HDFS学习进阶
Posted duoduomu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS学习进阶相关的知识,希望对你有一定的参考价值。
一、HDFS元数据管理
HDFS是一个分布式文件存储系统,文件分布式存储在多个DataNode节点上。一个文件存储在哪些DataNode节点的哪些位置的元数据信息(metadata)由NameNode节点来处理。随着存储文件的增多,NameNode上存储的信息也会越来越多。在HDFS中主要是通过两个组件FSImage(快照文件,存放在主Namenode上)和EditsLog来实现metadata的更新。在某次启动HDFS时,会从FSImage文件中读取当前HDFS文件的metadata,之后对HDFS的操作步骤都会记录到edit log文件中。创建目录执行样例如图所示:
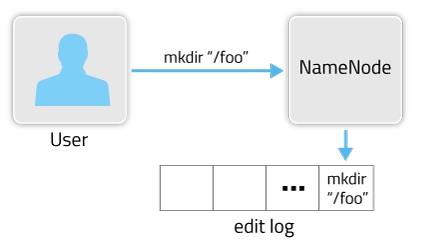
完整的metadata信息由FSImage文件和edit log文件组成。fsimage中存储的信息就相当于整个hdfs在某一时刻的一个快照。 FSImage文件和EditsLog文件可以通过ID来互相关联。在参数dfs.namenode.name.dir设置的路径下,会保存FSImage文件和EditsLog文件,如果是QJM方式HA的话,EditsLog文件保存在参数dfs.journalnode.edits.dir设置的路径下。 文件样例如图所示:
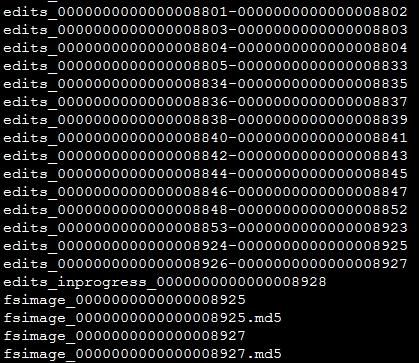
在上图中可以看到,edit log文件以edits_开头,后面跟一个txid范围段,并且多个edit log之间首尾相连,正在使用的edit log名字为edits_inprogress_txid(图中倒数第5行,最后一个edits文件)。该路径下还会保存两个fsimage文件,文件格式为fsimage_txid。上图中可以看出fsimage文件已经加载到了最新的一个edit log文件(加载了末尾数字8927这个edits文件),仅仅只有inprogress状态的edit log未被加载。在启动HDFS时,只需要读入fsimage_0000000000000008927以及edits_inprogress_0000000000000008928就可以还原出当前hdfs的最新状况。如果edit log文件越来越多、越来越大时,当重新启动hdfs时,由于需要加载fsimage后再把所有的edit log也加载进来,随着存储文件的增多,NameNode上存储的信息也会越来越多。HDFS提供Checkpoint机制来实现editslog和fsimage快照文件的合并。
fsimage和edit log合并的过程如下图所示:
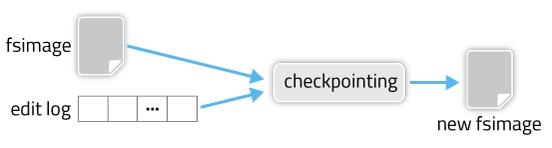
其实这个合并过程是一个很耗I/O与CPU的操作,并且在进行合并的过程中肯定也会有其他应用继续访问和修改hdfs文件。所以,这个过程一般不是在单一的NameNode节点上进行从。如果HDFS没有做HA的话,checkpoint由SecondNameNode进程(一般SecondNameNode单独起在另一台机器上)来进行,这种方式基本不用。在HA模式下,checkpoint则由StandBy状态的NameNode来进行。 什么时候进行checkpoint由两个参数dfs.namenode.checkpoint.preiod(默认值是3600,即1小时)和dfs.namenode.checkpoint.txns(默认值是1000000)来决定。period参数表示,经过1小时就进行一次checkpoint,txns参数表示,hdfs经过100万次操作后就要进行checkpoint了。这两个参数任意一个得到满足,都会触发checkpoint过程。进行checkpoint的节点每隔dfs.namenode.checkpoint.check.period(默认值是60)秒就会去统计一次hdfs的操作次数。在HA模式下checkpoint过程由StandBy NameNode来进行,以下简称为NM备节点,Active NameNode简称为NM主节点。HA模式下的edit log文件会同时写入多个JournalNodes节点的dfs.journalnode.edits.dir路径下,JournalNodes的个数为大于1的奇数(MRS大多为3个节点),类似于Zookeeper的节点数,当有不超过一半的JournalNodes出现故障时,仍然能保证集群的稳定运行。 NM备节点会读取FSImage文件中的内容,并且每隔一段时间就会把NM主节点写入edit log中的记录读取出来,这样NM备节点的NameNode进程中一直保持着hdfs文件系统的最新状况namespace。当达到checkpoint条件的某一个时,就会直接将该信息写入一个新的FSImage文件中,然后通过HTTP传输给NM主节点,传送过程如图所示:
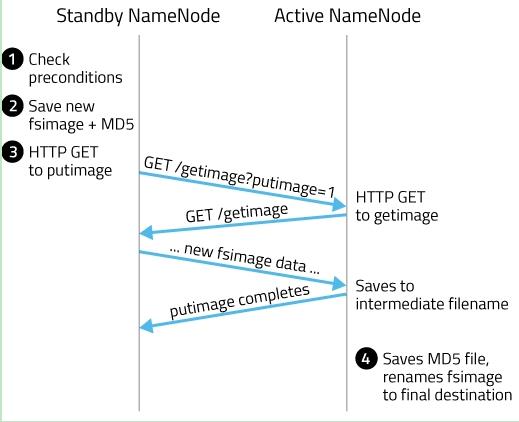
1. NM备节点检查是否达到checkpoint条件:离上一次checkpoint操作是否已经有一个小时,或者HDFS已经进行了100万次操作。
2. NM备节点检查达到checkpoint条件后,将该namespace以fsimage.ckpt_txid格式保存到NM备节点的磁盘上,并且随之生成一个MD5文件。然后将该fsimage.ckpt_txid文件重命名为fsimage_txid。
3. 然后NM备节点通过HTTP联系NM主节点。
4. NM主节点通过HTTP从NM备节点获取最新的fsimage_txid文件并保存为fsimage.ckpt_txid,然后也生成一个MD5,将这个MD5与NM备节点的MD5文件进行比较,确认NM主节点已经正确获取到了NM备节点最新的fsimage文件。然后将fsimage.ckpt_txid文件重命名为fsimage_txit。
通过上面一系列的操作,NM备节点上最新的FSImage文件就成功同步到了NM主节点上。
HDFS元数据相关参考材料:
https://www.cnblogs.com/nucdy/p/5892144.html
https://blog.csdn.net/dabokele/article/details/51686257
二、HDFS度写过程说明
2.1HDFS写入流程
写详细步骤:
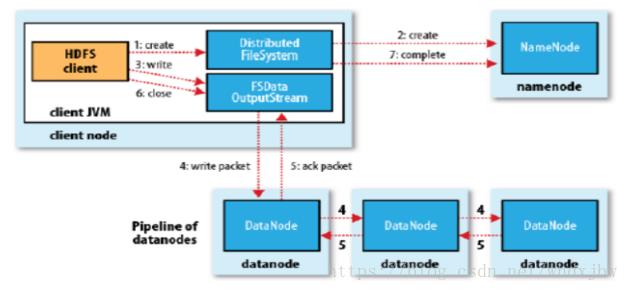 流程图后续优化。
流程图后续优化。
1、客户端向NameNode发出写文件请求。
2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
3、client端按128MB(根据实际配置block块大小)的块切分文件。
4、client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。(注:并不是写好一个块或一整个文件后才向后分发)
5、每个DataNode写完一个块后,会返回确认信息。(注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
6、写完数据,关闭输输出流。
