博学谷学习记录 自我总结 用心分享 | Alibaba- GateWay
Posted LiuLance
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了博学谷学习记录 自我总结 用心分享 | Alibaba- GateWay相关的知识,希望对你有一定的参考价值。
Spring Cloud Netflix 项目进入维护模式,Spring Cloud Netflix 将不再开发新的组件,我们知道 Spring Cloud 版本迭代算是比较快的,因而出现了很多中岛的 ISSUE 都来不及 Fix 就又推另一个 Release 了 。进入维护模式意思就是目前已知以后一段时间 Spring Cloud Netflix 提供的服务和功能就这么多了, 不再开发性的组件和功能了。 以后将以维护和 Merge 分支 Full Requset 为主。换句话说:就是 SpringCloud 的技术栈不再完整了!此时,我们就有必要寻找一个新的完整的技术栈。
服务限流降级:默认支持 Servlet、Feign\\
RestTemplate、Dubbo、和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级骨子额,还支持查看限流降级 Metrics 控制。
服务注册于发现:适配 Spring Cloud 服务注册于发现标准,默认集成 Ribbon 支持
分布式配置管理:支持分布式系统中的外部话配置,配置更改时自动刷新。
消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用,任何时间、任何低调存储和访问任意类型的数据。
分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务,网格任务支持海量任务均匀分配到所有 Worker (schedulerx-client) 执行。
在微服务架构中,通常一个系统会被拆分为多个微服务,面对这么多微服务客户端应该如何去调用呢?如果没有其他更优方法,我们只能记录每个微服务对应的地址,分别去调用,但是这样会有很多的问题和潜在因素。
-
客户端多次请求不同的微服务,会增加客户端代码和配置的复杂性,维护成本比价高。
-
认证复杂,每个微服务可能存在不同的认证方式,客户端去调用,要去适配不同的认证,
-
存在跨域的请求,调用链有一定的相对复杂性(防火墙 / 浏览器不友好的协议)。
-
难以重构,随着项目的迭代,可能需要重新划分微服务
为了解决上面的问题,微服务引入了 网关 的概念,网关为微服务架构的系统提供简单、有效且统一的API路由管理,作为系统的统一入口,提供内部服务的路由中转,给客户端提供统一的服务,可以实现一些和业务没有耦合的公用逻辑,主要功能包含认证、鉴权、路由转发、安全策略、防刷、流量控制、监控日志等。
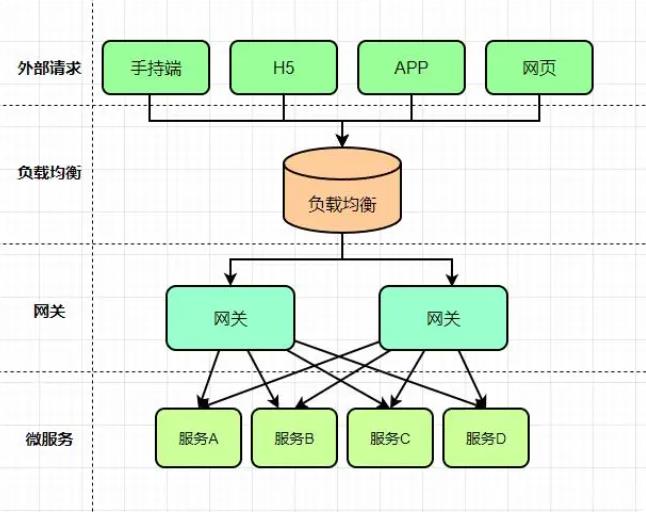
-
GateWay : 是Spring Cloud的一个全新的API网关项目,替换Zuul开发的网关服务,基于Spring5.0 + SpringBoot2.0 + WebFlux(基于性能的Reactor模式响应式通信框架Netty,异步阻塞模型)等技术开发,性能高于Zuul
- 核心流程 :
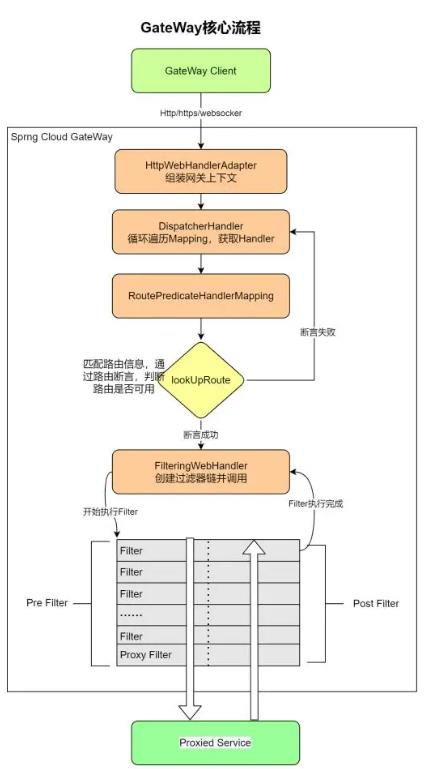
核心概念:
-
Gateway Client向Spring Cloud Gateway发送请求 -
请求首先会被
HttpWebHandlerAdapter进行提取组装成网关上下文 -
然后网关的上下文会传递到
DispatcherHandler,它负责将请求分发给RoutePredicateHandlerMapping -
RoutePredicateHandlerMapping负责路由查找,并根据路由断言判断路由是否可用 -
如果过断言成功,由
FilteringWebHandler创建过滤器链并调用 -
通过特定于请求的
Fliter链运行请求,Filter被虚线分隔的原因是Filter可以在发送代理请求之前(pre)和之后(post)运行逻辑 -
执行所有pre过滤器逻辑。然后进行代理请求。发出代理请求后,将运行“post”过滤器逻辑。
-
处理完毕之后将
Response返回到Gateway客户端
Filter过滤器:
-
Filter在pre类型的过滤器可以做参数效验、权限效验、流量监控、日志输出、协议转换等。
-
Filter在post类型的过滤器可以做响应内容、响应头的修改、日志输出、流量监控等
核心思想
当用户发出请求达到 GateWay 之后,会通过一些匹配条件,定位到真正的服务节点,并且在这个转发过程前后,进行一些细粒度的控制,其中 Predicate(断言) 是我们的匹配条件,Filter 是一个拦截器,有了这两点,再加上URL,就可以实现一个具体的路由,核心思想:路由转发+执行过滤器链
