HDFS学习基础
Posted duoduomu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS学习基础相关的知识,希望对你有一定的参考价值。
一、HDFS基础知识
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
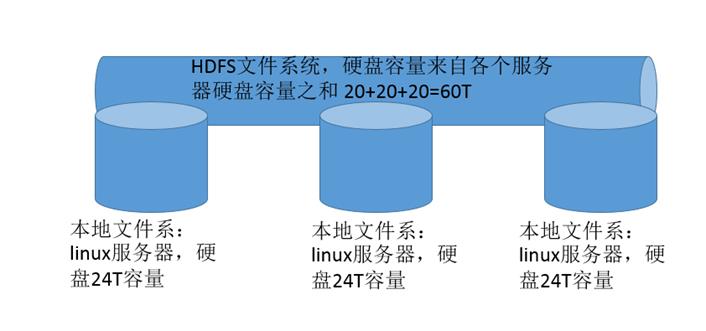 马拉车图上传失败,后续补充
马拉车图上传失败,后续补充
HDFS特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间目录树来定位文件;
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
master/slave架构
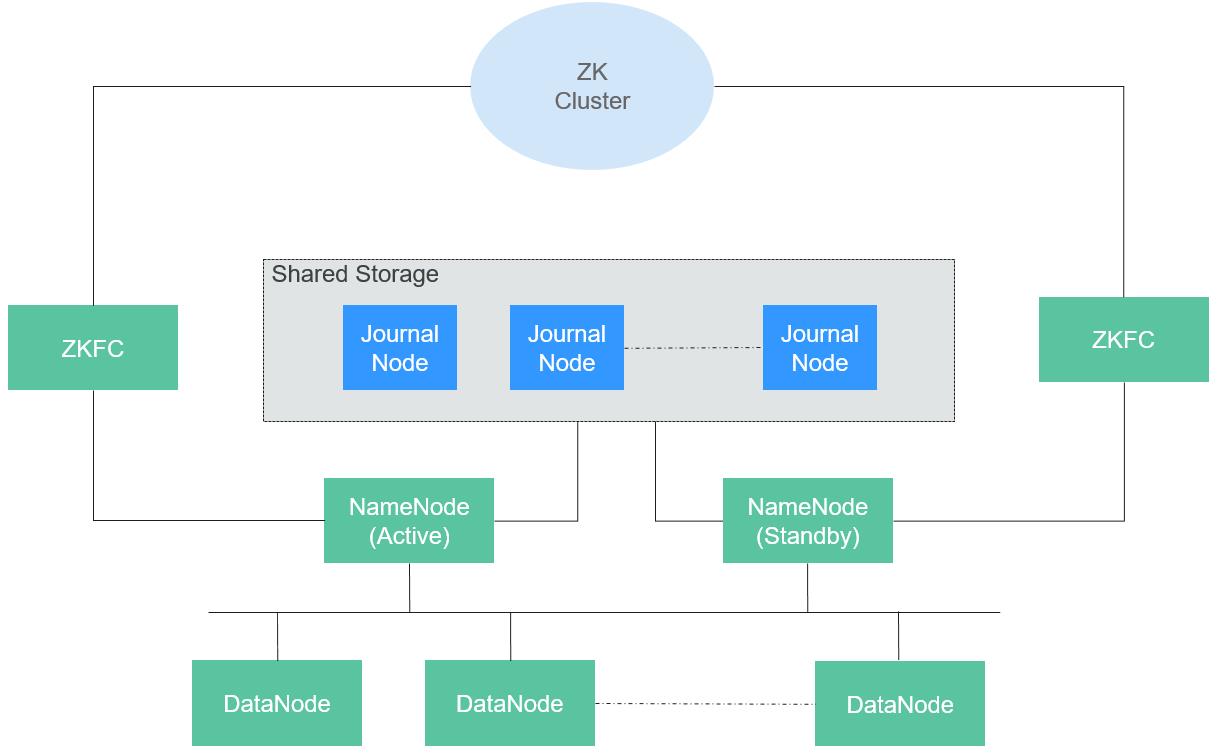
HA模式的HDFS集群包含主、备NameNode和多个DataNode,采用 master/slave 架构,在Master上运行NameNode,而在每一个Slave上运行DataNode,ZKFC需要和NameNode一起运行。注意datanode和namende之间维护的通信机制,基于TCP/IP,datanode会定期向主备namenode汇报是否挂掉,具体的block块数。balancing:负载均衡机制,如果datanode1上放了100个block块,datanode2上放了80个,那么有新的block块尽量往datanode2上放。
针对于该图的详细信息参考华为云官方文档:
https://support.huaweicloud.com/devg3-mrs/mrs_07_300003.html
https://support.huaweicloud.com/productdesc-mrs/mrs_08_000701.html
分块存储
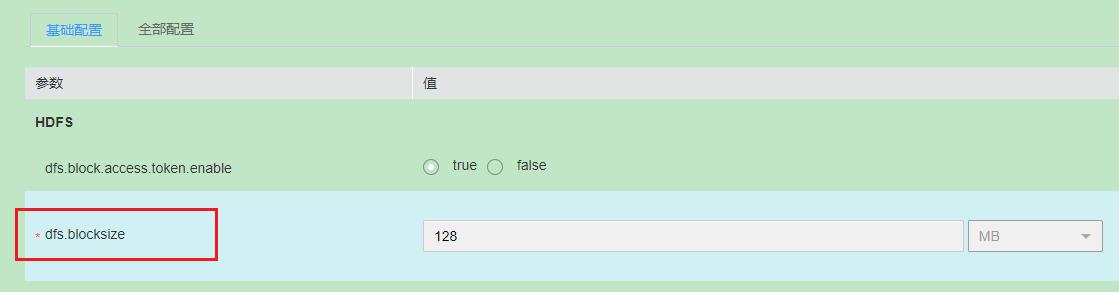
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,MRS 3.1.1版本默认大小128MB,参考hdfs服务的基础配置参数:dfs.blocksize

命名空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。Namenode 负责维护文件系统的命名空间,任何对文件系统命名空间或属性的修改都将被Namenode 记录下来。HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。hdfs客户端说明参考华为云官网:https://support.huaweicloud.com/devg3-mrs/mrs_07_300003.html
Namenode 元数据管理
我们把目录结构及文件分块位置信息叫做元数据。Namenode 负责维护整个hdfs文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的id,及所在的datanode 服务器)。
Datanode 数据存储
文件的各个 block 的具体存储管理由 datanode 节点承担。每一个 block 都可以在多个datanode 上。Datanode 需要定时向 主备Namenode 汇报自己持有的 block信息。存储多个副本。
副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本数可以在文件创建的时候指定,也可以在之后改变。MRS服务默认副本数信息
参考hdfs服务的基础配置参数:dfs.replication


MRS服务的副本数默认值区别于节点类型和存储盘类型选择,详情参考:https://support.huaweicloud.com/productdesc-mrs/mrs_08_000701.html
一次写入,多次读出
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改。
