MySQL学习基础篇Day9
Posted beichens
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL学习基础篇Day9相关的知识,希望对你有一定的参考价值。
6. 事务
6.1 事务简介
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系 统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
就比如: 张三给李四转账1000块钱,张三银行账户的钱减少1000,而李四银行账户的钱要增加 1000。 这一组操作就必须在一个事务的范围内,要么都成功,要么都失败。

正常情况: 转账这个操作, 需要分为以下这么三步来完成 , 三步完成之后, 张三减少1000, 而李四 增加1000, 转账成功 :

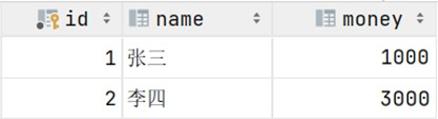
异常情况: 转账这个操作, 也是分为以下这么三步来完成 , 在执行第三步是报错了, 这样就导致张 三减少1000块钱, 而李四的金额没变, 这样就造成了数据的不一致, 就出现问题了。
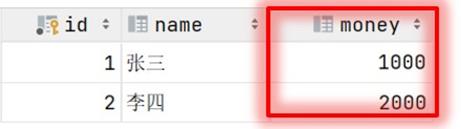
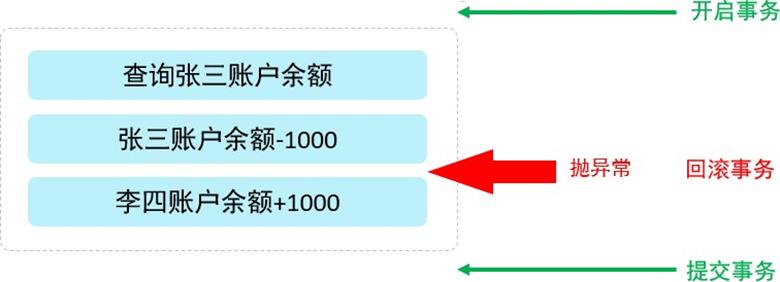
为了解决上述的问题,就需要通过数据的事务来完成,我们只需要在业务逻辑执行之前开启事务,执行 完毕后提交事务。如果执行过程中报错,则回滚事务,把数据恢复到事务开始之前的状态。
注意:
默认MySQL的事务是自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐 式的提交事务。
6.2 事务操作
数据准备:
drop table if exists account; create table account( id int primary key AUTO_INCREMENT comment \'ID\', name varchar(10) comment \'姓名\', money double(10,2) comment \'余额\' ) comment \'账户表\'; insert into account(name, money) VALUES (\'张三\',2000), (\'李四\',2000);
6.2.1 未控制事务
1). 测试正常情况
select * from account where name = \'张三\'; update account set money = money - 1000 where name = \'张三\'; update account set money = money + 1000 where name = \'李四\';
测试完毕之后检查数据的状态, 可以看到数据操作前后是一致的。
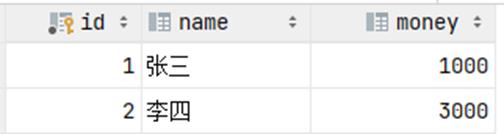
2). 测试异常情况
select * from account where name = \'张三\'; update account set money = money - 1000 where name = \'张三\'; 出错了.... update account set money = money + 1000 where name = \'李四\';
我们把数据都恢复到2000, 然后再次一次性执行上述的SQL语句(出错了.... 这句话不符合SQL语 法,执行就会报错),检查最终的数据情况, 发现数据在操作前后不一致了。
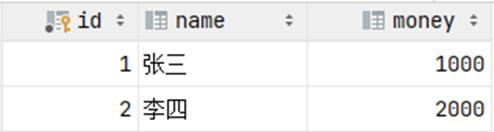
6.2.2 控制事务一
1). 查看/设置事务提交方式
SELECT @@autocommit ; SET @@autocommit = 0 ;
2). 提交事务
COMMIT;
3). 回滚事务
ROLLBACK;
注意:
上述的这种方式,我们是修改了事务的自动提交行为, 把默认的自动提交修改为了手动提 交, 此时我们执行的DML语句都不会提交, 需要手动的执行commit进行提交。
6.2.3 控制事务二
1). 开启事务
START TRANSACTION 或 BEGIN ;
2). 提交事务
COMMIT
3). 回滚事务
ROLLBACK;
转账案例:
start transaction select * from account where name = \'张三\'; update account set money = money - 1000 where name = \'张三\'; update account set money = money + 1000 where name = \'李四\'; commit;
