记一次JavaWeb-Servlet排错过程
Posted wang-jifeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次JavaWeb-Servlet排错过程相关的知识,希望对你有一定的参考价值。
说明
JavaWeb-Servlet开发
- 主要是404(无映射)和500(资源找不到), 两个异常;
- 404的排错过程, 分析主要是需要弄清楚JavaWeb的部署流程和配置;
- 资源找不到也是, 需要配置清楚resource资源文件夹的编译;
最后发现:
- 404的原因也是源码servlet没有被编译到out文件夹中;
- 500也是因为resources文件夹没有编译到out文件夹中;
总结
最后解决问题的步骤:
- 首先在解决问题的时候, 忽略了target文件夹和out文件夹的区别, 一开始没注意到out文件夹,两者都是编译目录, 但是web项目中好像是默认使用out文件夹下的内容;
- 用idea开了一个新的web项目, 然后对比了一下目录结构, 其次对比了Project Structure里面的配置;
- 正确配置了之后, 可以访问到服务, 但依然显示500错误, 读取不到resource文件夹下的资源目录;
- 根据网上参考资料, 在Project Structure中设置了Artifacts中 WEB-INF下的classes文件夹, 点击上方的添加, 将resources资源文件夹添加进去, 重新启动项目, 即发现资源文件已经被编译到out目录下;
- 然后还是500错误, 检查out文件夹下, 发现mybatis-config.xml的路径为根路径下, 因此修改资源路径, 即通过该处代码.
其它
关于注解@WebServlet
