MyBatissaveBatch 性能调优
Posted Natee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyBatissaveBatch 性能调优相关的知识,希望对你有一定的参考价值。
这个项目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。 我点进去看了下源码,感觉有点不太对劲:
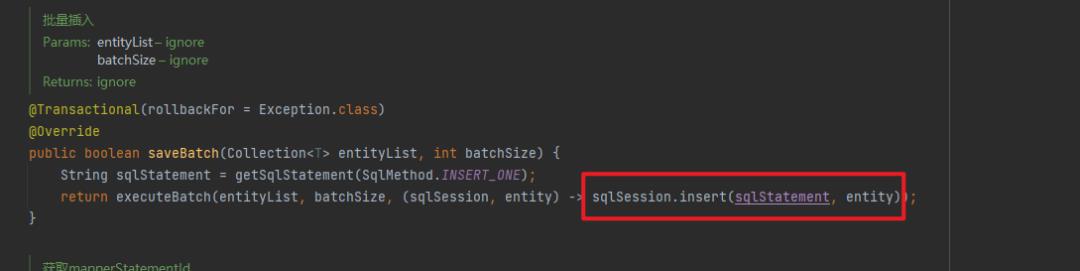
继续追踪了下,从这个代码来看,确实是 for 循环一条一条执行了 sqlSession.insert,下面的 consumer 执行的就是上面的 sqlSession.insert:
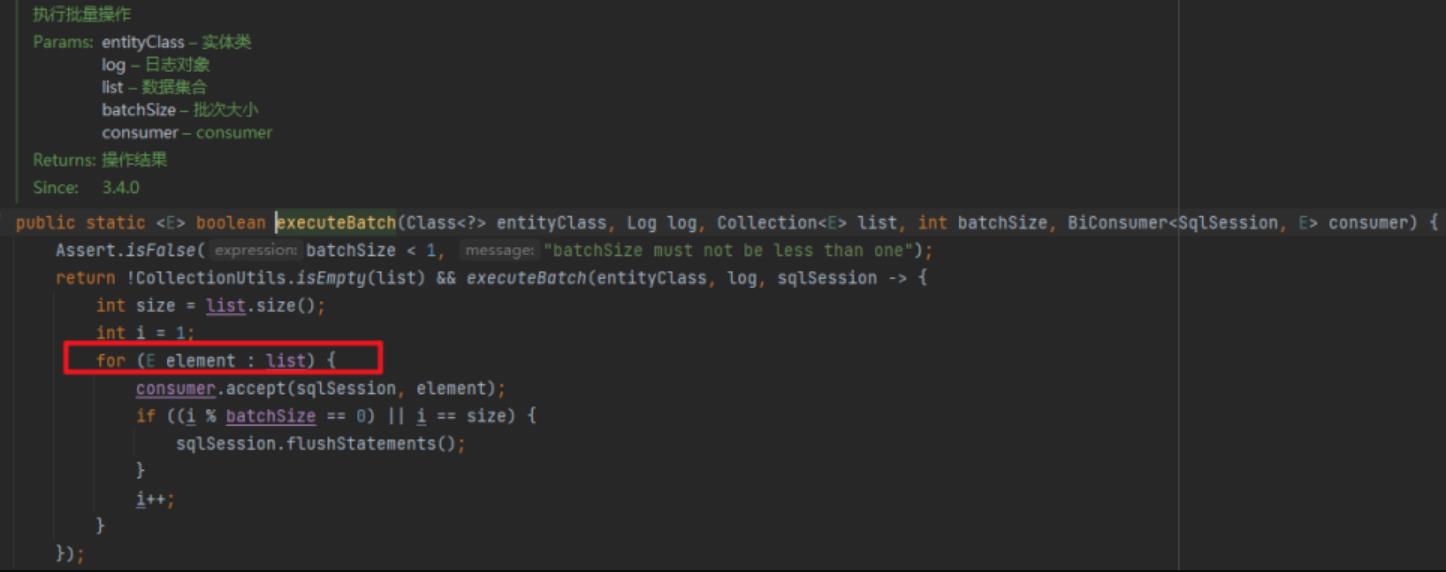
然后累计一定数量后,一批 flush。从这点来看,这个 saveBach 的性能肯定比直接一条一条 insert 快。
我直接进行一个粗略的实验,简单创建了一张表来对比一波!
