Python异常处理
Posted dongye95
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python异常处理相关的知识,希望对你有一定的参考价值。
一、异常和错误
1.1 程序中难免出现错误,而错误分成两种
1.语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正)


#语法错误示范一 if #语法错误示范二 def test: pass #语法错误示范三 print(haha
2.逻辑错误(逻辑错误)
#用户输入不完整(比如输入为空)或者输入非法(输入不是数字) num=input(">>: ") int(num) #无法完成计算 res1=1/0 res2=1+\'str\'
1.1 什么是异常
异常就是程序运行时发生错误的信号,在python中,错误触发的异常如下:
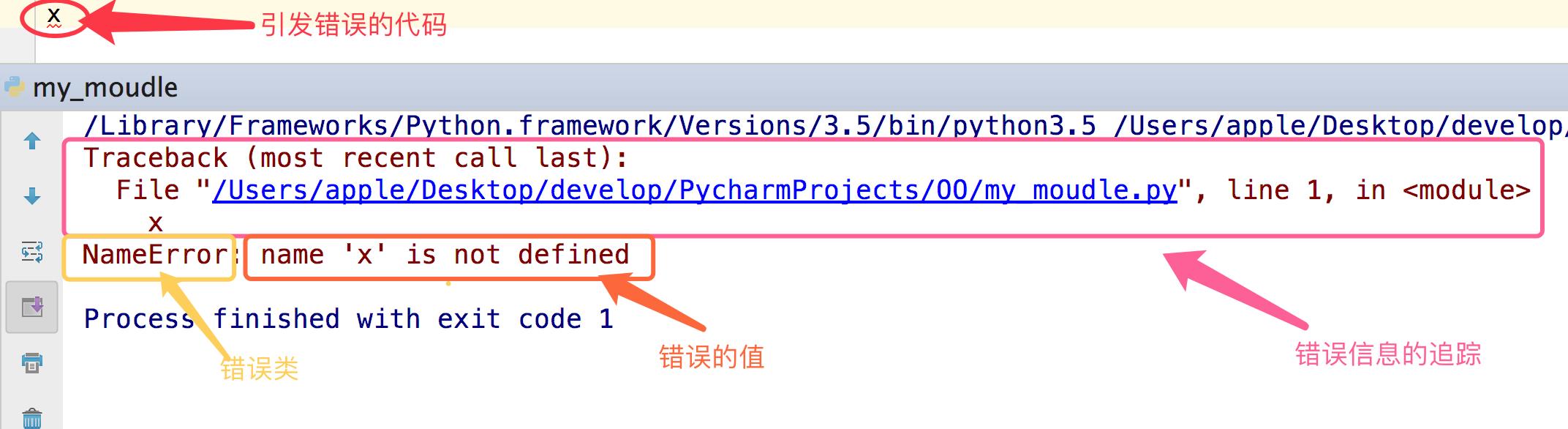
1.3 python中的异常种类
在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误
1.3.1 触发IndexError
l=[\'egon\',\'aa\'] l[3]
1.3.2 触发KeyError
dic={\'name\':\'egon\'}
dic[\'age\']
1.3.3 触发ValueError
s=\'hello\' int(s)
1.3.4 常用异常
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
1.3.5 更多异常
ArithmeticError
AssertionError
AttributeError
BaseException
BufferError
BytesWarning
DeprecationWarning
EnvironmentError
EOFError
Exception
FloatingPointError
FutureWarning
GeneratorExit
ImportError
ImportWarning
IndentationError
IndexError
IOError
KeyboardInterrupt
KeyError
LookupError
MemoryError
NameError
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
ReferenceError
RuntimeError
RuntimeWarning
StandardError
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
ZeroDivisionError
二、异常处理
2.1 什么是异常
异常发生之后
异常之后的代码就不执行了
2.2 什么是异常处理
python解释器检测到错误,触发异常(也允许程序员自己触发异常)
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
2.3 为什么要进行异常处理?
python解析器去执行程序,检测到了一个错误时,触发异常,异常触发后且没被处理的情况下,程序就在当前异常处终止,后面的代码不会运行,谁会去用一个运行着突然就崩溃的软件。
所以你必须提供一种异常处理机制来增强你程序的健壮性与容错性
2.4 如何进行异常处理?
