两个部分,proxy比如nginx, Haproxy, trafik, Istio,proxy一般通过service 接收流量,其中service的类型可以是NodePort或者LoadBalancer。Ingress Controller是将Ingress这种变化生成一段proxy的配置,然后将这个配置通过Kubernetes API写到proxy的Pod中,然后reload.
注意:写入proxy 配置文件如 nginx.conf 的不是backend service的地址,而是backend service 的 pod 的地址,避免在 service 在增加一层负载均衡转发
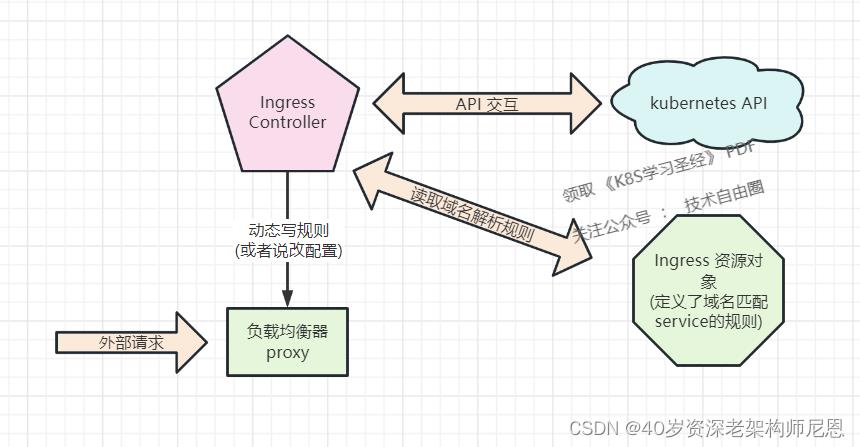
简而言之,ingress Controller借助service的服务发现机制,实现配置的动态更新以实现Pod的负载均衡机制实现,
由于涉及到proxy 的动态更新,目前社区Ingress Controller大体包含两种类型的控制器:
- 传统的七层负载均衡如Nginx,HAproxy,开发了适应微服务应用的插件,具有成熟,高性能等优点;
- 新型微服务负载均衡如Traefik,Envoy,Istio,专门适用于微服务+容器化应用场景,具有动态更新特点;
| 类型 | 常见类型 | 优点 | 缺点 |
|---|---|---|---|
| 传统负载均衡 | nginx,haproxy | 成熟,稳定,高性能 | 动态更新需reload配置文件 |
| 微服务负载均衡 | Traefik,Envoy,Istio | 天生为微服务而生,动态更新 | 性能还有待提升 |
如果公有云服务商能够提供该类型的HTTP路由LoadBalancer,则也可设置其为Ingress Controller。
Ingress 资源对象
ingress是一个API对象,通过yaml文件来配置,ingress对象的作用是定义请求如何转发到 backend service的规则,可以理解为配置模板。
ingress通过http或https暴露集群backend service,给backend service提供外部URI、负载均衡、SSL/TLS能力以及基于域名的反向代理。ingress要依靠ingress-controiler来具体实现以上功能。
简单来说,ingress-controller才是负责具体转发的组件,通过各种方式将它暴露在集群入口,外部对集群的请求流量会先到ingress-controller,而ingress对象是用来告诉ingress-controller该如何转发请求,比如哪些域名哪些path要转发到哪些服务等等。
Ingress 格式示例:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: abc-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
tls:
- hosts:
- api.abc.com
secretName: abc-tls
rules:
- host: api.abc.com
http:
paths:
- backend:
serviceName: apiserver
servicePort: 80
- host: www.abc.com
http:
paths:
- path: /image/*
backend:
serviceName: fileserver
servicePort: 80
- host: www.abc.com
http:
paths:
- backend:
serviceName: feserver
servicePort: 8080
每个 Ingress 都需要配置 rules,目前 Kubernetes 仅支持 http 规则。上面的示例表示请求/image/* 时转发到服务 fileserver的 80 端口。
与其他k8s对象一样,ingress配置也包含了apiVersion、kind、metadata、spec等关键字段。有几个关注的在spec字段中,tls用于定义https密钥、证书。rule用于指定请求路由规则。
这里值得关注的是metadata.annotations字段。在ingress配置中,annotations很重要。
前面有说ingress-controller有很多不同的实现,而不同的ingress-controller就可以根据 "kubernetes.io/ingress.class:" 来判断要使用哪些ingress配置,同时,不同的ingress-controller也有对应的annotations配置,用于自定义一些参数。
例如上面配置的\'nginx.ingress.kubernetes.io/use-regex: "true"\',最终是在生成nginx配置中,会采用location ~来表示正则匹配。
ingress-controller组件
ingress-controller是具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发。
ingress-controller并不是k8s自带的组件,实际上ingess-controller只是一个统称,用户可以选择不同的ingress-controller实现,
目前,由k8s维护的ingress-controller只有google云的GCE与ingress-nginx两个,其他还有很多第三方维护的ingress-controller,比如Contour, Haproxy, trafik, Istio,具体可以参考官方文档。
一般来说,ingress-controller的形式都是一个pod,里面跑着daemon程序和反向代理程序。
daemon负责不断监控集群的变化,根据ingress对象生成配置并应用新配置到反向代理,比如ingress-nginx就是动态生成nginx配置,动态更新upstreanm,并在需要的时候reload程序应用新配置。
为了方便,后面的例子都以k8s官方维护的ingress-nginx为例。
Ingress-Nginx github 地址: GitHub - kubernetes/ingress-nginx: Ingress-NGINX Controller for Kubernetes
Ingress-Nginx 官方网站: Welcome - NGINX Ingress Controller
nginx-ingress-controller
nginx-ingress-controller是一个使用Nginx来实现一个Ingress Controller,需要实现的基本逻辑如下。
- 监听API Server,获取全部Ingress的定义
- 基于Ingress的定义,生成Nginx所需的配置文件/etc/nginx/nginx.conf。
- 执行nginx -s reload命令,重新加载nginx.conf配置文件的内容。
部署ingress-controller
Minikube安装Ingress
Ingress安装很简单,Minikube里面带了Ingress附件。
- 安装Ingress
minikube addons enable ingress
- 禁用Ingress
minikube addons disable ingress
尼恩提示:
Minikube使用addon插件的模式安装Ingress很简单,但是,插件式部署是了解不到ingress 的底层原理
要了解 ingress 的底层原理, 还是得手工部署的模式。
手工部署ingress-controller pod及相关资源
官方文档中,部署ingress-nginx 只要简单的执行一个yaml
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.25.0/deploy/static/mandatory.yaml
上面的下载地址可能无法下载,可用国内的Gitee地址
cd /vagrant/chapter28/ingress
wget https://gitee.com/mirrors/ingress-nginx/raw/nginx-0.25.0/deploy/static/mandatory.yaml
wget https://gitee.com/mirrors/ingress-nginx/raw/nginx-0.30.0/deploy/static/mandatory.yaml
wget https://gitee.com/mirrors/ingress-nginx/raw/controller-v1.0.0/deploy/static/provider/cloud/deploy.yaml
