python的守护线程(简介作用及代码实例)
Posted burlingame
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python的守护线程(简介作用及代码实例)相关的知识,希望对你有一定的参考价值。
转载:(14条消息) python的守护线程(简介、作用及代码实例)_python守护线程的作用_HXH.py的博客-CSDN博客
python守护线程简介
守护线程的理解:
如果当前python线程是守护线程,那么意味着这个线程是“不重要”的,“不重要”意味着如果他的主进程结束了但该守护线程没有运行完,守护进程就会被强制结束。如果线程是非守护线程,那么父进程只有等到守护线程运行完毕后才能结束。
在python中,线程通过threadName.setDaemon(True|False)来设置是否为守护线程。
守护线程的作用:
守护线程作用是为其他线程提供便利服务,守护线程最典型的应用就是 GC (垃圾收集器)。
守护线程的特点:
只要当前 主线程中尚存任何一个非守护线程没有结束,守护线程就全部工作;
只有当最后一个非守护线程结束是,守护线程随着主线程一同结束工作。
代码实例:
情况一:线程为非守护线程
import time import threading def fun(): print("start fun") time.sleep(2) print("end fun") def main(): print("main thread") t1 = threading.Thread(target=fun,args=(),daemon=False) #t1.setDaemon(False) t1.start() time.sleep(1) print("main thread end") if __name__ == \'__main__\': main()
运行结果:
main thread
start fun
main thread end
end fun
说明:程序在等待子线程结束,才退出了。
情况二:线程为守护线程
import time import threading def fun(): print("start fun") time.sleep(2) print("end fun") def main(): print("main thread") t1 = threading.Thread(target=fun,args=()) t1.setDaemon(True) t1.start() time.sleep(1) print("main thread end") if __name__ == \'__main__\': main()
结果:
main thread
start fun
main thread end
说明:程序在主线程结束后,直接退出了。 导致子线程没有运行完。
python-- 继承式多线程守护线程
继承式多线程
1、定义
继承式多线程是自己自定义类,去继承theading.Tread这个类,通过类实例.start()启动,去执行run方法中的代码。
import threading
import time
class MyThread(threading.Thread): # 继承threading.Thread
"""继承式多线程"""
def __init__(self, n):
threading.Thread.__init__(self) # 也可以写成这样super(MyThread,self).__init__()
self.n = n
def run(self): # 重写run方法
"""这个方法不能叫别的名字,只能叫run方法"""
print("run", self.n)
time.sleep(2)
t1 = MyThread("t1") # 实例化
t2 = MyThread("t2")
t1.start() # 启动一个多线程
t2.start()
2、通过for循环来启动线程
上面的例子只启动了一个2个线程,还是用那种古老的方式t1,t2。要是一下子起10个或者100个线程,这种方式就不适用了,其实可以在启动线程的时候,把它加到循环里面去,并且来计算一下它的时间:
这里设置成启动5个线程,并且计算一下时间。这里有个疑问,为什么不启动1000个线程或者更多一点的线程?这是因为:计算机是4核的,它能干的事情,就是4个任务。启动的线程越多,就代表着要在这个很多线程之间进行上下文切换。相当于教室里有一本书,某个人只看了半页,因为cpu要确保每个人都能执行,也就是这本是要确保教室每个同学都能看到,那就相当于每个人看书的时间非常少。也就是说某个同学刚刚把这本书拿过来,一下子又被第二个人,第三个人拿走了。所以就导致所有的人都慢了,所以说如果线程启动1000,启动10000就没有意义了,导致机器越来越慢,所以要适当设置
import threading,time
def run(n): #这边的run方法的名字是自行定义的,跟继承式多线程不一样,那个是强制的
print("task:",n)
time.sleep(2)
print("task done",n)
start_time = time.time() #开始时间
for i in range(5): #一次性启动5个线程
t = threading.Thread(target=run,args=("t-{0}".format(i),))
t.start()
print("--------all thead has finished")
print("cost:",time.time()-start_time) #计算总耗时
#执行结果
task: t-0
task: t-1
task: t-2
task: t-3
task: t-4
--------all thead has finished
cost: 0.00096893310546875
task done t-1
task done t-2
task done t-0
task done t-4
task done t-3
从上面的程序发现,就是我主线程没有等其他的子线程执行完毕,就直接往下执行了,这是为什么呢?而且这个计算的时间根本不是我们想要的时间,中间的sleep 2秒哪里去了?
