Kafka未触发消费异常排查实录
Posted EJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka未触发消费异常排查实录相关的知识,希望对你有一定的参考价值。
前言:
最近生产环境系统发现一个疑难杂症,看了很久的问题但是始终无法定位到问题并处理,然后查阅了相关资料也是定位不到问题,不过资料查阅却给了个新的思路,以此为跳板最终解决了问题。
一、问题描述
功能介绍: “主计划拆分子计划”是APS系统很常见的功能,功能大概意思是用户可选多个主计划一次性进行“展开子计划”生成子计划,因单个主计划生成子计划的逻辑相对复杂,所以单个计划耗时不能算低,故这里的批量操作使用了异步进行,这里使用了Kafka进行生产及消费消息。
问题起因: 功能完成之后上生产系统,然而偶尔会收到客户提出少量单据卡在中间状态,导致“展开”不了的问题,前前后后查了好久也没能找到具体问题并解决。
二、问题分析
分析数据: 通过查看用户提供的单据,发现这些数据都是卡在了某一个中间状态,这个状态是作为中转状态使用的,一开始计划的状态为“未展开”,点击执行“展开子计划”的功能之后,将计划标识为“展开中”之后再推送到Kafka消费处理,Kafka消费者接收到生产者的消息之后,将计划进行处理,处理完成之后再将状态标识为“展开完成”。
所以从数据上分析,问题点应该出现在消息生产到消费过程这段期间,但是纵观代码,发现已经对业务逻辑做了异常处理,如果是消息消费过程发生异常,都会将错误过程记录下来,所以再次定位到问题出现在Kafka的生产消息及消费消息这个过程。
查看日志: 根据以上分析结合日志监控的方式,确定问题数据实际上并未进行消费,所以猜想有两种情况:
- Kafka根本没有生产消息成功;
- 生产消息成功,但是Kafka未Poll到需要消费的消息。
三、进展
- 加addCallback回调方法
- 生产端的kafkaTemplate对象中,封装发送消息的方法,将send()方法封装为通用方法,增加addCallback()回调方法,用于消息生产成功之后回调记录日志。以此确认生产消息是否成功.

2. 参考相关资料:
查问题过程中,看到大佬写的文章,文章里描述了造成消费不成功的问题是因为“Kafka 内存饱和”造成的,但是实际上内存饱和造成的问题是Kafka消费服务Poll消息时候超时,相应的错误信息在我们系统日志中搜不到,最终也确认不是因为改原因造成的问题。(文章下文参考)
- 【AGP网关】Kafka 异常排查实(内网文章)
-
记一次kafka消费者不消费,消费组被踢出问题(外网文章)
- 研究kafka消费原理
当前确认问题点应该是出现在消费端消费不了消息导致的,那么重新研究一下Kafka消费端的实现原理。
消费者是通过KafkaConsumer对象的poll方法从Kafka队列中将消息拉取出来进行消费,这个poll方法可传入poll超时时间,超过设置的时间则会报拉取超时的异常“due to consumer poll timeout has expired.”,上文中大佬出现的报错就是提示这种拉取超时的报错,超时时间可通过配置节点【max.poll.interval.ms】进行配置;
KafkaConsumer对象poll到数据之后取到ConsumerRecords对象,然后就可以对数据进行消费,直到取到的ConsumerRecords对象是空的(isEmpty()为true)才停止消费。
这里发现有一个隐患的地方,当ConsumerRecords对象取到空数据才停止消费,那么这个ConsumerRecords对象是否会取到多个数据进行消费,是如何进行消费的?!
