臭名昭著的“Hello,World!”
Posted 念经似的zzz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了臭名昭著的“Hello,World!”相关的知识,希望对你有一定的参考价值。

#include <iostream> using namespace std; int main(int argc, char** argv) int input = 10; cout << "Hello, world!\\n" << endl; cin >> input; return 0;
-
标准库 其使用到了c++标准库iostream。c++属于高级语言,其包含有很多封装好的库,所以学习库如何使用及其原理也是至关重要的。iostream是c++的常用标准库之一内部包含了很多我们常用的流文件的处理,如输入和输出。为了防止库与我们自定义的变量名称冲突,所以它使用了命名空间,封装的命名空间名称为std。
-
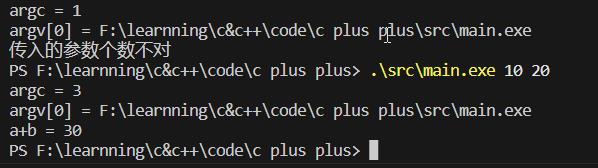
int main(int argc, char** argv) 系统运行的初始函数就是main函数,其第一个参数是argc(argument count)表示需要传入的参数个数,第二个参数是argv(argument value)表示需要传入的参数值。默认argc值为1,argv里保存的是程序的名称。至于为什么argv第一个保存的是程序的名称,可能是因为程序员会用到?不是我们需要关心的问题。
#include <iostream> using namespace std; int main(int argc, char** argv) cout << "argc = " << argc << endl; cout << "argv[0] = " << argv[0] << endl; return 0;



#include <iostream> using namespace std; int main(int argc, char** argv) cout << "argc = " << argc << endl; cout << "argv[0] = " << argv[0] << endl; if(argc == 3) int a = stoi(argv[1]); int b = stoi(argv[2]); cout << "a+b = " << a+b << endl; else cout << "传入的参数个数不对"<<endl; return 0;
-
main函数返回值
-
编写main函数梭哈return 0可不是个好习惯,应该根据不同情况返回不同值,方便程序执行过程中就可以得知程序是那个环节出现问题。
-
main函数中的return 0是返回给操作系统的,如不需要返回给操作系统可定义void main(),常见于单片机程序。
-
return 0 exit(0) _exit(0)区别,
-
return是关键字,exit(0)和_exit(0)是函数
-
return是返回给上一级,exit(0)和_exit(0)是退出进程,在main函数里,return 0 和 exit(0) 效果一样
-
exit(0)退出进程前刷新IO缓冲区,_exit(0)属于内核中的系统调用,不会刷新IO缓冲区
为啥“hello” + + '/' + “world” == “hello47world”?
【中文标题】为啥“hello” + + \'/\' + “world” == “hello47world”?【英文标题】:Why does "hello" + + '/' + "world" == "hello47world"?为什么“hello” + + '/' + “world” == “hello47world”? 【发布时间】:2015-08-01 17:48:37 【问题描述】:对于这个 C#,a==true:
bool a = "hello" + '/' + "world" == "hello/world";
对于这个 C#,b==true:
bool b = "hello" + + '/' + "world" == "hello47world";
我想知道这是怎么回事,更重要的是,为什么 C# 语言架构师会选择这种行为?
【问题讨论】:
此线程中的每个人:“+ 是一个将char 转换为int 的一元运算符”。此线程中没有人:“这就是它这样做的原因......”
@fgp 我有一整篇关于为什么 int 的帖子,但我怀疑有人在乎 :)
@Rawling 启发我 ;-)
@fgp 韦尔普,给你。这是令人兴奋的事情。
@leftaroundabout 不,在这个意义上它类似于C, C++、Java 或Javascript,因为它们都使用一元 + 将 char 提升为 int
【参考方案1】:
第二个+ 将char 转换为int,并将其添加到字符串中。 / 的 ASCII 值为 47,然后由另一个 + 运算符转换为字符串。
斜杠前的+ 运算符将其隐式转换为int。请参阅 MSDN 上的 + Operator 并查看“一元加号”。
对数值类型进行一元 + 运算的结果就是操作数的值。
我实际上是通过查看+ 操作员实际调用的内容来解决这个问题的。 (我认为这是 ReSharper 或 VS 2015 的功能)
【讨论】:
很好,Resharper 总是让我大吃一惊!加入 JetBrain 团队! "因为+在斜线之前,所以返回递增之前的值。" ++ 运算符,那你为什么要提到它们呢?这里的+ 是一元+ 运算符,它是整数上的标识。
这可能是我正在使用的 VS 2015 的一个功能。 (同样在 Resharper 9 上)
我没有 Re,它仍然对我有用,因此它是 VS 2015。
是的。只需检查 C# 内置转换和运算符。 C# 中的operator + 具有许多内置重载。这里相关的 binary 是string operator +(string x, object y),它在object 参数y 上调用ToString(),并将两个字符串连接起来。对于unary overloads,重要的是要注意char 中没有一元重载。但是 char 可以隐式转换为 ushort 一个“更大”的整数类型。这包括int,而+'/' 的最佳重载就是int operator +(int x)。【参考方案2】:
那是因为您使用的是一元运算符+。它类似于一元运算符-,但它不会改变操作数的符号,所以它在这里的唯一作用是将字符'/'隐式转换为int。
+'/'的值为/的字符码,即47。
代码与以下内容相同:
bool b = "hello" + (int)'/' + "world" == "hello47world";
【讨论】:
但我想知道让一元+ 在 char 上定义的动机是什么。我可能会使其成为编译时错误。如果有人需要数值,为什么不明确并使用强制转换? (那么,基本上,为什么char 有隐式 转换为int?)
