RocketMQ 在小米的多场景灾备实践案例
Posted 阿里系统软件技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ 在小米的多场景灾备实践案例相关的知识,希望对你有一定的参考价值。
作者:邓志文、王帆
01 为什么要容灾?
在小米内部,我们使用 RocketMQ 来为各种在线业务提供消息队列服务,比如商城订单、短信通知甚至用来收集 IoT 设备的上报数据,可以说 RocketMQ 的可用性就是这些在线服务的生命线。作为软件开发者,我们通常希望服务可以按照理想状态去运行:在没有Bug的前提下,系统可以提供正常的服务能力。
但现实的运维经验告诉我们这是不可能的,硬件故障是非常常见的问题,比如内存故障、磁盘故障等,甚至是机房相关的故障(专线故障、机房拉闸等)。因此我们需要对数据进行备份,使用多副本的方式来保证服务的高可用。Apache RocketMQ 设计上就支持多副本、多节点容灾,比如 Master-Slave 架构、DLedger 部署模式。
在小米内部,因为是面向在线业务,服务的恢复速度至关重要,而基于 Raft 协议的 DLedger 模式可以实现秒级 RTO,因此我们在 2020 年初选用了 DLedger 架构作为基本的部署模式(在 5.0 中,主从模式也可以做到自动 failover)。支持机房灾备需要增加额外的成本,下面我将用三个灾备部署的实践案例,讲解小米如何在成本和可用性的取舍上去支持灾备。
02 怎么去做容灾?
单机房高可用
实际在使用中,有许多业务是不需要机房级别容灾的,只要能够做到单机房高可用即可。Apache RocketMQ 本身就是分布式的消息队列服务,可以很好的做到同机房多节点高可用,下面主要分享下小米在权衡成本、可用性的前提下,如何去做部署架构的升级优化。
我们知道在 Raft 协议中,一般配置三个节点,利用机器冗余 + 自动选主切换来实现高可用的目标。因此在小米引入 RocketMQ 之初,单 Broker 组均部署三个 Broker 节点。同时为了保证集群中始终存在 Master 节点,我们一般会至少部署两个 Broker 组,一个简单的部署架构图如下:

可以说是一个很基本的部署架构,在单个机房中,通过多副本、多Broker组做到了单机房容灾。但不难发现,这样做有一个很严重的问题:资源浪费。RocketMQ 的从节点只有在客户端读取较旧的数据时才会起到从读的作用,其他时候都只是单纯地作为副本运行,机器利用率只有33%,这是让人无法忍受的。
出于成本上的考虑,我们需要重新思考现有的部署架构,如何才能利用起来从节点呢?一个很简单的思路便是节点混布:在从节点也部署 Broker 进程,让其可以作为 Master 来提供服务。比较巧合的是,社区当时也提出了 Broker Container 的概念,方案的原理是在 RocketMQ Broker 之上抽象一个 Container 角色,Container 用来管理 Broker 的增删改查,以此来达到单台服务主机上运行多个 Broker 的目的,具体架构图如下所示:

可以看到,Container 作为进程运行,原本的 Broker 被抽象为 Container 的一部分,同样的 3 台机器上我们可以运行 9个 Broker 节点,组成三个 Broker组,每台服务主机上存在一个 Master 节点,使用 Container 对等部署 Broker 之后,每台服务主机都得到了利用,同样的机器数,理论上可以提供三倍的性能。
Container 是一种很好的部署思想:主从节点对等部署进而充分利用所有的机器。 我们尝试直接使用该方案,但遇到了一些问题:
-
Container 本质上是一个进程。不管其内运行了多少个 Broker ,我们只要对其进行重启操作,都会影响该 Container 内部 Broker 相关的所有 Broker 组,升级时会产生较为严重的影响;
-
Container 自己维护 Broker 的上下线,无法与小米内部部署工具结合使用。
因此 Container 并不适合小米内部,但受 Broker Container的启发,我们提出了另一种与之类似的部署方案——单机多实例。所谓单机多实例,即单台主机上部署多个 Broker 实例,服务主机就是我们的 Container,Broker 以进程的方式运行,这样各个 Broker 之前不会相互影响,同时也可以和内部部署工具完美结合。一个简单的部署架构如下所示:

至此,小米内部完成了 RocketMQ 部署架构的第一次升级,集群中的节点数直接减少了 2/3。在成本优化的前提上依然提供 99.95% 的可用性保障。
多机房容灾 -Ⅰ
随着业务的不断接入,一些业务提出了机房灾备的需求。机房故障的概率虽然极低,但是一旦出现,其带来的影响是非常大的。比如机房故障导致 RocketMQ 不可用,那么作为流量入口,将会影响到所有的依赖业务。
在多机房容灾上,我们结合内部其他服务的部署经验,先提出了多集群多活的方式,即每个可用区部署一个集群,提供多个集群供业务容灾,方案部署架构如下:

用户视角看到的是三个独立的集群,需要在相同的可用区部署客户端去读写同机房的 RocketMQ 集群。举个例子:可用区1的客户端正常情况下访问可用区1的 RocketMQ 集群Cluster-1,当Cluster-1故障时,用户需要手动更改客户端的连接地址来切换集群,进而将流量转移到其他机房的集群中。用户可以通过配置下发去热更新连接地址,也可以修改配置重启客户端来切换,但这一切的操作前提都是:需要业务感知到 RocketMQ 集群故障,手动触发才可以。
▷优点
-
不用跨区同步数据,低延时(P99写入10ms)高吞吐(单Broker组写入TPS达100K)
-
部署架构简单,稳定性高
▷缺点
-
集群需预留灾备buffer,确保故障时,存活集群可承载故障集群的全部流量
-
需要业务自己手动切换集群,不够灵活
-
若消费存在堆积,故障集群的消息将可能不会被消费,恢复后可消费
▷生产耗时

多机房容灾 -Ⅱ
可以看到,业务如果选择以上方式接入的话,需要做一定的适配工作,该方案适用于流量较大的业务接入。然而有一些业务希望可以低成本接入:不做适配,直接使用SDK接入,我们结合 DLedger 自动切换的特性,实验性的部署了机房故障服务自动 failover 的 模式,部署架构如下所示:

用户视角看到的就是一个独立的 RocketMQ 集群,使用 SDK 正常接入即可,无需任何适配。机房故障时依赖 DLedger 自动切主做流量切换。
▷优点
-
部署方便,充分利用 RocketMQ 的原生能力
-
自动选主,业务接入方便,无需业务手动切换流量
▷缺点
-
跨机房部署,容易受网络波动,集群抖动概率较大
-
跨机房部署,会增加写入延时,从而降低集群吞吐能力
▷生产耗时

多机房容灾 - PLUS
目前看来 RocketMQ 服务已经在小米完成了很好的落地,日消息量也达到了千亿规模,但我们仔细观察以上两个方案不难发现,虽然可以实现机房故障切换,但都有一定的缺点,简要概况如下:
-
多机房容灾 -Ⅰ:同机房请求,延时较低,但需业务手动切换集群
-
多机房容灾 -Ⅱ:自动切流、可消费历史数据,但对专线负载高,需三个Region才可部署
方案总是存在不够完美的地方,但不论作为服务的开发者还是业务使用者,其实都希望可以在实现以下几个目标的前提下做到灾备:
1)低成本:双Region可以完成部署;
2)低耗时:尽量同机房请求,减少网络耗时;
3)自动切流:机房故障时,可自动将流量切到正常的机房内。
为了实现以上的需求,我们从 RocketMQ 自身的架构出发,希望能够以最低的改造成本支持灾备。我们发现客户端都是根据 Namesrv 返回的元数据进行生产、消费,只要客户端能够在机房故障时,可以根据元数据自动将流量切走即可,因此我们将视角移到了客户端,希望从客户端上支持灾备的功能。
RocketMQ 所有 Broker 都会将自己注册到 Namesrv 上去,一旦某个 Broker 组故障,那么它的信息将会被从 Namesrv 中移除,客户端也就无法再向这类 Broker 组发送、拉取消息。基于以上逻辑,只要我们将 Broker组部署在不同机房中,便可以做到机房级别的灾备效果。部署架构如下:

我们以一个实际的例子来讲解以上方案的可行性:Topic-A 在两个可用区上均存在分区,SDK在使用时需要配置自己所在的region。
对于生产者来说,客户端只会向位于相同可用区的分区发送消息。例如:位于可用区1的客户端只会向可用区1发送消息,当可用区1故障时,由于在可用区1不存在可写的分区,便会开始向可用区2发送消息,从而实现生产侧的自动切流。消费者同样需要配置 region ,所有的消费实例会先按照可用区分别去做 rebalance:分区会优先被相同可用区的消费者去分配消费。当可用区1故障时,由于生产者已经将流量切走,因此消费者不需要做特殊变更就做到了消费自动切流。

该方案对于业务来说是一个可选项,业务可自行决定是否需要开启灾备模式,因此较为灵活,可以说是结合了以往两种机房灾备方案的优点,但是仍有不足之处,比如故障集群在故障期间历史消息不可被消费等,后续也会不断的优化方案。
03 来做个总结吧!
本文介绍了四种部署模式,针对不同的业务需求提供不同的部署模式,总结如下:
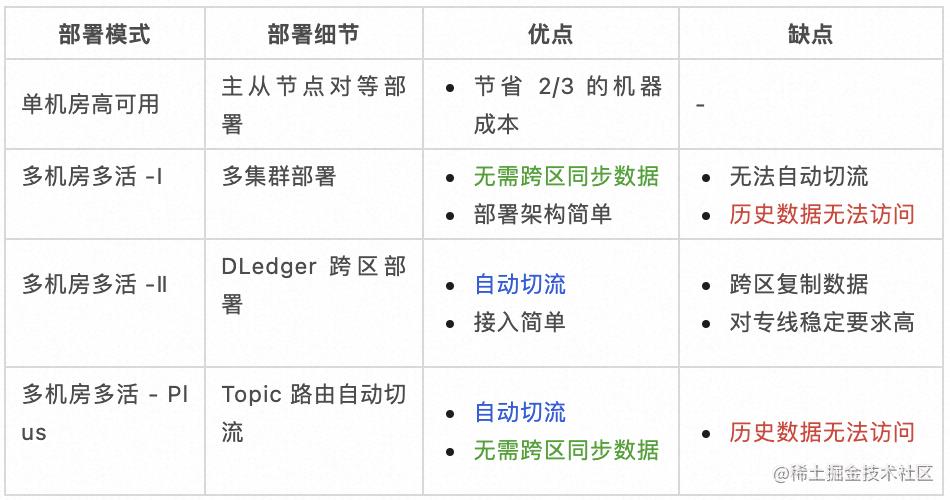
目前以上方案在小米内部均有具体的业务场景,消息量约占总体的 90%,未来也会逐步将剩余流量相关集群全部升级为机房灾备集群,从而提供 99.99% 的可用性服务能力。

虚拟化项目的监控灾备及案例 | 肖力说KVM
编辑
高浩淼-北京
嘉宾介绍
肖力 资深KVM专家
拥有15年运维经验,就职于金山西山居,担任系统运维经理,曾就职于盛大游戏,从2009年开始研究KVM技术,是国内较早在生产环境大规模实践KVM的人之一,积累了非常丰富的经验。著有《深度实践KVM》一书。
专栏简介
本次介绍长期的虚拟化项目实践中的经验,主要介绍如何将已有的业务迁移到虚拟化环境。本文是第四篇。其他三篇的链接如下:
正文
本文介绍虚拟化运维中的监控、报警、灾备及应急响应要点是什么。

