分布式架构及Dubbo
Posted JaxYoun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式架构及Dubbo相关的知识,希望对你有一定的参考价值。
Dubbo的前世今生
一、分布式系统的架构演进过程
Dubbo框架的出现是分布式系统演进的结果,我们先来回顾一下分布式系统的演进过程
1 单应用架构

2 应用服务器和数据库服务器分离
单机负载越来越来,所以要将应用服务器和数据库服务器分离 
3 应用服务器做集群
每个系统的处理能力是有限的,为了提高并发访问量,需要对应用服务器做集群
分布式和集群的概念经常被搞混,现在一句话让你明白两者的区别。
分布式:一个业务拆分成多个子业务,部署在不同的服务器上 集群:同一个业务,部署在多个服务器上
例如:电商系统可以拆分成商品,订单,用户等子系统。这就是分布式,而为了应对并发,同时部署好几个用户系统,这就是集群
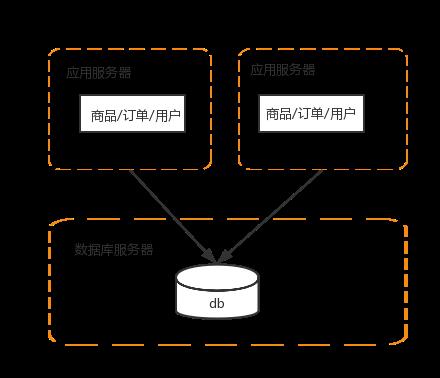
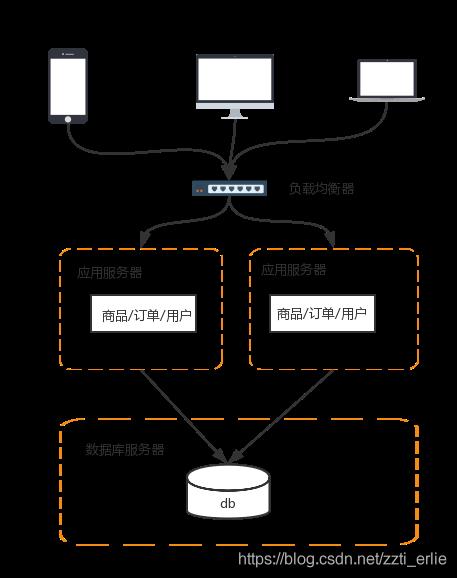
这时会涉及到两个问题:
- 负载均衡
- session共享
负载均衡就是将请求均衡地分配到多个系统上,常见的技术有如下几种
DNS
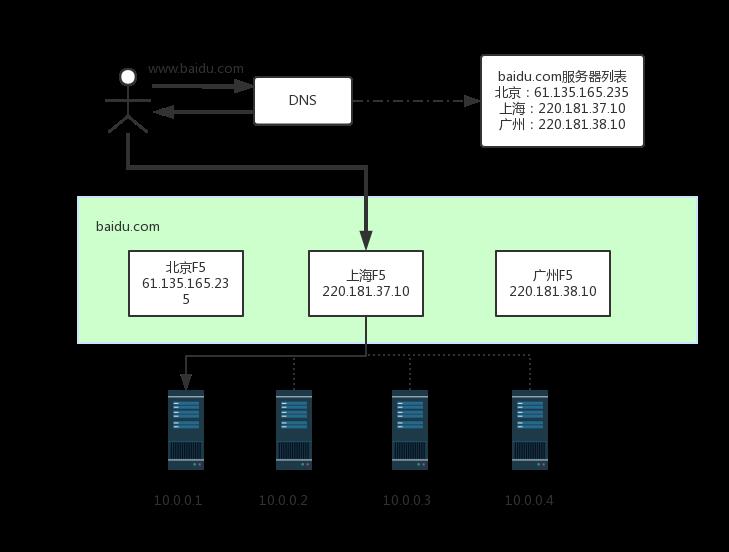
DNS是最简单也是最常见的负载均衡方式,一般用来实现地理级别的均衡。例如,北方的用于访问北京的机房,南方的用户访问广州的机房。一般不会使用DNS来做机器级别的负载均衡,因为太耗费IP资源了。例如,百度搜索可能要10000台以上的机器,不可能将这么多机器全部配置公网IP,然后用DNS来做负载均衡。
Nginx、LVS、F5
DNS是用于实现地理级别的负载均衡,而Nginx、LVS、F5用于同一地点内机器级别的负载均衡。其中Nginx是软件的7层负载均衡,LVS是内核的4层负载均衡,F5是硬件做4层负载均衡,性能从低到高位Nginx<LVS<F5
下图形象的展示了一个实际请求过程中,地理级别的负载均衡和机器级别的负载均衡是如何分工和结合的,其中粗线是地理几倍的负载均衡,细线是机器级别的负载均衡,实线代表最终的路由路径