7、发送完成信号给NameNode。
2.2HDFS读取流程
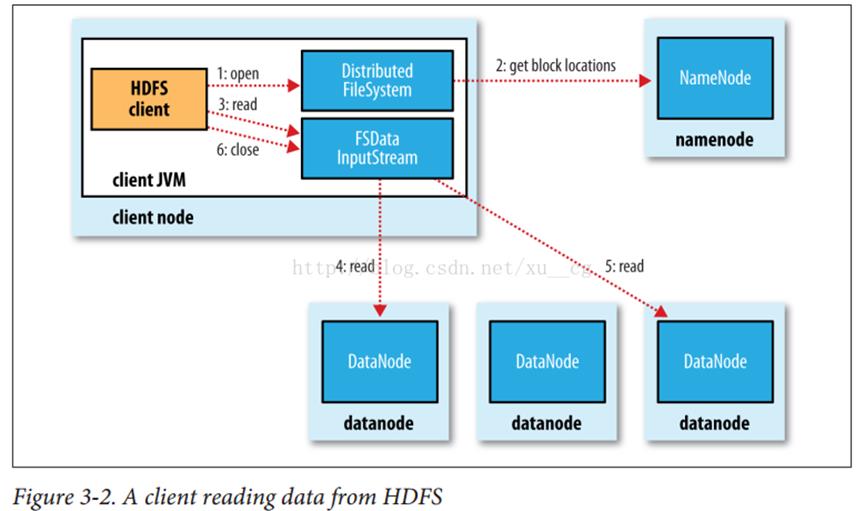
1、Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
3、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
4、底层上本质是建立Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
5、当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
6、读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
7、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
8、最终读取来所有的 block 会合并成一个完整的最终文件。
2.3 通过校验和方式保证HDFS读写过程保证数据完整性
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
HDFS中文件块目录结构具体格式如下:
$dfs.datanode.data.dir/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。
参考材料:https://blog.csdn.net/whdxjbw/article/details/81072207
三、HDFS API调用
在 java 中操作 HDFS,主要涉及以下 Class:
Configuration:该类的对象封转了客户端或者服务器的配置; FileSystem:该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过 FileSystem 的静态方法 get 获得该对象。
FileSystem fs = FileSystem.get(conf)
get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类型的文件系统。如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml ,默认值为: file:/// ,则获取的将不是一个DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象
3.1 使用url的方式访问数据
@Test
public void demo1()throws Exception
//第一步:注册hdfs 的url,让java代码能够识别hdfs的url形式
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
InputStream inputStream = null;
FileOutputStream outputStream =null;
//定义文件访问的url地址
String url = "hdfs://1.1.1.1:8020/test/input/install.log";
//打开文件输入流
try
inputStream = new URL(url).openStream();
outputStream = new FileOutputStream(new File("c:\\\\hello.txt"));
IOUtils.copy(inputStream, outputStream);
catch (IOException e)
e.printStackTrace();
finally
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
3.2 获取文件系统(FileSystem)的几种方式
方式1:
@Test
public void getFileSystem() throws URISyntaxException, IOException
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), configuration);
System.out.println(fileSystem.toString());
方式2:
@Test
public void getFileSystem2() throws URISyntaxException, IOException
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://1.1.1.1:8020");
FileSystem fileSystem = FileSystem.get(new URI("/"), configuration);
System.out.println(fileSystem.toString());
方式3:
@Test
public void getFileSystem3() throws URISyntaxException, IOException
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://1.1.1.1:8020"), configuration);
System.out.println(fileSystem.toString());
方式4:
@Test
public void getFileSystem4() throws Exception
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://1.1.1.1:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
3.3 通过官方API遍历hdfs文件系统
/**
* 递归遍历官方提供的API版本
* @throws Exception
*/
@Test
public void listMyFiles()throws Exception
//获取fileSystem类
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
//获取RemoteIterator 得到所有的文件或者文件夹,第一个参数指定遍历的路径,第二个参数表示是否要递归遍历
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true);
while (locatedFileStatusRemoteIterator.hasNext())
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
System.out.println(next.getPath().toString());
fileSystem.close();
3.4 拷贝文件到本地
@Test
public void getFileToLocal()throws Exception
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
FSDataInputStream open = fileSystem.open(new Path("/test/input/install.log"));
