Netflix 网站架构学习
Posted 路过的摸鱼侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netflix 网站架构学习相关的知识,希望对你有一定的参考价值。
Netflix 网站架构学习
Netflix 架构的特点是他们没有自建数据中心,而是将服务直接架设在 AWS 的云服务上(EC2 和 S3),并通过自建 CDN Open Connect 提供高质量的点播服务。Netflix 采用微服务架构,将复杂业务流程拆解成独立的小型服务,服务间通过 REST 或 RPC 彼此调用。
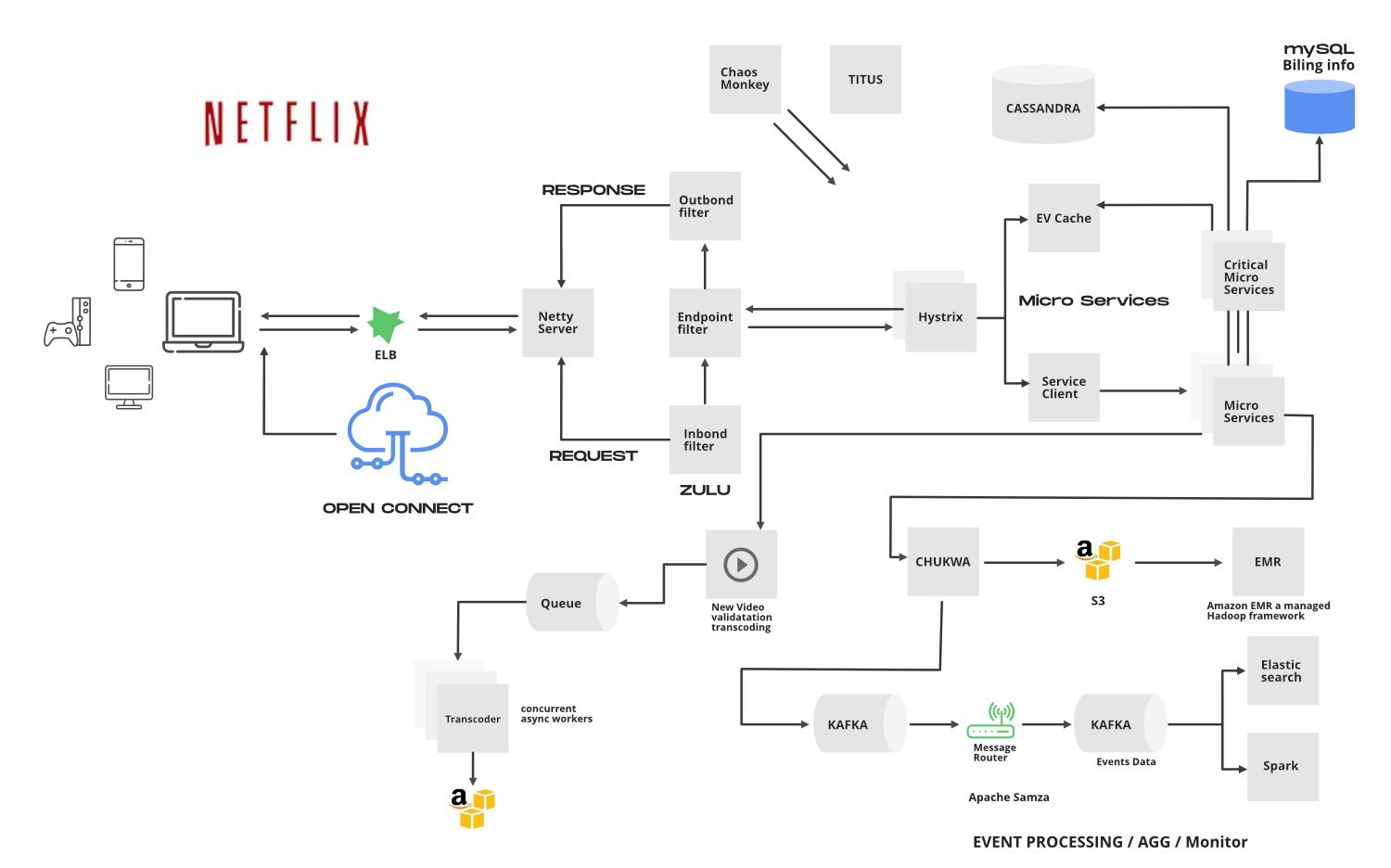
CDN
CDN 的主要原理是利用位于不同地理位置的服务器集群,将内容存储在靠近用户的服务器上,从而减少内容传输的延迟和带宽使用。
当用户请求访问特定的内容时,CDN 会自动为用户提供最接近他们所在地理位置的服务器上的内容,这将使用户能够更快地访问网站和其他在线服务。如果某个服务器出现故障或网络拥塞,CDN 可以自动将用户请求重新路由到其他可用的服务器上,从而确保内容始终可用。
CDN 中内容的来源称为 Origin,而缓存服务器称为 POP(Point of Presence)。
视频网站使用 CDN 能带来哪些优势:
- 性能优势:CDN 节点距离用户更近,请求内容的时延更小;
- 可用性:单个节点宕机,其他节点能仍能提供服务;即使源服务器宕机,CDN 仍能利用缓存的数据提供服务;
- 安全性:CDN 能缓解 DDos 攻击并提供其他安全功能;
- 可拓展性:CDN 按使用的流量计费,且可以处理流量高峰。
Open Connect
Open Connect 是 Netflix 自建的视频 CDN,它是一种主动的、有针对性的缓存解决方案(相对于缓存未命中时找 Origin 拉取内容的 CDN 方案)。
Open Connect 由一堆专用服务器构成,这些服务器被称为 OCAs(Open Connect Appliances)
- 存储编码的视频/图像文件,并通过 HTTP / HTTPS 将这些文件提供给客户端设备
- 部署在 IXP 中,和 ISP 对等互连或直接部署在 ISP 网络内部
OCAs 和客户设备、Netflix AWS 服务之间的交互
- OCAs 不存储客户数据(比如观看历史、DRM 信息)
- OCAs 只执行两件事
- 当客户端设备请求内容时,OCAs 服务器会通过 HTTP/HTTPS 提供内容
- 向 AWS 中的 Open Connect 控制平面服务报告自己的状态
- Open Connect 控制平面服务
- 接收 OCAs 报告的数据,并利用这些数据来控制客户端通过 URL 访问最优的 OCA
- 根据文件可用性、健康状况、与客户端的网络距离
- 控制 OCAs 的填充行为
- 根据算法预测用户行为,利用非峰值带宽更新 OCAs 上的视频
- 受欢迎的视频可以有更多的副本
- 根据算法预测用户行为,利用非峰值带宽更新 OCAs 上的视频
- 接收 OCAs 报告的数据,并利用这些数据来控制客户端通过 URL 访问最优的 OCA
视频播放的整体流程
- OCAs 定期汇报健康状态、路由、文件可用性等信息给 AWS 上的 Cache Control Service
- 用户在客户端设备上通过 Netflix 应用程序请求播放电视节目或电影
- Playback Apps 会检查用户授权和许可证,然后根据客户端特征和当前网络条件确定选择合适的文件来播放
- 应该指的是选择一个合适的分辨率或格式下的视频文件来播放
- Steering Service 使用由 CCS 存储的信息来选择应该让哪个 OCA 提供请求的文件,生成相应的 URL 并将其交给 Playback Apps
- Playback Apps 将适当的 OCA 的 URL 交给客户端设备,由 OCA 提供请求的文件
- Playback Apps 会返回一组 URL,由客户端来选择连接哪个 URL,网络质量下降时,客户端可能会切换到其他 OCA 上去
其中 Playback Apps、Steering Service、Cache Control Service 都部署在 AWS 上

media pipeline
工作室发给 Netflix 的原始视频,这些视频一般是高清格式的
- Netflix 首先会检查这些源视频
- 检查是否存在失真或伪影的问题,是否符合规范,如果存在问题就要求重新交付
- 同时生成编码管道所需的元数据
- 源视频首选格式为 IMF,也支持 ProRes、DPX 和 MPEG
- 在 EC2 服务器上执行转码(transcoding),生成不同分辨率和格式的视频以支持各种不同的播放设备
- 由于源视频可能会非常大,管道会将它分块放到不同实例上并行处理,所有块的编码都结束后再组装到一起
- 转码后输出的视频会被发送到 Open Connect 里
参考资料
本文来自博客园,作者:路过的摸鱼侠,转载请注明原文链接:https://www.cnblogs.com/ljx-null/p/17419453.html
SpringCloud-Netflix入门学习笔记
1、前言
1.1、回顾知识点

1.2、这个阶段该如何学



1.3、面试题
2、微服务概述
2.1、什么是微服务


2.2、微服务与微服务架构
2.3、微服务优缺点
优点

缺点

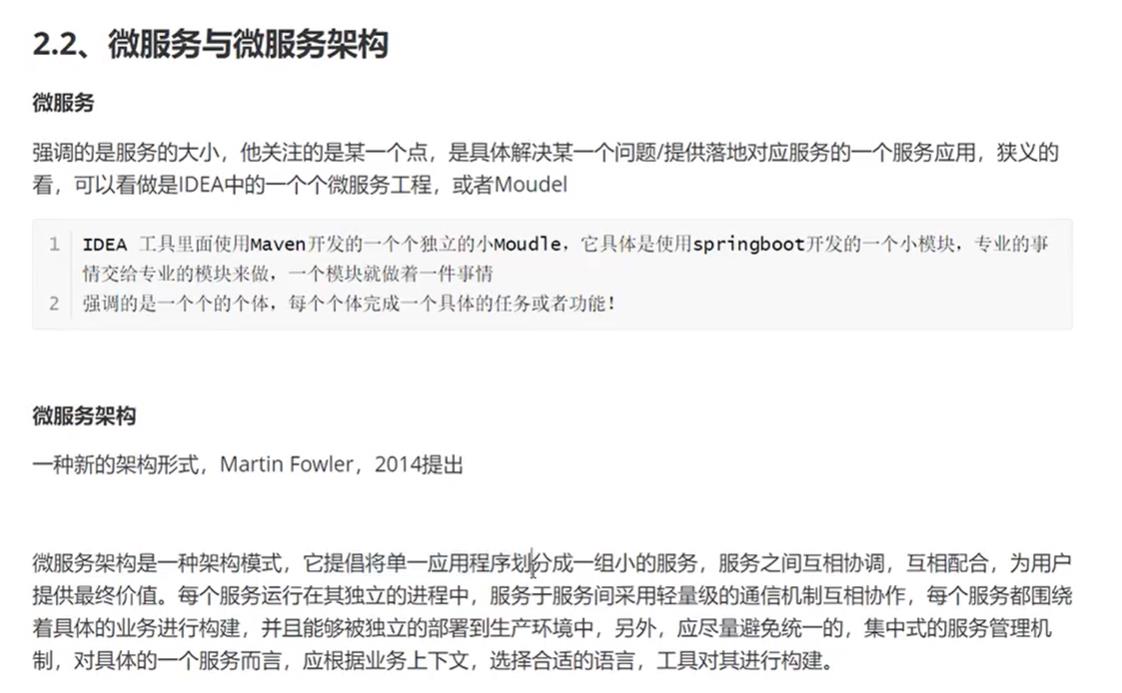
2.4、微服务技术栈有哪些?
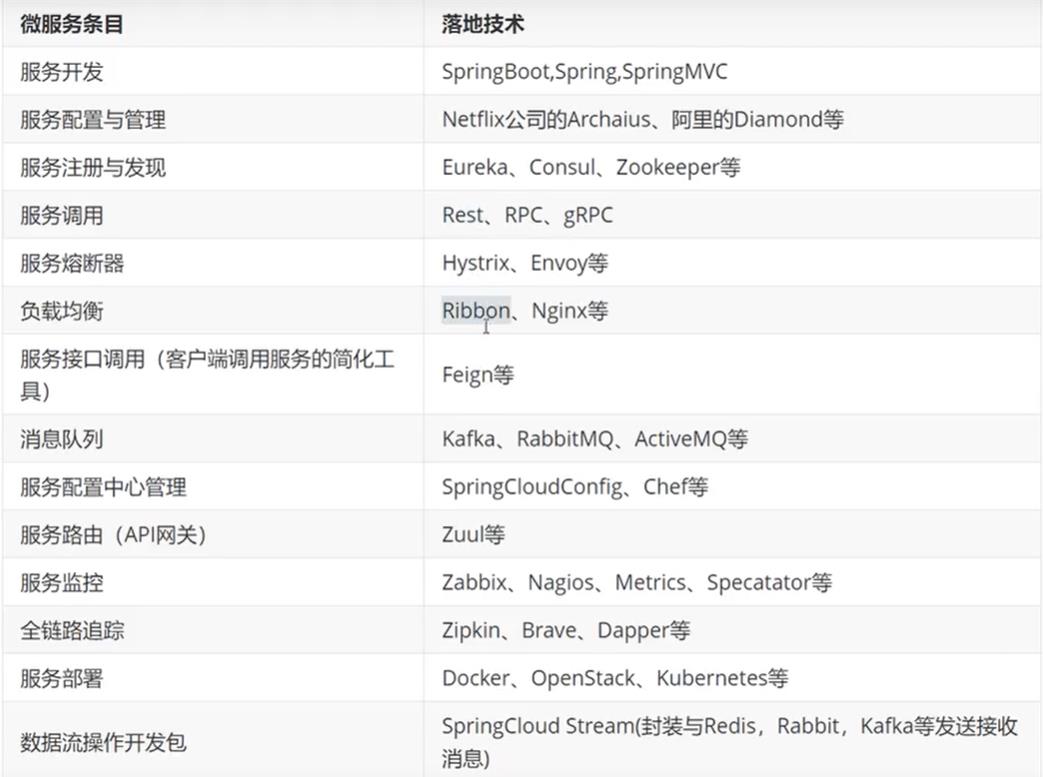

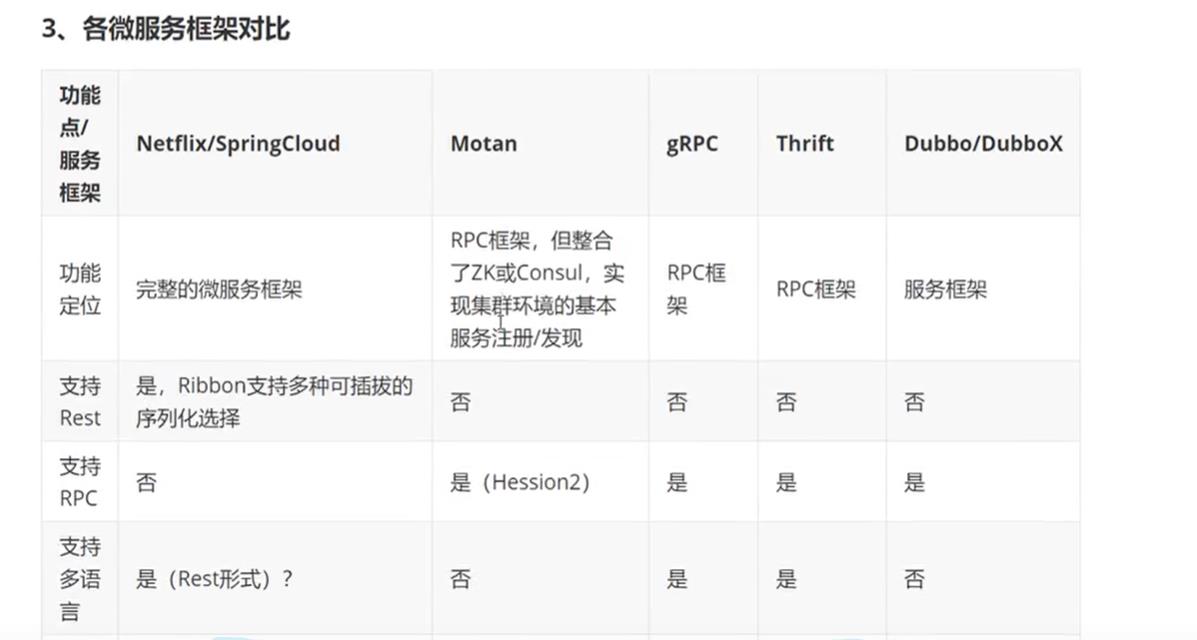
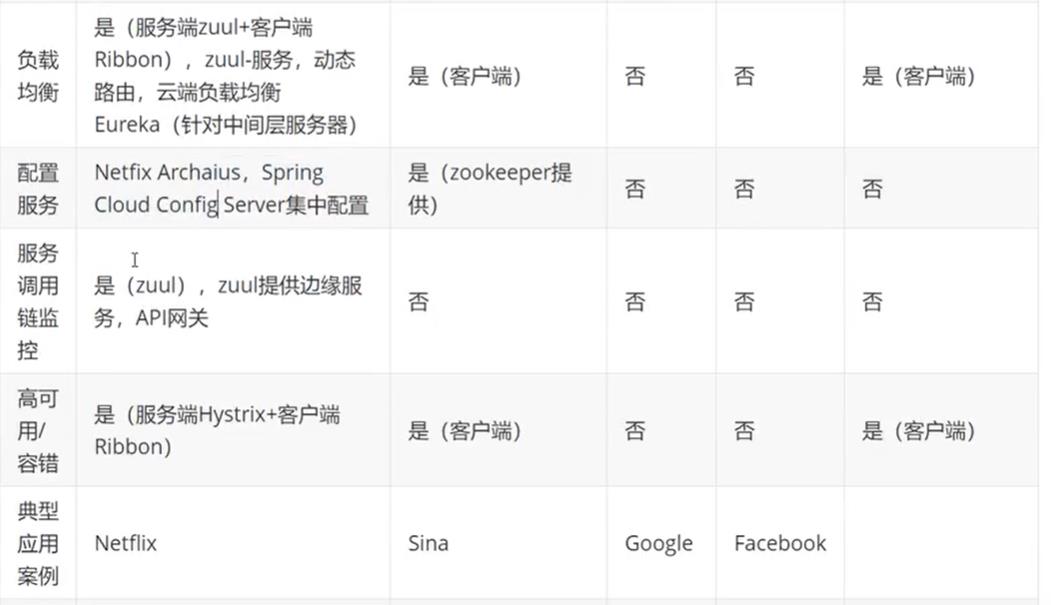
2.5、为什么选择SpringCloud作为微服务架构

3、SpringCloud入门概述
3.1、SpringCloud是什么
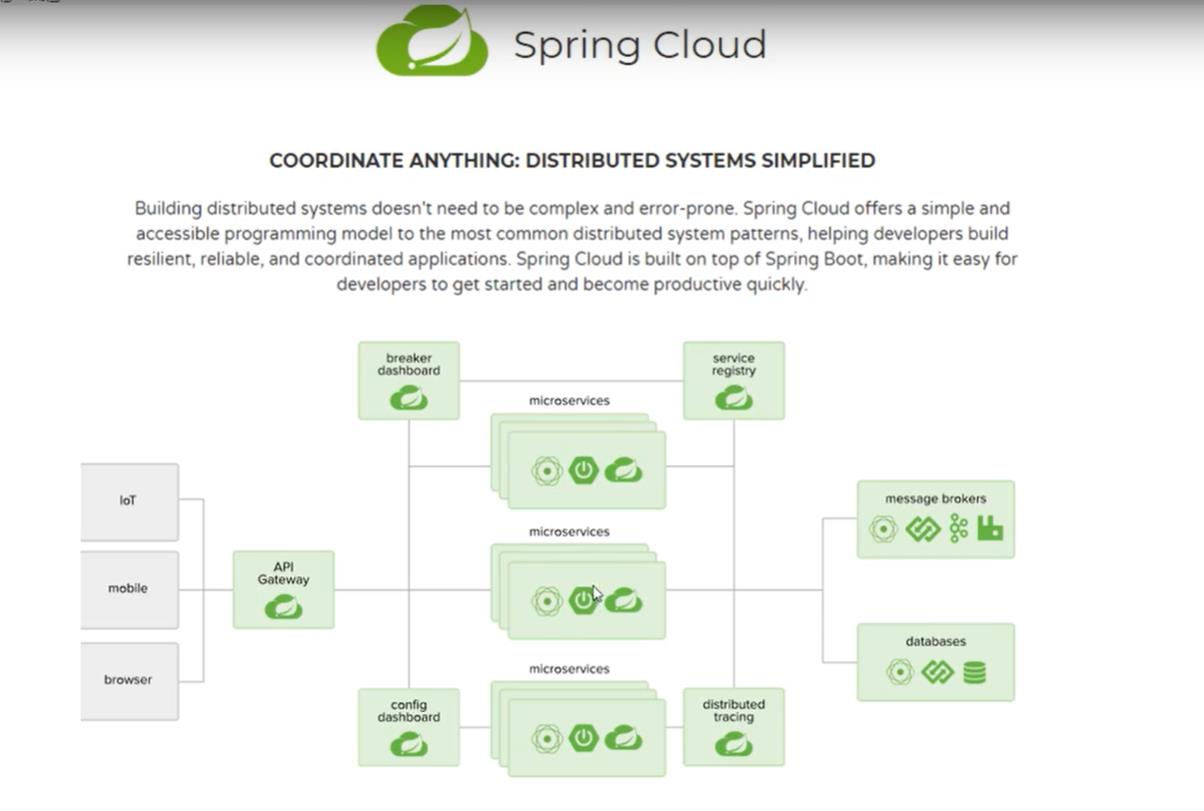

3.2、SpringCloud和SpringBoot关系

3.3、Dubbo和SpringCloud技术选型
3.3.1、分布式+服务治理Dubbo
目前成熟的互联网架构:应用服务化拆分+消息中间件
3.3.2、Dubbo和SpringCloud对比
看看社区活跃度,一直在跳动的就是经常改动,没有跳动的就是很久没用了
Dubbo
SpringCloud
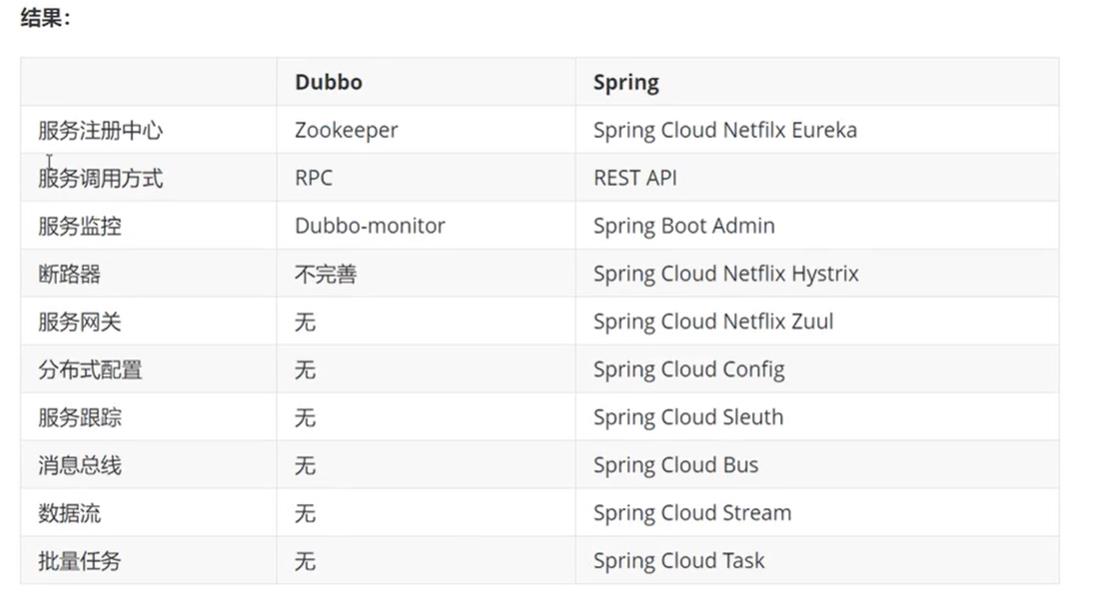

