看完这篇,DWS故障修复不再愁
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了看完这篇,DWS故障修复不再愁相关的知识,希望对你有一定的参考价值。
摘要:本文详细梳理分析了DWS服务面临软硬件故障场景和对应的修复原理,希望借此能够让你对DWS的集群故障修复有个全面深入的了解。
本文分享自华为云社区《GaussDB(DWS)故障修复系统性介绍》,作者: 闻鲜生。
DWS是一个分布式架构的MPP集群,物理部署上涉及数百数千台主机和对应的磁盘,以及这些主机所在的大规模分布式高速组网环境。在逻辑上,MPPDB包括CM、GTM、CN、DN各种实例组件的配合工作。因此DWS的故障场景较多,不过我们提供了针对各种故障场景的系统性修复方案。通过此文可以了解DWS服务面临的故障场景和对应的修复方案。
硬件故障场景
1、可修复故障:主要是指硬件故障后可以修复,并且不会造成数据损坏或者丢失,比如内存条故障更换,raid组内磁盘故障更换,主机断电重启等。这种故障场景下,等待硬件故障恢复后,上面的数据库实例会自动启动并恢复。
2、磁盘故障:包括磁盘故障和raid组故障,可能导致CN,DN数据损坏或者丢失。这种故障场景下,等待硬件故障修复后,需要对上面的CN实例做元数据修复,DN实例做数据修复,CM,GTM实例做配置修复。
3、主机故障:包括系统盘损坏,其他硬件故障导致的主机无法启动等,会导致该主机上部署的软件和数据丢失。这种故障场景下,则需要更换主机,使用新主机替换故障主机,需要在新主机上重装数据库软件,重建上面的数据库实例。
软件故障场景
DWS逻辑上包括OM,CM,GTM,CN,DN六种类型的实例组件,每类组件提供的功能不动,配置的数量也不同,但是共同配合,支撑DWS的运维和业务功能。如下是DWS服务的一种简单部署拓扑图(其中OM属于静态工具因此不再列出,为了拓扑简洁性DN从备也未列出):
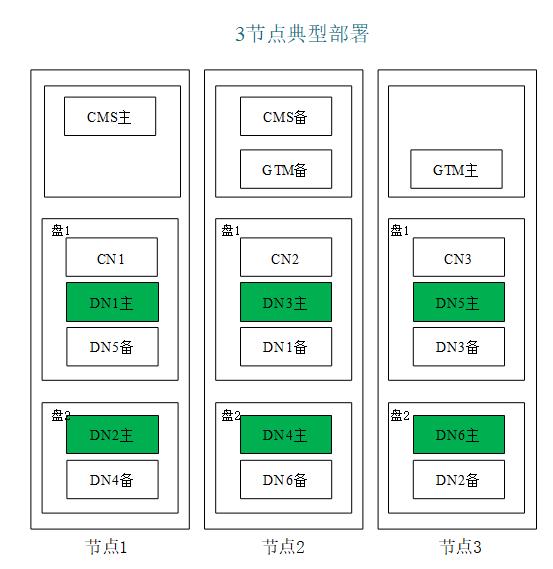
其中硬件故障最终体现到DWS数据库实例故障上,DWS集群修复也是通过修复每类故障实例来进行的,每类实例的修复条件和修复思路如下:
- 集群管理组件(CM)
- cm_server:主备模式,主备至少有一个正常的才能修复。主要修复配置,以对端为模板重建故障实例。
- cm_agent:每个节点都部署一个cm_agent,原则上只要有一个正常的cm_agent就能修复。主要修复配置,以正常的cm_agent为模板重建故障实例。
- 全局事务管理(GTM):主备模式,主备至少有一个正常的才能修复。主要修复配置和少量数据(xid,序列等),以对端为模板重建故障实例。
- 协调节点(CN):多主多活模式,每个节点可部署一个CN实例,整个DWS集群最多部署20个CN实例。只要有一个正常的CN就能修复。主要修复配置和元数据,以正常的CN为模板重建故障实例。
- 数据节点(DN):多切片模式,最多支持2048个数据切片。每个数据切片又包括主机,备机,从备三副本。每个DN切片主备从只能故障一个。主机或备机故障以对端实例为模板修复故障实例配置和数据。从备故障以主机实例为模板修复故障实例的配置。
故障修复场景
结合硬件故障场景和软件故障场景,DWS支持的故障修复主要包括:DN主备build,实例修复,节点修复(温备)
DN主备build
DN主备副本通过WAL实时同步数据,由CM来自动完成DN主备实例的状态监控、主备冲裁、主备切换及主备build。如果主DN所在机器发生故障,CM自动完成DN主备切换(备机升主,主机降备),如果故障恢复后,CM会自动做DN主备数据同步(build)来重建故障备机。该场景主要包括机器宕机重启,更换内存条等,是最常见的故障场景也是最简单的故障场景,DWS已经支持自动化处理。