 session共享就是用户在A服务器登录,结果查看购物车时,请求发送到了B服务器,因此用户的session存在A服务器上,所以当请求发送到B服务器上时,会认为用户没有登录
session共享就是用户在A服务器登录,结果查看购物车时,请求发送到了B服务器,因此用户的session存在A服务器上,所以当请求发送到B服务器上时,会认为用户没有登录
目前解决session跨域共享问题有如下几种方式
- session sticky 将请求都落到同一个服务器上,如Nginx的url hash
- session replication session复制,每台服务器都保存一份相同的session
- session 集中存储 存储在db、 存储在缓存服务器 (redis)
- cookie (主流) 将信息存在加密后的cookie中
4 数据库高性能操作
搭建数据库主从集群,实现数据库读写分离,改善数据库负载压力 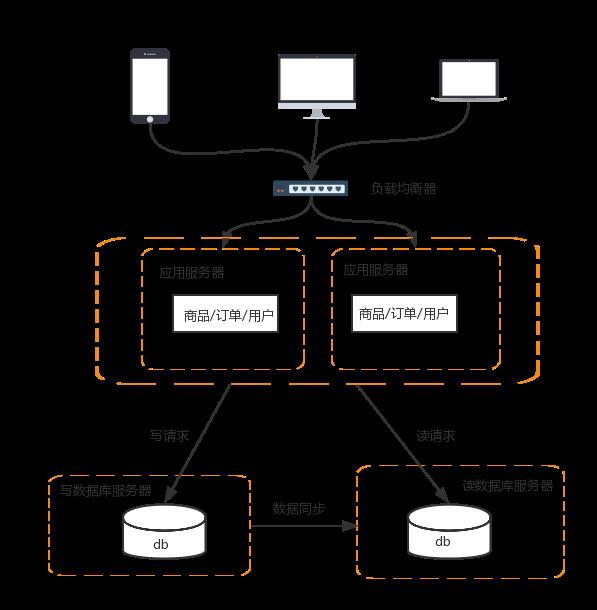
数据库读写分离的基本实现如下:
- 数据库服务器搭建主从集群,一主已从,一主多从都可以
- 数据库主机负责读写操作,从机只负责读操作
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据
- 业务服务器将写操作分给数据库主机,将读操作分给数据库从机
实现方式
读写分离需要将读/写操作区分开来,然后访问不同的数据库服务器;分库分表需要根据不同的数据访问不同的数据库服务器,两者本质上都是一种分配机制,即将不同的SQL语句发送到不同的数据库服务器。
读写分离,包括后面要提到的分库分表的实现方式有两种:
- 程序代码封装
- 中间件封装
程序代码封装指在代码中抽象一个数据访问层来实现读写分离,分库分表

中间件封装指的是独立一套系统出来,实现读写分离和分库分表操作,如我们熟悉的MySQL Router和Mycat等

5 引入搜索引擎来查询
传统的关系型数据库通过索引来达到快速查询的目的,但是在全文搜索的业务场景下,索引也无能为力,主要体现在如下几点:
- 全文搜索的条件可以随意排列组合,如果通过索引来满足,则索引的数量会非常多
- 全文搜索的模糊匹配方式,索引无法满足,只能用like查询,而like查询是整表扫描,效率非常低