总结

3.4、SpringCloud能干嘛

3.5、SpringCloud在哪下

参考书

4、SpringCloud测试
4.1、总体介绍
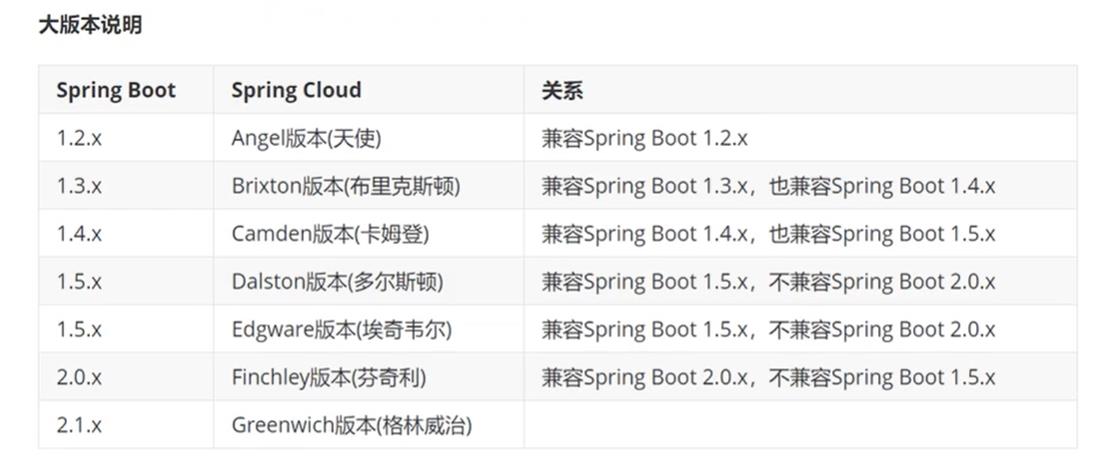
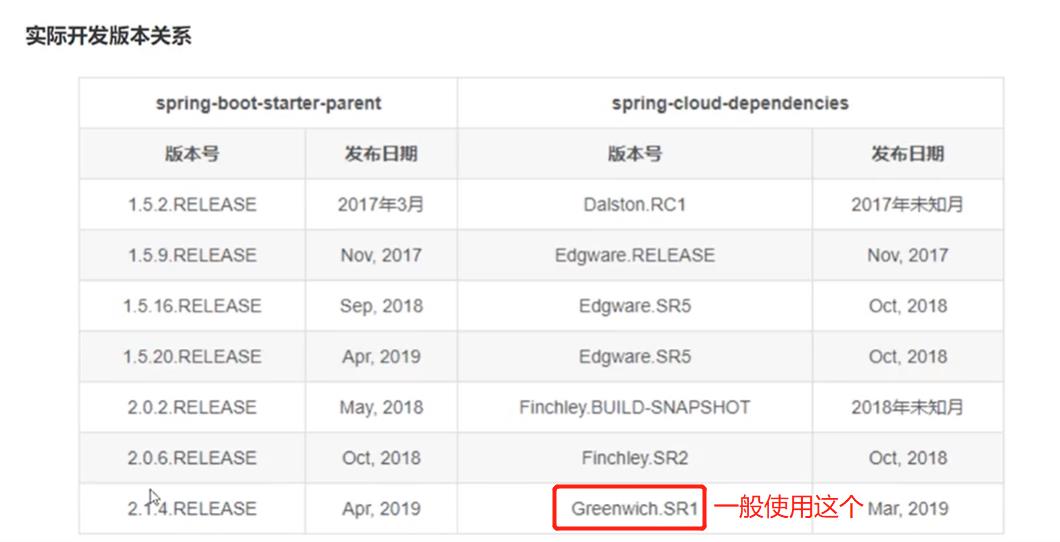
4.2、SpringCloud版本选择
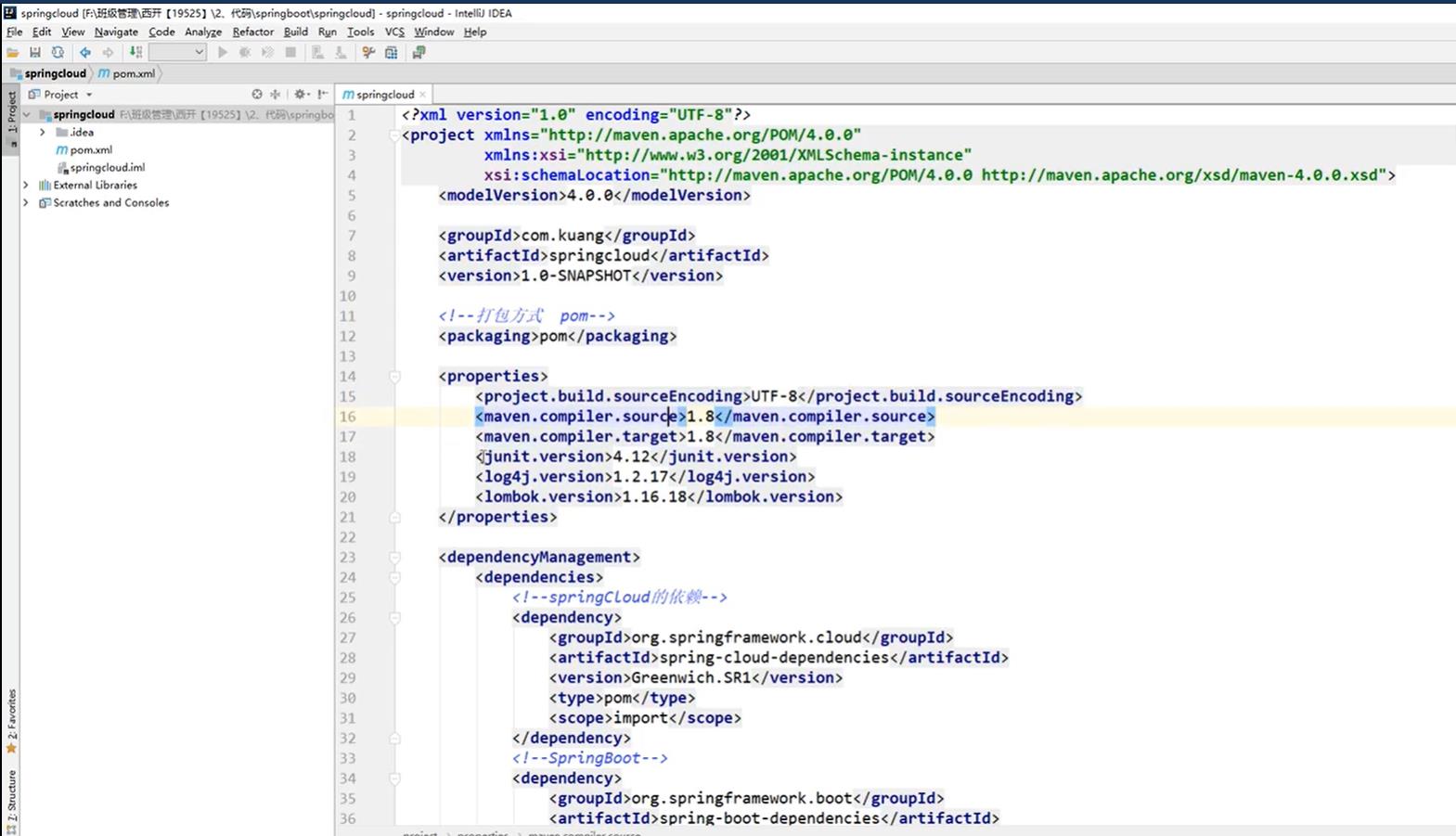
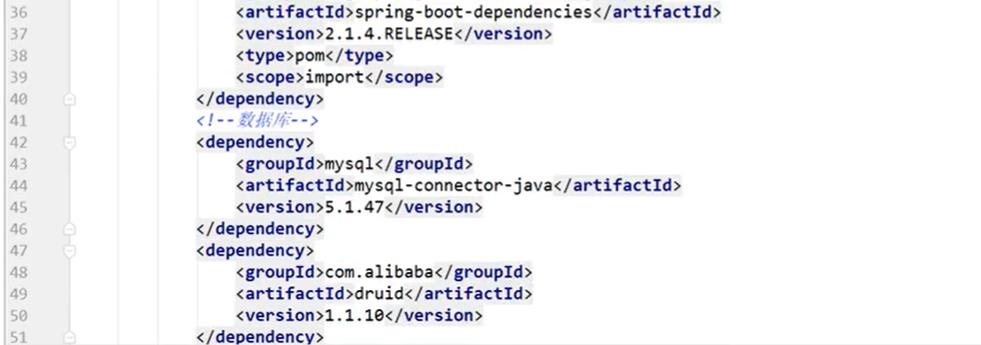
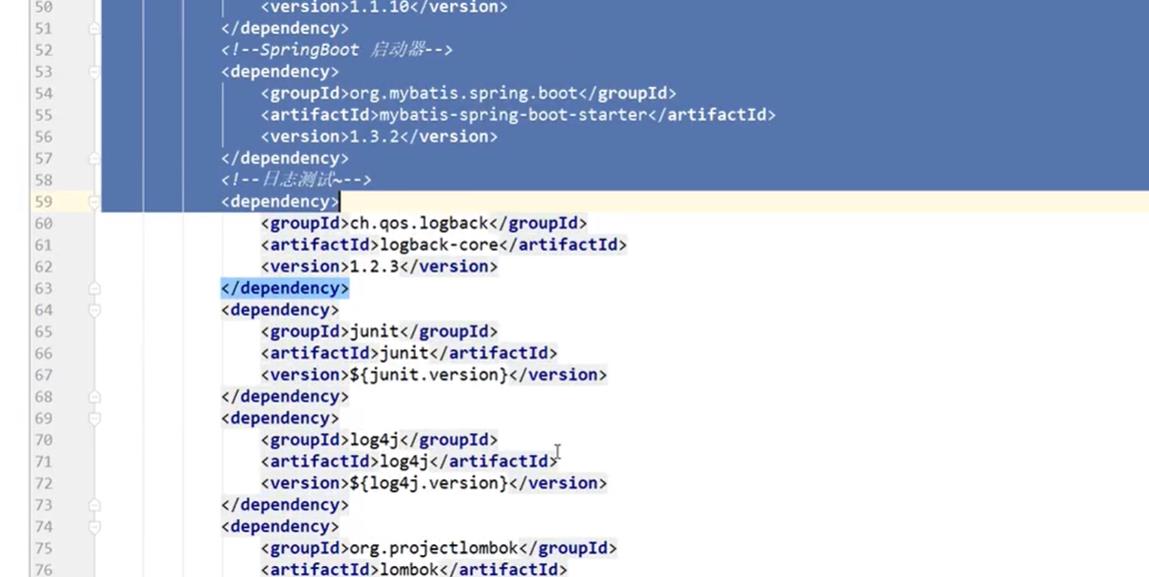
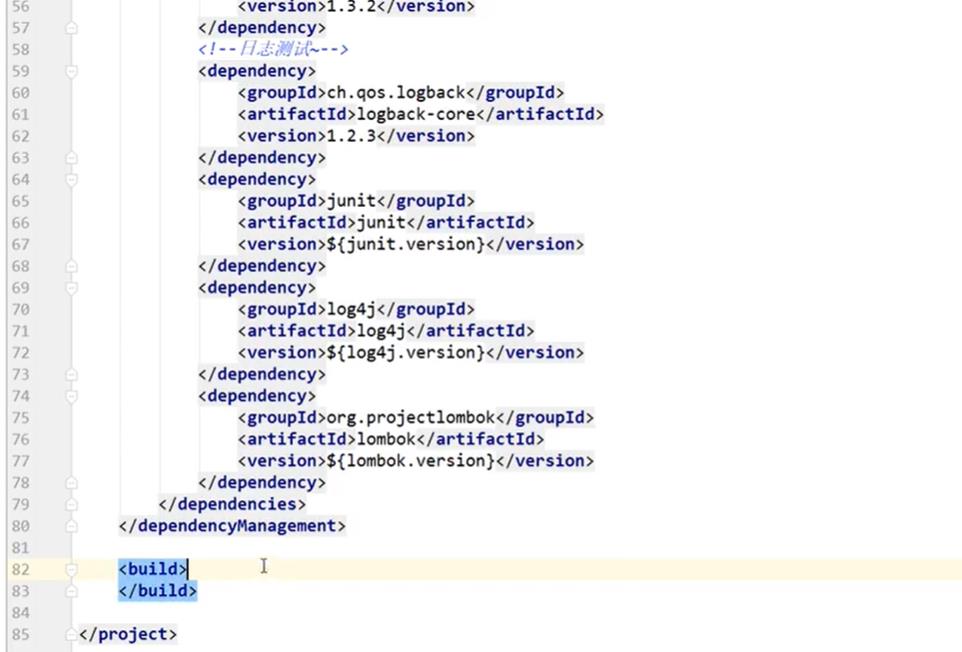
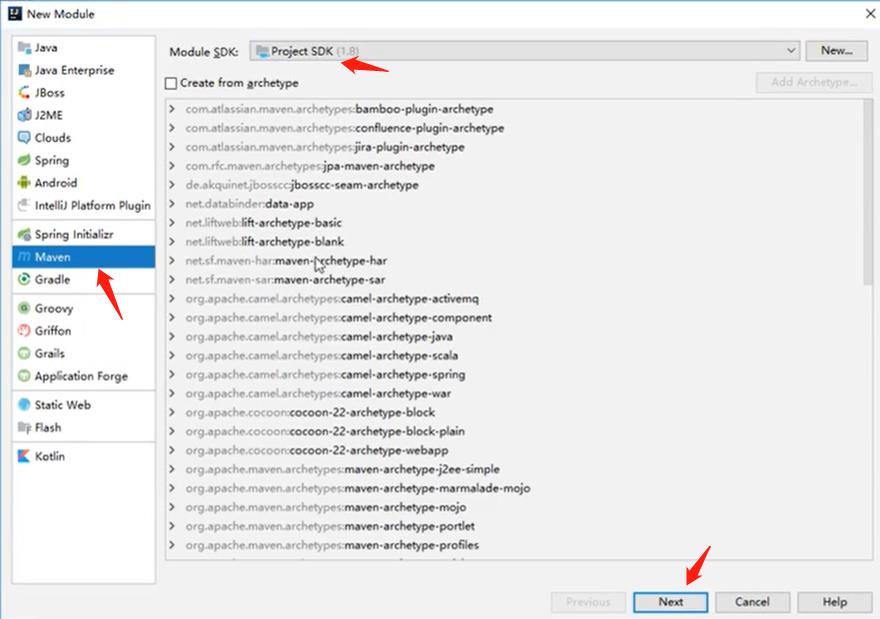
4.3、创建父工程
创建一个普通的maven项目作为父工程,可以将src文件夹都删了,只剩下一个pom.xml项目,pom.xml文件内容如下:
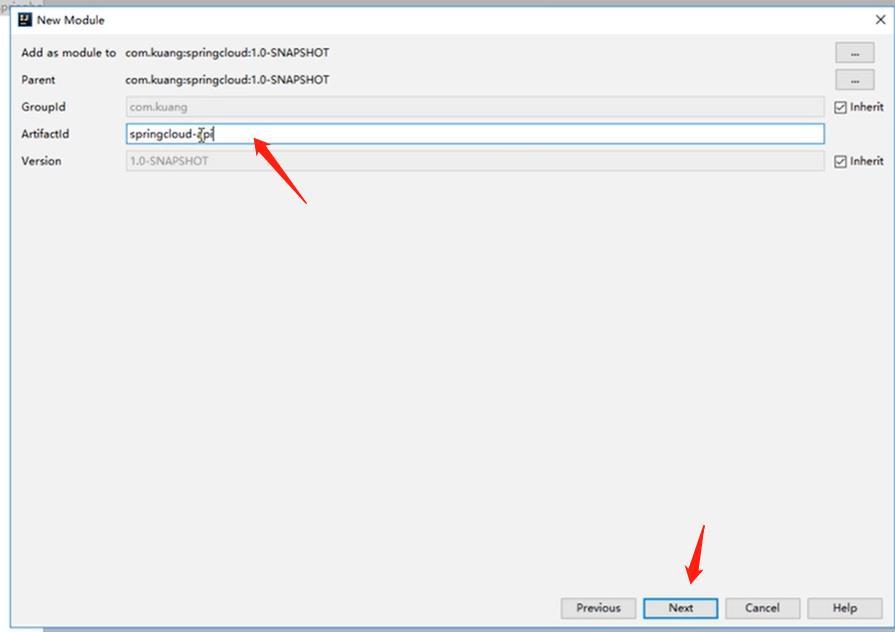
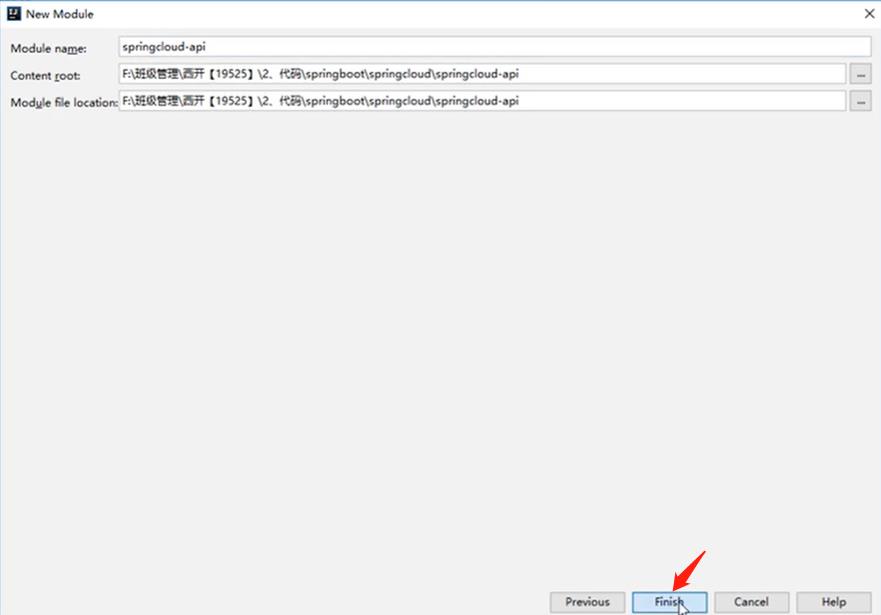
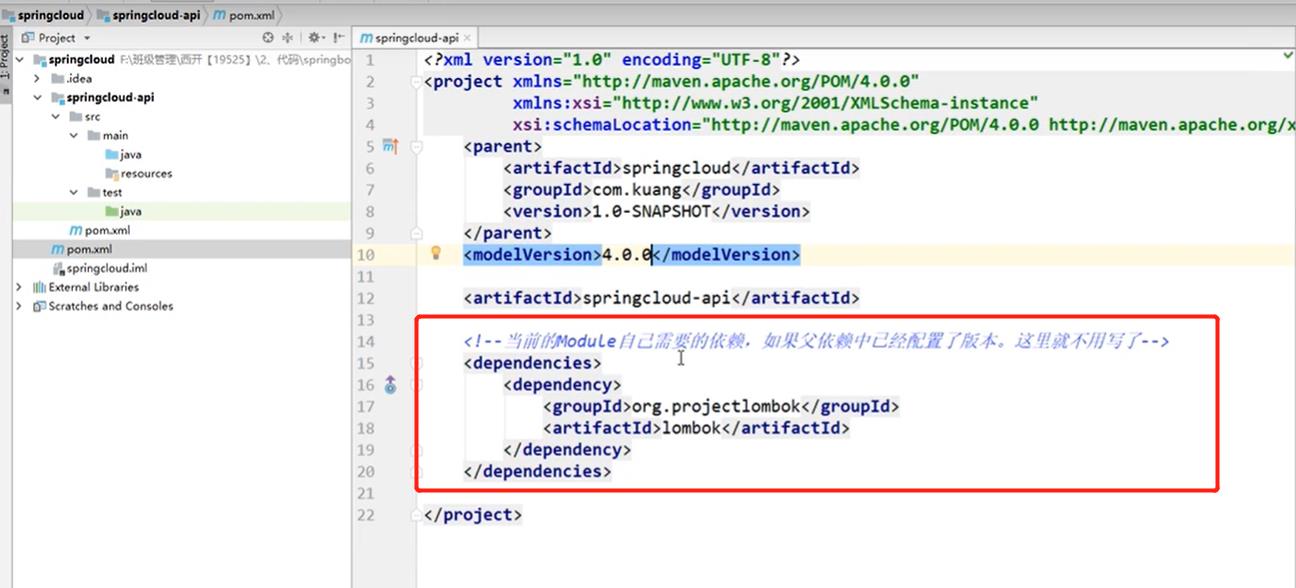
4.4、创建子工程作为一个微服务
- 在父工程中创建一个maven项目,导入子工程需要的依赖
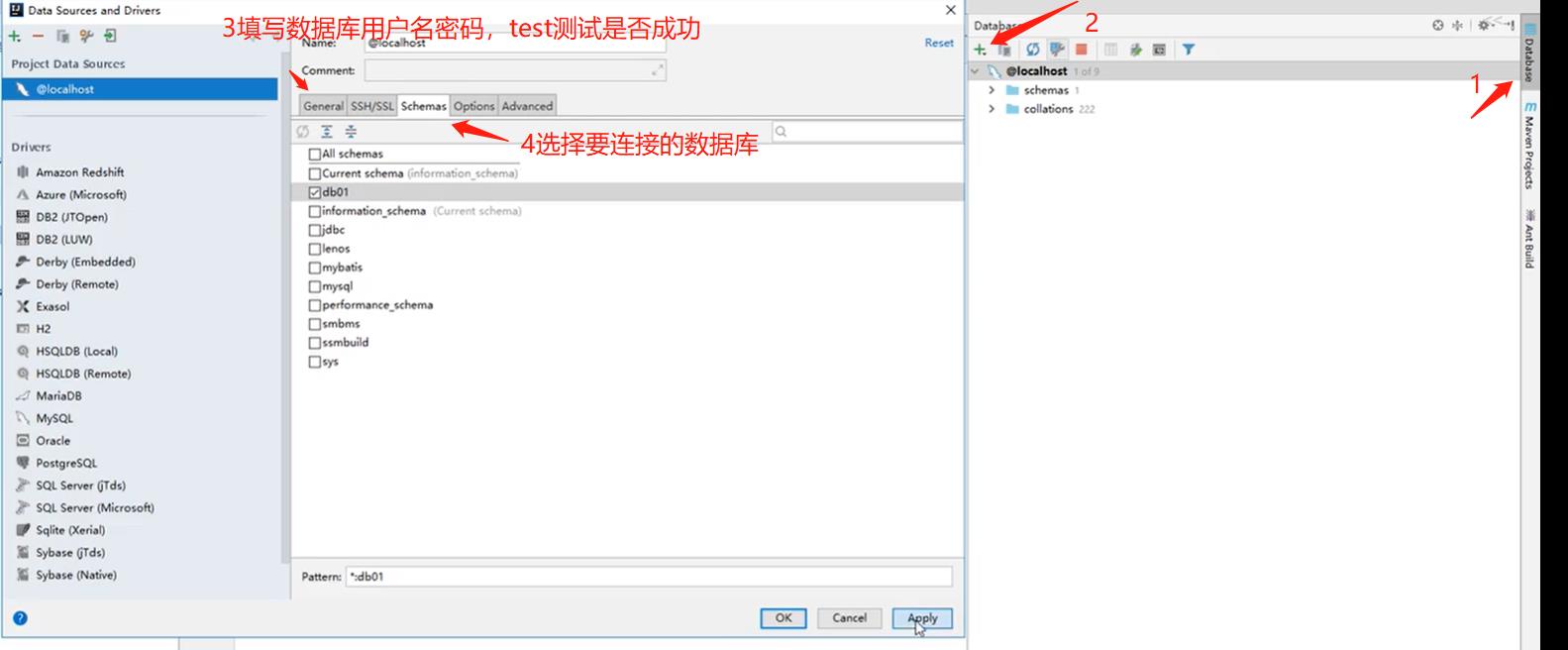
2. 创建数据库,连接数据库
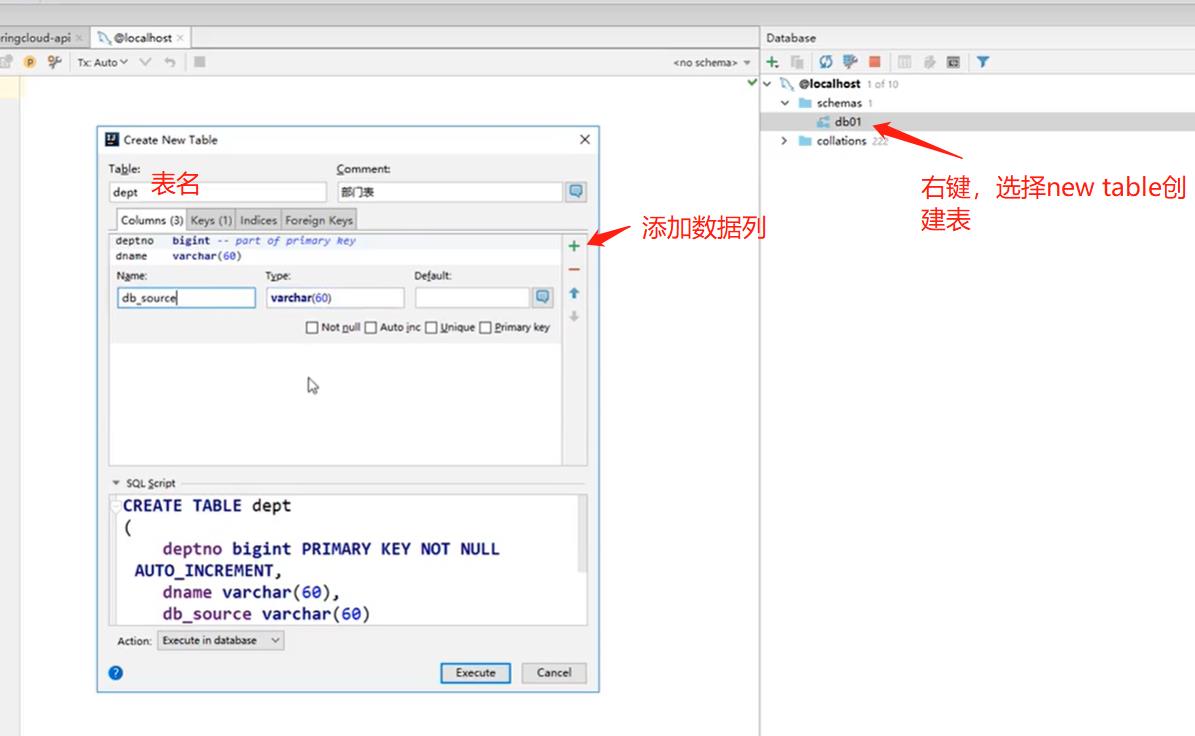
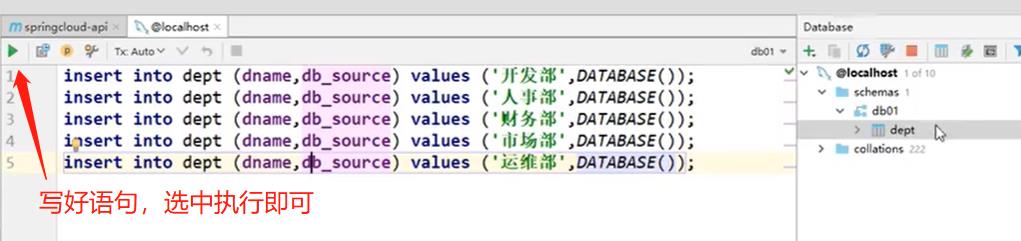
3. 创建表,插入数据
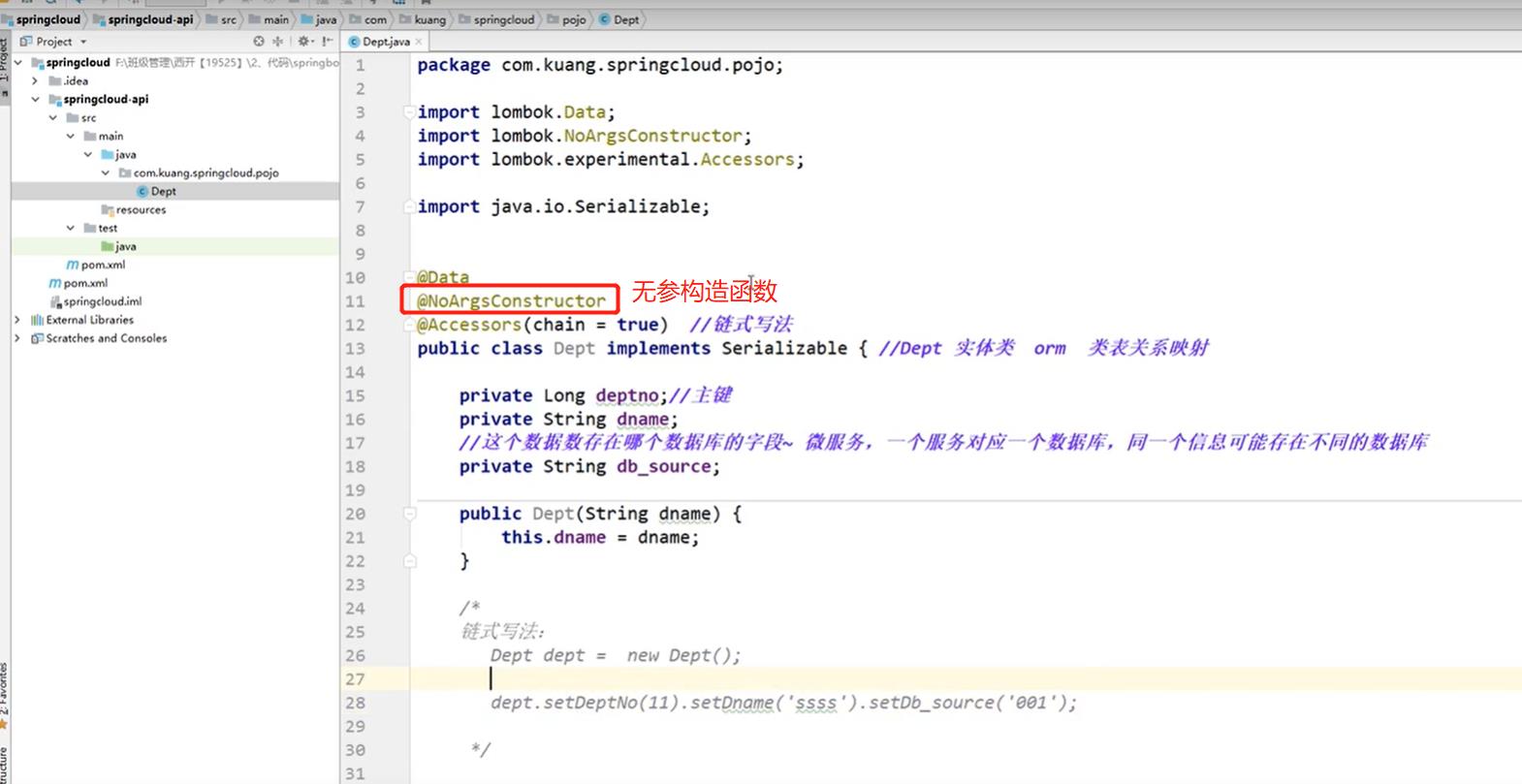
4. 实体类
4.5、创建子工程作为第二个微服务8001(提供服务)
- 在父工程中创建一个maven项目,导入子工程需要的依赖
导入依赖
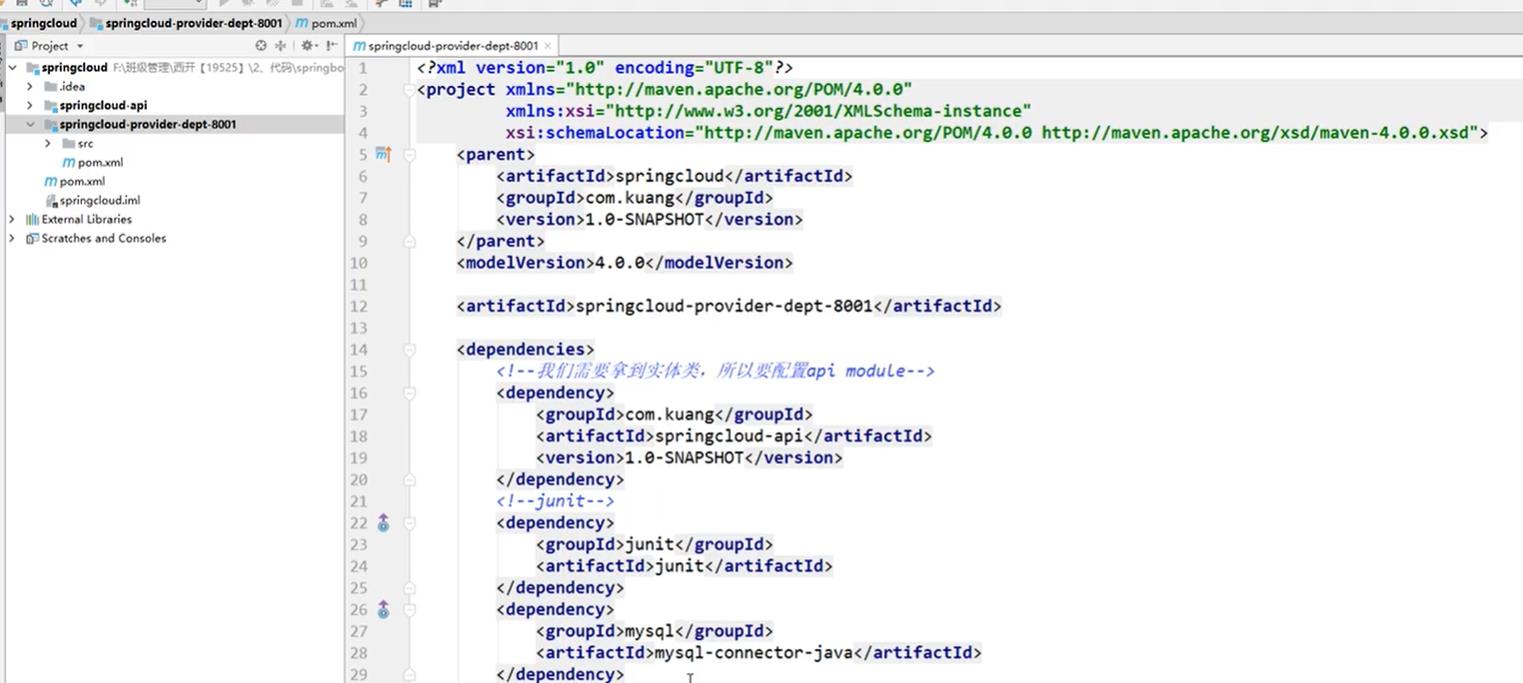
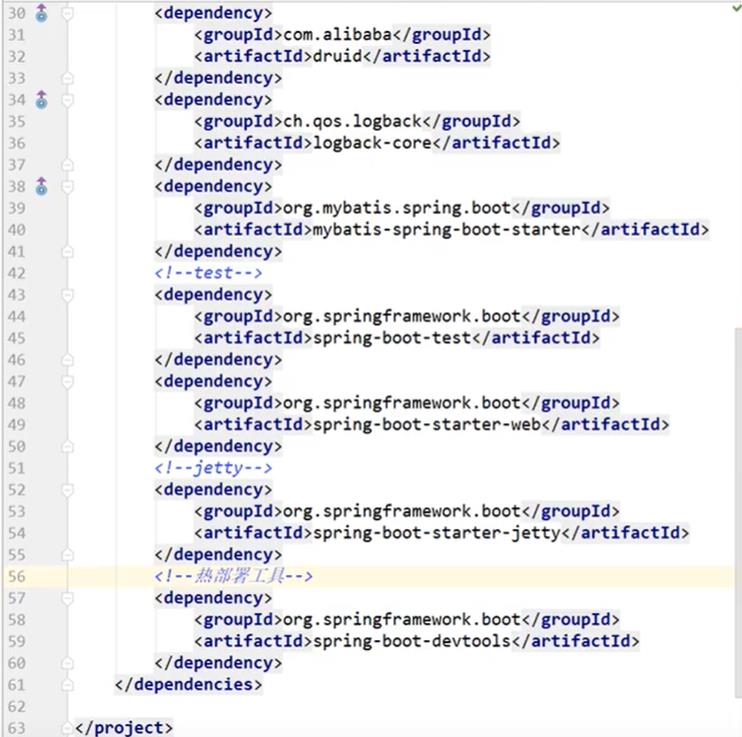
2. 写配置文件application.yml
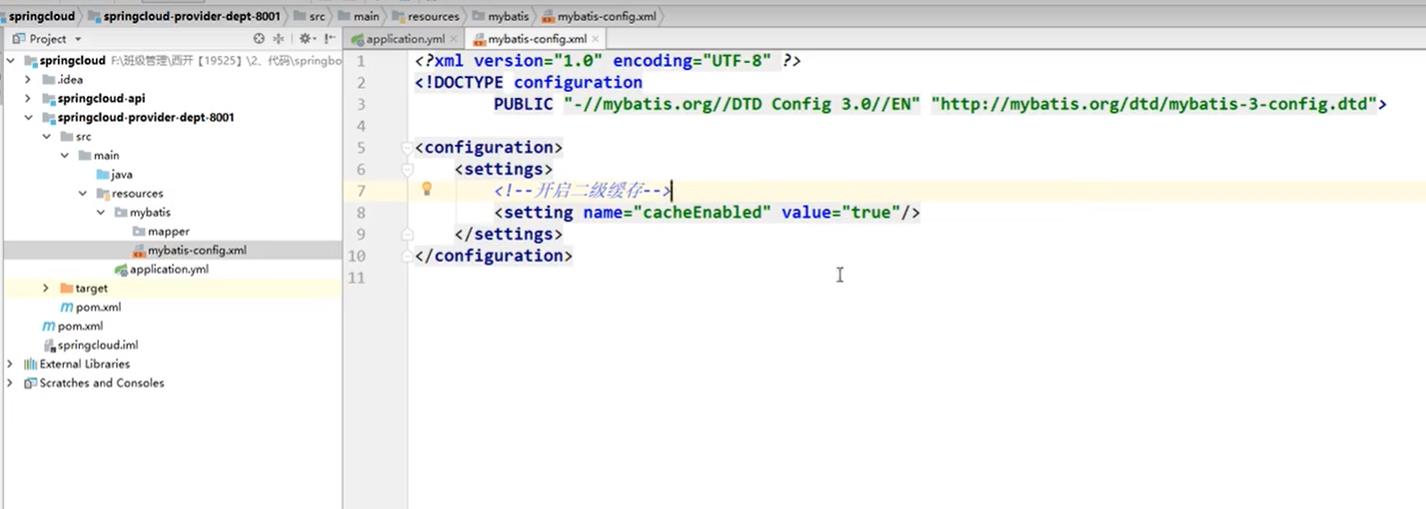
在mybatis文件夹下创建mybatis-config.xml文件然后再yml文件中写配置设置
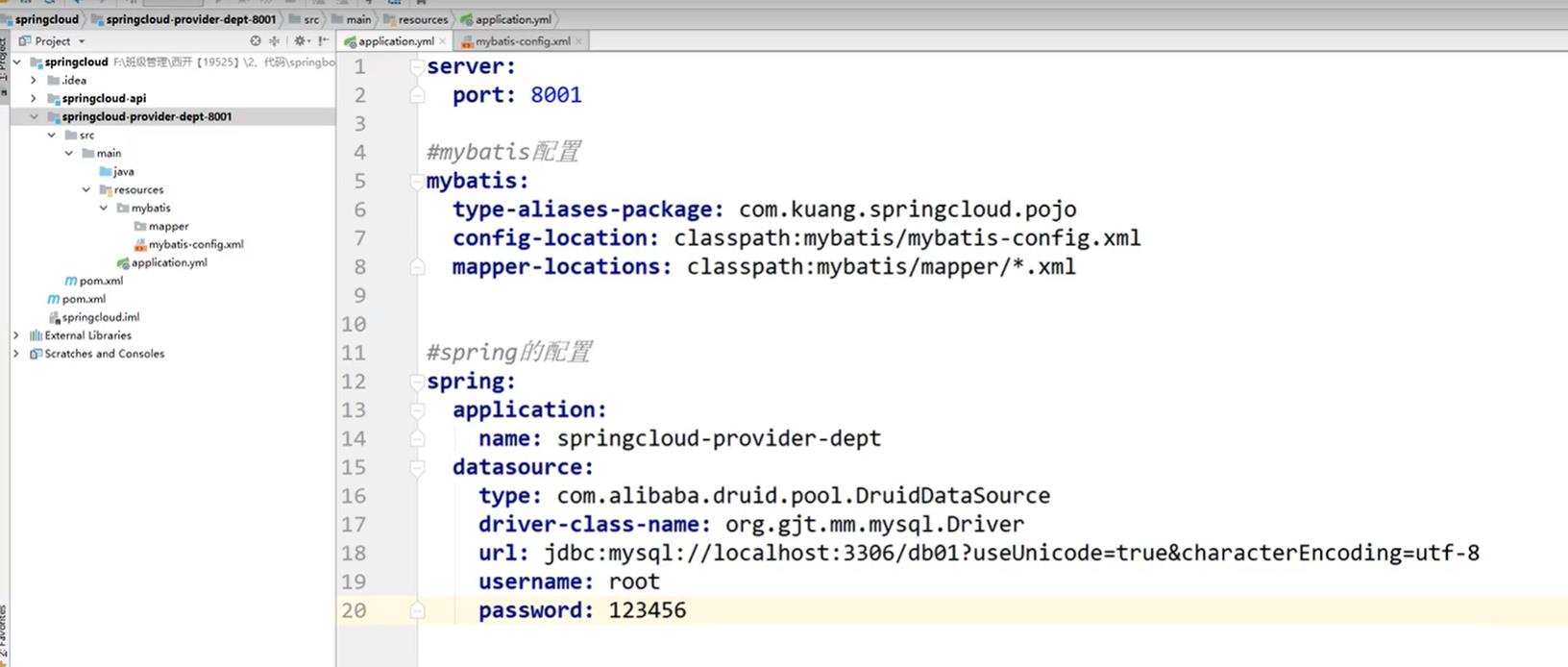
mybatis-config.xml文件
-
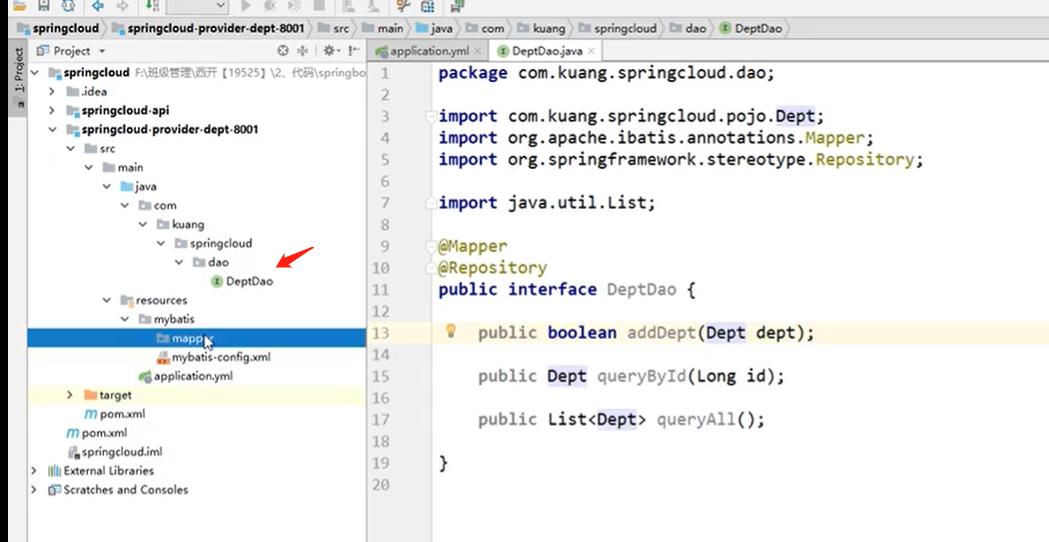
写接口dao层
dao层java文件
编写对应dao层的xml文件
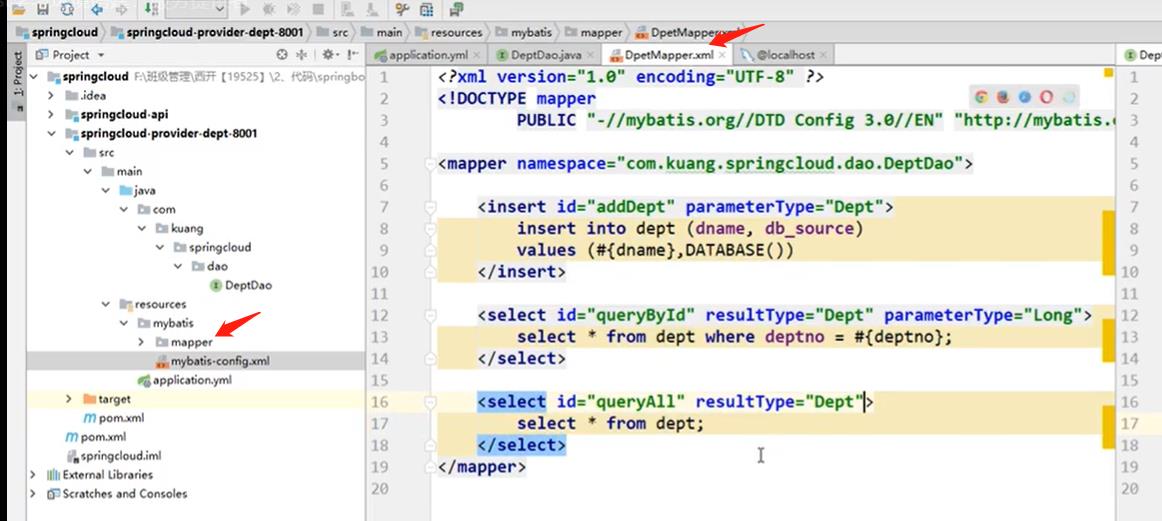
-
service层
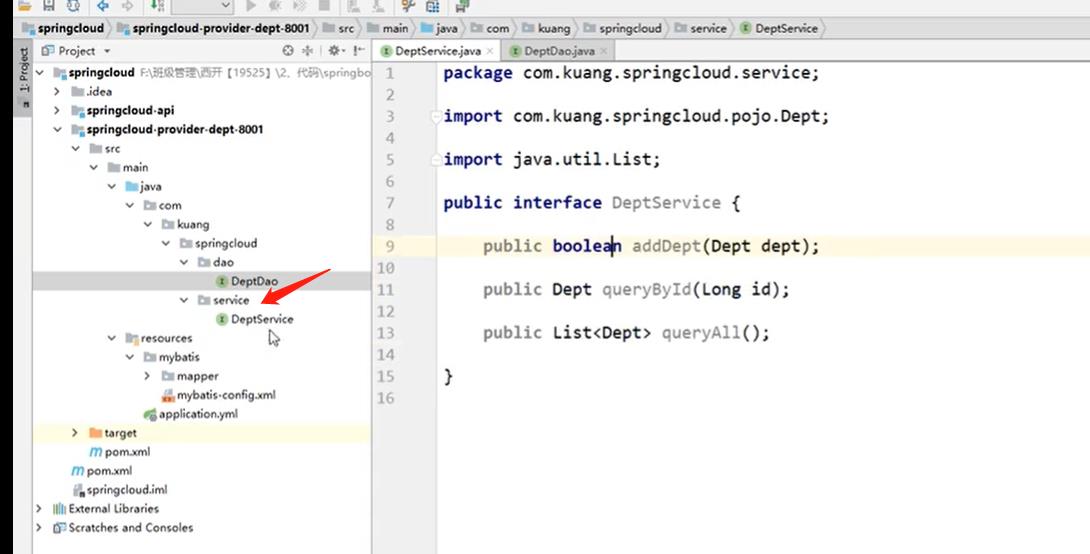
-
serviceImpl层
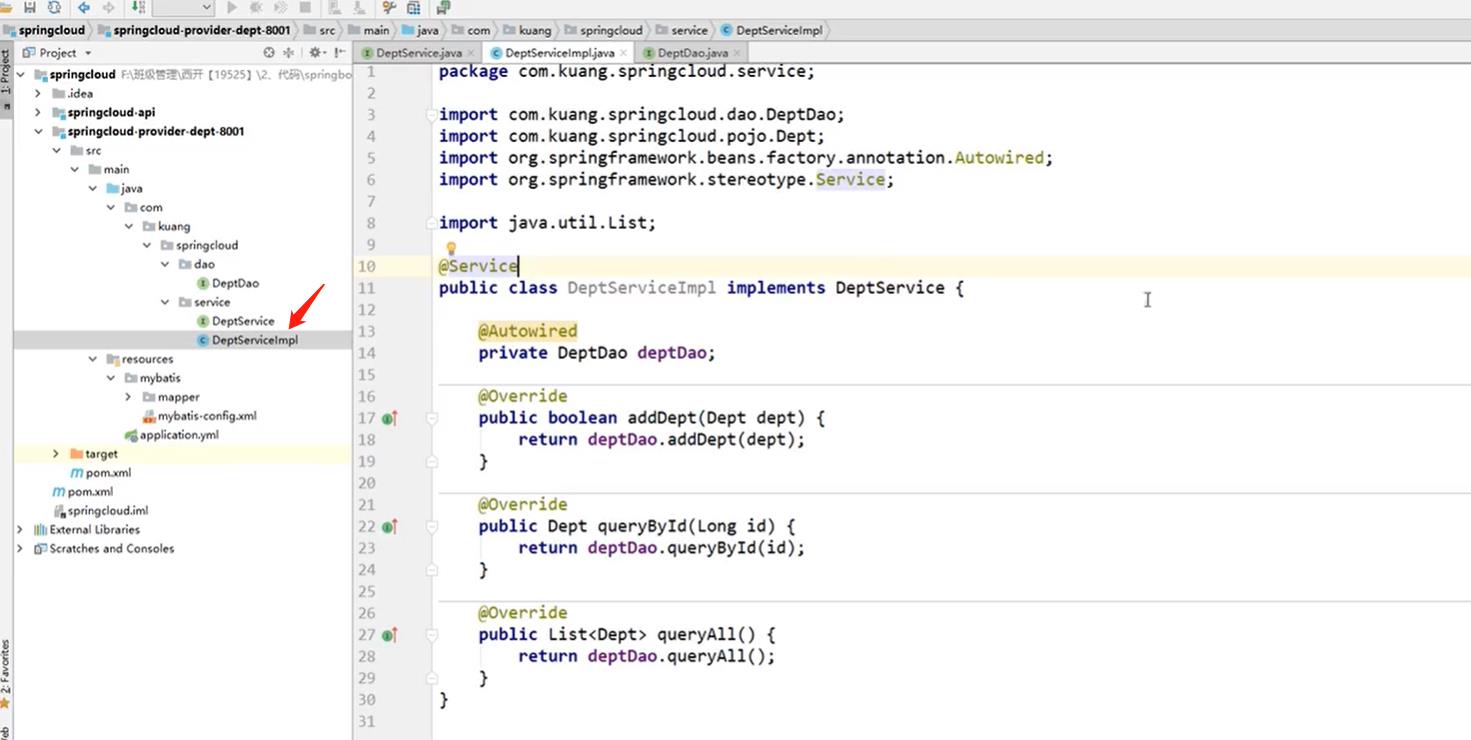
-
controller层
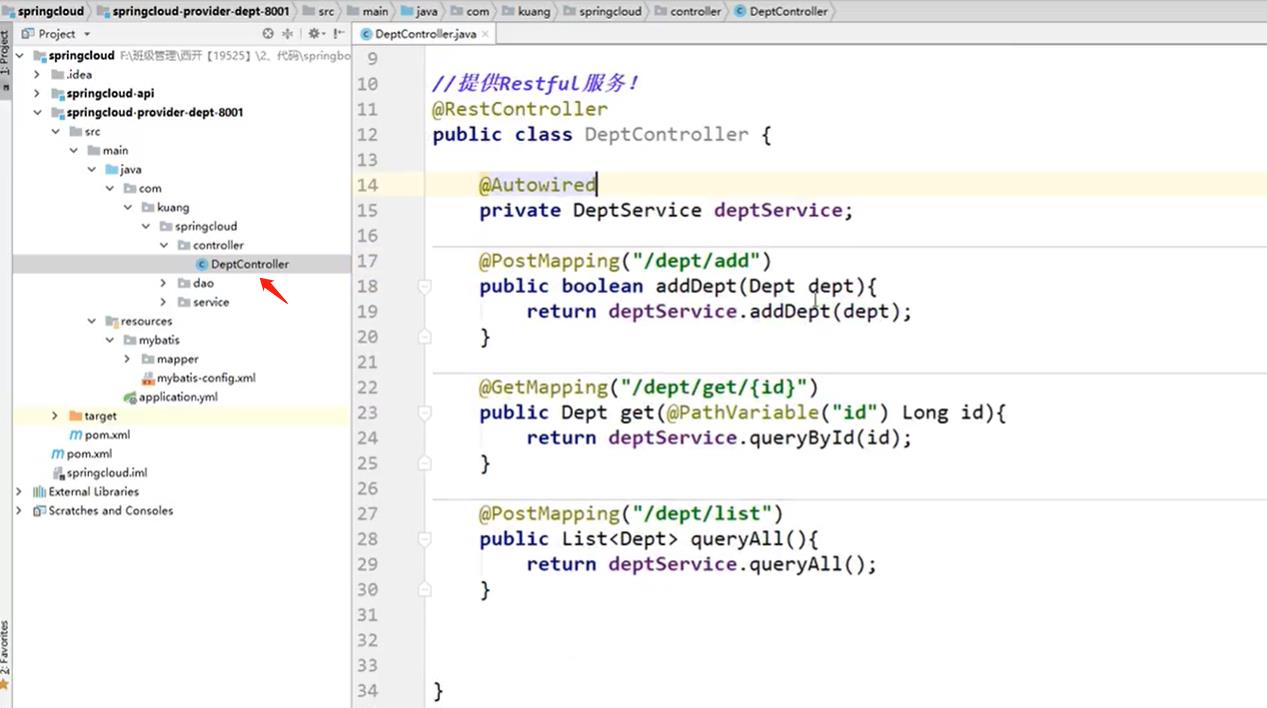
注意:这里的queryAll()方法用的PostMapping会报错,要修改成GetMapping:
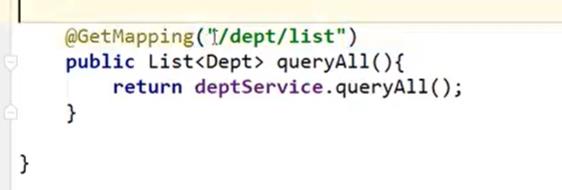
-
启动类
-
测试结果
list

