go语言调度gmp原理
Posted zpf253
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了go语言调度gmp原理相关的知识,希望对你有一定的参考价值。
go语言调度gmp原理(5)
线程管理
go语言的运行时会通过调度器改变线程的所有权,它也提供了runtime.lockOSthread和runtime.UnlockOSthread,让我们能绑定goroutine和线程完成一些比较特殊的操作。goroutine应该在调用操作系统服务或者依赖线程状态的非go语言库时调用runtime.lockOSThread函数,例如C语言图形库等
runtime.lockOSThread会通过如下所示的代码绑定goroutine和当前线程
func lockOSThread()
getg().m.lockedInt++
dolockOSThread()
func dolockOSThread()
if GOARCH == "wasm"
return // no threads on wasm yet
gp := getg()
gp.m.lockedg.set(gp)
gp.lockedm.set(gp.m)
runtime.dolockOSThread会分别设置线程的lockedg字段和goroutine的lockedm字段,这两行代码会绑定线程和goroutine
当goroutine完成特定操作之后,会调用函数runtime.UnlockOSThread分离goroutine和线程
func unlockOSThread()
gp := getg()
if gp.m.lockedInt == 0
systemstack(badunlockosthread)
gp.m.lockedInt--
dounlockOSThread()
func dounlockOSThread()
if GOARCH == "wasm"
return // no threads on wasm yet
gp := getg()
if gp.m.lockedInt != 0 || gp.m.lockedExt != 0
return
gp.m.lockedg = 0
gp.lockedm = 0
函数执行的过程与runtime.LockOSThread正好相反。在多数服务之中,我们用不到这对函数
线程的生命周期
go语言的运行时会通过runtime.startm启动线程来执行处理器P,如果我们在该函数中没能从空闲列表中获取线程M,就会调用runtime.newm创建新线程
func newm(fn func(), pp *p, id int64)
// allocm adds a new M to allm, but they do not start until created by
// the OS in newm1 or the template thread.
//
// doAllThreadsSyscall requires that every M in allm will eventually
// start and be signal-able, even with a STW.
//
// Disable preemption here until we start the thread to ensure that
// newm is not preempted between allocm and starting the new thread,
// ensuring that anything added to allm is guaranteed to eventually
// start.
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
if gp := getg(); gp != nil && gp.m != nil && (gp.m.lockedExt != 0 || gp.m.incgo) && GOOS != "plan9"
// We\'re on a locked M or a thread that may have been
// started by C. The kernel state of this thread may
// be strange (the user may have locked it for that
// purpose). We don\'t want to clone that into another
// thread. Instead, ask a known-good thread to create
// the thread for us.
//
// This is disabled on Plan 9. See golang.org/issue/22227.
//
// TODO: This may be unnecessary on Windows, which
// doesn\'t model thread creation off fork.
lock(&newmHandoff.lock)
if newmHandoff.haveTemplateThread == 0
throw("on a locked thread with no template thread")
mp.schedlink = newmHandoff.newm
newmHandoff.newm.set(mp)
if newmHandoff.waiting
newmHandoff.waiting = false
notewakeup(&newmHandoff.wake)
unlock(&newmHandoff.lock)
// The M has not started yet, but the template thread does not
// participate in STW, so it will always process queued Ms and
// it is safe to releasem.
releasem(getg().m)
return
newm1(mp)
releasem(getg().m)
func newm1(mp *m)
if iscgo
var ts cgothreadstart
if _cgo_thread_start == nil
throw("_cgo_thread_start missing")
ts.g.set(mp.g0)
ts.tls = (*uint64)(unsafe.Pointer(&mp.tls[0]))
ts.fn = unsafe.Pointer(abi.FuncPCABI0(mstart))
if msanenabled
msanwrite(unsafe.Pointer(&ts), unsafe.Sizeof(ts))
if asanenabled
asanwrite(unsafe.Pointer(&ts), unsafe.Sizeof(ts))
execLock.rlock() // Prevent process clone.
asmcgocall(_cgo_thread_start, unsafe.Pointer(&ts))
execLock.runlock()
return
execLock.rlock() // Prevent process clone.
newosproc(mp)
execLock.runlock()
创建新线程需要使用如下所示的runtime.newosproc,该函数在Linux平台上会通过系统调用clone创建新的操作系统线程,它也是创建线程链路上距离操作系统最近的go语言函数
func newosproc(mp *m)
// We pass 0 for the stack size to use the default for this binary.
thandle := stdcall6(_CreateThread, 0, 0,
abi.FuncPCABI0(tstart_stdcall), uintptr(unsafe.Pointer(mp)),
0, 0)
if thandle == 0
if atomic.Load(&exiting) != 0
// CreateThread may fail if called
// concurrently with ExitProcess. If this
// happens, just freeze this thread and let
// the process exit. See issue #18253.
lock(&deadlock)
lock(&deadlock)
print("runtime: failed to create new OS thread (have ", mcount(), " already; errno=", getlasterror(), ")\\n")
throw("runtime.newosproc")
// Close thandle to avoid leaking the thread object if it exits.
stdcall1(_CloseHandle, thandle)
使用系统调用clone创建的线程会在线程主动调用exit或者传入的函数runtime.mstart返回时主动退出,runtime.mstart会执行调用runtime.newm时传入的匿名函数fn,至此也就完成了从线程创建到销毁的整个闭环
小结
调度器主要函数运行逻辑