6.3 事务四大特性
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立 环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
上述就是事务的四大特性,简称ACID。
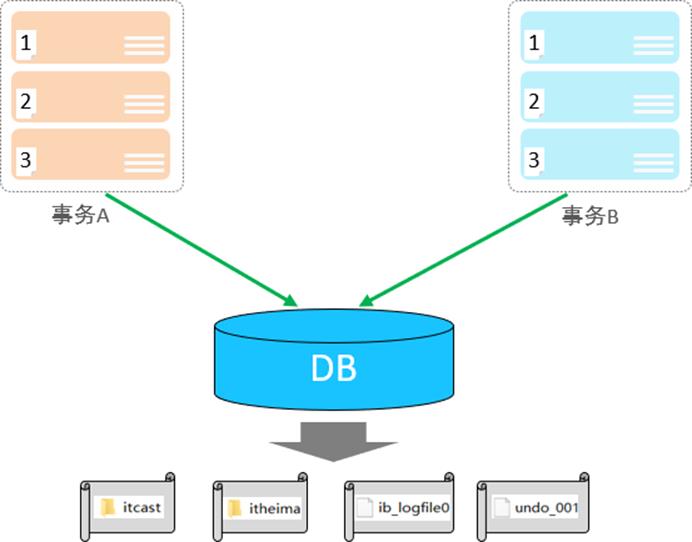
6.4 并发事务问题
1). 赃读:一个事务读到另外一个事务还没有提交的数据
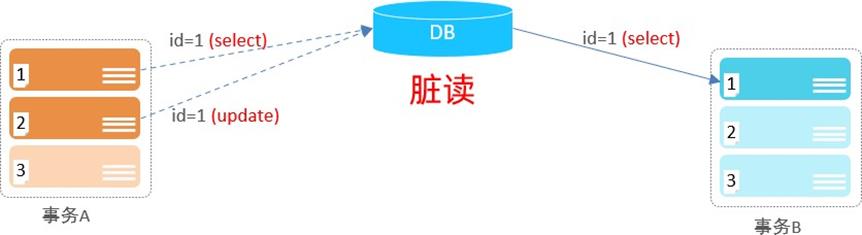
2). 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
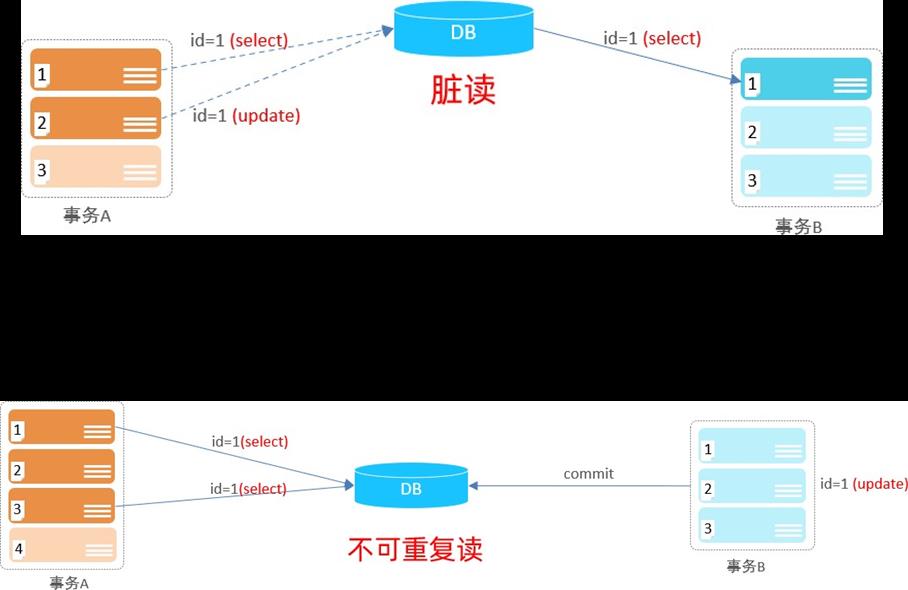
事务A两次读取同一条记录,但是读取到的数据却是不一样的。
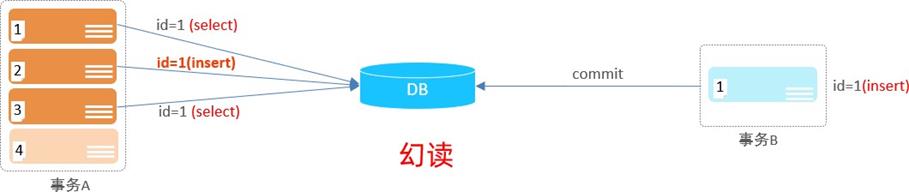
3). 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据 已经存在,好像出现了 "幻影"。
6.5 事务隔离级别
为了解决并发事务所引发的问题,在数据库中引入了事务隔离级别。主要有以下几种:
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
|
Read uncommitted |
√ |
√ |
√ |
|
Read committed |
× |
√ |
√ |
|
Repeatable Read(默认) |
× |
× |
√ |
|
Serializable |
× |
× |
× |
1). 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
2). 设置事务隔离级别
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE
注意:事务隔离级别越高,数据越安全,但是性能越低。
Sklearn机器学习基础(day02基础入门篇)
文章目录
基本算法使用(Sklearn)
到目前这一步涉及到了具体的算法使用,也就是调用 sklearn 的一些基本集成算法,那么关于 sklearn 的算法调用可以有一下调用规范(这些都是统一的,由于操作类似所有形成了规范)
(Ps:此时对于一些基本算法将不再进行数学推导,不太会,东西多 ,有些我很熟悉不想写,本博文为学习总结笔记结合 B站学习的浓缩精简笔记)
算子API调用分步曲
estimator 预估器
estimator = 某个算子 API()
estimator.fit(x_train,y_train) 进行运算,训练对应的模型
estimator.predict(x_test) 进行预测(调用模型)
estimator.score(x_test,y_test) 进行模型预估评价
数据分析分步曲
1.加载数据
2.数据标准化,归一化
3.数据特征提取,降维 etc
4.数据切割划分,划分训练集,测试集
5.使用对于算子API
6.使用estimator 进行训练
7.对数据进行预测评估
8.根据测试结果进行优化
9.保存优化后的算法模型
那么接下来就是关于数据处理的一些算子。
分类算法
KNN 算法
描述:
如果一个样本在特征空间中的k个最相似(k值)的大对数属于某一个类别,则该样本也属于这个类别。
用于做分类预测!例如对地图地点分类,预测用户最喜欢聚集的地方(然后投放广告,参考 facebook 案例 :预测facebook签到位置)
原理:
对于一个样本,计算对应某个相似值与其他点的距离(例如通过欧式距离等)从而找到近似的点进行划分。
优点:
- 易于实现,无需训练
缺点:
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证(此时需要通过一定的自我修正,在这里是sklearn 的网格修正)
对应 API:
from sklearn.neighbors import KNeighborsClassifier
代码示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
#用KNN对鸢尾花进行分类
def knn_iris():
"""用KNN算法对鸢尾花进行分类"""
#1.获取数据
iris=load_iris()
#2.划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=6)