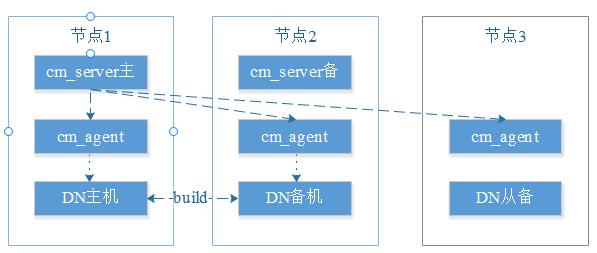
实例修复
实例修复主要指相对于“DN主备build”更复杂的故障场景,该故障场景主要是指某个机器(或多台机器)发生实例级别故障,实例范围包括CM、GTM、CN、DN等实例,故障范围主要包括实例的配置或者数据发生损坏或者丢失,但是故障机器的OS系统和DWS数据库软件还是正常的。该故障场景主要包括机器数据盘,raid组损坏,更换磁盘等。
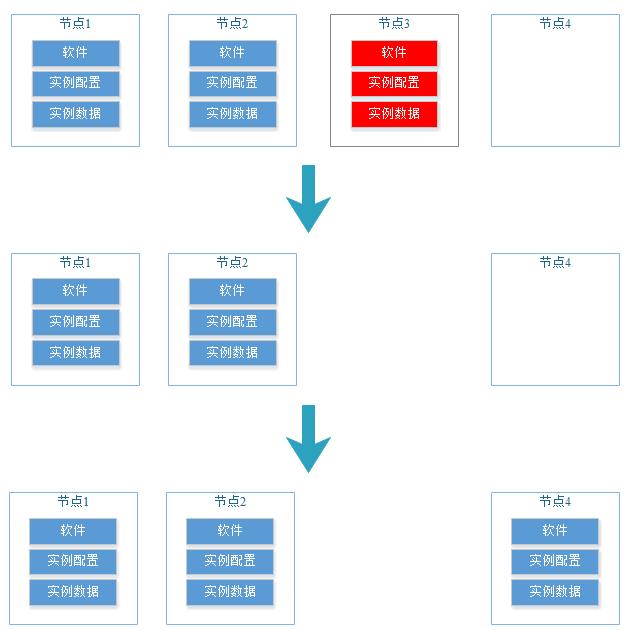
典型的故障场景和修复示意图如下:
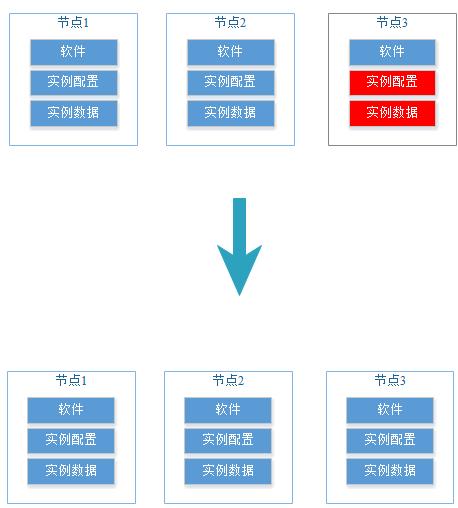
该故障场景DWS已经不能做自动化修复,但是提供了一键式修复工具gs_replace,需要运维人员分析故障场景,预估修复耗时,然后在业务空闲时间窗进行修复。
CM、GTM主要修复配置,秒级修复,对业务和系统负载影响很小;CN涉及元数据重建,耗时与表数量正相关,并且在修复后期会短暂锁集群做元数据追增,阻塞用户DDL业务;DN涉及数据重建,耗时与数据量正相关,修复过程中不影响业务,但会消耗系统的网络和IO资源。
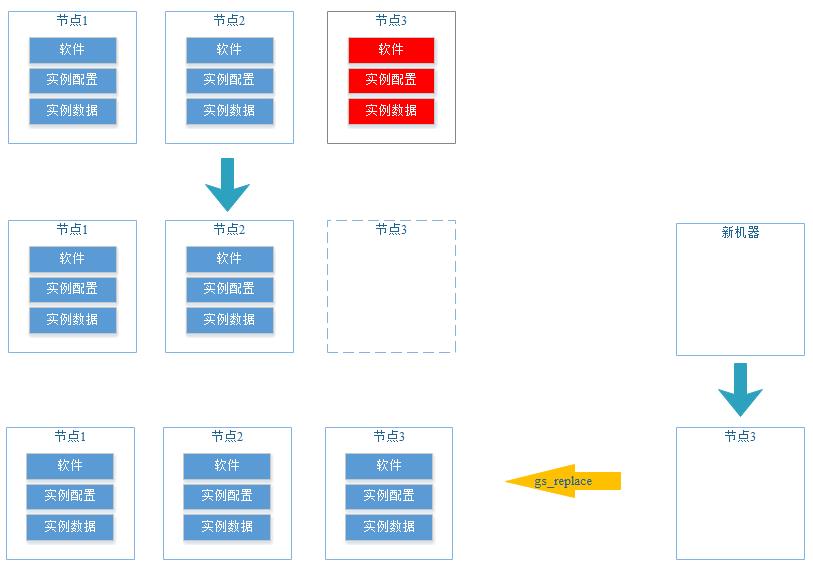
节点修复
节点修复主要处理更加复杂的故障场景,该故障场景主要是指某个机器(或多台机器)发生整机故障,如CPU、内存故障,OS系统损坏导致的机器无法启动。
该故障场景修复思路如下:
1、确认故障范围,包括故障机器,影响的数据库实例。
2、故障机器断电下网。
3、重新准备一台新机器,新机器软硬件规格要和故障机器一样。
4、把新机器的主机名和IP修改成故障机器一样,并加入到DWS集群网络内。
5、通过DWS修复工具在新机器上重建故障机器上的软件、配置和数据。
温备
温备处理的故障场景和节点修复一样,主要是修复方式不一样,温备主要适用于云上场景或者有机器富裕的用户。
主要使用场景如下:
1、针对N台主机的DWS集群,提前规划M台机器作为温备机器,温备机器软硬件规格和DWS集群机器一样。并把温备机器也加入到DWS集群网络环境内。
2、如果DWS集群内某台机器发生了硬件故障且无法修复。
3、把故障机器断电并下网。
4、从温备机器中任找一台机器,然后使用DWS修复工具在温备机器上重建故障机器上面的软件、配置和数据。
本文详细梳理分析了DWS服务面临软硬件故障场景和对应的修复原理,希望借此能够让你对DWS的集群故障修复有个全面深入的了解。具体的使用说明和操作步骤可参见DWS产品文档,从此对DWS故障修复不再愁。
看完这篇,让你不再惧怕内存优化
对于安卓应用开发来说,内存究竟会遇到什么样的问题,有什么方法可以用来测试和分析,以及有什么样的策略可以去实践优化,今天就来好好聊聊这个话题。

缘起
现代计算机是基于冯*诺依曼架构的,计算机的软件是运行在内存之中的,进程(也即运行中的程序)会耗费一定的内存,才能够正常执行。 在软件开发的中世纪,C和C++盛行的时代,是由软件开发人员(下称猿)自己管理内存,也就是说猿自己申请内存,并处理申请不到内存的情况,并在使用完成后自己负责释放内存,这无疑会加大程序开发难度,产生一些难以调试的问题,如内存越界或者内存踩踏。到了近现代,自动内存管理成为主流,研发人员不再用自己去手动管理内存了,尽管用,可劲儿造,由GC(也即是Garbage Collector内存回收器)来善后。
这极大的解放了研发人员的双手,可以让他们把更多的精力放在接收产品经理的需求上面了,三天一小需求,一周一大需求,产品迭代速度相当快,业务发展迅速,老板相当高兴啊,这干掉BAT指日可待,赶英超美就在明天,IPO触手可及。然而,现实是极其骨感的。
内存问题会引发什么问题
