(Python第八天)模块
Posted ywangji
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(Python第八天)模块相关的知识,希望对你有一定的参考价值。
一、模块
为了便于使用、调试以及拥有更好的可读性,我们使用模块来达到目的,模块就是包括Python定义和声明的文件
我们可以由全局变量__name__得到模块的模块名。
2)导入模块
有不同的方式导入模块,甚至可以从模块中导入指定的函数
from module import *
导入模块中的所有定义
二、包
含有__init__.py 文件的目录可以用来作为一个包,目录里的所有.py文件都是这个包的子模块
实例:mymodule是一个包名,并且bars和utils是里面的两个子模块
如果__init__.py文件内有一个名为__all__的列表,那么只有在列表内列出的名字将会被公开,如果mymodule内的__init__.py文件内含有以下内容:
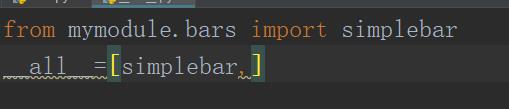
导入的时候只有simplebar可用,
三、默认模块
1)os模块
getuid()返回当前进程的有效用户id
getpid()返回当前进程的id
getppid()返回父进程的id
uname()返回识别操作系用的不同信息
getcwd()返回当前工作目录
chdir(path)更改当前目录到path
实例:创建一个自己的函数,这个函数打印给定目录中的所有文件和目录,
def view_dir(path=\'.\'): #默认当前目录
names = os.listdir(path)
names.sort()
for name in names:
print(name, end =\' \')
print()
ps:1)os.listdir()
返回指定路径下的文件和文件夹列表。
用法是:
import os, sys # 打开文件 path = "/var/www/html/" dirs = os.listdir( path ) # 输出所有文件和文件夹 for file in dirs: print file
2)list.sort()方法
该方法没有返回值,但是会对列表的对象进行排序。
list.sort(cmp=None, key=None, reverse=False)
- cmp -- 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
例子:
aList = [123, \'Google\', \'Runoob\', \'Taobao\', \'Facebook\']; aList.sort(); print "List : ", aList
List : [123, \'Facebook\', \'Google\', \'Runoob\', \'Taobao\']
3)end()
python中“end=”用法:例如print(“#”,end=" \\n")在打印过程中默认换行,print(“#”,end=" ")则在循环中不换行


2)Requests模块
Requests是一个第三方Python模块,即需要安装这个模块,是唯一的一个Python HTTP库
1)使用get()获取任意一个网页
实例:

req的text属性存有服务器返回的HTML网页,这个实例可以让我们写一个能够从指定的URL中下载文件的程序
1 import os 2 import os.path 3 import requests 4 5 def download(url): 6 req = requests.get(url) 7 # 首先我们检查是否存在文件 8 if req.status_code == 404: 9 print(\'No such file found at %s\' % url) 10 return 11 filename = url.split(\'/\')[-1] 12 with open(filename, \'wb\') as fobj: 13 fobj.write(req.content) 14 print("Download over.") 15 16 if __name__ == \'__main__\': 17 url = input(\'Enter a URL: \') 18 download(url)
1)open()函数用法
①文件操作的流程
#1打开文件,得到文件句柄并赋值给一个变量
#2用过句柄对文件进行操作
#3关闭文件
②关于打开模式
r 只读方式打开文件
rb 以二进制格式打开一个文件用于只读
w 打开一个文件用于写入
w+ 打开一个文件用于读写,如果该文件已经存在则将其覆盖,如果该文件不存在,创建新文件
a 打开一个文件用于追加
后面有带b的方式,不需要考虑编码方式
2)url.split(\'/\')[-1]的含义
实例:
url = "http://www.runoob.com/python/att-string-split.html" path = url.split(\'.\')[-1] print(path)
输出
html#该实例以。以分隔符保留最后一段
url.split(\'/\')[-1] 就是获得一个url最后一个/后的字符串
②split("/")[-1] 和 split("/",-1)的区别
str="http://www.runoob.com/python/att-string-split.html"
print("0:%s"%str.split("/")[-1])
print("1:%s"%str.split("/")[-2])
print("2:%s"%str.split("/")[-3])
print("3:%s"%str.split("/")[-4])
print("4:%s"%str.split("/")[-5])
print("5:%s"%str.split("/",-1))
print("6:%s"%str.split("/",0))
print("7:%s"%str.split("/",1))
print("8:%s"%str.split("/",2))
print("9:%s"%str.split("/",3))
print("10:%s"%str.split("/",4))
print("11:%s"%str.split("/",5))
结果是:
0:att-string-split.html
1:python
2:www.runoob.com
3:
4:http:
5:[\'http:\', \'\', \'www.runoob.com\', \'python\', \'att-string-split.html\']
6:[\'http://www.runoob.com/python/att-string-split.html\']
7:[\'http:\', \'/www.runoob.com/python/att-string-split.html\']
8:[\'http:\', \'\', \'www.runoob.com/python/att-string-split.html\']
9:[\'http:\', \'\', \'www.runoob.com\', \'python/att-string-split.html\']
10:[\'http:\', \'\', \'www.runoob.com\', \'python\', \'att-string-split.html\']
11:[\'http:\', \'\', \'www.runoob.com\', \'python\', \'att-string-split.html\']
即: -1 :全切 0 :不切 1:切一刀 (每一块都保留)
[-1]:将最后一块切割出来 [-2]:将倒数第二块切割出来 (只保留切出来的一块)
3)request content
request一般情况下text提取出来的可能是乱码,但是content提取出来的不会是乱码
req.text返回的是Unicode型的数据,使用req.content返回的是bytes型的数据,即想提取文本,使用req.text,想提取图片,文件,通过req.content
# 例如下载并保存一张图片
import requests
jpg_url = \'http://img2.niutuku.com/1312/0804/0804-niutuku.com-27840.jpg\'
content = requests.get(jpg_url).content
with open(\'demo.jpg\', \'wb\') as fp:
fp.write(content)
4)os.path可以检查当前目录是否已经存在相同的文件名
四、Pycharm中的部分快捷键
1、Ctrl + Enter:在下方新建行但不移动光标;
2、Shift + Enter:在下方新建行并移到新行行首;
3、Ctrl + /:注释(取消注释)选择的行;
4、Ctrl+d:对光标所在行的代码进行复制。
以上是关于(Python第八天)模块的主要内容,如果未能解决你的问题,请参考以下文章