查阅相关资料,发现Kafka的消费原理是:KafkaConsumer 对象是实时拉取消息的,但不是实时消费消息的。KafkaConsumer 在 poll() 方法中从 Kafka 集群中批量拉取数据,将多个消息封装在 ConsumerRecords 对象中返回。这些消息可以在消费者应用程序的时间间隔内处理,但poll() 方法返回的消息不是立即消费的。只有在 ConsumerRecords 中的所有消息都被处理后,才会发送下一个拉取请求。如果在处理消息时发生错误,可以根据实际需要重新处理这些消息或跳过这些消息。
反观项目代码,发现在KafkaListener监听器拉取到数据之后,项目中仅仅只是取第一条数据进行消费,这里是不是有问题呢?(参考下面代码块)
/** * 计划发布SAP-KTWKZ * * @param records * @param consumer */ @KafkaListener(topics = KafkaTopicConst.SCHEDULE_DAY_PLAN_RELEASE_SAP_KTWKZ_TOPIC, id = KafkaTopicConst.SCHEDULE_DAY_PLAN_RELEASE_SAP_KTWKZ_TOPIC, containerFactory = "batchFactory") public void dayPlanReleaseToSapKTWKZTopic(ConsumerRecords<String, String> records, Consumer<String, String> consumer) String data = ApsKafkaUtils.getFirstRecordValues(); log.info("mq消费-KT万颗子计划发布SAP数据:\\n", data); try SystemPostDTO systemPostDTO = JsonUtils.fromJson(data, SystemPostDTO.class); String postContent = systemPostDTO.getData(); if (StrUtil.isEmpty(postContent)) log.warn("mq消费-KT万颗子计划发布SAP数据异常警告,systemPostDTO.data数据不能为空"); return; pushRecordService.consumePushProductionOrderKtWKZ(postContent); catch (Exception e) log.error("mq消费-KT万颗子计划发布SAP数据异常:", e);
四、问题重现及
重现:
从第三点的分析中,暂时确定可能是ConsumerRecords对象接收到多条消息,但是消费端仅仅消费了第一条消息导致的问题,那么通过写demo来测试批量生产消息是否会导致ConsumerRecords一次性拉取到多条消息。
生产:
@ApiOperation("测试Kafka poll消息机制")
@PostMapping("/v99/schedule/kafka/test")
public ResponseEntity<String> testKafkaPollMessage(
@RequestParam("testData") String testData)
String topic = "my-test-topic";
for (int i = 0; i < 100; i++)
Thread.sleep(0);//参数有0,10,100
SubassemblyOpenPlanListInfoRespDTO dto = kafkaDemo.sendMessage(testData);
return Results.success("Success");