1、1000条数据,一条一条插入
@Test void MybatisPlusSaveOne() SqlSession sqlSession = sqlSessionFactory.openSession(); try StopWatch stopWatch = new StopWatch(); stopWatch.start("mybatis plus save one"); for (int i = 0; i < 1000; i++) OpenTest openTest = new OpenTest(); openTest.setA("a" + i); openTest.setB("b" + i); openTest.setC("c" + i); openTest.setD("d" + i); openTest.setE("e" + i); openTest.setF("f" + i); openTest.setG("g" + i); openTest.setH("h" + i); openTest.setI("i" + i); openTest.setJ("j" + i); openTest.setK("k" + i); //一条一条插入 openTestService.save(openTest); sqlSession.commit(); stopWatch.stop(); log.info("mybatis plus save one:" + stopWatch.getTotalTimeMillis()); finally sqlSession.close();

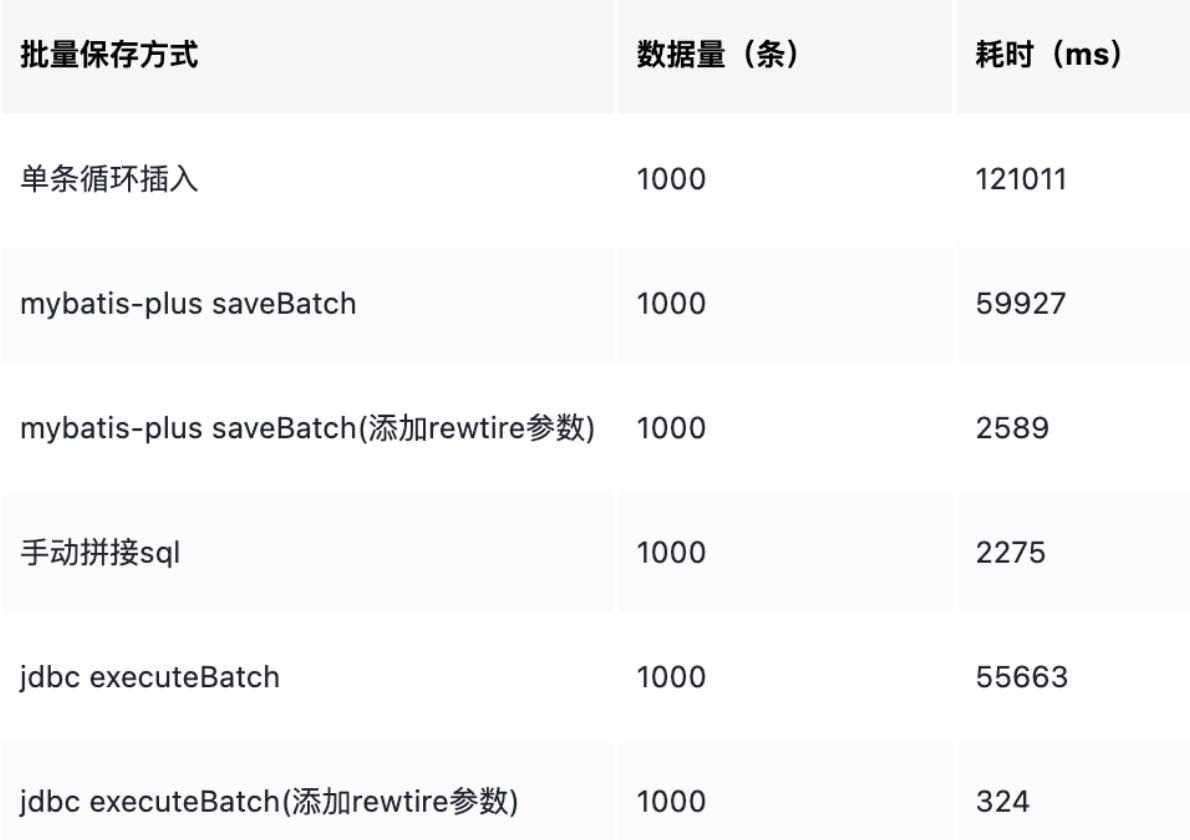
可以看到,执行一批 1000 条数的批量保存,耗费的时间是 121011 毫秒。
2、1000条数据用 mybatis-plus 自带的 saveBatch 插入
@Test void MybatisPlusSaveBatch() SqlSession sqlSession = sqlSessionFactory.openSession(); try List<OpenTest> openTestList = new ArrayList<>(); for (int i = 0; i < 1000; i++) OpenTest openTest = new OpenTest(); openTest.setA("a" + i); openTest.setB("b" + i); openTest.setC("c" + i); openTest.setD("d" + i); openTest.setE("e" + i); openTest.setF("f" + i); openTest.setG("g" + i); openTest.setH("h" + i); openTest.setI("i" + i); openTest.setJ("j" + i); openTest.setK("k" + i); openTestList.add(openTest); StopWatch stopWatch = new