正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
Hadoop文件系统补充说明:具体详细参见hadoop权威指南第三版第59页。
二、HDFS常用命令
fs、dfs区别
(1) fs是文件系统, dfs是分布式文件系统。
(2) fs > dfs。
(3) 分布式环境情况下,fs与dfs无区别。
(4) 本地环境中,fs就是本地文件,dfs就不能用了。
(5) fs涉及到一个通用的文件系统,可以指向任何的文件系统如local,HDFS,HSTP,S3等。但是dfs仅是针对HDFS的。
(6) 查看本地文件系统,根目录下的文件:hadoop fs -ls file:///
常用hdfs命令
1、显示HDFS目录信息:hdfs dfs -ls [-R] <args>
样例:
hdfs dfs -ls /user
hdfs dfs -ls /user/yarn/ats
hdfs dfs -ls -R /user/yarn/ats
说明:-R参数会以递归的方式显示出全部子目录
2、创建HDFS目录:hdfs dfs -mkdir [-p] <paths>
样例:
hdfs dfs -mkdir /user/bbb
hdfs dfs -mkdir -p /user/ccc/ddd
说明:创建的目录中如果存在没有创建的父目录,需要使用 -p参数,如果在hdfs根目录下创建文件目录需要具有超级管理员的权限
3、将本地文件移动到hdfs目录:hdfs dfs -moveFromLocal <localsrc><dst>
样例:
hdfs dfs -moveFromLocal a.txt /user/aaa
hdfs dfs -moveFromLocal 1.txt 2.txt /user/aaa
说明:文件从本地移动到HDFS文件系统之后,本地不保留,该命令是移动,不是纯上传,支持同时移动多个文件
4、从本地上传一个或多个文件到hdfs目录:hdfs dfs -put <localsrc> ... <dst>
样例:
hdfs dfs -put 3.txt 4.txt 5.txt /user/aaa
说明:文件从本地上传到hdfs文件系统,本地文件继续保留,支持多个文件上传,命令等同于copyFromLocal
5、从hdfs一个目录移动文件到另一个目录:hdfs dfs -mv URI [URI ...] <dest>
样例:
hdfs dfs -mv /user/aaa/a.txt /user/bbb/a.txt
hdfs dfs -mv /user/aaa/1.txt /user/aaa/2.txt /user/aaa/3.txt /user/bbb
说明:目的端的目录一定要存在,移动多个文件时,目的端参数要是一个指定的目录,不能设置为具体文件
6、从hdfs一个目录拷贝文件或目录到另一个目录,可以覆盖,可以保留原有权限信息:hdfs dfs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>
样例:
hdfs dfs -cp /user/aaa/4.txt /user/bbb/4.txt
hdfs dfs -cp /user/aaa/4.txt /user/aaa/5.txt /user/bbb
hdfs dfs -cp -f /user/aaa/4.txt /user/aaa/5.txt /user/bbb
说明:可以拷贝hdfs上一个或多个文件、目录到另一个目录,如果不设置-f参数,则不会有覆盖的效果

7、查看hdfs目录上的文件:hdfs dfs -cat URI [URI ...]
样例:
hdfs dfs -cat /user/aaa/4.txt
hdfs dfs -cat /user/aaa/4.txt /user/aaa/5.txt
说明:可以同时看多个文件,如果是压缩格式的文件可能会失效
8、追加本地文件内容到hdfs指定的文件中:hdfs dfs -appendToFile <localsrc> ... <dst>
样例:
hdfs dfs -appendToFile 5.txt /user/aaa/4.txt