@Vlad:Eric Lippert 写过一些关于这方面的文章:blogs.msdn.com/b/ericlippert/archive/2009/10/01/…
@Guffa:文本的匹配部分是“C 编程中将字符视为整数的悠久传统 - 以获得它们的基础值,或对它们进行数学运算。 ”,我将其解读为“C 时代的遗产,一切都是数字”。截至目前,使用非英语语言环境(因此有效字母不再是范围)和 Unicode 及其怪癖(所以大写不再是位操作,两个字符一起不一定会产生两位字符串) ,使用数字字符值的想法越来越没有吸引力了。
@Vlad:是的,这是真的。允许隐式转换的动机是它无害,就像允许从数字到字符的隐式转换一样。 OP 发现了这些特殊情况的组合,它们共同产生了意想不到的结果;很少使用的一元加运算符导致隐式转换,从 char 到 int 的隐式转换,以及字符串和 int 的连接。如果其中任何一个需要明确,代码就不会那样工作。【参考方案3】:
为什么,我听到你问,char 是专门针对运营商int operator +(int x) 而不是many other fine unary + operators available 之一?:
char 没有任何这些,编译器查看 predefined 一元 + 运算符。
显然none of those 也可以使用char,因此编译器使用overload resolution rules 来决定哪个运算符(int、uint、long、ulong、@9876543345@、@9876 @decimal) 是最好的。
那些解析规则说看看哪个是best function...几乎说看看哪个参数类型从char提供best conversion。
int 击败了 long、float 和 double,因为您可以将 implicitly convert int 用于这些类型而不是返回。
int 胜过 uint 和 ulong,因为...最佳转换规则确实如此。
【讨论】:
太棒了,这解释了为什么 C# 架构师将它设计为按照它的方式工作。谢谢!【参考方案4】:这是如何发生的是隐式转换(“一个 char 可以隐式转换为 ushort、int、uint、long、ulong、float、double 或 decimal。”(@987654321 @)。
最简单的复制形式如下
int slash = +'/'; // 47
Char 内部是一个结构。 “目的:这是代表 Unicode 字符的值类”(char.csms referencesource),而结构体可以被隐式转换的原因是因为它实现了IConvertible界面。
public struct Char : IComparable, IConvertible
具体来说,用这段代码
/// <internalonly/>
int IConvertible.ToInt32(IFormatProvider provider)
return Convert.ToInt32(m_value);
IConvertible 接口在代码注释中声明
// IConvertible 接口表示一个包含值的对象。这 // 接口由 System 命名空间中的以下类型实现: // Boolean, Char, SByte, Byte, Int16, UInt16, Int32, UInt32, Int64, UInt64, // Single、Double、Decimal、DateTime、TimeSpan 和 String。
回顾 struct 的用途(作为一个代表 unicode 字符的值),很明显,该语言中这种行为的目的是提供一种将值转换为支持的类型的方法。 IConvertible 继续声明
// System.XXX值类提供的IConvertible的实现 // 只需转发到相应的 Value.ToXXX(YYY) 方法( // Value 类如下所示)。如果使用 Value.ToXXX(YYY) 方法 // 不存在(因为不支持特定的转换), // IConvertible 实现应该简单地抛出一个 InvalidCastException。
其中明确指出不支持的转换会引发异常。还明确指出,将字符转换为整数将给出该字符的整数值。
ToInt32(Char) 方法返回一个 32 位有符号整数,表示 value 参数的 UTF-16 编码代码单元。 Convert.ToInt32 Method (Char)MSDN
总而言之,这种行为的原因似乎是不言而喻的。 char 的整数值具有“UTF-16 编码代码单元”的含义。反斜杠的值为 47。
由于存在值转换并且char 是内置数字类型,因此从加号到整数的隐式转换是在编译时完成的。这可以通过在一个小程序中重用上面的简单示例来看出(linqpad 可以对此进行测试)
void Main()
int slash = +'/';
Console.WriteLine(slash);
变成
IL_0000: ldc.i4.s 2F
IL_0002: stloc.0 // slash2
IL_0003: ldloc.0 // slash2
IL_0004: call System.Console.WriteLine
IL_0009: ret
'/' 被简单地转换为 2F 的十六进制值(十进制的 47),然后从那里使用。
【讨论】:
【参考方案5】:+ '/'
为您提供字符“/”的UTF-16 (decimal) 47 字符代码,@Guffa 已经向您解释了原因。
【讨论】:
感谢@Guffa 指出该错误。 C# 使用 UTF-16 作为 .NET 中字符串的默认编码 @Guffa 有趣...如果你有+'?' 会发生什么?会不会导致语法错误?
@Rhymoid 会导致错误。 “字符文字中的字符太多”
@Cyral 有道理。对于那些想知道:表情符号位于 SMP 中的人,因此 UTF-16 使用代理对对其进行编码(在本例中为:U+D83C U+DF81),编译器将其视为“两个字符”(这与事实相去甚远'甚至没有错)。【参考方案6】:
在 c# 中,一个 char 用单引号表示,即在您的情况下为 '/',char 前面的 + 运算符充当一元运算符,并要求编译器提供 char '/' 的 UTF 值,是 47 岁。
【讨论】:
以上是关于臭名昭著的“Hello,World!”的主要内容,如果未能解决你的问题,请参考以下文章