Go底层原理:一起来唠唠GMP调度
目录
前言
春招开始了,作为23届的科班咸鱼学习记录一下八股文和go底层原理(GC、GMP调度、goroutine等)本文介绍 Go 语言运行时调度器的实现原理,其中包含调度器的设计与实现原理、演变过程以及与运行时调度相关的数据结构。
参考几篇不错的文章:
mingguangtu《深入分析Go1.18 GMP调度器底层原理》
刘丹冰Aceld《Golang 调度器 GMP 原理与调度全分析》
一、进程、线程、Goroutine
1、进程与线程
在了解Go的调度器的时候,都离不开操作系统、进程与线程这些概念。
| 进程 | 线程 |
|---|---|
| 操作系统资源调度和分配的基本单位 | CPU调度和分派的基本单位 |
| 一个进程可以有多个线程 | 一个线程只能属于一个进程 |
| 有独立的地址空间 | 同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器 |
| 创建销毁开销大,进程切换时,耗费资源较大 | 创建销毁开销小,线程切换时,耗费资源小 |
| 实现操作系统的并发 | 实现进程内部的并发 |
进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。资源分配给进程,同一进程的所有线程共享该进程的所有资源。同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。
在同一进程中,线程的切换不会引起进程切换。在不同进程中进行线程切换,如从一个进程内的线程切换到另一个进程中的线程时,会引起进程切换。

