Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法相关的知识,希望对你有一定的参考价值。
原文地址https://www.cnblogs.com/zhaof/p/7198407.html
这篇文章中写了常用的下载中间件的用法和例子。
Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以从这里我们可以知道下载中间件是介于Scrapy的request/response处理的钩子,用于修改Scrapy request和response。
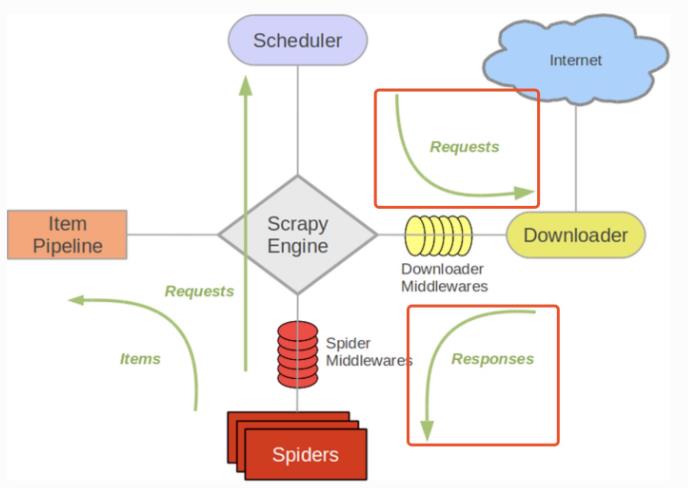
编写自己的下载器中间件
编写下载器中间件,需要定义以下一个或者多个方法的python类
为了演示这里的中间件的使用方法,这里创建一个项目作为学习,这里的项目是关于爬去httpbin.org这个网站
scrapy startproject httpbintest
cd httpbintest
scrapy genspider example example.com
创建好后的目录结构如下:
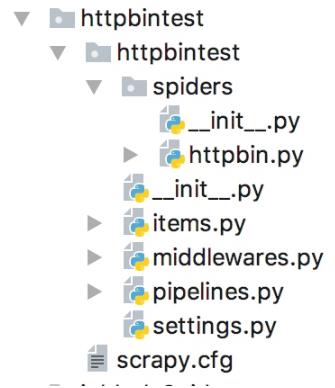
这里我们先写一个简单的代理中间件来实现ip的伪装
创建好爬虫之后我们讲httpbin.py中的parse方法改成:
def parse(self, response):
print(response.text)
然后通过命令行启动爬虫:scrapy crawl httpbin

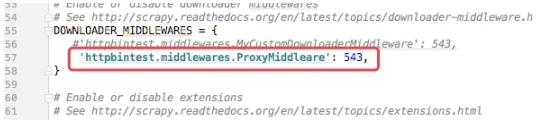
而我们要做就是通过代理中间件来实现ip的伪装,在middleares.py中写如下的中间件类:

class ProxyMiddleare(object):
logger = logging.getLogger(__name__)
def process_request(self,request, spider):
self.logger.debug("Using Proxy")
request.meta[\'proxy\'] = \'http://127.0.0.1:9743\'
return None
这里因为我本地有一个代理FQ地址为:http://127.0.0.1:9743
所以直接设置为代理用,代理的地址为日本的ip
然后在settings.py配置文件中开启下载中间件的功能,默认是关闭的
然后我们再次启动爬虫:scrapy crawl httpbin
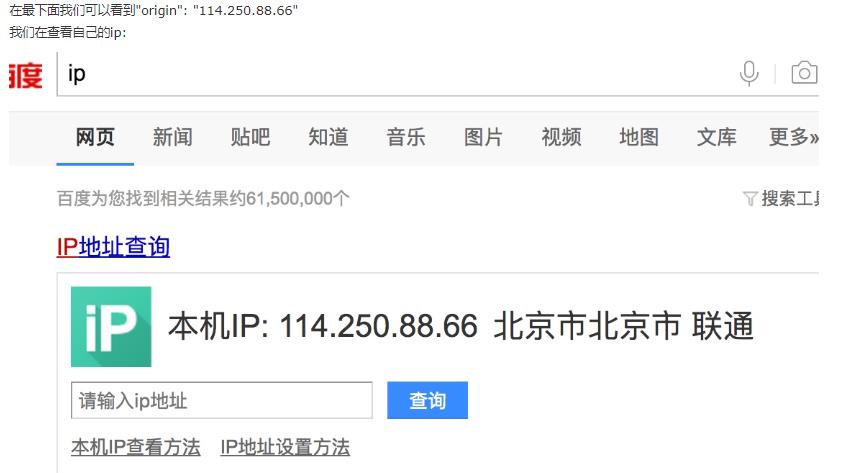
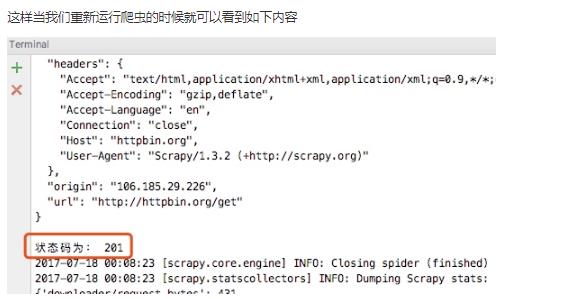
从下图的输入日志中我们可以看书我们定义的中间件已经启动,并且输入了我们打印的日志信息,并且我们查看origin的ip地址也已经成了日本的ip地址,这样我们的代理中间件成功了
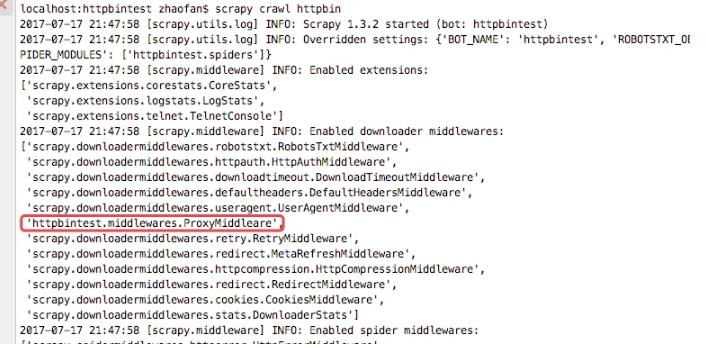
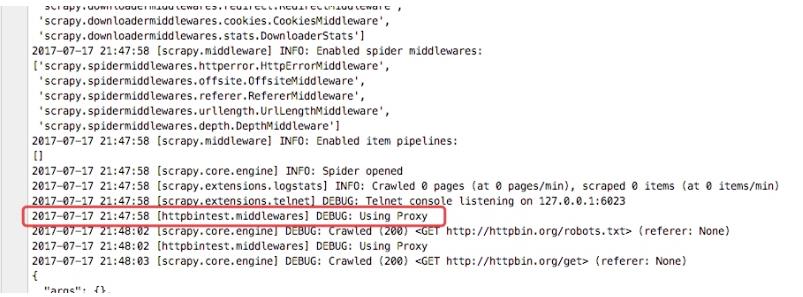
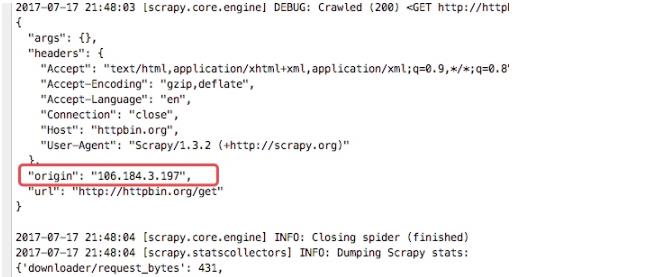
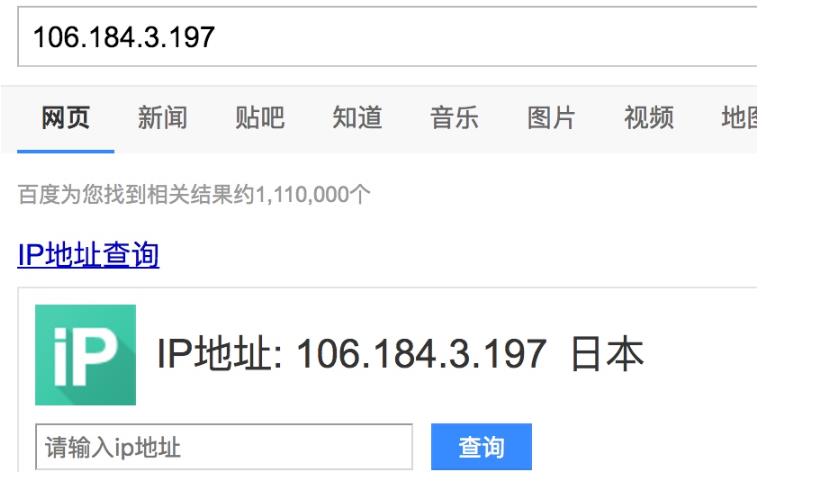
详细说明
class Scrapy.downloadermiddleares.DownloaderMiddleware
process_request(request,spider)