下载之后,到了window本地,使用editplus就可编辑了
使用editplus打开mandatory.yaml,
mandatory.yaml文件中包含了很多资源的创建,包括namespace、ConfigMap、role,ServiceAccount等等所有部署ingress-controller需要的资源。
重点看下deployment部分:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
spec:
serviceAccountName: nginx-ingress-serviceaccount
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.25.0
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
可以看到主要使用了“quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.25.0”这个镜像,
并且deployment指定了一些启动参数。
同时开放了80与443两个端口,并在10254端口做了健康检查。
ingress版本的问题
网上的资料一般是基于v0.30.0来安装,但是对于kubernetes@1.22来说要安装ingress-nginx@v1.0.0以上版本(目前最新版本是v1.0.4,本文采用v1.0.0),
原因是 kubectl@v1.22版本不再支持v1beta1
如果安装ingress-nginx@v0.30.0版本后启动pod有如下问题
Failed to list *v1beta1.Ingress: the server could not find the requested resource
有一个版本的支持情况(https://github.com/kubernetes/ingress-nginx/)
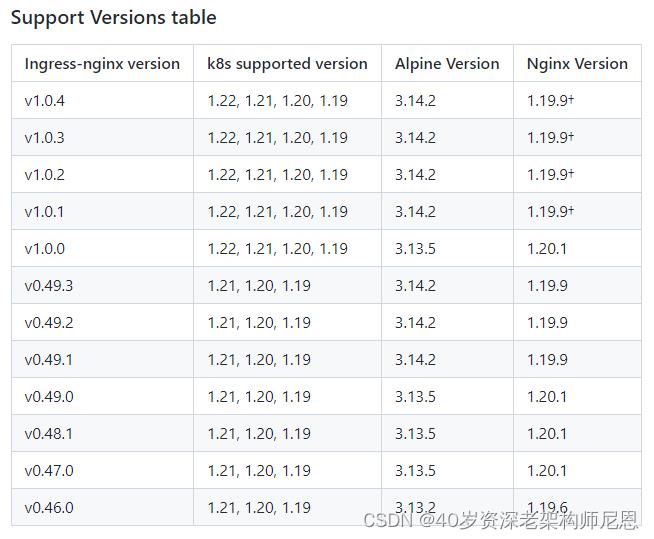
尼恩也是先用的 0.25,然后换成 0.30,再换成1.0.0
躺了很多的坑
调整RBAC api-versions 版本
早期版本:
RBAC相关资源从1.17版本开始改用rbac.authorization.k8s.io/v1,rbac.authorization.k8s.io/v1beta1在1.22版本即将弃用
查看 kubectl api-versions 版本
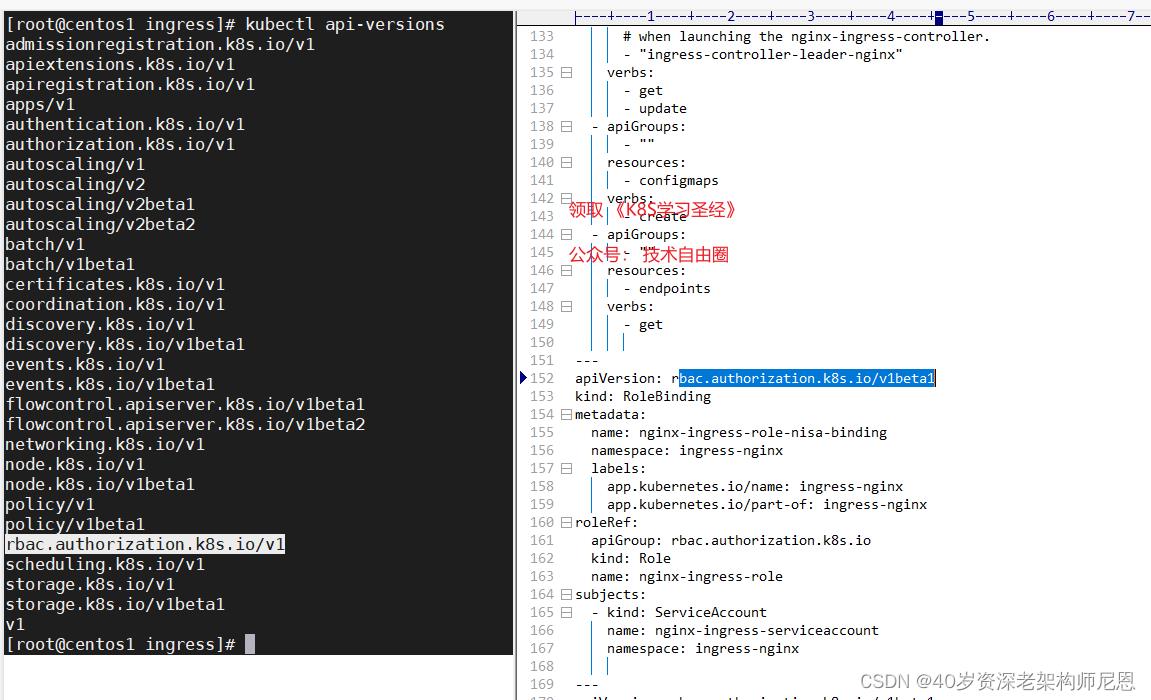
1.0.0的版本,不用改
部署 ingress-nginx
修改完后执行apply,并检查服务
kubectl apply -f deploy.yaml
kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
# 检查部署情况
kubectl get daemonset -n ingress-nginx
kubectl get po -n ingress-nginx -o wide
kubectl get svc -n ingress-nginx
kubectl logs -f nginx-ingress-controller-hrd46 -n ingress-nginx
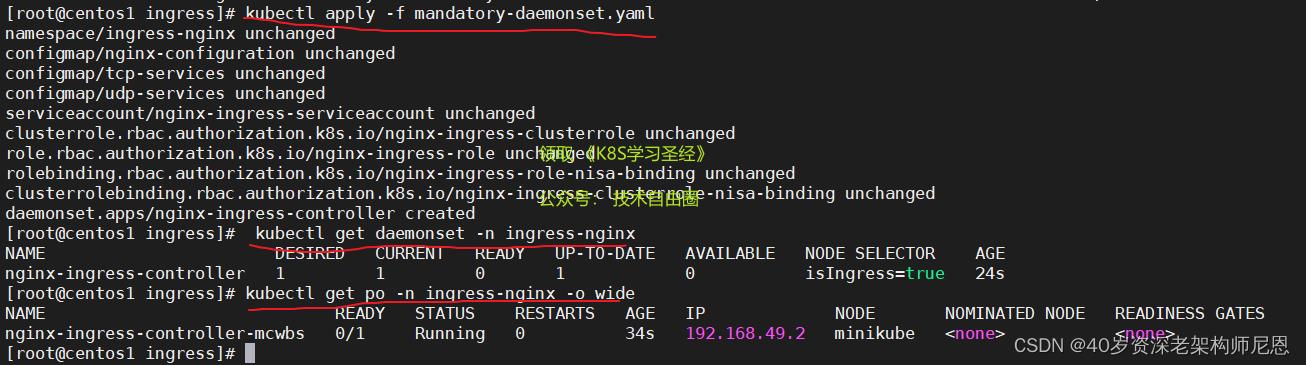
可以看到,nginx-controller的pod已经部署上了,但是没有启动。
换成最新版本,就启动啦
配置ingress资源
部署完ingress-controller,接下来就按照测试的需求来创建ingress资源。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-test
spec:
ingressClassName: nginx #指定Ingress 类
defaultBackend: #默认后端路由
service:
name: service1
port:
number: 8008
rules:
- host: "foo.bar.com" #主机精确匹配
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 8008
- host: "*.foo.com" #通配符匹配,bar.foo.com匹配,test.bar.foo.com不匹配
http:
paths:
- pathType: Prefix #以 / 分隔的 URL 路径前缀匹配,匹配区分大小写(必填)
path: "/foo"
backend:
service:
name: service2
port:
number: 9008
部署资源
kubectl apply -f app-service.yaml
curl http://192.168.49.2:30808/demo-provider/swagger-ui.html
kubectl apply -f app-service-2.yaml
curl http://192.168.49.2:30909/demo-provider/swagger-ui.html
kubectl apply -f ingresstest.yaml
kubectl delete -f ingresstest.yaml
curl http://10.100.15.33:30909/demo-provider/swagger-ui.html
curl http://10.100.15.33:30909/demo-provider/swagger-ui.html
kubectl get svc -A
curl http://foo.bar.com:32661/bar/
curl http://a.foo.com:32661/foo/
报错 failed calling webhook
Error from server (InternalError): error when creating "ingress-http.yaml": Internal error occurred: failed calling webhook "validate.nginx.ingress.kubernetes.io": failed to call webhook: Post "https://ingress-nginx-controller-admission.ingress-nginx.svc:443/networking/v1/ingresses?timeout=10s": x509: certificate signed by unknown authority
[root@k8s-master01 ~]# kubectl get -A ValidatingWebhookConfiguration
NAME WEBHOOKS AGE
ingress-nginx-admission 1 52m
[root@k8s-master01 ~]# kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
validatingwebhookconfiguration.admissionregistration.k8s.io "ingress-nginx-admission" deleted
[root@k8s-master01 ~]# kubectl apply -f ingresstest.yaml
再次创建就发现没有问题了
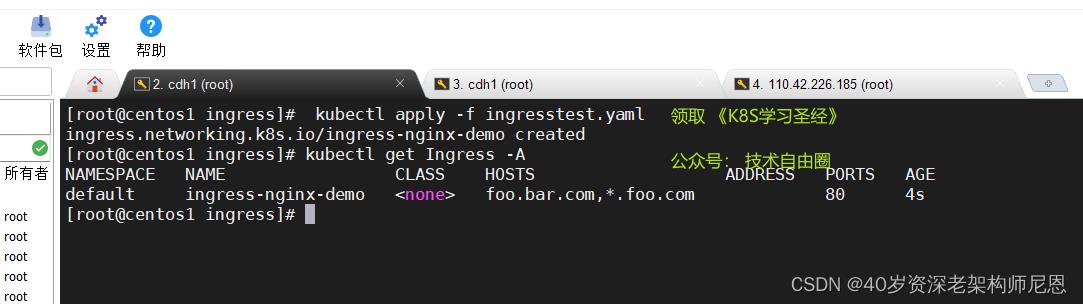
获取 ingress 启动的svc
kubectl get svc -A
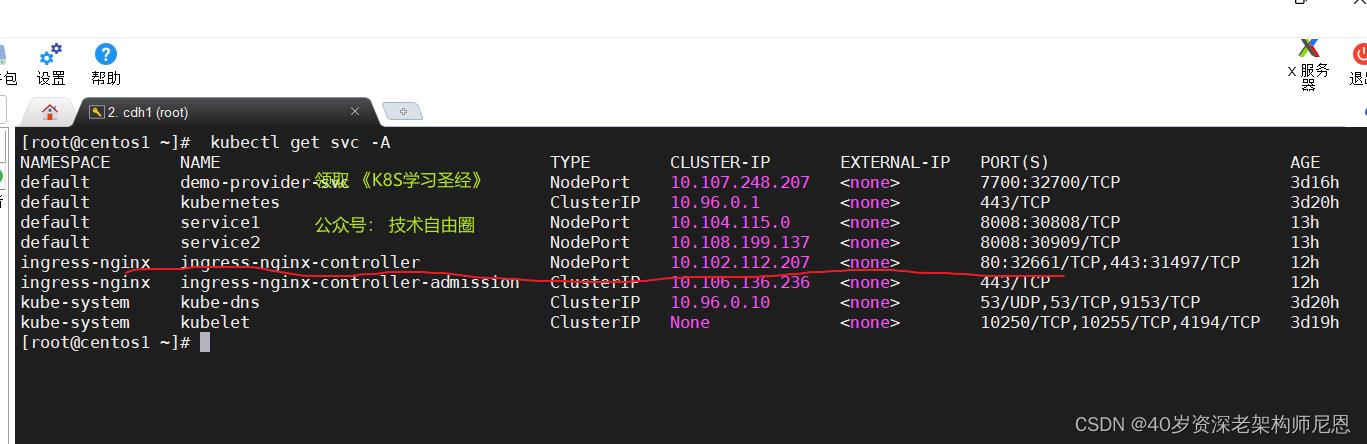
kubectl get svc -A
加上本地的host
部署好以后,做一条本地host来模拟解析 foo.bar.com 到node的ip地址。
echo 192.168.49.2 foo.bar.com >> /etc/hosts
echo 192.168.49.2 a.foo.com >> /etc/hosts
curl http://foo.bar.com/demo-provider/swagger-ui.html
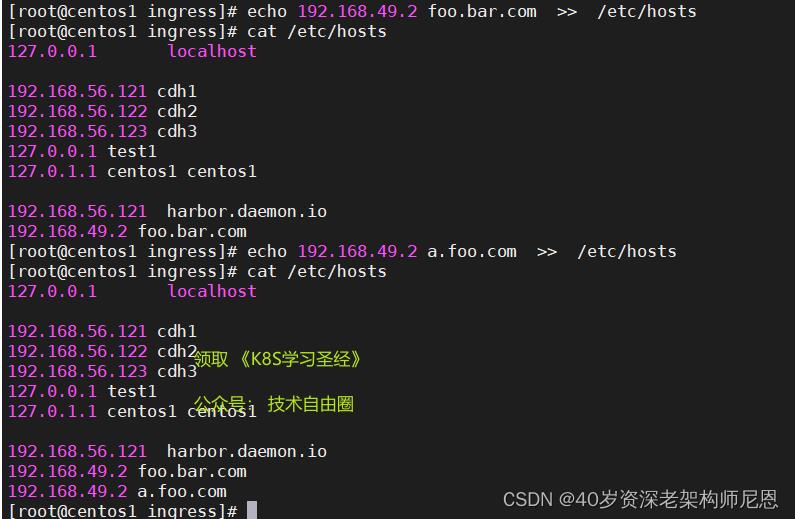
测试访问
curl http://foo.bar.com:32661/bar/
curl http://a.foo.com:32661/foo/
