8千多古诗词唐诗宋词鉴赏ACCESSEXCEL数据库
Posted 数据挖掘整理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了8千多古诗词唐诗宋词鉴赏ACCESSEXCEL数据库相关的知识,希望对你有一定的参考价值。
虽然已经有很多诗词类的数据库,最近又再次找了一下古诗词类的数据,又发现了一些,可是真的是各有各的优点,各有各的特色,之后不再重找诗词类的数据了。
今天这个诗词鉴赏数据也不错,有分类TAG,也有译文、注释、品析、朝代,但是又有些不足,详见下面说明:

朝代记录统计:金朝(15)、近代(8)、两汉(143)、明代(133)、南北朝(89)、清代(236)、宋代(1229)、隋代(12)、唐代(1650)、未知(22)、魏晋(96)、五代(72)、先秦(414)、现代(4231)、元代(93)。现代的竟然有4千多条,哎其一。现代的都没有译文、注释、品析内容,哎其二。
fanyi字段有内容的记录共有3376条,zhushi字段有内容的记录共有3882条,pingxi字段有内容的字段有536条。
截图下方有显示“共有记录数”,截图包含了表的所有字段列。该数据提供ACCESS数据库文件(扩展名是MDB)以及EXCEL文件(扩展名是XLS)。
爬虫实例:唐诗宋词爬虫
每年都期待夏天赶紧变成秋天,没有木头马尾的九月,没有颜色奇迹的南方,只得古诗词里把情绪商量,算云烟,此处认春秋。
基本分析
1.根据古诗词网页结构,可以看出诗词正文有两种结构,一种是p标签分隔的,一种是br标签分隔的
from lxml import etree s = """ <div id="contson47919" class="contson"> <p>aaa<br>a</p> <p>bb</p> <p>c</p> </div> """ selector = etree.HTML(s) #s = selector.xpath(\'//*[@class="contson"]/p\') #aaa #s = selector.xpath(\'string(//*[@class="contson"]/p)\') #aaaa s = selector.xpath(\'string(//*[@class="contson"])\') # aaaa \\n bb \\n c #print list(s) #[\'\\n\', \'a\', \'a\', \'a\', \'a\', \'\\n\', \'b\', \'b\', \'\\n\', \'c\', \'\\n\'] s = [i for i in s if i != \'\\n\'] #[\'a\', \'a\', \'a\', \'a\', \'b\', \'b\', \'c\'] s = \'\'.join(s) print type(s) #<type \'str\'> print s #aaaabbc import re s = """ <div id="contson47919" class="contson"> <p> 环滁皆山也。其西南诸峰,林壑尤美,望之蔚然而深秀者,琅琊也。山行六七里,渐闻水声潺潺而泻出于两峰之间者,酿泉也。峰回路转,有亭翼然临于泉上者,醉翁亭也。作亭者谁?山之僧智仙也。名之者谁?太守自谓也。太守与客来饮于此,饮少辄醉,而年又最高,故自号曰醉翁也。醉翁之意不在酒,在乎山水之间也。山水之乐,得之心而寓之酒也。</p> <p> 若夫日出而林霏开,云归而岩穴暝,晦明变化者,山间之朝暮也。野芳发而幽香,佳木秀而繁阴,风霜高洁,水落而石出者,山间之四时也。朝而往,暮而归,四时之景不同,而乐亦无穷也。</p> <p> 至于负者歌于途,行者休于树,前者呼,后者应,伛偻提携,往来而不绝者,滁人游也。临溪而渔,溪深而鱼肥。酿泉为酒,泉香而酒洌;山肴野蔌,杂然而前陈者,太守宴也。宴酣之乐,非丝非竹,射者中,弈者胜,觥筹交错,起坐而喧哗者,众宾欢也。苍颜白发,颓然乎其间者,太守醉也。</p> <p> 已而夕阳在山,人影散乱,太守归而宾客从也。树林阴翳,鸣声上下,游人去而禽鸟乐也。然而禽鸟知山林之乐,而不知人之乐;人知从太守游而乐,而不知太守之乐其乐也。醉能同其乐,醒能述以文者,太守也。太守谓谁?庐陵欧阳修也。</p> </div> <div id="contson49394" class="contson"> 大江东去,浪淘尽,千古风流人物。 <br> 故垒西边,人道是,三国周郎赤壁。 <br> 乱石穿空,惊涛拍岸,卷起千堆雪。 <br> 江山如画,一时多少豪杰。 <br> 遥想公瑾当年,小乔初嫁了,雄姿英发。 <br> 羽扇纶巾,谈笑间,樯橹灰飞烟灭。(樯橹 一作:强虏) <br> 故国神游,多情应笑我,早生华发。 <br> 人生如梦,一尊还酹江月。(人生 一作:人间;尊 通:樽) </div> <div id="contson52821" class="contson"> <p> 寻寻觅觅,冷冷清清,凄凄惨惨戚戚。乍暖还寒时候,最难将息。三杯两盏淡酒,怎敌他、晚来风急?雁过也,正伤心,却是旧时相识。 <br> 满地黄花堆积。憔悴损,如今有谁堪摘?守着窗儿,独自怎生得黑?梧桐更兼细雨,到黄昏、点点滴滴。这次第,怎一个愁字了得!(守着窗儿 一作:守著窗儿) </p> </div> """ #SFiltered = re.sub("<br/>", " ",s) #SFiltered = re.sub("<p/>", " ",s) SFiltered = re.sub(r\'\\<.*?\\>\'," ",s).strip() print SFiltered #<type \'str\'>
数据抓取
Version1 正则提取
import re links = \'<a href="/type.aspx?p=1&c=%e5%94%90%e4%bb%a3">唐代</a><a href="/search.aspx?value=%e6%9d%8e%e7%99%bd">李白</a>\' author = re.findall(r\'<a href="/search.aspx?value=% .*? >(.*?)</a>\',links) print author #[] text = \'<div id="contson71138" class="contson"> 山不在高,有仙则名。水不在深,有龙则灵。斯是陋室,惟吾德馨。苔痕上阶绿,草色入帘青。谈笑有鸿儒,往来无白丁。可以调素琴,阅金经。无丝竹之乱耳,无案牍之劳形。南阳诸葛庐,西蜀子云亭。孔子云:何陋之有? </div>\' song = re.findall(r\'?<=<div id="contson\\d+" class="contson"?<=>(.?*)?<=</div>\',text) #报错nothing to repeat song = re.findall(r\'<div id="contson\\d+" class="contson">(.?*)</div>\',text) #报错multiple repeat print song
注:提取失败
Version2 Xpath提取
#coding=utf-8 import requests from lxml import etree import sys import re import pymongo reload(sys) sys.setdefaultencoding(\'utf-8\') #conn = pymongo.MongoClient(host=\'localhost\',port=27017) #先启动mongoDB,再建立数据库poetry和集合poem #poetry = conn[\'poetry\'] #newdata = poetry[\'poem\'] urllist = [\'http://so.gushiwen.org/type.aspx?p={}&c=%e5%ae%8b%e4%bb%a3\'.format(i) for i in range(1,2)] #print urllist poemL = [] for url in urllist: print url html = requests.get(url).content #HtmlFiltered = html.replace(\'\\n\',\'\').replace(\'\\r\',\'\') #HtmlFiltered = re.sub(r\'\\<.*?