StopWatch(); stopWatch.start("mybatis plus save batch"); //批量插入 openTestService.saveBatch(openTestList); sqlSession.commit(); stopWatch.stop(); log.info("mybatis plus save batch:" + stopWatch.getTotalTimeMillis()); finally sqlSession.close();

耗费的时间是 59927 毫秒,比一条一条插入快了一倍,从这点来看,效率还是可以的。
然后常见的还有一种利用拼接 SQL 方式来实现批量插入,我们也来对比试试看性能如何。
3、1000 条数据用手动拼接 SQL 方式插入, 搞个手动拼接:

来跑跑下性能如何:
@Test void MapperSaveBatch() SqlSession sqlSession = sqlSessionFactory.openSession(); try List<OpenTest> openTestList = new ArrayList<>(); for (int i = 0; i < 1000; i++) OpenTest openTest = new OpenTest(); openTest.setA("a" + i); openTest.setB("b" + i); openTest.setC("c" + i); openTest.setD("d" + i); openTest.setE("e" + i); openTest.setF("f" + i); openTest.setG("g" + i); openTest.setH("h" + i); openTest.setI("i" + i); openTest.setJ("j" + i); openTest.setK("k" + i); openTestList.add(openTest); StopWatch stopWatch = new StopWatch(); stopWatch.start("mapper save batch"); //手动拼接批量插入 openTestMapper.saveBatch(openTestList); sqlSession.commit(); stopWatch.stop(); log.info("mapper save batch:" + stopWatch.getTotalTimeMillis()); finally sqlSession.close();

耗时只有 2275 毫秒,性能比 mybatis-plus 自带的 saveBatch 好了 26 倍!
这时,我又突然回想起以前直接用 JDBC 批量保存的接口,那都到这份上了,顺带也跑跑看!
4、1000 条数据用 JDBC executeBatch 插入