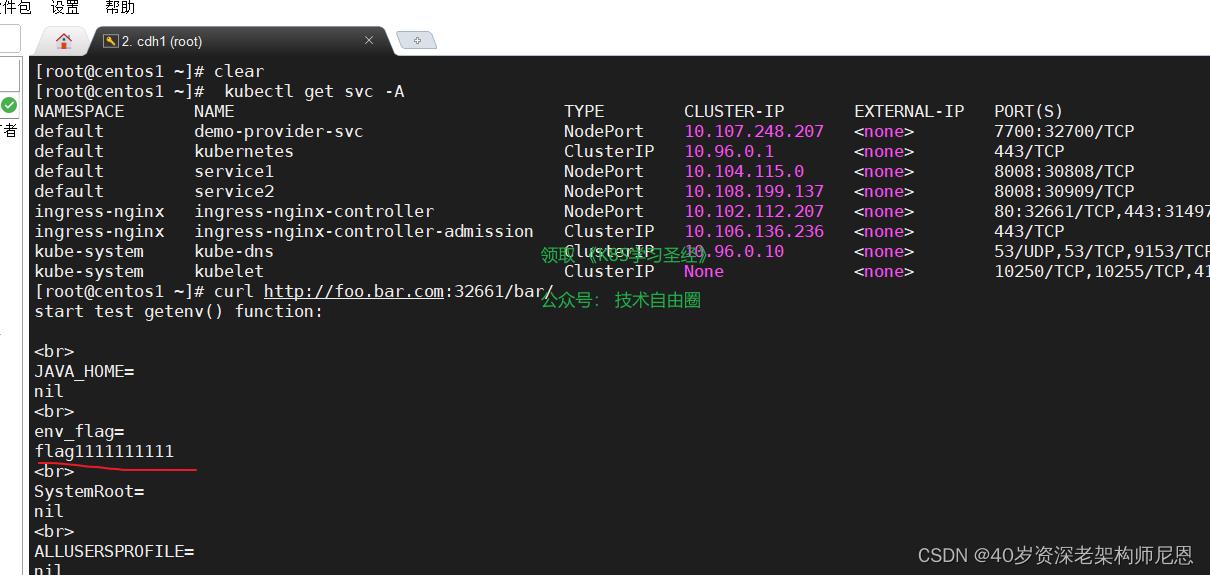
curl http://foo.bar.com:32661/bar/ ,
请求不同的path已经按照需求请求到不同服务了,这里是 请求到service1
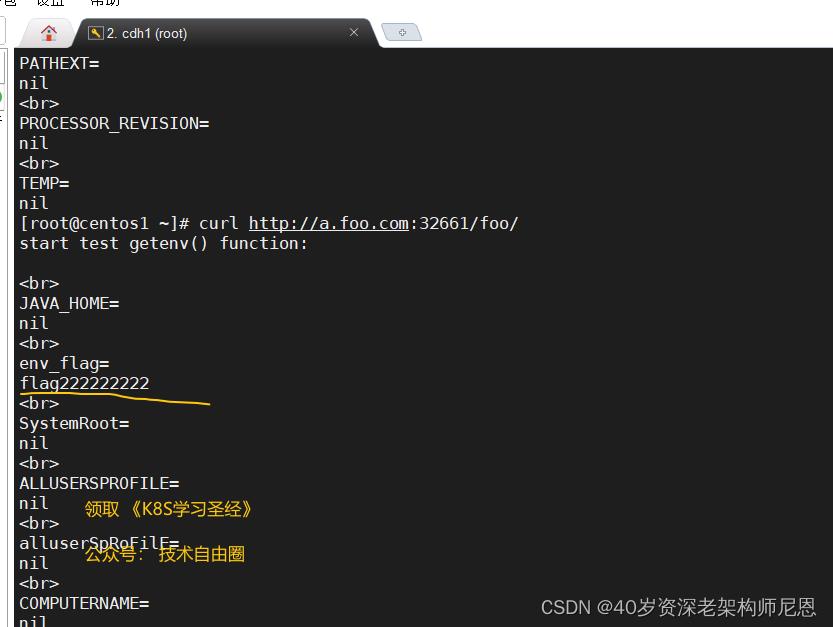
curl http://a.foo.com:32661/foo/
请求不同的path已经按照需求请求到不同服务了,这里是 请求到service2
如果没有路径, 则发生了404
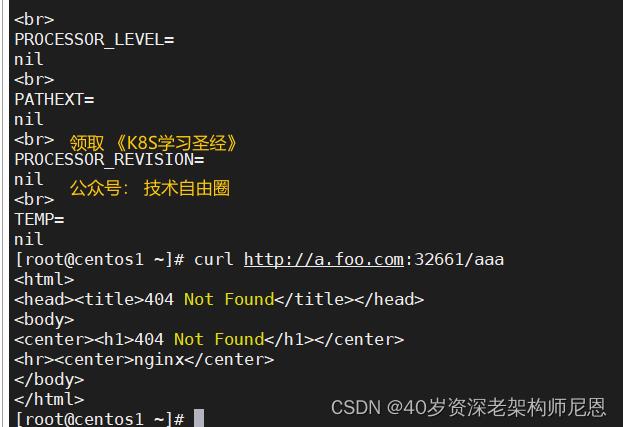
实操的善后工作
实验完成,可以清理所有服务
kubectl delete all -l app=my-app
kubectl delete all -l app=my-app-2
k8s ingress的工作原理
通过实操可以发现,k8s ingress的两大实操部分:
(1)Ingress Controller 控制器
(2)Ingress 资源对象
要理解ingress,需要区分两个概念,ingress和ingress-controller:
- ingress对象:
指的是k8s中的一个api对象,一般用yaml配置。作用是定义请求如何转发到service的规则,可以理解为配置模板。 - ingress-controller:
具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发。
简单来说,ingress-controller才是负责具体转发的组件,通过各种方式将它暴露在集群入口,外部对集群的请求流量会先到ingress-controller,而ingress对象是用来告诉ingress-controller该如何转发请求,比如哪些域名哪些path要转发到哪些服务等等。
(1)Ingress Controller 控制器
Ingress Controller实质上可以理解为是个监视器,
Ingress Controller通过不断地跟Kubernetes API Server打交道,实时的感知后端Service、Pod等变化,比如新增和减少Pod,Service增加与减少等;
当得到这些变化信息后,Ingress Controller在结合下文的Ingress生成配置,然后更新反向代理负载均衡器,并刷新其配置,达到服务发现的作用。
Ingress Controller是将Ingress这种变化生成一段Nginx的配置,然后将这个配置通过Kubernetes API写到Nginx的Pod中,然后reload.(注意:写入 nginx.conf 的不是service的地址,而是service backend 的 pod 的地址,避免在 service 在增加一层负载均衡转发)。
ingress-controller并不是k8s自带的组件,实际上ingress-controller只是一个统称,用户可以选择不同的ingress-controller实现,目前,由k8s维护的ingress-controller只有google云的GCE与ingress-nginx两个,其他还有很多第三方维护的ingress-controller,具体可以参考官方文档。
但是不管哪一种ingress-controller,实现的机制都大同小异,只是在具体配置上有差异。
一般来说,ingress-controller的形式都是一个pod,里面跑着daemon程序和反向代理程序。
daemon负责不断监控集群的变化,根据ingress对象生成配置并应用新配置到反向代理,比如nginx-ingress就是动态生成nginx配置,动态更新upstream,并在需要的时候reload程序应用新配置。为了方便,后面的例子都以k8s官方维护的nginx-ingress为例。
(2) Ingress 资源对象
Ingress简单理解就是个路由规则定义,
比如某个域名对应某个Serivce,即当某个域名的请求进来时转发给某个Service;
这个规则将与Ingress Controller结合,然后Ingress Controller将其动态写入到负载均衡器中,从而实现整体的服务发现和负载均衡。
Ingress解决的是新的服务加入后,域名和服务的对应问题,基本上是一个ingress的对象,通过yaml进行创建和更新进行加载。
从上图可以很清晰的看到,实际上请求进行被负载均衡器拦截,比如nginx,然后Ingress Controller通过交互得知某个域名对应哪个Service,再通过跟Kubernetes API交互得知Service地址等信息;
综合以后生成配置文件实时写入负载均衡器,然后负载均衡器reload该规则便可实现服务发现,即动态映射。
从上图中可以很清晰的看到,实际上请求进来还是被负载均衡器拦截,比如 nginx,然后 Ingress Controller 通过跟 Ingress 交互得知某个域名对应哪个 service,再通过跟 kubernetes API 交互得知 service 地址等信息;综合以后生成配置文件,实时写入负载均衡器,然后负载均衡器 reload 该规则便可实现服务发现,即动态映射:
- ingress-controller通过和 kubernetes APIServer交互,动态的去感知集群中ingress规则变化;
- 然后读取它,按照自定义的规则,规则就是写明了哪个域名对应哪个service,生成一段nginx配置;
- 再写到nginx-ingress-controller的pod里,这个ingres-controller的pod里运行着一个Nginx服务,控制器会把生成的nginx置写入/etc/nginx.conf文件中;
- 最后reload一下使配置生效。以此达到域名区分配置和动态更新的作用。
详解ingress资源
ingress是一个API对象,和其他对象一样,通过yaml文件来配置。
ingress通过http或https暴露集群内部service,给service提供外部URL、负载均衡、SSL/TLS能力以及基于host的方向代理。ingress要依靠ingress-controller来具体实现以上功能。前一小节的图如果用ingress来表示,大概就是如下配置:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: abc-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
tls:
- hosts:
- api.abc.com
secretName: abc-tls
rules:
- host: api.abc.com
http:
paths:
- backend:
serviceName: apiserver
servicePort: 80
- host: www.abc.com
http:
paths:
- path: /image/*
backend:
serviceName: fileserver
servicePort: 80
- host: www.abc.com
http:
paths:
- backend:
serviceName: feserver
servicePort: 8080
与其他k8s对象一样,ingress配置也包含了apiVersion、kind、metadata、spec等关键字段。
有几个关注的在spec字段中,tls用于定义https密钥、证书。rule用于指定请求路由规则。
这里值得关注的是metadata.annotations字段。
在ingress配置中,annotations很重要。
前面有说ingress-controller有很多不同的实现,
而不同的ingress-controller就可以根据"kubernetes.io/ingress.class:"来判断要使用哪些ingress配置,
同时,不同的ingress-controller也有对应的annotations配置,用于自定义一些参数。
列如上面配置的’nginx.ingress.kubernetes.io/use-regex: “true”’,最终是在生成nginx配置中,会采用location ~来表示正则匹配。
首先我们先看个简单的资源示例。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-nginx
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 8008
与所有其他 Kubernetes 资源一样,Ingress 需要使用 apiVersion、kind 和 metadata 字段。