FileOutputStream fileOutputStream = new FileOutputStream(new File("c:\\\\install.log"));
IOUtils.copy(open,fileOutputStream );
IOUtils.closeQuietly(open);
IOUtils.closeQuietly(fileOutputStream);
fileSystem.close();
3.5 hdfs上创建文件夹
@Test
public void mkdirs() throws Exception
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test"));
fileSystem.close();
3.6 hdfs文件上传
@Test
public void putData() throws Exception
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
fileSystem.copyFromLocalFile(new Path("file:///c:\\\\install.log"),new Path("/hello/mydir/test"));
fileSystem.close();
更详细开发内容参考华为云官网HDFS开发指南
https://support.huaweicloud.com/devg3-mrs/mrs_07_090002.html
https://support.huaweicloud.com/devg3-mrs/mrs_07_300002.html
Hive_进阶
回顾:
hive 优点 1. 类sql语句靠近关系型数据库,可自定义函数,增加了扩展性,易于开发,减少mapreduce学习成本 2. hive转换sql语句为mapreduce程序以mapreduce为底层实现 3. hive基于hadoop的hdfs,在hdfs上存储,因为hdfs的扩展性,hive的存储扩展性相应增加
hive 安装部署
1. 解压安装包 2. 进入conf目录,拷贝(备份)相应配置文件,修改 hive-env.sh --> HADOOP_HOME=/opt/cdh-5.6.3/hadoop-2.5.0-cdh5.3.6 --> export HIVE_CONF_DIR=/opt/cdh-5.6.3/hive-0.13.1-cdh5.3.6/conf hive-log4j.properties --> 在hive根目录下创建日志文件夹,来存放hive运行日志 --> hive.log.threshold=ALL hive.root.logger=INFO,DRFA hive.log.dir=/opt/cdh-5.6.3/hive-0.13.1-cdh5.3.6/logs hive.log.file=hive.log hive-site.xml --> javax.jdo.option.ConnectionURL --- jdbc:mysql://hadoop09-linux-01.ibeifeng.com:3306/chd_metastore?createDatabaseIfNotExist=true --> javax.jdo.option.ConnectionDriverName --- com.mysql.jdbc.Driver --> javax.jdo.option.ConnectionUserName --- root --> javax.jdo.option.ConnectionPassword --- root --> hive.cli.print.header --- true # 这行表示是否显示标的列名(可不配) --> hive.cli.print.current.db --- true # 这行表示是否显示当前数据库名(可不配) --> hive.fetch.task.conversion --- true # 这行表示运行sql语句是否走mr(可不配)
hive 架构
1. metastore --> 在derby数据库存储,在hive目录中会生成derby文件和metastore_db,弊端同级目录下启动hive会报错 --> 在mysql中存储元数据 --> 在远程mysql存储元数据 2. client --> cli/jdbc/Driver/SQLParser/QueryOptimizer/Physical Plan/Execution
hive 创建表几种方式,分别是什么
1. 普通建表 create table if not exists tablename(...) row format delimited fields terminated by ‘\t‘; stored as textfile; 2. 子查询方式 create table if not exists tablename as select * from tablename2; 3. like 方式 create table if not exists tablename like tablename2 # 该创建方式仅复制tablename2的表结构
表的类型
1. 管理表(默认表类型) 2. 外部表(external;解决多用户使用同一表) 3. 分区表(partiion;优化分析查询表数据) --> 查看分区表: show partitions tablename; # 查看tablename的分区情况 手动添加分区 1. 创建分区 hive (workdb)> dfs -mkdir /user/hive/warehouse/workdb.db/emp_part/date=20161029 dfs -put /home/liuwl/opt/datas/emp.txt /user/hive/warehouse/workdb.db/emp_part/date=20161029 --- 发现使用show partitions emp_parts; 不能检索出刚刚手动添加的表分区 2. 解决:alter tabel emp_part add partition (date=‘20161029‘)
分析函数和窗口函数(重点)
