0002.统计描述分析 Posted 2023-05-25 lxinghua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0002.统计描述分析相关的知识,希望对你有一定的参考价值。
描述统计分析是进行其他统计分析的基础和前提。在描述性分析中,通过各种统计图及数字特征量尅对样本来自的总体特征有比较准确的把握,从而选择正确的推断方法。
一、 频数分布分析(Frequencies)
基本概念:频数分布分析主要通过频数分布表、条图和直方图,以及集中趋势和离散趋势的各种统计量,描述数据的分布特征。
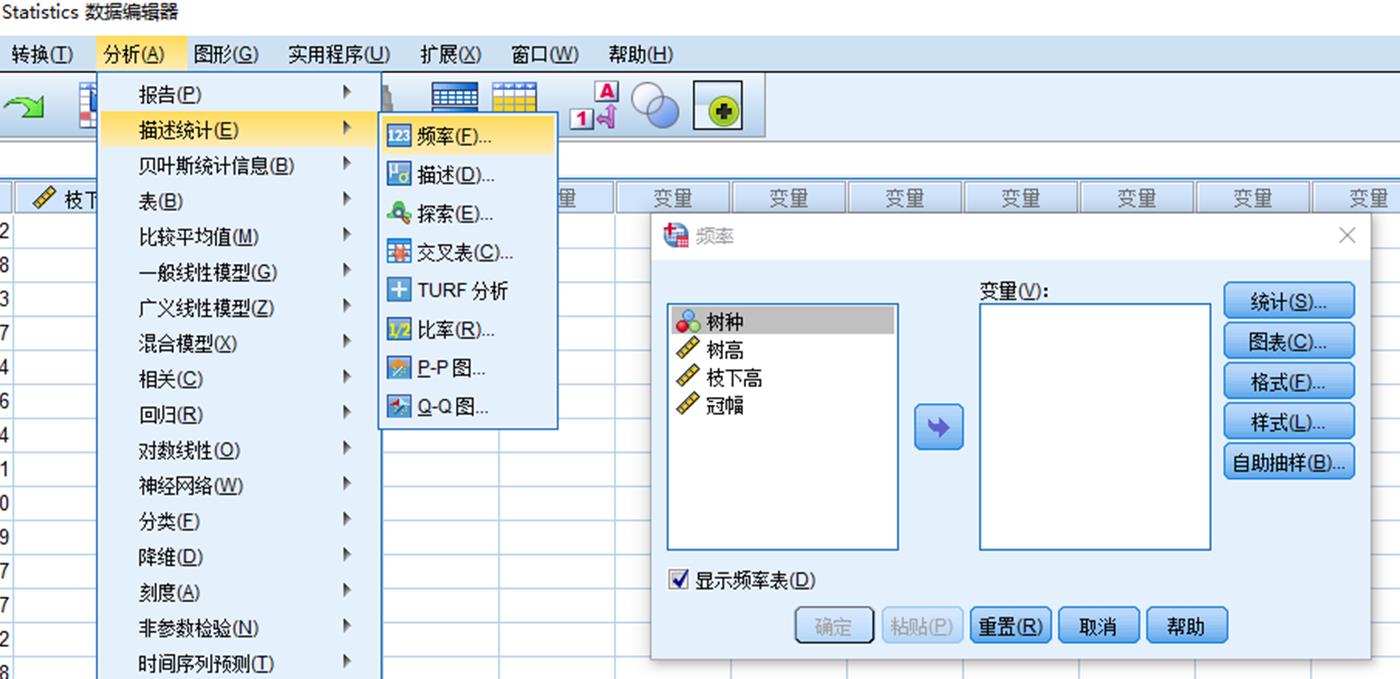
通过 分析>描述统计>频率 路径进入频率统计主对话框
1. 在频率统计主对话框中点击统计即可进入统计量对话框,针对需求进行各项目勾选即可
2. 在频率统计主对话框中点击图表即可进入图表对话框,针对统计数据选择需求图表即可
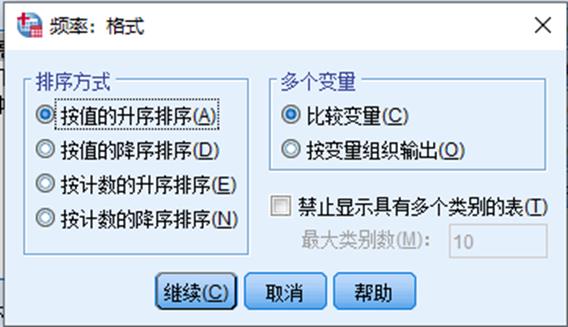
3. 在频率统计主对话框中点击格式即可进入格式对话框,针对统计数据选择需求输出格式即可
① 排序方式,按需求选择即可
② 多个变量:比较变量为将所有变量的描述统计的结果显示在同一张表格中;按变量组织输出为每个变量分别输出单独的描述统计表格
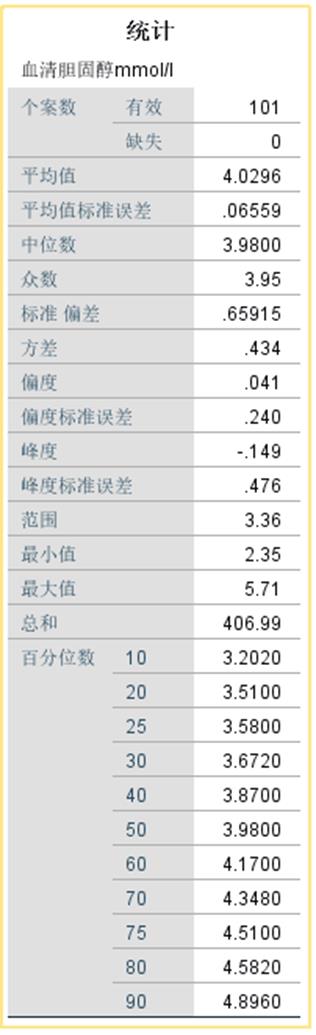
案例:从某单位职工体检资料中获得101名正常成年女子的血清总胆固醇(mmol/L)的测量结果
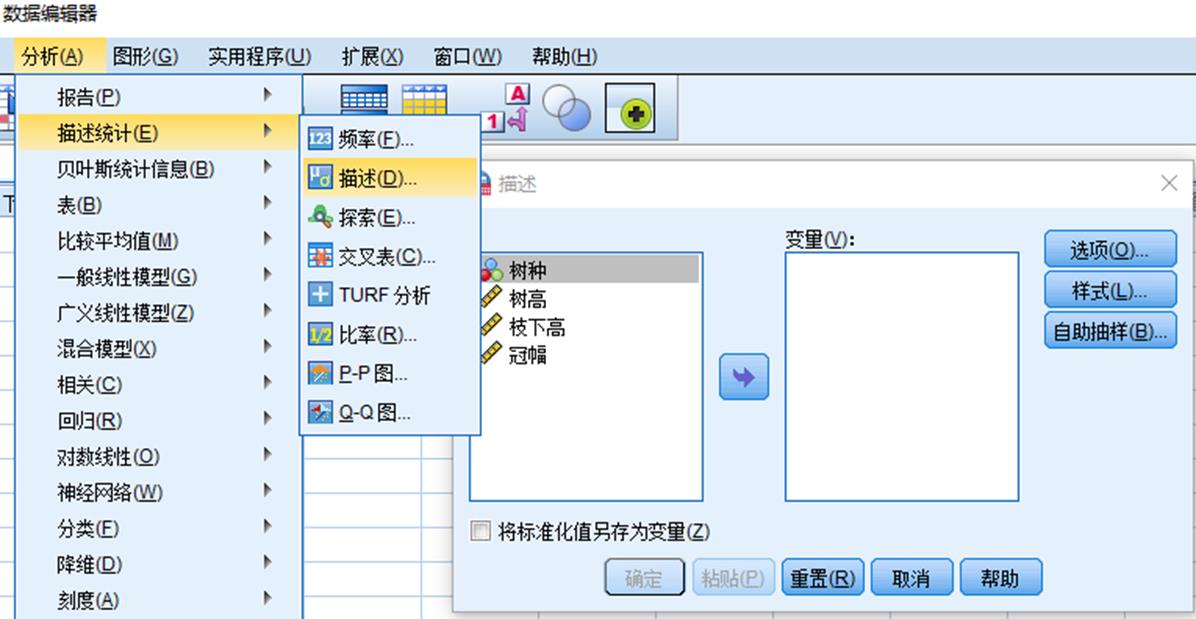
二、描述性统计分析(Descriptives)
基本概念:描述性统计分析主要用以计算描述集中趋势和离散趋势的各种统计量,此外还有一个重要功能是对变量做标准化变换,即Z变换。
通过 分析>描述统计>描述 路径进入描述统计主对话框
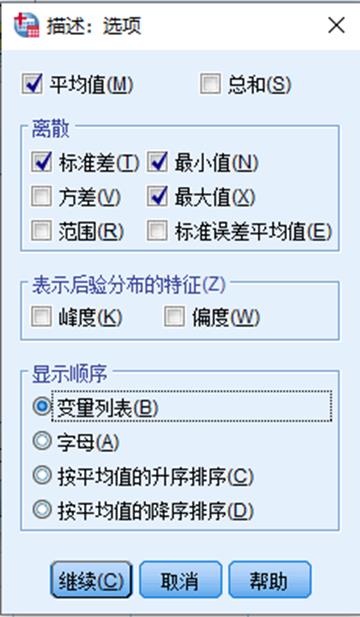
1. 在描述统计主对话框中点击选项即可进入选项对话框,针对统计需求进行各项目勾选即可
案例:分析不同性别演员获得奥斯卡的年龄差异性
三、探索性分析(Explore)
基本概念:探索分析是在对数据的基本特征 统计量有初步连接的基础上,对数据进行的更为深入详细的描述性观察分析。在一般描述性统计指标的基础上,增加了有关数据其他特征的文字与图形描述,显得更加细致与全面,有助于用户四开对数据进行进一步的方案。
探索性分析有以下几个目的:
对数据进行初步检查,判断有无离群点和极端值;