Ingress 对象的命名必须是合法的DNS子域名名称。
ingress规约提供了配置负载均衡器或者代理服务器所需的所有信息。 最重要的是,其中包含与所有传入请求匹配的规则列表。
Ingress 资源仅支持用于转发 HTTP 流量的规则。
ingress规则
每个 HTTP 规则都包含:
- 可选的
host。在此示例中,未指定host,因此该规则适用于通过指定 IP 地址的所有入站 HTTP 通信。 如果提供了host(例如 foo.bar.com),则rules适用于该host。- 路径列表 paths(例如,
/testpath),每个路径都有一个由serviceName和servicePort定义的关联后端。 在负载均衡器将流量定向到引用的服务之前,主机和路径都必须匹配传入请求的内容。backend(后端)是Service文档中所述的服务和端口名称的组合。 与规则的host和path匹配的对 Ingress 的 HTTP(HTTPS )请求发送到列出的backend。
通常在 Ingress 控制器中会配置 defaultBackend(默认后端),服务不符合任何规约中 path 的请求。
DefaultBackend
没有 rules 的 Ingress 将所有流量发送到同一个默认后端。
defaultBackend 通常是ingress控制器的配置选项,而非在 Ingress 资源中指定。如果 hosts 或 paths 都没有与 Ingress 对象中的 HTTP 请求匹配,则流量将路由到默认后端
资源后端
resource 后端是一个 ObjectRef,指向同一名字空间中的另一个 Kubernetes,将其作为 Ingress 对象。Resource 与 Service 配置是互斥的,在 二者均被设置时会无法通过合法性检查。
Resource 后端的一种常见用法是将所有入站数据导向带有静态资产的对象存储后端。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
defaultBackend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: static-assets
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
路径类型
Ingress 中的每个路径都需要有对应的路径类型(Path Type)。
未明确设置 pathType 的路径无法通过合法性检查。当前支持的三种路径类型:
ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的pathType处理或者与Prefix或Exact类型作相同处理。Exact:精确匹配 URL 路径,且区分大小写。Prefix:基于以/分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。 路径元素指的是由/分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。注意:如果路径的最后一个元素是请求路径中最后一个元素的子字符串,则不会匹配 (例如:
/foo/bar匹配/foo/bar/baz, 但不匹配/foo/barbaz)。
路径类型示例
| 类型 | 路径 | 请求路径 | 匹配与否? |
|---|---|---|---|
| Prefix | / |
(所有路径) | 是 |
| Exact | /foo |
/foo |
是 |
| Exact | /foo |
/bar |
否 |
| Exact | /foo |
/foo/ |
否 |
| Exact | /foo/ |
/foo |
否 |
| Prefix | /foo |
/foo, /foo/ |
是 |
| Prefix | /foo/ |
/foo, /foo/ |
是 |
| Prefix | /aaa/bb |
/aaa/bbb |
否 |
| Prefix | /aaa/bbb |
/aaa/bbb |
是 |
| Prefix | /aaa/bbb/ |
/aaa/bbb |
是,忽略尾部斜线 |
| Prefix | /aaa/bbb |
/aaa/bbb/ |
是,匹配尾部斜线 |
| Prefix | /aaa/bbb |
/aaa/bbb/ccc |
是,匹配子路径 |
| Prefix | /aaa/bbb |
/aaa/bbbxyz |
否,字符串前缀不匹配 |
| Prefix | /, /aaa |
/aaa/ccc |
是,匹配 /aaa 前缀 |
| Prefix | /, /aaa, /aaa/bbb |
/aaa/bbb |
是,匹配 /aaa/bbb 前缀 |
| Prefix | /, /aaa, /aaa/bbb |
/ccc |
是,匹配 / 前缀 |
| Prefix | /aaa |
/ccc |
否,使用默认后端 |
| 混合 | /foo (Prefix), /foo (Exact) |
/foo |
是,优选 Exact 类型 |
路径多重匹配
在某些情况下,Ingress 中的多条路径会匹配同一个请求。
这种情况下最长的匹配路径优先。
如果仍然有两条同等的匹配路径,则精确路径类型优先于前缀路径类型。
主机名通配符
主机名可以是精确匹配(例如“foo.bar.com”)或者使用通配符来匹配 (例如“*.foo.com”)。
精确匹配要求 HTTP host 头部字段与 host 字段值完全匹配。
通配符匹配则要求 HTTP host 头部字段与通配符规则中的后缀部分相同。
| 主机 | host 头部 | 匹配与否? |
|---|---|---|
*.foo.com |
bar.foo.com |
基于相同的后缀匹配 |
*.foo.com |
baz.bar.foo.com |
不匹配,通配符仅覆盖了一个 DNS 标签 |
*.foo.com |
foo.com |
不匹配,通配符仅覆盖了一个 DNS 标签 |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-nginx-demo
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: "foo.bar.com" #主机精确匹配
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 8008
- host: "*.foo.com" #通配符匹配,bar.foo.com匹配,test.bar.foo.com不匹配
http:
paths:
- pathType: Prefix #以 / 分隔的 URL 路径前缀匹配,匹配区分大小写(必填)
path: "/foo"
backend:
service:
name: service2
port:
number: 8008
ingress类
Ingress 可以由不同的控制器实现,不同的控制器 通常使用不同的配置。
每个 Ingress 应当指定一个类,也就是一个对 IngressClass 资源的引用。
IngressClass 资源包含额外的配置,其中包括应当实现该类的控制器名称。
# Source: ingress-nginx/templates/controller-ingressclass.yaml
# We don\'t support namespaced ingressClass yet
# So a ClusterRole and a ClusterRoleBinding is required
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
helm.sh/chart: ingress-nginx-4.0.15
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 1.1.1
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: nginx
namespace: ingress-nginx
spec:
controller: k8s.io/ingress-nginx
IngressClass 资源包含可选的 parameters 字段,可用于为该类引用额外的、 特定于具体实现的配置。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
参数(parameters)的具体类型取决于你在 .spec.controller 字段中指定的 Ingress 控制器.