\\>\'," ",HtmlFiltered).strip() tree = etree.HTML(html) rez = tree.xpath(\'//*[@class="sons"]\') print \'aaaeee\' for i in rez: poem1 = i.xpath(\'//*[@class="contson"]/p/text()\') poem2 = i.xpath(\'//*[@class="contson"]/text()\') title = i.xpath(\'//*[@class="cont"]/p[1]/a/b/text()\') dynasty = i.xpath(\'//*[@class="source"]/a[1]/text()\') #从1开始 author = i.xpath(\'//*[@class="source"]/a[2]/text()\') poemL.extend(poem1) poemL.extend(poem2) poemL = [i for i in poemL if i != \'\\n\'] #poemL = \'\'.join(poemL) #print poemL print u\'诗:\' count = 0 for i in poemL: count +=1 print count, i
输出:每页十首诗,然而len(poemL)=32
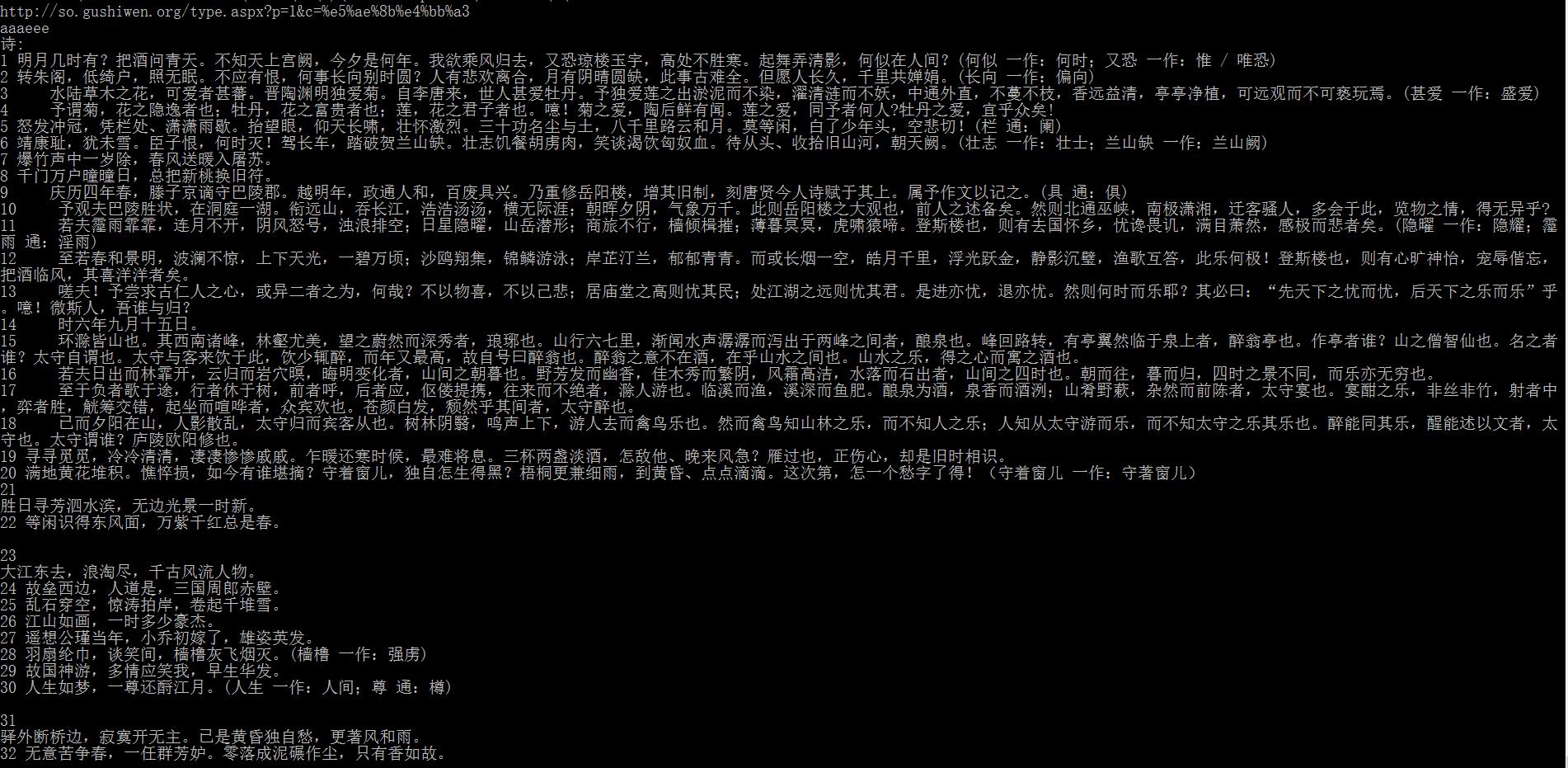
改进版:
#coding=utf-8 import requests from lxml import etree import sys import re import pymongo reload(sys) sys.setdefaultencoding(\'utf-8\') conn = pymongo.MongoClient(host=\'localhost\',port=27017) #先启动mongoDB,再建立数据库poetry和集合poem poetry = conn[\'poetry\'] newdata = poetry[\'poemSong\'] urllist = [\'http://so.gushiwen.org/type.aspx?p={}&c=%e5%94%90%e4%bb%a3\'.format(i) for i in range(1,501)] #print urllist for url in urllist: print url html = requests.get(url).content tree = etree.HTML(html) rez = tree.xpath(\'//*[@class="left"]\') for i in rez: title = i.xpath(\'//*[@class="cont"]/p[1]/a/b/text()\') dynasty = i.xpath(\'//*[@class="source"]/a[1]/text()\') author = i.xpath(\'//*[@class="source"]/a[2]/text()\') poem = [] for i in range(10): result = tree.xpath(\'//div[@class="contson"][starts-with(@id,"contson")]\')[i] info = result.xpath(\'string(.)\') content = info.replace(\'\\n\',\'\').replace(\' \',\'\') #print content #print type(content) #<type \'unicode\'> print len(content) poem.append(content) #break #打印输出 for i,j,m,n in zip (title,dynasty,author,poem): print i,\'|\',j,\'|\',m,\'|\',n print \'\\n\' break #写入文件 for i in list(range(0,len(title))): text =\',\'.join((title[i],dynasty[i],author[i],poem[i]))+\'\\n\' with open(r"C:\\Users\\HP\\Desktop\\codes\\DATA\\poemTang.csv",\'a+\') as file: file.write(text+\' \') #存入数据库 data = {\'title\':title, \'author\':author, \'dynasty\':dynasty, \'poem\':poem} newdata.insert_one(data)
print \'succeed\'
说明:通过contsonid提取元素,id获取使用startwith()
输出:

5000首唐诗,5000首宋词搬回家了,满满的成就感,哈哈哈
以上是关于8千多古诗词唐诗宋词鉴赏ACCESSEXCEL数据库的主要内容,如果未能解决你的问题,请参考以下文章