摘抄某知乎大佬的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
2、Goroutine
Goroutine = Golang + Coroutine。Goroutine是golang实现的用户态、轻量级的协程。Goroutine具有以下特点:
- 相比线程,其启动的代价很小,以很小栈空间启动(2Kb左右)
- 能够动态地伸缩栈的大小,最大可以支持到Gb级别
- 工作在用户态,切换成本很小
- 与线程关系是 N:M,即可以在 N 个系统线程上多工调度 M 个Goroutine
Goroutine是Golang支持高并发的重要保障。Golang可以创建成千上万个Goroutine来处理任务,将这些Goroutine分配、负载、调度到处理器上采用的是G-M-P模型。
二、Go调度器设计思想
在我们学习Go调度器前,先了解线程模型的概念,大部分的调度器都是基于线程模型思想开发的。
1、线程模型
线程创建、管理、调度等采用的方式称为线程模型。线程模型一般分为以下三种:
- 内核级线程(Kernel Level Thread)模型
- 用户级线程(User Level Thread)模型
- 两级线程模型,也称混合型线程模型
三大线程模型最大差异就在于用户级线程与内核调度实体KSE(KSE,Kernel Scheduling Entity)之间的对应关系。KSE是Kernel Scheduling Entity的缩写,其是可被操作系统内核调度器调度的对象实体,是操作系统内核的最小调度单元,可以简单理解为内核级线程。
用户级线程即协程,由应用程序创建与管理,协程必须与内核级线程绑定之后才能执行。线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程。
| 特性 | 用户级线程 | 内核级线程 |
|---|---|---|
| 创建者 | 应用程序 | 内核 |
| 操作系统是否感知存在 | 否 | 是 |
| 开销成本 | 创建成本低,上下文切换成本低,上下文切换不需要硬件支持 | 创建成本高,上下文切换成本高,上下文切换需要硬件支持 |
| 如果线程阻塞 | 整个进程将被阻塞。即不能利用多处理来发挥并发优势 | 其他线程可以继续执行,进程不会阻塞 |
| 案例 | JAVA threads | Window Solaris |
1.1 内核级线程模型
内核级线程模型中用户线程与内核线程是一对一关系(1 : 1)。线程的创建、销毁、切换工作都是有内核完成的。应用程序不参与线程的管理工作,只能调用内核级线程编程接口(应用程序创建一个新线程或撤销一个已有线程时,都会进行一个系统调用)。
操作系统调度器管理、调度并分派这些线程。运行时调度器为每个用户级线程静态关联一个内核级线程,用户线程在其生命期内都会绑定到该内核线程。一旦用户线程终止,两个线程都将离开系统。
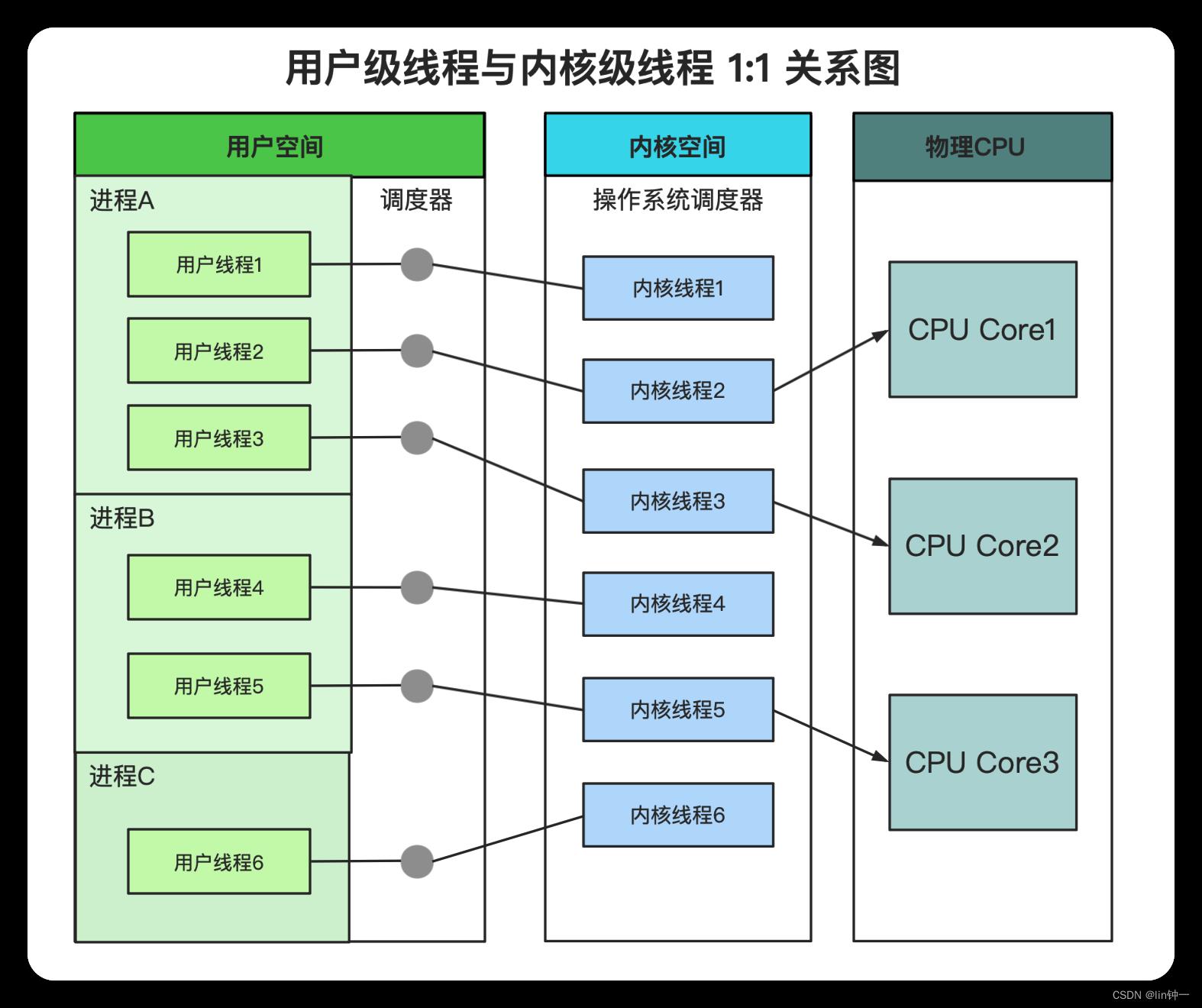
大部分编程语言的线程库(如linux的pthread,Java的java.lang.Thread,C++11的std::thread等等)都是对操作系统的线程(内核级线程)的一层封装,创建出来的每个线程与一个不同的内核级线程静态关联,因此其调度完全由OS调度器来做。
内核级线程模型有如下优点:
- 在多处理器系统中,内核能够并行执行同一进程内的多个线程
- 如果进程中的一个线程被阻塞,不会阻塞其他线程,是能够切换同一进程内的其他线程继续执行
- 当一个线程阻塞时,内核根据选择可以运行另一个进程的线程,而用户空间实现的线程中,运行时系统始终运行自己进程中的线程
缺点:
- 线程的创建与删除都需要CPU参与,成本大
- 需要使用大量线程的场景下对OS的性能影响会很大
1.2 用户级线程模型
用户线程模型中的用户线程与内核线程是多对一关系(N : 1)。线程的创建、销毁以及线程之间的协调、同步等工作都是在用户态完成,具体来说就是由应用程序的线程库来完成。线程的并发处理从宏观来看,任意时刻每个进程只能够有一个线程在运行,且只有一个处理器内核会被分配给该进程。
从图中可以看出来:一个进程中所有创建的线程都与同一个内核线程在运行时动态关联。内核线程将被操作系统调度器指派到处理器内核。用户级线程是一种”多对一”的线程映射