这个过程就好比考试,我们考试首先要找到对应的考场,我们需要知道考场的地址和名称(id和url),然后我们进入考场之前会有考官查看我们的准考证是否匹配(断言),如果匹配才会进入考场,我们进入考场之后,(路由之前)会进行身份的登记和考试的科目,填写考试信息,当我们考试完成之后(路由之后)会进行签字交卷,走出考场,这个就类似我们的过滤器
Route(路由) :构建网关的基础模块,由ID、目标URL、过滤器等组成
Predicate(断言) :开发人员可以匹配HTTP请求中的内容(请求头和请求参数),如果请求断言匹配贼进行路由
Filter(过滤) :GateWayFilter的实例,使用过滤器,可以在请求被路由之前或者之后对请求进行修改
博学谷学习记录超强总结,用心分享 | hive 查询分组join
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
【博学谷IT技术支持】
查询
常用函数
- 常用函数
--- 常用函数
-- 求总行数(count)
select count(1) from score; -- 36
-- 求分数的最大值(max)
select max(sscore) from score; --- 99
-- 求分数的最小值(min)
select min(sscore) from score; -- 20
-- 求分数的总和(sum)
select sum(sscore) from score; --- 2510
-- 求分数的平均值(avg)
select avg(sscore) from score; --- 69.72222222222223
- LIMIT, where, between and, is null, in
-- LIMIT语句
select * from score limit 3, 5; -- 从索引为3的行开始,显示5行
--- where 将不满足条件的行过滤掉
select * from score where sscore> 60;
-- 查询分数在80到90的所有数据
select * from score where sscore between 80 and 90;
--- 查询成绩为空的所有数据
select * from score where sscore is null;
-- 查询成绩是80或 90的数据
select * from score where sscore in (80, 90);
- like,rlike, not in
--- 查看开头是8的所有成绩
select * from score where sscore like '8%';
--- 查看第二个数据为9的成绩
select * from score where sscore like '_9%';
-- 查找id中含1的所有成绩信息
select * from score where sscore rlike '[1]';
desc score;
-- 查询成绩大于80,并且sid是01的数据
select * from score where sscore > 80 and sid='01';
-- 查询sid 不是 01和02的学生
select * from score where sid not in (01, 02);
- group by
--- group by
-- 计算每个学生的平均分数
select sid, avg(sscore) from score group by sid;
-- HAVING语句
-- having与where不同点
-- (1)where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据。
-- (2)where后面不能写分组函数,而having后面可以使用分组函数。
-- (3)having只用于group by分组统计语句。
-- 求每个学生的平均分数
select sid, avg(sscore) from score group by sid;
-- 求每个学生平均分数大于85的人
select sid, avg(sscore) avgscore from score group by sid having avgscore > 85;
join语句
-- JOIN语句
-- 内连接(INNER JOIN)
select * from teacher t, course c where t.tid = c.tid; -- 隐式内连接
select * from teacher t join course c on t.tid = c.tid; -- 显式内连接