对于安卓 应用程序来说,内存优化很重要,因为Java VM本身就是比较耗资源的,当应用复杂到一定程度的时候,就会出现由内存使用不当造成的问题。如,测试同学反馈说应用越用越卡,经常crash,用户也反馈说应用越来越不好用了。老板把老猿叫进办公室一顿骂,然后老板让老猿尽快来解决一下问题。
老程序猿只得把需求放一边,花时间看一看这些问题,然后说凭我多年经验来看,这怕是内存出了问题。
前面提过,现代编程语言一般都有GC,帮助研发人员管理内存。但由于各种原因,还是会出现内存相关的问题。
特别是对于安卓猿来说,实现应用的编程语言是Java(准确说是JVM,Java和Kotlin 以及像Scala都是基于JVM的编程语言),天生支持GC,导致很多人对内存管理知之甚少。当应用程序复杂到一定程度,当源码庞大到一定的量级时,性能问题,特别是内存性能问题便随之而来。
具体可能是内存出现问题的场景有:
-
OOM导致的crash。OOM,也即OutOfMemoryError,可能发生在任何地方,当Heap中可用内存不足时,便可能会遇到此类crash
-
应用程序越用越慢,出现黑屏或者白屏。
-
UI操作出现卡顿,不流畅。造成UI卡,不流畅的原因很多,当排除了其他原因时,就是内存问题了
-
应用程序莫名闪退
内存问题的具体类型及其原因
要想做好内存优化,则必须先弄懂内存问题的根本原因,然后再对内存问题进行归类,最后是通过技术手段来解决。
内存问题的根本原因
安卓应用程序是由Java构建的,而Java是支持GC的编程语言,所以安卓猿是不需要自己手动的去做内存管理的,只管不停的创建对象即可,Java虚拟机(JVM)会帮助我们管理内存,当有不用的对象时会自动被GC。
但是Java应用程序(当然也包括安卓)还是会遇到内存问题,主要是两类,一类是内存不合理使用,如内存使用过多,频繁创建大量对象,内存碎片等等;二是内存泄露。很多人会把二者混为一谈,网络上绝大多数文章一谈性能优化,一谈内存优化,必然说到内存泄露,但其实并不严谨。内存泄露确实是最常见的内存优化内容,也确实是内存使用不合理的最常见问题,但内存问题并不局限于内存泄露。
内存使用不合理
主要分为三个方面:
-
浪费内存,简单来理解就是用一个人住着一千平米的大平层
-
大量创建小对象,产生碎片,内存碎片会造成JVM中的内存管理效率变低,当后面申请大块内存的时候效率就变差,它需要把小对象(碎片)进行转移压缩,以腾出更大的空间给大的对象使用。简单理解,这个时候JVM的效率就会变差,你的应用程序性能变差,甚至可能引起卡顿。
-
频繁创建对象,特别是较大的对象,造成内存抖动,也即应用程序使用的内存忽多忽少,会频繁的触发GC,从而影响JVM的运行效率。
内存泄露
JVM是支持自动GC的,也就是说JVM帮助你管理内存,当有不再使用的对象时,会被JVM自动回收,此称之为GC(Garbage Collection)。但如果对象长期处于『使用』状态,并且超出了它本应该存的周期,无法被及时GC,这就会造成泄露。一般来说,这也没啥影响,但是如果泄露的对象太多,或者泄露的时间够长,就会把系统配额Java Heap空间耗尽,应用程序便会因没有内存创建对象而OOM,就会crash。即使没有crash,因为剩余空间较少,会频繁触发GC,从而导致应用程序卡顿严重。
内存泄露的根本原因是 对象的生命周期错乱 ,对象存活了超过了其本该的生命周期,或者简言之,一个本该是较短的生命周期的对象被一个更长生命周期的对象所引用着,就会导致它本该生命周期结束时无法被GC,便产生了泄露。
这是要重点关注对象的生命周期,只有管理好了对象的生命周期,才能彻底的解决内存泄露问题。
安卓应用中的生命周期
短生命周期的对象
安卓应用程序里面,有一些是短生命周期的,或者说有明显生命周期,且不是由研发人猿自己控制的,如框架层控制的那一坨东西。