用户级线程有如下优点:
- 创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多, 因为保存线程状态的过程和调用程序都只是本地过程
- 线程能够利用的表空间和堆栈空间比内核级线程多
缺点:
- 线程发生I/O或页面故障引起的阻塞时,如果调用阻塞系统调用则内核由于不知道有多线程的存在,而会阻塞整个进程从而阻塞所有线程, 因此同一进程中只能同时有一个线程在运行
- 资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
1.3 混合型线程模型
混合型线程模型中用户线程与内核线程是多对多关系(N : M)。混合型线程模型充分吸收上面两种模型的优点,为一个进程中创建多个内核线程,并且线程可以与不同的内核线程在运行时进行动态关联,当某个内核线程由于其上工作的线程的阻塞操作被内核调度出CPU时,当前与其关联的其余用户线程可以重新与其他内核线程建立关联关系。
其线程创建在用户空间中完成,线程的调度和同步也在应用程序中进行。一个应用程序中的多个用户级线程被绑定到一些(小于或等于用户级线程的数目)内核级线程上。
此模型有时也被称为 两级线程模型,即用户调度器实现用户线程到内核线程的“调度”,内核调度器实现内核线程到CPU上的调度。

缺点:
- 这种动态关联机制的实现很复杂,也需要用户自己去实现。Go语言中的并发就是使用的这种实现方式,Go为了实现该模型自己实现了一个运行时调度器来负责Go中的"线程"与内核的动态关联。
这里我们只需要知道 Go 的线程模型,下面我们讲一下GMP调度的升级之路