@Test void JDBCSaveBatch() throws SQLException SqlSession sqlSession = sqlSessionFactory.openSession(); Connection connection = sqlSession.getConnection(); connection.setAutoCommit(false); String sql = "insert into open_test(a,b,c,d,e,f,g,h,i,j,k) values(?,?,?,?,?,?,?,?,?,?,?)"; PreparedStatement statement = connection.prepareStatement(sql); try for (int i = 0; i < 1000; i++) statement.setString(1,"a" + i); statement.setString(2,"b" + i); statement.setString(3, "c" + i); statement.setString(4,"d" + i); statement.setString(5,"e" + i); statement.setString(6,"f" + i); statement.setString(7,"g" + i); statement.setString(8,"h" + i); statement.setString(9,"i" + i); statement.setString(10,"j" + i); statement.setString(11,"k" + i); statement.addBatch(); StopWatch stopWatch = new StopWatch(); stopWatch.start("JDBC save batch"); statement.executeBatch(); connection.commit(); stopWatch.stop(); log.info("JDBC save batch:" + stopWatch.getTotalTimeMillis()); finally statement.close(); sqlSession.close();

耗时是 55663 毫秒,所以 JDBC executeBatch 的性能跟 mybatis-plus 的 saveBatch 一样(底层一样)。
综上所述,拼接 SQL 的方式实现批量保存效率最佳。
但是我又不太甘心,总感觉应该有什么别的法子,然后我就继续跟着 mybatis-plus 的源码 debug 了一下,跟到了 MySQL 的驱动,突然发现有个 if 里面的条件有点显眼:
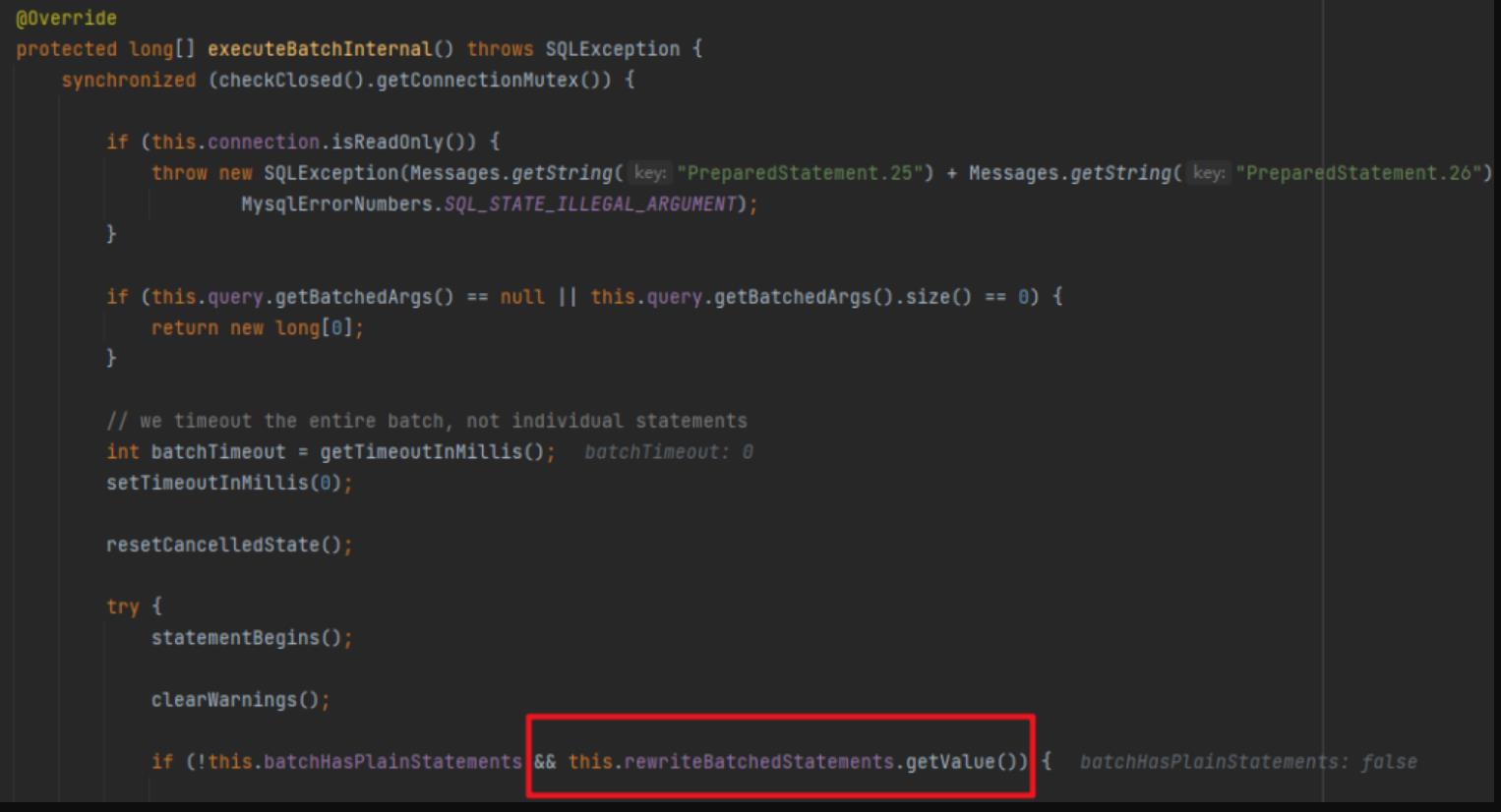
就是这个叫 rewriteBatchedStatements 的玩意,从名字来看是要重写批操作的 Statement,前面batchHasPlainStatements 已经是 false,取反肯定是 true,所以只要这参数是 true 就会进行一波操作。
我看了下默认是 false。
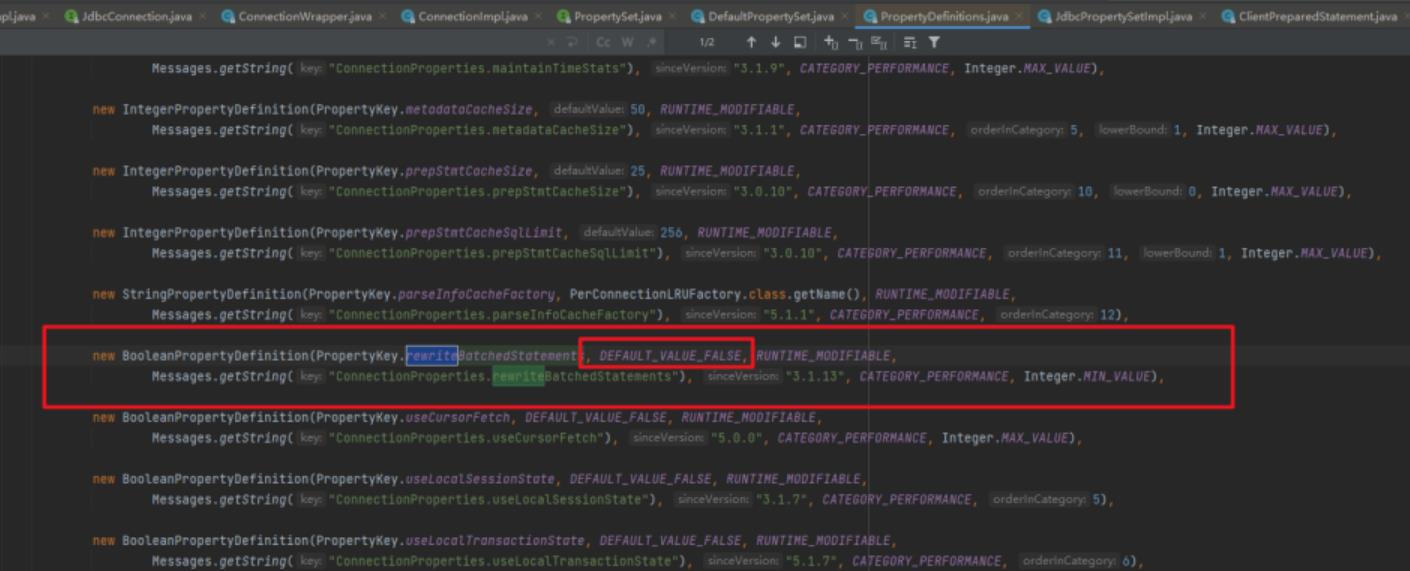
同时我也上网查了下 rewriteBatchedStatements 参数,好家伙,好像有用!