-
Activity
-
Fragment
-
View
特别是Activity,它也是内存泄露的头号对象,90%的内存泄露都是Activity对象。这货完全由系统框架控制,并且有明显的生命周期,而且还有重建实例的情况(涉及状态恢复时),所以它的生命周期其实相当短暂,并且它跟进程和主线程没有任何关系,Activity退出 了(走了onDestroy)进程仍还在,主线程也仍还在。而,又因为它是应用程序的第1级入口,应用程序所有的对象,以及GUI所有的东西,全部都由Activity直接或者间接持有,换句话说,Activity泄露了,你整个应用程序的对象也基本上全泄露了。
长生命周期对象
这里所谓的长生命周期,是指它们的生命周期是与进程绑定的,除非进程退出,或者明显的执行一些退出,否则一直随进程而存在:
-
Looper,或者说消息队列,这玩意儿除非主动quit,否则一直存在。主线程的Looper与进程同在,自己创建的Looper要手动退出才算终结。
-
被static修饰的成员变量,这东西的生命周期是跟进程一样的
-
单例,单例必须由static来修饰,所以与进程生命周期是一样的,进程在,则单例在
-
线程池,或者一个长时间运行的thread,除非主动去shutdown
-
RxJava的Schedulers,这玩意跟looper一样,都是长时间运行的消息队列,且与进程绑定的
-
系统框架,手机还在开机系统框架就在运行,所以它的生命周期远远长于某一个应用程序
-
Application和ApplicationContext,这东西与进程生命周期是一样的,相当于单例了
业务逻辑中的生命周期
业务逻辑就纯属于应用程序的本身逻辑了,无法一概而论,但一般来说,主页面的生命周期肯定是长于某个子页面的。那么子页面在其退出后,理论上它的绝大多数对象应该要被回收。
如何发现内存问题
生活中不是缺少美,而是缺少发现。
对于内存优化,第一步就是要通过各种测试手段发现问题。最理想的情况是建立一种监控手段,这样最能保住革命果实,以及非常及时的发现问题。
这里指的是一般性的粗略手段来发现你的应用有内存问题了,可能需要优化了。并且这些测试方法最好能做成定期监控,这样一旦内存性能有回撤时,能尽快发现。
『队长,我们暴露了』
很多时候都是问题主动找上门来了。
前方有雷区
很不幸,你的应用程序中弹身亡(crash了),还是OOM。这是Java语言中的一个运行时的错误,可能在创建任何对象时发生,但一般来说创建比较大的对象时,这里的大是指对内存需求大,如图片,或者大块数组时,更容易发生。
当你的应用程序出现了OOM的时候,就是一个特别明显的信号,告诉你要重视内存优化了。
遇到终结者了,是lowmemorykiller
有时候,没有明显的错误,但是应用却闪退了,特别是在后台,或者跳到其他应用页面时。
这个会比较隐蔽,通常会引发其他表象的问题。最明显的问题就是,当跳转到其他页面,再返回时,发现原来的页面状态不存在了,比如你的应用要访问一个URL,跳转到了网页浏览器,但从浏览器返回时,要么你的应用不在了,要么你的应用的原先状态不在了。这其中的原因就是当你的应用不在前台了,就被系统回收了,其中一个占大头的原因就是占用内存太多,被系统的lmk(lowmemorykiller)干掉了。
因为系统要保证整个设备的正常运转,所以会把占用内存太多的先杀掉,以释放内存。
当你的应用频繁的遇到被lowmemory killer干掉时,也是一个明显的信号,要重视内存优化了。
读懂系统GC日志
有些时候不像前面那样严重,但是查看logcat日志时,能发现大量的GC日志,就像这样的