名字空间域的参数
parameters 字段中scope 和 namespace 字段,可用来引用特定 于名字空间的资源,对 Ingress 类进行配置。
scope 字段默认为 Cluster,表示默认是集群作用域的资源。
将 scope 设置为 Namespace 并设置 namespace 字段就可以引用某特定 名字空间中的参数资源。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
namespace: external-configuration
scope: Namespace
默认ingress类
可以将一个特定的 IngressClass 标记为集群默认 Ingress 类。
将 IngressClass 资源的 ingressclass.kubernetes.io/is-default-class 注解设置为 true 将确保新的未指定 ingressClassName 字段的 Ingress 能够分配为这个默认的 IngressClass.
注意: 如果集群中有多个 IngressClass 被标记为默认,准入控制器将阻止创建新的未指定
ingressClassName的 Ingress 对象。解决这个问题只需确保集群中最多只能有一个 IngressClass 被标记为默
ingress部署的三种模式
ingress的部署,需要考虑两个方面:
- ingress-controller是作为pod来运行的,以什么方式部署比较好
- ingress解决了把如何请求路由到集群内部,那它自己怎么暴露给外部比较好
模式一:NodePort模式的Service
同样用deployment模式部署ingress-controller,并创建type为NodePort的服务。
这样,ingress就会暴露在集群节点ip的特定端口上。
由于nodeport暴露的端口是随机端口,一般会在前面,再搭建一套负载均衡器来转发请求。
该方式一般用于宿主机是相对固定的环境ip地址不变的场景。
NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响。
模式二:DaemonSet+nodeSelector+HostNetwork
用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,
然后使用HostNetwork直接把该pod与宿主机node的网络打通,直接使用宿主机的80/433端口就能访问服务。
这时,ingress-controller的node机器就很类似传统架构的边缘节点,比如机房入口的nginx服务器。
该方式整个请求链路最简单,性能相对NodePort模式更好。
缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。
比较适合大并发的生产环境使用。
模式三:Deployment+LoadBalancer模式的Service
如果要把ingress部署在公有云,那用这种方式比较合适。
用Deployment部署ingress-controller,创建一个type为LoadBalancer的service关联这组pod。
大部分公有云,都会为LoadBalancer的service自动创建一个负载均衡器,通常还绑定了公网地址。
只要把域名解析指向该地址,就实现了集群服务的对外暴露。
模式一的问题:service暴露服务的问题
但是,单独用service暴露服务的方式,在实际生产环境中不太合适
ClusterIP的方式只能在集群内部访问。
NodePort方式的话,测试环境使用还行,当有几十上百的服务在集群中运行时,NodePort的端口管理是灾难。
LoadBalance方式受限于云平台,且通常在云平台部署ELB还需要额外的费用。
生产环境,推荐模式二。
云服务器环境,推荐模式三。
DaemonSet+HostNetwork+nodeselector 实操
首先来看看 nodePort的NAT性能问题
nodePort的NAT性能问题
采用 NodePort 方式暴露服务面临问题是,服务一旦多起来,NodePort 在每个节点上开启的端口会及其庞大,而且难以维护;
这时,如果使用一个ingress直接对内进行转发,ingress的流量是很大的
NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响
众所周知的是,Pod是可以共享宿主机的网络名称空间的,也就是说当在共享网络名称空间时,Pod上所监听的就是Node上的端口。
那么这又该如何实现呢?
简单的实现就是使用 DaemonSet 在每个 Node 上监听 80端口,然后写好规则,
因为 ingress 外面绑定了宿主机 80 端口,本身又在集群内,那么向后直接转发到相应Service IP就行了,不需要进行nat 了。
如下图所示:
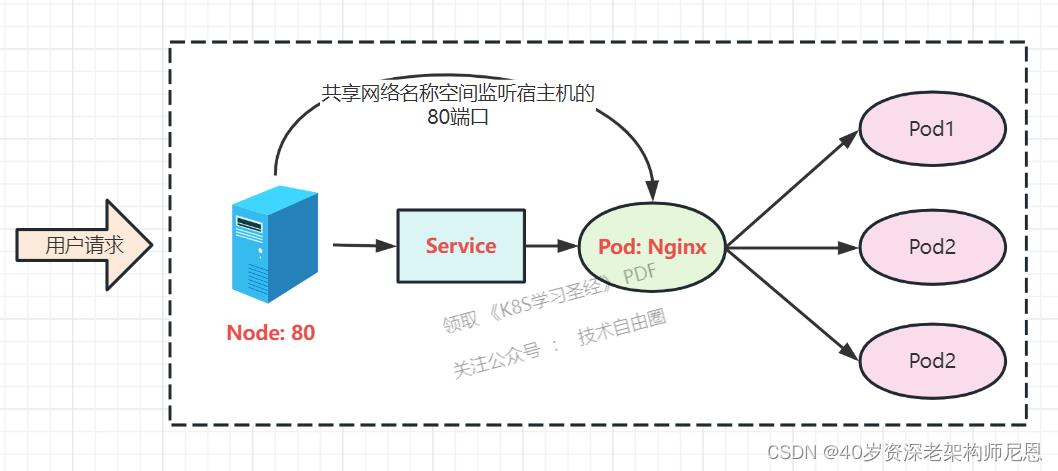
指定nginx-ingress-controller运行的node节点
这里使用daemonset+hostNetwork 模式部署,并且部署到特定node,
DaemonSet:守护进程控制器
DaemonSet 也是 Kubernetes 提供的一个 default controller,它实际是做一个守护进程的控制器,它能帮我们做到以下几件事情:
(1)首先能保证集群内的每一个节点都运行一组相同的 pod;
(2)同时还能根据节点的状态保证新加入的节点自动创建对应的 pod;
(3)在移除节点的时候,能删除对应的 pod;
(4)而且它会跟踪每个 pod 的状态,当这个 pod 出现异常、Crash 掉了,会及时地去 recovery 这个状态。
daemonset与deployment非常相似,区别是不需要设置replicas,因为daemonset是每节点启动的
首先,需要修改node的部分配置
先给要部署nginx-ingress的node打上特定标签,这里测试部署在"minikube"这个节点。
kubectl label node node-** isIngress="true"

在正式环境下,也是类似的,比如部署在 node02
kubectl get node
kubectl label node node02 ingress=true
kubectl get nodes --show-labels
kubectl delete -f ingresstest.yaml
kubectl delete -f deploy.yaml
修改Deployment为Daemonset,指定节点运行,并开启 hostNetwork
vim mandatory.yaml
...
apiversion: apps/vl
kind: Daemonset #修改kind
...
hostNetwork: true #使用主机网络
nodeSelector:
ingress: "true" #选择节点运行
...