2、 被废弃的 G-M 调度器
Golang在底层实现了混合型线程模型。Go 语言将线程分为了两种类型:内核级线程 M (Machine),轻量级的用户态的协程 Goroutine。
这里我们提到了 Go 语言调度器的三个核心概念中的两个:
-
M: Machine的缩写,代表了内核线程 OS Thread,CPU调度的基本单元
-
G: Goroutine的缩写,用户态、轻量级的协程,一个 G 代表了对一段需要被执行的 Go 语言程序的封装;每个 Goroutine 都有自己独立的栈存放自己程序的运行状态;分配的栈大小 2KB,可以按需扩缩容

2.1 了解 G-M 调度如何工作
老调度器存在一个全局 G 队列,M在执行和放回队首的 G 都需要访问全局 G 队列,因为存在多个 M 同时竞争,在访问临界资源全局 G 队列时需要加锁进行保证互斥 / 同步,所以全局 G 队列是有互斥锁进行保护的。
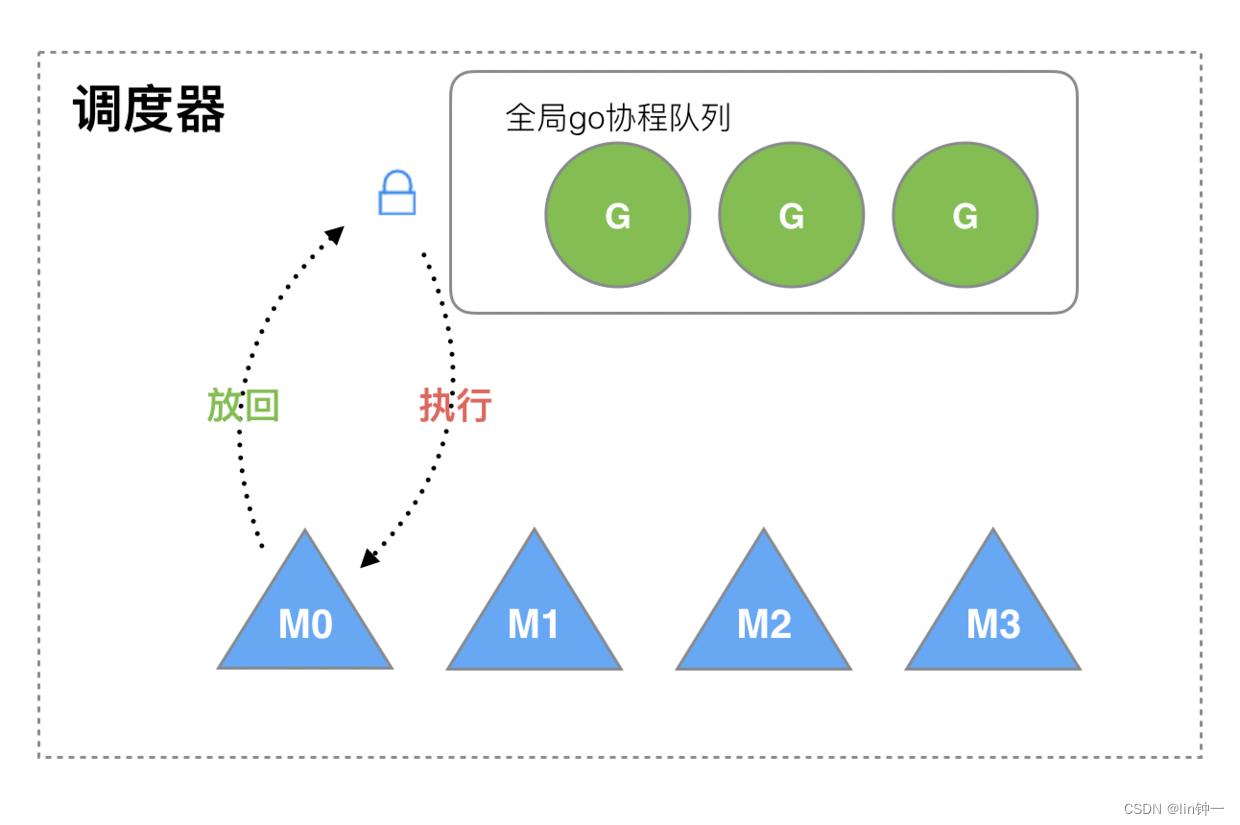
我们知道在多线程下,老调度器存在几个缺点:
- 创建、销毁、调度 G 都需要每个 M 获取锁,在多线程下这就形成了激烈的
锁竞争。 - M 转移 G 会造成延迟和额外的系统负载。比如当 G 中包含创建新协程的时候,M 创建了 G’,为了继续执行 G,需要把 G’交给 M’执行,也造成了很差的局部性,因为 G’和 G 是相关的,最好放在 M 上执行,而不是其他 M’。
- 系统调用 (CPU 在 M 之间的切换) 导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
3、如今高效的 GMP 模型
Go为了解决 G-M 调度的缺点,在原先的 G-M 调度器基础上引进了 P,也就是如今Go优秀的GMP 调度模型。
- P:Processor的缩写,
代表一个虚拟的处理器,是线程 M 和 G 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,它维护一个本地的可运行的 G 队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。