259857:01-08 20:00:17.836 10083 26337 26347 I test.test: NativeAlloc concurrent copying GC freed 141174(6852KB) AllocSpace objects, 29(12MB) LOS objects, 49% free, 24MB/48MB, paused 180us total 308.126ms 279178:01-08 20:00:19.618 10083 26337 26347 I test.test: Background young concurrent copying GC freed 469755(20MB) AllocSpace objects, 40(3608KB) LOS objects, 41% free, 28MB/48MB, paused 396us total 124.817ms
这是系统在进行GC,通常来说这没有什么问题。但如果在短时间内,比如某个页面,点了某个按扭后大量出现此类日志,也是一个明显的信号,告诉你要重视内存优化了。
主动出击,以攻为守
作为一个优秀的猿,不能坐着等问题上来,要能主动的去创造问题。每当完成一个需求后,或者写了一大坨代码以后,就需要主动的去查看一下内存方面是否有需要优化的地方。我们可以通过如下测试方法,来看内存是否有问题,是否需要做优化。重点就是看应用程序在一定时间内,使用的内存是否一直在增长, 有没有抖动,并且在GC后,或者退出 后是否仍不回落。
meminfo
具命令是adb shell dumpsys meminfo ,这个命令还是比较常见的,网上有很多资料可以用,可以看后面罗列的参考文章中来详细了解它的具体用法以及各个字段的意义,这里就重复了。
需要关注一下重点,就是,可以重点看Java Heap一栏的数据变化,这是Java层的占用内存情况。另外就是每次运行meminfo其实会对进程产生影响。所以,这个命令可以用来粗维度的监控,查看一些信息,做一些定性的分析。
它最大的优点是方便,且只要是进程都可以查看,不用有源码。
Android Studio的Memory Profiler
在远古时代安卓SDK中会有DDMS,里面是一套调试工具,但现在都集成到Android Studio的Profiler里面了,通常会在下方的工具栏里面,如果 没有就到菜单View->Tools Window->Profiler把它调出来。然后选择要调试的进程,默认它会把CPU,Network,Memory和功耗都显示,这里可以双击Memory那一坨,就会进入专门的内存页面。
它会以时间轴的方式来图形化的展示内存使用情况,非常的直观和方便。通过这个可以直观的看到两个问题,就是嫌疑内存泄露以及内存抖动。
嫌疑内存泄露就是看到曲线一直在增长,且通过显示GC,或者退出后,或者停止某项目操作后,仍不回落的,这就非常有可能有泄露的存在,泄露是超出了它本该的生命周期,比如某一操作结束了,退出 了某一页面,甚至退出应用了,内存仍没有回落,就可能有问题。
另外就是内存抖动,就是能看到内存曲线 有毛刺,短时间内忽上忽下的,这就是内存抖动。
这货也是非常流行的,专门用于检测内存泄露的工具,它的功能较为强大,除了可以监控以外,还可以给出详细的trace。具体使用可以参考官方的文档,并不难。
但它最大的问题在于,必须参与项目构建。假如你想研究一下竞品的情况,就没有办法了。
如何调试内存问题
通过前面提到的手段,我们可以发现内存有一些问题了,需要进行内存方面的优化了,但这还不够,还需要一些精细化的调试方法来具体定位问题,这样才能更好的去进行优化。
那么有哪些具体的调试方法呢?
Allocation tracer
这个是前面提到的Android Studio Profier里面的工具。用Profiler可以发现问题,但还需要进一步的深入的分析问题。这就需要Allocation tracer了。