4.6、创建子工程作为第三个微服务80(客户端)
- 在父工程中创建一个maven项目,导入子工程需要的依赖
导入依赖
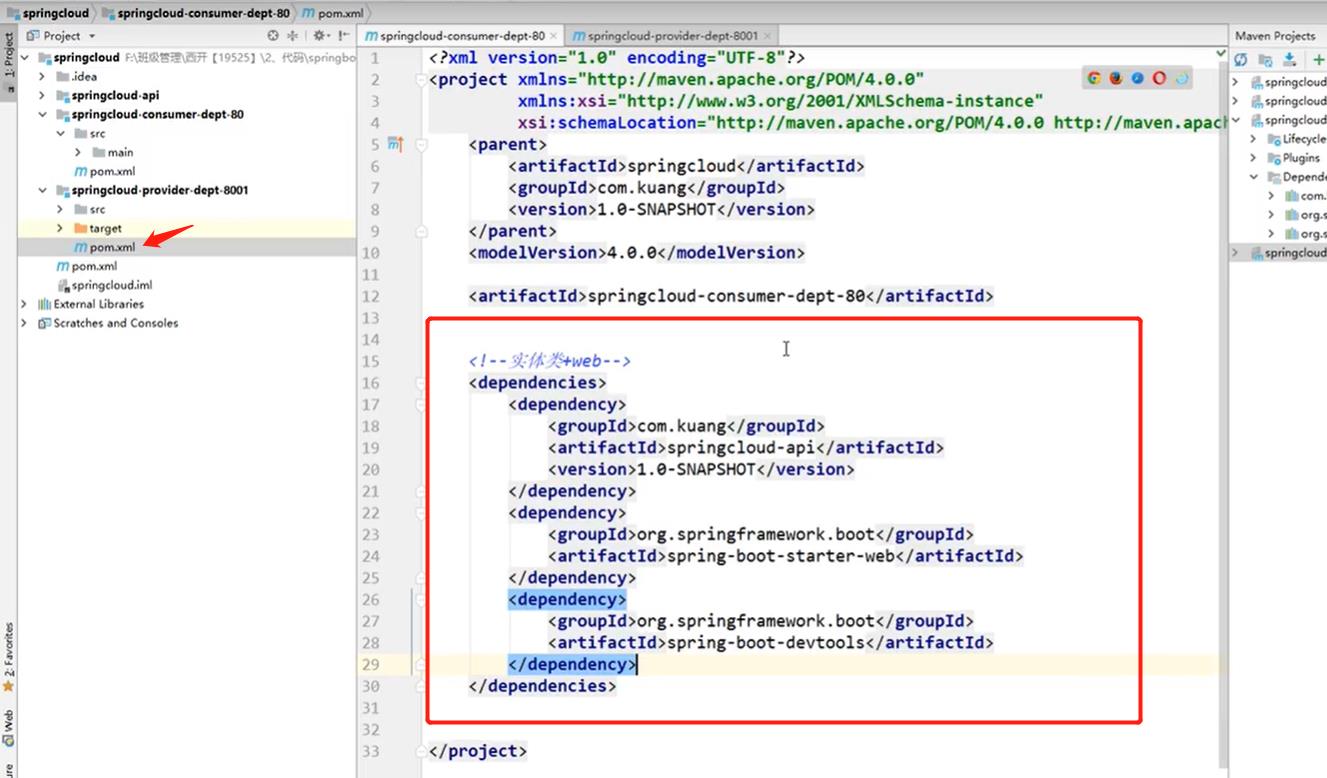
- 写配置文件application.yml
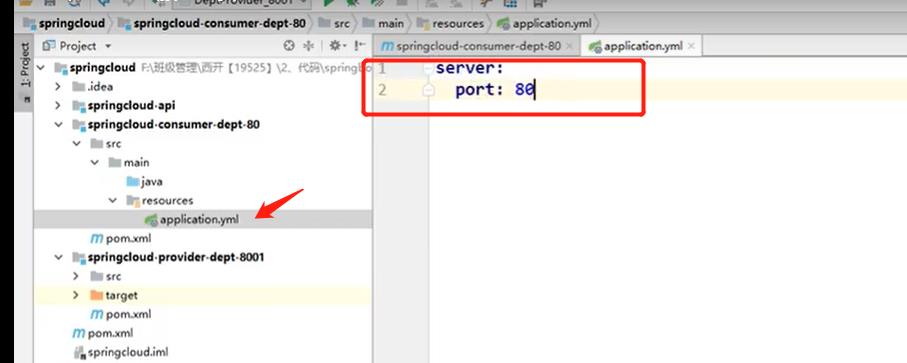
3. 配置类config
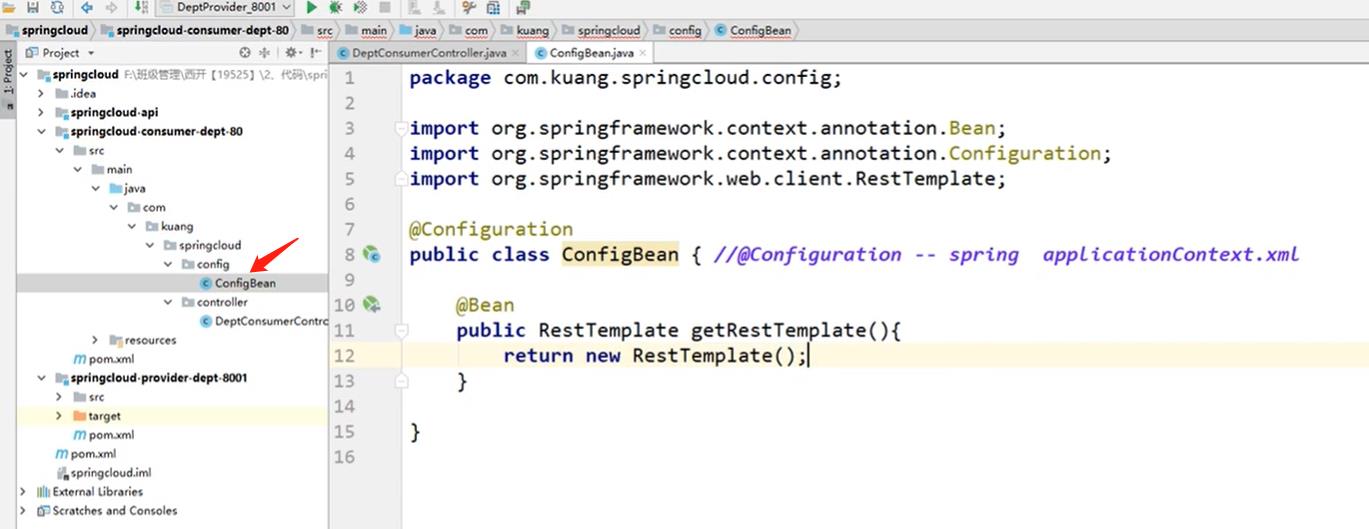
4. controller层
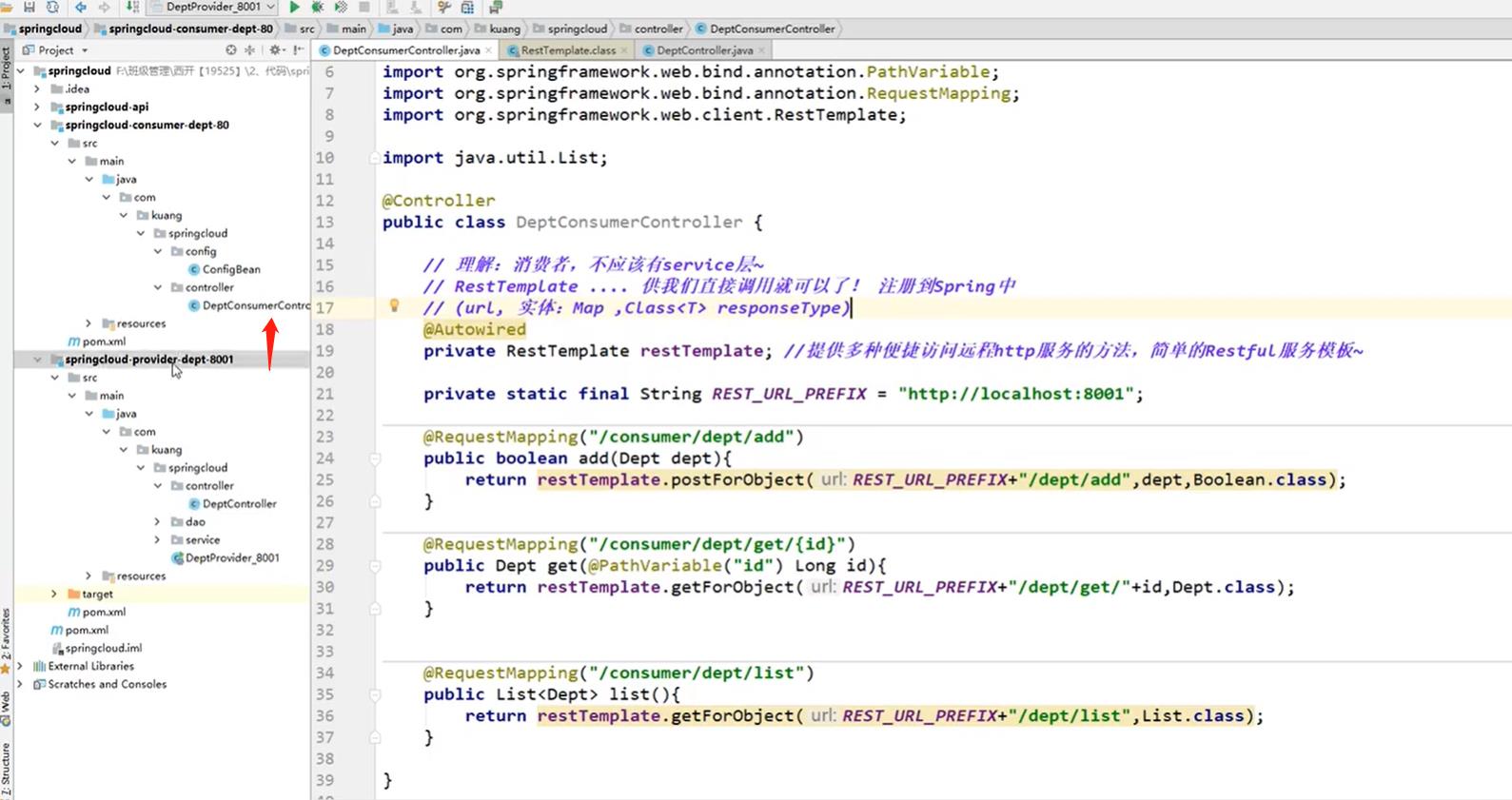
注意:这里的controller层的注解要使用@RestController注解,否则在测试客户端和提供者的时候出现问题