#3.特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#4.KNN算法预估器
estimator=KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train,y_train)
#5.模型评估
#5.1 方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\\n",y_predict)
print("直接比对真实值和预测值:\\n",y_test==y_predict)
#5.2 方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\\n",score)
out:
y_predict:
[0 2 0 0 2 1 1 0 2 1 2 1 2 2 1 1 2 1 1 0 0 2 0 0 1 1 1 2 0 1 0 1 0 0 1 2 1
2]
直接比对真实值和预测值:
[ True True True True True True False True True True True True
True True True False True True True True True True True True
True True True True True True True True True True False True
True True]
准确率为:
0.9210526315789
网格优化
from sklearn.model_selection import GridSearchCV
这个作用呢其实很简单,就是前面说的自动参数设置,也就是前面 estimator=KNeighborsClassifier(n_neighbors=3)
这个 n_neighbors 的数值其实那啥也是要不断的去试试的,那么这里sklearn 提供了一个方法来帮助我们去试一试这个参数的设置
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
def knn_iris_gsv():
"""用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证"""
#1.获取数据
iris=load_iris()
#2.划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=6)
#3.特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#4.KNN算法预估器
estimator=KNeighborsClassifier()
'''加入网格搜索与交叉验证'''
#参数准备
param_dict={"n_neighbors":[1,3,5,7,9,11],}#估计器参数
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)#estimator:估计器对象,cv:几折交叉验证,fit():输入训练数据,score():准确率
estimator.fit(x_train,y_train)
#5.模型评估
#5.1 方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\\n",y_predict)
print("直接比对真实值和预测值:\\n",y_test==y_predict)
#5.2 方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\\n",score)
'''查看网格搜索与交叉验证结果'''
# 最佳参数:best_params_
print("最佳参数:\\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\\n", estimator.cv_results_)
重点在这:
param_dict={"n_neighbors":[1,3,5,7,9,11],}#估计器参数
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)#estimator:估计器对象,cv:几折交叉验证,fit():输入训练数据,score():准确率
KNN 案例 (预测facebook签到位置)
此案例为facebook 的定位 案例。
这个案例比较复杂的其实是数据清洗 也就是pandas 的数据清洗。这里详细说一下毕竟我觉得难点就是数据处理这一块。
数据集:
链接:https://pan.baidu.com/s/1nojpx6ovymtLJEr9CoBadw