对前提条件假设,如正态分布和方差齐性进行检查,不满足正态分布和方差齐性时,提示数据转换方法,最后决定使用参数方法或非参数方法;
了解组间差异的特征。
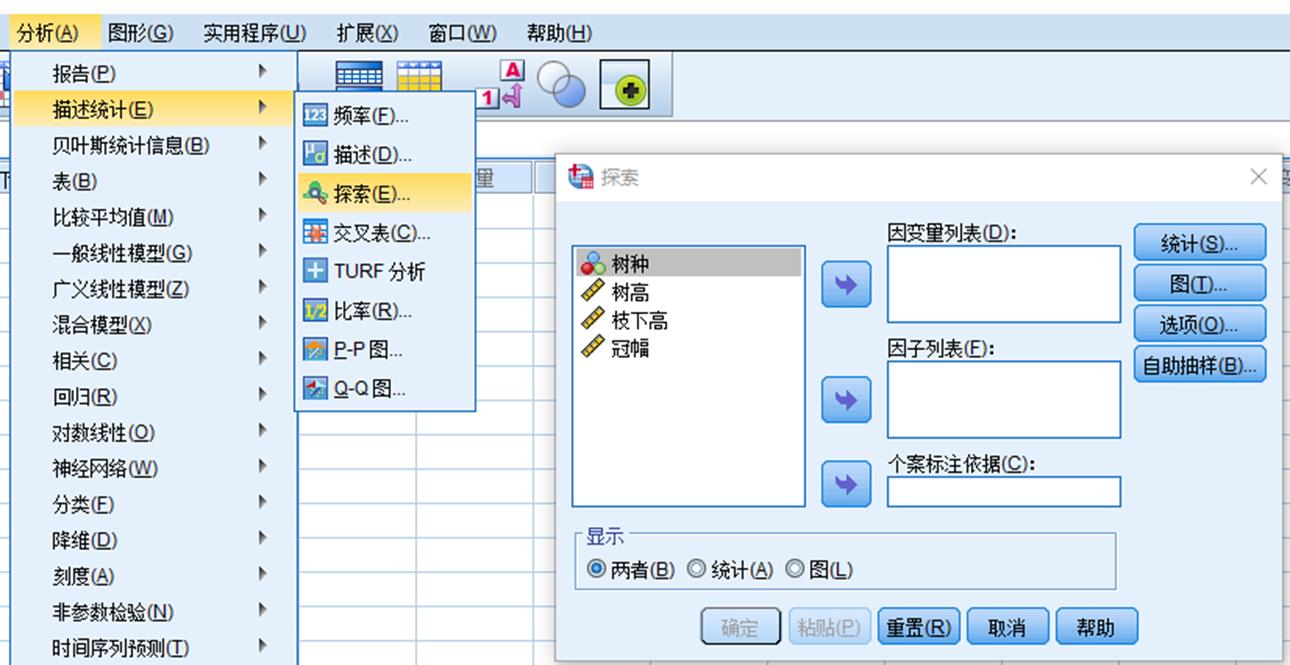
通过 分析>描述统计>探索 路径进入探索统计主对话框
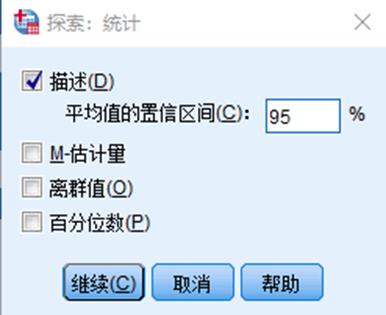
1. 在探索统计主对话框中点击统计即可进入统计对话框,针对统计需求进行项目勾选即可
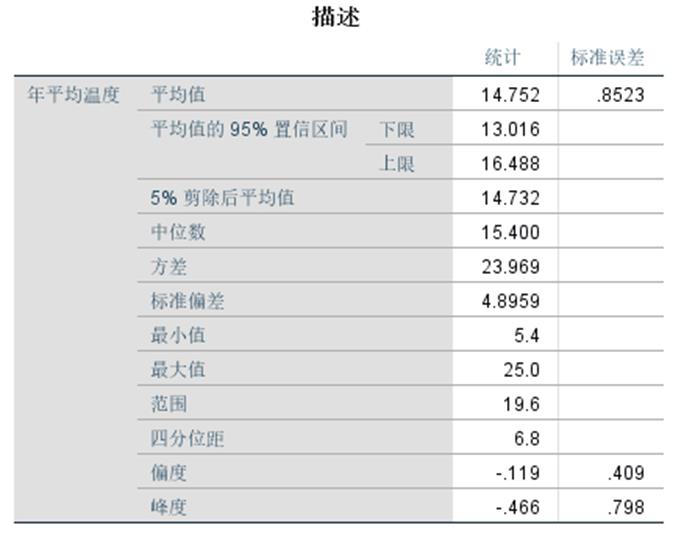
描述:生成描述性统计表格,表中显示样本数据的描述统计量,包括平均值、中位数、5%调整平均数、标准误差、方差、标准差、最大/小值、组距、四分位数、峰/偏度、峰/偏度的标准误差; 均值置信区间可输入,一般在95;
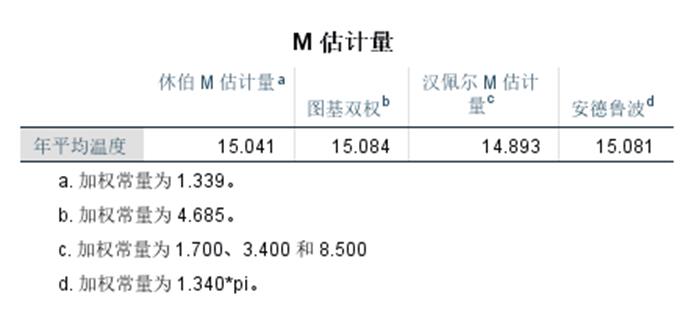
M-估计量:计算并生成稳健估计量。M估计在计算时对所有观测量赋予权重,随观测量距分布中心的远近而变化,通过给远离中心值的数据赋予较小的权重来减小异常值的影响;
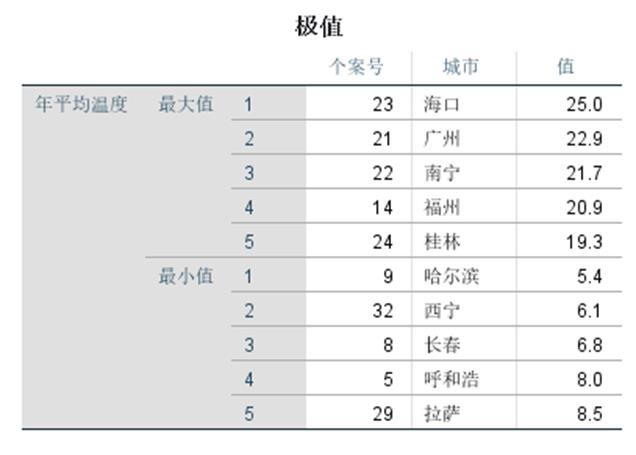
离群值:输出分析数据中5个最大值和5个最小值作为异常嫌疑值;
百分位数:计算并显示制定的百分位数,包括5%、10%、25%、50%、75%、90%、95%等。
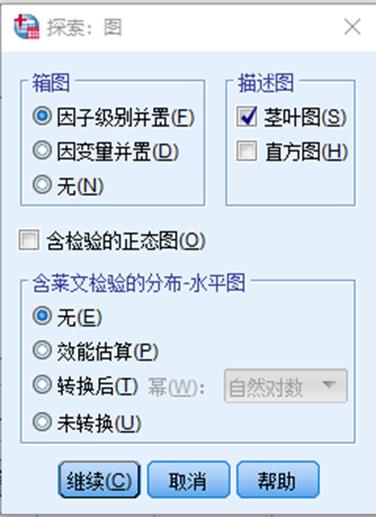
2. 在探索统计主对话框中点击图即可进入图形对话框,针对统计需求进行输出图表选择
箱图:因子级别并置-为每个因变量创建一个箱图,在每个箱图 内根据分组变量的不同水平的取值创建箱型单元;因变量并置-为每个分组变量的水平创建一个箱图,在每个箱图内用不同的颜色区分不同因变量所对应的箱型单元,方便用户进行比较;无-不创建箱图
描述图:茎叶图-主要由频率、茎、叶组成,在图中按从左到右的顺序依次排列,在图的底端,注明了茎的宽和每一叶所代表的观测量数;直方图-直接绘制直方图
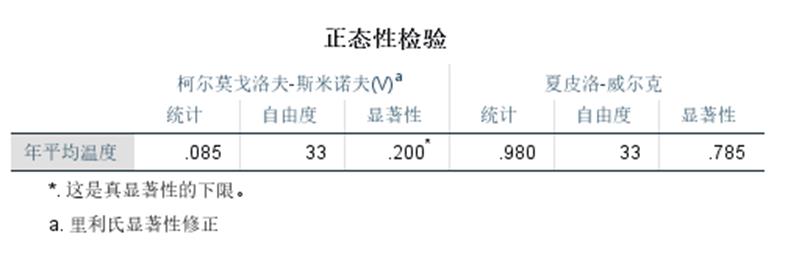
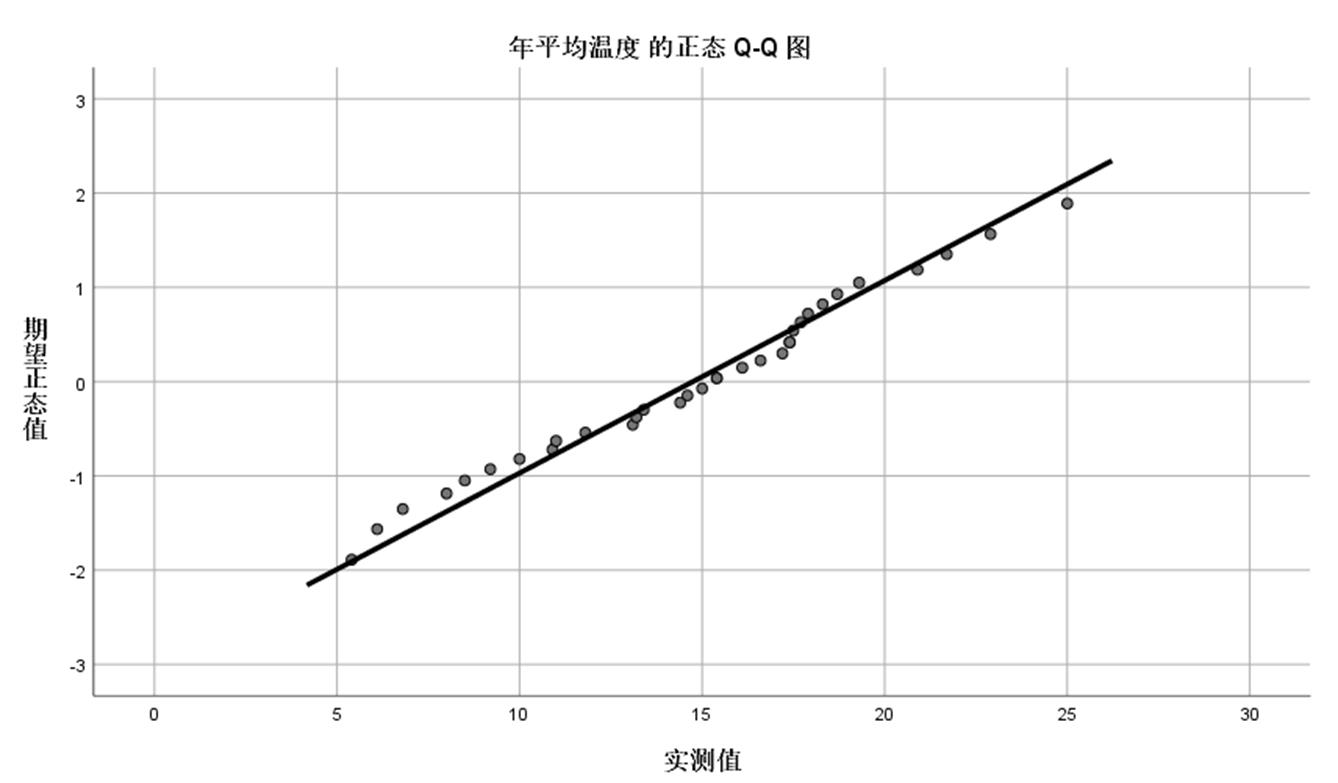
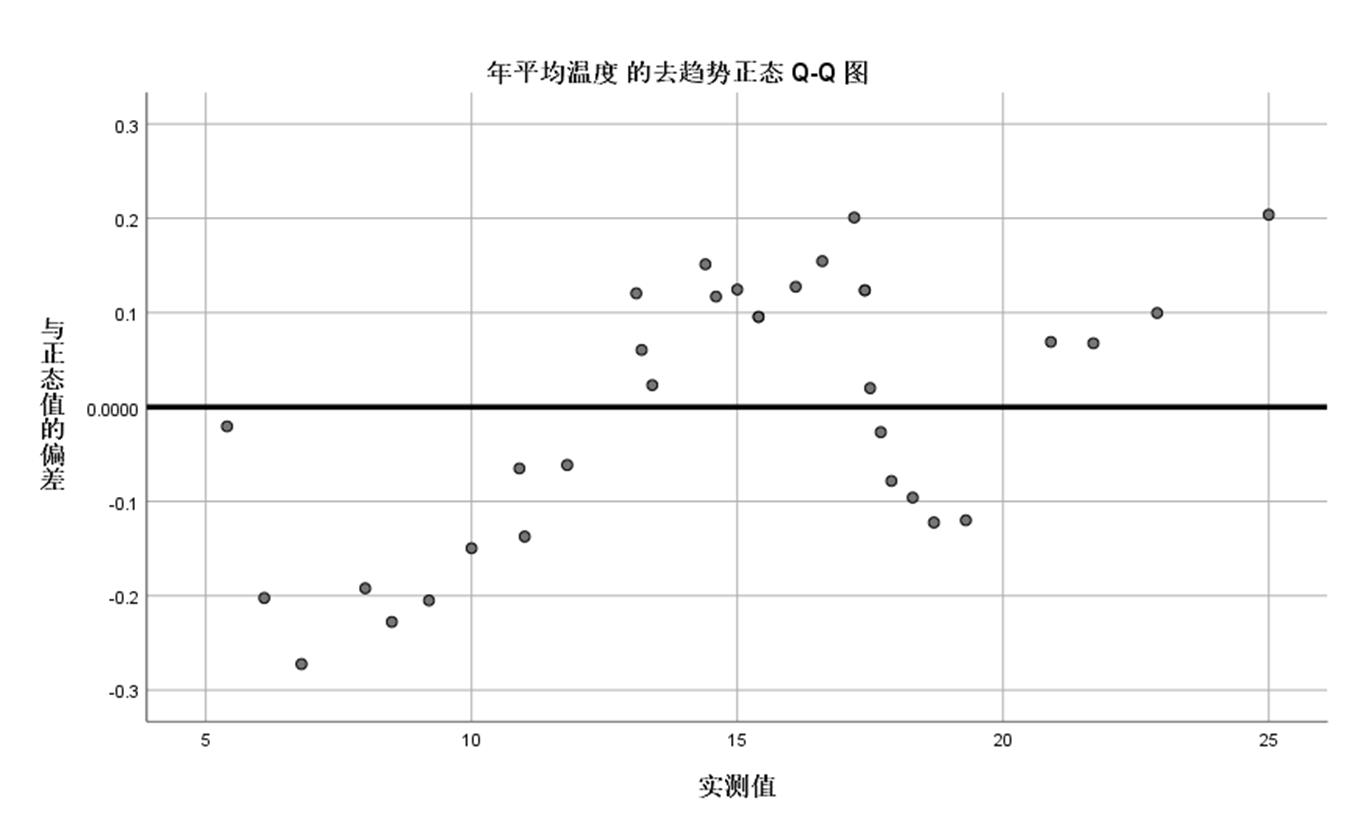
函检验的正态图:进行正态性检验,并生成正态Q-Q概率图和无趋势正态Q-Q概率图
含莱文检验的分布:伸展与级别检验,对所有的展布-水平图进行方差齐性检验和数据转换,同时输出回归直线的斜率及方差齐性的级别检验,但如果没有指定分组变量,则此选项无效