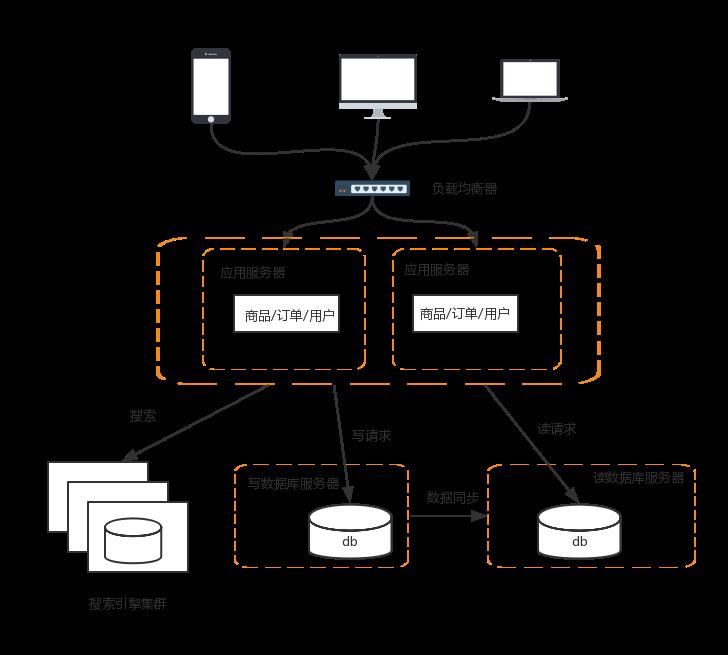
6 增加缓存
为了应对流量持续增加,必须增加缓存 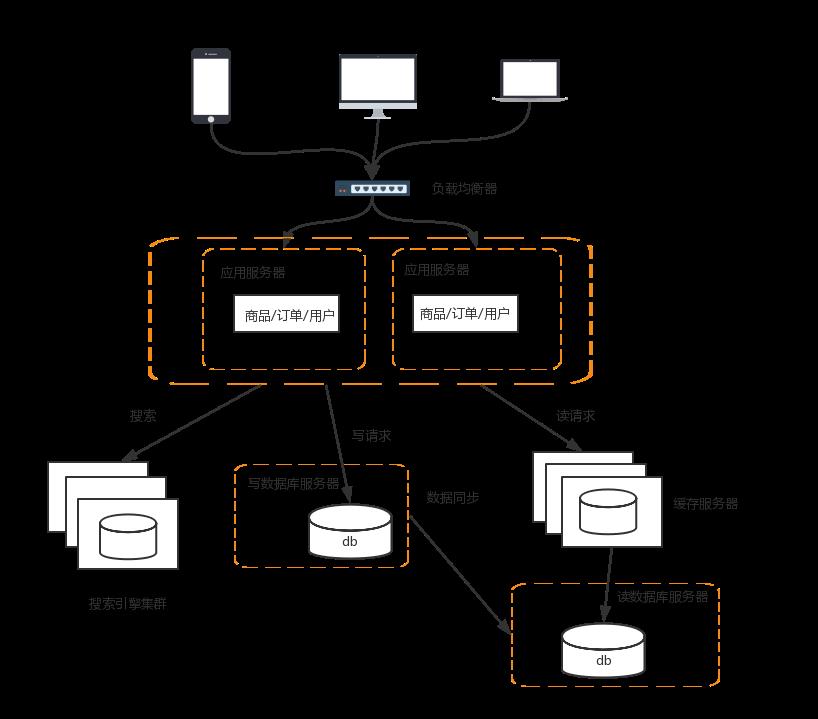
常见的方式有如下几种:
Redis与Memcached
以我们常见的Mybatis为例,很容易和Redis与Memcached整合起来,缓存已经查询过的SQL,因为Mybatis知道自己不擅长缓存,所以提供了接口让这些缓存工具进行整合
CDN
CDN是为了解决用户网络访问时的“最后一公里”效应,本质上是一种“以空间换空间”的加速策略,即建内容缓存在离用户最近的地方,用户访问的是缓存的内容,而不是站点实时的内容。
7 分库分表
读写分离分散了数据库读写操作的压力,但没有分散存储压力,当数据量达到千万甚至上亿条的时候,单台服务器的存储能力会成为系统的瓶颈。常见的分散存储的方法有分库和分表两大类 
业务分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。例如,一个简单的电商网站,包括商品,订单,用户三个业务模块,我们可以将商品数据,订单数据,用户数据,分开放到3台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上
当然业务分库也会带来新的问题:
- join操作问题:业务分库后,原本在同一个数据库中的表分散到不同数据库中,导致无法使用SQL的join查询
- 事务问题:原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同数据库中,无法通过事务统一修改
- 成本问题:业务分库同时也带来了成本的代价,本来1台服务器搞定的事情,现在要3台,如果考虑备份,那就是2台变成6台
分表
表单数据拆分有两种方式,垂直分表和水平分表 
垂直分表:垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。如上图的nickname和description字段不常用,就可以将这个字段独立到另外一张表中,这样在查询name时,就能带来一定的性能提升