hdfs dfs -appendToFile 1.txt 2.txt /user/aaa/4.txt
说明:可以追加多个文件
9、删除文件或目录:hdfs dfs -rm [-f] [-r|-R] [-skipTrash] URI [URI ...]
样例:
hdfs dfs -rm /user/aaa/4.txt
hdfs dfs -rm -R /user/cccc

说明:删除命令是把文件或者目录移动到垃圾箱(类似windows系统回收站),此时还没有彻底删除文件,需要清理垃圾箱之后才能彻底删除文件
hdfs dfs -rmr 这个命令也可用,但是已被废弃(deprecated),替换为:hdfs dfs -rm -r
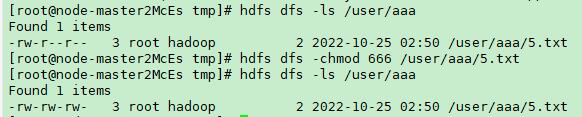
10、修改目录权限:hdfs dfs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
样例:
hdfs dfs -chmod 666 /user/aaa/5.txt
其他:
清空垃圾箱:hdfs dfs -expunge,该命令不能直接在MRS集群上使用,会报错,可以使用rm相关密令直接删除指定目录
其他常用命令参考:https://blog.51cto.com/u_15105906/5167794
hdfs的高级命令:限制文件目录整体大小、限制目录文件个数、查看hdfs集群安全模式信息等命令在MRS集群上被限制使用或者使用不了,不推荐使用,感兴趣可参考文档:https://blog.csdn.net/qq_45841239/article/details/108527942
三、HDFS HA架构
HA架构图上传失败(后续维护补充)
备注:上图中NN代表namenode,os代表操作系统,hw代表硬件(hardware),Failover是故障转移机制,datanode栅栏防御:每次只从一个NameNode更新信息
1、 在一个典型的HA集群中,需要把两个NameNodes配置在两台独立的机器上。在任何一个时间点,只有一个NameNode处于Active状态,另一个处于Standby状态。Active节点负责处理所有客户端操作,Standby节点时刻保持与Active节点同步的状态以便在必要时进行快速主备切换。NameNode是一个中心服务器,负责管理文件系统的命名空间(namespace,本质就是namenode维护的各种各样的元数据)以及客户端对文件的访问。
2、 文件操作,namenode是负责文件元数据的操作,datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过Namenode,只询问它跟哪个dataNode联系,否则NameNode会成为系统的瓶颈,副本存放在哪些Datanode上由NameNode来控制,根据全局情况作出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低读取网络开销和读取延时。
3、 NameNode全权管理数据库的复制,它周期性的从集群中的每个DataNode接收心跳信合和状态报告,接收到心跳信号意味着DataNode节点工作正常,块状态报告包含了一个该DataNode上所有的数据列表。
4、 ZKFC是需要和NameNode一一对应的服务,即每个NameNode都需要部署ZKFC。它负责监控NameNode的状态,并及时把状态写入ZooKeeper。ZKFC也有选择谁作为Active NameNode的权利。
5、 JournalNode作用:为保持Active和Standby节点的数据一致性,两个节点都要与一组称为JournalNode的节点通信。当Active对文件系统元数据进行修改时,会将其修改日志保存到大多数的JournalNode节点中,例如有3个JournalNode,则日志会保存在至少2个节点中。Standby节点监控JournalNodes的变化,并同步来自Active节点的修改。根据修改日志,Standby节点将变动应用到本地文件系统元数据中。一旦发生故障转移,Standby节点能够确保与Active节点的状态是一致的。这保证了文件系统元数据在故障转移时在Active和Standby之间是完全同步的。对一个HA集群,保证任何时刻只有一个NameNode是Active状态至关重要。否则,命名空间会分为两部分,有数据丢失和产生其他错误的风险。为保证这个属性,防止“split-brain”问题的产生,JournalNodes在任何时刻都只允许一个NameNode写入。在故障转移时,将变为Active状态的NameNode获得写入JournalNodes的权限,这会有效防止其他NameNode的Active状态,使得切换安全进行。