当每个request通过下载中间件时,该方法被调用,这里有一个要求,该方法必须返回以下三种中的任意一种:None,返回一个Response对象,返回一个Request对象或raise IgnoreRequest。三种返回值的作用是不同的。
None:Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该request被执行(其response被下载)。
Response对象:Scrapy将不会调用任何其他的process_request()或process_exception() 方法,或相应地下载函数;其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
Request对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
raise一个IgnoreRequest异常:则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录。
process_response(request, response, spider)
process_response的返回值也是有三种:response对象,request对象,或者raise一个IgnoreRequest异常
如果其返回一个Response(可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
这里我们写一个简单的例子还是上面的项目,我们在中间件中继续添加如下代码:
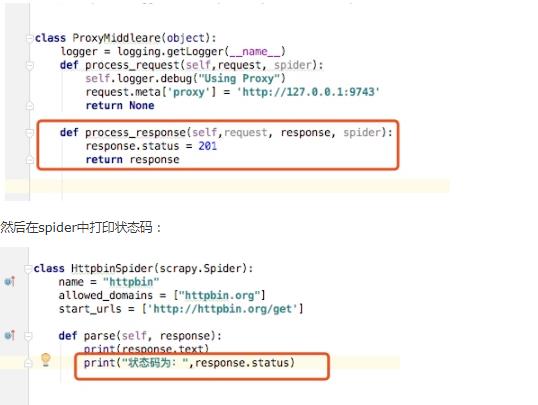