1. 分析函数 部门20的所有员工,按薪资降序排列 select * from emp where emp.deptno=‘20‘ order by sal desc; 所有部门分组,按薪资降序排列 select empno,ename,deptno,sal,max(sal) over (partition by deptno order by sal desc) as maxsal from emp; 结果: empno ename deptno sal maxsal 7839 KING 10 5000.0 5000.0 7782 CLARK 10 2450.0 5000.0 7934 MILLER 10 1300.0 5000.0 7788 SCOTT 20 3000.0 3000.0 7902 FORD 20 3000.0 3000.0 7566 JONES 20 2975.0 3000.0 7876 ADAMS 20 1100.0 3000.0 7369 SMITH 20 800.0 3000.0 7698 BLAKE 30 2850.0 2850.0 7499 ALLEN 30 1600.0 2850.0 7844 TURNER 30 1500.0 2850.0 7654 MARTIN 30 1250.0 2850.0 7521 WARD 30 1250.0 2850.0 7900 JAMES 30 950.0 2850.0 实现行号 select empno,ename,deptno,sal,row_number() over (partition by deptno order by sal desc) as rownum from emp; empno ename deptno sal rownum 7839 KING 10 5000.0 1 7782 CLARK 10 2450.0 2 7934 MILLER 10 1300.0 3 7788 SCOTT 20 3000.0 1 7902 FORD 20 3000.0 2 7566 JONES 20 2975.0 3 7876 ADAMS 20 1100.0 4 7369 SMITH 20 800.0 5 7698 BLAKE 30 2850.0 1 7499 ALLEN 30 1600.0 2 7844 TURNER 30 1500.0 3 7654 MARTIN 30 1250.0 4 7521 WARD 30 1250.0 5 7900 JAMES 30 950.0 6 ROW_NUMBER() 行号 获取工资最高的前两位 select * from (select empno,ename,deptno,sal,row_number() over (partition by deptno order by sal desc) as rownum from emp) t where t.rownum < 3; t.empno t.ename t.deptno t.sal t.rownum 7839 KING 10 5000.0 1 7782 CLARK 10 2450.0 2 7788 SCOTT 20 3000.0 1 7902 FORD 20 3000.0 2 7698 BLAKE 30 2850.0 1 7499 ALLEN 30 1600.0 2 RANK()排名(第一二位为1,第三位为3,默认第二位为1) DENSE_RANK()(第一二位为1,第三位为2,默认第二位为1) 为所有部门分组,按薪资降序排列,且进行排名 select empno,ename,deptno,sal,rank() over (partition by deptno order by sal desc) ranksal from emp; empno ename deptno sal ranksal 7839 KING 10 5000.0 1 7782 CLARK 10 2450.0 2 7934 MILLER 10 1300.0 3 7788 SCOTT 20 3000.0 1 7902 FORD 20 3000.0 1 7566 JONES 20 2975.0 3 7876 ADAMS 20 1100.0 4 7369 SMITH 20 800.0 5 7698 BLAKE 30 2850.0 1 7499 ALLEN 30 1600.0 2 7844 TURNER 30 1500.0 3 7654 MARTIN 30 1250.0 4 7521 WARD 30 1250.0 4 7900 JAMES 30 950.0 6 select empno,ename,deptno,sal,dense_rank() over (partition by deptno order by sal desc) ranksal from emp; empno ename deptno sal dense_ranksal 7839 KING 10 5000.0 1 7782 CLARK 10 2450.0 2 7934 MILLER 10 1300.0 3 7788 SCOTT 20 3000.0 1 7902 FORD 20 3000.0 1 7566 JONES 20 2975.0 2 7876 ADAMS 20 1100.0 3 7369 SMITH 20 800.0 4 7698 BLAKE 30 2850.0 1 7499 ALLEN 30 1600.0 2 7844 TURNER 30 1500.0 3 7654 MARTIN 30 1250.0 4 7521 WARD 30 1250.0 4 7900 JAMES 30 950.0 5 NTILE()层次查询 例:查询出所有组中工资水平前1/3人员 select empno,ename,sal,ntile(3) over (order by sal desc ) ntile from emp group by empno,ename; empno ename sal til 7839 KING 5000.0 1 7902 FORD 3000.0 1 7788 SCOTT 3000.0 1 7566 JONES 2975.0 1 7698 BLAKE 2850.0 1 7782 CLARK 2450.0 2 7499 ALLEN 1600.0 2 7844 TURNER 1500.0 2 7934 MILLER 1300.0 2 7654 MARTIN 1250.0 2 7521 WARD 1250.0 3 7876 ADAMS 1100.0 3 7900 JAMES 950.0 3 7369 SMITH 800.0 3 2. 窗口函数LAG(向前取值)LEAG(向后取值) select empno,ename,sal,lag(ename,4,0) over (order by sal desc) lagvalue from emp; 结果: empno ename sal lagvalue 7839 KING 5000.0 0 7902 FORD 3000.0 0 7788 SCOTT 3000.0 0 7566 JONES 2975.0 0 7698 BLAKE 2850.0 KING 7782 CLARK 2450.0 FORD 7499 ALLEN 1600.0 SCOTT 7844 TURNER 1500.0 JONES 7934 MILLER 1300.0 BLAKE 7654 MARTIN 1250.0 CLARK 7521 WARD 1250.0 ALLEN 7876 ADAMS 1100.0 TURNER 7900 JAMES 950.0 MILLER 7369 SMITH 800.0 MARTIN select empno,ename,sal,lead(ename,4,0) over (order by sal desc) leadvalue from emp; 结果: empno ename sal leadvalue 7839 KING 5000.0 BLAKE 7902 FORD 3000.0 CLARK 7788 SCOTT 3000.0 ALLEN 7566 JONES 2975.0 TURNER 7698 BLAKE 2850.0 MILLER 7782 CLARK 2450.0 MARTIN 7499 ALLEN 1600.0 WARD 7844 TURNER 1500.0 ADAMS 7934 MILLER 1300.0 JAMES 7654 MARTIN 1250.0 SMITH 7521 WARD 1250.0 0 7876 ADAMS 1100.0 0 7900 JAMES 950.0 0 7369 SMITH 800.0 0