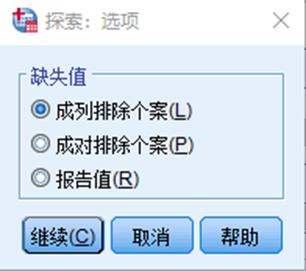
3. 在探索统计主对话框中点击图即可进入选项对话框,针对统计需求进行输出类型选择
成列排除个案:对所有的分析过程剔除分组变量和因变量中所有带有缺失值的观测量数据;
成对排除个案:同时剔除带缺失值的观测值及与缺失值有成对关系的观测量。在当前分析过程中用到的变量数据中剔除带有缺失值的观测量数据,在其他分析过程中可能包含缺失值;
报告值:将分组变量的缺失值单独分为一组,在输出频数表的同时输出缺失值。
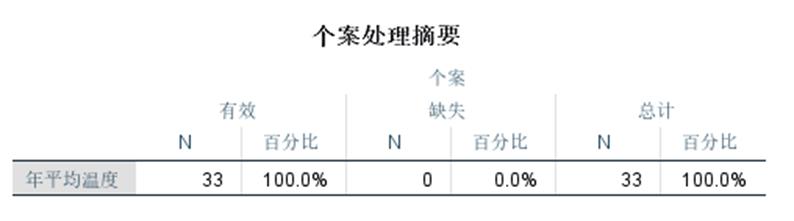
案例:分析中国南北城市的温度差异
R-基本统计分析--描述性统计分析
描述性统计分析主要包括
基本信息:样本数、总和 集中趋势:均值、中位数、众数 离散趋势:方差(标准差)、变异系数、全距(最小值、最大值)、内四分位距(25%分位数、75%分位数) 分布描述:峰度系数、偏度系数
不分组描述性统计
该数据采用R自带数据集mtcars进行分析,可在R编辑器直接输入得到该数据集内容
1.1、自带summary函数
myvars <- c("mpg", "hp", "wt")
summary(mtcars[myvars]) #给出集中趋势汇总
mpg hp wt
Min. :10.40 Min. : 52.0 Min. :1.513
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581
Median :19.20 Median :123.0 Median :3.325
Mean :20.09 Mean :146.7 Mean :3.217
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610
Max. :33.90 Max. :335.0 Max. :5.424
1.2、pastecs包的stat.sesc函数
install.packages("pastecs")
library(pastecs)
myvars <- c("mpg", "hp", "wt")
stat.desc(mtcars[myvars],basic = TRUE,desc=TRUE,norm=TRUE,p=0.95) #给出基本信息,集中趋势,离散趋势,偏度系数,峰度系数--基本覆盖所有描述性统计分析要求
mpg hp wt
nbr.val 32.0000000 32.00000000 32.00000000
