一次redis主从切换导致的数据丢失与陷入只读状态故障
Posted To be a better programmer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次redis主从切换导致的数据丢失与陷入只读状态故障相关的知识,希望对你有一定的参考价值。
背景
最近一组业务redis数据不断增长需要扩容内存,而扩容内存则需要重启云主机,在按计划扩容升级执行主从切换时意外发生了数据丢失与master进入只读状态的故障,这里记录分享一下。
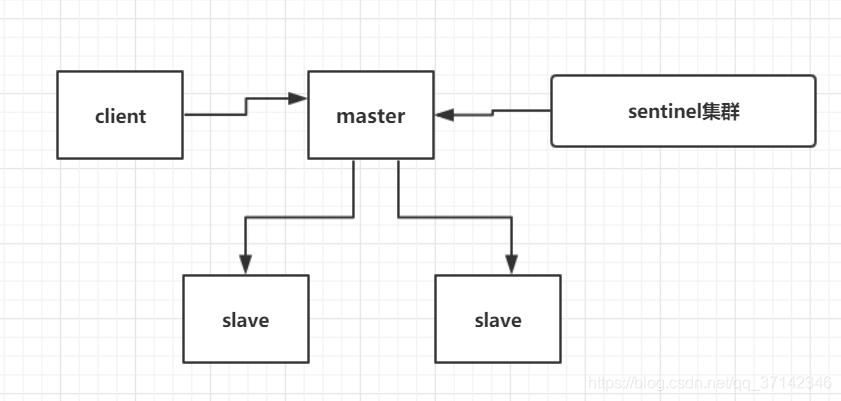
业务redis高可用架构
该组业务redis使用的是一主一从,通过sentinel集群实现故障时的自动主从切换,这套架构已经平稳运行数年,经历住了多次实战的考验。
高可用架构大体如下图所示:

简单说一下sentinel实现高可用的原理:
集群的多个(2n+1,N>1)哨兵会定期轮询redis的所有master/slave节点,如果sentinel集群中超过一半的哨兵判定redis某个节点已经主观下线,就会将其判定为客观下线进行相应处理:
- 如果下线节点是master,选定一个正常work的slave将其选定为新的master节点。
- 如果下线节点是slave,将其从slave节点中移除。
如果已经被客观下线的节点恢复了正常,sentinel中超过一半哨兵确认后则将其加回可用的slave节点。
所有需要读写redis的server并不需要直接写死redis 主从配置,而是通过访问sentinel获取当前redis的主从可用状态,具体实现方式可以定时查询sentinel询问更新,也可以通过订阅机制让sentinel在主从变动时主动通知订阅方更新。
sentinel实现高可用的详细原理这里不做过多赘述,有兴趣的小伙伴可以移步参考文献中的相关资料。
具体内存扩容流程
sentinel可以在检测到故障时自动切换redis主从,也可以主动执行sentinel failover mastername 命令实现手动切换主从,所以这次的内存扩容重启流程设计如下(A代表初始master所在云主机,B代表初始slave所在云主机):
- 升级主机B内存配置,重启主机B
- 检查B重启后其上的redis slave是否重新同步master数据完成,包括:
2.1 查看slave redis log是否异常,无异常pass
2.2 使用info keyspace命令check master、slave 各db key数量是否一致,无异常pass
2.3 在master写入一个测试key,在slave上check是否同步成功
2.4 观察依赖server log是否有异常 - 使用sentinel failover mastername命令手动主从切换,主机A变成新slave,主机B变成新master,根据以前手动切换的经验走到这一步基本上就稳了--因为这里本质上和一次普通主从切换已经没有区别了。
- 升级主机A内存配置,重启主机A,执行以下check:
4.1 查看新slave redis log是否异常
4.2 使用info keyspace命令check 新master、新slave 各db key数量是否一致,无异常pass
4.3 在新master写入测试key,在新slave上check是否同步成功
4.4 观察依赖server log是否有异常
至此,若以上步骤都正常通过,一个完美的redis内存升级工作就完成了。
主从切换后数据丢失
结果正是没有想过可能会出问题的步骤3反而出现了问题,直接导致了主从切换后丢掉了部分数据,并且新master进入只读状态将近十分钟。
当时的情况是这样的:
在执行完步骤3后,check 新slave redis log无异常,正在考虑观察一会儿后执行主机A的升级重启操作,api的分钟级别异常监控触发了一小波redis相关报警。第一反应在新master与新slave上执行了info keyspace查看key数量是否已经不一致,结果发现master/slave的key数量是一致的--但是再仔细一看:和切换前的key总数百万级相比切换后key总数降到了十万级--大部分key数据被丢失了。
查看新master、新slave log都没有发现明显log可以解释为什么主从切换后会丢失一大半数据这一现象,这时小伙伴第一次提到了是不是内存不够了,当时自己略一思考马上回复到:新master刚升级了内存,不可能内容扩大后反而内存不足的,所以应该不是这个问题。
n分钟后...