数据导入Hive(重点)
1. 从本地导入 load data local inpath ‘filepath‘ into table tbname; 2. 从hdfs导入 load data inpath ‘hdfs_filepath‘ into table tbname; 3. load覆盖 load data local inpath ‘filepath‘ overwrite into table tbname; load data inpath ‘hdfs_filepath‘ overwrite into table tbname; 4. 子查询方式 create table tb2 as select * from tb1; # 默认分隔符为^A 5. insert into table select ql; # 分隔符为emp定义的分隔符 --> create table emp_insert like emp; --> insert into table emp_insert select * from emp; 6. location方式 create table if not exists tbname location ‘localPath‘;
Hive数据导出(重点)
1. insert方式(注意使用该方式导出数据到本地,1:文件夹得有相应权限;2:最好建一个文件夹,否则原文件夹下所有内容被覆盖) --> insert overwrite [local] directory ‘path‘ select ql ; 例:insert overwrite local directory ‘/tmp‘ row format delimited fields terminated by ‘\t‘ select * from emp; 2. bin/hdfs -get 3. Linux命令执行HQL: -> -e -> -f -> 输出重定向 4. sqoop:用户hdfs与关系型数据库之间的导入导出
hive的export与import(相关地址只能是hdfsPath)
-> export export table tb_name to ‘hdfs_path‘ 例: export table emp to ‘/export_emp‘; -> import import table tb_name from ‘hdfs_path‘ 例: import table emp_im from ‘/export_emp‘;
hive中的HQL
1. 字段查询 -> select empno,ename from emp; 2. where、limit、distinct -> select * from emp where sal > 3000; -> select * from emp limit 5; -> select distinct deptno from emp; 3. between and,>,<,=,is null,is not null,in -> select * from emp where sal between 2000 and 3000; -> select * from emp where comm is null; -> select * from emp where sal in (2000,3000,4000); 4. count(),sum(),avg(),max(),min() -> select count(1) from emp; -> select sum(sal) form emp; -> select avg(sal) from emp; 5. group by,having -> select deptno,avg(sal) from emp group by deptno; -> select deptno,avg(sal) avgsal from emp group by deptno having avgsal >= 3000; 6. join -> 等值join(匹配共有的记录) select e.empno,e.deptno,e.ename,e.sal,e.mgr from emp e join dept d on e.deptno=d.deptno; -> 左join(左边为小表) select e.empno,e.deptno,e.ename,e.sal,e.mgr from emp e left join dept d on e.deptno=d.deptno; -> 右join(右边为小表) select e.empno,e.deptno,e.ename,e.sal,e.mgr from emp e right join dept d on e.deptno=d.deptno; -> 全join select e.empno,e.deptno,e.ename,e.sal,e.mgr from emp e full join dept d on e.deptno=d.deptno;
hive中mapreduce相关操作(重点)
1. 设置每个reduce处理的数据量 -> set hive.exec.reducers.bytes.per.reducer; 默认1G,当处理的数据量为10G时,将开启10个reduce,每个reduce处理1G 2. 设置最大运行reduce的个数 -> set hive.exec.reducers.max; 默认最大运行个数为999 3. 设置实际reduce的个数 -> set mapreduce.job.reduces; hive打印显示-1,hadoop默认为1
hive中的几种排序(重点)
1. order by (只针对一个文件排序,当有多个reduce Task生成多个文件时,排序失效) -> select * from emp order by sal desc; 2. sort by (对于每一个文件进行排序,注意目必须是绝对路径) -> set mapreduce.job.reduces=3; -> insert overwrite local directory ‘/home/liuwl/opt/datas/sortData‘ row format delimited fields terminated by ‘\t‘ select * from emp sort by sal; 需要注意的是如果使用order by 不管reduce Task设置多少,只生成一个文件,并为该文件排序 3. distribute by (底层为mapreduce的分区,一般与sort by 连用) -> insert overwrite local directory ‘/home/liuwl/opt/datas/sortData‘ row format delimited fields terminated by ‘\t‘ select * from emp distribute by deptno sort by sal; 4. cluster by (等价于distribute by xx sort by xx) # xx为同一字段 -> insert overwrite local directory ‘/home/liuwl/opt/datas/sortData‘ row format delimited fields terminated by ‘\t‘ select * from emp cluster by sal ;