直接将 jdbcurl 加上了这个参数:

然后继续跑了下 mybatis-plus 自带的 saveBatch,果然性能大大提高,跟拼接 SQL 差不多!

顺带我也跑了下 JDBC 的 executeBatch ,果然也提高了。

然后我继续 debug ,来探探 rewriteBatchedStatements 究竟是怎么 rewrite 的! 如果这个参数是 true,则会执行下面的方法且直接返回:

看下 executeBatchedInserts 究竟干了什么:

看到上面我圈出来的代码没,好像已经有点感觉了,继续往下 debug。
果然!SQL 语句被 rewrite了:
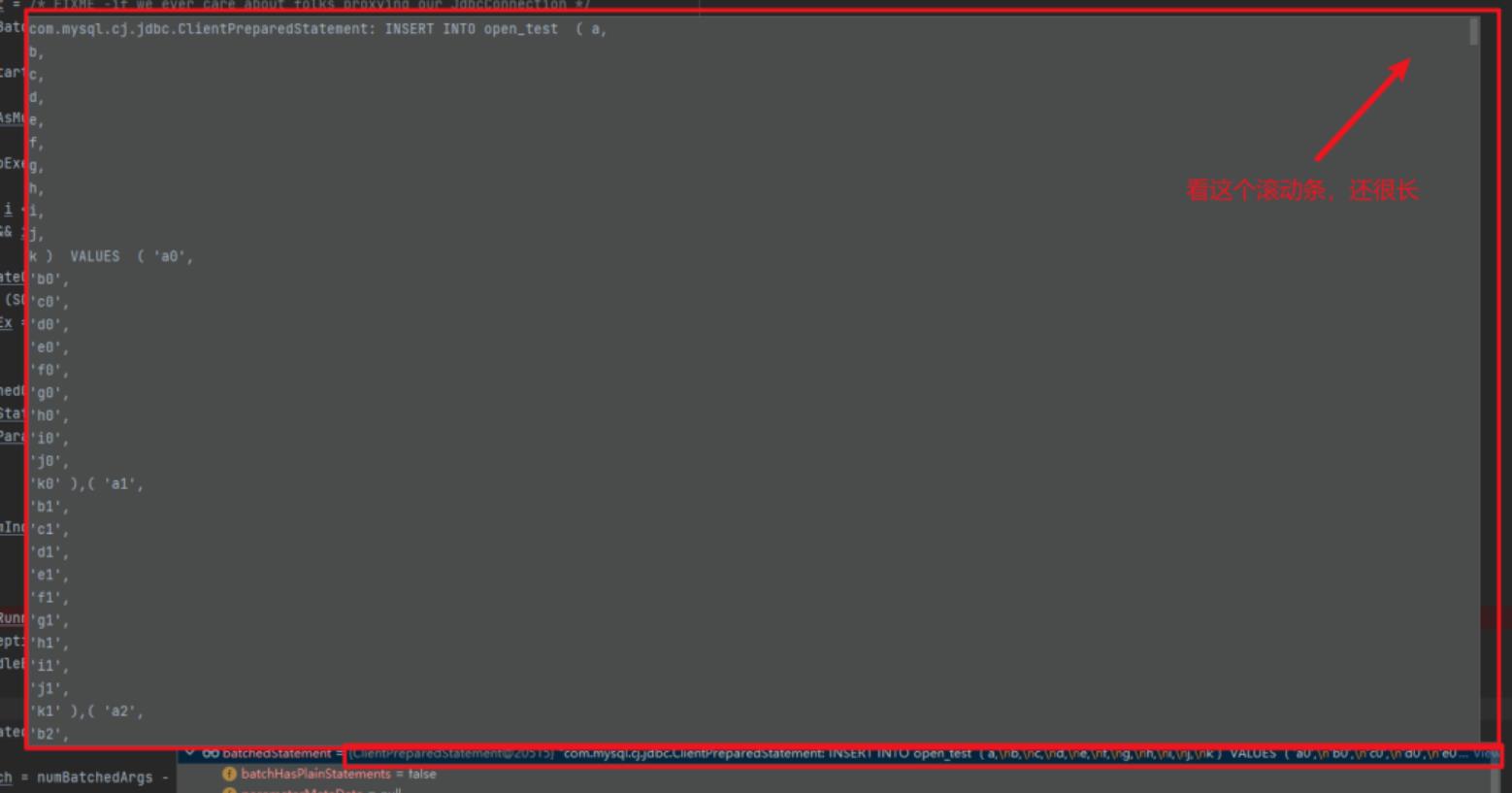
对插入而言,所谓的 rewrite 其实就是将一批插入拼接成 insert into xxx values (a),(b),(c)...这样一条语句的形式然后执行,这样一来跟拼接 SQL 的效果是一样的。
那为什么默认不给这个参数设置为 true 呢?主要有以下两点:
如果批量语句中的某些语句失败,则默认重写会导致所有语句都失败。
批量语句的某些语句参数不一样,则默认重写会使得查询缓存未命中。
看起来影响不大,所以我给我的项目设置上了这个参数!