具体做法就是,当你发现某一系列操作后内存一直增长,或者看到有抖动现象时,就可以抓取这段时间的Heap dump,然后详细分析,现在Android Studio都集成好了,只需要点几下,就能抓到,并把结果列出来,可以看到具体创建哪些对象,以及它们的引用关系是怎样的。
可以参考 以下资源来详细了解如何使用此工具:
这是专门用于Java heap内存分析的工具,相当强大。但不能直接使用。
需要先想办法抓取进程的heap dump,然后转换为Java标准的格式(因为安卓的Heap与Java SE的并不一样,安卓 SDK中有转换工具),然后再用MAT打开即可,它的功能要远强大于前面的提到的Allocation tracer。所以,如果要深度的分析和优化,还是要用MAT。
关于MAT的具体使用方法,可以参考以下资源:
leakcanary
除了能监控以外,它还能分析具体的内存泄露,并给出trace,所以当发现问题后,具体定位问题的时候,也可以使用此工具,还是相当强大的。
它的使用相当简单,直接把它加入到dependencies,然后构建 就好了。
至于它的分析结果也是相当直观的,会以Notification的方式通知你,点开后有一个页面展示出引用关系链,然后判断是否是泄露,即可。
详细可以参阅它的 官方文档 就可以了。
如何优化内存
内存优化,一大半在于测试,监控和调试分析,约占70%,这部分是重头,因为只有找到具体的代码位置,才好去修复问题,并且修复后还要验证问题是否真的修复了。不能光在那里看代码,想当然的认为把几个内部类改为static,或者传递引用了ApplicationContext,就能优化了内存。
对于性能优化,当然也包括内存优化,必须用测试手段进行量化,以此来验证是否真有有改善。
本节内容,假设已通过前面提到的测试方法发现了内存问题,并通过调试手段定位到了具体位置。优化的手段也要针对 具体的问题来进行:
避免内存泄露
内存优化的大头是要避免泄露,所以重点来谈谈如何避免内存泄露。
前面提到了,内存泄露的根本原因是生命周期混乱,较长生命周期的对象,甚至是超长生命周期的对象,持有了较短生命周期的对象,这一定会导致泄露。所以,要想真的解决内存泄露问题,必须设计好对象的生命周期,这是根本解决之法。
要尽可能的,缩小对象的生命周期
对象的生周期不应该超出它本该存在的范围,并且应该尽可能的减少对象的生命周期,这个可能在设计阶段考虑到。但一般较难执行,代码复杂了,很难控得住。
对于超过Activity生命周期的对象要及时清理
前面提到过的超长生命周期的东西,如Looper,如Frameworks,如单例,如RxJava的Schedulers,如线程池,这些东西的生命周期远长于Activity,所以,一定要在对应的地方,及时清除对Activity的引用持有。
后面的参考 资料里面也有大量的实用建议可以参考,这里就不重复了。避免内存泄露应该要被总结成为编程规范,然后在团队内部推行,当然也可以设计一些源码静态检测工具,来强制执行。当然,再好的工具和规范也需要人来遵守,任何事情能够在编码阶段防止发生,成本是最小的,收益 是最大的。
WeakReference和SoftReference不是救命稻草
千万不要用WeakReference和SoftReference这东西来修复内存泄露问题,它们根本就不是用来修复内存泄露问题的。
再说一遍,内存泄露是由生命周期混乱造成的。
如果强行使用WeakReference来代替原来的强引用,就会造成想使用对象的时候它却被回收了,这时你的正常逻辑就没法走了,而且如何正确的处理这种异常case,也是很难恰当 的处理的。