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正
2.4.1 使用if判断式
正常代码 num1=input(\'>>: \') #输入一个字符串试试 int(num1)
-
使用if判断进行异常处理 #_*_coding:utf-8_*_ __author__ = \'Linhaifeng\' num1=input(\'>>: \') #输入一个字符串试试 if num1.isdigit(): int(num1) #我们的正统程序放到了这里,其余的都属于异常处理范畴 elif num1.isspace(): print(\'输入的是空格,就执行我这里的逻辑\') elif len(num1) == 0: print(\'输入的是空,就执行我这里的逻辑\') else: print(\'其他情情况,执行我这里的逻辑\') \'\'\' 问题一: 使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂 问题二: 这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。 \'\'\'
总结:
1.if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
2.在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差
3.if是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理。
你之前用的异常处理机制 def test(): print(\'test running\') choice_dic={ \'1\':test } while True: choice=input(\'>>: \').strip() if not choice or choice not in choice_dic:continue #这便是一种异常处理机制啊 choice_dic[choice]()
2.4.2 python为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来进行异常处理
part1:基本语法
读文件例子
读文件例子
try: 被检测的代码块 except 异常类型: try中一旦检测到异常,就执行这个位置的逻辑
-
try: f = open(\'a.txt\') g = (line.strip() for line in f) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) except StopIteration: f.close() \'\'\' next(g)会触发迭代f,依次next(g)就可以读取文件的一行行内容,无论文件a.txt有多大,同一时刻内存中只有一行内容。 提示:g是基于文件句柄f而存在的,因而只能在next(g)抛出异常StopIteration后才可以执行f.close() \'\'\'
part2:异常类只能用来处理指定的异常情况,如果非指定异常则无法处理。
# 未捕获到异常,程序直接报错 s1 = \'hello\' try: int(s1) except IndexError as e: print e
part3:多分支
s1 = \'hello\' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
part4:万能异常 在python的异常中,有一个万能异常:Exception,他可以捕获任意异常,即:
s1 = \'hello\' try: int(s1) except Exception as e: print(e)
你可能会说既然有万能异常,那么我直接用上面的这种形式就好了,其他异常可以忽略
你说的没错,但是应该分两种情况去看
1.如果你想要的效果是,无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理他们,那么骚年,大胆的去做吧,只有一个Exception就足够了。
s1 = \'hello\' try: int(s1) except Exception,e: \'丢弃或者执行其他逻辑\' print(e) #如果你统一用Exception,没错,是可以捕捉所有异常,但意味着你在处理所有异常时都使用同一个逻辑去处理(这里说的逻辑即当前expect下面跟的代码块)
2.如果你想要的效果是,对于不同的异常我们需要定制不同的处理逻辑,那就需要用到多分支了。
多分支 s1 = \'hello\' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e)
多分支+Exception
多分支+Exception s1 = \'hello\' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) except Exception as e: print(e)
part5:异常的其他机构
s1 = \'hello\' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) #except Exception as e: # print(e) else: print(\'try内代码块没有异常则执行我\') finally: print(\'无论异常与否,都会执行该模块,通常是进行清理工作\')
part6:主动触发异常
try: raise TypeError(\'类型错误\') except Exception as e: print(e)
part7:自定义异常
class EvaException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise EvaException(\'类型错误\') except EvaException as e: print(e)
part8:try..except的方式比较if的方式的好处
try..except这种异常处理机制就是取代if那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性
异常处理中为每一个异常定制了异常类型(python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到,可以同时处理多段代码的异常(无需‘写多个if判断式’)减少了代码,增强了可读性
使用try..except的方式
1:把错误处理和真正的工作分开来
2:代码更易组织,更清晰,复杂的工作任务更容易实现;
3:毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;
三 什么时候用异常处理
有的同学会这么想,学完了异常处理后,好强大,我要为我的每一段程序都加上try...except,干毛线去思考它会不会有逻辑错误啊,这样就很好啊,多省脑细胞。
try...except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,才应该加上try...except,其他的逻辑错误应该尽量修正
四、断言
“断言”是一个心智正常的检查,确保代码没有做什么明显错误的事情。这些心智正常的检查由 assert 语句执行。如果检查失败,就会抛出异常。在代码中,assert语句包含以下部分:
- assert 关键字;
- 条件(即求值为 True 或 False 的表达式);
- 逗号;
- 当条件为 False 时显示的字符串。
例如,在交互式环境中输入以下代码:
>>> podBayDoorStatus = \'open\' >>> assert podBayDoorStatus == \'open\', \'The pod bay doors need to be "open".\' >>> podBayDoorStatus = \'I\\\'m sorry, Dave. I\\\'m afraid I can\'t do that.\'\' >>> assert podBayDoorStatus == \'open\', \'The pod bay doors need to be "open".\' Traceback (most recent call last): File "<pyshell#10>", line 1, in <module> assert podBayDoorStatus == \'open\', \'The pod bay doors need to be "open".\' AssertionError: The pod bay doors need to be "open".