6、 ZooKeeper是一个协调服务,帮助ZKFC执行主NameNode的选举。
参考文档:
https://support.huaweicloud.com/productdesc-mrs/mrs_08_000701.html
https://support.huaweicloud.com/productdesc-mrs/mrs_08_000702.html
MapReduce和HDFS的基本原理和基础知识--利用ChatGPT进行问答学习
你好你好!有什么可以帮到你的吗?现在你就是我的hadoop顾问了好的,很高兴成为你的Hadoop顾问。请问你有什么关于Hadoop的问题需要帮忙解答吗?如果我想学习hadoop,请向我介绍一下详细的学习路径把。当然,以下是一个简单的Hadoop学习路径:
掌握基本的计算机科学概念和Linux操作系统基础知识。
了解Java编程语言,因为Hadoop是用Java编写的,理解Java语言的特性有助于理解Hadoop的工作原理。
学习Hadoop的核心组件:HDFS(Hadoop分布式文件系统)和MapReduce。您可以通过阅读官方文档、教程和书籍来深入了解它们。
掌握Hadoop生态系统中的其他重要组件,例如YARN(Hadoop资源管理器)、Hive(基于Hadoop的数据仓库)、Pig(基于Hadoop的数据流语言)、Spark(内存计算框架)和HBase(NoSQL数据库)等等。
练习Hadoop的开发和部署,可以在本地机器上使用单机模拟器(例如Apache Hadoop Mini-Cluster)或在云环境中使用亚马逊AWS或微软Azure等提供的服务。
参与Hadoop社区,例如贡献代码、回答问题、提出改进建议等等,以加深对Hadoop的理解并从社区中获取帮助和支持。
请注意,这只是一个简单的Hadoop学习路径,并且具体的学习路径可能因个人背景和兴趣而异。建议您根据自己的需求和兴趣选择适合自己的学习材料和资源。请向我简单的说明一下mapreduce的工作原理把。MapReduce是一种分布式计算模型,它可以处理大规模数据集,将其分为若干个小的数据块,然后在分布式计算集群中并行处理这些数据块。下面是MapReduce的基本工作原理:
分片:将大规模数据集分成若干个小数据块,每个小数据块都会被分配给一个Map任务进行处理。
映射:每个Map任务对其分配到的数据块进行处理,将数据块中的每个元素映射成一个键/值对(key/value pair)。
排序:将所有Map任务产生的键/值对按照键进行排序,以便进行归并操作。
归并:将相同键的键/值对归并在一起,形成新的键/值对集合,这些键/值对集合就是Reduce任务的输入。
规约:如果指定了规约函数,则对Reduce任务的输入进行规约操作,以减少数据传输和提高计算效率。
归约:Reduce任务对规约后的键/值对集合进行处理,生成最终结果。
总的来说,MapReduce模型通过将大规模数据集分割成若干个小的数据块,并在分布式计算集群中进行并行计算,实现了高效处理大规模数据集的能力。请结合具体的数据案例和java代码来向我展示mapreduce的过程好的,下面是一个使用MapReduce计算文本文件中单词频率的Java代码示例。以文本文件作为输入,将每个单词映射为键/值对(key/value pair),其中键为单词,值为1,然后进行排序和归并操作,最后得到每个单词出现的频率。
假设我们有一个名为input.txt的文本文件,包含以下内容:
Hello Hadoop
Hello MapReduce
Hello World
以下是代码示例:
Mapper类实现map函数,用于将文本文件中的每个单词映射为键/值对(key/value pair),其中键为单词,值为1:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
String line = value.toString();
String[] words = line.split(" ");
for (String w : words)
word.set(w);
context.write(word, one);
Reducer类实现reduce函数,用于对相同键的键/值对进行归并操作,计算每个单词出现的频率:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
context.write(key, new IntWritable(sum));
Driver类实现main函数,用于配置和启动MapReduce作业:
java
Copy code
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver
public static void main(String[] args) throws Exception
Job job = Job.getInstance();
job.setJarByClass(WordCountDriver.class);
job.setJobName("Word Count");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
最后,在终端中运行以下命令启动作业:
hadoop jar wordcount.jar WordCountDriver input.txt output
运行后,将得到以下输出:
Copy code
Hello 3
Hadoop 1
MapReduce 1
World 1
这就是一个简单的MapReduce示例,简要说明一下学习hdfs的路径吧。学习Hadoop分布式文件系统(HDFS)的一般路径如下:
了解HDFS的基本概念和架构,例如数据块、NameNode和DataNode等。
安装Hadoop并启动HDFS服务。可以使用单节点或多节点的Hadoop集群。
使用Hadoop Shell命令或Java API与HDFS交互。例如,上传、下载、删除文件或目录等操作。
学习HDFS的高级特性,例如数据复制、数据损坏和故障恢复等。
使用Hadoop生态系统中的工具和框架,例如Apache Pig、Apache Hive和Apache Spark等,与HDFS交互,进行更高级别的数据分析和处理。
以下是一些可以学习HDFS的资源和工具:
Hadoop官方文档:包括Hadoop和HDFS的详细介绍和操作指南。
Hadoop: The Definitive Guide (《Hadoop权威指南》):这是一本广泛使用的Hadoop和HDFS教材,它详细讲解了HDFS的工作原理和操作。
Hadoop Shell命令:Hadoop Shell命令是与HDFS交互的一种常见方式。可以使用hadoop fs命令来操作HDFS。
HDFS Java API:Hadoop提供了Java API,可以使用Java编写程序与HDFS交互。可以使用这些API来进行文件的读写、修改、删除等操作。
Hadoop生态系统中的工具和框架:Apache Pig、Apache Hive和Apache Spark等,这些工具和框架提供了更高级别的数据分析和处理功能,可以直接与HDFS交互。请详细说明一下hdfs中数据块的概念,同时数据块在实际工作中有什么作用。在Hadoop分布式文件系统(HDFS)中,文件被分割成一个个数据块存储在不同的节点上。一个数据块是HDFS存储数据的最小单元,通常大小为128MB或256MB,也可以通过配置更改其大小。数据块由HDFS自动管理,每个数据块在文件系统中都有一个唯一的标识符,由Block ID和Generation Stamp组成。
数据块在实际工作中有以下作用:
数据块是HDFS分布式存储的基本单位。文件被分割成多个数据块,并且每个数据块会被复制到多个数据节点上,实现了数据的冗余备份,保证了数据的可靠性和容错性。