WeakReference这东西最最合理,最为适合的场景就是缓存里面,也就是说它本身是用于一种可有可无的引用关系,这样一旦被GC了,也不会影响原有逻辑,因为对象本来就可能在,也可能不在缓存里面,使用者必须处理在或者不在两种case。因为缓存的清理可能不够及时(必须由编码人员手动设置条件去清理,比如在退出的时候),当JVM需要GC时,因为都是WeakReference,GC就可以快速的回收对象释放内存。
不要到处给对象引用置为null
很多有过C++经验的同学,可能会习惯在对象使用完成后,手动把对象置为null。但其实这是完全没有必要的,只会造成不必要的混乱,JVM会自己去追踪每个对象,它到底还有没有被引用持有着。我们要把精力重点放在对象生命周期的把控上面,简单的置为null,不会缩减对象的生命周期,所以它对解决和防止泄露方面没有任何帮助。
内存使用优化方式
除了避免内存泄露,其他一些方式也是有很多技术可以用于优化的。
减少内存浪费
内存浪费,就是使用了没必要的内存,虽然可能不会引发问题,但是还是会增加风险,比如同样都是后台进程,你的应用占用内存稍大了一些,被杀的风险就高了一些。
减少内存浪费,核心的方法就是按需申请,特别像图片这种内存占用大户,一定要按需要来加载,何为需要就是目标View的大小,具体可以看官方教程 Loading Large Bitmaps Efficiently 。以及尽可能的 要复用bitmap 。
再如资源图片,设置合理的分辨率,没有必要啥都上高清,且要为低精度设备提供单独的一套资源。
以及像不是要求那么清晰的场景就用RGB_565,而非RGBA_8888等等,这些都是在编码的时候就可以提高内存使用的方法。
使用缓存
缓存是计算机史上最伟大的发明,甚至是人类史上最伟大的发明,它无处不在从硬件到软件都会使用缓存,并且它在各种东西的设计之中都是很重要的一部分。
前面提到的内存抖动问题,就需要用缓存来解决,以避免频繁创建对象。特别是涉及图片的场景,比如流行的图片加载开源库里面都有专门的缓存的机制,有些是二级,有些是三级。当需要设计缓存时,可以重点参考图片加载库中的缓存设计。
另外,SDK中也有标准的缓存组件可以用, LruCache ,这是针对内存层面的缓存,可以看 这篇文章 来详细了解使用方法。
合理复用对象
这里的意思是使用像 享元这样的设计模式 ,来合理的复用对象。
需要注意的是享元(Flyweight Pattern)的适用场景,它适用于创建对象的成本较高,比如创建对象需要的一些资源较昂贵,不同的对象仅是有不同的属性,或者说对象本身在使用的时候的表现是不同的。
一个典型的例子就是绘图的形状,比如一个页面有大量的不同的形状需要绘制,有方的,有圆的,有白色的,有彩色的,有实边的有虚线的。常规的思路是一个基类叫Shape,里面有各种属性,还有一个draw方法,子类可以定义不同的属性,各自实现draw方法。然后根据需求创建一大坨具体的对象,遍历调用draw方法。这是面向对象编程(OOP)中的非常标准的多态(Polymophsim)。事实上,你只需要创建一个对象就够了,它会根据不同的属性画出不同的效果。这就是设计模式中的享元模式,具体可以参考 这篇文章 来详细了解。
认识几种不同的内存类型
通过各种工具查看的内存时,如通过meminfo以及像Memory profiler,但可以发现有不同种类,需要重点关注以几种:
Java Heap
也即通常意义上的heap内存(堆内存),名字可能会是Java,Java Heap,或者Java allocate,但都是一样就是指纯Java代码中通过new创建对象时使用的内存。
Native Heap
因为Java是支持JNI与C/C++接通,也即native方法,那么通过native方法创建的对象是计算在Native之中的,它与Java层是分开的,当然通过native方法(malloc或者new)创建的对象,要记得去释放,否则是一定会泄露的。