这里将 podBayDoorStatus 设置为 \'open\',所以从此以后,我们充分期望这个变量的值是 \'open\'。在使用这个变量的程序中,基于这个值是 \'open\' 的假定,我们可能写下了大量的代码,即这些代码依赖于它是 \'open\',才能按照期望工作。所以添加了一个断言,确保假定 podBayDoorStatus 是 \'open\' 是对的。这里,我们加入了信息 \'Thepod bay doors need to be "open".\',这样如果断言失败,就很容易看到哪里出了错。稍后,假如我们犯了一个明显的错误,把另外的值赋给 podBayDoorStatus,但在很多行代码中,我们并没有意识到这一点。这个断言会抓住这个错误,清楚地告诉我们出了什么错。在日常英语中,assert 语句是说:“我断言这个条件为真,如果不为真,程序中什么地方就有一个缺陷。”不像异常,代码不应该用 try 和 except 处理 assert 语句。如果assert 失败,程序就应该崩溃。通过这样的快速失败,产生缺陷和你第一次注意到该缺陷之间的时间就缩短了。这将减少为了寻找导致该缺陷的代码,而需要检查的代码量。断言针对的是程序员的错误,而不是用户的错误。对于那些可以恢复的错误(诸如文件没有找到,或用户输入了无效的数据),请抛出异常,而不是用assert 语句检测它。
在交通灯模拟中使用断言
假定你在编写一个交通信号灯的模拟程序。代表路口信号灯的数据结构是一个字典,以 \'ns\' 和 \'ew\' 为键,分别表示南北向和东西向的信号灯。这些键的值可以是 \'green\'、\'yellow\' 或 \'red\' 之一。代码看起来可能像这样:
market_2nd = {\'ns\': \'green\', \'ew\': \'red\'}
mission_16th = {\'ns\': \'red\', \'ew\': \'green\'}
这两个变量将针对 Market 街和第 2 街路口,以及 Mission 街和第 16 街路口。作为项目启动,你希望编写一个 switchLights() 函数,它接受一个路口字典作为参数,并切换红绿灯。开始你可能认为,switchLights() 只要将每一种灯按顺序切换到下一种顔色:\'green\' 值应该切换到 \'yellow\',\'yellow\' 应该切换到 \'red\',\'red\' 应该切换到\'green\'。实现这个思想的代码看起来像这样:
def swithLights(stoplight): for key in stoplight.keys(): if stoplight[key] == \'green\': stoplight[key] = \'yellow\' elif stoplight[key] == \'yellow\': stoplight[key] = \'red\' elif stoplight[key] == \'red\': stoplight[key] = \'green\' assert \'red\' in stoplight.values(), \'Neither light is red! \' + str(stoplight) swithLights(market_2nd)
你可能已经发现了这段代码的问题,但假设你编写了剩下的模拟代码,有几千行,但没有注意到这个问题。当最后运行时,程序没有崩溃,但虚拟的汽车撞车了!因为你已经编写了剩下的程序,所以不知道缺陷在哪里。也许在模拟汽车的代码中,或者在模拟司机的代码中。可能需要花几个小时追踪缺陷,才能找到switchLights() 函数。但如果在编写 switchLights() 时,你添加了断言,确保至少一个交通灯是红色,可能在函数的底部添加这样的代码:
assert \'red\' in stoplight.values(), \'Neither light is red! \' + str(stoplight)
有了这个断言,程序就会崩溃,并提供这样的出错信息:
Traceback (most recent call last): File "carSim.py", line 14, in <module> switchLights(market_2nd) File "carSim.py", line 13, in switchLights assert \'red\' in stoplight.values(), \'Neither light is red! \' + str(stoplight) AssertionError: Neither light is red! {\'ns\': \'yellow\', \'ew\': \'green\'}
这里重要的一行是 AssertionError。虽然程序崩溃并非如你所愿,但它马上指出了心智正常检查失败:两个方向都没有红灯,这意味着两个方向的车都可以走。在程序执行中尽早快速失败,可以省去将来大量的调试工作。
禁用断言
在运行 Python 时传入-O 选项,可以禁用断言。如果你已完成了程序的编写和测试,不希望执行心智正常检测,从而减慢程序的速度,这样就很好(尽管大多数断言语句所花的时间,不会让你觉察到速度的差异)。断言是针对开发的,不是针对最终产品。当你将程序交给其他人运行时,它应该没有缺陷,不需要进行心智正常检查。