水平分表:水平分表适合表行数特别大的表,如果单表行数超过5000万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能
水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算,常见的路由算法有
范围路由:选取有序的数据列(例如,整型,时间戳等)作为路由条件,不同分段分散到不同的数据库表中。以最常见的用户ID为例,路由算法可以按照1000000的范围大小进行分段,1-999999放到数据库1的表中,1000000-1999999放到数据库2的表中,以此类推
Hash路由:选取某个列(或者某几个列组合也可以)的值进行Hash运算,然后根据Hash结果分散到不同的数据库表中。同样以用户Id为例,假如我们一开始就规划了10个数据库表,路由算法可以简单地用user_id%10的值来表示数据所属的数据库表编号,ID为985的用户放到编号为5的子表中,ID为10086的用户放到编号为6的子表中。
配置路由:配置路由就是路由表,用一张独立的表来记录路由信息,同样以用户ID为例,我们新增一张user_router表,这个表包含user_id和table_id两列,根据user_id就可以查询对应的table_id
8 应用拆分/微服务
随着业务的发展,业务越来越多,应用的压力越来越大。工程规模也越来越庞大。这个时候就可以考虑将应用拆分,按照领域模型将我们的商品,订单,用户分拆成子系统。 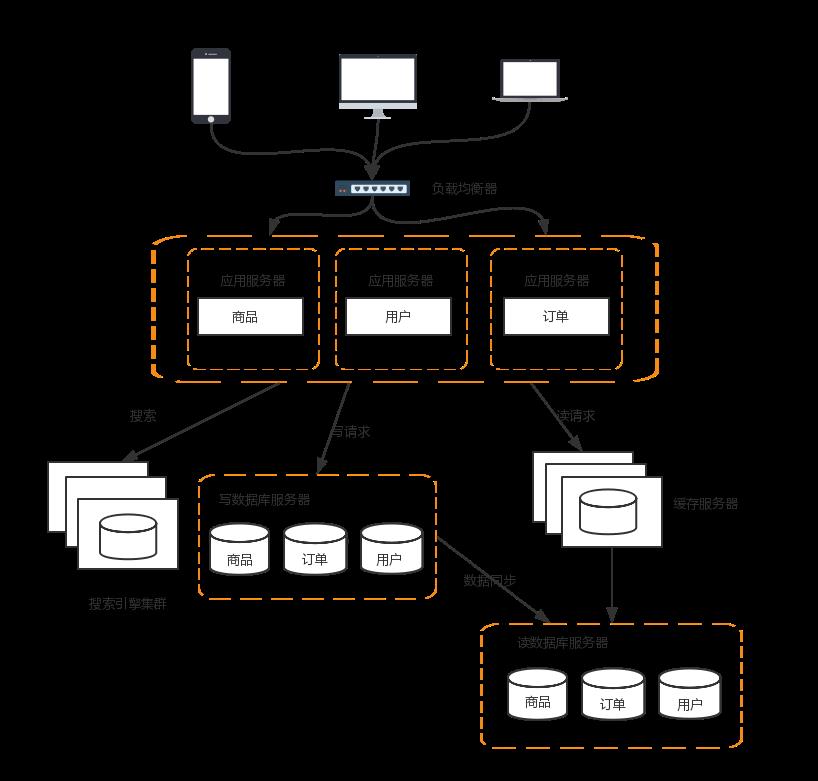
这样拆分以后,可能会有一些相同的代码,比如订单模块有对用户数据的查询,用户模块中肯定也有对用户数据的查询。这些相同的代码和模块一定要抽象出来。这样有利于维护和管理。这时可以将模块变为一个个服务,模块之间互相调用来获取数据,系统就变成一个微服务了。

服务拆分以后,服务之间的通信可以通过RPC技术,比较典型的有:Webservice、Hessian、HTTP、RMI等。
当前的Dubbo和Spring Cloud都是目前比较流行的微服务框架,这些微服务框架使得远程调和本地调用服务一样方便
两者的区别如下
| 区别 | Dubbo | Spring Cloud |
|---|---|---|
| 注册中心 | Zookeeper等 | Eureka等 |