nbr.null 0.0000000 0.00000000 0.00000000
nbr.na 0.0000000 0.00000000 0.00000000
min 10.4000000 52.00000000 1.51300000
max 33.9000000 335.00000000 5.42400000
range 23.5000000 283.00000000 3.91100000
sum 642.9000000 4694.00000000 102.95200000
median 19.2000000 123.00000000 3.32500000
mean 20.0906250 146.68750000 3.21725000
SE.mean 1.0654240 12.12031731 0.17296847
CI.mean.0.95 2.1729465 24.71955013 0.35277153
var 36.3241028 4700.86693548 0.95737897
std.dev 6.0269481 68.56286849 0.97845744
coef.var 0.2999881 0.46740771 0.30412851
skewness 0.6106550 0.72602366 0.42314646
skew.2SE 0.7366922 0.87587259 0.51048252
kurtosis -0.3727660 -0.13555112 -0.02271075
kurt.2SE -0.2302812 -0.08373853 -0.01402987
normtest.W 0.9475647 0.93341934 0.94325772
normtest.p 0.1228814 0.04880824 0.09265499
总数值个数(NBR.VAL),空值的数目(NBR. NULL),
数目缺失值(NBR.NA),最小值(min),最大值(max),
范围(范围,即max min)和所有非缺失值之和(和)
中位数(median),平均值(mean),
标准误差平均(SE.mean),P水平均值(CI.mean)的置信区间,
方差(Var)、标准差(std.dev)
和变异系数(coef.var)定义为标准差除以平均值。
偏度系数G1(skeness),其显著判据(skew.2SE),即
是,G1/2.SEG1;如果SkW.2SE>1,则偏度显著不同于
零)峰度系数G2(kurtosis)及其显著判据(Kurt.2SE)
以及夏皮罗的Wikk检验的两个统计量