最后
稍微总结下我粗略的对比(虽然粗略,但实验结果符合原理层面的理解),如果你想更准确地做实验,可以使用 JMH,并且测试更多组数(如 5000,10000等)的情况。
所以如果有使用 JDBC 的 Batch 性能方面的需求,要将 rewriteBatchedStatements 设置为 true,这样能提高很多性能。
然后如果喜欢手动拼接 SQL 要注意一次拼接的数量,分批处理。
JVM性能调优
JVM技术图谱
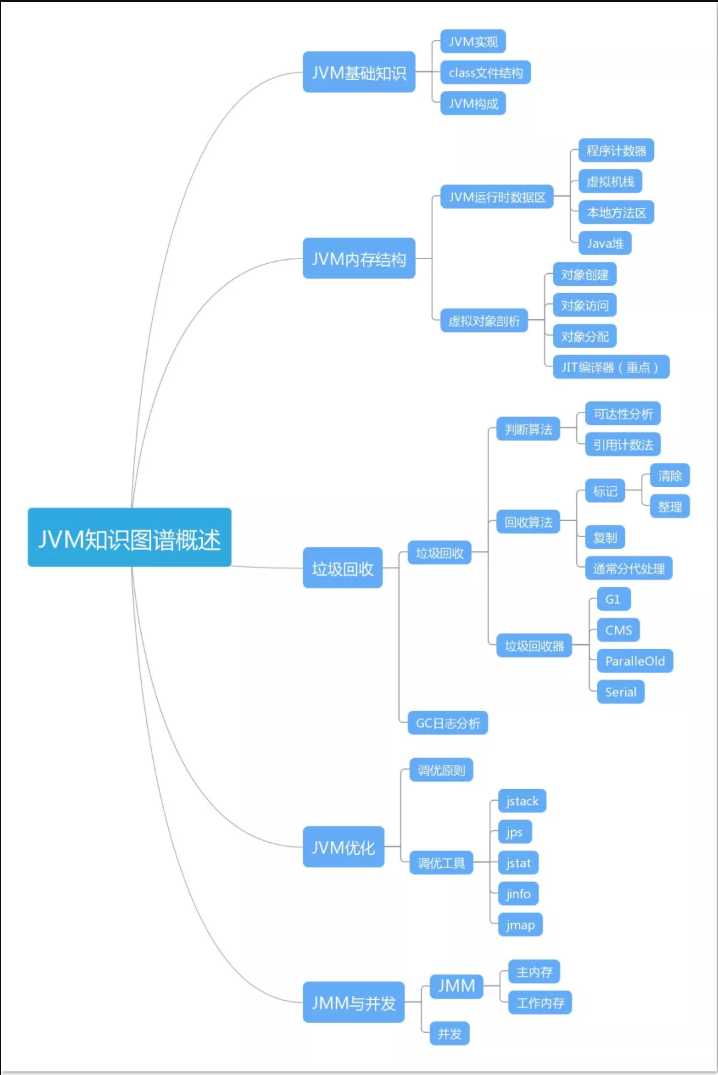
性能调优
性能调优包含多个层次,比如:架构调优、代码调优、JVM调优、数据库调优、操作系统调优等。
架构调优和代码调优是JVM调优的基础,其中架构调优是对系统影响最大的。
性能调优基本上按照以下步骤进行:明确优化目标、发现性能瓶颈、性能调优、通过监控及数据统计工具获得数据、确认是否达到目标。
何时进行JVM调优
遇到以下情况,就需要考虑进行JVM调优了:
- Heap内存(老年代)持续上涨达到设置的最大内存值;
- Full GC 次数频繁;
- GC 停顿时间过长(超过1秒);
- 应用出现OutOfMemory 等内存异常;
- 应用中有使用本地缓存且占用大量内存空间;
- 系统吞吐量与响应性能不高或下降。
JVM调优的基本原则
JVM调优是一个手段,但并不一定所有问题都可以通过JVM进行调优解决,因此,在进行JVM调优时,我们要遵循一些原则:
- 大多数的Java应用不需要进行JVM优化;
- 大多数导致GC问题的原因是代码层面的问题导致的(代码层面);
- 上线之前,应先考虑将机器的JVM参数设置到最优;
- 减少创建对象的数量(代码层面);
- 减少使用全局变量和大对象(代码层面);
- 优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
- 分析GC情况优化代码比优化JVM参数更好(代码层面);
通过以上原则,我们发现,其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
JVM调优目标
调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。jvm调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量。
- 延迟:GC低停顿和GC低频率;
- 低内存占用;
- 高吞吐量;
其中,任何一个属性性能的提高,几乎都是以牺牲其他属性性能的损为代价的,不可兼得。具体根据在业务中的重要性确定。
JVM调优量化目标
下面展示了一些JVM调优的量化目标参考实例:
- Heap 内存使用率 <= 70%;
- Old generation内存使用率<= 70%;
- avgpause <= 1秒;
- Full gc 次数0 或 avg pause interval >= 24小时 ;
注意:不同应用的JVM调优量化目标是不一样的。
JVM调优的步骤
一般情况下,JVM调优可通过以下步骤进行:
- 分析GC日志及dump文件,判断是否需要优化,确定瓶颈问题点;
- 确定JVM调优量化目标;
- 确定JVM调优参数(根据历史JVM参数来调整);
- 依次调优内存、延迟、吞吐量等指标;
- 对比观察调优前后的差异;
- 不断的分析和调整,直到找到合适的JVM参数配置;
- 找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪。
以上操作步骤中,某些步骤是需要多次不断迭代完成的。一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。
JVM参数
JVM调优最重要的工具就是JVM参数了。先来了解一下JVM参数相关内容。
-XX 参数被称为不稳定参数,此类参数的设置很容易引起JVM 性能上的差异,使JVM存在极大的不稳定性。如果此类参数设置合理将大大提高JVM的性能及稳定性。
不稳定参数语法规则包含以下内容。
布尔类型参数值:
- -XX:+ ‘+’表示启用该选项
- -XX:- ‘-‘表示关闭该选项