| 支持的协议 | Dubbo,Http,Hessian等 | Http |
| 断路器 | 无 | Spring Cloud Netflix Hystrix |
| 服务网关 | 无 | Spring Cloud Netflix Zuul |
| 分布式配置 | 无 | Spring Cloud Config |
| 服务跟踪 | 无 | Spring Cloud Sleuth |
可以看到Dubbo因为出现的时间较早,偏向RPC和服务治理,而Spring Cloud则是一个完整的微服务生态,提供了一站式的解决方案。
另外Dubbo一般通过自定义的协议来进行调用,比使用Http方式的Spring Cloud性能高。但是自定义协议使得跨语言进行服务调用比较麻烦
下面我们就正式开始学习Dubbo了。
二、Dubbo工作流程
Dubbo架构的流程图如下,有5个比较重要的角色 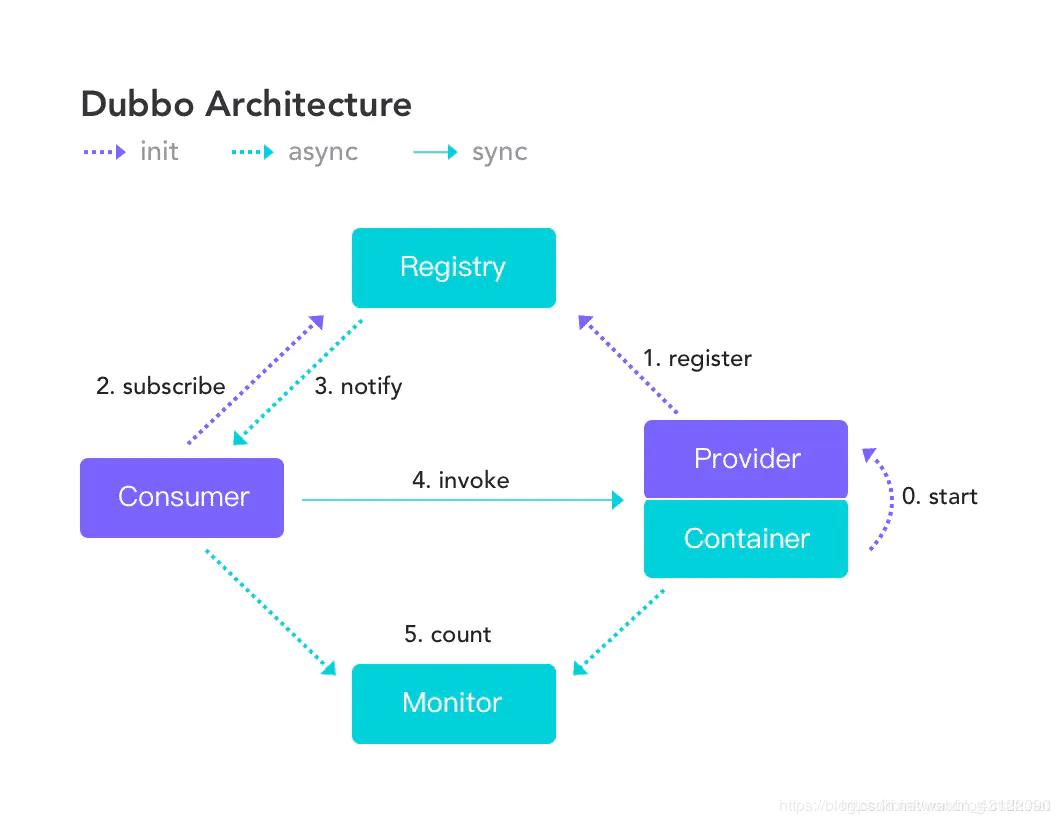
- Provider:暴露服务的服务提供方
- Consumer:调用远程服务消费方
- Registry:服务注册与发现注册中心
- Monitor:监控中心和访问调用统计
- Container:服务运行容器
Dubbo服务注册和发现的流程如下
- 服务容器Container负责启动,加载,运行服务提供者。
- 服务提供者Provider在启动时,向注册中心注册自己提供的服务。
- 服务消费者Consumer在启动时,向注册中心订阅自己所需的服务。
- 注册中心Registry返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者Consumer,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者Consumer和提供者Provider,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心Monitor。
一般RPC的框架整体架构如下所示 
- Server将服务信息注册到Registry,Client从Registry拉取Server的信息。