标准检验.W(normtest.W)及其相关概率标准检验p(normtest.p)
2018/10/27 16:28
分组描述性统计分析
2.1、单一分组
vars<-c("mpg","hp","wt")
aggregate(mtcars[vars],by=list(am=mtcars$am),mean) #采用aggregate侧重于计算某个统计量
aggregate(mtcars[vars],by=list(am=mtcars$am),sd)
> aggregate(mtcars[vars],by=list(am=mtcars$am),mean)
am mpg hp wt
1 0 17.14737 160.2632 3.768895
2 1 24.39231 126.8462 2.411000
> aggregate(mtcars[vars],by=list(am=mtcars$am),sd)
am mpg hp wt
1 0 3.833966 53.90820 0.7774001
2 1 6.166504 84.06232 0.6169816
2.2、自动分组(14个统计指标)
library(psych)
describeBy(mtcars[vars],mtcars$am,mat=T,digits = 3) #psych包中的describeBy函数能给出14个分组计算指标
describeBy(mtcars[vars],mtcars$am,mat=F) #describeBy函数给出特定输出结果便于分析
> describeBy(mtcars[vars],mtcars$am,mat=T,digits = 3)
item group1 vars n mean sd median trimmed mad min max range skew kurtosis se
mpg1 1 0 1 19 17.147 3.834 17.30 17.118 3.113 10.400 24.400 14.000 0.014 -0.803 0.880
mpg2 2 1 1 13 24.392 6.167 22.80 24.382 6.672 15.000 33.900 18.900 0.053 -1.455 1.710
hp1 3 0 2 19 160.263 53.908 175.00 161.059 77.095 62.000 245.000 183.000 -0.014 -1.210 12.367
hp2 4 1 2 13 126.846 84.062 109.00 114.727 63.752 52.000 335.000 283.000 1.360 0.563 23.315