3.1 GMP模型调度流程
了解一下图中出现的几个概念:
- 全局队列(Global Queue):存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,本地队列中 G 的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列(本地队列的前一半 + G’,通常为 G’)。

GMP调度流程大致如下:
- 线程M想运行任务就需得获取 P,即与P关联
- P 的本地队列(LRQ)获取 G
- 若LRQ中没有可运行的G,M 会尝试从全局队列(GRQ)拿一批G放到P的本地队列(拿取数量 = 全局队列中 G 的数量 / 运行的 M-P 数量 + 1,至少拿一个,保证合理分配)
- 若全局队列也未找到可运行的G时候,M会随机从其他 P 的本地队列偷一半放到自己 P 的本地队列
- 拿到可运行的G之后,M 运行 G,G 执行结束后,M 会从 P 获取下一个 G,不断重复下去
- 当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P
- 当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中
3.2 GMP调度设计策略
-
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。可以使用下面两种机制实现对线程对复用。
-
Work Stealing 任务窃取机制:M 优先执行其所绑定的 P 的本地队列的 G;如果本地队列为空,当 P 本地队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列;如果全局队列也为空时,会从其他 P 的本地队列偷一半放到自己 P 的本地队列,这种 GMP 调度模型也叫任务窃取调度模型;
-
Hand Off 交接机制:当前线程 M 因为 G 进行系统调用阻塞时,线程 M 释放绑定的 P,P 会寻找其他空闲的线程 M 绑定执行, 如果没找到空闲的 M 的 P 进入全局 P 队列。
-
-
利用多核并行能力:Go默认设置线程 M 最大数量为10000,实际等于 CPU 的核心数。GOMAXPROCS 设置 P 处理器的数量,实际上 P 数量应该小于等于 CPU 核数。GOMAXPROCS 也限制了并行,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
-
基于协作的抢占机制:
- G 主动让出 CPU 才能调度执行下一个 G,某些 Goroutine 可以长时间占用线程,造成其它 Goroutine 的饥饿;
- 垃圾回收需要暂停整个程序(Stop-the-world,STW),最长可能需要几分钟的时间,导致整个程序无法工作;
- Go为了公平,让每个孩子都有奶吃,一个 G 最多占用 CPU 10ms,防止其他 G 等待时间过长被饿死。
-
基于信号的真抢占机制:尽管基于协作的抢占机制能够缓解长时间 GC 导致整个程序无法工作和大多数 Goroutine 饥饿问题,但是还是有部分情况下,Go调度器有无法被抢占的情况,例如,for 循环或者垃圾回收长时间占用线程,为了解决这些问题, Go1.14 引入了基于信号的抢占式调度机制,能够解决 GC 垃圾回收和栈扫描时存在的问题。
3.3 GMP调度场景
可能到这里对于调度流程和设计策略还是一知半解,先用几张图形象的描述下 GMP 调度机制的一些场景,帮助理解 GMP 调度器为了保证公平性、可扩展性、及提高并发效率,所设计的一些机制和策略。
3.3.1 G1 运行中创建 G2
正在 M1 上运行的 G1,通过go func() 创建 G2 后,由于局部性,G2优先放入 P 的本地队列。