提取码:6666
数据清洗
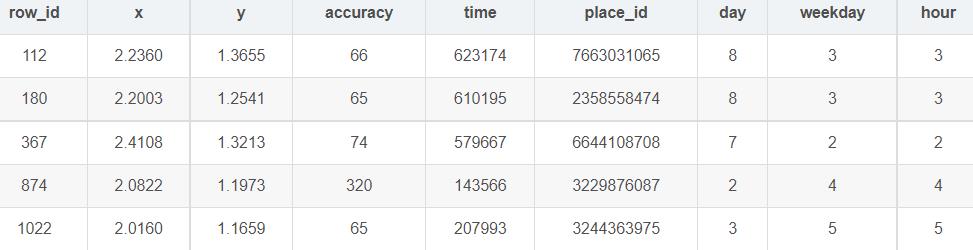
首先数据长这个样子:
row_id x y accuracy time place_id
0 0 0.7941 9.0809 54 470702 8523065625
1 1 5.9567 4.7968 13 186555 1757726713
2 2 8.3078 7.0407 74 322648 1137537235
3 3 7.3665 2.5165 65 704587 6567393236
4 4 4.0961 1.1307 31 472130 7440663949
(29118021, 6)
#1.获取数据 data = pd.read_csv("…/input/train.csv")
然后我们需要对数据进行基本处理,也就是说首先 要 把 time 进行格式转换,然后我们需要提取出训练集X 和 预测集Y
也就是提取之后长这个样子
Y 长这个样子
place_id
1014605271 28
1015645743 4
1017236154 31
1024951487 5
1028119817 4
Name: row_id, dtype: int64
那么具体代码是这样的:
# 1)缩小数据范围
data=data.query(" x<2.5 & x>2 & y<1.5 & y>1.0")
# 2)处理时间特征
time_value=pd.to_datetime(data["time"],unit="s")
data["day"]=date.day
data["weekdaty"]=date.weekday
data["hour"]=date.hour
# 3)过滤掉次数少的地点
place_count=data.groupby("place_id").count()["row_id"]
data_final = data[data["place_id"].isin(place_count[place_count>3].index.values)]
# 4)筛选特征值和目标值
x=data_final[["x","y","accuracy","day","weekdaty","hour"]]
y=data_final["place_id"]
KNN处理预测
这一步就是套口诀了:
# 5)数据集划分
x_train,x_test,y_train,y_test=train_test_split(x,y)
#3.特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#4.KNN算法预估器
estimator=KNeighborsClassifier()
'''加入网格搜索与交叉验证'''
#参数准备
param_dict={"n_neighbors":[3,5,7,9]}#估计器参数
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=3)#estimator:估计器对象,cv:几折交叉验证,fit():输入训练数据,score():准确率
estimator.fit(x_train,y_train)
#5.模型评估
#5.1 方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\\n",y_predict)
print("直接比对真实值和预测值:\\n",y_test==y_predict)
#5.2 方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\\n",score)
'''查看网格搜索与交叉验证结果'''
# 最佳参数:best_params_
print("最佳参数:\\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\\n", estimator.cv_results_)
完整代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 1.获取数据
data=pd.read_csv("./FBlocation/train.csv")
# 2.基本数据处理
# 1)缩小数据范围
data=data.query(" x<2.5 & x>2 & y<1.5 & y>1.0")
# 2)处理时间特征
time_value=pd.to_datetime(data["time"],unit="s")
data["day"]=date.day
data["weekdaty"]=date.weekday
data["hour"]=date.hour