该注解能替代基于web.xml的servlet编程
参考资料:
@WebServlet注解(Servlet注解)
https://blog.csdn.net/qq_51795666/article/details/124778720
IDEA编译Web项目时,target文件下resource目录内容没有完全编译的解决办法:
记一次 K8S 排错实战过程
一 背景
收到测试环境集群告警,登陆K8s集群进行排查。
二 故障定位
2.1 查看pod
查看kube-system node2节点calico pod异常
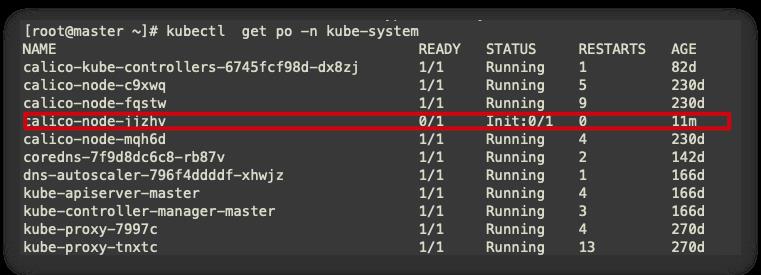
-
查看详细信息,查看node2节点没有存储空间,cgroup泄露

2.2 查看存储
-
登陆node2查看服务器存储信息,目前空间还很充足
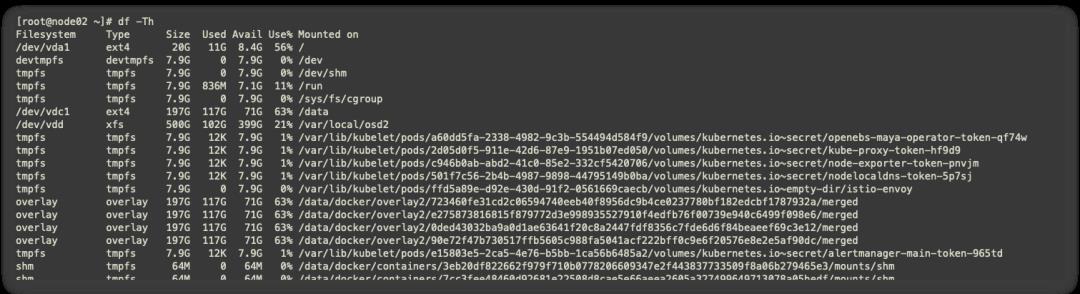
-
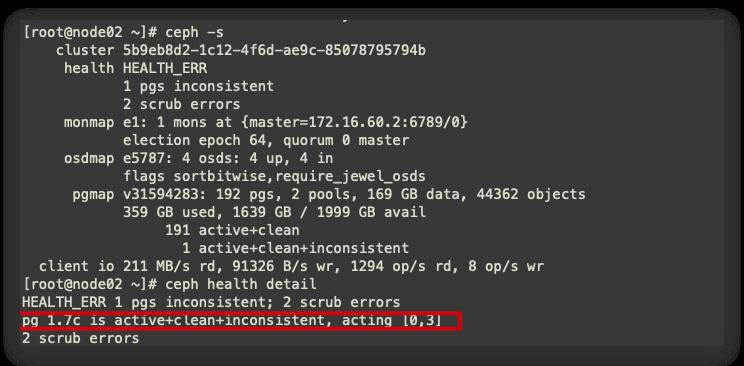
集群使用到的分布式存储为ceph,因此查看ceph集群状态
三 操作
3.1 ceph修复
目前查看到ceph集群异常,可能导致node2节点cgroup泄露异常,进行手动修复ceph集群。
数据的不一致性(inconsistent)指对象的大小不正确、恢复结束后某副本出现了对象丢失的情况。数据的不一致性会导致清理失败(scrub error)。
CEPH在存储的过程中,由于特殊原因,可能遇到对象信息大小和物理磁盘上实际大小数据不一致的情况,这也会导致清理失败。
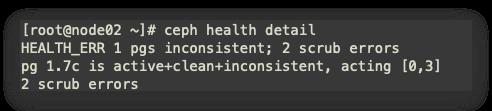
由图可知,pg编号1.7c 存在问题,进行修复。
-
pg修复
ceph pg repair 1.7c