问题
5. 启动类
启动的时候,先第二个微服务启动也就是提供方先启动,然后到客户端启动
6. 测试结果
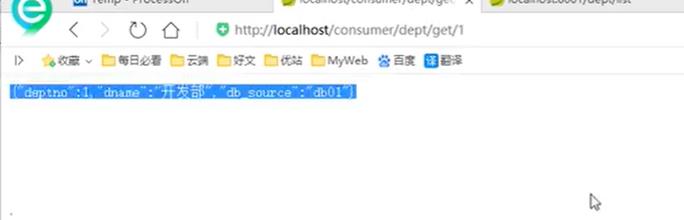
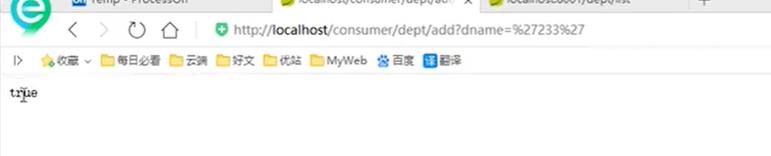
5、Eureka服务注册与发现
5.1、什么是Eureka

5.2、原理讲解
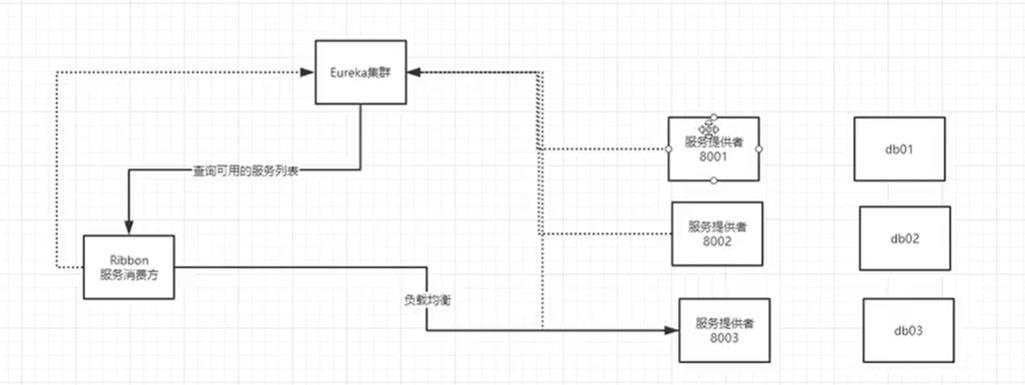
上面的SpringCloud例子中的客户端要想使用提供者的服务,就要带上提供者的URL,现在可以使用Eureka去做这件事
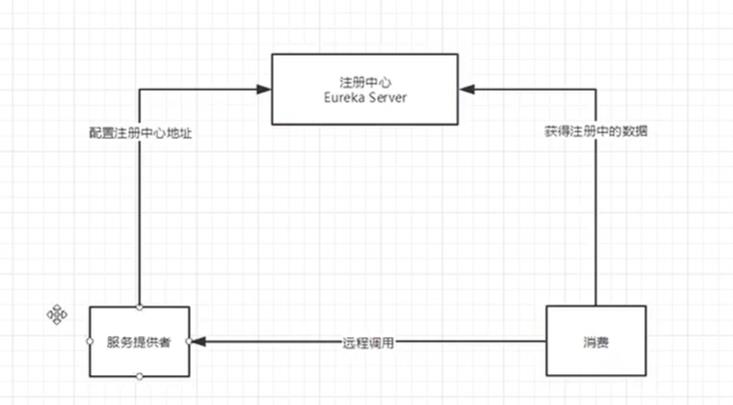
Eureka的基本架构

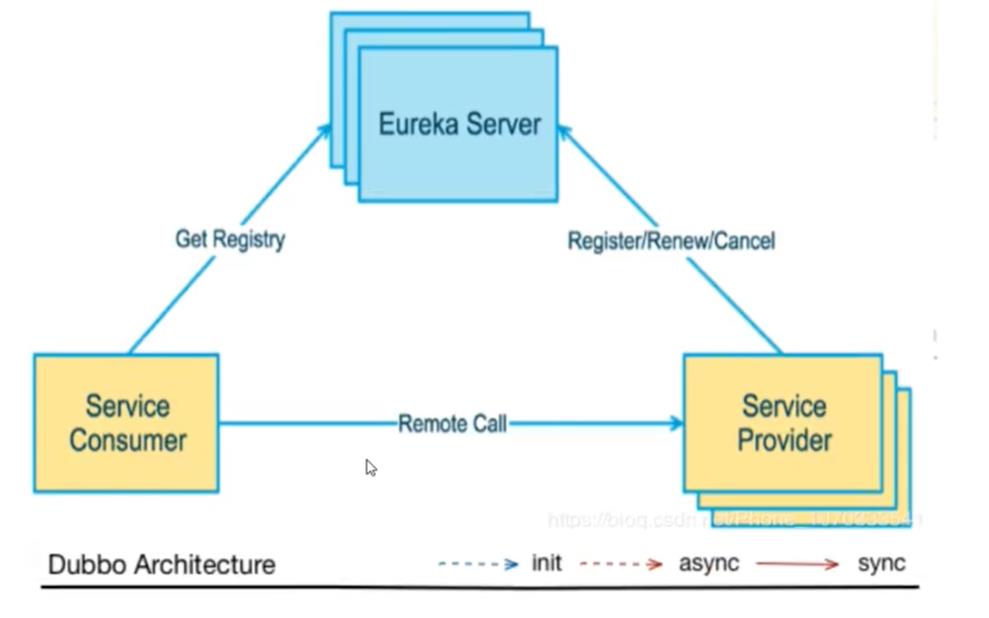
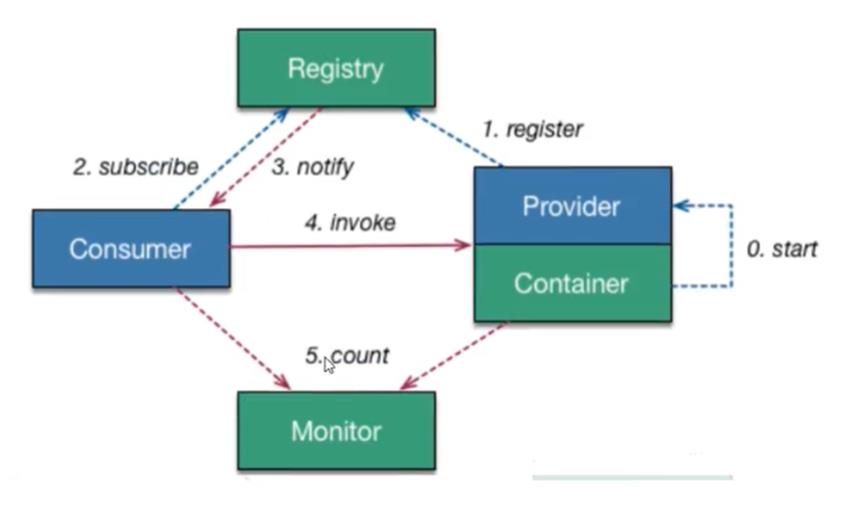

三大角色

5.3、配置集群环境1–服务注册(第四个子工程7001搭建Erueka(搭建Erueka))
在4.3父工程创建一个子工程作为第四个微服务
- 在父工程中创建一个maven项目,导入子工程需要的依赖
导入依赖
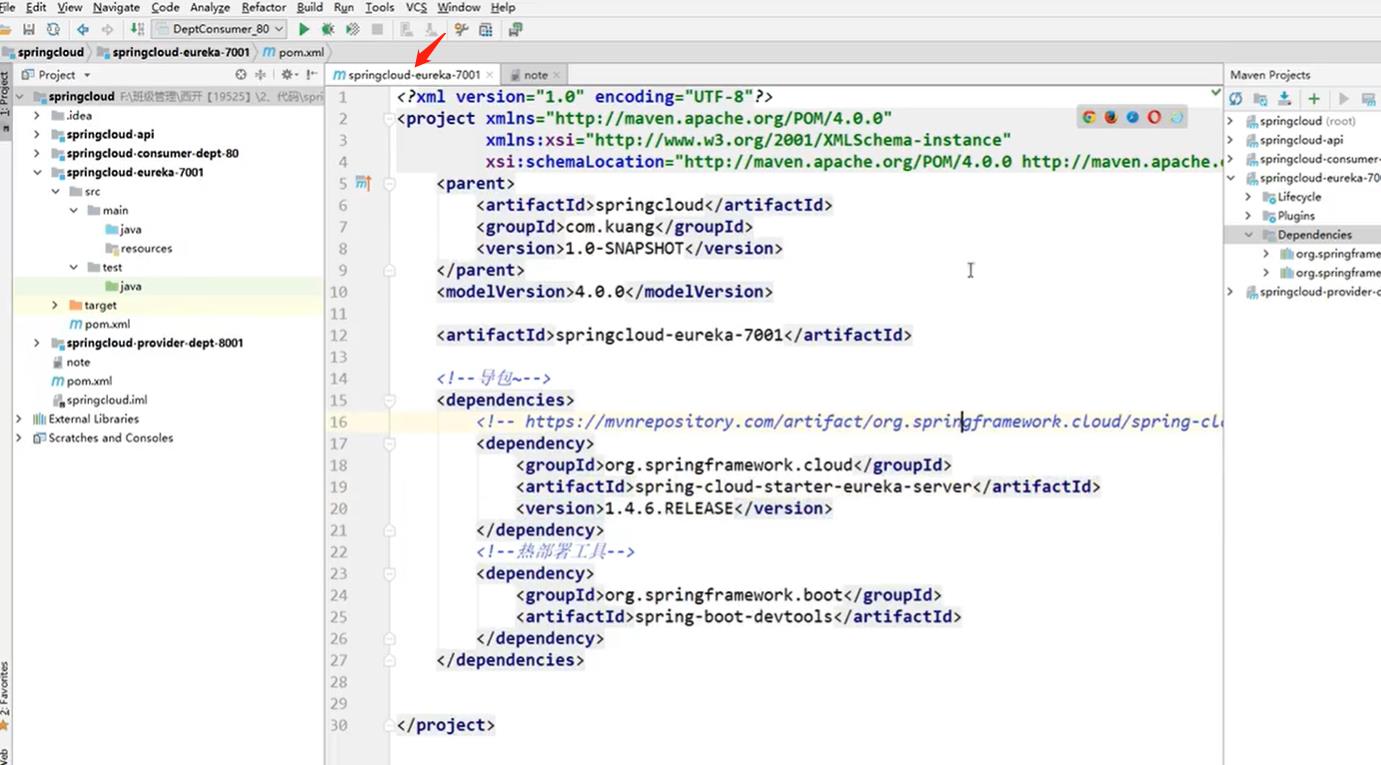
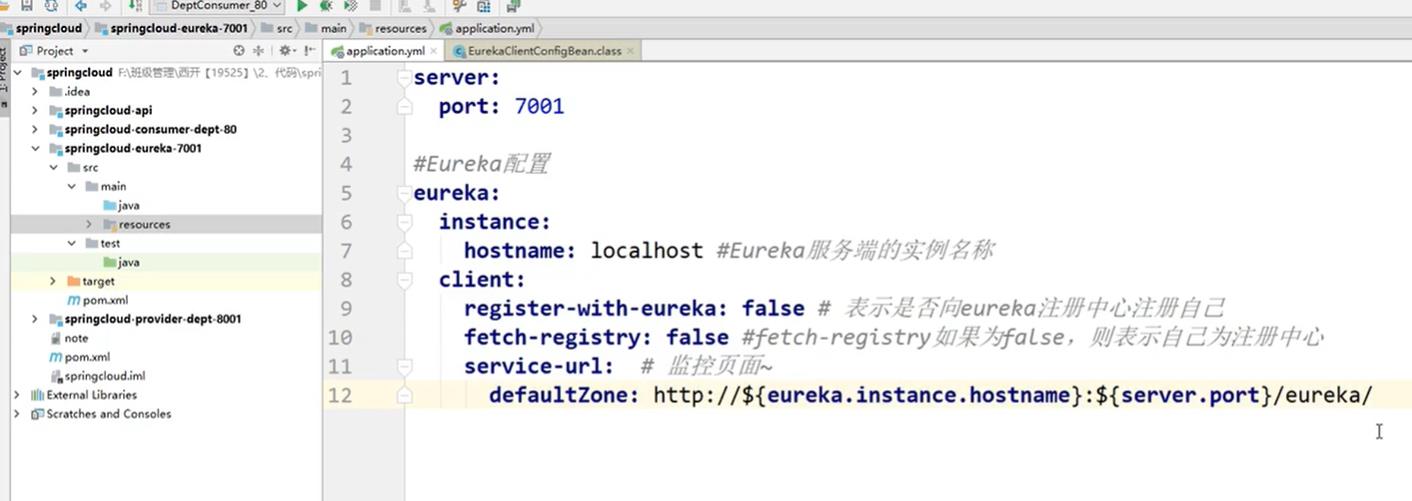
2. 写配置文件application.yml
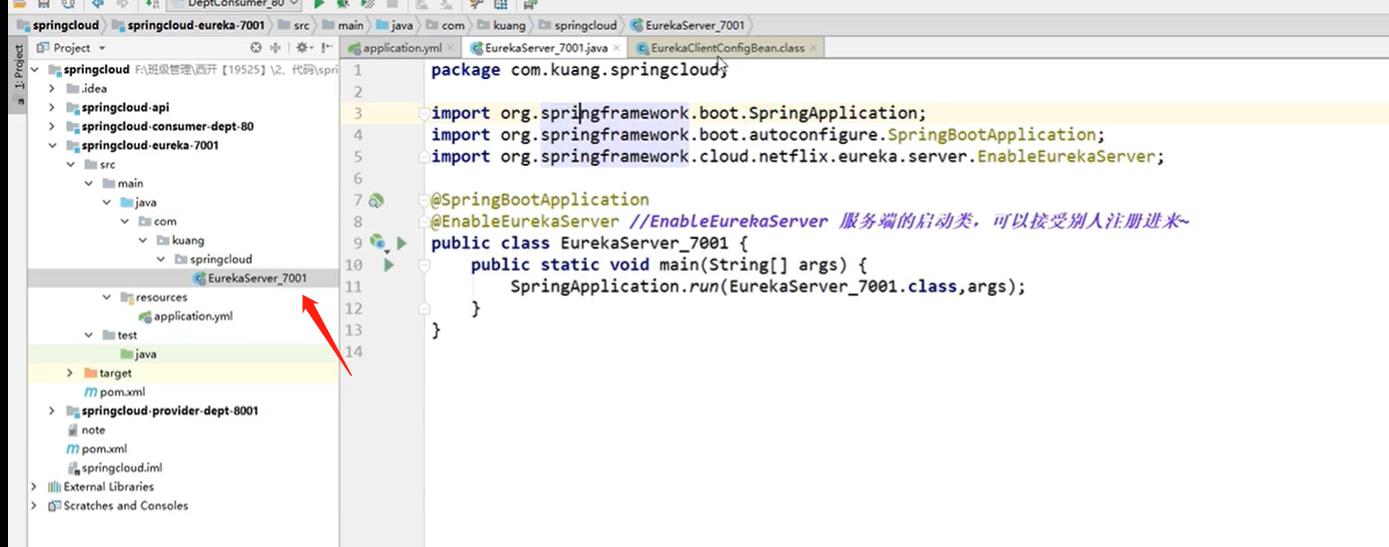
3. 注册启动类
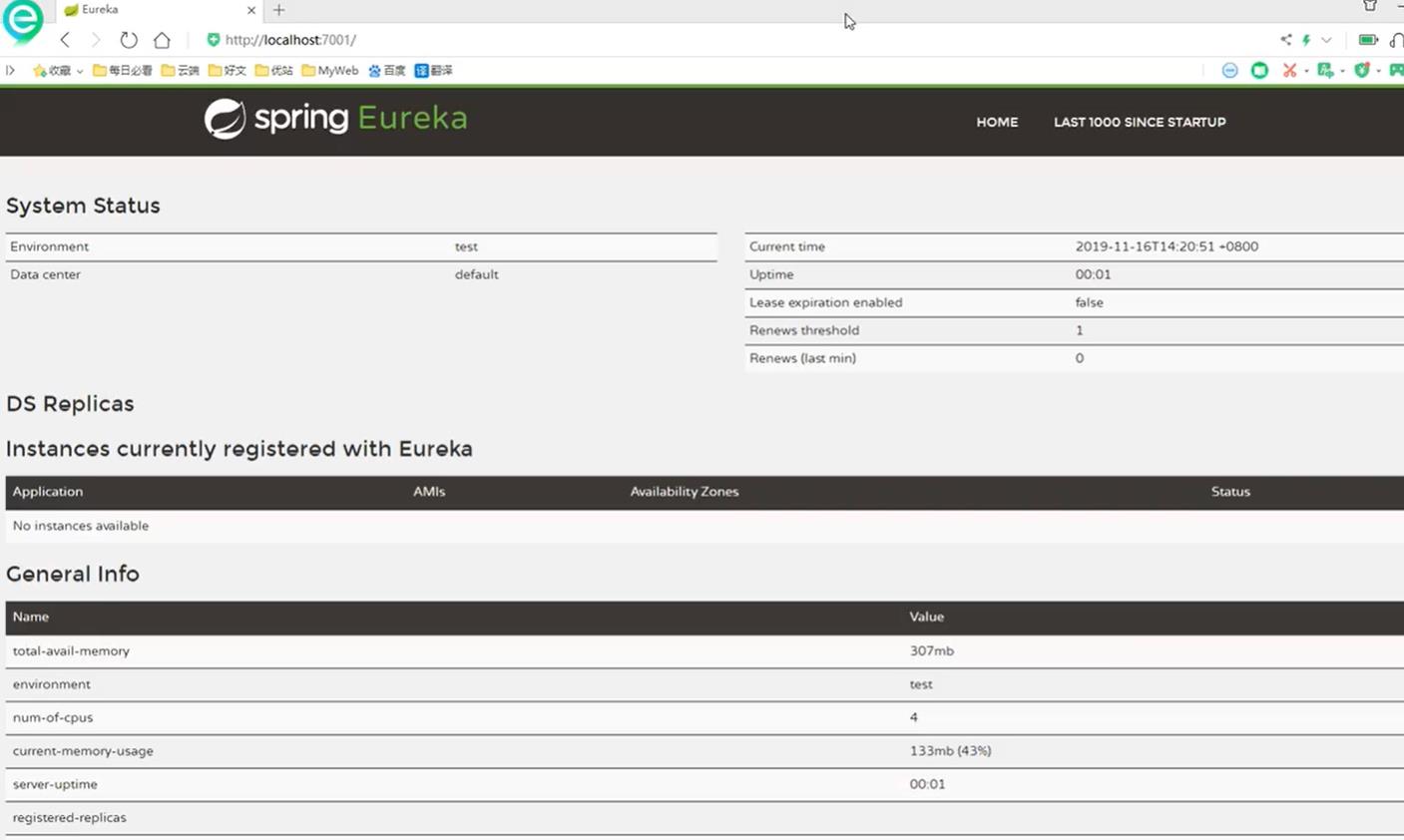
4. 测试结果
5.4、优化上面代码
-
在4.5小节中的pom.xml文件中添加Eureka依赖