消费:
@KafkaListener(topics = "my-test-topic", id = "my-test-topic", containerFactory = "batchFactory") public void myTestKafka(ConsumerRecords<String, String> records, Consumer<String, String> consumer) List<String> recordValues = ApsKafkaUtils.getRecordValues(); try log.info("接收到的数据为【】", recordValues.size(), JsonUtils.toJson(recordValues)); catch (Exception e) log.error("接收到的数据为异常:", e);
以上接口,通过调用发现确实出现ConsumerRecords对象poll到多条消息的情况:
其中,for循环中执行等待时间越长,出现一个ConsumerRecords对象拉取到多条数据的情况越少:
那么分析为什么在实际使用过程中,【主计划拆分子计划】这个功能是偶然出现消费失败的问题,而不是稳定出现呢?
再次通过代码ReView的方式去回顾一下这个功能,发现当前代码中,是使用了for循环将一批次计划单循环推送给MQ进行消费,单个循环里执行了一次读库一次写库的操作,一次循环耗时大概几十毫秒,与上述demo的Thread.sleep(10)场景类似,所以基本确定偶发这种问题的原因出现在这里。
解决:
其实解决该问题很简单,只需要在消费端获取到ConsumerRecords对象之后,将拉取到的所有消息列表循环消费而不是只消费单条消息即可,之前的仅消费单条消息的场景经过沟通确认只存在某些特殊场景才需要使用,暂时不再保证该种场景。
五、总结
本案例中,通过日志、业务场景、写Demo使用并发工具等方式来分析及重现问题,将一个生产上的疑难杂症处理掉,其中也通过参考大佬的文章,虽然问题描述和大佬描述的基本一致,也和网络上的Blog描述一致,但是产生的问题却并不一样。
总的来说,其实解决问题不难,重要的是要了解问题,了解原理以及了解到解决问题的步骤,建议从多个方面一起查看问题。从其他参考文章描述中,可以从业务、日志、内存环境等查看问题,我这里补充一点,也可以多多结合业务来适当写demo去测试问题,可能也会有意外收获。
其他
大家有没有遇到其他的生产上的疑难杂症呢,大家都是怎么遇到问题,最后怎么解决问题呢,这里大家不妨进行讨论,也可以列出多多的跟进方案或者工具,大家一起学习进步。
kafka故障排查-consumer处理超时导致的异常
最近遇到一个kafka方面的问题,大致就是由于consumer处理业务超时,导致无法正常提交Offset,进而导致无法消费新消息的问题。下面我想从以下几个方面对此次故障排查进行复盘分析:业务背景、问题描述、排查思路、经验教训。一、业务背景
先简单描述一下业务背景吧。我们有个业务需要严格按顺序消费Topic消息,所以针对该topic设置了唯一的partition,以及唯一的副本。当同一个消费组的多个consumer启动时,只会有一个consumer订阅到该Topic,进行消费,保证同一个消费组内的消费顺序。
注:消费组的groupId名称为“smart-building-consumer-group”,订阅的Topic名称为“gate_contact_modify”。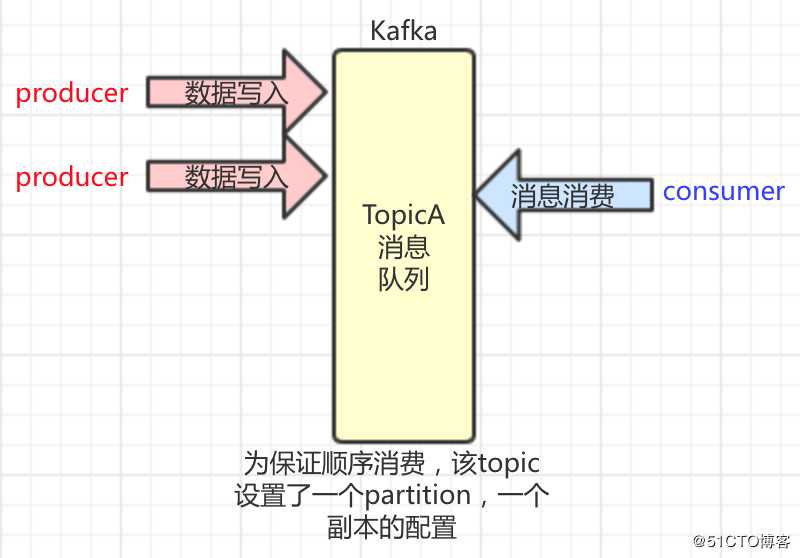
二、问题描述