# 3)过滤掉次数少的地点
place_count=data.groupby("place_id").count()["row_id"]
data_final = data[data["place_id"].isin(place_count[place_count>3].index.values)]
# 4)筛选特征值和目标值
x=data_final[["x","y","accuracy","day","weekdaty","hour"]]
y=data_final["place_id"]
# 5)数据集划分
x_train,x_test,y_train,y_test=train_test_split(x,y)
#3.特征工程:标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#4.KNN算法预估器
estimator=KNeighborsClassifier()
'''加入网格搜索与交叉验证'''
#参数准备
param_dict={"n_neighbors":[3,5,7,9]}#估计器参数
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=3)#estimator:估计器对象,cv:几折交叉验证,fit():输入训练数据,score():准确率
estimator.fit(x_train,y_train)
#5.模型评估
#5.1 方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\\n",y_predict)
print("直接比对真实值和预测值:\\n",y_test==y_predict)
#5.2 方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\\n",score)
'''查看网格搜索与交叉验证结果'''
# 最佳参数:best_params_
print("最佳参数:\\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\\n", estimator.cv_results_)
朴素贝叶斯算法
这个其实是类似于用概率预测的方式进行运算预测分类,其实就是问某一个玩意属于某一个类别(或者范围)的概率
朴素:这个是指假设忽略数据集的影响(数据集可能不完整)也就是假设在数据集里面的每一个元素都是独立的!
- 联合概率
包含多个条件,且所有条件同时成立的概率- 条件概率
就是时间A在另外一个时间B已经发生的条件下发生的概率- 相互独立
如果P(A,B)=P(A)P(B),则称事件A与事件B相互独立- 贝叶斯公式
P(C|W)=( P(W|C)PC ) / P(W)- 朴素
特征与特征之间相互独立- 朴素贝叶斯算法
朴素 + 贝叶斯- 应用分类
文本分类(单词作为特征)- 拉普拉斯平滑系数
P(F1|C) = (分子+α) / (分母+αm)
α:指定的系数
m:训练文档出现的特征总个数
调用 API:
from sklearn.naive_bayes import MultinomialNB
这个咱们直接上例子:
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_news():
"""
用朴素贝叶斯算法对新闻进行分类
:return:
"""
#1.获取数据
news = fetch_20newsgroups(subset="all")#subset="all"获取所有数据,train获取训练数据
#2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
#3.特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#4.朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
#5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\\n", y_predict)
print("直接比对真实值和预测值:\\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\\n", score)
y_predict:
[15 2 16 ... 11 10 18]
直接比对真实值和预测值:
[False True False ... True True True]
准确率为:
0.8503820033955858
(PS :这些玩意都是可以用网格优化的!)
决策树
这玩意懂的都懂!
