Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换相关的知识,希望对你有一定的参考价值。
原文地址https://www.cnblogs.com/zhaof/p/7345856.html
总架构理解Middleware
通过scrapy官网最新的架构图来理解:
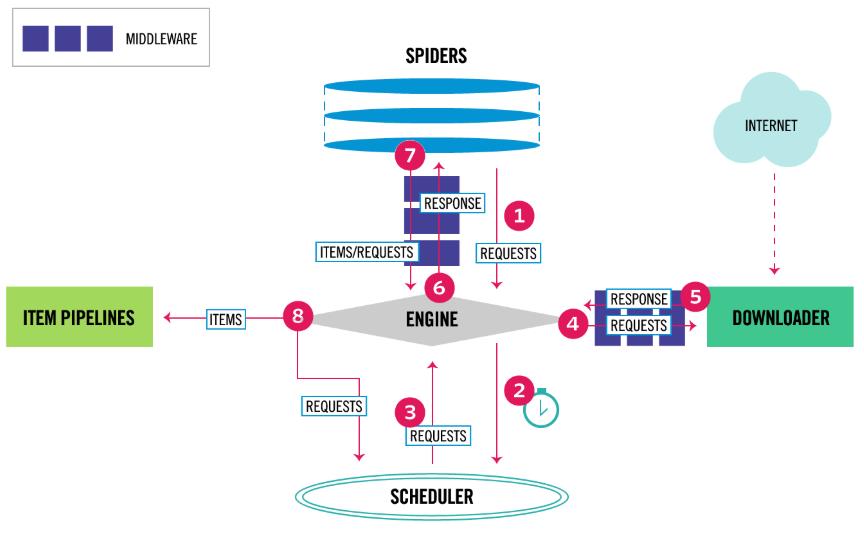
这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可以设置中间件,两者是双向的,并且是可以设置多层.
关于Downloader Middleware我在http://www.cnblogs.com/zhaof/p/7198407.html 这篇博客中已经写了详细的使用介绍。
如何实现随机更换User-Agent
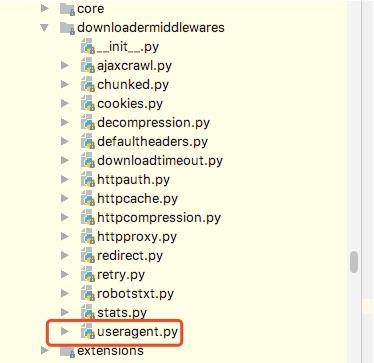
这里要做的是通过自己在Downlaoder Middleware中定义一个类来实现随机更换User-Agent,但是我们需要知道的是scrapy其实本身提供了一个user-agent这个我们在源码中可以看到如下图:

from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent"""
def __init__(self, user_agent=\'Scrapy\'):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings[\'USER_AGENT\'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, \'user_agent\', self.user_agent)
def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b\'User-Agent\', self.user_agent)
从源代码中可以知道,默认scrapy的user_agent=‘Scrapy’,并且这里在这个类里有一个类方法from_crawler会从settings里获取USER_AGENT这个配置,如果settings配置文件中没有配置,则会采用默认的Scrapy,process_request方法会在请求头中设置User-Agent.
关于随机切换User-Agent的库
github地址为:https://github.com/hellysmile/fake-useragent
安装:pip install fake-useragent
基本的使用例子:
from fake_useragent import UserAgent ua = UserAgent() print(ua.ie) print(ua.chrome) print(ua.Firefox) print(ua.random) print(ua.random) print(ua.random)
这里可以获取我们想要的常用的User-Agent,并且这里提供了一个random方法可以直接随机获取,上述代码的结果为:

关于配置和代码
这里我找了一个之前写好的爬虫,然后实现随机更换User-Agent,在settings配置文件如下:
DOWNLOADER_MIDDLEWARES = {
\'jobboleSpider.middlewares.RandomUserAgentMiddleware\': 543,
\'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware\': None,
}
RANDOM_UA_TYPE= \'random\'
这里我们要将系统的UserAgent中间件设置为None,这样就不会启用,否则默认系统的这个中间会被启用
定义RANDOM_UA_TYPE这个是设置一个默认的值,如果这里不设置我们会在代码中进行设置,在middleares.py中添加如下代码:
class RandomUserAgentMiddleware(object):
\'\'\'
随机更换User-Agent
\'\'\'
def __init__(self,crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get(\'RANDOM_UA_TYPE\',\'random\')
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault(\'User-Agent\',get_ua())
上述代码的一个简单分析描述:
1. 通过crawler.settings.get来获取配置文件中的配置,如果没有配置则默认是random,如果配置了ie或者chrome等就会获取到相应的配置
2. 在process_request方法中我们嵌套了一个get_ua方法,get_ua其实就是为了执行ua.ua_type,但是这里无法使用self.ua.self.us_type,所以利用了getattr方法来直接获取,最后通过request.heasers.setdefault来设置User-Agent
通过上面的配置我们就实现了每次请求随机更换User-Agent
以上是关于Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换的主要内容,如果未能解决你的问题,请参考以下文章