数字类型参数值:
- -XX:=给选项设置一个数字类型值,可跟随单位,例如:’m’或’M’表示兆字节;’k’或’K’千字节;’g’或’G’千兆字节。32K与32768是相同大小的。
字符串类型参数值:
- -XX:=给选项设置一个字符串类型值,通常用于指定一个文件、路径或一系列命令列表。例如:-XX:HeapDumpPath=./dump.core
JVM参数解析及调优
比如以下参数示例:
- -Xmx4g –Xms4g –Xmn1200m –Xss512k -XX:NewRatio=4 -XX:SurvivorRatio=8 -XX:PermSize=100m -XX:MaxPermSize=256m -XX:MaxTenuringThreshold=15
上面为Java7及以前版本的示例,在Java8中永久代的参数-XX:PermSize和-XX:MaxPermSize已经失效。这在前面章节中已经讲到。
参数解析:
- -Xmx4g:堆内存最大值为4GB。
- -Xms4g:初始化堆内存大小为4GB。
- -Xmn1200m:设置年轻代大小为1200MB。增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
- -Xss512k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1MB,以前每个线程堆栈大小为256K。应根据应用线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
- -XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
- -XX:SurvivorRatio=8:设置年轻代中Eden区与Survivor区的大小比值。设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
- -XX:PermSize=100m:初始化永久代大小为100MB。
- -XX:MaxPermSize=256m:设置持久代大小为256MB。
- -XX:MaxTenuringThreshold=15:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
新生代、老生代、永久代的参数,如果不进行指定,虚拟机会自动选择合适的值,同时也会基于系统的开销自动调整。
可调优参数:
-Xms:初始化堆内存大小,默认为物理内存的1/64(小于1GB)。
-Xmx:堆内存最大值。默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。
-Xmn:新生代大小,包括Eden区与2个Survivor区。
-XX:SurvivorRatio=1:Eden区与一个Survivor区比值为1:1。
-XX:MaxDirectMemorySize=1G:直接内存。报java.lang.OutOfMemoryError: Direct buffer memory异常可以上调这个值。
-XX:+DisableExplicitGC:禁止运行期显式地调用System.gc()来触发fulll GC。
注意: Java RMI的定时GC触发机制可通过配置-Dsun.rmi.dgc.server.gcInterval=86400来控制触发的时间。
-XX:CMSInitiatingOccupancyFraction=60:老年代内存回收阈值,默认值为68。
-XX:ConcGCThreads=4:CMS垃圾回收器并行线程线,推荐值为CPU核心数。
-XX:ParallelGCThreads=8:新生代并行收集器的线程数。
-XX:MaxTenuringThreshold=10:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
-XX:CMSFullGCsBeforeCompaction=4:指定进行多少次fullGC之后,进行tenured区 内存空间压缩。