-
在4.5小节中的yml文件中添加如下代码
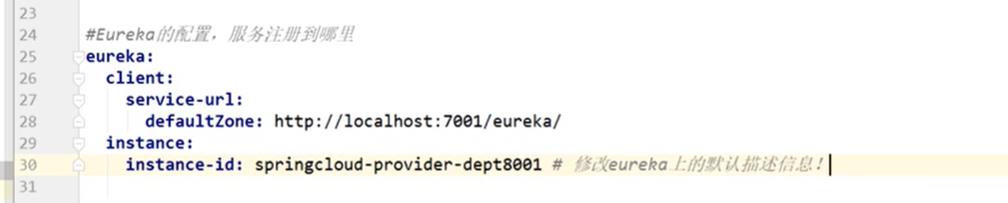
-
在4.5小节中的启动类中修改代码如下
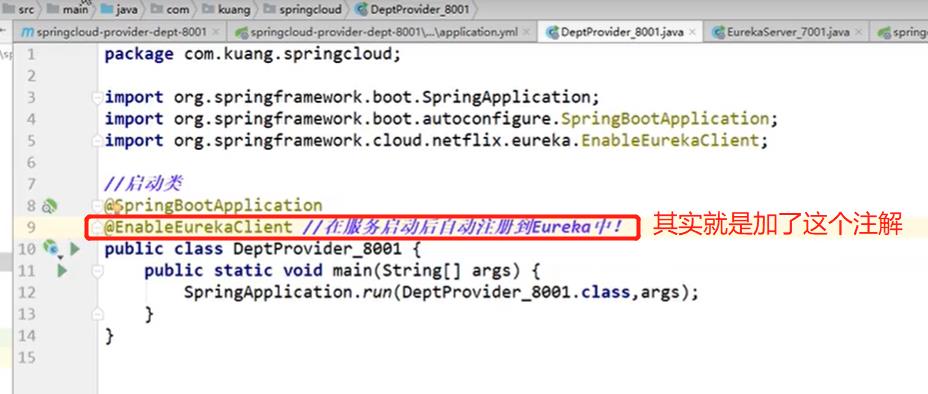
-
先启动EureKa启动类再启动提供服务的启动类
-
测试结果
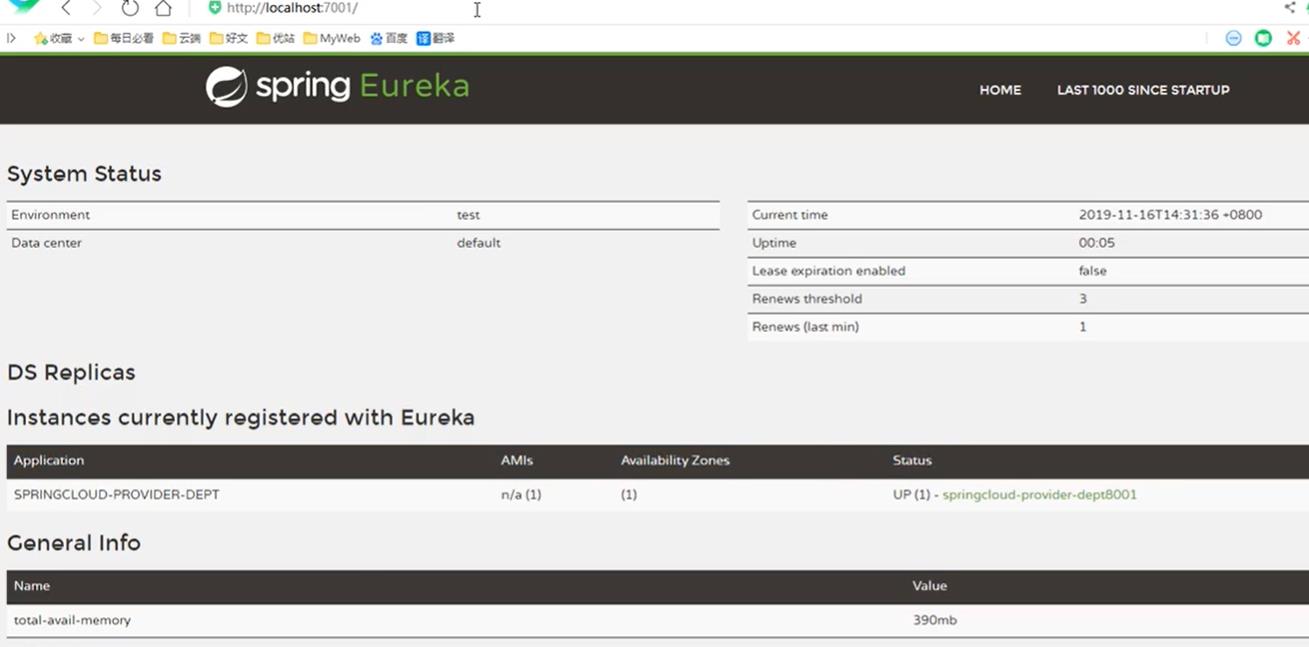
-
服务加载信息没有,需要去配置
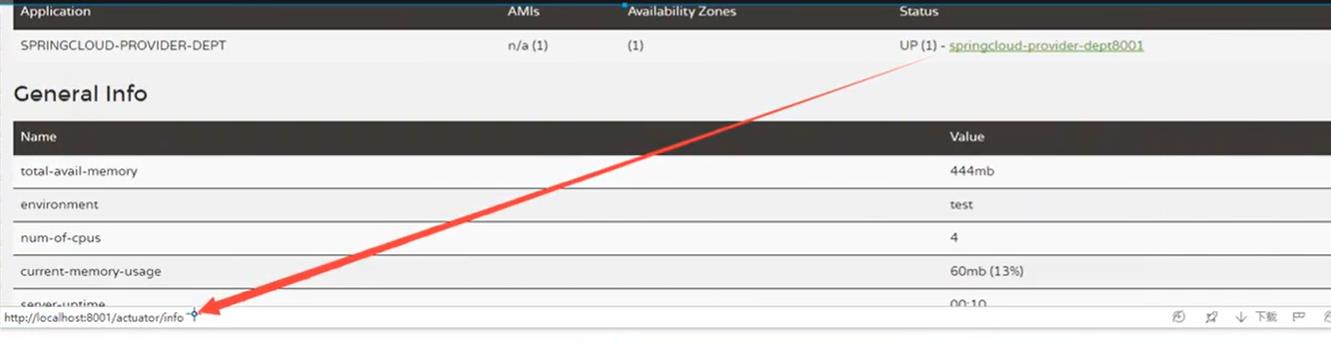
-
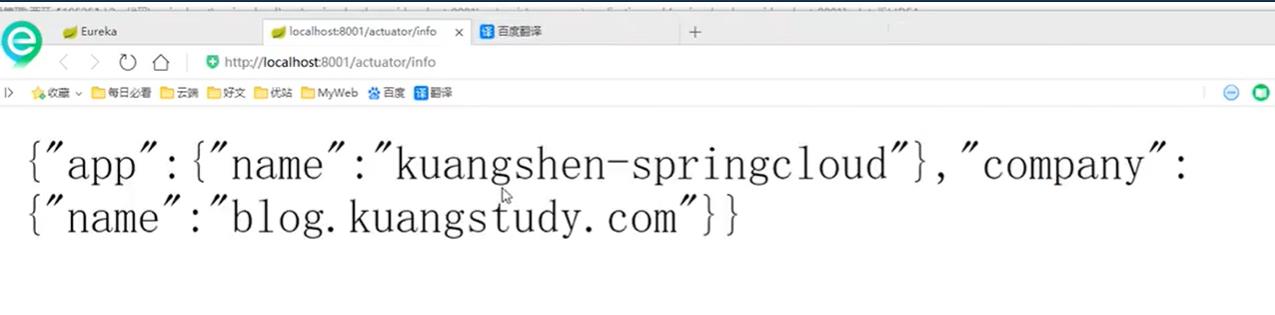
配置服务加载信息
在4.5小节的提供服务那里的pom文件中加入以下依赖:

然后在4.5小节的提供服务那里的yml文件中添加如下信息:

-
重新启动,测试结果
5.5、自我保护机制

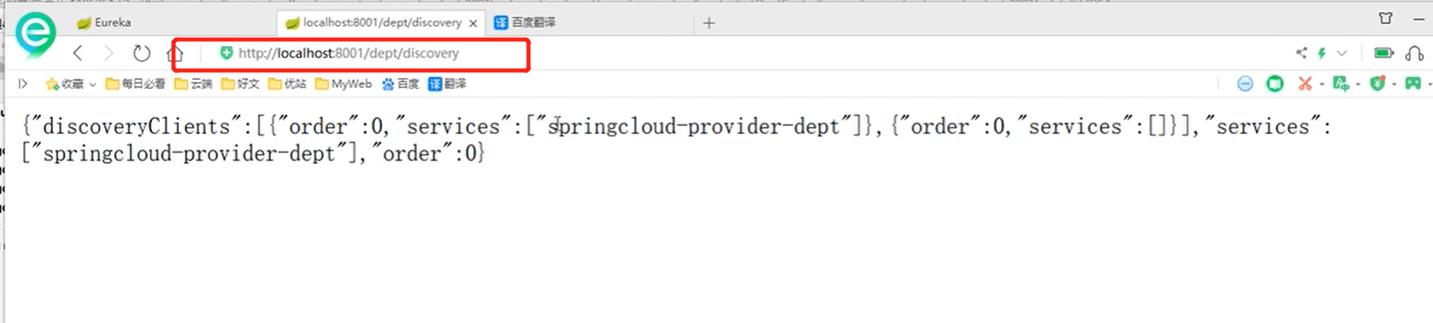
5.6、服务发现Discovery
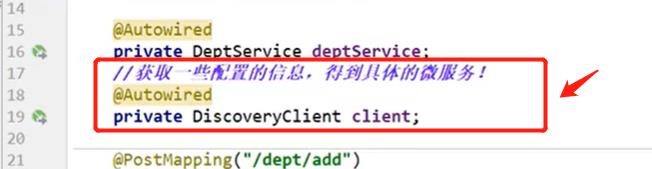
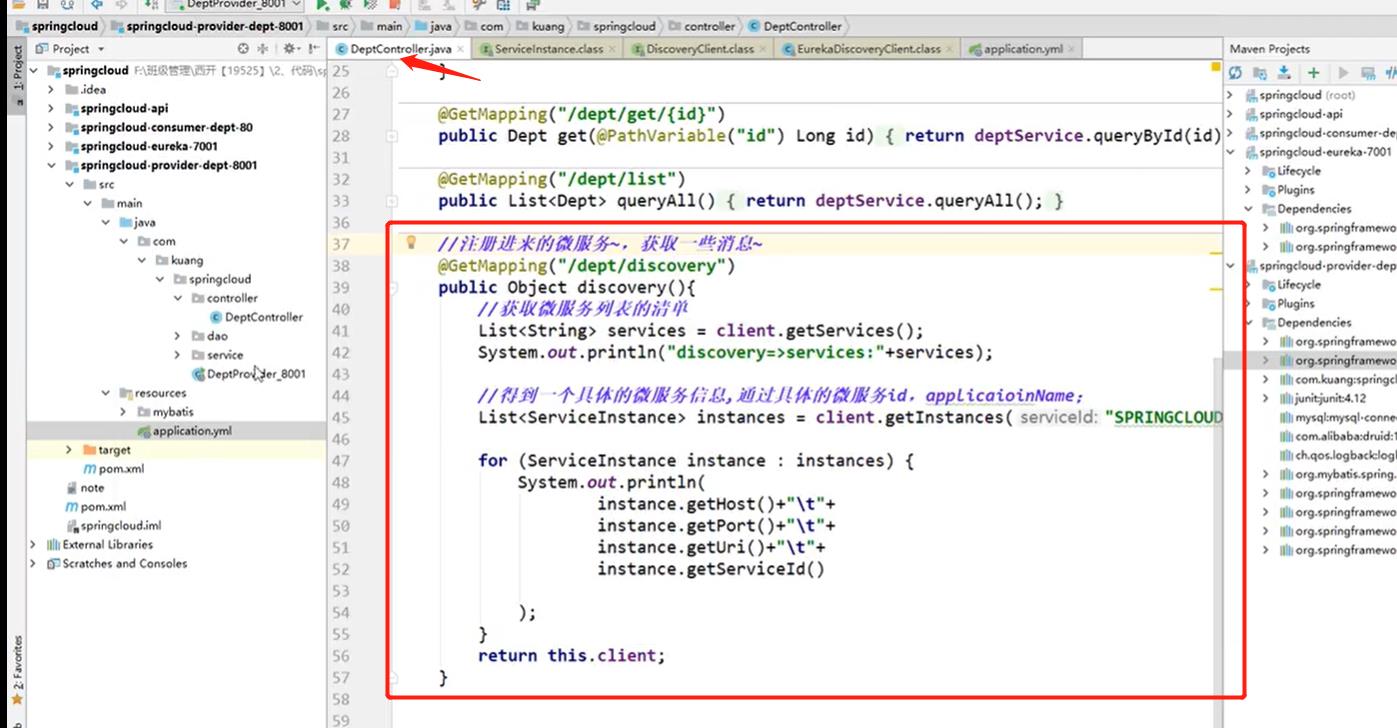
在4.5的提供服务中添加Discovery
- 4.5的controller层添加如下代码
- 在4.5的启动类添加注解使上面的修改生效
- 启动4.5的服务
- 测试结果
6、集群环境配置(注册中心)
实现几个集群直接可以互通
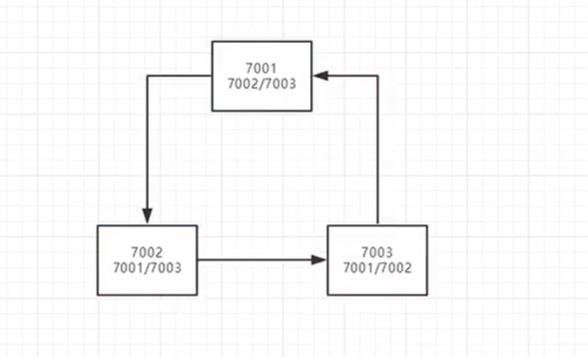
可以将localhost改成对应的集群名字:
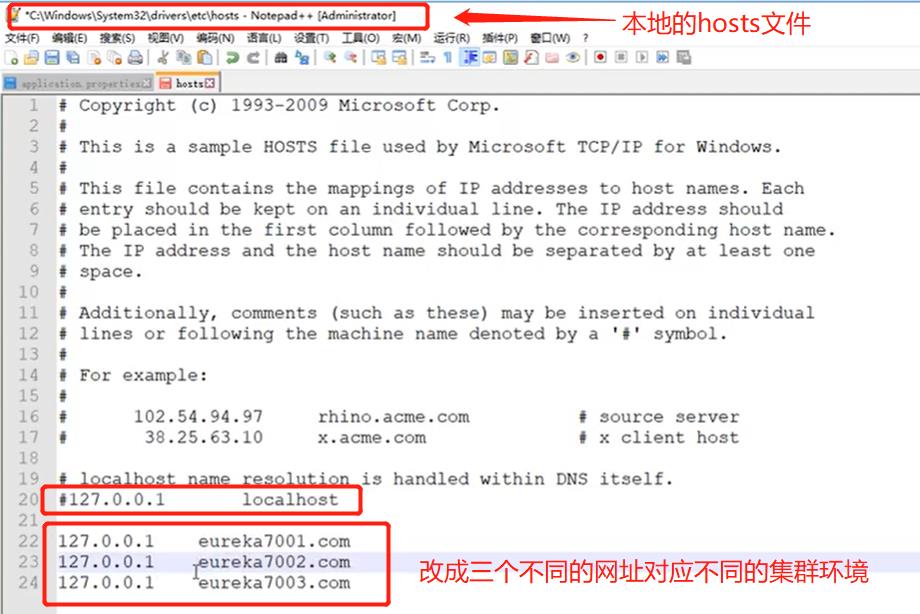
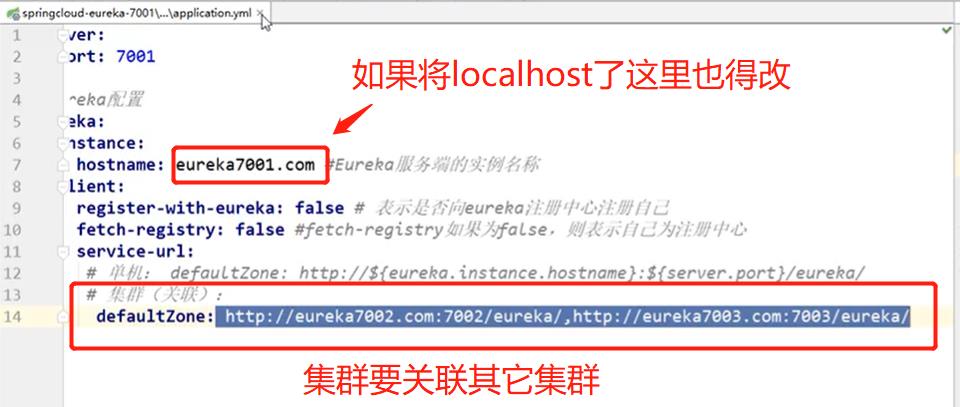
修改了localhost之后要修改5.3小节中集群1中的yml配置文件
6.1、配置集群环境2(第五个子工程7002)
在4.3父工程创建一个子工程作为第五个微服务
- 在父工程中创建一个maven项目,导入子工程需要的依赖
导入依赖:跟上面的集合环境的一样,所以复制一下就可以了
2. 写配置文件application.yml
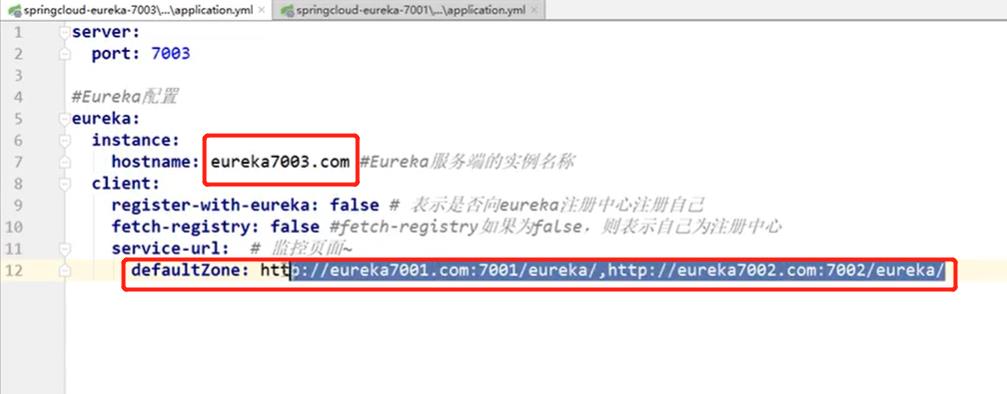
- 注册启动类(改一下类名就可以了)
6.2、配置集群环境3(第六个子工程7003)
在4.3父工程创建一个子工程作为第六个微服务
- 在父工程中创建一个maven项目,导入子工程需要的依赖
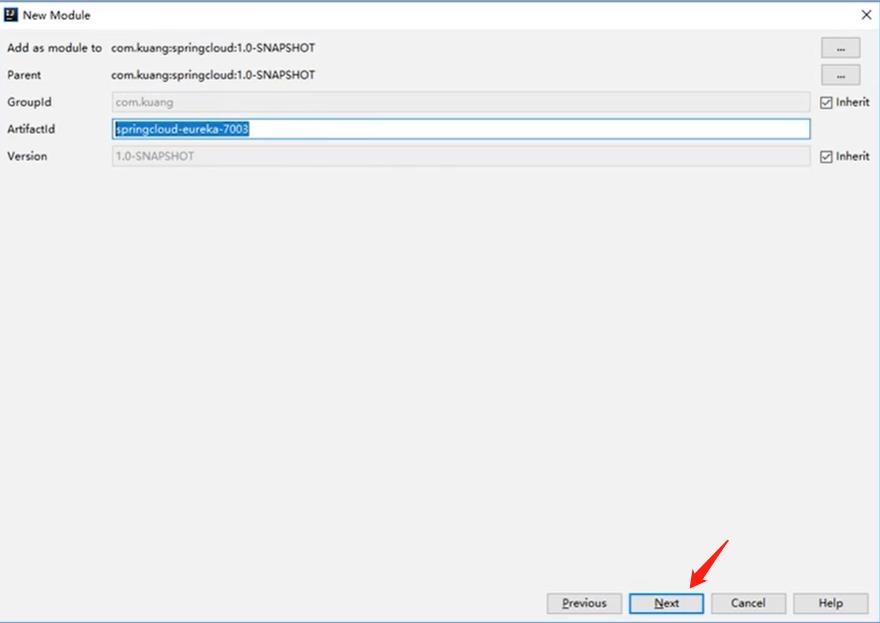
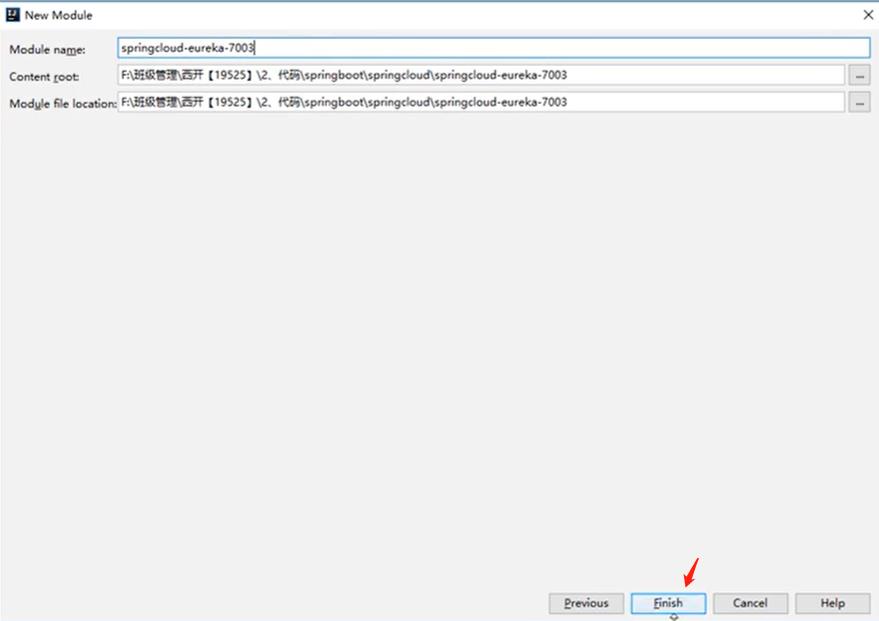
导入依赖:跟上面的集合环境的一样,所以复制一下就可以了
2. 写配置文件application.yml(跟集群环境1一样,直接复制过来)
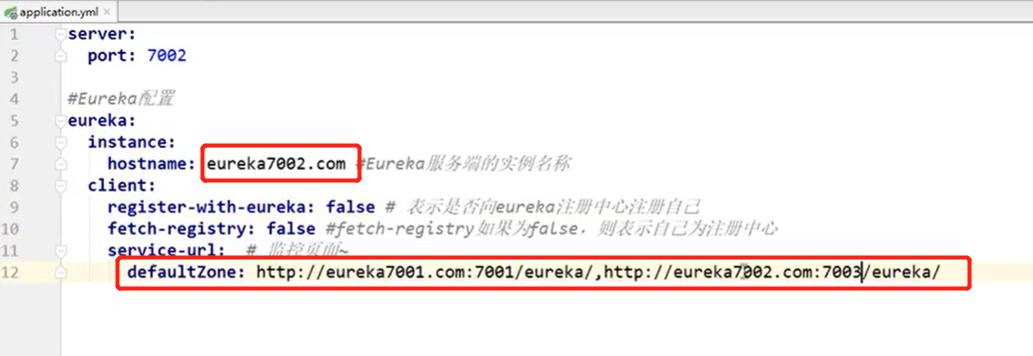
3. 注册启动类(改一下类名就可以了)
修改好三个集群环境之后还得在提供服务的那个子工程中将三个集群服务都注册,修改4.5小节中的yml配置文件如下:
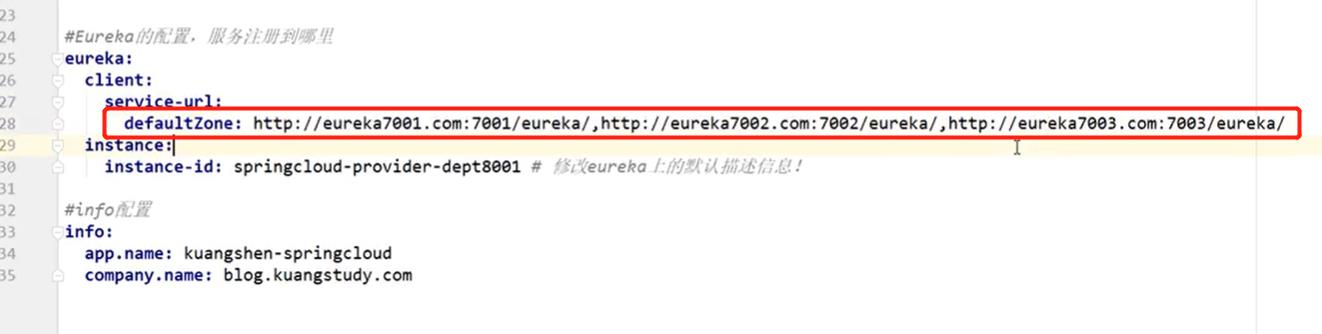
4. 启动集群环境1,然后启动集群2,然后启动集群3,测试结果
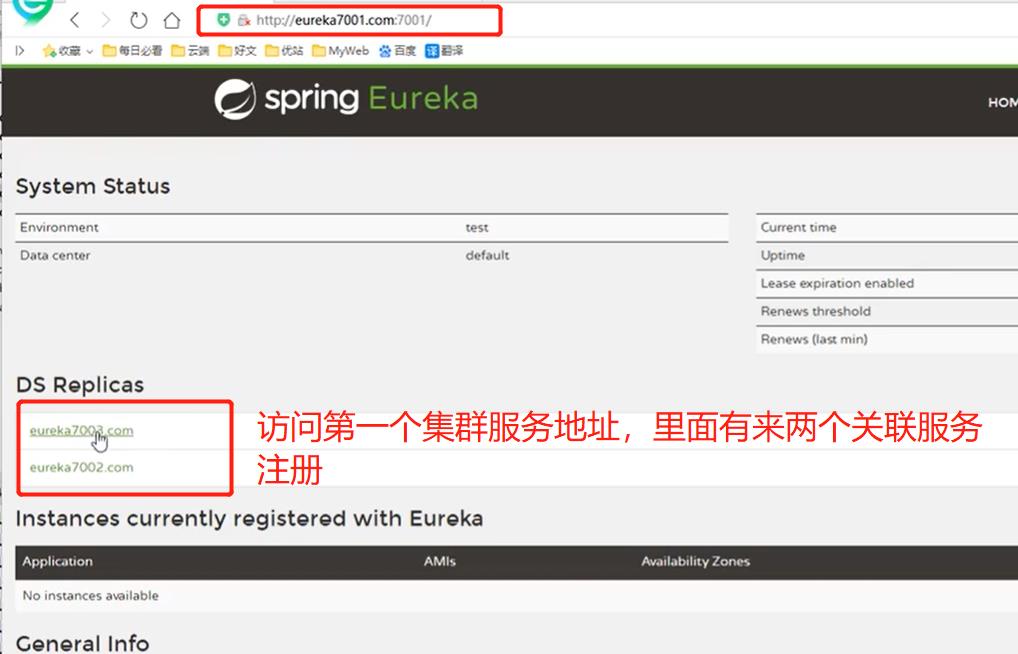
5. 启动提供服务子工程
如果第三个服务崩了,因为在第一个和第二中都关联了第一个,那么访问第一个或者第二个都可以进入第三个服务中,因此即使他崩了也不至于导致整个系统全部崩掉。
7、Eureka与Zookeeper对比
7.1、ACID和CAP原则
回顾CAP原则