wt1 5 0 3 19 3.769 0.777 3.52 3.748 0.452 2.465 5.424 2.959 0.976 0.142 0.178
wt2 6 1 3 13 2.411 0.617 2.32 2.387 0.682 1.513 3.570 2.057 0.210 -1.174 0.171
> describeBy(mtcars[vars],mtcars$am,mat=F)
Descriptive statistics by group
group: 0
vars n mean sd median trimmed mad min max range skew kurtosis se
mpg 1 19 17.15 3.83 17.30 17.12 3.11 10.40 24.40 14.00 0.01 -0.80 0.88
hp 2 19 160.26 53.91 175.00 161.06 77.10 62.00 245.00 183.00 -0.01 -1.21 12.37
wt 3 19 3.77 0.78 3.52 3.75 0.45 2.46 5.42 2.96 0.98 0.14 0.18
-----------------------------------------------------------------------------------------
group: 1
vars n mean sd median trimmed mad min max range skew kurtosis se
mpg 1 13 24.39 6.17 22.80 24.38 6.67 15.00 33.90 18.90 0.05 -1.46 1.71
hp 2 13 126.85 84.06 109.00 114.73 63.75 52.00 335.00 283.00 1.36 0.56 23.31
wt 3 13 2.41 0.62 2.32 2.39 0.68 1.51 3.57 2.06 0.21 -1.17 0.17
Usage
describeBy(x, group=NULL,mat=FALSE,type=3,digits=15,...)
describe.by(x, group=NULL,mat=FALSE,type=3,...) # deprecated
x表示数据集
group要进行的分组值
Mat是否采用矩阵输出(很有用)
digits仅在采用矩阵输出时可选默认保留15位小数
type 偏斜度和峰度类型(不用管)