小伙伴再一次提出了是不是maxmemory问题,这一下子点中了关键点,马上想到主机B升级了内存是不会有系统层面内存不足的问题,但是redis的内存使用实际上还会受到maxmemory参数限制,马上在新master上执行config get maxmemory, 只有3GB,而升级前数据实际使用内存超过了6GB!
立刻调大了新master的maxmemory参数,redis很快恢复了可读写正常状态,一大波redis只读引发的告警通知开始快速下降。
原因定位
紧张又刺激的故障处理就这么过去了,在优先处理完丢失key数据恢复工作之后,开始回顾整理故障的详细原因,总共有如下几个疑问:
- 明确记得上个月给主机A、B上的redis都通过config set maxmemory设置为了7GB,为什么出现问题时查询B上redis 的maxmemory配置却变成了3GB?
- 如果主机B的maxmemory是3GB,其作为slave时为什么从master同步超过6GB的数据时不会有问题?--在主从切换前无论是查看info keyspace还是在master上写入测试key同步check都是OK的。
- 为什么主从切换后主机B上的key数据会丢失?这个是因为maxmemory设置过小,是故障的直接原因。
- 为什么新master由于maxmemory参数超限进入只读状态且删除部分数据后,新master中实际数据占用的大小依然超过>3GB?
如上四个疑问除了问题3已经明确了,剩下三个问题都让人疑惑--事出诡异必有妖,经过一番探寻得出其答案:
- 上个月修改redis maxmemory时,只通过config set命令修改了其运行时配置,而没有修改对应配置redis.conf上maxmemory的值,主机B上redis在重启后就会从redis.conf上载入该maxmemory,该配置正是3GB,同时maxmemory参数是redis节点独立的配置,slave并不会从master同步该值。
- 在redis5.0版本之后,redis引入了一个新的参数replica-ignore-maxmemory,其官方文档定义如下:
Maxmemory on replicas
By default, a replica will ignore maxmemory (unless it is promoted to master after a failover or manually). It means that the eviction of keys will be handled by the master, sending the DEL commands to the replica as keys evict in the master side.
This behavior ensures that masters and replicas stay consistent, which is usually what you want. However, if your replica is writable, or you want the replica to have a different memory setting, and you are sure all the writes performed to the replica are idempotent, then you may change this default (but be sure to understand what you are doing).
Note that since the replica by default does not evict, it may end up using more memory than what is set via maxmemory (since there are certain buffers that may be larger on the replica, or data structures may sometimes take more memory and so forth). Make sure you monitor your replicas, and make sure they have enough memory to never hit a real out-of-memory condition before the master hits the configured maxmemory setting.