ACID是什么?

CAP是什么?


7.2、Zookeeper保证的是CP


7.3、Eureka保证的是AP

因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪
8、负载均衡与Ribbon
8.1、ribbon是什么

8.2、负载均衡
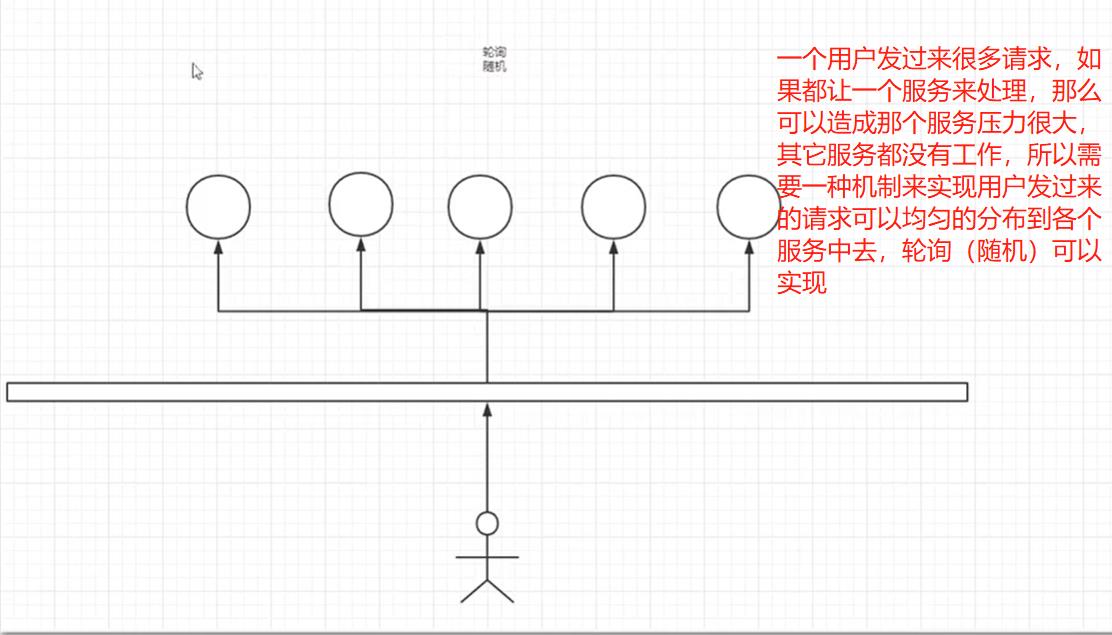
8.3、ribbon能干嘛

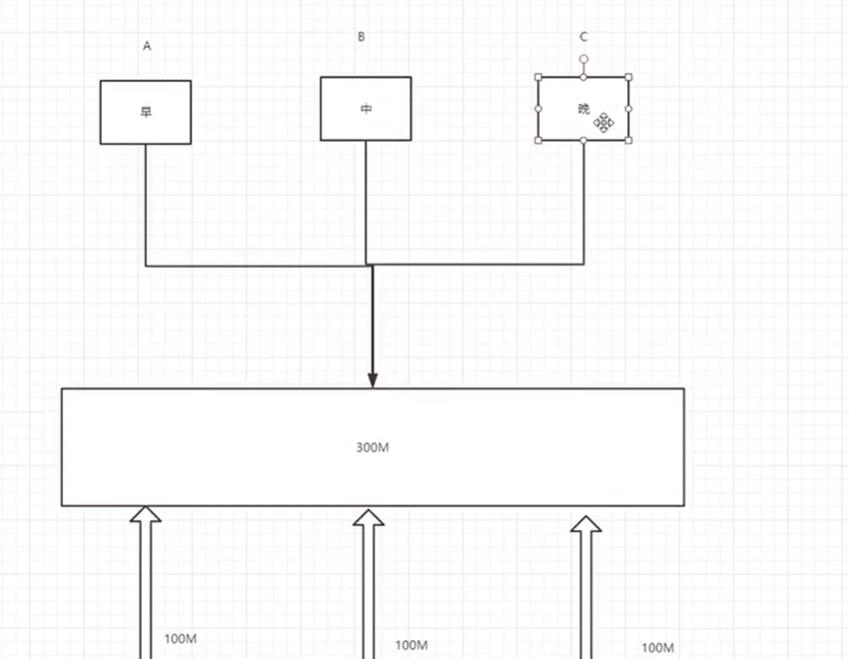
LVS作用之小例子分析:
小区中有些早上上网,有些中午上网还有的晚上上网,ABC三个小区中,A区一般早上上网,B区一般中午上网,C区一般晚上上网,如果网线是直接接到客户端,每个小区都是100m,早上的时候,BC取使用0m,A区使用超过100M,但是他连接的只有100M,所以最多也只能是100M,所以上网速度就差了。
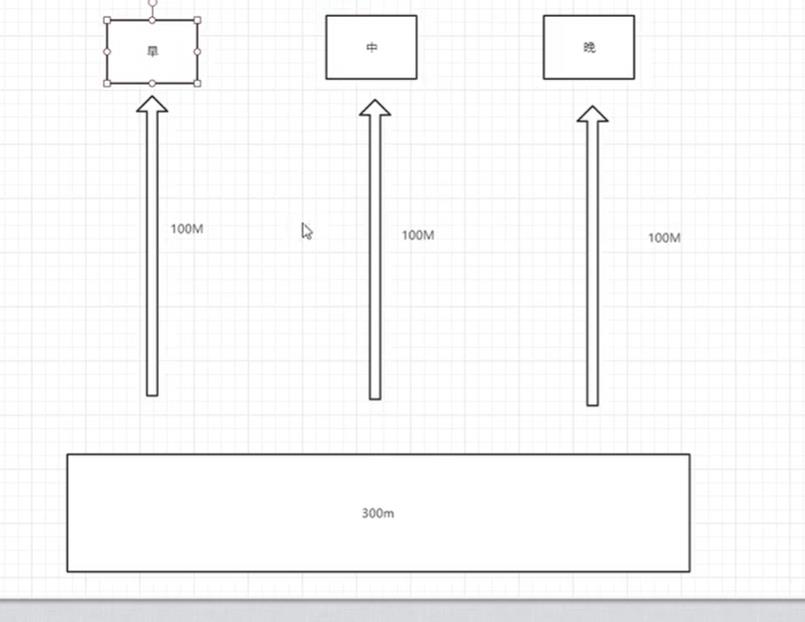
提高效率
如果加了一个中间商,接了一条300M的中间商,小区都是直接接中间商,那么这几个小区就加起来使用300M,如果BC没有上网的时候,A区上网速度就最高可以达到300M,速度大大提升了。
8.4、体验Ribbon
-
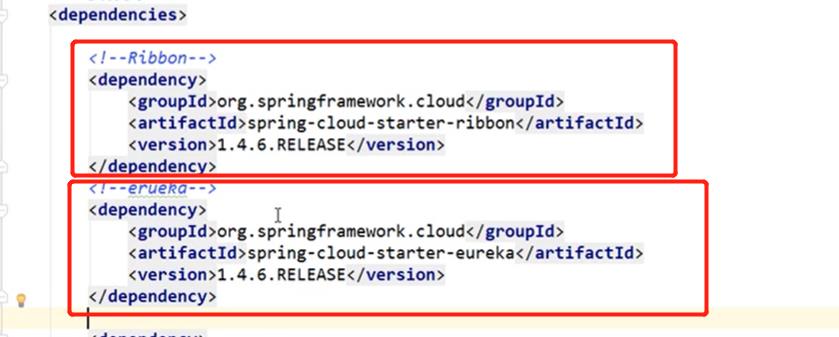
修改4.6第三个子工程中的pom文件中添加如下依赖:
-
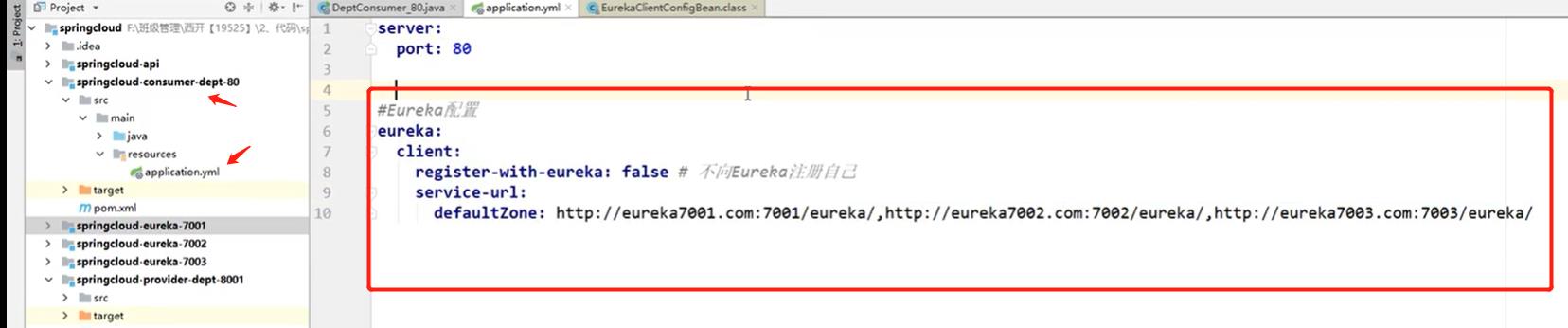
修改4.6第三个子工程中的yml配置文件如下:
-
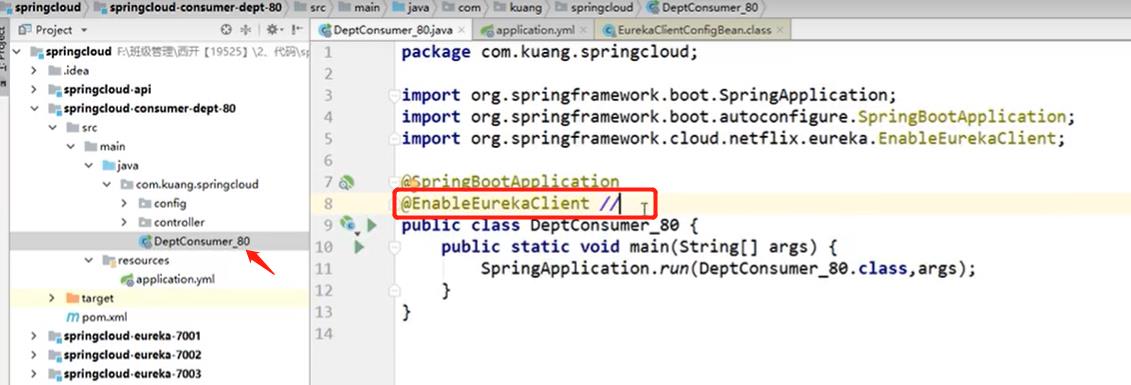
修改4.6第三个子工程中的启动类加上一个注解:
-
修改4.6的第三个子工程中的config类:
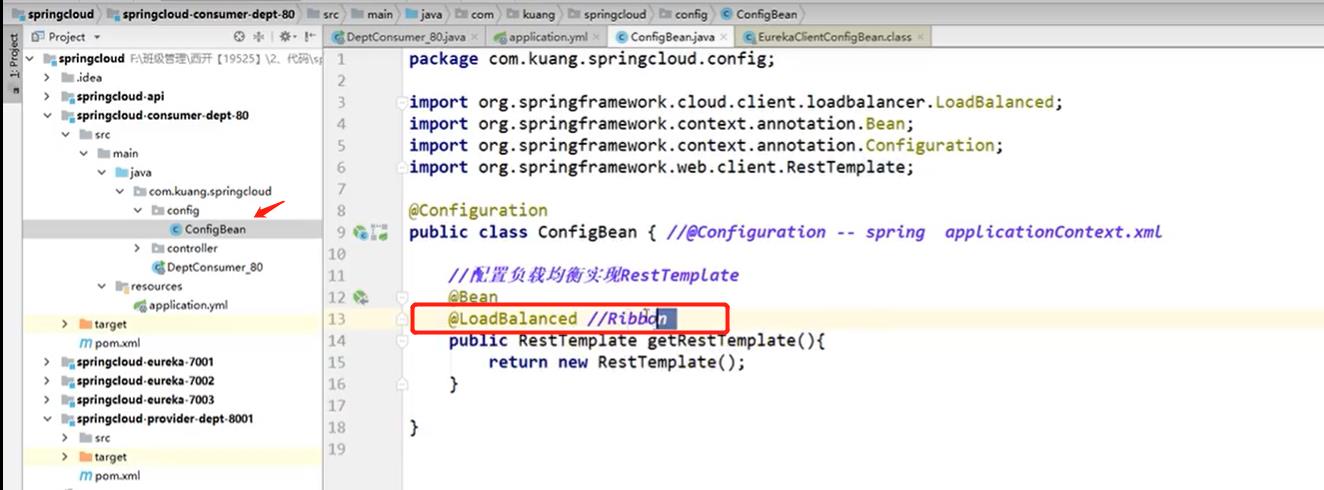
-
修改4.6第三个子工程中的controller层代码如下:
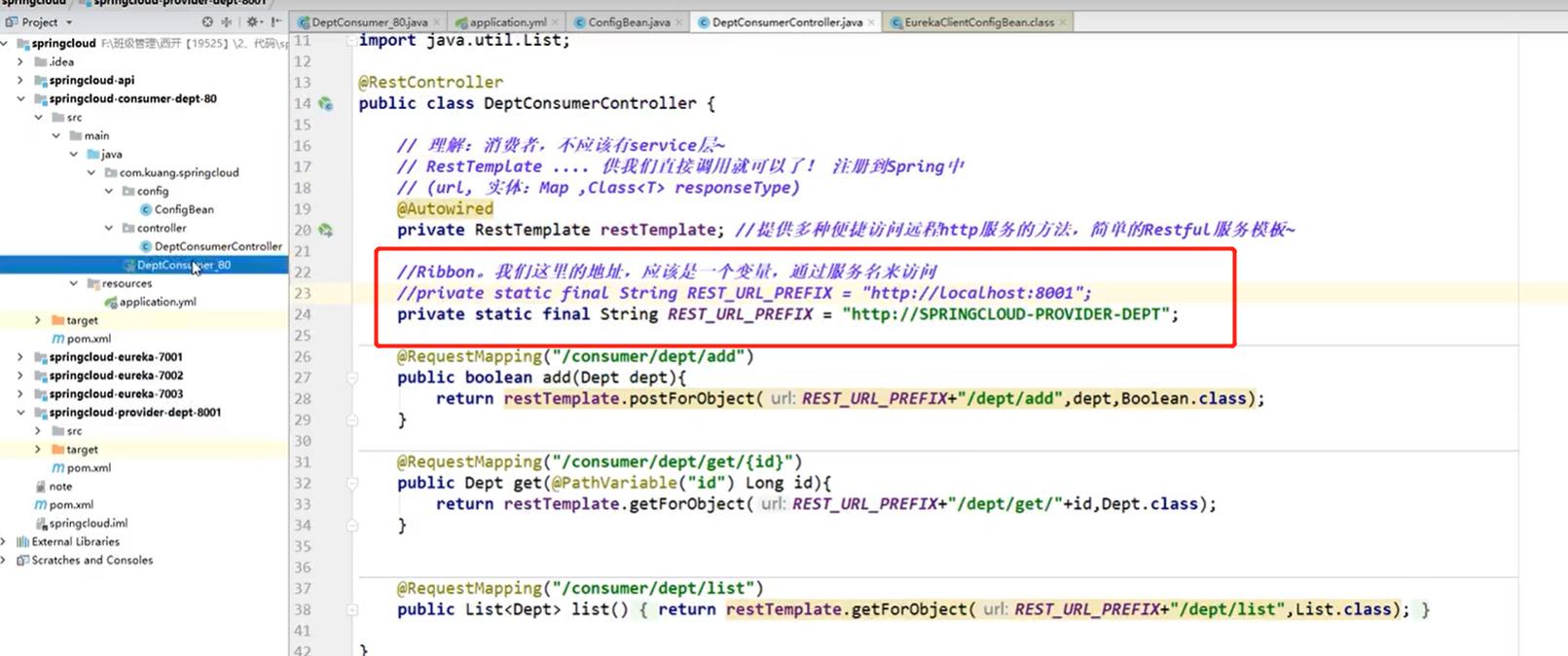
-
测试4.6中的启动是否有问题:可以访问没有问题
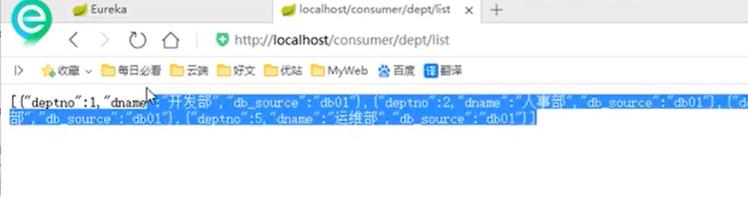
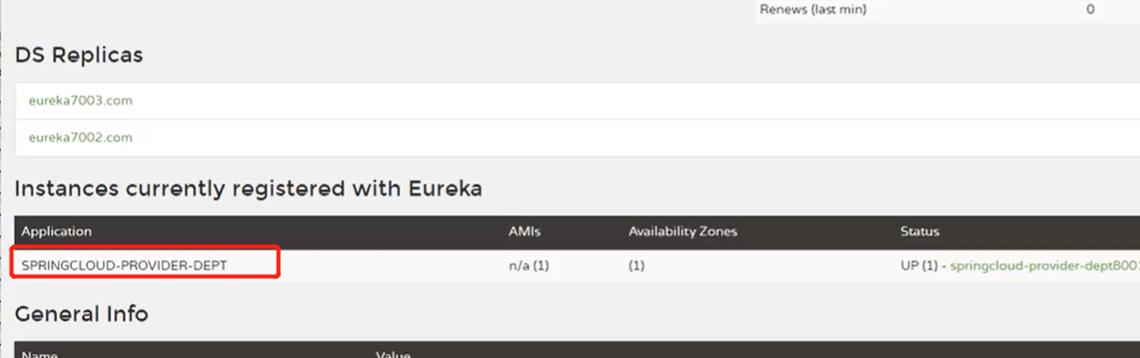
Ribbon和Eureka整合以后,客户端可以直接调用,不用关心IP地址和端口号
小结
8.5、使用Ribbon实现负载均衡
在父工程中创建第七、八个子工程作为微服务,也是第二个提供服务2(8002),第三个提供服务3(8003端口)
- 在父工程中创建一个maven项目,导入子工程需要的依赖
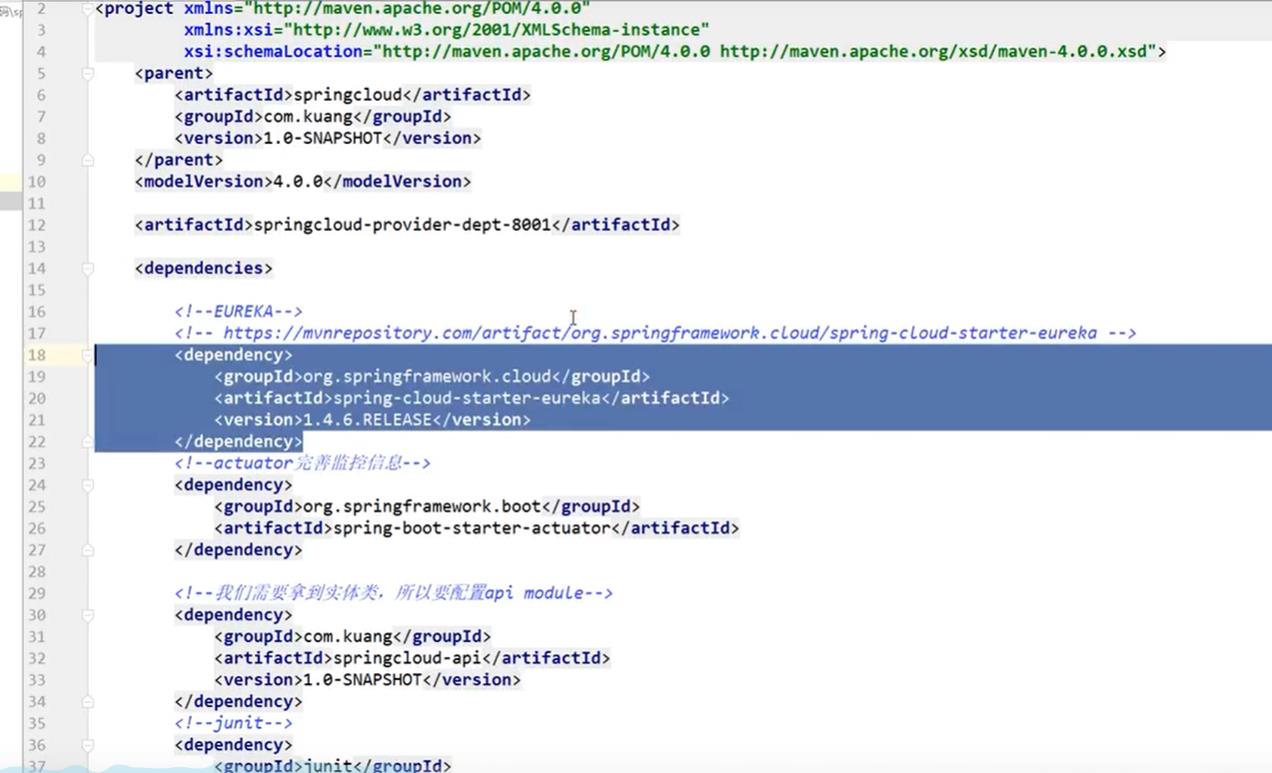
导入依赖:将第一个提供服务者的依赖全部复制过来8002和8003中