2.3、自定义分组指标(自定义函数,多个分组指标)
mystats <- function(x, na.omit=FALSE){ #自定义计算所需特定统计值
if (na.omit)
x <- x[!is.na(x)]
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum((x-m)^3/s^3)/n
kurt <- sum((x-m)^4/s^4)/n - 3
return(c(n=n, mean=m, stdev=s, skew=skew, kurtosis=kurt))
}
dstats <- function(x)sapply(x, mystats)
myvars <- c("mpg", "hp", "wt") #给出特定数据框计算列的(标号),在by的data里作为下标
by(mtcars[myvars], mtcars$am, dstats) #将data数据框按照indces进行分组,具体计算采用自定义函数dstats
> by(mtcars[myvars], mtcars$am, dstats)
mtcars$am: 0
mpg hp wt
n 19.00000000 19.00000000 19.0000000
mean 17.14736842 160.26315789 3.7688947
stdev 3.83396639 53.90819573 0.7774001
skew 0.01395038 -0.01422519 0.9759294
kurtosis -0.80317826 -1.20969733 0.1415676
-------------------------------------------------------------
mtcars$am: 1
mpg hp wt
n 13.00000000 13.0000000 13.0000000
mean 24.39230769 126.8461538 2.4110000
stdev 6.16650381 84.0623243 0.6169816
skew 0.05256118 1.3598859 0.2103128
kurtosis -1.45535200 0.5634635 -1.1737358
Usage
by(data, INDICES, FUN, ..., simplify = TRUE)
data: 一般是数据框或矩阵。an R object, normally a data frame, possibly a matrix.