五、其它(assertpy)
python自带的Assert功能并不尽人意,可用测试框架的断言机制,比如pytest的或者是unittest的等等。
还可以用assert包。强烈推荐assertpy 这个包,它异常强大而且好评如潮。它的 github主页:https://github.com/ActivisionGameScience/assertpy
它支持了几乎你能想到的所有测试场景,包括但不限于以下列表。
-
Strings
-
Numbers
-
Lists
-
Tuples
-
Dicts
-
Sets
-
Booleans
-
Dates
-
Files
-
Objects
而且它的断言信息简洁明了,不多不少。
Expected <foo> to be of length <4>, but was <3>. Expected <foo> to be empty string, but was not. Expected <False>, but was not. Expected <foo> to contain only digits, but did not. Expected <123> to contain only alphabetic chars, but did not. Expected <foo> to contain only uppercase chars, but did not. Expected <FOO> to contain only lowercase chars, but did not. Expected <foo> to be equal to <bar>, but was not. Expected <foo> to be not equal to <foo>, but was. Expected <foo> to be case-insensitive equal to <BAR>, but was not.
安装
pip install assertpy 引用 from assertpy import assert_that
可用于python的pytest、nose等单元测试框架 可用于断言strings、numbers、lists、tuples、dicts、sets、Booleans、dates、files、object等匹配字符串
类型判断
assert_that(’’).is_not_none()#不是null assert_that(’’).is_empty()#是空 assert_that(’’).is_false()#是false assert_that(’’).is_type_of(str)#是str的类型 assert_that(’’).is_instance_of(str)#是str的实例
常用
assert_that(‘foo’).is_length(3)#字符串长度是3 assert_that(‘foo’).is_not_empty()#不是空的 assert_that(‘foo’).is_true()#是true assert_that(‘foo’).is_alpha()#是字母 assert_that(‘123’).is_digit()#是数字 assert_that(‘foo’).is_lower()#是小写的 assert_that(‘FOO’).is_upper()#是大写的 assert_that(‘foo’).is_iterable()#是可迭代类型 assert_that(‘foo’).is_equal_to(‘foo’)#相同 assert_that(‘foo’).is_not_equal_to(‘bar’)#不相同 assert_that(‘foo’).is_equal_to_ignoring_case(‘FOO’)#忽略大小写等于
编码
assert_that(u’foo’).is_unicode() # on python 2#是unicode编码 assert_that(‘foo’).is_unicode() # on python 3#是unicode编码
是否含有部分字符或子字符串
assert_that(‘foo’).contains(‘f’)#字符串包含该字符 assert_that(‘foo’).contains(‘f’,‘oo’)#包含这个字符和这个字符串 assert_that(‘foo’).contains_ignoring_case(‘F’,‘oO’)#忽略大小写包含这个字符和这个字符串 assert_that(‘foo’).does_not_contain(‘x’)#不包含该字符 assert_that(‘foo’).contains_only(‘f’,‘o’)#仅包含f和0字符 assert_that(‘foo’).contains_sequence(‘o’,‘o’)#包含’o’,‘o’序列
是否含有重复字符
assert_that(‘foo’).contains_duplicates()#包含重复字符 assert_that(‘fox’).does_not_contain_duplicates()#不包含重复字符
是否属于几个字符串中的一个,或者大字符串的部分字符串