- Client通过代理对象(Client Stub)发送发送网络请求,Server通过代理对象(Server Stub)执行本地方法
- 网络传输过程中有编解码和序列化的过程
可以看到客户端发送网络请求和服务端收到网络请求执行本地方法都是通过代理对象来实现的。正是由于这2个代理对象的存在才使得我们调用远程方法和本地方法一样方便。这个代理对象在RPC框架中有一个专属名词Stub(桩)
至于更细节的问题,我们在《如何手写一个RPC框架?》仔细分析一波
架构分层
接着我们来分析一下Dubbo架构的分层。在日常开发中我们只会用到Service层和Config层,这是用户API层,其他的层都是基Dubbo SPI(后面的文章会聊这个Dubbo SPI的作用)来实现的,可以替换现成的组件,可扩展性强
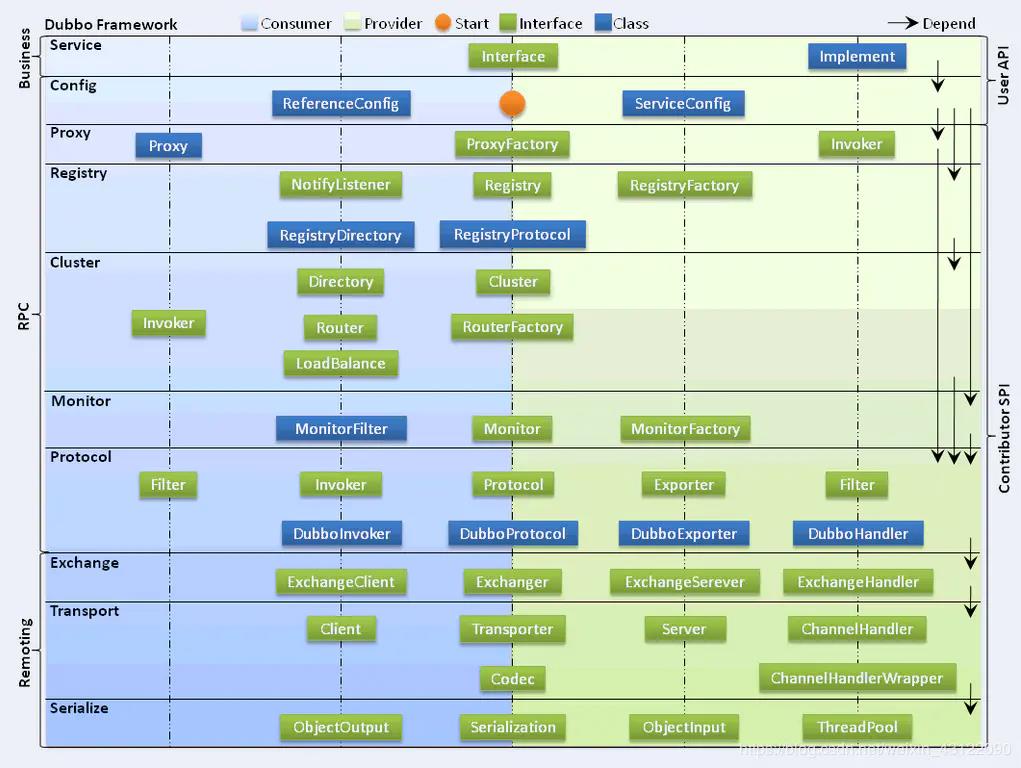
每个分层的作用如下,了解了每个层的作用,对于我们后面分析源码有很大的用处
| 层次名 | 作用 |
|---|---|
| Service | 业务层,业务代码的接口与实现 |
| Config | 配置层,主要的配置类为ServiceConfig(服务导出配置)和ReferenceConfig (服务引入配置) |
| Proxy | 代理层,即生成Client Stub和Server Stub的过程 |
| Registry | 注册中心层,通过注册中心动态的维护服务提供者列表,自动感知服务的上下线,而不用人工维护 |
| Cluster | 集群容错层,通过什么方式来调用服务提供者,如失败重试,快速失败等 |
| Monitor | 监控层,统计服务的调用信息 |
| Protocol | 协议层,dubbo中的协议主要分为两种,一种是服务注册用哪种注册中心的协议,例如zookeeper,redis。一种是服务导出的网络的协议,如dubbo,hessian,http协议 |
| Exchange | 信息交换层 ,建立Request-Reponse模型,封装请求和响应 |
| Transport | 网络传输层,发送请求和返回响应用哪种通信框架,如netty或者mina |
| Serialize | 序列化层,对数据进行网络传输都涉及到序列化和反序列化的过程 |
好了,下节我们就用Dubbo实现了一个小功能!