hive中的UDF(自定义函数,允许用户扩展HiveOL功能)(重点)
1. udf: 一进一出 upper/lower/day
2. udaf: 多进一出 count/max/min
3. udtf: 一进多出 ateral/view/explode
udf:编程步骤
--> 继承 org.apache.hadoop.hive.ql.UDF
--> 实现 evaluate函数,evaluate函数支持重载
注意:UDF必须要有返回类型,可以返回NULL,但是返回类型不能为void
UDF中常用Text/LongWritable等类型,不推荐使用java
-->代码
public Text evaluate(Text str){
return this.evaluate(str,new IntWritable(0));
}
public Text evaluate(Text str, IntWritable flag){
if(str != null){
if(flag.get() == 0){
return new Text(str.toString().toLowerCase());
}else if(flag.get() ==1){
return new Text(str.toString().toUpperCase());
}else return null;
}else return null;
}
--> 打包
--> 在hive中添加
---> 关联jar包
add jar jar_path;
---> 创建方法
create temporary function tolower as ‘com.hive.udf.UDFTest‘
---> 测试
select ename,tolower(ename),tolower(tolower(ename),1) lowername from emp;
ename lowername uppername
SMITH smith SMITH
ALLEN allen ALLEN
WARD ward WARD
JONES jones JONES
MARTIN martin MARTIN
BLAKE blake BLAKE
CLARK clark CLARK
SCOTT scott SCOTT
KING king KING
TURNER turner TURNER
ADAMS adams ADAMS
JAMES james JAMES
FORD ford FORD
MILLER miller MILLER
-->案例2:去除所有双引号
-->代码
public Text evaluate(Text str){
if(str != null){
return new Text(str.toString().replaceAll("\"", ""));
}else return null;
}
--> 关联jar包
add jar jar_path;
--> 创建方法
create temporary function rmquotes as ‘com.hive.udf.RMQuotes‘
--> 测试
select dname,rmquotes(dname) rmquotes from dept_quotes;
dname rmquotes
"ACCOUNTING" ACCOUNTING
"RESEARCH" RESEARCH
"SALES" SALES
"OPERATIONS" OPERATIONS
-->案例3:去除多有引号,并取出get后的路径
如:"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/styles.php/bootstrap/1427679483/all HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" /theme/styles.php/bootstrap/1427679483/all
-->准备数据:
moodel.log
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/styles.php/bootstrap/1427679483/all HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/image.php/bootstrap/theme/1427679483/fp/logo HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/image.php/bootstrap/core/1427679483/t/expanded HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/image.php/bootstrap/theme/1427679483/fp/search_btn HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/image.php/bootstrap/core/1427679483/t/collapsed HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/image.php/bootstrap/theme/1427679483/fp/footerbg HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/yui_combo.php?m/1427679483/theme_bootstrap/bootstrap/bootstrap-min.js HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:42 +0800" "GET /theme/yui_combo.php?m/1427679483/block_navigation/navigation/navigation-min.js HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:43 +0800" "GET /theme/yui_combo.php?m/1427679483/theme_bootstrap/zoom/zoom-min.js HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:43 +0800" "GET /theme/yui_combo.php?3.17.2/cssbutton/cssbutton-min.css HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:43 +0800" "GET /theme/yui_combo.php?m/1427679483/core/lockscroll/lockscroll-min.js HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:43 +0800" "GET /theme/image.php/bootstrap/core/1427679483/t/block_to_dock HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:43 +0800" "GET /theme/image.php/bootstrap/core/1427679483/t/switch_plus HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:43 +0800" "GET /theme/image.php/bootstrap/core/1427679483/t/switch_minus HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:45 +0800" "GET /course/view.php?id=27§ion=4 HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:46 +0800" "GET /theme/image.php/bootstrap/page/1427679483/icon HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:46 +0800" "GET /theme/image.php/bootstrap/core/1427679483/spacer HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:46 +0800" "GET /theme/yui_combo.php?m/1427679483/core/formautosubmit/formautosubmit-min.js HTTP/1.1"
"116.216.17.0" "31/Aug/2015:00:19:54 +0800" "GET /mod/page/view.php?id=11187§ion=4 HTTP/1.1"
-->创建moodle表
create table if not exists moodle(
ip string,
date string,
url string) row format delimited fields terminated by ‘\t‘;
-->加载数据
load data local inpath ‘/home/liuwl/opt/datas/dd/moodle.log‘ into table moodle;
-->代码
public Text evaluate(Text text){
if(text != null){
String strs = text.toString().replaceAll("\"", "");
String str = "";
boolean isDate = false;
try{
SimpleDateFormat sdf = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss Z", new Locale("ENGLISH", "CHINA"));
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyyMMddHHmm",new Locale("CHINESE", "CHINA"));
Date date = sdf.parse(strs);
str=sdf1.format(date);
isDate = true;
}catch(ParseException p){
isDate = false;
}
// is date
if(isDate){
return new Text(str);
}else{
if(strs.indexOf("HTTP/1.1")>0){
return new Text(strs.split(" ")[1]);
}else{
return new Text(strs.split(" ")[0]);
}
}
}else return null;
}
--> 关联jar包
add jar jar_path;
--> 创建方法
create temporary function mymoodle as ‘com.hive.udf.mymoodle‘;
--> 测试
select mymoodle(ip) ip,mymoodle(date) date,mymoodle(url) url from moodle;
ip date url
116.216.17.0 201508310019 /theme/styles.php/bootstrap/1427679483/all
116.216.17.0 201508310019 /theme/image.php/bootstrap/theme/1427679483/fp/logo
116.216.17.0 201508310019 /theme/image.php/bootstrap/core/1427679483/t/expanded
116.216.17.0 201508310019 /theme/image.php/bootstrap/theme/1427679483/fp/search_btn
116.216.17.0 201508310019 /theme/image.php/bootstrap/core/1427679483/t/collapsed
116.216.17.0 201508310019 /theme/image.php/bootstrap/theme/1427679483/fp/footerbg
116.216.17.0 201508310019 /theme/yui_combo.php?m/1427679483/theme_bootstrap/bootstrap/bootstrap-min.js
116.216.17.0 201508310019 /theme/yui_combo.php?m/1427679483/block_navigation/navigation/navigation-min.js
116.216.17.0 201508310019 /theme/yui_combo.php?m/1427679483/theme_bootstrap/zoom/zoom-min.js
116.216.17.0 201508310019 /theme/yui_combo.php?3.17.2/cssbutton/cssbutton-min.css
116.216.17.0 201508310019 /theme/yui_combo.php?m/1427679483/core/lockscroll/lockscroll-min.js
116.216.17.0 201508310019 /theme/image.php/bootstrap/core/1427679483/t/block_to_dock
