用Python爬取豆瓣Top250的电影标题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python爬取豆瓣Top250的电影标题相关的知识,希望对你有一定的参考价值。
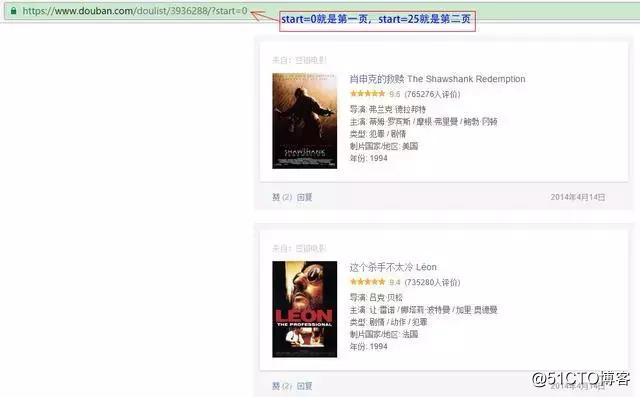
所以我们可以这么写去得到所有页面的链接
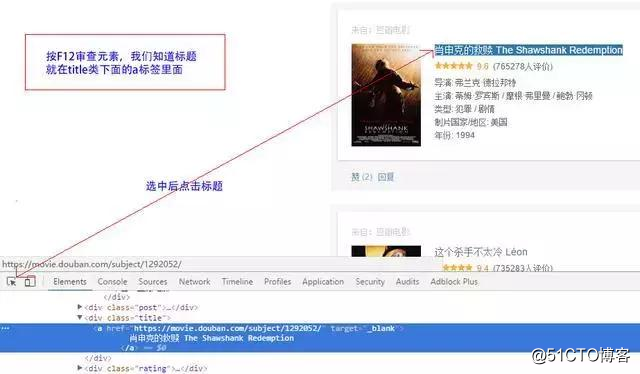

我们知道标题是在 target="_blank"> 标题的位置</a> 之中
所以可以通过正则表达式找到所有符合条件的标题

将内容写入到表格保存起来

下面贴入完整代码
import requests, bs4, re, openpyxl
url = ‘https://www.douban.com/doulist/3936288/?start=%s‘
urls = []
多少页
pages = 10
for i in range(pages):
urls.append(url%(i*25)) #得到所有页面的链接(共10页)
存储标题的数组
titles = []
urlElems = []
for index in range(pages):
res = requests.get(urls[index]) #每一页的链接
html_doc=str(res.content,‘utf-8‘) #得到链接里面的内容,转换编码
soup = bs4.BeautifulSoup(html_doc, ‘html.parser‘)
urlElems.extend(soup.select(‘.title a‘)) #得到所有 title类 下面的 a 标签(标题的位置)
try:
res.raise_for_status() #下载失败就抛异常
except Exception as exc:
print(‘There is was a problem: %s‘ %(exc))
for i in range(len(urlElems)):
将得到的标题保存在数组里面
titles.extend(re.findall(re.compile(‘‘‘target="_blank">
(.*?)[
</a>]‘‘‘),str(urlElems[i])))
wb = openpyxl.Workbook()
sheet = wb.get_active_sheet()
for i in range(len(titles)):
将标题写入表格中
sheet.cell(row = i+1, column = 1).value= titles[i]
wb.save(‘豆瓣top250.xlsx‘)#保存表格
print(‘OK‘)
好哦,大家可以举一反三,去爬取其它网站上面自己想要的内容~~~
注:python学习关注我们企鹅qun: 8393 83765 各类入门学习资料免费分享哦!
以上是关于用Python爬取豆瓣Top250的电影标题的主要内容,如果未能解决你的问题,请参考以下文章