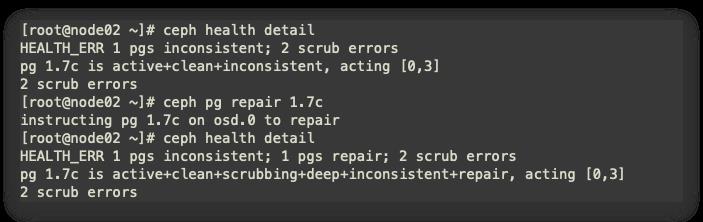
-
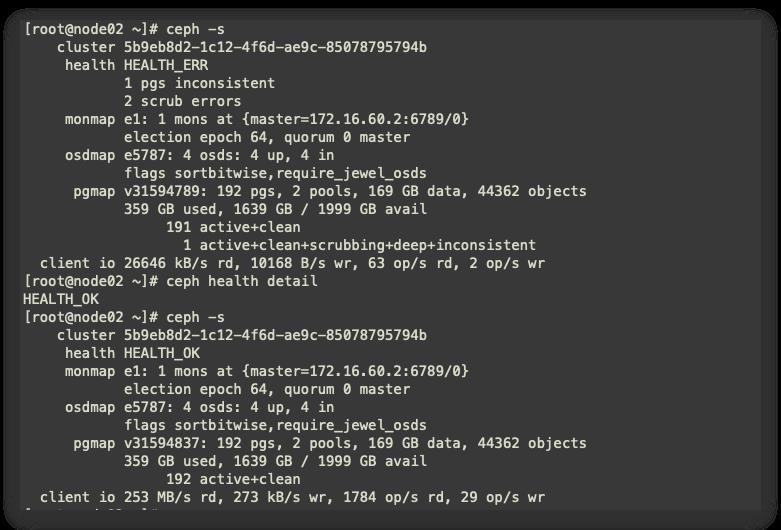
进行修复后,稍等一会,再次进行查看,ceph集群已经修复
3.2 进行pod修复
对异常pod进行删除,由于有控制器,会重新拉起最新的pod
查看pod还是和之前一样,分析可能由于ceph异常,导致node2节点cgroup泄露,网上检索重新编译
-
Google一番后发现存在的可能有:
-
Kubelet 宿主机的 Linux 内核过低 - Linux version 3.10.0-862.el7.x86_64 -
可以通过禁用kmem解决
查看系统内核却是低版本

3.3 故障再次定位
最后,因为在启动容器的时候runc的逻辑会默认打开容器的kmem accounting,导致3.10内核可能的泄漏问题
在此需要对no space left的服务器进行 reboot重启,即可解决问题,出现问题的可能为段时间内删除大量的pod所致。
初步思路,可以在今后的集群管理汇总,对服务器进行维修,通过删除节点,并对节点进行reboot处理
3.4 对node2节点进行维护
3.4.1 标记node2为不可调度
kubectl cordon node02
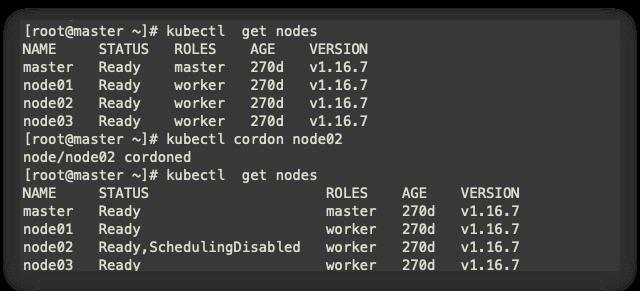
3.4.2 驱逐node2节点上的pod
kubectl drain node02 --delete-local-data --ignore-daemonsets --force
-
--delete-local-data 删除本地数据,即使emptyDir也将删除; -
--ignore-daemonsets 忽略DeamonSet,否则DeamonSet被删除后,仍会自动重建; -