监控报警
硬件故障报警,现在主要是使用带外管理卡报警。
新一代服务器,带外管理卡监控已经非常完善,CPU、内存、磁盘、网卡、风扇、电源任何硬件故障都会报警,通过邮件,或者写脚本和自己的监控平台结合,可以很好的解决硬件报警的问题。
CPU:建议每个核的CPU利用率也监控起来,经常会碰到一直情况,就是整体的CPU利用率不高,可能只有20-30%;但是有一两个核已经100%了,这时候其实已经碰到压力瓶颈了,但是通过整体的CPU利用率是发现不了的。
内存:swap利用情况建议也监控起来,作为虚拟化来说,一般不希望宿主机使用swap分区,所以swap的使用要监控起来,方便出问题的时候排查,如果有大量的swap使用,应该设置报警,肯定是碰到性能问题了。
磁盘、网络:虚拟化磁盘、网络是两个难点,一般在上线之前,应对其性能进行压力测试,得到极限数据,然后根据极限数据设置报警阀值。
灾备及应急响应
虚拟化的灾备有两种思路,应用层灾备及虚拟化层灾备,一般建议在应用层灾备。
虚拟化层灾备的手段是多份的镜像复制及快照,这个往往要消耗大量的资源,多份复杂是以牺牲几倍的磁盘空间为代价,快照是以牺牲性能为代价。
往往应用层即使做了很少的改动,虚拟化层难以感知,于是只能全部备份,或者快照。
但是应用层灾备就简单很多,只需要备份最近改动的部分,消耗的资源很少,而且速度很快。
灾备还要注意,定期演练非常重要,一方面是验证自己的灾备几种,一方面也是让参与的人能熟悉灾备过程,这样当发生问题的时候,就可以很快的恢复业务。
软硬件选型
软件方面,当然是稳定版本,但是在稳定版本的基础上,内核版本越高越好,为什么呢?
因为内核版本越高,对CPU的上下文切换和中断优化的越好,越有利于提高宿主机转化率。Windows系统也一样,Windows虚拟机建议尽量使用比较新的版本。
硬件方面越强悍越好,内存越大越好,硬件越强悍,可以虚拟的虚拟机越多,从长时间综合看,肯定是节省成本的。
另外,一台宿主机,使用上一段时间,我们往往发现内存是瓶颈点,所有一开始的时候,尽量内存配置点一点,可以避免随后的内存瓶颈。
公有云的选择
下面是本系列专栏的最后一项内容公有云选择的一些经验。
用户选择公有云的主要因素主要有以下5条:

市场
主要是价格,还有写公司和某些公有云就有合作,或者就是老板强制指定必须使用某款公有云。云主机稳定性
选择公有云,对用户来说,最终用的就是云主机,所以云主机的稳定性也是重要因素,如果云主机三天两头崩溃、重启,甚至数据丢失。这方面,一般公有云都能做到。网络覆盖及网络质量
在云上业务都是基于网络,网络质量是一个很关键的因素,网络质量包含多个因素:覆盖范围,覆盖范围越广越好;
延时,丢包,抖动,就是延时、丢包符合要求,网络抖动不能很频繁。大数据分析、RDS、运维工具支持
如果公有云能提供API,提供一套方便业务部署监控的工具,对用户也有一定的吸引力,尤其是运维。融合物理机和云主机的混合云是喜闻乐见的解决方案
业务压力非常高,就需要物理机的支持,现在可以看到好多公有云也开始支持物理机的租用。
将业务迁移到云上,其实和虚拟化的过程是一样的,按照前面介绍的流程去做,可以保证比较稳定的完成,而且虚拟化的具体技术还不用我们关心。
最后,总结下本系列分享的内容:

在企业内部实施虚拟化,最重要的时候口碑,如果一个项目接一个项目成功实施,就会越做越顺利,相反,如果连续失败几个项目,虚拟化就推行不下去了。
(以上内容节选自《深度实践KVM》一书)
好消息来啦
全球运维大会·上海站,将于10月31日举行,届时三大运维体系(精益运维、高效运维和白盒运维),将首度同台汇演。本次会议免费,如需报名或了解详情,请猛戳如下链接。
如何一起愉快地发展
尊重知识,请必须全文转载,并包括本行。
欢迎点击广告或赞赏,以鼓励我们做得更好。谢谢:)
以上是关于RocketMQ 在小米的多场景灾备实践案例的主要内容,如果未能解决你的问题,请参考以下文章