复制一份,改为deploy-daemonset.yaml,然后修改上面的deployment部分配置为daemonset:
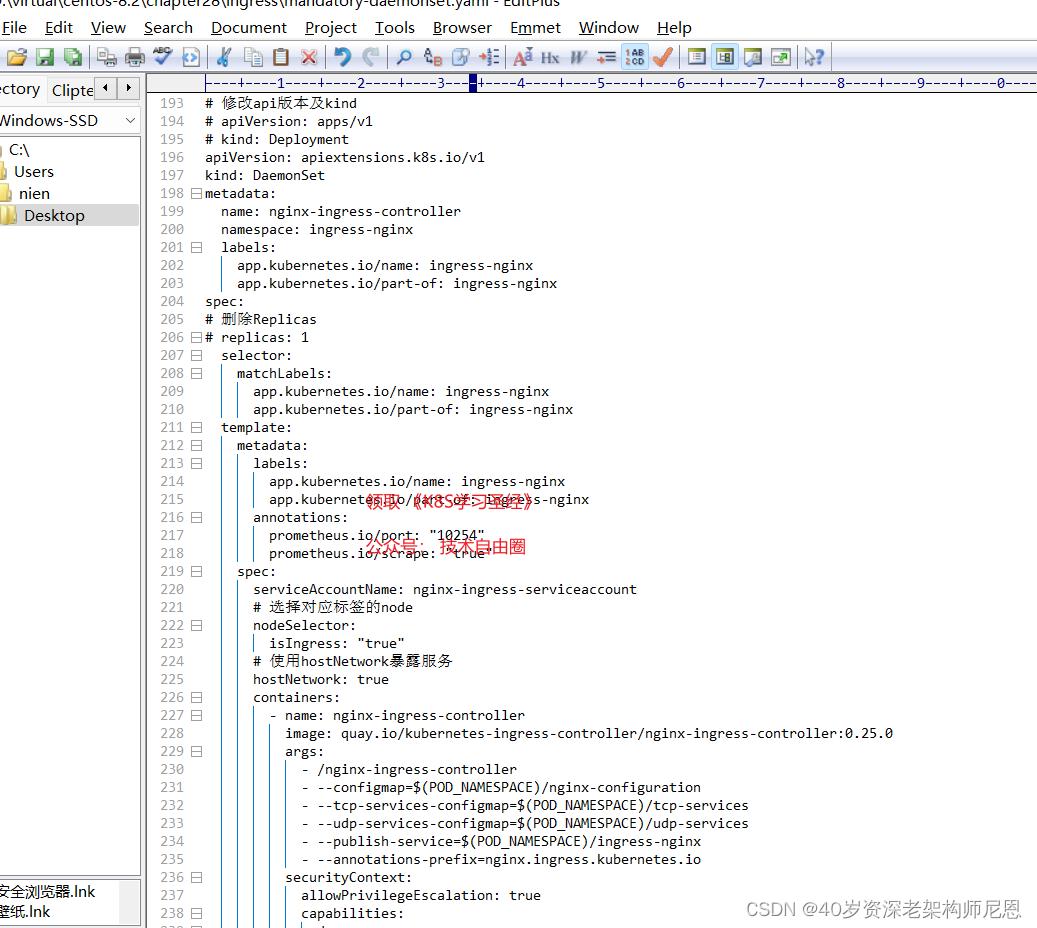
# 修改api版本及kind
# apiVersion: apps/v1
# kind: Deployment
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
# 删除Replicas
# replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
spec:
serviceAccountName: nginx-ingress-serviceaccount
# 选择对应标签的node
nodeSelector:
isIngress: "true"
# 使用hostNetwork暴露服务
hostNetwork: true
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.25.0
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
- kind: DaemonSet:官方原始文件使用的是deployment,replicate 为 1,这样将会在某一台节点上启动对应的nginx-ingress-controller pod。外部流量访问至该节点,由该节点负载分担至内部的service。测试环境考虑防止单点故障,改为DaemonSet然后删掉replicate ,配合亲和性部署在制定节点上启动nginx-ingress-controller pod,确保有多个节点启动nginx-ingress-controller pod,后续将这些节点加入到外部硬件负载均衡组实现高可用性。
- hostNetwork: true:添加该字段,暴露nginx-ingress-controller pod的服务端口(如9118)
- nodeSelector: 增加亲和性部署,有isIngress: "true"标签的节点才会部署该DaemonSet
启动nginx-ingress-controller
#主节点
kubectl delete -f deploy-daemonset.yaml
kubectl apply -f deploy-daemonset.yaml
kubectl logs -f nginx-ingress-controller-hrd46 -n ingress-nginx
kubernetes "hostNetwork: true",这是一种直接定义Pod网络的方式。
如果在POD中使用"hostNetwork: true"配置网络,pod中运行的应用程序可以直接看到宿主主机的网络接口,宿主机所在的局域网上所有网络接口都可以访问到该应用程序及端口。
hostNetwork: true
# 使用主机网络
dnsPolicy: ClusterFirstWithHostNet
# 该设置是使POD使用k8s的dns,dns配置在/etc/resolv.conf文件中
# 如果不加,pod默认使用所在宿主主机使用的DNS,这样会导致容器
# 内不能通过service name访问k8s集群中其他POD
另外: HostNetwork 模式不需要创建service
查看pod的IP和端口
kubectl describe pod ingress-nginx-controller-nvrrq -n ingress-nginx
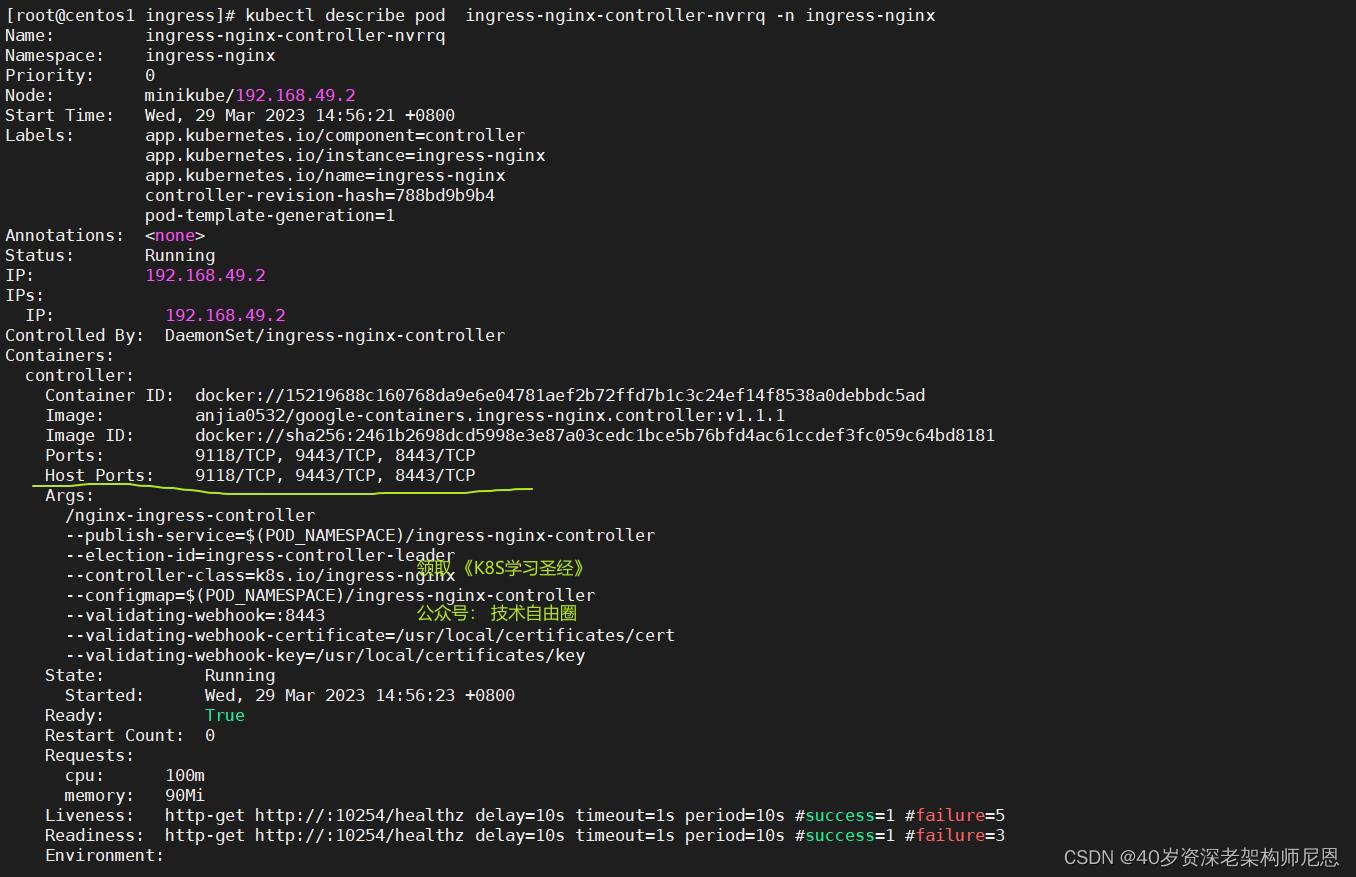
可以使用下面的命令,查看端口:
netstat -natp | grep nginx
由于配置了hostnetwork, nginx已经在 node主机本地监听团9118/9443/8443端口。
其中 9118是nginx-controller默认配置的一个defaultbackend (Ingress资源没有匹配的 rule 对象时,流量就会被导向这个default backend
这样,只要访问 node主机有公网 TP,就可以直接映射域名来对外网暴露服务了。