-
跟第一个提供服务者一样创建数据库db02,db03,连接数据库
-
分别在db02,db03中创建表,插入数据(可以跟db01数据一样的)
-
将第一个提供服务者的yml配置文件拷贝到8002,8003这两个提供服务者的resources文件夹下。
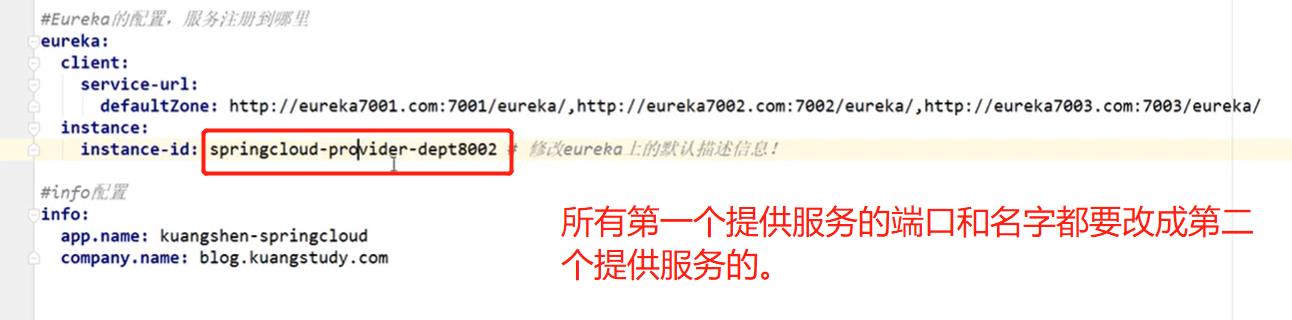
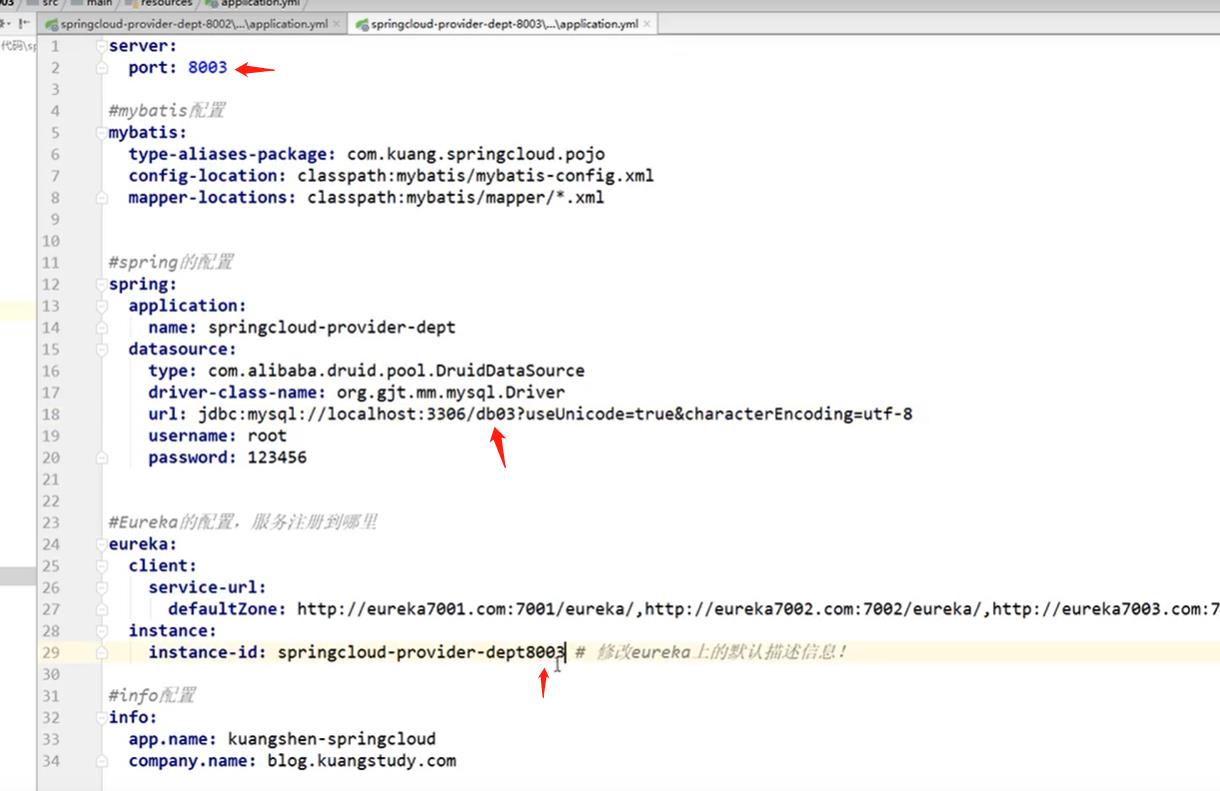
-
将第一个提供服务的mybatis文件夹都拷贝到第二个、第三个服务那里。拷贝过来不需要修改里面的内容
-
将第一个提供服务的com.kuan.springcloud文件夹下的内容都拷贝到第二个,第三个提供服务那里,也就是controller,dao,service和启动类,只需要修改启动类中的有关第一个提供服务者的都改成第二,第三个对应的。
-
测试结果,启动集群1,也就是上面的7001端口对应的,要体验三个服务,所以不敢启动太多集群,怕电脑撑不了。然后将提供服务者三个都启动起来(如果启动不了就启动两个吧)因为在每一个提供服务都是往三个集群里注册服务的,没有开集群2,3也就是7002,7003,所以会有报错,但是没影响其他的,其他集群崩了就崩了,7001是可以进去的。如果要不报错那就得启动所有的集群
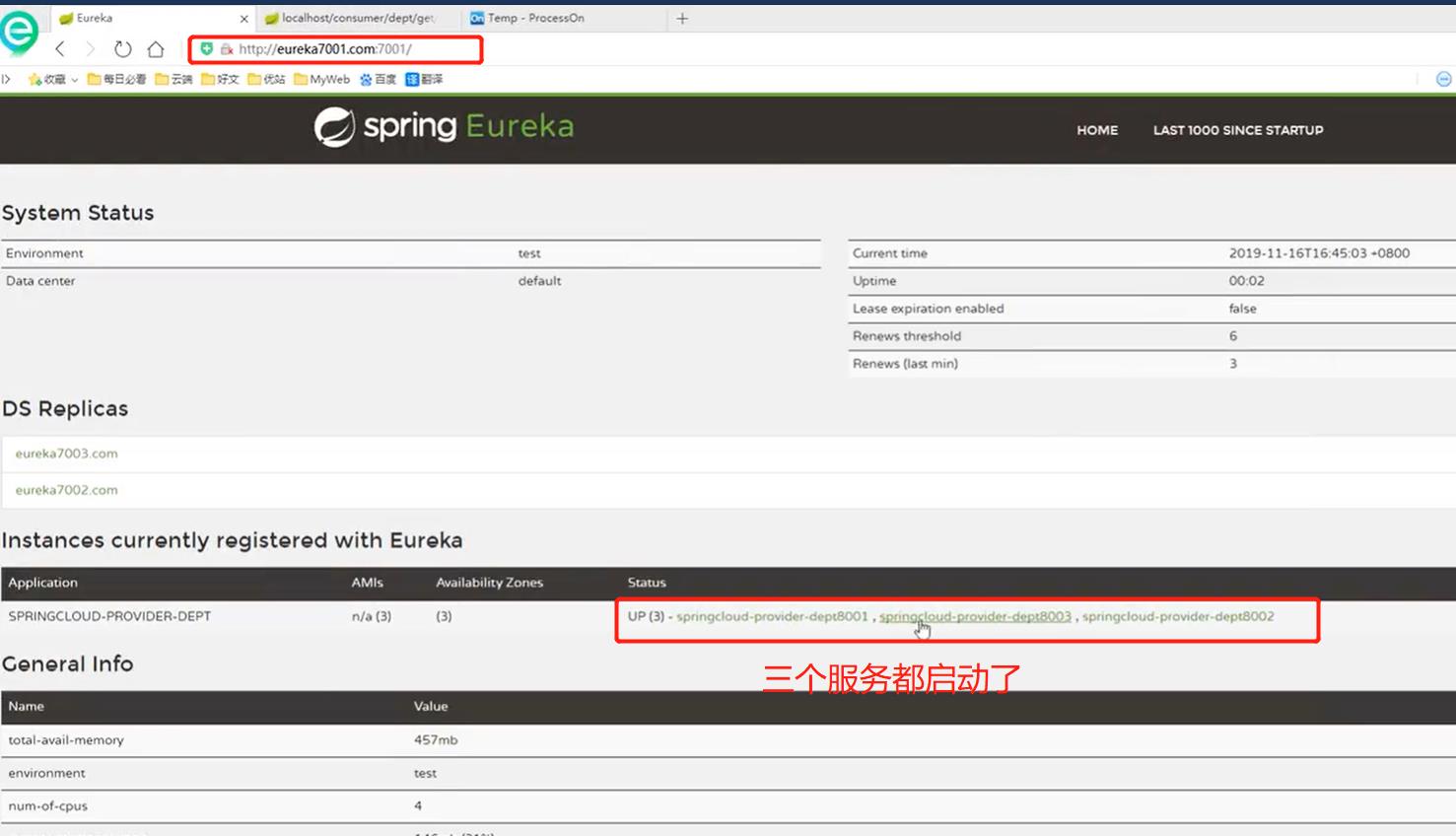
-
启动客户端也即是80那个端口号的,访问看结果
第一次访问结果:

第二次访问结果:
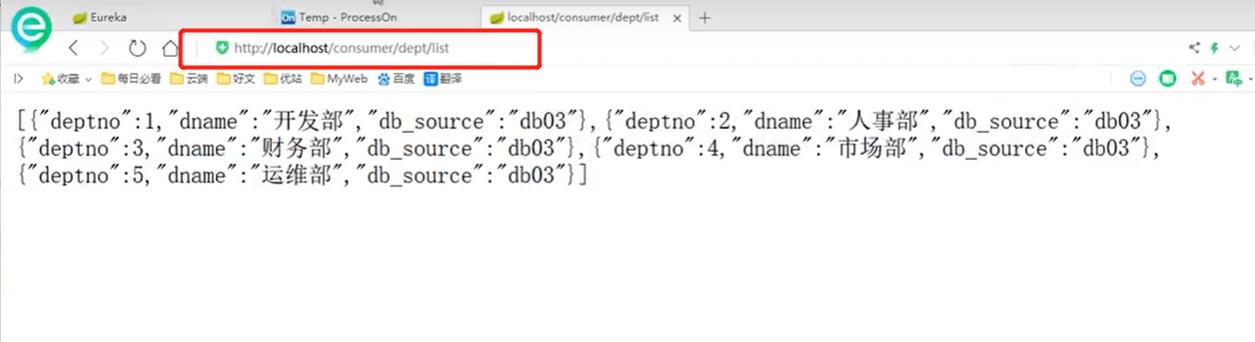
第三次访问结果:

负载均衡总结:一个集群环境开了三个服务,那么客户端发过来请求的时候,会使用ribbon默认负载均衡算法–轮询来实现去访问数据
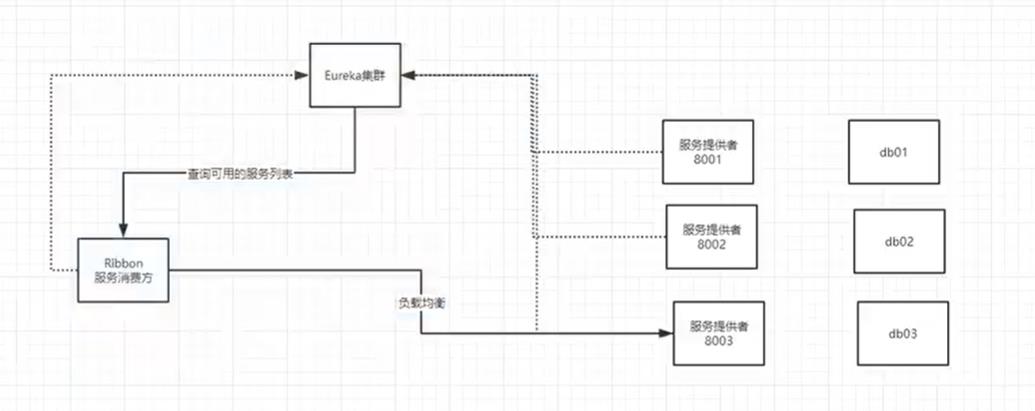
8.6、自定义负载均衡算法
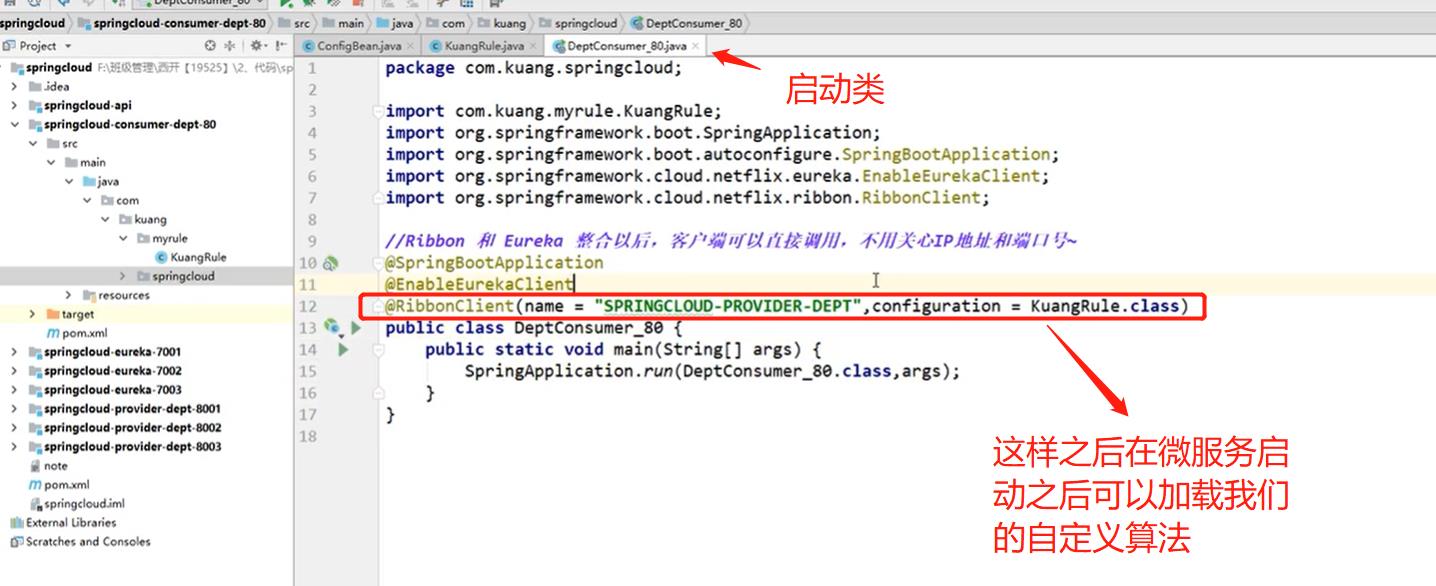
在客户端4.6小节中的config类中自定义负载均衡的算法
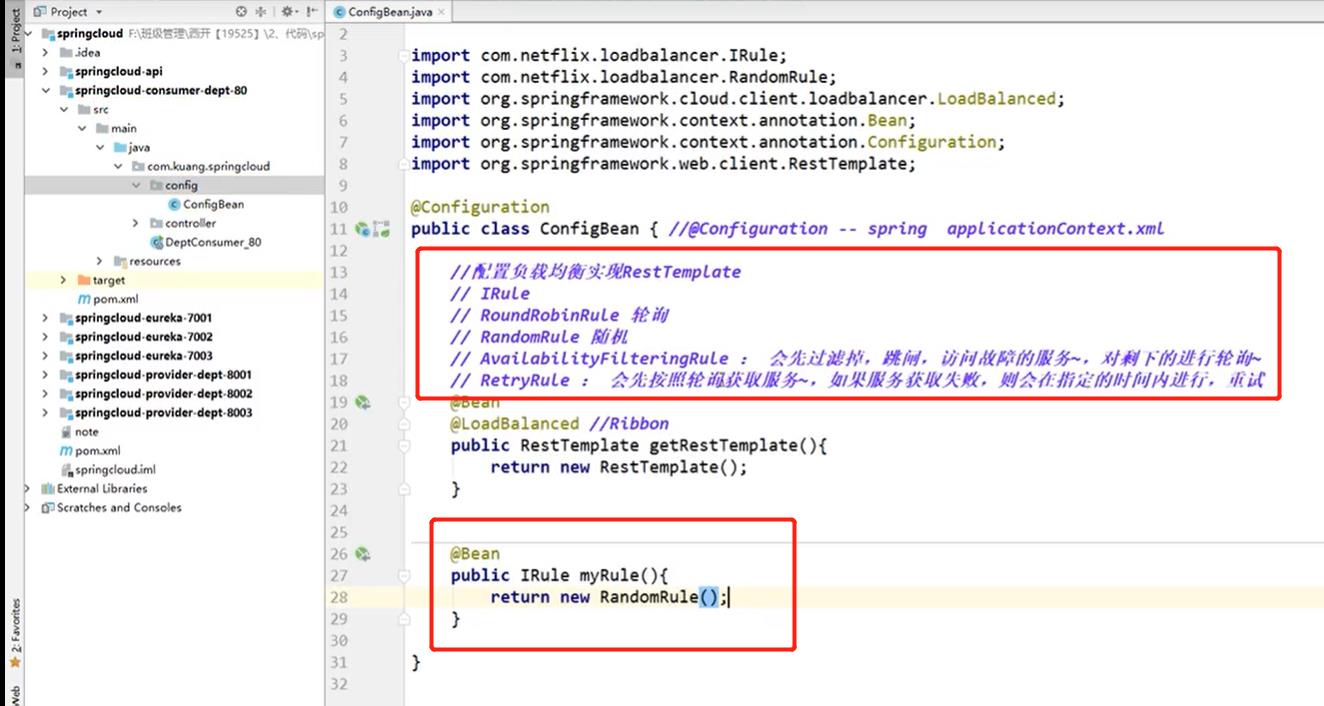
启动集群1,三个服务还有客户端,访问的时候就可以发现是按照我们定义的算法进行访问数据的。
正常情况下不应该将自定义的算法放到config中,应该在我的组件中去定义。
在客户端中添加一个组件:
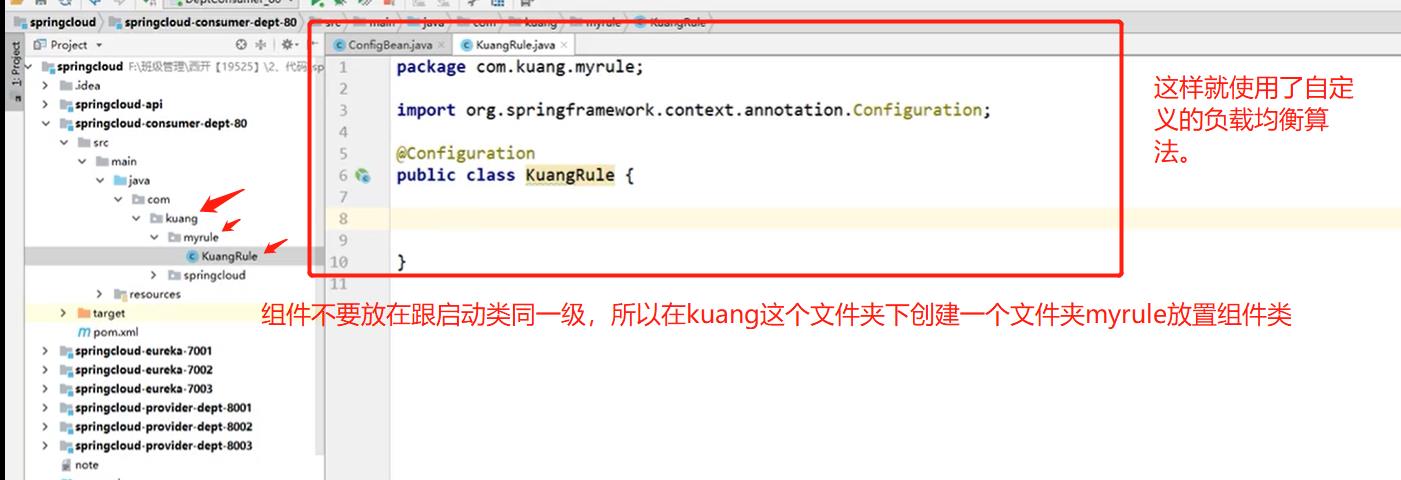
然后再客户端启动类中使用到这个组件:
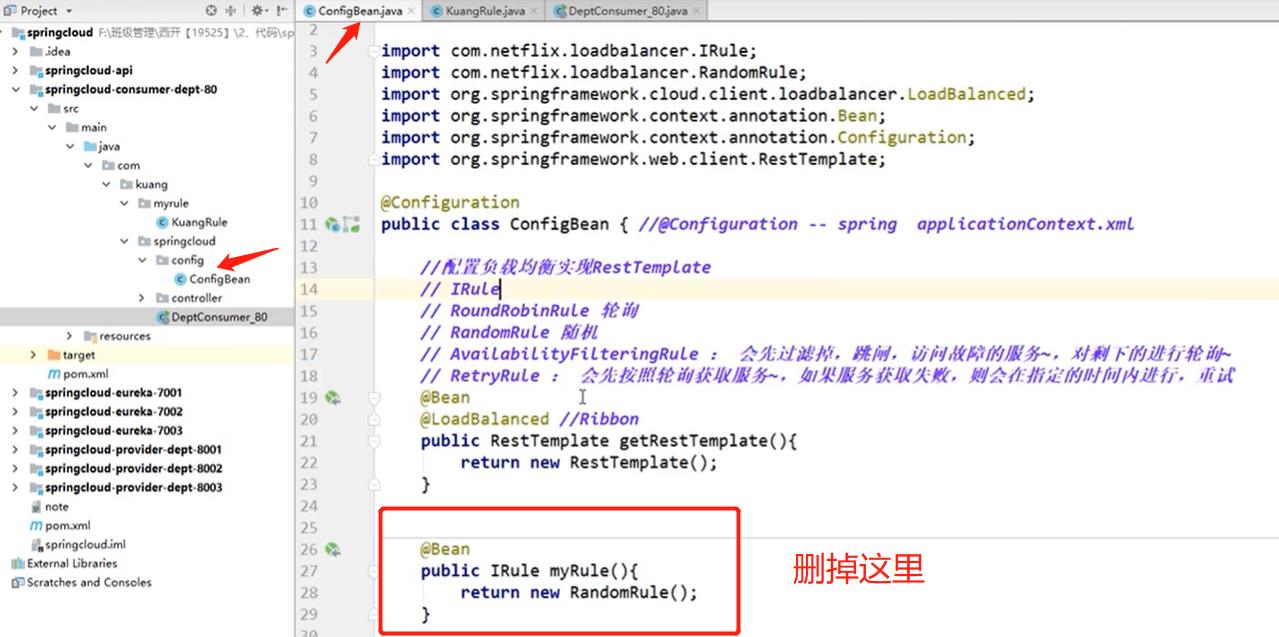
然后要将config中的自定义算法去掉,在组件类中自定义算法。
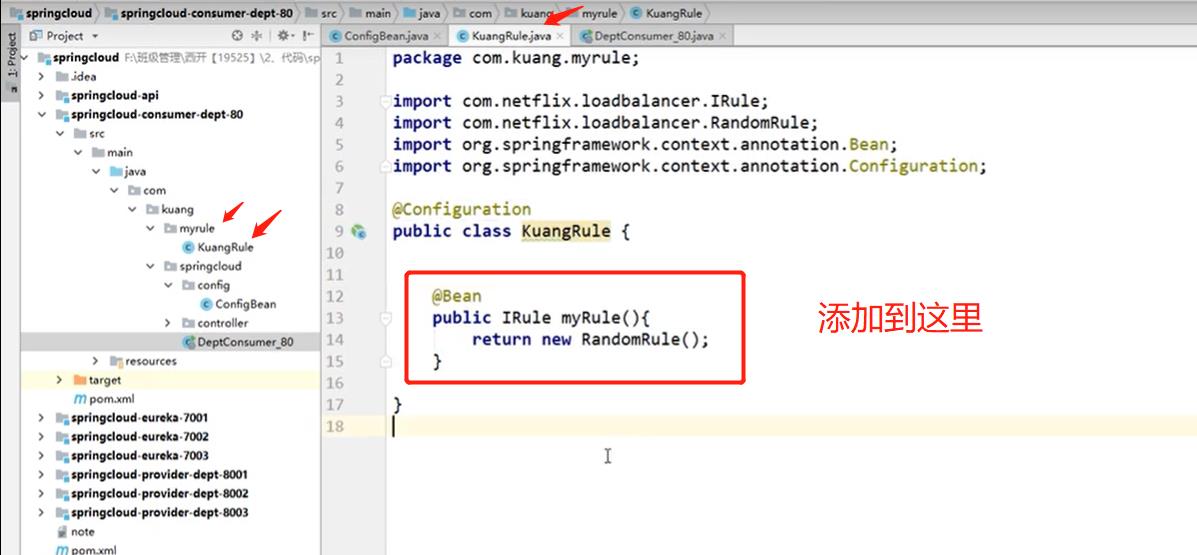
注意:
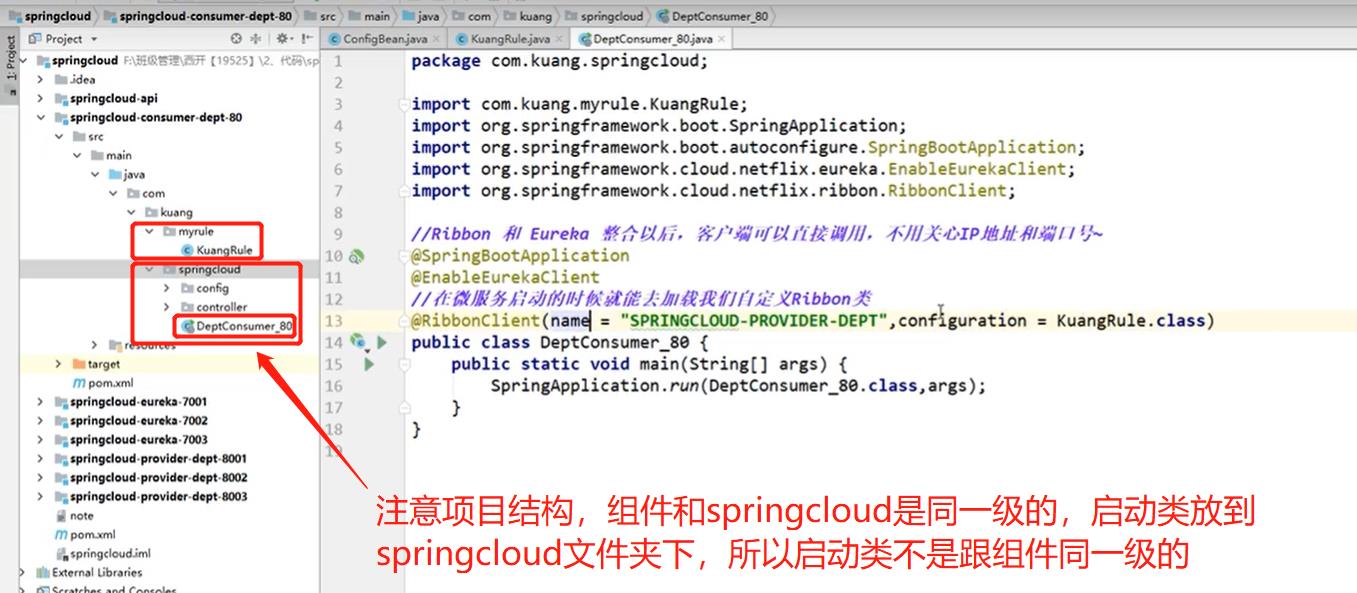
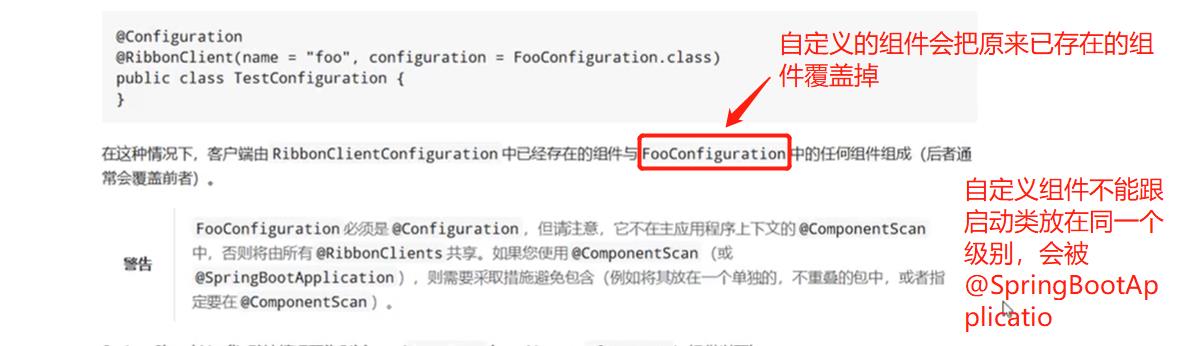
不要放在同一级,会被@SpringBootApplication扫描到,也就是spring会自动扫描到bean里,被扫描到了,如果那个组件你不想用,他也会生效的,被扫描到就不会被覆盖了,会被所有的RibbonClient客户端共享,如果想单独模块使用自己的策略,那就放到外面,就不会被共享到了。