数据块可以并行读取和写入,提高了系统的吞吐量和性能。当一个大文件被读取或写入时,数据块可以并行传输到不同的节点上,同时读写操作可以分布在不同的节点上,从而提高了系统的并发性和效率。
数据块可以在HDFS集群中移动,以支持数据的负载均衡和故障恢复。HDFS可以自动移动数据块到不同的节点上,以实现负载均衡和优化存储空间的利用率。同时,当某个节点发生故障时,HDFS可以自动地将该节点上的数据块移动到其他节点上,从而实现故障恢复。
总之,数据块是HDFS分布式存储的基本单位,它实现了数据的可靠性、并发性、负载均衡和故障恢复等功能,使得HDFS可以支持大规模数据的存储和处理。请详细说明一下hdfs中namenode以及datanode的概念,同时这两个Node在实际工作中有什么作用。在Hadoop分布式文件系统(HDFS)中,有两种类型的节点:NameNode和DataNode。它们在HDFS的实际工作中有不同的作用。
NameNode
NameNode是HDFS的中心节点,它维护文件系统的元数据信息,包括文件的层次结构、文件名、文件属性、数据块的位置和副本信息等。NameNode将这些元数据信息存储在内存中,并将其持久化到磁盘上的文件系统镜像文件和日志文件中。
在实际工作中,NameNode的主要作用包括:
管理文件系统的命名空间:NameNode负责管理文件系统的层次结构和文件名,为文件和目录分配唯一的ID,确保文件和目录的唯一性和正确性。
管理数据块的位置信息:NameNode维护数据块的位置和副本信息,记录每个数据块所在的DataNode,以及数据块的副本数目和位置信息。
控制文件系统的访问和权限:NameNode负责控制文件系统的访问和权限,实现用户和用户组的认证和授权,以保证数据的安全和保密性。
DataNode
DataNode是HDFS集群中的工作节点,它负责实际存储数据块和处理读写请求。每个数据块在多个DataNode上进行复制,以保证数据的可靠性和容错性。
在实际工作中,DataNode的主要作用包括:
存储数据块:DataNode负责存储HDFS中的数据块,包括读取和写入数据块,并将数据块的副本传输到其他DataNode上。
处理读写请求:DataNode负责处理来自客户端的读写请求,包括打开、关闭、读取、写入和删除文件等操作。
上报数据块状态:DataNode定期向NameNode上报数据块的状态信息,包括数据块的存储位置和副本数目,以便NameNode更新元数据信息和实现故障恢复。
总之,NameNode和DataNode是Hadoop分布式文件系统的两个核心组件,分别负责文件系统的元数据管理和数据存储管理。它们通过协同工作,实现了HDFS的高可靠性、高可扩展性和高性能,成为大规模数据处理的重要基础设施。详细解释一下hdfs的高可用性。HDFS(Hadoop分布式文件系统)是Hadoop生态系统的核心组件之一,具有高可用性的特点。在Hadoop集群中,HDFS可以通过以下几个方面实现高可用性:
名称节点(NameNode)的高可用性
在HDFS中,名称节点(NameNode)是元数据信息的中心节点,负责管理文件系统的命名空间、数据块的位置和副本信息等。如果名称节点发生故障,整个HDFS集群将无法正常工作。为了避免这种情况,HDFS提供了两种方式实现名称节点的高可用性:
基于共享存储的名称节点:这种方式通过共享存储,将多个名称节点部署在不同的服务器上,实现名称节点的冗余备份。当一个名称节点发生故障时,其他名称节点会自动接管其职责,确保文件系统的可用性。这种方式的缺点是需要高昂的共享存储成本和复杂的系统配置。
基于主备模式的名称节点:这种方式通过在集群中选举一个主名称节点和多个备份名称节点,实现名称节点的故障转移和恢复。当主名称节点发生故障时,备份名称节点会自动接管其职责,保证文件系统的可用性。这种方式的优点是简单易用,缺点是故障切换的过程中可能会导致服务中断。
数据节点(DataNode)的高可用性
在HDFS中,数据节点(DataNode)负责存储数据块和处理读写请求。为了确保数据节点的高可用性,HDFS采用了数据块的冗余备份机制。每个数据块在多个数据节点上进行复制,以保证数据的可靠性和容错性。如果一个数据节点发生故障,其他数据节点会自动接管其职责,确保数据块的可用性。