如果要nginx高可用的话,可以在多个node上部署,并在前面再搭建一套LVS+keepalive做负载均衡。
配置ingress资源
部署完ingress-controller,接下来就按照测试的需求来创建ingress资源。
kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
kubectl apply -f ingresstest-one.yaml
kubectl delete -f ingresstest-one.yaml
kubectl get svc -A
curl http://a.foo.com:30909/foo/
curl http://foo.bar.com:30808/demo-provider/swagger-ui.html
curl http://foo.bar.com:9118/bar/
curl http://a.foo.com:9118/foo/
查看日志
kubectl logs -f ingress-nginx-controller-nvrrq -n ingress-nginx
命令清单
#主节点
kubectl delete -f deploy-daemonset.yaml
kubectl apply -f deploy-daemonset.yaml
kubectl get pod -n ingress-nginx -o wide
# 检查部署情况
kubectl get daemonset -n ingress-nginx
kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
kubectl get po -n ingress-nginx -o wide
kubectl get po -A
kubectl get svc -n ingress-nginx
kubectl logs -f ingress-nginx-controller-j4cq4 -n ingress-nginx
kubectl describe pod ingress-nginx-controller-j4cq4 -n ingress-nginx
echo 192.168.49.2 foo.bar.com >> /etc/hosts
echo 192.168.49.2 a.foo.com >> /etc/hosts
查看日志
kubectl logs -n ingress-nginx -f
kubectl logs -f ingress-nginx-controller-nvrrq -n ingress-nginx
生产环境 LVS+keepalive 做高可用和负载均衡
为了配置kubernetes中的ingress的高可用,对于kubernetes集群以外只暴露一个访问入口,需要使用keepalived排除单点问题。需要使用daemonset方式将ingress-controller部署在边缘节点上。
边缘节点
首先解释下什么叫边缘节点(Edge Node),所谓的边缘节点即集群内部用来向集群外暴露服务能力的节点,
集群外部的服务通过边缘节点(Edge Node)来调用集群内部的服务,
边缘节点是集群内外交流的一个Endpoint。
边缘节点要考虑两个问题
- 边缘节点的高可用,不能有单点故障,否则整个kubernetes集群将不可用
- 对外的一致暴露端口,即只能有一个外网访问IP和端口
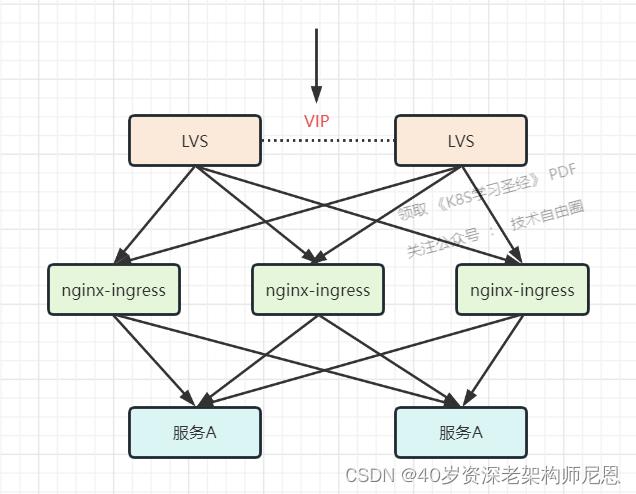
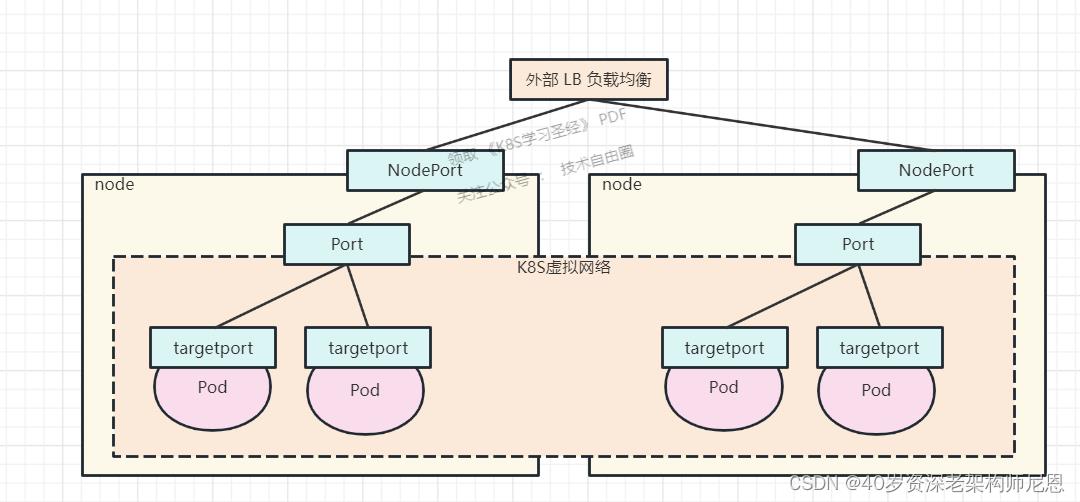
生产环境可以使用 HA + LB + DaemonSet hostNetwork 架构
为了满足边缘节点的高可用需求,我们使用keepalived来实现。
在Kubernetes中添加了ingress后,在DNS中添加A记录,域名为你的ingress中host的内容,IP为你的keepalived的VIP,这样集群外部就可以通过域名来访问你的服务,也解决了单点故障。
选择Kubernetes的三个node作为边缘节点,并在前面再搭建一套LVS+keepalive做负载均衡。
在 k8s 前面部署 lvs, 并且使用 DR 模式, 解决单个 nginx-ingress 会成为性能瓶颈问题,