其实一个程序至少有一个线程,那先往下走的,没有等的就是主线程,主线程启动了子线程之后,子线程就是独立的,跟主线程就没有关系了。主线程和它启动的子线程是并行关系,这就解释了为什么我的主线程启动子线程之后,没有等子线程,而继续往下走了。所以计算不出来线程总共耗时时间,因为程序已经不是串行的了。程序本身就是一个线程,就是主线程。如果要想测试这五个线程总共花了多长时间,就需要用到线程的内置韩式join()
3、join设置等待线程执行结果
3.1、通过设置在主线程里去等待子线程的执行结果,这里join()相当于wait的意思
import threading
import time
class MyThead(threading.Thread):
"继承式多线程"
def __init__(self,n):
super(MyThead,self).__init__()
self.n = n
def run(self):
"这个方法不能叫别的名字,只能叫run方法"
print("runinit task",self.n)
time.sleep(2)
t1 = MyThead("t1")
t2 = MyThead("t2")
t1.start()
t1.join() #等待t1线程的执行结果,相当于于其他语言里面的 t1.wait()
t2.start()
注:
- t1.join() 等待第一个线程的执行结果,这个结果在没有返回之前,程序是不往下走的。所以这个程序变成串行的了。
- t2.start() 这个后面没有写 join() 这个方法,但是程序在退出之前,它肯定要确保线程都执行完毕,所以它就默认就有一个join()。
3.2、实现并发效果
上面虽然有想要的结果,却失去了并行的效果。如果想要的是线程依然是并行效果,就需要更换join()的位置了
流程图:
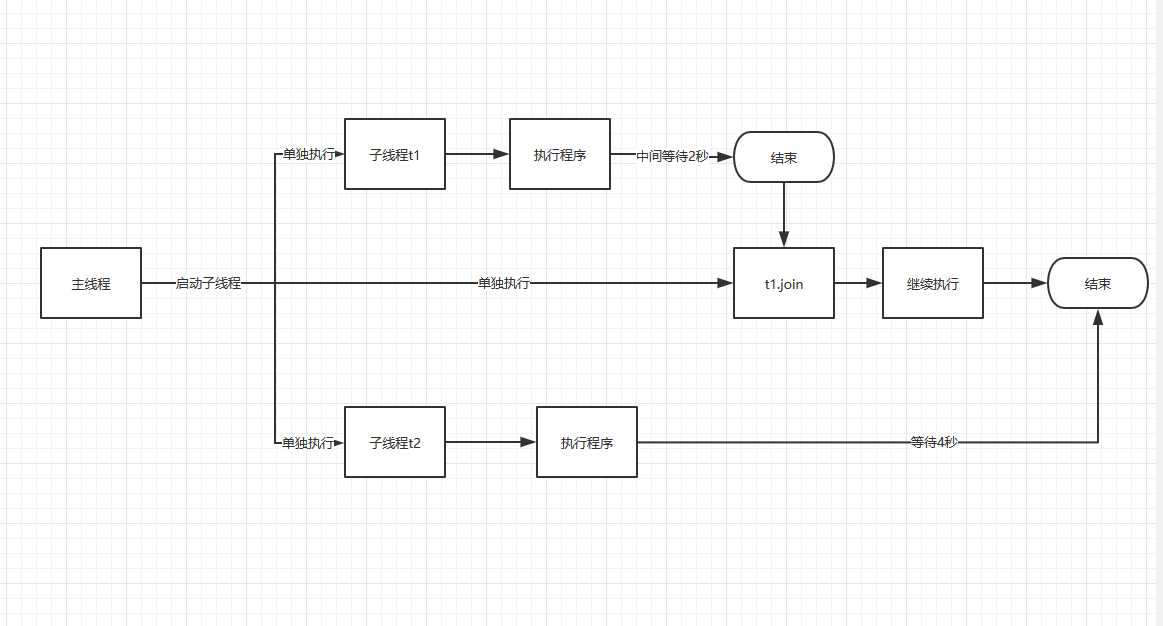
代码:
import threading
import time
class MyThread(threading.Thread): # 继承threading.Thread
"""继承式多线程"""
def __init__(self, n, sleep_time): # 增加时间属性
threading.Thread.__init__(self) # 也可以写成这样super(MyThread,self).__init__()
self.n = n
self.sleep_time = sleep_time
def run(self): # 重写run方法
print("run task", self.n)
time.sleep(self.sleep_time) # 每个线程可以传入不不同的时间
print("task done,", self.n)
t1 = MyThread("t1", 2) # 实例化
t2 = MyThread("t2", 4)
t1.start() # 启动一个多线程
t2.start()
t1.join() # 把t1.join()放在线程启动之后
print("main thread.....")