process_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时,Scrapy调用 process_exception()。
process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
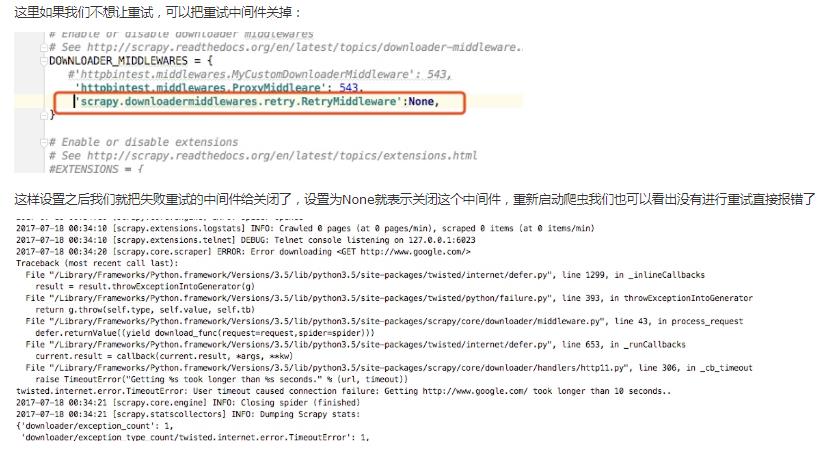
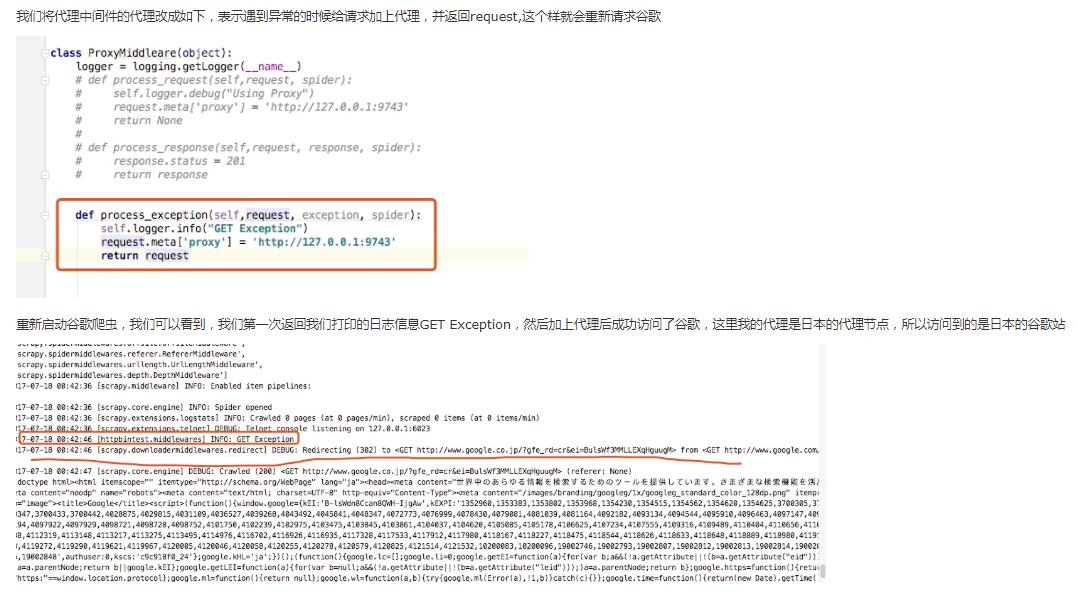
如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。 这个是非常有用的,就相当于如果我们失败了可以在这里进行一次失败的重试,例如当我们访问一个网站出现因为频繁爬取被封ip就可以在这里设置增加代理继续访问,我们通过下面一个例子演示
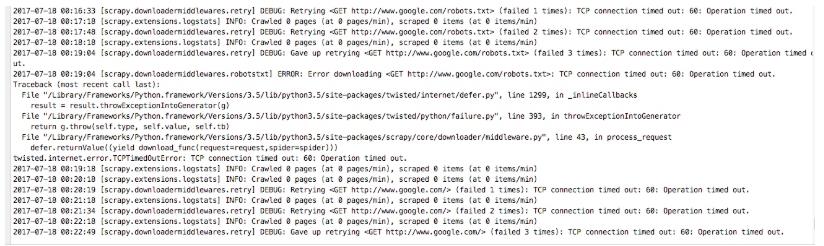
scrapy genspider google www.google.com 这里我们创建一个谷歌的爬虫,
然后启动scrapy crawl google,可以看到如下情况:
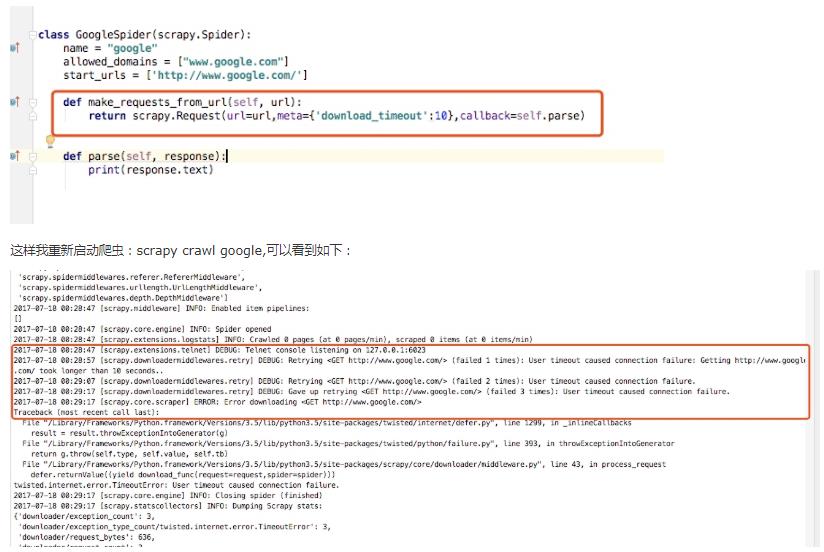
这里我们就写一个中间件,当访问失败的时候增加代理
首先我们把google.py代码进行更改,这样是白超时时间设置为10秒要不然等待太久,这个就是我们将spider里的时候的讲过的make_requests_from_url,这里我们把这个方法重写,并将等待超时时间设置为10s
以上是关于Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法的主要内容,如果未能解决你的问题,请参考以下文章