select * from teacher t inner join course c on t.tid = c.tid; -- 显式内连接
--- 左外连接(LEFT OUTER JOIN)
-- 左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
-- 查询老师对应的课程
select * from teacher t left join course c on t.tid = c.tid;
-- 右外连接(RIGHT OUTER JOIN)
-- 右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
select * from course c right join teacher t on c.tid = t.tid;
-- 满外连接(FULL OUTER JOIN)
-- 满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
select * from teacher t Full Join course c on t.tid = c.tid;
排序
- order by
--- order by
-- Order By:全局排序,一个reduce
-- 查询学生的成绩,并按照分数降序排列
select * from student s left join score sco on s.sid = sco.sid order by sscore desc ;
-- 按照分数的平均值排序
select sid, cid, avg(sscore) avg from score group by sid, cid order by avg;
- Sort By-每个MapReduce内部局部排序
-- Sort By-每个MapReduce内部局部排序
-- Sort By:每个MapReduce内部进行排序,对全局结果集来说不是排序。
-- 设置reduce个数
set mapreduce.job.reduces=3;
-- 查询成绩按照成绩降序排列
select * from score sort by sscore;
-- 将查询结果导入到文件中(按照成绩降序排列)
insert overwrite local directory '/export/data/hivedatas/sort'
select * from score sort by sscore;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQrwMga9-1667291463952)(https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/69457d7f032f4373824eb08261b36ad4~tplv-k3u1fbpfcp-watermark.image?)]
- Distribute By-分区排序
-- Distribute By-分区排序
-- Distribute By:类似MR中partition,进行分区,结合sort by使用。
-- 注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
set mapreduce.job.reduces=7;
-- 通过distribute by进行数据的分区
insert overwrite local directory '/export/data/hivedatas/distribute'
select * from score distribute by sid sort by sscore;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xBaVtC7d-1667291463954)(https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/76b57734f2c348f2a8fd9bef4b7841b2~tplv-k3u1fbpfcp-watermark.image?)]
- Cluster By
-- Cluster By
-- 当distribute by和sort by字段相同时,可以使用cluster by方式。
-- cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
select * from score cluster by sid;
select * from score distribute by sid sort by sid;
以上是关于博学谷学习记录 自我总结 用心分享 | Alibaba- GateWay的主要内容,如果未能解决你的问题,请参考以下文章