To change this behavior, you can allow a replica to not ignore the maxmemory. The configuration directives to use is:
replica-ignore-maxmemory no
大意是redis作为slave时默认会无视maxmemory参数,这样可以保证主从的数据始终保持一致。当master/slave实际数据大小均小于其maxmemory设置时,这个参数没有任何影响,而这次丢失数据的原因正是因为主机B重启后作为slave时maxmemory(3GB)小于实际数据大小(6GB+),此时replica-ignore-maxmemory 默认开启保证作为slave时直接无视maxmemory的限制,而当执行sentinel failover mastername将主机B切换为新master后,新master不会受replica-ignore-maxmemory影响,发现自身maxmemory<实际数据大小后直接开始主动淘汰key,从而导致了数据丢失。
4. 至于主机B作为master执行淘汰key策略并最终进入只读状态后,其实际数据大小依然>3GB的原因,则是由于线上redis配置的策略是volatile-lru策略,该策略只会淘汰有过期时间的key,对于不过期的key是不淘汰的。
总结
总的来看这次故障的根本原因还是个人对于redis的配置、操作经验不足,如果在调整运行时maxmemory时能做到以下二者之一,这次故障就不会出现了:
- 调整运行时maxmemory时同时调整配置文件maxmemory保持一致。
- 将配置文件maxmemory设置为0--表示不限制内存使用。
正是因为对redis的认识和经验不足,没有想过到运行时配置与静态配置不一致可能导致的问题,这次不可避免的踩坑了。
但是,作为一个本职RD,半路接手基本靠自学的兼职运维,要考虑到maxmemory的运行配置与静态配置一致性问题好像也确实不是那么的理所当然
Redis主从集群切换数据丢失问题如何应对?
数据丢失的情况
-
异步复制同步丢失 -
集群产生脑裂数据丢失
异步复制丢失
对于Redis主节点与从节点之间的数据复制,是异步复制的,当客户端发送写请求给master节点的时候,客户端会返回OK,然后同步到各个slave节点中。
如果此时master还没来得及同步给slave节点时发生宕机,那么master内存中的数据会丢失;
要是master中开启持久化设置数据可不可以保证不丢失呢?答案是否定的。在master 发生宕机后,sentinel集群检测到master发生故障,重新选举新的master,如果旧的master在故障恢复后重启,那么此时它需要同步新master的数据,此时新的master的数据是空的(假设这段时间中没有数据写入)。那么旧master中的数据就会被刷新掉,此时数据还是会丢失。
集群产生脑裂
首先我们需要理解集群的脑裂现象,这就好比一个人有两个大脑,那么到底受谁来控制呢?在分布式集群中,分布式协作框架zookeeper很好的解决了这个问题,通过控制半数以上的机器来解决。
那么在Redis中,集群脑裂产生数据丢失的现象是怎么样的呢?
假设我们有一个redis集群,正常情况下client会向master发送请求,然后同步到salve,sentinel集群监控着集群,在集群发生故障时进行自动故障转移。
此时,由于某种原因,比如网络原因,集群出现了分区,master与slave节点之间断开了联系,sentinel监控到一段时间没有联系认为master故障,然后重新选举,将slave切换为新的master。
但是master可能并没有发生故障,只是网络产生分区,此时client仍然在旧的master上写数据,而新的master中没有数据,如果不及时发现问题进行处理可能旧的master中堆积大量数据。在发现问题之后,旧的master降为slave同步新的master数据,那么之前的数据被刷新掉,大量数据丢失。

在了解了上面的两种数据丢失场景后,我们如何保证数据可以不丢失呢?在分布式系统中,衡量一个系统的可用性,我们一般情况下会说4个9,5个9的系统达到了高可用(99.99%,99.999%,据说淘宝是5个9)。对于redis集群,我们不可能保证数据完全不丢失,只能做到使得尽量少的数据丢失。
如何保证尽量少的数据丢失?
在redis的配置文件中有两个参数我们可以设置:
min-slaves-to-write 1
min-slaves-max-lag 10min-slaves-to-write默认情况下是0,min-slaves-max-lag默认情况下是10。
以上面配置为例,这两个参数表示至少有1个salve的与master的同步复制延迟不能超过10s,一旦所有的slave复制和同步的延迟达到了10s,那么此时master就不会接受任何请求。
我们可以减小min-slaves-max-lag参数的值,这样就可以避免在发生故障时大量的数据丢失,一旦发现延迟超过了该值就不会往master中写入数据。
那么对于client,我们可以采取降级措施,将数据暂时写入本地缓存和磁盘中,在一段时间后重新写入master来保证数据不丢失;也可以将数据写入kafka消息队列,隔一段时间去消费kafka中的数据。
|
参考: |
以上是关于一次redis主从切换导致的数据丢失与陷入只读状态故障的主要内容,如果未能解决你的问题,请参考以下文章