因为Android的大部分是由C/C++实现的,Java层仅是封装,Frameworks层大部分功能都由JNI转到native层去实现的,因此native这部分的内存也是很多的,并且由于Frameworks本身会大量调用JNI native层,所以即使你的应用程序根本没有用到JNI,但是还是会看到Native内存使用。
Graphics
主要是涉及OpenGL ES的相关内存占用,如GL Surfaces,如Texture或者如Framebuffer等,它们所占用的内存。
这里需要特别注意的是,即使你的应用没有用到OpenGL相关的东西,但仍可能会有此部分内存占用,这是由于硬件加速本身也是通过OpenGL ES实现的。
ion内存
这个是为了效率,直接从kernel层开出shared buffer,以加速内存使用效率,这个是偏底层的,普通app是用不到的。
可以参考一下这个 The Android ION memory allocator 。
共享内存
可以理解为Linux中的匿名共享内存,可以用来实现IPC通信,但它并不会被Profiler计算在Java或者Native里面。非死不可出品的Fresco当初牛逼的地方就在于把Bitmap放在匿名共享内存里面,从而不占用应用自己的Heap空间。
可以参考这两个文章:
学无止境
深入学习GC相关知识,如JVM的GC如何演进。
也可以学习一下其他编程语言的GC机制。
不要过早优化,更不能过度优化
性能优化这个事情是要在架构设计和产品设计阶段就需要考虑的事情,比如是否要加入缓存。
但如果前期想太多,会造成严重的扭曲,会让你陷入无限的复杂问题里面,难以自拔(本是问题1,但是变成了问题A,问题B,直到问题z,最初的问题1却被忽略了),反倒不是好事情。
最为想理的情况就是小步迭代,先提出能满足需求的最小版本,然后逐步迭代。比如说做一个新的feature的时候,先用最简单的架构和设计来实现,然后考虑补充细节,处理异常case,再考虑可能的扩展,然后考虑性能优化。
剩下的是态度
不是说一线开发的态度,而是老板们的态度。
性能问题是直接影响体验,所以只有重视体验的老板才会重视性能问题。而且这也不是研发猿的问题,需要测试,产品都要能重视性能问题,才能最终把性能做好。产品同学不能只顾着提需求,也要平衡性能,并且给研发同学一定的时间去注重性能问题,而测试同学更加重要,需要不断精进你的测试方法,帮助研发同学更好的解决问题,并且要有监控手段,比如说A版本做了性能优化专项,那么为了保留革命果实,需要有一种监控手段,以防性能出现重大回撤。
很多事情不能怪研发,就像有一位技术相当不错的同事说过的话,当时大家聊起性能优化的事情,他说:『道理大家都懂,但当左边是产品经理在那里崔需求,右边是设计师在那说按扭还差几个象素,测试同学在那崔你赶紧发版本啊,我还等着测完回家呢!当你处在这种条件下,谁TMD的还管性能啊,先实现了再说吧,甚至代码格式都懒得改了。』
所以,这是整个工程体系的事情,只有整个研发体系都注重性能,性能才会好,体验才会好,而这就需要一个老板的支持了,否则,性能不可能好,产品汪们只顾着提需求,设计师只顾着画面精美,研发同学光实现需求都做不完,哪有精力去搞性能啊!测试同学也不能只用粗浅的测试方法,只说性能不好,具体哪不好,不应该都让研发自己去调试,去发现问题。另外,也需要做好性能监控机制,以保住革命果实。要不然,A版本辛辛苦苦搞了一轮性能优化,也有大幅改善,然后到了B版本,或者几个月后,再来一轮。
这就是很骨感的现实。所以,在现实生活中只有大厂头部应用 才真的重视性能和体验,并且才能把性能和体验做好。
希望能对你有所帮助!
需要领取免费资料的小伙伴们,添加小助手vx:SOSOXWV 即可免费领取资料哦!
以上是关于看完这篇,DWS故障修复不再愁的主要内容,如果未能解决你的问题,请参考以下文章