参考 up:https://www.bilibili.com/video/BV1Xp4y1U7vW
[信息论基础]
- 信息
香农:消除随机不确定的东西- 信息的衡量 - 信息量 - 信息熵
2.1 单位:bit
2.2 信息增益
g(D|A) = H(D)-H(D|A)
2.3 决策树的划分依据之一 ------- 信息增益(越大越好)优点:
- 可视化 - 可解释能力强
缺点:
- 决策树不能很好的用于过于复杂的树(过拟合)
改进:
- 减枝cart算法
- 随机森林
调用 API
from sklearn.tree import DecisionTreeClassifier
案例
决策树对鸢尾花数据分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,export_graphviz
def decision_iris():
"""用决策树对决策树对鸢尾花进行分类"""
#1.获取数据集
iris = load_iris()
#2.划分数据集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=22)
#3.决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train,y_train)
#4.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\\n", y_predict)
print("直接比对真实值和预测值:\\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\\n", score)
#可视化决策树
export_graphviz(estimator,out_file="iris_tree.dot",feature_names=iris.feature_names)
可视化决策树
export_graphviz(estimator,out_file=“iris_tree.dot”,feature_names=iris.feature_names)
这个会生成一个文件然后你放到网站去解析就好了。
随机森林
参考 up:https://www.bilibili.com/video/BV1H5411e73F?spm_id_from=333.999.0.0
一句话总结: 让多个森林去跑,然后统一一下。
[集成学习方法]
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
[随机森林]
随机:训练集随机,特征随机
森林:包含多个决策树的分类器
API
from sklearn.ensemble import RandomForestClassifier
数据集:
链接:https://pan.baidu.com/s/1cocizyxtizZMCGoyZvgQOg
提取码:6666
随机森林对泰坦尼克号乘客的生存进行预测
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
#获取数据
path="./titanic.csv"
titanic=pd.read_csv(path)
#筛选特征值和目标值
x=titanic[["pclass","age","sex"]]
y=titanic["survived"]
#2.数据处理
#2.1缺失值处理
x["age"].fillna(x["age"].mean(),inplace=True)
#2.2转换成字典
x=x.to_dict(orient="records")
#3.数据集划分
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=22)
#4.字典特征抽取
transfer=DictVectorizer()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
estimator=RandomForestClassifier()
#加入网格搜索与交叉验证
#参数准备
param_dict={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}#估计器参数
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=3)#estimator:估计器对象,cv:几折交叉验证,fit():输入训练数据,score():准确率
estimator.fit(x_train,y_train)
#5.模型评估
#5.1 方法1:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print("y_predict:\\n",y_predict)
print("直接比对真实值和预测值:\\n",y_test==y_predict)
#5.2 方法2:计算准确率
score=estimator.score(x_test,y_test)
print("准确率为:\\n",score)
'''查看网格搜索与交叉验证结果'''
# 最佳参数:best_params_
print("最佳参数:\\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\\n", estimator.cv_results_)
回归与聚类算法
线性回归
参考up : https://www.bilibili.com/video/BV17T4y1J7SB?spm_id_from=333.999.0.0
这个老朋友了,来看老师给的定义:
[线性回归]
- 回归问题
目标值 - 连续型的数据- 定义
函数关系(线性模型):特征值和目标值建立关系
y = w1x1 + w2x2 + w3x3 + … + wnxn + b = wTx + b- 广义线性模型
a. 自变量一次(线性关系)
y = w1x1 + w2x2 + w3x3 + … + wnxn + b = wTx + b
b. 参数一次(非线性关系)
y = w1x1 + w2x1^2 + w3x1^3 + w4x2^3 + … + b- 线性回归的损失和优化原理
目标:求模型参数
损失函数/cost/成本函数/目标函数 – 最小 – 最小二乘法
优化损失(优化方法)
a. 正规方程(天才)
直接求解w
b. 梯度下降(勤奋努力的普通人)
试错、改进
分类
GD梯度下降:计算所有的样本的值才能得出梯度
SGD随机梯度下降:在一次迭代只考虑一个样本
SAG随机平均梯度法- 回归性能评估
均方误差(MSE)评价机制
正规方程
API
from sklearn.linear_model import LinearRegression
特点:运算快,适合小样本数据
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
以上是关于MySQL学习基础篇Day9的主要内容,如果未能解决你的问题,请参考以下文章