Dubbo——Dubbo及注册中心原理
1.Dubbo意义
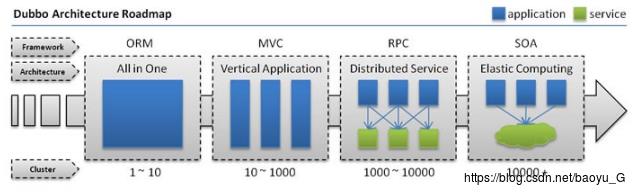
网站应用的架构变化经历了一个从所有服务分布在一台服务器上(All in one 、单一应用架构)到 垂直应用架构 (MVC模式,按照各模块的职能划分)到分布式应用架构(RPC、按照服务不同分布在不同的服务器上)再到面向服务的架构(SOA,增加调度中心,负责集群的调度和管理)的过程。 Dubbo就是处在SOA架构阶段的一个远程服务调用框架。
2.系统结构
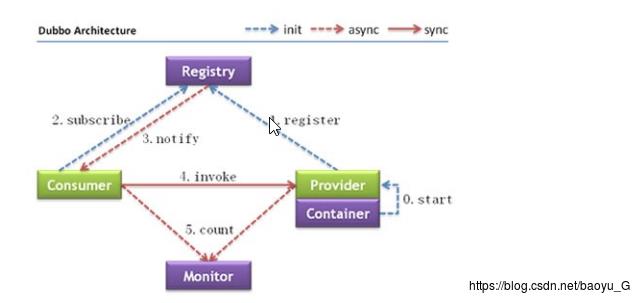
Dubbo系统分为五个部分:远程服务运行容器(Container),远程服务提供方(Provider)、注册中心(Register)、远程服务调用者(Consumer)、监控中心(Monitor)。
Dubbo服务调用过程:
- 服务提供方(Provider)所在的应用在容器中启动并运行(这个容器可以说是该应用部署的tomcat)
- 服务提供方(Provider)将自己要发布的服务注册到注册中心(Registry)
- 服务调用方(Consumer)启动后向注册中心订阅它想要调用的服务
- 注册中心(registry)存储着Provider注册的远程服务,并将其所管理的服务列表通知给服务调用方(Consumer),且注册中心和提供方和调用方之间均保持长连接,可以获取Provider发布的服务的变化情况,并将最新的服务列表推送给Consumer
- Consumer根据从注册中心获得的服务列表,根据软负载均衡算法选择一个服务提供者(Provider)进行远程服务调用,如果调用失败则选择另一台进行调用。(Consumer会缓存服务列表,即使注册中心宕机也不妨碍进行远程服务调用)
- 监控中心(Monitor)对服务的发布和订阅进行监控和统计服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心(Monitor);Monitor可以选择Zookeeper、Redis或者Multiast注册中心等,后序介绍。
3.Dubbo + Zookeeper

Dubbo可以用Zookeeper作为注册中心,存储Provider注册的远程服务信息。
Zookeeper采用树形的目录结构来存储信息。
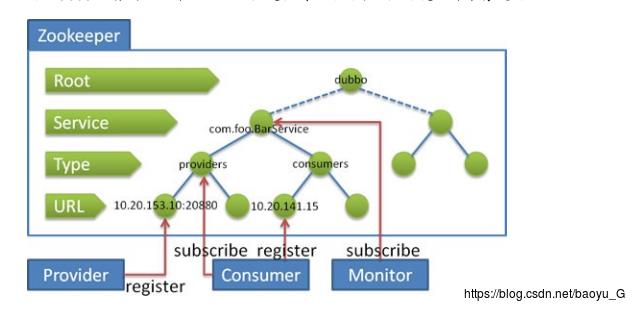
- 服务提供者启动时: 向 /dubbo/com.foo.BarService/providers 目录下写入自己的 URL 地 址
- 服务消费者启动时: 订阅 /dubbo/com.foo.BarService/providers 目录下的提供者 URL 地 址。并向 /dubbo/com.foo.BarService/consumers 目录下写入自己的 URL 地址
- 监控中心启动时: 订阅 /dubbo/com.foo.BarService 目录下的所有提供者和消费者 URL 地 址。
支持以下功能:
- 当提供者出现断电等异常停机时,注册中心能自动删除提供者信息
- 当注册中心重启时,能自动恢复注册数据,以及订阅请求
- 当会话过期时,能自动恢复注册数据,以及订阅请求
- 当设置<dubbo:registry check=“false” />时,记录失败注册和订阅请求,后台定时重试