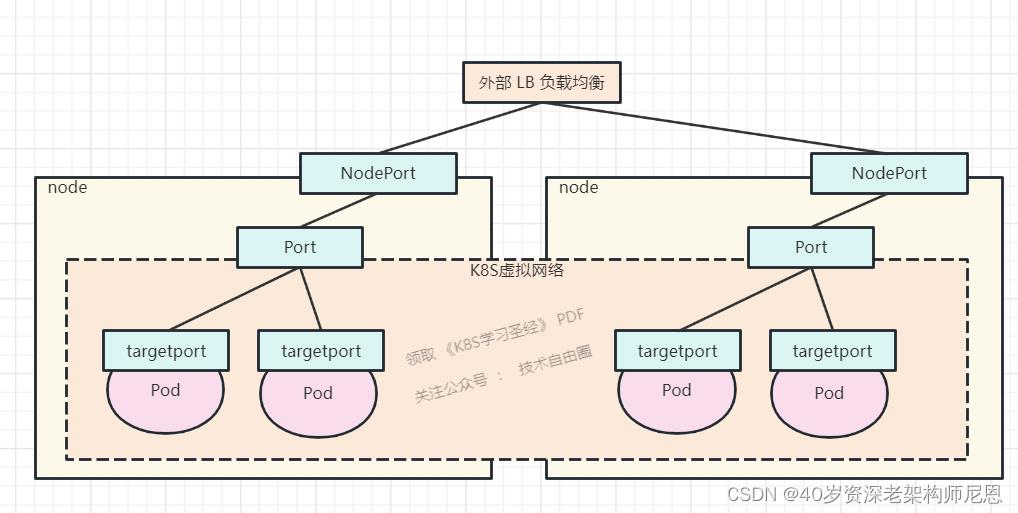
如图
四种port底层原理:nodePort、port、targetPort、containerPort 的核心
在尼恩的 读者群(50+)中,大家对K8S的四大Port 有很多的理解误区。
基于咱们的K8S学习圣经,把四种port底层原理介绍一下:nodePort、port、targetPort、containerPort
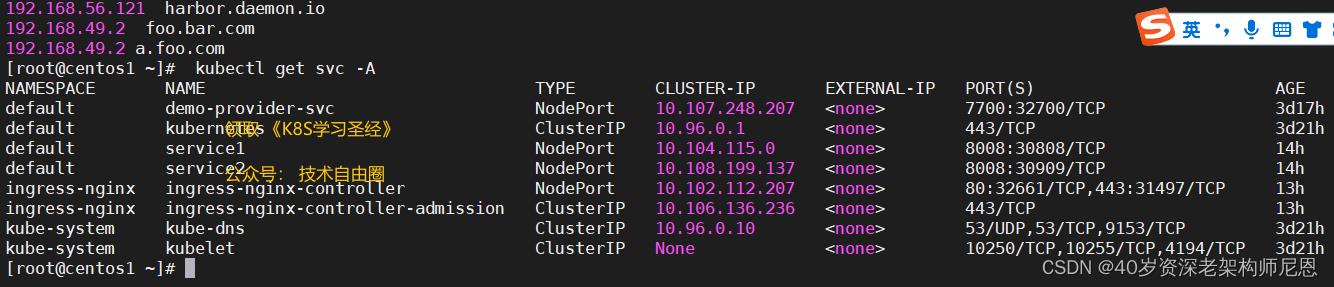
1、nodePort
nodePort提供了集群外部客户端访问service的一种方式,nodePort提供了集群外部客户端访问service的端口,即nodeIP:nodePort提供了外部流量访问k8s集群中service的入口。
比如外部用户要访问k8s集群中的一个Web应用,那么我们可以配置对应service的type=NodePort,nodePort=30082。
其他用户就可以通过浏览器http://node:30082访问到该web服务。
而这里的nodeIP,是pod启动所在的node 机器。
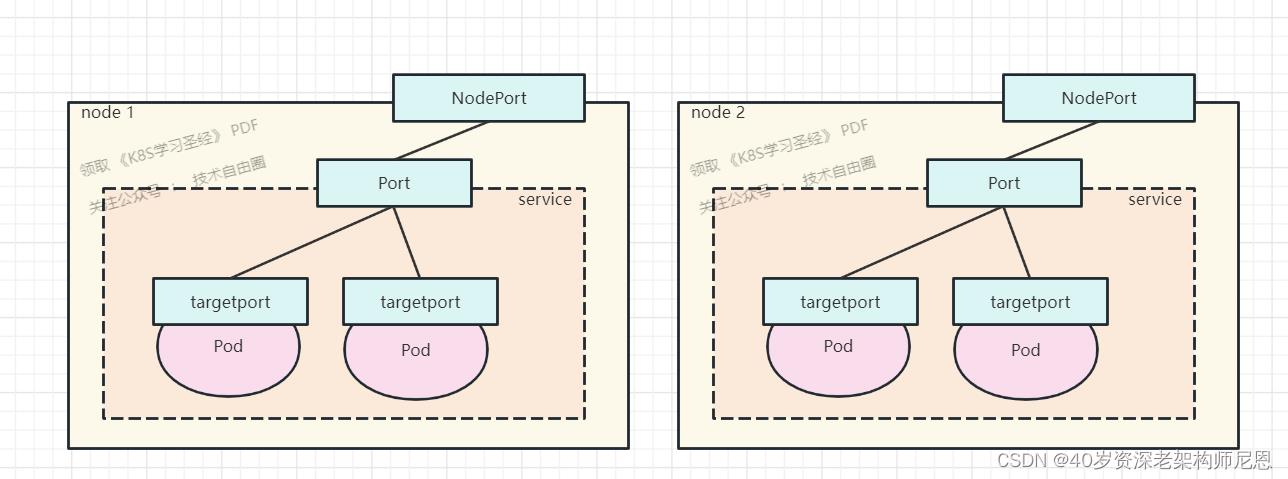
在咱们的ingress 测试中,node 机器 ip 是 192.168.49.2 ,
ingress 开启的node port 为 32661
ingress 的svc服务暴露了8008端口(参考前面的配置文件),
集群内其他容器通过8008端口访问ingress 的svc服务,但是外部流量不能通过该端口访问ingress 的svc服务,因为外部服务,访问不到这个 IP 10.102.112.207
这个ip 是 K8S管理的虚拟网络IP, 这个网络是跨 物理机器的,跨node节点, 一个统一的虚拟网络
外部的流量不能访问这个虚拟网络, 怎么办呢,需要配置NodePort访问,
NodePort 需要通过 完成NAT 转换, 转换成 10.102.112.207 虚拟IP,再通过svc的路由机制 kube-proxy +路由表 结合,路由到正确的POD。
2、port
port是暴露在cluster ip上的端口,port提供了集群内部客户端访问service的入口,即clusterIP:port。
对应的service.yaml如下:
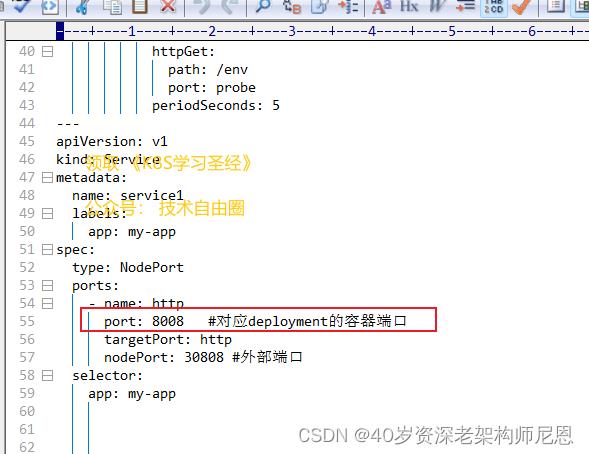
相当于在虚拟网络上开的端口,一般和 pod的 targetPort 端口,保持一致。
3、targetPort
targetPort是pod上的端口,
从nodePort-》上来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器。
targetPort与制作容器时暴露的端口一致(使用DockerFile中的EXPOSE),例如官方的nginx(参考DockerFile)暴露8008端口。
我们这里设置为web服务端口8008。
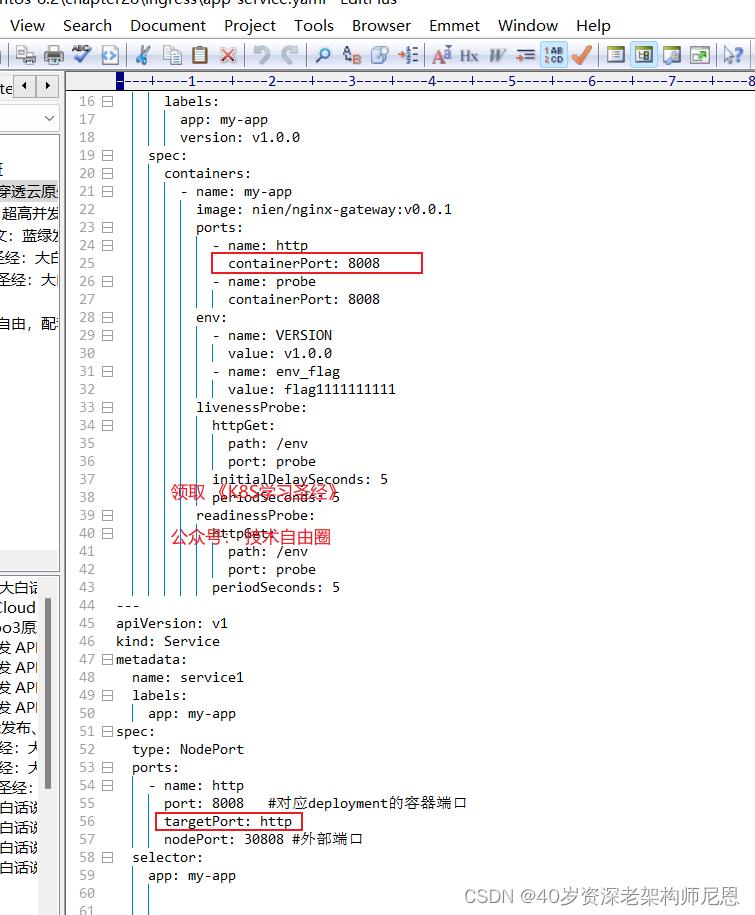
4、containerPort
containerPort是在pod控制器中定义的、pod中的容器需要暴露的端口。如spring boot的8080,mysql的3306等。咱们实例当中的web服务端口8008。
该端口只是起到specification作用,哪怕不在yaml中定义,也是可以通过nodePort->targetPort的流向(外部)或者port->targetPort流向(内部)进行访问。
如果设置的话,也是设置为docker镜像的暴露端口。
需要注意的,nodePort的使用只是实验性质,如果在生产环境上通过通过nginx等反向代理工具去管理nodePort绝对是灾难性的。
更多是需要通过外部LoadBalancer或者ingress去做管理。
Ingress 动态域名配置底层原理
问题:当每次有新服务加入,Ingress 又该如何修改 Nginx 配置呢?
回到 Nginx的原理,Nginx可以通过虚拟主机域名进行区分不同的服务,而
以上是关于Go学习圣经:队列削峰+批量写入 超高并发原理和实操的主要内容,如果未能解决你的问题,请参考以下文章
调优圣经:零基础精通Jmeter分布式压测,10Wqps+超高并发