故障检测和恢复机制
HDFS还提供了故障检测和恢复机制,用于检测集群中的故障和恢复故障节点。故障检测机制通过心跳机制和数据块报告机制实现,数据节点定期向名称节点发送心跳消息和数据块报告,以便名称节点及时发现故障节点。故障恢复机制通过名称节点的故障转移和数据块的重新复制实现,使得整个文件系统恢复正常运行。
综上所述,HDFS通过多种方式实现高可用性,包括名称节点的冗余备份、故障转移和恢复机制、数据节点的冗余备份和故障恢复请详细说明hdfs的文件操作方法,请附上java代码和命令行代码。HDFS是Hadoop分布式文件系统的缩写,提供了可扩展、高可靠、高性能的存储服务。在HDFS中,可以使用Java代码和命令行来进行文件操作,下面我将详细介绍一下它们的使用方法。
Java代码操作HDFS文件
Hadoop提供了Java API来操作HDFS文件,具体使用方法如下:
(1)创建HDFS文件系统对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
(2)上传本地文件到HDFS
Path src = new Path("file:///localpath");
Path dst = new Path("/hdfspath");
fs.copyFromLocalFile(src, dst);
(3)从HDFS下载文件到本地
Path src = new Path("/hdfspath");
Path dst = new Path("file:///localpath");
fs.copyToLocalFile(src, dst);
(4)在HDFS中创建目录
Path dir = new Path("/hdfspath");
fs.mkdirs(dir);
(5)在HDFS中删除文件或目录
Path path = new Path("/hdfspath");
fs.delete(path, true);
HDFS命令行操作文件
(1)上传本地文件到HDFS
hadoop fs -put /localpath /hdfspath
(2)从HDFS下载文件到本地
hadoop fs -get /hdfspath /localpath
(3)在HDFS中创建目录
hadoop fs -mkdir /hdfspath
(4)在HDFS中删除文件或目录
hadoop fs -rm -r /hdfspath
综上所述,Java代码和命令行都可以很方便地操作HDFS中的文件,具体选择哪种方式取决于实际情况和个人喜好。请详细说明一下hdfs中的数据流。HDFS是Hadoop分布式文件系统,数据在HDFS中以块(Block)的形式进行存储,每个块的大小通常是默认的128MB,可以通过配置进行修改。HDFS中的数据流是指在HDFS中,文件从客户端到存储在数据节点(DataNode)上的数据块,以及在从数据节点到客户端的过程中数据的流动。
在HDFS中,一个大的文件会被分成多个数据块进行存储,数据块的大小是可配置的,通常为128MB。当客户端向HDFS中上传文件时,文件首先被切割成多个数据块,然后每个数据块都会存储到不同的数据节点(DataNode)上,以达到数据分布式存储的目的。
当客户端需要读取文件时,HDFS的NameNode会返回包含数据块的位置信息(DataNode的IP地址和端口)给客户端。客户端接收到位置信息后,会向相应的DataNode请求数据块,DataNode将数据块的内容通过网络传输给客户端,客户端将多个数据块合并成一个完整的文件。由于数据块分布在多个DataNode上,客户端可以并行从多个DataNode上获取数据块,从而实现了数据的高效访问。
在HDFS中,数据流的设计使得数据的传输和存储都是高度优化的,可以大大提高数据访问的效率和可靠性。同时,通过数据块的复制和分布式存储,HDFS也具有很高的容错性,即使某个DataNode发生故障,数据仍然可以从其他的DataNode上获取。请详细介绍客户端从hdfs中读取一个数据的详细过程,最好能用具体案例说明。当客户端从HDFS中读取一个数据时,会经过以下步骤:
客户端向NameNode发送文件读取请求,并获取包含数据块信息的元数据(Metadata)。
根据元数据,客户端确定要读取的数据块的位置信息(DataNode的IP地址和端口号),并选择最近的DataNode进行读取。
客户端向DataNode发送读取数据块的请求,并获取数据块的副本(如果存在多个副本,则选择最近的一个)。
数据块的副本通过网络传输到客户端。
客户端将多个数据块合并成一个完整的文件,并保存到本地。
下面以一个具体的案例来说明客户端从HDFS中读取一个数据的过程。
假设HDFS中有一个名为/input/sample.txt的文件,客户端需要从中读取数据。具体步骤如下:
客户端执行hdfs dfs -cat /input/sample.txt命令,向NameNode发送读取文件的请求。NameNode返回文件的元数据信息,包括文件大小、数据块数量、每个数据块的位置信息等。
客户端解析元数据信息,选择离自己最近的DataNode(可以通过网络距离、负载等因素进行选择),并向该DataNode发送读取第一个数据块的请求。
DataNode收到请求后,会先检查自己是否有该数据块的副本。如果有,DataNode将该数据块的副本发送给客户端;如果没有,DataNode会向其他的DataNode请求该数据块的副本。
客户端收到第一个数据块的副本后,继续向该数据块的下一个副本所在的DataNode发送请求,并重复上述步骤,直到将所有的数据块都读取完毕。
客户端将读取到的所有数据块合并成一个完整的文件,并保存到本地。
需要注意的是,在实际的应用场景中,由于网络、硬件等原因,可能会出现某个DataNode无法响应请求或者读取速度过慢等情况。因此,HDFS中通常会为每个数据块保存多个副本,以提高数据的可靠性和读取性能。在客户端读取数据时,会优先选择最近的副本进行读取,以减少网络延迟和数据传输的带宽占用。详细说明hdfs中 distcp命令和cp命令的相同点和不同点,以及他们的应用场景。distcp命令和cp命令都是Hadoop中用于复制文件的命令,但它们之间存在一些不同点。
相同点:
都可以复制文件和目录。
都支持在本地文件系统和HDFS之间复制文件。
都可以使用通配符来复制多个文件。
不同点:
复制方式不同:cp命令是在本地文件系统中将文件复制到HDFS或者将HDFS上的文件复制到本地文件系统中,而distcp命令是在HDFS之间进行数据复制。
复制速度不同:distcp命令是在多个节点之间并行复制数据,可以充分利用Hadoop集群的计算和网络资源,因此比cp命令更快。
复制的目标不同:cp命令只能将文件复制到本地文件系统或者HDFS中的一个目录,而distcp命令可以将文件复制到多个HDFS集群中的不同目录。
应用场景:
cp命令通常用于本地文件系统和HDFS之间的数据迁移,以及在HDFS中进行文件的简单复制。例如,可以使用cp命令将本地文件系统中的数据上传到HDFS中,或者将HDFS中的数据复制到本地文件系统中进行本地处理。
distcp命令通常用于HDFS之间的数据复制。例如,在Hadoop集群之间迁移数据、进行数据备份或数据恢复等场景中,可以使用distcp命令复制数据。由于distcp命令可以在多个节点之间并行复制数据,因此在处理大量数据或者跨越多个数据中心进行数据复制时,使用distcp命令可以提高数据传输的效率和速度。
总的来说,cp命令适用于简单的数据复制场景,而distcp命令适用于大规模数据复制和数据迁移场景。用distcp命令传输集群之间的文件,虽然利用到集群的map的功能提高了文件读取的效率,但是最终的传输速度依然是取决于网络带宽是么。是的,你说得对。虽然distcp命令在复制数据时利用了Hadoop集群的计算和网络资源,使用多个map任务并行复制数据,但是最终的传输速度仍然取决于网络带宽的大小和稳定性。在进行跨数据中心的数据复制时,网络带宽和延迟往往是瓶颈,会影响数据复制的速度和效率。因此,在进行数据复制时,应该尽可能利用好网络带宽,采取合理的传输策略,例如在网络带宽充足的情况下,增加并行复制的线程数等。好的,非常感谢不用谢,有问题随时问我。以上是关于HDFS学习基础的主要内容,如果未能解决你的问题,请参考以下文章