- 可通过设置<dubbo:registry username=“admin” password=“124”/>设置zookeeper 登录信息
- 可通过<dubbo:registry group=“dubbo” />设置 zookeeper 的根节点,不设置将使用无 根树
- 支持 * 号通配符 <dubbo:redistry group=“*” version=“*” />,可订阅服务的所有分组 和所有版本的提供者
4.Dubbo + Redis
Redis是一个基于内存的,以Key-Value形式存储数据的高性能Nosql数据库,可以用来存储远程服务信息用作注册中心
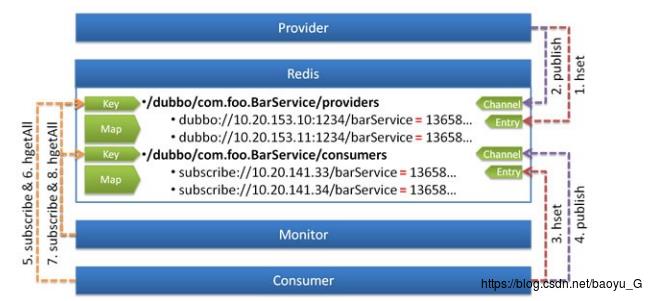
使用 Redis 的 Key—Map 结构存储数据结构:
- 主键 Key 为服务名和服务类型:比如./dubbo/com.foo.BarService/providers或./dubbo/com.foo.BarService/providers,相当于Zookeeper中的第三层目录
- 值 Map 中的 Key 为 URL 地址 ,Map 中的 Value 为过期时间,用于判断脏数据,脏数据由监控中心删除
使用 Redis 的 Publish/Subscribe 事件通知数据变更:
- 通过事件的值区分事件类型: register , unregister , subscribe , unsubscribe
- 普通消费者直接订阅指定服务提供者的 Key,只会收到指定服务的 register , unregister 事件
- 监控中心通过 psubscribe 功能订阅 /dubbo/* ,会收到所有服务的所有变更事件
调用过程:
- 服务提供方启动时,向 Key:/dubbo/com.foo.BarService/providers 下,添加当前提供者的地址,并向 Channel:/dubbo/com.foo.BarService/providers 发送 register 事件
- 服务消费方启动时,从 Channel:/dubbo/com.foo.BarService/providers 订阅 register 和 unregister 事件 ,并向 Key:/dubbo/com.foo.BarService/providers 下,添加当前消费者的地址
- 服务消费方收到 register 和 unregister 事件后,从 Key:/dubbo/com.foo.BarService/providers 下获取提供者地址列表
- 服务监控中心启动时,从 Channel:/dubbo/* 订阅 register 和 unregister ,以及subscribe 和 unsubsribe 事件
- 服务监控中心收到 register 和 unregister 事件后,从 Key:/dubbo/com.foo.BarService/providers 下获取提供者地址列表
- 服务监控中心收到 subscribe 和 unsubsribe 事件后,从 Key:/dubbo/com.foo.BarService/consumers 下获取消费者地址列表
以上是关于分布式架构及Dubbo的主要内容,如果未能解决你的问题,请参考以下文章