#执行结果
run task t1
run task t2
task done, t1
main thread.....
task done, t2
注:t1.join() 这边只等t1的结果,然后主线程继续往下走,因为t2需要等4秒,所以,最后打出来的是t2的执行结果。t1的结果到了,就立刻算结果。这边只计算了t1的结果,没有t2的结果
3.3 、计算多个线程的执行时间
重新改进一下第二点 “通过for循环来启动线程” 里面的代码,来计算一下10个线程启动执行的时间
import threading
import time
def run(n): # 这边的run方法的名字是自行定义的,跟继承式多线程不一样,那个是强制的
print("task:", n)
time.sleep(2)
print("task done", n)
start_time = time.time() # 开始时间
t_obj = [] # 存放子线程实例
for i in range(10): # 一次性启动10个线程
t = threading.Thread(target=run, args=("t-{0}".format(i),))
t.start()
t_obj.append(t) # 为了不阻塞后面线程的启动,不在这里join,先放到一个列表中
for t in t_obj: # 循环线程实例列表,等待所有线程执行完毕
t.join()
print("--------all thread has finished")
print("cost:", time.time() - start_time) # 计算总耗时
# 执行结果
task: t-0
task: t-1
task: t-2
task: t-3
task: t-4
task: t-5
task: t-6
task: t-7
task: t-8
task: t-9
task done t-2
task done t-1
task done t-0
task done t-3
task done t-4
task done t-5
task done t-6
task done t-9
task done t-8
task done t-7
--------all thread has finished
cost: 2.0067291259765625
这样主线程没有等其他的子线程执行完毕,才继续往下执行,就能测试出10个线程执行的总共耗时。
守护线程
上面的例子在不加join的时候,主线程和子线程完全是并行的,没有了依赖关系,主线程执行了,子线程也执行了。但是加了join之后,主线程依赖子线程执行完毕才往下走。
守护进程:
只要主线程执行完毕,它不管子线程有没有执行完毕。就退出了。现在就可以把所有的子线程变成守护线程。变成守护线程之后,主程序就不会等子线程结束载退出了。说白了,设置一个主人,在设置几个仆人,这几个仆人都是为主人服务的。可以帮主人做很多事情,一个主人(主线程)可以有多个仆人(守护线程),服务的前提是,主线程必须存在,如果主线程不存在,则守护进程也没了。那守护进程是干嘛的呢?可以管理一些资源,打开一些文件,监听一些端口,监听一些资源,把一些垃圾资源回收,可以干很多事情,可以随便定义。
1、守护线程设置
用setDaemon(True)来设置守护线程
import threading
import time
def run(n):
print("task:", n)
time.sleep(2)
print("task done", n)
start_time = time.time()
for i in range(5):
t = threading.Thread(target=run,args=("t-{0}".format(i),))
t.setDaemon(True) # Daemon意思是守护进程,这边是把当前线程设置为守护线程
t.start()
print("--------all thread has finished")
print("cost:", time.time() - start_time)
#执行结果
task: t-0
task: t-1
task: t-2
task: t-3
task: t-4
--------all thread has finished
cost: 0.0010023117065429688
注:守护进程一定要在start之前设置,start之后就不能设置了,之后设置会报错,所以必须在start之前设置
2、使用场景
比如写一个socket_server,每一个链接过来,socket_server就会给这个链接分配一个新的线程。如果我手动的把socket_server停掉。那这种情况你必须手动停掉服务,那它就要down了,这种情况下还要等线程结束吗?就不用等线程结束了,它自己就直接结束了。这样,是不是就可以把每个socket线程设置一个守护线程,主线程一旦down掉,就全部退出。
3、知识点补充
查看当前线程和统计活动线程个数,用theading.current_thead()查看当前线程;用theading.active_count()来统计当前活动的线程数,线程个数=子线程数+主线程数
import threading,time
def run(n):
print("task:",n)
time.sleep(2)
print("task done",n,threading.current_thread()) #查看每个子线程
start_time = time.time()
for i in range(5):
t = threading.Thread(target=run,args=("t-{0}".format(i),))
t.start()
print("--------all thead has finished",threading.current_thread(),threading.active_count())#查看主线程和当前活动的所有线程数
print("cost:",time.time()-start_time)
#执行结果
task: t-0
task: t-1
task: t-2
task: t-3
task: t-4
--------all thead has finished <_MainThread(MainThread, started 3840)> 6
cost: 0.0019359588623046875
task done t-0 <Thread(Thread-1, started 11536)>
task done t-3 <Thread(Thread-4, started 10480)>
task done t-2 <Thread(Thread-3, started 11008)>
task done t-4 <Thread(Thread-5, started 5088)>
task done t-1 <Thread(Thread-2, started 2464)>
以上是关于python的守护线程(简介作用及代码实例)的主要内容,如果未能解决你的问题,请参考以下文章