-XX:CMSMaxAbortablePrecleanTime=500:当abortable-preclean预清理阶段执行达到这个时间时就会结束。
在设置的时候,如果关注性能开销的话,应尽量把永久代的初始值与最大值设置为同一值,因为永久代的大小调整需要进行FullGC才能实现。
内存优化示例
当JVM运行稳定之后,触发了FullGC我们一般会拿到如下信息:

以上gc日志中,在发生fullGC之时,整个应用的堆占用以及GC时间。为了更加精确需多次收集,计算平均值。或者是采用耗时最长的一次FullGC来进行估算。上图中,老年代空间占用在93168kb(约93MB),以此定为老年代空间的活跃数据。则其他堆空间的分配,基于以下规则来进行。
- java heap:参数-Xms和-Xmx,建议扩大至3-4倍FullGC后的老年代空间占用。
- 永久代:-XX:PermSize和-XX:MaxPermSize,建议扩大至1.2-1.5倍FullGc后的永久带空间占用。
- 新生代:-Xmn,建议扩大至1-1.5倍FullGC之后的老年代空间占用。
- 老年代:2-3倍FullGC后的老年代空间占用。
基于以上规则,则对参数定义如下:
- java -Xms373m -Xmx373m -Xmn140m -XX:PermSize=5m -XX:MaxPermSize=5m
延迟优化示例
对延迟性优化,首先需要了解延迟性需求及可调优的指标有哪些。
- 应用程序可接受的平均停滞时间: 此时间与测量的Minor
- GC持续时间进行比较。可接受的Minor GC频率:Minor
- GC的频率与可容忍的值进行比较。
- 可接受的最大停顿时间:最大停顿时间与最差情况下FullGC的持续时间进行比较。
- 可接受的最大停顿发生的频率:基本就是FullGC的频率。
其中,平均停滞时间和最大停顿时间,对用户体验最为重要。对于上面的指标,相关数据采集包括:MinorGC的持续时间、统计MinorGC的次数、FullGC的最差持续时间、最差情况下,FullGC的频率。
")
如上图,Minor GC的平均持续时间0.069秒,MinorGC的频率为0.389秒一次。
新生代空间越大,Minor GC的GC时间越长,频率越低。如果想减少其持续时长,就需要减少其空间大小。如果想减小其频率,就需要加大其空间大小。
这里以减少了新生代空间10%的大小,来减小延迟时间。在此过程中,应该保持老年代和持代的大小不变化。调优后的参数如下变化:
- java -Xms359m -Xmx359m -Xmn126m -XX:PermSize=5m -XX:MaxPermSize=5m
吞吐量调优
吞吐量调优主要是基于应用程序的吞吐量要求而来的,应用程序应该有一个综合的吞吐指标,这个指标基于整个应用的需求和测试而衍生出来的。
评估当前吞吐量和目标差距是否巨大,如果在20%左右,可以修改参数,加大内存,再次从头调试,如果巨大就需要从整个应用层面来考虑,设计以及目标是否一致了,重新评估吞吐目标。
对于垃圾收集器来说,提升吞吐量的性能调优的目标就是尽可能避免或者很少发生FullGC或者Stop-The-World压缩式垃圾收集(CMS),因为这两种方式都会造成应用程序吞吐降低。尽量在MinorGC 阶段回收更多的对象,避免对象提升过快到老年代。
调优工具
借助GCViewer日志分析工具,可以非常直观地分析出待调优点。可从以下几方面来分析:
Memory,分析Totalheap、Tenuredheap、Youngheap内存占用率及其他指标,理论上内存占用率越小越好;
Pause,分析Gc pause、Fullgc pause、Total pause三个大项中各指标,理论上GC次数越少越好,GC时长越小越好;
原文链接:《JVM性能调优详解》
本文参考:
(1)https://blog.csdn.net/jisuanjiguoba/article/details/80176223
(2)https://juejin.im/post/59f02f406fb9a0451869f01c
《面试官》系列文章:
以上是关于MyBatissaveBatch 性能调优的主要内容,如果未能解决你的问题,请参考以下文章