assert_that(‘foo’).is_in(‘foo’,‘bar’,‘baz’)#在这几个字符串中 assert_that(‘foo’).is_not_in(‘boo’,‘bar’,‘baz’)#不在这几个字符串中 assert_that(‘foo’).is_subset_of(‘abcdefghijklmnopqrstuvwxyz’)#是后面字符串的子集 字符串的头尾字符或子字符串 assert_that(‘foo’).starts_with(‘f’)#字符串以f字符开始 assert_that(‘foo’).ends_with(‘oo’)#字符串以oo字符串结束
匹配正则
assert_that(‘foo’).matches(r’\\w’) assert_that(‘123-456-7890’).matches(r’\\d{3}-\\d{3}-\\d{4}’) assert_that(‘foo’).does_not_match(r’\\d+’)
匹配数字
整数
整数类型判断
assert_that(0).is_not_none()#不是空 assert_that(0).is_false()#是false assert_that(0).is_type_of(int)#是int类型 assert_that(0).is_instance_of(int)#是int的实例
整数0正负判断
assert_that(0).is_zero()#是0 assert_that(1).is_not_zero()#不是0 assert_that(1).is_positive()#是正数 assert_that(-1).is_negative()#是负数
整数是否等于判断
assert_that(123).is_equal_to(123)#等于 assert_that(123).is_not_equal_to(456)#不等于
整数 区间、大小判断
assert_that(123).is_greater_than(100)#大于 assert_that(123).is_greater_than_or_equal_to(123)#大于等于 assert_that(123).is_less_than(200)#小于 assert_that(123).is_less_than_or_equal_to(200)#小于等于 assert_that(123).is_between(100, 200)#之间 assert_that(123).is_close_to(100, 25)#接近于
整数是否属于判断
assert_that(1).is_in(0,1,2,3)#是后面的某一个 assert_that(1).is_not_in(-1,-2,-3)#不是后面的任何一个
浮点数
浮点数类型判断
assert_that(0.0).is_not_none()#不是空 assert_that(0.0).is_false()#是false assert_that(0.0).is_type_of(float)#是浮点类型 assert_that(0.0).is_instance_of(float)#是浮点的实例
浮点数是否等于判断
assert_that(123.4).is_equal_to(123.4)#等于 assert_that(123.4).is_not_equal_to(456.7)#不等于
浮点数区间、大小判断
assert_that(123.4).is_greater_than(100.1)#大于 assert_that(123.4).is_greater_than_or_equal_to(123.4)#大于等于 assert_that(123.4).is_less_than(200.2)#小于 assert_that(123.4).is_less_than_or_equal_to(123.4)#小于等于 assert_that(123.4).is_between(100.1, 200.2)#之间 assert_that(123.4).is_close_to(123, 0.5)#接近于
nan和inf
assert_that(float(‘NaN’)).is_nan()#是NaN(未定义或不接可表述的值) assert_that(123.4).is_not_nan()#不是NaN assert_that(float(‘Inf’)).is_inf()#是inf(无穷大) assert_that(123.4).is_not_inf()#不是inf nan是无效数字,inf是无穷大数字
列表
多层列表时,可通过extracting取出子列表的值 people = [[‘Fred’, ‘Smith’], [‘Bob’, ‘Barr’]] assert_that(people).extracting(0).is_equal_to([‘Fred’,‘Bob’]) assert_that(people).extracting(-1).is_equal_to([‘Smith’,‘Barr’]) 列表、元祖和字符串的断言类似
自己写错误原因
assert_that(x,"错误原因").contains("a")
以上是关于Python异常处理的主要内容,如果未能解决你的问题,请参考以下文章