有一天我们突然收到一个问题反馈:producer侧的业务产生消息后,consumer侧并没有得到预期的结果。经过排查,排除了业务逻辑出现问题的可能性,我们判断最有可能是因为kafka消息没有被消费到。为了印证这个猜测,我们查看了consumer消费日志,发现日志中存在这样几处问题:
(1)日志偶尔会打印出一条Kafka的警告日志,内容为:org.springframework.kafka.KafkaListenerEndpointContainer#2-0-C-1 org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.maybeAutoCommitOffsetsSync:648 - Auto-commit of offsets {gate_contact_modify-0=OffsetAndMetadata{offset=2801, metadata=‘‘}} failed for group smart-building-consumer-group: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
(2)接着进行了一次rebalance;
(3)consumer侧输出了Topic消费者的业务日志,表明正常获取到了Topic消息。
接着我们查看kafka 消费组中该Topic对应的Offset的变化情况,发现Offset一直没有变化。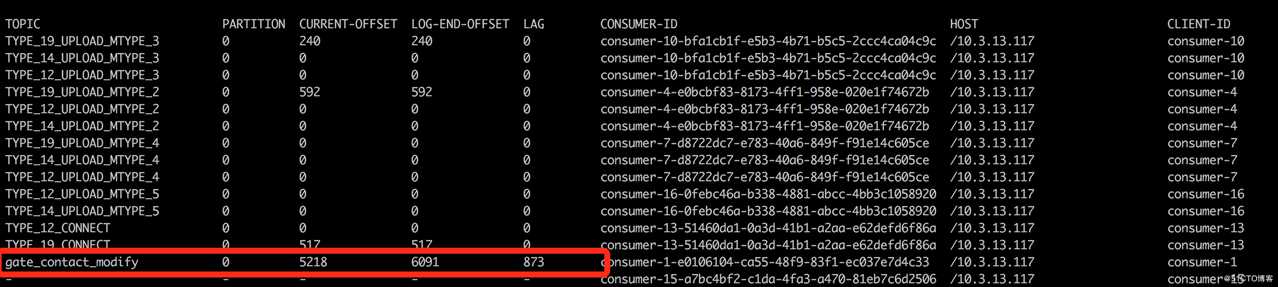
三、排查思路
日志中的异常信息很明确的告知我们,topic消息消费完成后,由于group发生了一次rebalance,导致Commit没有被提交,这表明两次poll消息的间隔时间超过了max.poll.interval.ms定义的最大间隔,这也意味着一次poll后处理消息的过程超时了,正是由于poll间隔时间超时,导致了一次rebalance。同时建议我们要么增加间隔时间,要么减少每次拉取的最大消息数。
另外,由于Commit没有被提交,导致OffSet值没有变化,那么每次拉取到的消息都是同一批重复消息。具体的异常流程如下图:
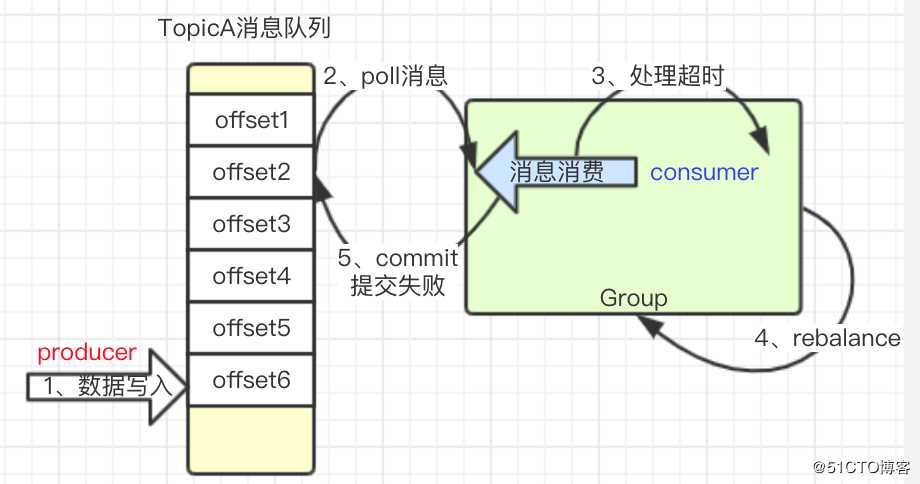
根据上述信息,我们进一步检查了consumer的max.poll.records配置、max.poll.interval.ms配置,并统计了每条Topic消息的处理耗时,发现max.poll.records使用了默认配置值500,max.poll.interval.ms使用了默认配置值为300s,而每条Topic消息的处理耗时为10S。这进一步证实了我们的推论:
由于每次拉取的消息数太多,而每条消息处理时间又较长,导致每次消息处理时间超过了拉取时间间隔,从而使得group进行了一次rebalance,导致commit失败,并最终导致下次拉取重复的消息、继续处理超时,进入一个死循环状态。
知道问题根源后,我们结合业务特点,更改了max.poll.records=1,每次仅拉取一条消息进行处理,最终解决了这个问题。
四、经验教训
这次故障排查,使我们对Kafka消息poll机制、rebalance和commit之间的相互影响等有了更深的理解。
(1)kafka每次poll可以指定批量消息数,以提高消费效率,但批量的大小要结合poll间隔超时时间和每条消息的处理时间进行权衡;
(2)一旦两次poll的间隔时间超过阈值,group会认为当前consumer可能存在故障点,会触发一次rebalance,重新分配Topic的partition;
(3)如果在commit之前进行了一次rebalance,那么本次commit将会失败,下次poll会拉取到旧的数据(重复消费),因此要保证好消息处理的幂等性;
以上是关于Kafka未触发消费异常排查实录的主要内容,如果未能解决你的问题,请参考以下文章