3.3.2 G 运行结束后
M1 上的 G1 运行完成后(调用goexit()函数),M1 上运行的 Goroutine 会切换为 G0,G0 负责调度协程的切换(运行schedule() 函数),从 M1 上 P 的本地运行队列获取 G2 去执行(函数execute())。
注意:这里 G0 是程序启动时的线程 M(也叫M0)的系统栈表示的 G 结构体,负责 M 上 G 的调度;

3.3.3 M 上创建的 G 个数大于本地队列长度时
如果 P 本地队列最多能存 4 个 G(实际上是256个),正在 M1 上运行的 G2 要通过 go func()创建 6 个 G,那么,前 4 个 G 放在 P 本地队列中,G2 创建了第 5 个 G(G7)时,P 本地队列中前一半和 G7 一起打乱顺序放入全局队列,P 本地队列剩下的 G 往前移动,G2 创建的第 6 个 G(G8)时,放入 P 本地队列中,因为还有空间

3.3.5 M 的自旋状态
创建新的 G 时,运行的 G 会尝试唤醒其他空闲的 M 绑定 P 去执行,如果 G2 唤醒了M2,M2 绑定了一个 P2,会先运行 M2 的 G0,这时 M2 没有从 P2 的本地队列中找到 G,会进入自旋状态(spinning),自旋状态的 M2 会尝试从全局空闲线程队列里面获取 G,放到 P2 本地队列去执行,获取的数量满足公式:n = min(len(globrunqsize)/GOMAXPROCS + 1, len(localrunsize/2)),含义是每个P应该从全局队列承担的 G 数量,为了公平性和提高效率,不能太多,要给其他 P 留点;

3.3.5 任务窃取机制
自旋状态的 M 会寻找可运行的 G,如果全局队列为空,则会从其他 P 偷取 G 来执行,个数是其他 P 运行队列的一半;

3.3.6 G 发生系统调用进入阻塞时
如果 G 发生系统调度进入阻塞,其所在的 M 也会阻塞,因为会进入内核状态等待系统资源,和 M 绑定的 P 会解除绑定寻找空闲的 M 执行,这是为了提高效率,不能让 P 本地队列的 G 因所在 M 进入阻塞状态而无法执行。

GMP模型的阻塞可能发生在下面几种情况:
- I/O,select
- block on syscall
- channel
- 等待锁
- runtime.Gosched()
3.3.6.1 用户态阻塞
- 当 G 因为channel操作或者network I/O而阻塞时(实际上golang已经用netpoller实现了 G 网络I/O阻塞不会导致M被阻塞,仅阻塞G),对应的G会被放置到某个wait队列(如channel的waitq),该G的状态由_Gruning变为_Gwaitting,而M会跳过该G尝试获取并执行下一个G,如果此时没有runnable的G供M运行,那么M将解绑P,并进入sleep状态;
- 当阻塞的G被另一端的G2唤醒时(比如channel的可读/写通知),G被标记为runnable,尝试加入G2所在P的runnext,然后再是P的Local队列和Global队列。
3.3.6.2 系统调用阻塞
- 当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于 block on syscall 状态,此时的M执行可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;
- 当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。
3.3.7 G 退出系统调用时
如果刚才进入系统调用的 G2 解除了阻塞,其所在的 M1 会寻找 P 去执行,优先找原来的 P,发现没有找到或者 P 已经与其他 M 绑定,则其上的 G2 会进入全局队列,等其他 M 获取执行,M1 进入休眠线程队列,等待 P 将他重新唤醒。

以上是关于go语言调度gmp原理的主要内容,如果未能解决你的问题,请参考以下文章