INDICES:一个因子或一览表,每行长度n行。
FUN:应用于(通常是数据帧)数据子集的函数。
simplify:logical; if FALSE, tapply always returns an array of mode "list"; in other words, a list with a dim attribute. If TRUE (the default), then if FUN always returns a scalar, tapply returns an array with the mode of the scalar.(不常用)
> head(mtcars[myvars])
mpg hp wt
Mazda RX4 21.0 110 2.620
Mazda RX4 Wag 21.0 110 2.875
Datsun 710 22.8 93 2.320
Hornet 4 Drive 21.4 110 3.215
Hornet Sportabout 18.7 175 3.440
Valiant 18.1 105 3.460
> mtcars$am
[1] 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1
> class(mtcars[myvars])
[1] "data.frame"
> class(mtcars$am)
[1] "numeric"
关于R的描述性统计,这些包与函数基本覆盖所有的使用范围,还有几个包没有列入,笔者进行了适当筛选。
欢迎热心网友讨论,学习!
2018-10-28
具体统计函数指标及其含义可参看博友(传送门)
R提高篇(五): 描述性统计分析 - 天戈朱 - 博客园
以上是关于0002.统计描述分析的主要内容,如果未能解决你的问题,请参考以下文章
XPath 笔记本:XError:Focus for / 不存在;代码:XPDY0002
组合数据类型练习,英文词频统计实例上
LM0002 最大公约数GCD
M0002 迭代求和
M0002 迭代求和
本周工作量及进度统计

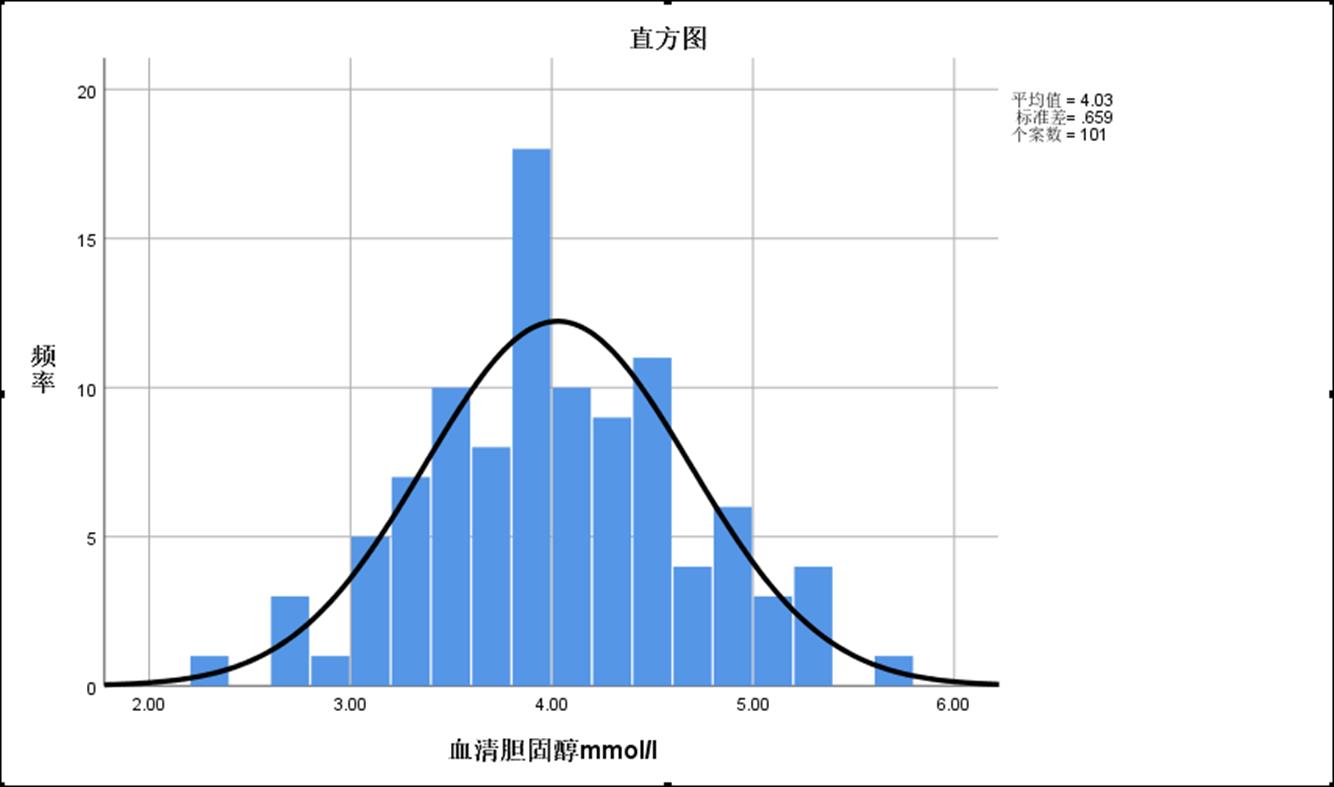
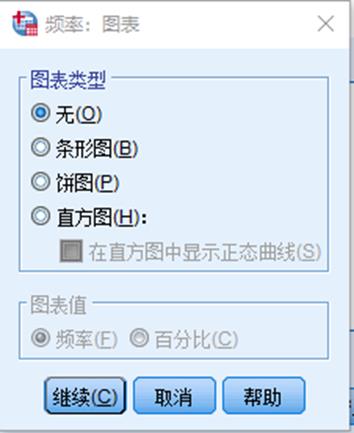 在选择直方图时,可勾选在直方图中显示正态曲线,则输出图像为正态分布图。
在选择直方图时,可勾选在直方图中显示正态曲线,则输出图像为正态分布图。