--force 不加force参数只会删除该node节点上的ReplicationController, ReplicaSet, DaemonSet,StatefulSet or Job,加上后所有pod都将删除;
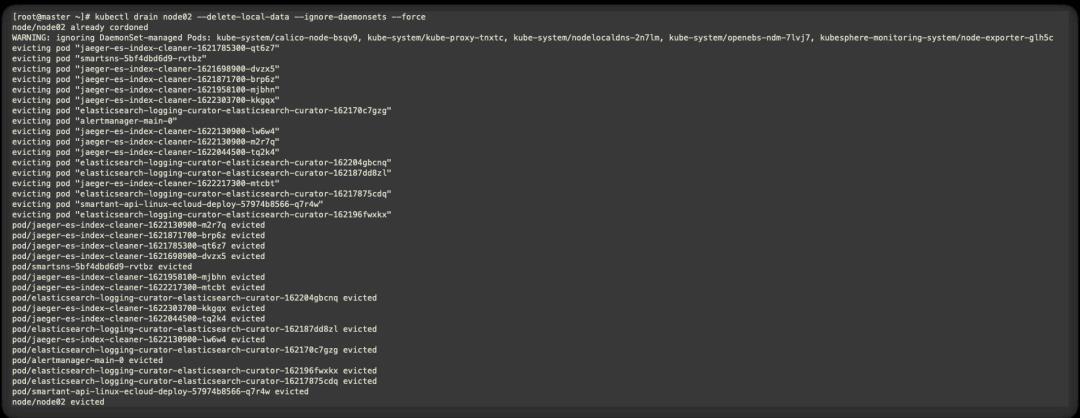
目前查看基本node2的pod均已剔除完毕
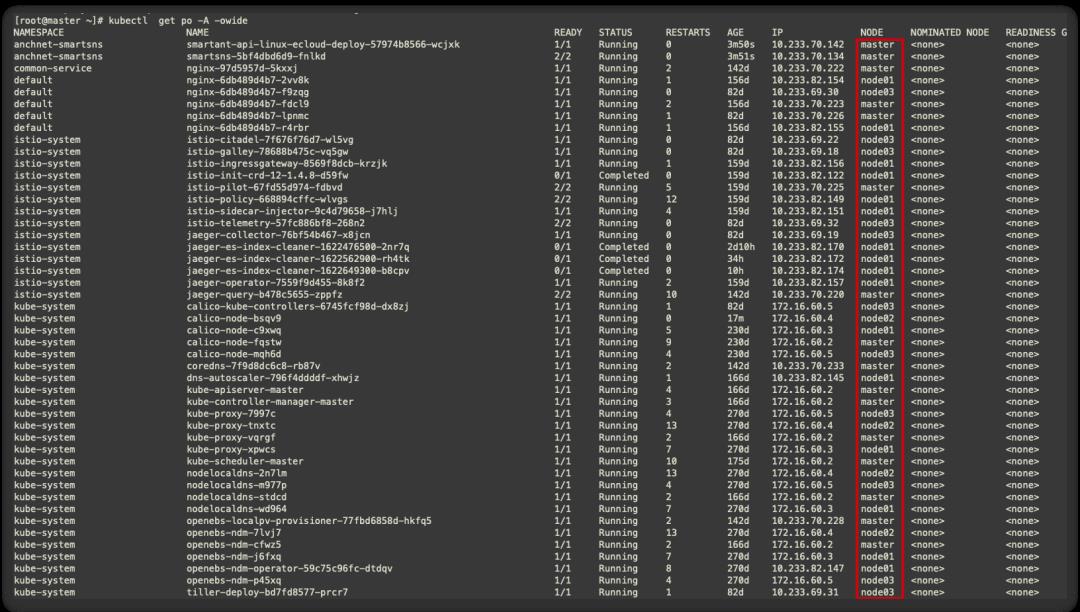
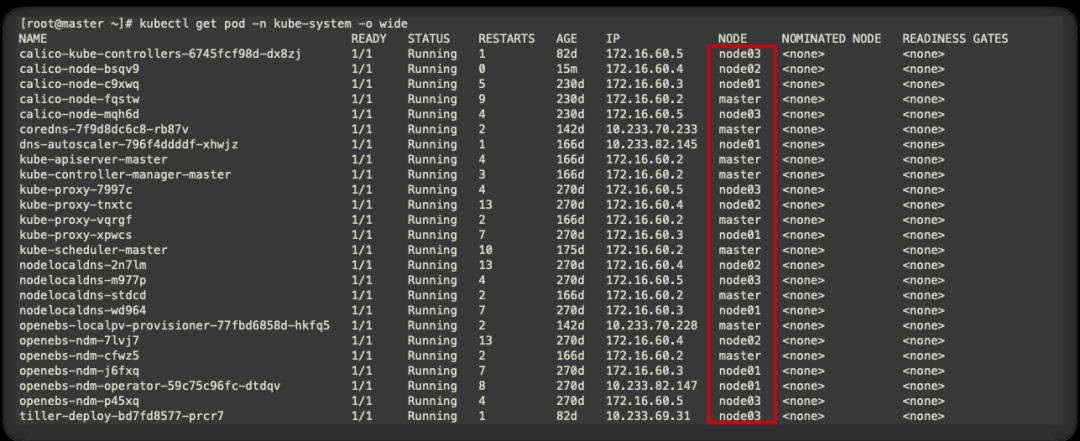
此时与默认迁移不同的是,pod会先重建再终止,此时的服务中断时间=重建时间+服务启动时间+readiness探针检测正常时间,必须等到1/1 Running服务才会正常。因此在单副本时迁移时,服务终端是不可避免的。
3.4.3 对node02进行重启
重启后node02已经修复完成。
对node02进行恢复
-
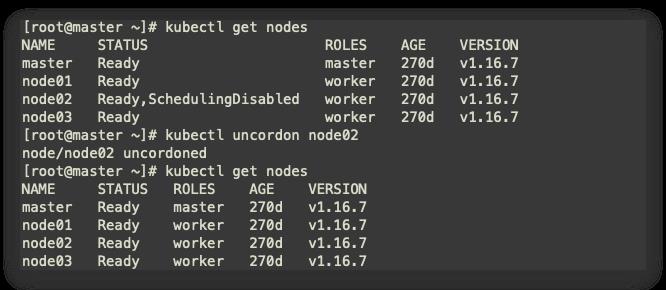
恢复node02可以正常调度
kubectl uncordon node02
四 反思
-
后期可以对部署k8s 集群内核进行升级。 -
集群内可能pod的异常,由于底层存储或者其他原因导致,需要具体定位到问题进行针对性修复。
原文链接:https://juejin.cn/post/6969571897659015205
K8S 进阶训练营
 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习

扫描二维码获取
更多云原生知识
k8s 技术圈
以上是关于记一次JavaWeb-Servlet排错过程的主要内容,如果未能解决你的问题,请参考以下文章