116.216.17.0 201508310019 /theme/image.php/bootstrap/core/1427679483/t/switch_plus
116.216.17.0 201508310019 /theme/image.php/bootstrap/core/1427679483/t/switch_minus
116.216.17.0 201508310019 /course/view.php?id=27§ion=4
116.216.17.0 201508310019 /theme/image.php/bootstrap/page/1427679483/icon
116.216.17.0 201508310019 /theme/image.php/bootstrap/core/1427679483/spacer
116.216.17.0 201508310019 /theme/yui_combo.php?m/1427679483/core/formautosubmit/formautosubmit-min.js
116.216.17.0 201508310019 /mod/page/view.php?id=11187§ion=4
hive中hiveserver2,beeline,java client
-->hiveserver2启动方式:bin/hiveserver2;bin/hiveserver2;bin/hive --service hiveserver2
-->beeline启动方式:bin/beeline -u jdbc:hive2://hadoop09-linux-01.ibeifeng.com:10000/workdb -n liuwl -p liuwl
--> bin/beeline
--> !connect jdbc:hive2://hadoop09-linux-01.ibeifeng.com:10000/workdb
-->java client
-->启动hiveserver2
-->编写代码:
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://hadoop09-linux-01.ibeifeng.com:10000/workdb";
private static String username = "root";
private static String password = "root";
public static Connection getConnection(){
try {
Class.forName(driverName);
Connection con = DriverManager.getConnection(url, username, password);
return con;
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
public static List<Object> querySql(Statement stmt, String sql) throws SQLException{
ResultSet res = stmt.executeQuery(sql);
List<Object> objectList = new ArrayList<Object>();
while (res.next()) {
objectList.add(res.getString(1));
}
return objectList;
}
public static void main(String[] args) throws SQLException {
Connection con = getConnection();
Statement stmt = con.createStatement();
List<Object> objectList = new ArrayList<Object>();
//query
String qsql = "select * from emp";
objectList = querySql(stmt,qsql);
for(int i = 0; i < objectList.size(); i++){
System.out.println(objectList.get(i));
}
//regular
String rsql = "select count(1) from emp";
objectList = querySql(stmt,rsql);
for(int i = 0; i < objectList.size(); i++){
System.out.println(objectList.get(i));
}
//create
String csql = "create table if not exists test (key int, value string) row format delimited fields terminated by ‘\t‘";
stmt.execute(csql);
//load
//String lsql = "load data local inpath ‘/home/liuwl/opt/datas/test.txt‘ into table test";
//update start as 0.14
//String usql = "update table test set key =4 where value=‘uuuu‘";
//stmt.executeUpdate(usql);
//drop
String dsql = "drop table if exists test";
if(!stmt.execute(dsql)){
System.out.println("success");
}
}
hive的执行sql两种模式(Fetch Task与mapreduce)
--> hive.fetch.task.conversion--minimal # SELECT STAR, FILTER on partition columns, LIMIT only 译:在select *;使用分区作为过滤条件;limit语句 hive.fetch.task.conversion--more # SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns) 译: 在所有select语句,数据取样, 虚拟列, --> 虚拟列(注意是双下划线) --> input__file__name # 数据的来源 --> block__offset_inside__file # 记录在块中的偏移量 --> row__offset__inside__block # 行的偏移量(默认不启用,需要修改hive.exec.rowoffset)
hive的严格模式
--> hive.mapred.mode--(默认nonstrict) 注意: 在严格模式下 不允许由风险型sql语句: 笛卡尔积查询(使用join而不使用on或where) 分区表没有指定分区 order by没有使用limit bigint与string/double的比较
以上是关于HDFS学习进阶的主要内容,如果未能解决你的问题,请参考以下文章