9、Feign负载均衡
9.1、简介



9.2、Feign使用步骤
在4.3小节父工程中创建的子工程
-
创建一个跟4.6客户端一样的普通maven项目,作为第二个客户端
-
将第一个客户端中的pom依赖、yml配置文件和springcloud文件夹下的文件都拷贝到创建好的第二个客户端中,将自定义的负载均衡策略删掉,启动类名字改成第二个客户端对应的。
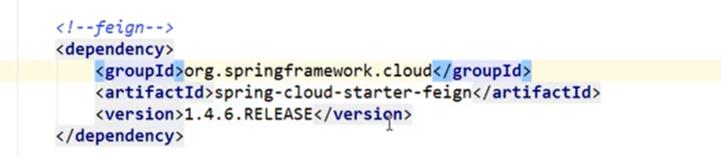
依赖还要添加一个feign依赖:
-
在第一个子工程也即是4.4小节中的子工程中的pom文件中也导入依赖feign
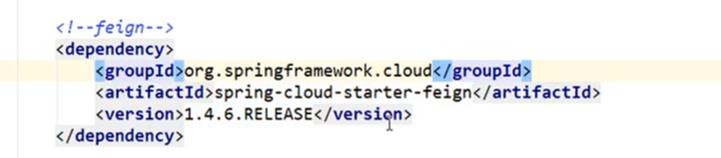
-
在第一个子工程也就是4.4小节的子工程中添加service层,代码如下:
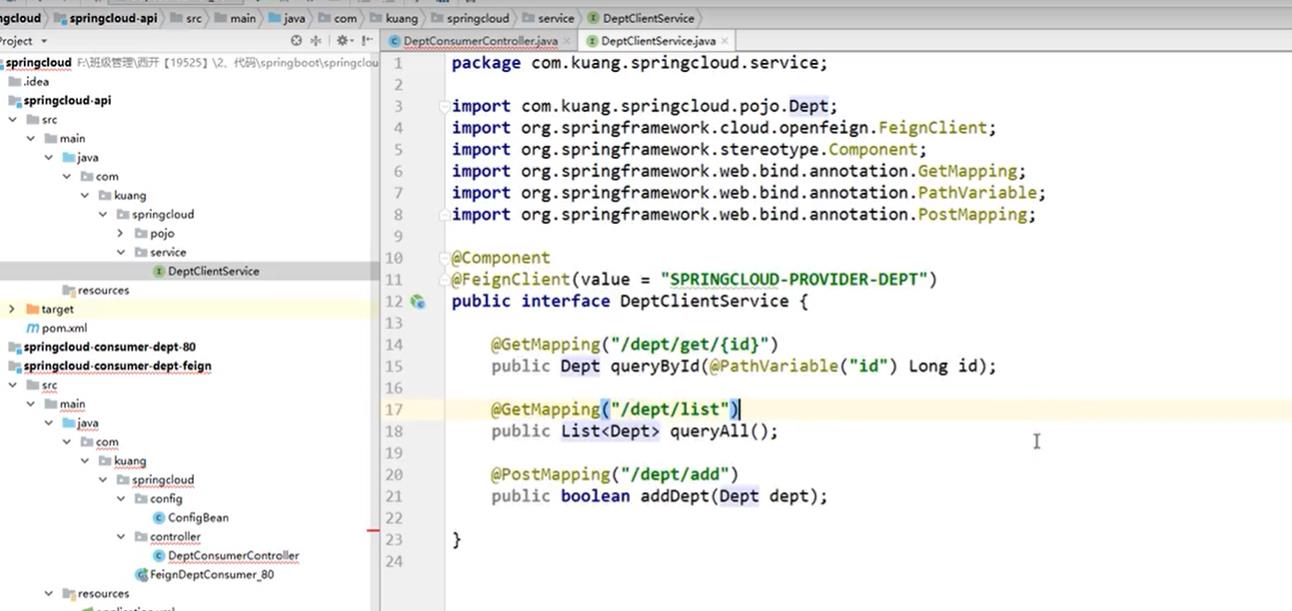
-
在第二个客户端中的controller层调用上面设置到的service层服务。
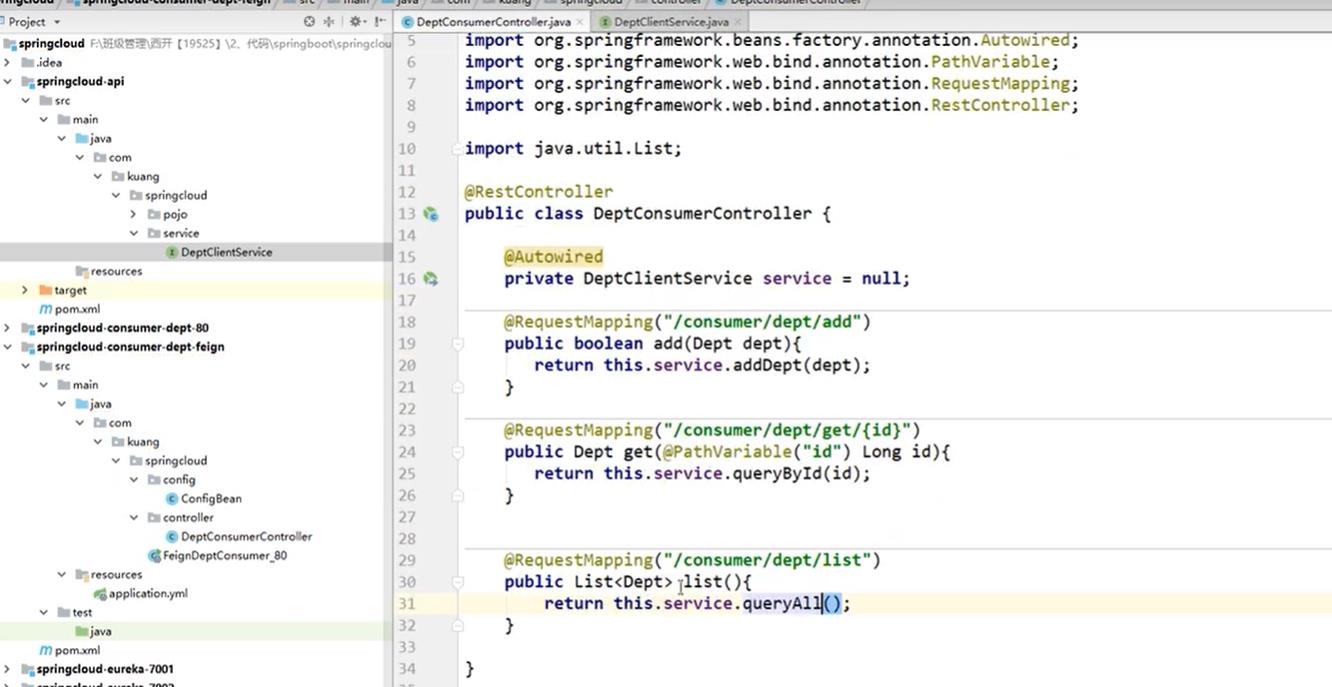
对比一下第一个客户端中的controller层代码,可以发现第一个客户端是使用微服务名称进行调用的,而第二个客户端是使用feign访问的。这也是调用微服务访问的两种方式
- 第二个客户端的启动类添加如下代码:
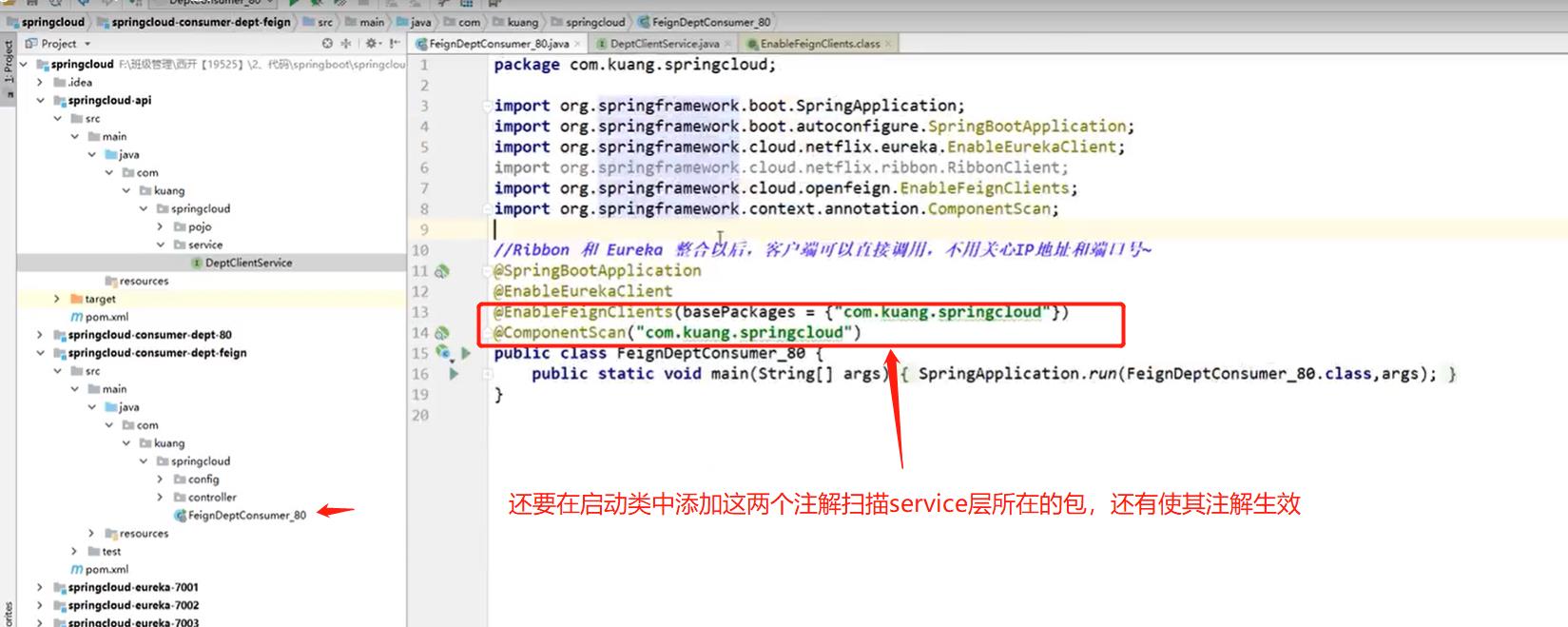
- 启动第一个集群,启动注册服务8001,8002,启动feign第二个客户端(第二个客户端和第一个客户端的端口都是80,所以启动第二个客户端的时候记得先关闭第一个客户端,否则端口被占用)

如果出现超时错误,可以继续刷新一下就可以了

10、Hystrix
10.1、分布式系统面临的问题
复杂的分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败!
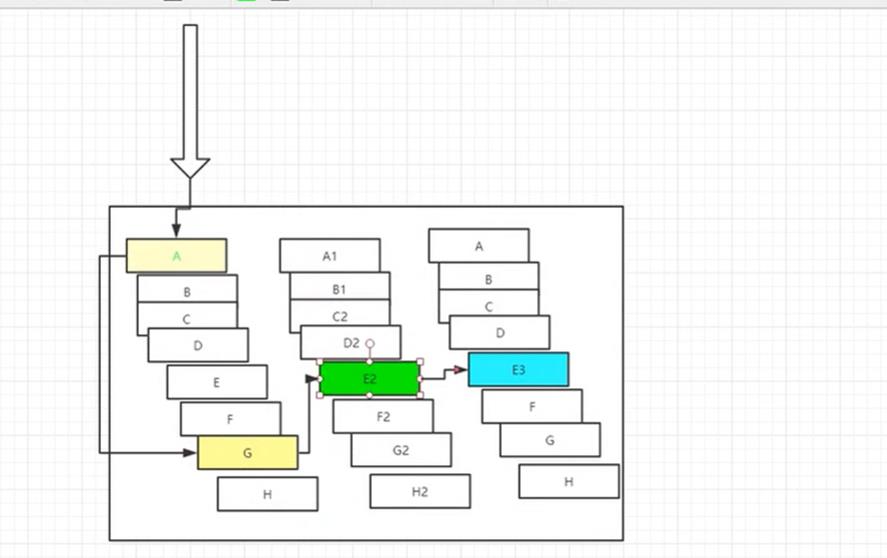
在这里要是E2崩了,那么其他调用者就会等待E2的资源,这样一直等待就会占用资源。
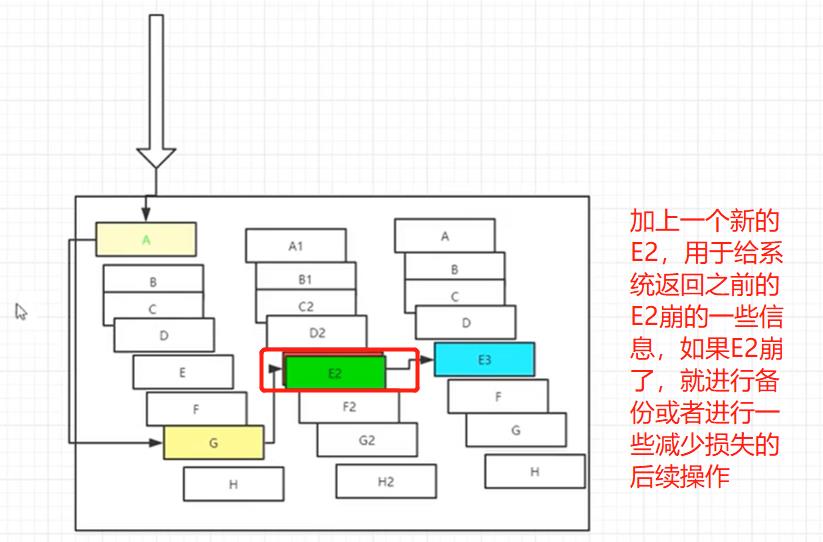
10.2、服务雪崩

10.3、什么是Hystrix


10.4、Hystrix服务熔断

所有的项目都是在一开始建立的父工程下创建的子工程。
可以直接将第一个服务也即是8001那个服务的项目直接拷贝到父项目中,修改项目添加到父项目的pom文件中即可,要是怕直接拷贝整个项目出现问题,可以按照下面方法一步一步拷贝。
-
创建一个普通的maven子项目
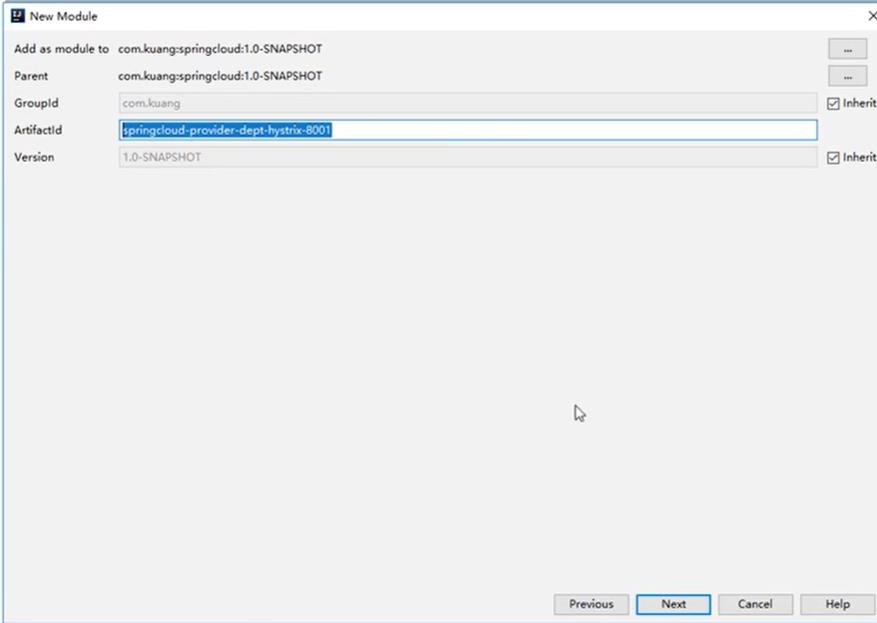
-
将第一个服务8001中的pom文件拷贝到这个子项目中的pom文件中
-
将第一个服务8001中的resources下的资源都拷贝到子项目中的resources文件夹下。
-
将8001中的com.kuang.springcloud目录下的所有文件拷贝到新建的子项目中
-
启动类改变个名字
-
在子项目中pom依赖中再添加一个依赖:
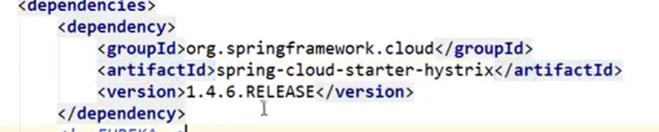
-
修改yml配置文件:
-
修改controller层代码:
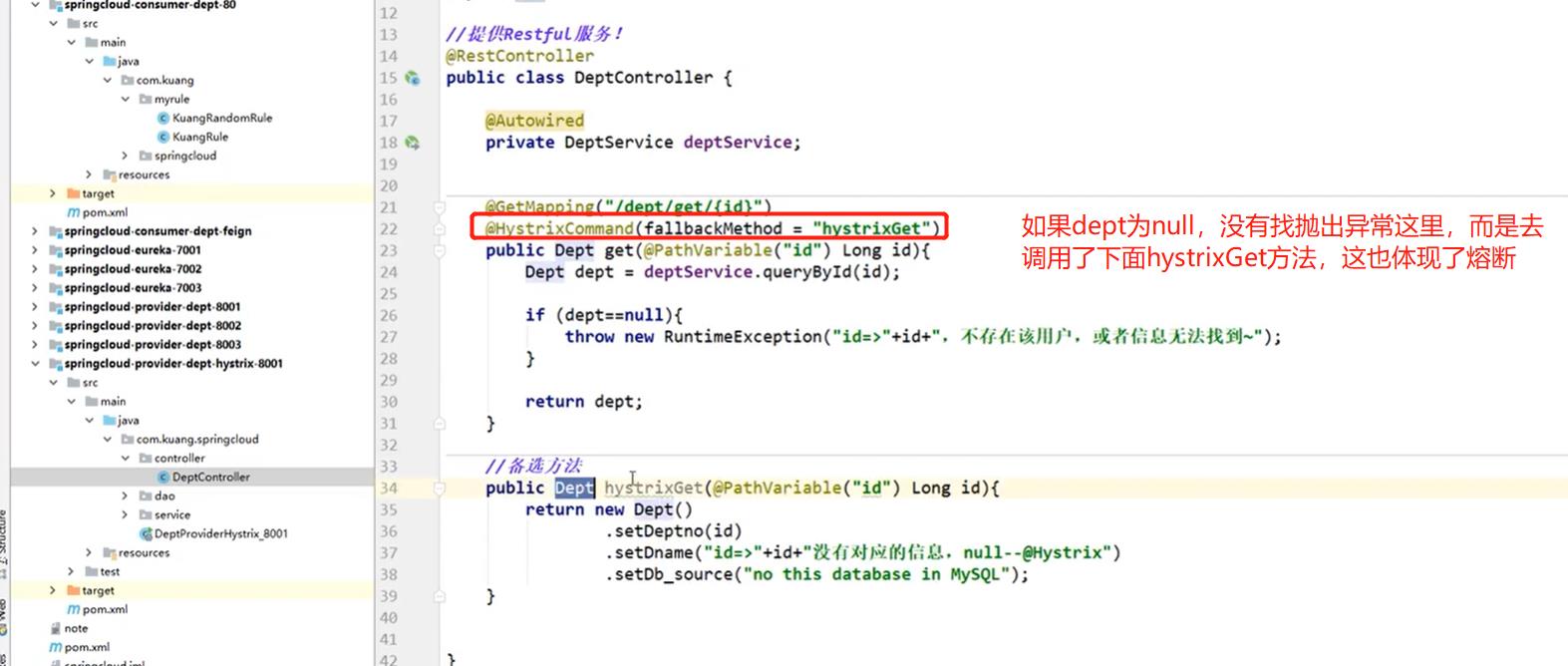
== 服务崩了会抛出异常,熔断截取这个异常,走另一个请求,只要不是Hystrix异常都可以截取的,再考虑另一种,我B服务崩了,但是我A服务没崩,我A服务去调用B服务,调用失败返回异常。== -
修改启动类,添加注解
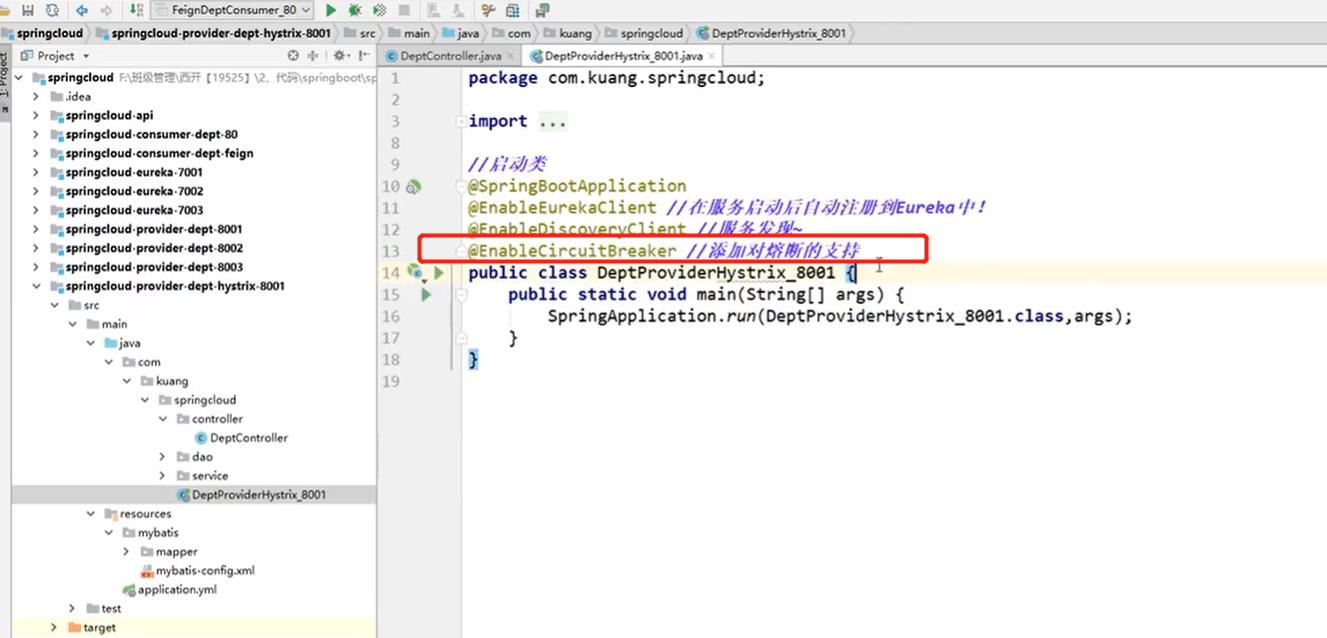
-
启动集群1,集群2,然后启动熔断,启动第一个客户端